Start with a basic concurrency decomposition• A problem decomposed into a set of tasks• A data decomposition aligned with the set of tasks … designed to minimize
interactions between tasks and make concurrent updates to data safe.• Dependencies and ordering constraints between groups of tasks.
– A computation begins as a single thread of control. Additional threads are created as needed (forked) to execute functions and then when complete terminate (join). The computation continues as a single thread until a later time when more threads might be useful.
• SPMD– Multiple copies of a single program are launched typically with their own view of the data. The
path through the program is determined in part base don a unique ID (a rank). This is by far the most commonly used pattern with message passing APIs such as MPI.
• Loop parallelism– Parallelism is expressed in terms of loops that execute concurrently.
• Master-worker– A process or thread (the master) sets up a task queue and manages other threads (the workers)
as they grab a task from the queue, carry out the computation, and then return for their next task. This continues until the master detects that a termination condition has been met, at which point the master ends the computation.
• SIMD– The computation is a single stream of instructions applied to the individual components of a
data structure (such as an array). • Functional parallelism
– Concurrency is expressed as a distinct set of functions that execute concurrently. This pattern may be used with an imperative semantics in which case the way the functions execute are defined in the source code (e.g., event based coordination). Alternatively, this pattern can be used with declarative semantics, such as within a functional language, where the functions are defined but how (or when) they execute is dictated by the interaction of the data with the language model.
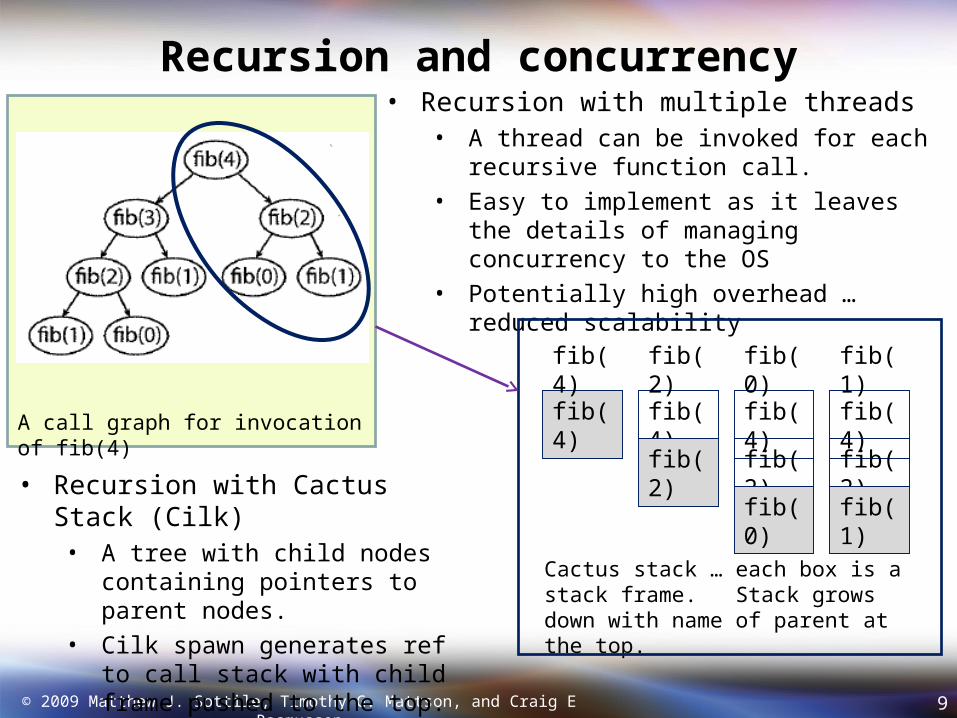
Cilk in one slide:• Extends C to create a parallel language but maintains serial semantics.• A task oriented programming model perfect for recursive algorithms
(e.g. branch-and-bound) … shared memory machines only!• Solid theoretical foundation … can prove performance theorems.
cilk Marks a function as a “cilk” function that can be spawned
spawn Spawns a cilk function … only 2 to 5 times the cost of a regular function call
sync Wait until immediate children spawned functions return
• “Advanced” key wordsinlet Define a function to handle return values from a cilk task
cilk_fence A portable memory fence.
abort Terminate all currently existing spawned tasks
• Also Includes locks and a few other odds and ends.
• Cilk makes it inexpensive to spawn new tasks.• Instead of loops, recursively generate lots of tasks.• Creates nested queues of tasks. A scheduler
intelligently uses work-stealing to keep all the cores busy as they work on these tasks.
With Cilk, the programmer worries about With Cilk, the programmer worries about expressing concurrency, not the details of expressing concurrency, not the details of how it is implementedhow it is implemented
With Cilk, the programmer worries about With Cilk, the programmer worries about expressing concurrency, not the details of expressing concurrency, not the details of how it is implementedhow it is implemented
// geometric decomposition implemented with the SPMD patternlong search_geom(long Nlen, long *a, long key){ long count = 0;
#pragma omp parallel reduction(+:count) { int i, num_threads = omp_get_num_threads(); int ID = omp_get_thread_num(); int istart = ID * N/num_threads; int iend = (ID+1)*N/num_threads;
if(ID == (num_threads-1)) iend = N;
for (i=istart; i<iend; i++) if(a[i]==key) count++; } return count;}
• Design Patterns used:• Geometric
Decomposition• SPMD
Source: Mattson and Keutzer, UCB CS294
This is a common trick to handle the case when N is not evenly divided by the number of threads
Count keys: with OpenMPlong search_recur(long Nlen, long *a, long key){ long count = 0; #pragma omp parallel reduction(+:count) { #pragma omp single count = search(Nlen, a, key); } return count;}
• Design Patterns used:• Divide and conquer • Fork-Join
long search(long Nlen, long *a, long key){ long count1=0, count2=0, Nl2; if (Nlen == 2){ if (*(a) == key) count1=1; if (*(a+1) == key) count2=1; return count1+count2; } else { Nl2 = Nlen/2; #pragma omp task shared(count1) count1 = search(Nl2, a, key); #pragma omp task shared(count2) count2 = search(Nl2, a+Nl2, key);
// A simple random number generator static unsigned long long MULTIPLIER = 764261123;static unsigned long long PMOD = 2147483647;unsigned long long random_last = 42;
long random(){ unsigned long long random_next;
// // compute an integer random number from zero to pmod// random_next = (unsigned long long)(( MULTIPLIER * random_last)% PMOD); random_last = random_next; return (long) random_next;
}
I include this for completeness … it has nothing to do with any parallelism
• Recursion concepts• Recursion and the divide and conquer pattern• Case study: sorting• Case Study: Sudoku
26
Merge Sort
• Sorting: An important class of algorithms that take an input list and generate a sorted list.\
• Merge sort– Split a list in two– Sort each half by a call to merge sort– Continue until you his a trivial base case.– Unwind the recursive stack to generate final list
/* merge sorted halves into sorted list */ merge(X, n, tmp);}
30
Main program for OpenMP merge sort
Source: Mattson and Keutzer, UCB CS294
• The only way to create threads in OpenMP is with a parallel construct.• Hence our parallel merge sort must occur within a parallel region.
#include “omp.h”#define MAX_SIZE 1000Int main(){ int n = 100; int data[MAX_SIZE], tmp[MAX_SIZE]; generate_list(data, n) #pragma omp parallel { #pragma omp single mergesort(data, n, tmp); }}
Create a team of threads using the “default number” of threads
The single construct causes only one member of the team to call the first mergesort
31
Background for Merge Sort: The merge routine
Source: Mattson and Keutzer, UCB CS294
#include <string.h>#include <stdlib.h>void merge(int * X, int n, int * tmp) { int i = 0; int j = n/2; int ti = 0;
while (i<n/2) { /* finish up lower half */ tmp[ti] = X[i]; ti++; i++; } while (j<n) { /* finish up upper half */ tmp[ti] = X[j]; ti++; j++; } memcpy(X, tmp, n*sizeof(int));
} // end of merge()
• This is the merge function used by both the serial and parallel versions of the program
32
Background for merge sort: Generate_list
Source: Mattson and Keutzer, UCB CS294
• A function to generate a list of integers (included for completeness … this has nothing to do with sorting or parallelism)
void generate_list(int * x, int n) { int i; srand(10000); for (i = 0; i < n; i++) { int val = n * ((double) rand() / ((double) RAND_MAX + (double) 1)); x[i] = val; } }
• Recursion concepts• Recursion and the divide and conquer pattern• Case study: sorting• Case Study: Sudoku
34
Sudoko
• A game where you fill in a grid with numbers– A number cannot appear more than once in any column– A number cannot appear more than once in any row– A number can not appear more than once in any “region”
• Typically presented with a 9 by 9 grid … but for simplicity we’ll consider a 4 by 4 grid
Source: Mattson and Keutzer, UCB CS294
A 4 x 4 Sudoku puzzle with 11 open positions … we show three steps in the solution
1
23
Since 1 is the only number missing in this column
Since 3 already appears in this region
Since 3 is the only number missing in this row
35
Sudoko Algorithm
• The two-dimensional Sudoko grid is flattened into a vector– Unsolved locations are filled with zeros– The first two rows of the initial 4 x 4 puzzle are shown– The current working location [loc=0] is shown in red and the subgrid size is 3– Initially call spawn solve(size=3, grid, loc=0)
Source: Mattson and Keutzer, UCB CS294
3 0 0 4 0 0 0 2 …
• The first location has a solution so move to next location– Recursively call spawn solve(size=3, grid, loc=loc+1)
grid
3 0 0 4 0 0 0 2 …
36
Exhaustive Search
• The next location [loc=1] has no solution (‘0’ in the current cell) so …– Create 4 new grids and try each of the 4 possibilities (1,2,3,4) concurrently– Note: the search goes much faster if the guess is first tested to see if it is legal– Spawn a new search tree for each guess k– Call: spawn solve(size=3, grid[k], loc=loc+1)
Source: Mattson and Keutzer, UCB CS294
3 1 0 4 0 0 0 2 …
new grids
3 2 0 4 0 0 0 2 …
3 3 0 4 0 0 0 2 …
3 4 0 4 0 0 0 2 …
Illegal since 3 and 4 are already in the same row
37
Cilk Sudoko solution (part 1 of 3)
Source: Mattson and Keutzer, UCB CS294
cilk int solve(int size, int* grid, int loc){ int i, k, solved, solution[MAX_NUM]; int* grid[MAX_NUM]; int numNumbers = size*size: int Girdlen = numNumbers*numNumbers;
if (loc == Gridlen) { /* maximum depth; reached the end of the puzzle */ return check_solution(size, grid); }
/* if this node has a solution (given by puzzle) at this location */ /* move to next node location */ if (grid[loc] != 0) { solved = spawn solve(size, g, loc+1); return solved; }
38
Cilk Sudoko solution (part 2 of 3)
Source: Mattson and Keutzer, UCB CS294
/* try each number (unique to row,col,sq) */ numGrids = 0; for (i = 0, k = 0; i < MAX_NUM; i++) { k = next_guess(size, k, loc, grid); if (k == 0) break; /* no more legal solutions at t his location */
/* need new grid to work with */ myGrid[i] = new_grid(size, grid); myGrid[i][loc] = k; solution[i] = spawn solve(size, myGrid[i], loc+1); nGrids += 1; }
sync;
39
Cilk Sudoko solution (part 3 of 3)
Source: Mattson and Keutzer, UCB CS294
/* check to see if there is a solution */
solved = 0; for (i = 0; i < nGrids; i++) { if (solution[i] == 1) { int n; /* found a solution, copy result to parent */ for (n = loc; n < len; n++) { grid[n] = (myGrid[i])[n]; } solved = 1; } free(myGrid[i]); }