31
Hidden Morkov Models Dr Khurram Khurshid Pattern Recognition
| Date post: | 08-Aug-2015 |
| Category: |
Technology |
| Upload: | institute-of-space-technology-ist |
| View: | 80 times |
| Download: | 1 times |

Hidden Morkov Models
Dr Khurram Khurshid
Pattern Recognition

Markov Model
• A discrete (finite) system:– N distinct states.– Begins (at time t=1) in some initial state(s).– At each time step (t=1,2,…) the system moves
from current to next state (possibly the same as
the current state) according to transition
probabilities associated with current state.
• This kind of system is called a finite, or discrete Markov model

Markov Model
• Discrete Markov Model with 5 states.
• Each aij represents the probability of moving from state i to state j
• The aij are given in a matrix A = {aij}
• The probability to start in a given state i is i ,
The vector represents these
startprobabilities.

4
Markov Property• Markov Property: The state of the system at time t+1
depends only on the state of the system at time t
Xt=1Xt=2 Xt=3 Xt=4 Xt=5
] x X | x P[X
] x X , x X , . . . , x X , x X | x P[X
tt11t
00111-t1-ttt11t
t
t

5
Markov Chains
Stationarity Assumption
Probabilities independent of t when process is “stationary”
So,
This means that if system is in state i, the probability that
the system will next move to state j is pij , no matter what
the value of t is
t 1 j t i ijfor all t, P[X x |X x ] p

6
• raining today rain tomorrow prr = 0.4
• raining today no rain tomorrow prn = 0.6
• no raining today rain tomorrow pnr = 0.2
• no raining today no rain tomorrow prr = 0.8
Simple Minded Weather Example

7
Simple Minded Weather ExampleTransition matrix for our example
• Note that rows sum to 1
• Such a matrix is called a Stochastic Matrix
• If the rows of a matrix and the columns of a matrix all
sum to 1, we have a Doubly Stochastic Matrix
8.02.0
6.04.0P

8
Coke vs. Pepsi (a cental cultural dilemma)
Given that a person’s last cola purchase was Coke ™, there is a 90% chance that her next cola purchase will also be Coke ™.
If that person’s last cola purchase was Pepsi™, there is an 80% chance that her next cola purchase will also be Pepsi™.
coke pepsi
0.10.9 0.8
0.2

9
Coke vs. PepsiGiven that a person is currently a Pepsi purchaser, what is the probability that she will purchase Coke two purchases from now?
66.034.0
17.083.0
8.02.0
1.09.0
8.02.0
1.09.02P
8.02.0
1.09.0P
The transition matrices are: (corresponding to
one purchase ahead)

10
Coke vs. Pepsi
Given that a person is currently a Coke drinker, what is the probability that she will purchase Pepsi three purchases from now?
562.0438.0
219.0781.0
66.034.0
17.083.0
8.02.0
1.09.03P

11
Coke vs. PepsiAssume each person makes one cola purchase per week. Suppose 60% of all people now drink Coke, and 40% drink Pepsi.
What fraction of people will be drinking Coke three weeks from now?
6438.0438.04.0781.06.0)0( )3(101
)3(000
1
0
)3(03
pQpQpQXPi
ii
Let (Q0,Q1)=(0.6,0.4) be the initial probabilities.
We will regard Coke as 0 and Pepsi as 1
We want to find P(X3=0)
8.02.0
1.09.0P
P00

12
Discrete Markov Model - Example
• States – Rainy:1, Cloudy:2, Sunny:3
• Matrix A –
• Problem – given that the weather on day 1 (t=1) is sunny(3), what is the probability for the observation O:

13
Discrete Markov Model – Example (cont.)
• The answer is -

14
Hidden Markov Models (probabilistic finite state automata)
Often we face scenarios where states cannot be
directly observed.
We need an extension: Hidden Markov Models
a11 a22a33 a44
a12 a23a34
b11 b14
b12
b13
12 3
4
Observed
phenomenon
aij are state transition probabilities.
bik are observation (output) probabilities.
b11 + b12 + b13 + b14 = 1,
b21 + b22 + b23 + b24 = 1, etc.

15
Hidden Markov Models - HMM
H1 H2 HL-1 HL
X1 X2 XL-1 XL
Hi
Xi
Hidden variables
Observed data

Hidden Markov Models

Consider this case …
• Consider two friends, Alice and Bob, who live far apart from each other and who talk together daily over the telephone about what they did that day.
• Bob is only interested in three activities: walking in the park, shopping, and cleaning his apartment. – The choice of what to do is determined exclusively by the
weather on a given day.
• Alice has no definite information about the weather where Bob lives, but she knows general trends. Based on what Bob tells her he did each day, Alice tries to guess what the weather must have been like.

Consider this case …
• Alice believes that the weather operates as a discrete Markov chain. There are two states, "Rainy" and "Sunny", but she cannot observe them directly, that is, they are hidden from her. On each day, there is a certain chance that Bob will perform one of the following activities, depending on the weather: "walk", "shop", or "clean". Since Bob tells Alice about his activities, those are the observations.
The entire system is that of a hidden Markov model.

Consider this case …
• Alice knows the general weather trends in the area, and what Bob likes to do on average.
In other words, the parameters of the HMM are known.

states = ('Rainy', 'Sunny')
observations = ('walk', 'shop', 'clean')
start_probability = {'Rainy': 0.6, 'Sunny': 0.4}
transition_probability = {
'Rainy' : {'Rainy': 0.7, 'Sunny': 0.3},
'Sunny' : {'Rainy': 0.4, 'Sunny': 0.6}, }
emission_probability = {
'Rainy' : {'walk': 0.1, 'shop': 0.4, 'clean': 0.5},
'Sunny' : {'walk': 0.6, 'shop': 0.3, 'clean': 0.1}, }
Consider this case …

In this piece of code, start_probability represents Alice's belief about which state the HMM is in when Bob first calls her (all she knows is that it tends to be rainy on average). The particular probability distribution used here is not the equilibrium one, which is (given the transition probabilities) approximately {'Rainy': 0.57, 'Sunny': 0.43}.
The transition_probability represents the change of the weather in the underlying Markov chain. In this example, there is only a 30% chance that tomorrow will be sunny if today is rainy.
The emission_probability represents how likely Bob is to perform a certain activity on each day. If it is rainy, there is a 50% chance that he is cleaning his apartment; if it is sunny, there is a 60% chance that he is outside for a walk.
Consider this case …

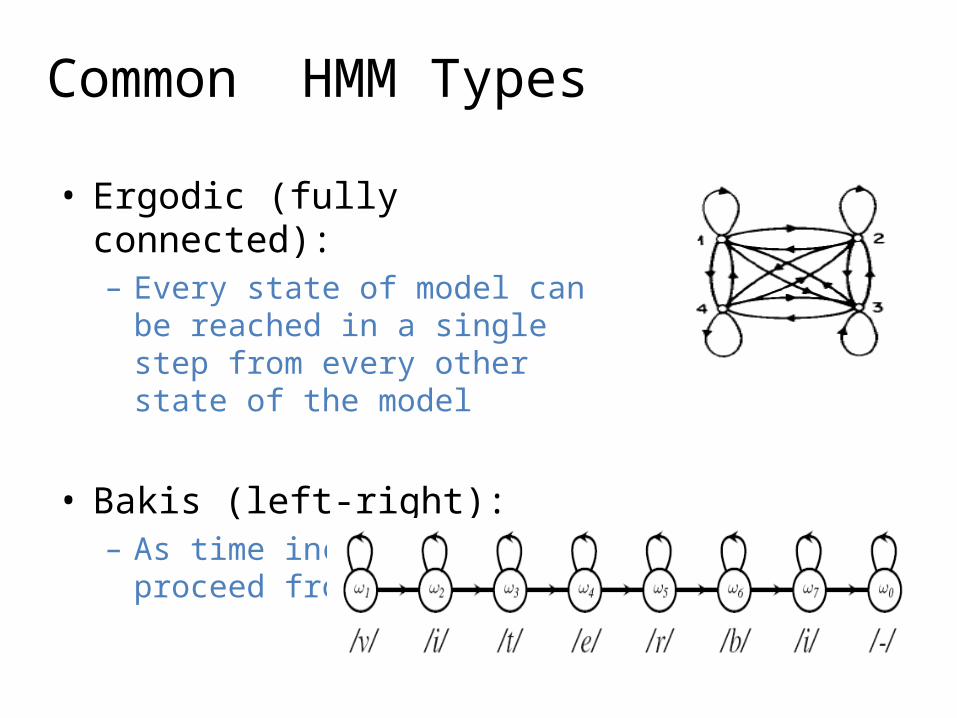
Common HMM Types
• Ergodic (fully connected):– Every state of model can be
reached in a single step from every other state of the model
• Bakis (left-right):– As time increases, states proceed
from left to right

Evaluation problem. Given the HMM M=(A, B, ) and the observation
sequence O=o1 o2 ... oK , calculate the probability that model M has
generated sequence O .
Decoding problem. Given the HMM M=(A, B, ) and the observation
sequence O=o1 o2 ... oK , calculate the most likely sequence of hidden states
si that produced this observation sequence O.
Learning problem. Given some training observation sequences O=o1 o2 ... oK and general structure of HMM (numbers of hidden and visible states), determine
HMM parameters M=(A, B, ) that best fit training data.
O=o1...oK denotes a sequence of observations
Main issues

• Typed word recognition, assume all characters are separated.
• Character recognizer outputs probability of the image being particular character, P(image|character).
0.5
0.03
0.005
0.31z
c
b
a
Word recognition example(1).
Hidden state Observation

• Hidden states of HMM = characters.
• Observations = typed images of characters segmented from the image.
• Observation probabilities = character recognizer scores.
Word recognition example(2).

• If lexicon is given, we can construct separate HMM models for each lexicon word.
Amherst a m h e r s t
Buffalo b u f f a l o
0.5 0.03
• Here recognition of word image is equivalent to the problem of evaluating few HMM models.•This is an application of Evaluation problem.
Word recognition example(3).
0.4 0.6

• We can construct a single HMM for all words.• Hidden states = all characters in the alphabet.• Transition probabilities and initial probabilities are calculated from language model.• Observations and observation probabilities are as before.
a m
h e
r
s
t
b v
f
o
• Here we have to determine the best sequence of hidden states, the one that most likely produced word image.• This is an application of Decoding problem.
Word recognition example(4).

• The structure of hidden states is chosen.
• Observations are feature vectors extracted from vertical slices.
• Probabilistic mapping from hidden state to feature vectors: 1. use mixture of Gaussian models2. Quantize feature vector space.
Character recognition with HMM example.

• The structure of hidden states:
• Observation = number of islands in the vertical slice.
s1 s2 s3
•HMM for character ‘A’ : Transition probabilities: {aij}=
Observation probabilities: {bjk}=
.8 .2 0 0 .8 .2 0 0 1
.9 .1 0 .1 .8 .1 .9 .1 0
•HMM for character ‘B’ : Transition probabilities: {aij}=
Observation probabilities: {bjk}=
.8 .2 0 0 .8 .2 0 0 1
.9 .1 0 0 .2 .8 .6 .4 0
Exercise: character recognition with HMM

• Suppose that after character image segmentation the following sequence of island numbers in 4 slices was observed: { 1, 3, 2, 1}
• What HMM is more likely to generate this observation sequence , HMM for ‘A’ or HMM for ‘B’ ?
Assignment
Exercise: character recognition with HMM

















