26
1 © 2008 Supervised.ppt / yyyy-mm-dd / tkj AS 84.4340 Automation Technology Postgraduate Course Supervised learning in robotics Turo Keski-Jaskari 18.4.2008
| Date post: | 28-Dec-2015 |
| Category: |
Documents |
| Upload: | michael-ryan |
| View: | 213 times |
| Download: | 0 times |

1 © 2008 Supervised.ppt / yyyy-mm-dd / tkj
AS 84.4340 Automation Technology Postgraduate Course
Supervised learning in roboticsTuro Keski-Jaskari
18.4.2008

2 © 2008 Supervised.ppt / yyyy-mm-dd / tkj
Contents
•Introduction
•Learning methods
•Classifiers
•Decision trees
•Support Vector Machines
•Neural nets
•Backpropagation
•Exercise

3 © 2008 Supervised.ppt / yyyy-mm-dd / tkj
Machine vs. Robot Learning
Machine Learning• Learning in “vacuum”
• Statistically well-behaved data
• Mostly off-line
• Informative feedback
• Computational time not an issue
• Hardware does not matter
• Convergence proof
• Generalized statements, but there’s some truth behind them
http://www.nada.kth.se/kurser/kth/2D1431/02/index.html, lecture 12
Robot Learning• Embedded learning
• Data distribution not homogeneous
• Mostly on-line
• Qualitative and sparse feed-back
• Time is crucial
• Hardware is a priority
• Empirical proof

4 © 2008 Supervised.ppt / yyyy-mm-dd / tkj
Supervised learning
•In supervised learning the “teacher signal” and corresponding output signals are known
• vs. unsupervised learning, where only input is known• Signal can be made for teaching• Or recorded from successful runs• Or it could be from robot’s own complementary sensors
•Depending on the method, the learning system will build an internal model based on the training input-output pairs, that then produces reasonable results for unseen inputs too
•Usually used for minimization of error signals for problems that have static input-output mappings
•Training can be used for example to learn the signal weights of a neural network. Like teaching a child, only easier..

5 © 2008 Supervised.ppt / yyyy-mm-dd / tkj
In robotics
•“Naturalness” makes it a good approach for interacting with robots
• Natural teaching in human world is in essence supervised too
•Supervised learning can also be utilized for navigation, localization, action control, or basically any task where a “correct” signal can be shown to the robot
6 © 2008 Supervised.ppt / yyyy-mm-dd / tkj
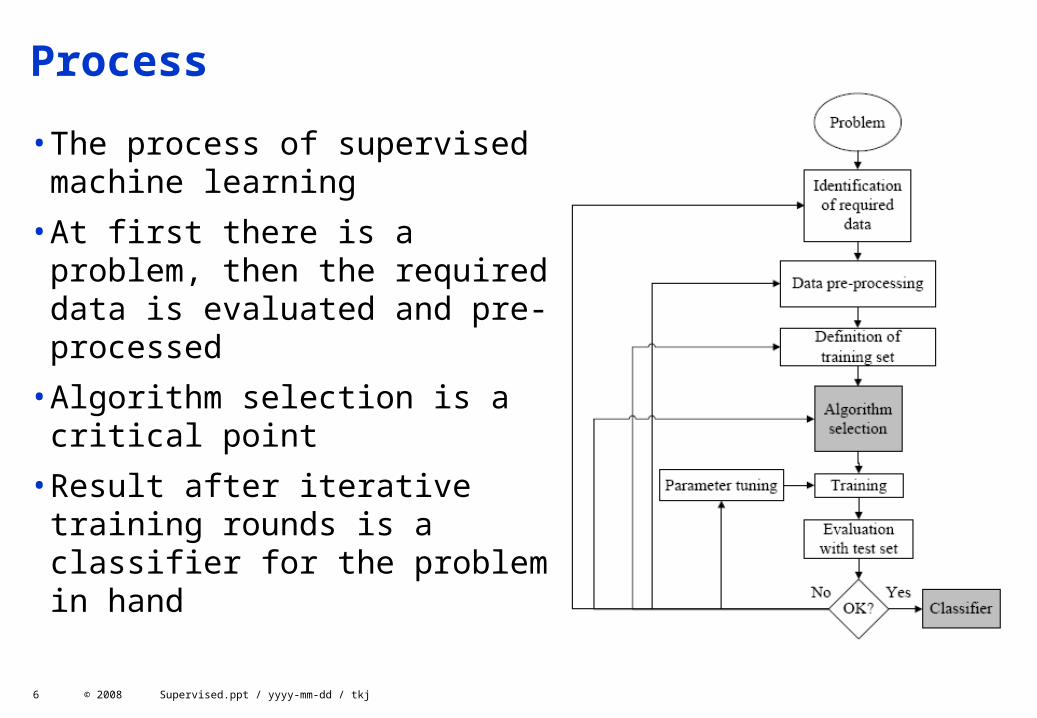
Process
•The process of supervised machine learning
•At first there is a problem, then the required data is evaluated and pre-processed
•Algorithm selection is a critical point
•Result after iterative training rounds is a classifier for the problem in hand

7 © 2008 Supervised.ppt / yyyy-mm-dd / tkj
“Approaches and algorithms”From Wikipedia: Supervised learning• Analytical learning • Artificial neural network • Backpropagation • Boosting • Bayesian statistics • Case-based reasoning • Decision tree learning • Inductive logic programming • Gaussian process regression • Learning Automata • Minimum message length (decision trees, decision graphs, etc.) • Naive bayes classifier • Nearest Neighbor Algorithm • Probably approximately correct learning (PAC) learning • Ripple down rules, a knowledge acquisition methodology • Symbolic machine learning algorithms • Subsymbolic machine learning algorithms • Support vector machines • Random Forests • Ensembles of Classifiers • Ordinal Classification • Data Pre-processing • Handling imbalanced datasets

8 © 2008 Supervised.ppt / yyyy-mm-dd / tkj
Supervised learning methods
•Classifiers•Decision trees•Support Vector Machines•Neural approaches fit well into this scope
• They can track errors over the learning steps, and adjust network weights accordingly, thus learning even complex shapes (and the brain learns too)
•Reinforcement learning is close but not quite• Handling of successful runs can be the same• Difference is in handling of errors• Basically in RL the learner knows it did wrong, but in supervised
learning it also gets to know where the goal was• RL suits for problems with sequential dynamics, and optimizing a
scalar objective• ”Further relatives”: Hebbian learning, Q-learning

9 © 2008 Supervised.ppt / yyyy-mm-dd / tkj
Basic classifier
•Reached hypothesis:
•Most specific & most general hypotheses

10 © 2008 Supervised.ppt / yyyy-mm-dd / tkj
Decision trees
•Trees that classify instances by sorting them based on feature values
•“Leafs” are features, nodes are decisions, branches are values
•Root should be the one that best divides the groupUnivariatetree

11 © 2008 Supervised.ppt / yyyy-mm-dd / tkj
Multivariate trees
•Univariate trees use only one input dimension to split.
•Multivariate tree is more general, offering all input dimensions to be used in the decision node
•Nonlinear versions even more effective
Cutting hyperplane
12 © 2008 Supervised.ppt / yyyy-mm-dd / tkj
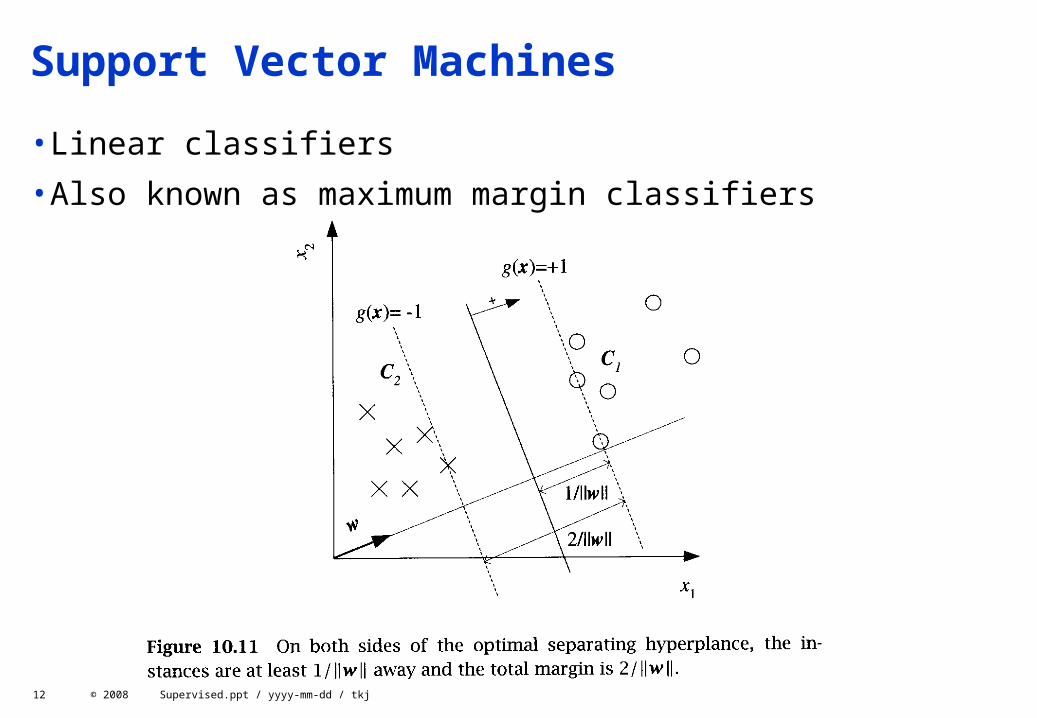
Support Vector Machines
•Linear classifiers
•Also known as maximum margin classifiers

13 © 2008 Supervised.ppt / yyyy-mm-dd / tkj
Supervised actor-critic reinforcement learning•Combining supervised learning with actor-critic RL
•Supervisor adds structure to a learning problem• Like a parent’s comment for a child learning to bounce a ball
•Supervised learning makes that structure part of an actor critic framework for reinforcement learning
Rosenstein & al.
“Value function”
“Control policy”
14 © 2008 Supervised.ppt / yyyy-mm-dd / tkj
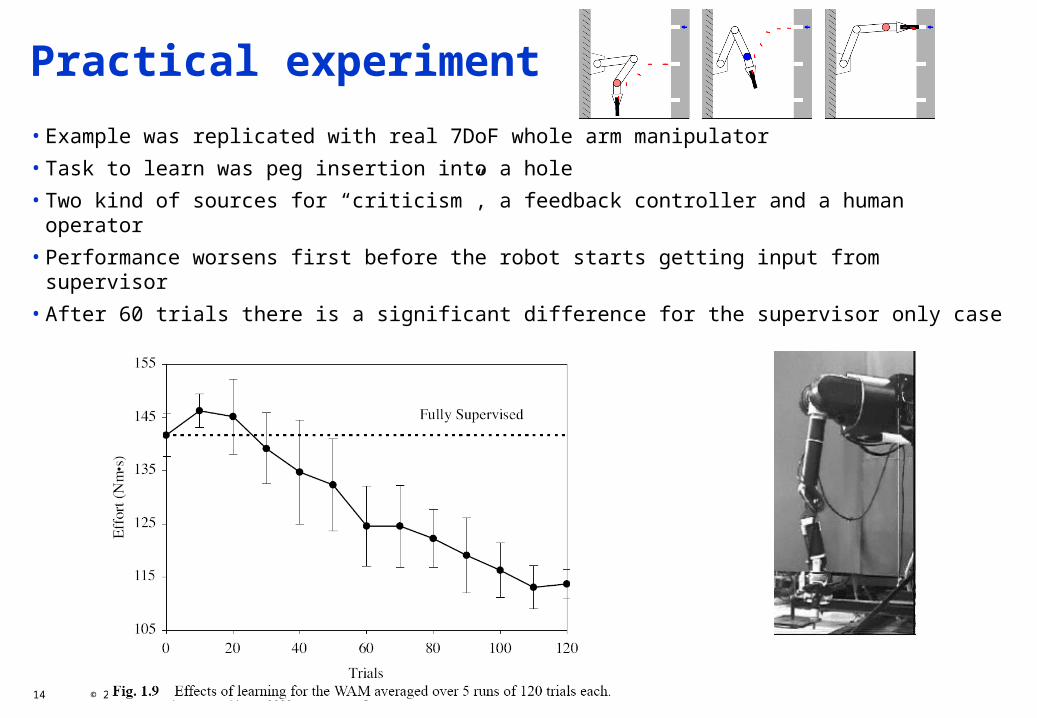
Practical experiment
• Example was replicated with real 7DoF whole arm manipulator
• Task to learn was peg insertion into a hole
• Two kind of sources for “criticism”, a feedback controller and a human operator
• Performance worsens first before the robot starts getting input from supervisor
• After 60 trials there is a significant difference for the supervisor only case

15 © 2008 Supervised.ppt / yyyy-mm-dd / tkj
Neuron
•Even a single neuron is a hugely complicated machine
•In average 7000 links to other cells in human brain..
•Try to model this!
•Considering these..
302 neurons(fully mapped) ~300000 neurons
~60 billion neurons
Caenorhabditis elegans HumanFruit fly
16 © 2008 Supervised.ppt / yyyy-mm-dd / tkj
Neuron
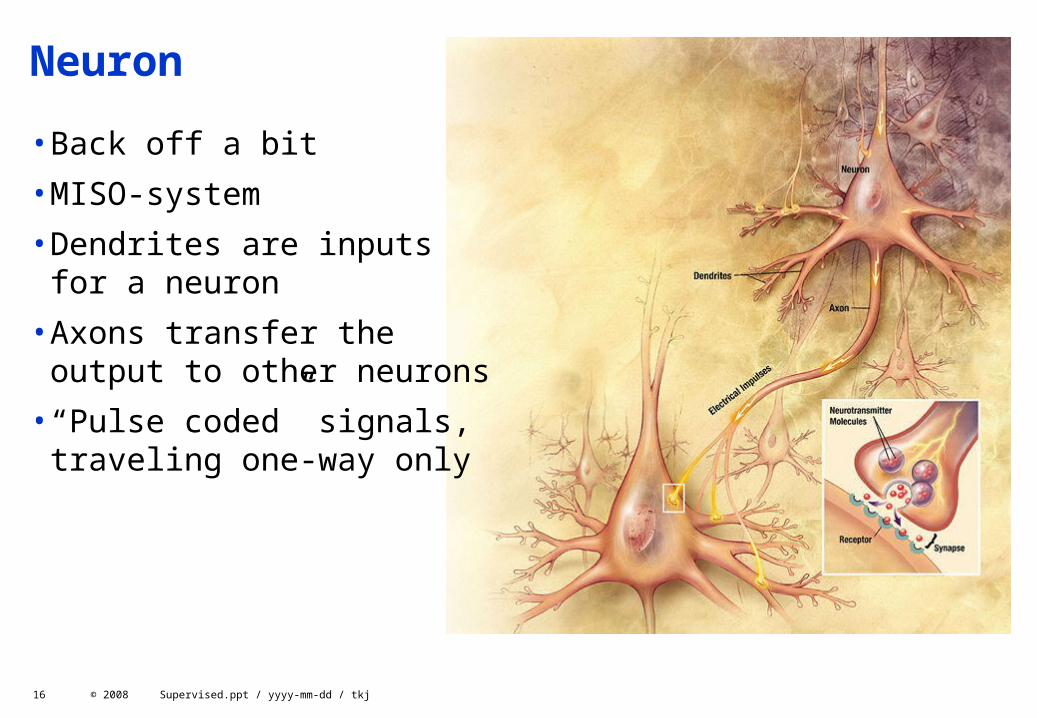
•Back off a bit
•MISO-system
•Dendrites are inputs for a neuron
•Axons transfer the output to other neurons
•“Pulse coded” signals, traveling one-way only

17 © 2008 Supervised.ppt / yyyy-mm-dd / tkj
Perceptron
• A simplified stochastic model of a neuron• Invented 1957 at Cornell Aeronautical
Laboratory by Frank Rosenblatt
• Simplest kind of feedforward neural network
• m input signals (dendrites), weighted by weights wk0 to wkm, and bk is the bias
• The perceptron (“neuron”) sums up the weighted signals, and outputs a pulse if the threshold function was fulfilled
• Ф can be a function or simply a threshold
• Output is selected by a threshold (usually constant, but can be a function too)
m
jkjkjk bxwy
1

18 © 2008 Supervised.ppt / yyyy-mm-dd / tkj
Perceptron network
•All the inputs connect to every output
•Weights are adjustable -> learning
•Essentially perceptron also defines a hyperplane for data classification, adding perceptrons and soon also layers increase the representation capabilities

19 © 2008 Supervised.ppt / yyyy-mm-dd / tkj
Multilayer perceptrons
•One layer can only learn linear behaviors
•Multiple layers allow for nonlinear regression
•Usually output neurons have linear output, and hidden ones either log-sigmoid or tan-sigmoid (normally preferable) activation functions
Log sigmoid function[0 .. 1]
Symmetric tanh[-1 .. 1]

20 © 2008 Supervised.ppt / yyyy-mm-dd / tkj
Multilayer perceptrons
•In larger networks every neuron in a layer is linked to every neuron in the next layer, unidirectional in feed-forward nets
•In learning phase all the weights of these “synapses” are adjusted gradually by iteration

21 © 2008 Supervised.ppt / yyyy-mm-dd / tkj
Layers and neurons
•Number of output layer neurons is normally the same as the amount of desired output variables
•Amount of neurons in hidden layers is in practice usually selected by trial and error, though experienced user can estimate something from the input data variations too
•If the MLP network has only one hidden layer, its neurons seem to “interact” with each other (improving one causes degrading in another)
•For this reason, MLP networks are commonly designed with two hidden layers
• The first hidden layer is responsible for extracting local features• Second one extracts global features• -> Leads to multi-level feature extraction like in the human visual
cortex

22 © 2008 Supervised.ppt / yyyy-mm-dd / tkj
Training the net
• Usually multi-layer perceptron networks learn (=estimate the weights) by back-propagation technique1. Present a training sample to the net
2. Compare output with the desired output, calculate error
3. Calculate local errors, i.e. error for each neuron
4. Adjust the weights of inputs of each neuron to lower the local error
5. Assign “blame” for the local error to neurons at the previous level (back-propagation step)
6. Repeat the steps above on the neurons at the previous level, using each one’s “blame” as its error
• Using the training samples once (one cycle through all layers) is called an epoch in learning. Full learning cycle could utilize f.ex. 200 epochs. Normally an error goal criteria is also set.
Maths in Alpaydin, Chapter 11.7

23 © 2008 Supervised.ppt / yyyy-mm-dd / tkj
Training the net
•Online learning is more interesting in robotics than offline• It saves memory• Problem may be changing over time• There may be physical changes in the system
•Gradient descent, minimize quadratic error
•And for multi-layer with back-propagation as before (non-linearity added)

24 © 2008 Supervised.ppt / yyyy-mm-dd / tkj
Conclusions
•Multilayer perceptrons are a powerful tool to learn even nonlinear behaviors
•Supervised learning is a natural way for teaching robots
•Combining supervised learning with other types (like RL) may be a good idea, and also increases naturality
• Human supervisor corrects the little mistakes, preventing the robot to “bang its head to the wall” for too long..

25 © 2008 Supervised.ppt / yyyy-mm-dd / tkj
References
•Ethem Alpaydin, “Introduction to machine learning”, The MIT Press (Mainly chapters 2 & 9-11)
•S. Kotsiantis, Supervised Machine Learning: A Review of Classification Techniques, Informatica Journal 31 (2007) 249-268
•Michael T. Rosenstein and Andrew G. Barto, Supervised Actor Critic Reinforcement Learning, Department of Computer Science, University of Massachusetts, Amherst
• A chapter in J. Si, A. Barto, W. Powell, and D. Wunsch, eds., Learning and Approximate Dynamic Programming: Scaling Up to the Real World. John Wiley & Sons, Inc., New York, 2004.
•+Misc links, like wikipedia..

26 © 2008 Supervised.ppt / yyyy-mm-dd / tkj
Exercise
• Build and train a multilayer feedforward backpropagation neural network to estimate optimal controls for a flying robot!
• Data (matrices P and T) is in “superdata.mat”
• Input data (P) is recorded from four successful runs through a certain zig-zag route (Red Bull Air Race etc) using a simulator. First four rows of P are the rudder angles, next four rows of P are the elevator angles of the same run. The first row of T shows the rudder angles from a real run with the flying robot, and the second row shows the corresponding elevator angles.
• Find a neural network model for the system by using feed-forward neural network (Matlab ’doc newff’, Neural Network Toolbox). Choose a suitable number of neurons and their layers, suitable transfer functions for neurons and train and simulate the net. Plot the results. Comment on how well you can estimate the rudder movements and how well the elevator.
• (Don’t worry, the results will not be utilized in a commercial airliner )
0 200 400 600 800 1000 1200 1400 1600 1800 2000-10
-5
0
5
10
15
0 200 400 600 800 1000 1200 1400 1600 1800 2000-8
-6
-4
-2
0
2
4
6
8
10

















