55
1 Analysis of Simulation Experiments
| Date post: | 19-Dec-2015 |
| Category: |
Documents |
| View: | 217 times |
| Download: | 0 times |

1
Analysis of Simulation Experiments

2
Introduction Classification of Outputs DIDO vs. RIRO Simulation Analysis of One System Terminating vs. Steady-State Simulations Analysis of Terminating Simulations Obtaining a Specified Precision Analysis of Steady-State Simulations Method of Moving Average for Removing
the Initial Bias Method of Batch Means Multiple Measures of Performance Analysis of Several Systems Comparison of Two Alternative Systems Comparison of More than Two Systems Ranking and Selection
Outline

3
Introduction
The greatest disadvantage of simulation: Don’t get exact answers Results are only estimates
Careful design and analysis is needed to: Make these estimates as valid and
precise as possible Interpret their meanings properly
Statistical methods are used to analyze the results of simulation experiments.

4
What Outputs to Watch?
Need to think ahead about what you would want to get out of the simulation: Average, and worst (longest) time in
system
Average, and worst time in queue(s)
Average hourly production
Standard deviation of hourly production
Proportion of time a machine is up, idle, or down
Maximum queue length
Average number of parts in system

5
Classification of Outputs
There are typically two types of dynamic processes:
Discrete-time process: There is a natural “first” observation, “second” observation, etc.—but can only observe them when they “happen”.
If Wi = time in system for the ith part produced (for i = 1, 2, ..., N), and there are N parts produced during the simulation
i1 2 3 N ..................................
Wi

6
Classification of Outputs
Typical discrete-time output performance measures:
Average time in system
Maximum time in system
Proportion of parts that were in the system for more than 1 hour
Delay of ith customer in queue
Throughput during ith hour
W N
W
N
ii
N
( )
1

7
Classification of Outputs
Continuous-time process: Can jump into system at any point in time (real, continuous time) and take a “snapshot” of something-there is no natural first or second observation.
If Q(t) = number of parts in a particular queue at time t between [0,T] and we run simulation for T units of simulated time
Q(t)
0
1
2
3
t T

8
Classification of Outputs
Typical continuous-time output performance measures:
Time-average length of queue
Server Utilization (proportion of time the server is busy)
Q T
Q t dt
T
T
( )
( )
0
T0
1
t
B(t)
( )
( )
T
B T dt
T
T
0

9
Classification of Outputs
Other continuous-time performance measures:
Number of parts in the system at time t
Number of machines down at time t
Proportion of time that there were more
than n parts in the queue

10
DIDO Vs. RIRO Simulation
Simulation Model
Inputs:Cycletimes
Interarrivaltimes
Batchsizes
Outputs:Hourly
productionMachine
utilization
DIDO

11
Simulation Model
Inputs:Cycletimes
Interarrivaltimes
Batchsizes
Outputs:Hourly
productionMachine
utilization
RIRO
DIDO Vs. RIRO Simulation
12
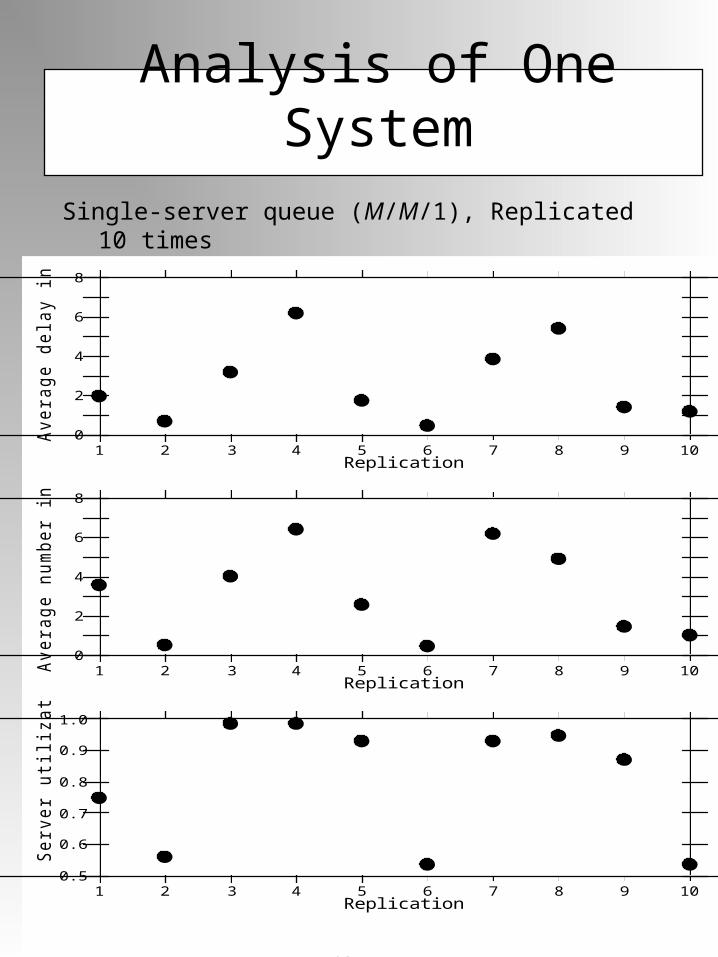
Analysis of One SystemSingle-server queue (M/M/1), Replicated 10
times
0.5
0.6
0.7
0.8
0.9
Se
rve
r u
tiliza
tio
n
1.0
1 2 3 4 5 6Replication
7 8 9 10
0
2
4
6
8
Ave
rag
e n
um
be
r in
qu
eu
e
1 2 3 4 5 6 7Replication
8 9 10
0
2
4
6
8
Ave
rag
e d
ela
y in
qu
eu
e
1 2 3 4 5 6 7Replication
8 9 10

13
Analysis of One System
CAUTION: Because of autocorrelation that exists in the output of virtually all simulation models, “classical” statistical methods don’t work directly within a simulation run.
Time in system for individual jobs: Y1, Y2, Y3, ..., Yn
= E(average time in system)
Sample mean:
is an unbiased estimator for , but how close is
this sample mean to ?
Need to estimate Var( ) to get confidence intervals on
Y nY
n
ii
n
( )
1
Y n( )

14
Analysis of One System
Problem: Because of positive
autocorrelation between Yi and Yi+1 (Correl
(Yi, Yi+l) > 0), sample variance is no longer an
unbiased estimator of the population variance (i.e., unbiasedness of variance estimators can only be achieved if Y1, Y2,
Y3, ..., Yn are independent).
As a result, the sample variance
may be severely biased for Var[ ].
In fact, usually E[ ] < Var[ ]
Implications: Understating variances causes us to have too much faith in our point estimates and believe the results too much.
S n
n
Y Y n
n n
ii
n
22
1
1
( )[ ( )]
( )
Y n( )
S n
n
2 ( ) Y n( )

15
Types of Simulations with Regard to Output Analysis
Terminating: A simulation where there is a specific starting and stopping condition that is part of the model.
Steady-state: A simulation where there is no specific starting and ending conditions. Here, we are interested in the steady-state behavior of the system.
“The type of analysis depends on the goal of the
study.”

16
Examples of Terminating Simulations
A retail/commercial establishment (a bank) that operates from 9 to 5 daily and starts empty and idle at the beginning of each day. The output of interest may be the average wait time of first 50 customers in the system.
A military confrontation between a blue force and a red force. The output of interest may be the probability that the red force loses half of its strength before the blue force loses half of its strength.

17
Examples of Steady-State Simulations
A manufacturing company that operates 16 hours a day. The system here is a continuous process where the ending condition for one day is the initial condition for the next day. The output of interest here may be the expected long-run daily production.
A communication system where service must be provided continuously.

18
Analysis for Terminating Simulations
Objective: Obtain a point estimate and confidence interval for some parameter
Examples:= E (average time in system for n customers)
= E (machine utilization)
= E (work-in-process)
Reminder: Can not use classical statistical methods within a simulation run because observations from one run are not independently and identically distributed (i.i.d.)

19
Analysis for Terminating Simulations
Make n independent replications of the model
Let Yi be the performance measure from the ith replication
Yi = average time in system, or
Yi = work-in-process, or
Yi = utilization of a critical facility
Performance measures from different replications, Y1, Y2, ..., Yn, are i.i.d.
But, only one sample is obtained from each replication
Apply classical statistics to Yi’s, not to observations within a run
Select confidence level 1 – (0.90, 0.95, etc.)

20
Analysis for Terminating Simulations
Approximate 100(1 – a)% confidence interval for :
unbiased estimator of
unbiased estimator of Var(Yi)
covers with approximate
probability (1 – a)
is the Half-Width expression
Y nY
n
ii
n
( )
1
S nY Y n
n
ii
n
2
2
1
1( )
[ ( )]
Y n tS n
nn( )( )
, 1 1 2
( , )( )
,n tS n
nn 1 1 2

21
Consider a single-server (M/M/1) queue. The objective is to calculate a confidence interval for the delay of customers in the queue.
n = 10 replications of a single-server queueYi = average delay in queue from ith replication
Yi’s: 2.02, 0.73, 3.20, 6.23, 1.76, 0.47, 3.89, 5.45, 1.44, 1.23
For 90% confidence interval, = 0.10
= 2.64, = 3.96, t9, 0.95 = 1.833
Approximate 90% confidence interval is
2.64 ± 1.15, or [1.49, 3.79]
Example
Y( )10 S 2 10( )

22
Analysis for Terminating Simulations
Interpretation: 100(1 – a)% of the time, the confidence interval formed in this way covers
Wrong Interpretation: “I am 90%
confident that is between 1.49 and 3.79”
(unknown)

23
Issue 1
This confidence-interval method assumes Yi’s are normally distributed. In real life, this is almost never true.
Because of central-limit theorem, as the number of replications (n) grows, the coverage probability approaches 1 – a.
In general, if Yi’s are averages of something, their distribution tends not to be too asymmetric, and the confidence- interval method shown above has reasonably good coverage.

24
The confidence interval may be too wide
In the M/M/1 queue example, the approximate 90% C.I. was:2.64 ± 1.15, or [1.49, 3.79]
The half-width is 1.15 which is 44% of the mean (1.15/2.64)
That means that the C.I. is 2.64 44% which is not very precise.
To decrease the half-width:Increase n until is small enough (this is called Sequential Sampling)
There are two ways of defining the precision in the estimate Y:
Absolute precision Relative precision
Issue 2
( , )n

25
Obtaining a Specified Precision
Absolute Precision:
Want to make n large enough such that , where is the
half-width and > 0 .
Make n0 replications of the simulation model and compute , , and the half-width, .
Assuming that the estimate of the variance, , does not change appreciably, an approximate expression for the required number of replications to achieve an absolute error of is
S n2 ( )
n i n tS n
ia i*
,( ) min :( )
1 1 2
2
( , )n ( , )n
Y n( ) S n2 ( ) ( , )n

26
Obtaining a Specified Precision
Relative Precision:
Want to make n large enough such that where .
Make n0 replications of the simulation model and compute , , and the half-width, .
Assuming that the estimates of both population mean, , and population variance, , do not change appreciably, an approximate expression for the required number of replications to achieve an absolute error of is
( , ) ( )n Y n 0 1
Y n( ) S n2 ( ) ( , )n
S n2 ( )Y n( )
n i nt
S (n)i
Y nr
i , a*( ) min :
( )
1 1 2
2

27
Analysis for Steady-State Simulations
Objective: Estimate the steady state mean
Basic question: Should you do many short runs or one long run ?????
lim ( )i iE Y
Many short runs
One long run
X1
X2
X3
X4
X5
X1

28
Analysis for Steady-State Simulations
Advantages: Many short runs:
Simple analysis, similar to the analysis for terminating systems
The data from different replications are i.i.d.
One long run: Less initial bias No restarts
Disadvantages Many short runs:
Initial bias is introduced several times One long run:
Sample of size 1 Difficult to get a good estimate of the
variance

29
Analysis for Steady-State Simulations
Make many short runs: The analysis is exactly the same as for terminating systems. The (1 – a)% C.I. is computed as before.
Problem: Because of initial bias, may no longer be an unbiased estimator for the steady state mean, .
Solution: Remove the initial portion of the data (warm-up period) beyond which observations are in steady-state. Specifically pick l (warm-up period) and n (number of observations in one run) such that
Y n( )
EY
n l
ii l
n
1

30
Method of Moving Average for Removing the Initial Bias
Welch’s method for removing the warm-up period, l:
Make n replications of the model (n>5), each of length m, where m is large. Let
be the ith observation from the jth replication ( j = 1, 2, …, n; i =1, 2, …, m).
Let for i =1, 2, …, m.
To smooth out the high frequency oscillations in define the moving average as follows (w is the window and is a positive integer such that ):
Yji
Y Y ni jij
n
1
Y Y Ym1 2, , ..., Y wi ( )
Y wi ( )
Y
wi w m w
i ss w
w
2 11 if , ...,
Y
ii m
i ss i
i
( ), ...,
1
1
2 11 if
w m / 2

31
Plot and choose l to be the value of i beyond which seem to have converged.
Note: Perform this procedure for several values of w and choose the smallest w for which the plot of looks reasonably smooth.
Method of Moving Average for Removing the Initial Bias
Y wi ( )Y w Y w1 2( ), ( ), ...
Y wi ( )

32
Analysis for Steady-State Simulations
Make one Long run: Make just one long replication so that the initial bias is only introduced once. This way, you will not be “throwing out” a lot of data.
Problem: How do you estimate the variance because there is only one run?
Solution: Several methods to estimate the variance: Batch means (only approach to be
discussed) Time-series models Spectral analysis Standardized time series

33
Method of Batch Means
Divide a run of length m into n adjacent “batches” of length k where m = nk.
Let be the sample or (batch) mean of the jth batch.
The grand sample mean is computed as
Y j
i
Yi
k k k k k
Y 1 Y 2 Y 3 Y 4 Y 5 m nk
Y
Y
Y
n
Y
m
jj
n
ii
m
1 1

34
Method of Batch Means
The sample variance is computed as
The approximate 100(1 – a )% confidence interval for is
S n
Y Y
nY
jj
n
2
2
1
1( )
( )
Y tS n
nnY 1 1 2,
( )

35
Method of Batch Means
Two important issues:
Issue 1: How do we choose the batch size k? Choose the batch size k large enough
so that the batch means, are approximately uncorrelated. Otherwise, the variance, , will be biased low and the confidence interval will be too small which means that it will cover the mean with a probability lower than the desired probability of (1 – a ).
Y j ' s
S nY2 ( )

36
Method of Batch Means
Issue 2: How many batches n? Due to autocorrelation, splitting the
run into a larger number of smaller batches, degrades the quality of each individual batch. Therefore, 20 to 30 batches are sufficient.

37
Multiple Measures of Performance
In most real-world simulation models, several measures of performance are considered simultaneously.
Examples include: Throughput Average length of queue Utilization Average time in system
Each performance measure is perhaps estimated with a confidence interval.
Any of the intervals could “miss” its expected performance measure.
Must be careful about overall statements of coverage (i.e., that all intervals contain their expected performance measures simultaneously).

38
Multiple Measures of Performance
Suppose we have k performance measures and the confidence interval for performance measure s for s = 1, 2, ..., k, is at confidence level .
Then the probability that all k confidence intervals simultaneously contain their respective true measures is
This is referred to as the Bonferroni inequality.
P
All s intervals contain theirrespective performance measure
1 s
s1
k
1 s

39
Multiple Measure of Performance
To ensure that the overall probability (of all k confidence intervals simultaneously containing their respective true mean) is at least 100( ) percent, choose ’s such that
Can select for all s, or pick ’s
differently with smaller ’s for the more important performance measures.
s
s1
k
1
s k

40
Multiple Measures of Performance
Example: If k =2 and we want the desired overall confidence level to be at least 90%, we can construct two 95% confidence intervals.
Difficulty: If there are a large number of performance measures, and we want a reasonable overall confidence level (e.g., 90% ), the individual ’s could become small, making the corresponding confidence intervals very wide. Therefore, it is recommended that the number of performance measures do not exceed 10.
s

41
Analysis of Several Systems
Most simulation projects involve comparison of two or more systems or configurations:
Change the number of machines in some workcenters
Evaluate various job-dispatch policies (FIFO, SPT, etc.)
With two alternative systems, the goal may be to:
test the hypotheses: , or
build confidence interval for With k > 2 alternatives, the objective may be
to: build simultaneous confidence intervals for
various combinations of select the “best” of the k alternatives select a subset of size m < k that contains the
“best” alternative select the m “best” (unranked) of the
alternatives
H0 1 2: H0 1 2: 1 2
i i1 2

42
Analysis of Several Systems
To illustrate the danger in making only one run and eyeballing the results when comparing alternatives, consider the following example:
Compare:
Alternative 1: M/M/1 queue with interarrival time of 1 min., and one “fast” machine with service time of 0.9 min., and Alternative 2: M/M/2 queue with interarrival time of 1 min., and two “slow” machines with service time of 1.8 min. for each machine.
vs.

43
Analysis of Several Systems
If the performance measure of interest is the expected average delay in queue of the first 100 customers with empty-and-idle initial conditions, using queuing analysis, the true steady-state average delays in the queues are:
Therefore, system 2 is “better”
If we run each model just once and calculate the average delay, , from each alternative, and select the system with the smallest , then
Prob(selecting system 1 (wrong answer)) = 0.52
Reason: Randomness in the output
1 24 13 3 70 . .
Yi
Yi

44
Analysis of Several Systems
Solution: Replicate each alternative n times Let = average delay from jth
replication of alternative i Compute the average of all replications
for alternative i
Select the alternative with the lowest .
If we conduct this experiment many times, the following results are obtained:
n P(wrong Answer)
15
1020
0.520.430.380.34
Yij
Y
Y
ni
ijj
n
1
Y i

45
Comparison of Two Alternative Systems
Form a confidence interval for the difference between the performance measures of the two systems ( i.e., ).
If the interval misses 0, there is a statistical difference between the two systems.
Confidence intervals are better than hypothesis tests because if a difference exists, the confidence interval measures its magnitude, while a hypothesis test does not.
There are two slightly different ways for constructing the confidence intervals:
Paired-t Two-Sample-t.
1 2

46
Paired-t Confidence Interval
Make n replications of the two systems. Let be the jth observation from system i
(i = 1, 2). Pair with and define for
j = 1, 2, …, n. Then, the are IID random variables and
, the quantity for which we want to construct a confidence interval.
Let
and
Then, the approximate 100(1- ) percent C.I. is
Yij
Y j1 Y j2Z Y Yj j j 1 2
Z j ' s
E Z j( )
Z n
Z
n
jj
n
( )
1
Var Z n
Z Z n
n n
jj
n
( )
( )
( )
1
2
1
Z n t Z nn( ) ( ), 1 1 2 Var

47
Two-Sample-t Confidence Interval
Make n1 replications of system 1 and n2
replications of system 2. Here . Again, for system i= 1, 2, let
and
Estimate the degrees of freedom as
Then, the approximate 100(1- ) percent C.I. is
n n1 2
Y n
Y
ni i
ijj
n
i
i
( )
1
S n
Y Y n
ni i
ij i ij
n
i
i
2 1
2
( )
( )
fS n n S n n
S n n n S n n n
12
1 1 22
2 2
2
12
1 1
2
1 22
2 2
2
21 1
( ) ( )
( ) ( ) ( ) ( )
Y n Y n tS n
n
S n
nf1 1 2 2 1 212
1
1
22
2
2
( ) ( )( ) ( )
,

48
Contrasting the Two Methods
The two-sample-t approach requires independence of and , whereas in the paired-t approach and do not have to be independent.
Therefore, in the paired-t approach, common random numbers can be used to induce positive correlation between the observations on the different systems to reduce the variance.
In the paired-t approach, n1 = n2, whereas in the two-sample-t method , .
n n1 2
Y j1 ' s Y j2 ' sY j1 ' s Y j2 ' s

49
Confidence Intervals For Comparing More Than Two
Systems
In the case of more than two alternative systems, there are two ways to construct a confidence interval on selected differences .
Comparison with a standard, and All pairwise comparisons
NOTE: Since we are making c > 1 confidence intervals, in order to have an overall confidence level of , we must make each interval at level (Bonferroni).
i i1 2
1 1 c

50
Comparison with a Standard
In this case, one of the systems (perhaps the existing system or policy) is a “standard”. If system 1 is the standard and we want to compare systems 2, 3, ..., k to system 1, k-1 confidence intervals must be constructed for the k-1 differences
In order to achieve an overall confidence level of at least , each of the k-1 confidence intervals must be constructed at level .
Can use paired-t or two-sample-t methods described in the previous section to make the individual intervals.
2 1 3 1 1 , , ..., k
1 1 ( )k
1

51
All Pairwise Comparisons
In this case, each system is compared to every other system to detect and quantify any significant differences. Therefore, for k systems, we construct k (k -1) / 2 confidence intervals for the k (k -1) / 2 differences:
Each of the confidence intervals must be constructed at a level of , so that an overall confidence of at least
can be achieved.
Again, we can use paired-t or two-sample-t methods to make the individual confidence intervals.
1 1 2 [ ( ) ]k k
1
2 – 1 3 – 1 ... k – 13 – 2 ... k – 2...
k – k–1

52
Ranking and Selection
The goals of ranking and selection are different and more ambitious than simply making a comparison between several alternative systems. Here, the goal may be to: Select the best of k systems
Select a subset of size m containing the best of k systems
Select the m best of k systems

53
Ranking and Selection
1. Selecting the best of k systems:
Want to select one of the k alternatives as
the best. Because of the inherent randomness in
simulation modeling, we can’t be sure that the selected system is the one with smallest (assuming small is good). Therefore, we specify a correct-selection probability P* (like 0.90 or 0.95).
Also we specify an indifference zone d* which means that if the best mean and next-best mean differ by more than d*, we select the best one with probability P*.
As an example, suppose that we have 5 alternative configurations and we want to identify the best system with a probability of at least 95%.
i

54
Ranking and Selection
2. Selecting a subset of size m containing the best of k systems:
Want to select a subset of size m (< k) that contains the best system with probability of at least P*.
This approach is useful in initial screening of alternatives to eliminate the inferior options.
For example, suppose that we have 10 alternative configurations and we want to identify a subset of 3 alternatives that contains the best system with a probability of at least 95% .

55
Ranking and Selection
3. Selecting the m best of k systems:
Want to select the m best (unranked) of the k systems so that with probability of at least P* the expected responses of the selected subset are equal to the m smallest expected responses.
This situation may be useful when we want to identify several good options, in case the best one is unacceptable for some reason.
For example, suppose that we have 5 alternative configurations and we want to select the 3 best alternatives and we want the probability of correct selection to be at least 90% .

















