1 Berkeley-Helsinki Summer Course Lecture #12: Introspection and Adaptation Randy H. Katz Computer Science Division Electrical Engineering and Computer Science Department University of California Berkeley, CA 94720-1776
Transcript
1
Berkeley-Helsinki Summer Course
Lecture #12: Introspection and Adaptation
Randy H. Katz
Computer Science Division
Electrical Engineering and Computer Science Department
University of California
Berkeley, CA 94720-1776
2
Outline
• Introspection Concept and Methods• SPAND Content Level Adaptation• MIT Congestion Manager/TCP Layer
Adaptation• ICAP Cache-Layer Adaptation
3
Outline
• Introspection Concept and Methods• SPAND Content Level Adaptation• MIT Congestion Manager/TCP Layer
Adaptation• ICAP Cache-Layer Adaptation
4
Introspection
• From Latin introspicere, “to look within”– Process of observing the operations of one’s own mind
with a view to discovering the laws that govern the mind
• Within the context of computer systems– Observing how a system is used (observe): usage
patterns, network activity, resource availability, denial of service attacks, etc.
– Extracting a behavioral model from such use (discover)– Use this model to improve the behavior of the system,
by making it more proactive, rather than reactive, to how it is used
– Improve performance and fault tolerance, e.g., deciding when to make replicas of objects and where to place them
5
Introspection in Computer Systems
• Locality of Reference– Temporal: objects that are used are likely to be used
again in the near future– Geographic: objects near each other are likely to be
used together
• Exploited in many places– Hardware caches, virtual memory mechanisms, file
caches– Object interrelationships– Adaptive name resolution– Mobility patterns
• Implications– Prefetching/prestaging– Clustering/grouping– Continuous refinement of behavioral model
6
Example: Wide-Area Routing and Data Location in
OceanStore• Requirements
– Find data quickly, wherever it might reside» Locate nearby data without global communication » Permit rapid data migration
– Insensitive to faults and denial of service attacks» Provide multiple routes to each piece of data» Route around bad servers and ignore bad data
– Repairable infrastructure» Easy to reconstruct routing and location information
• Technique: Combined Routing and Data Location
– Packets are addressed to GUIDs, not locations– Infrastructure gets the packets to their destinations and
verifies that servers are behaving John Kubiatowicz
7
Two-levels of Routing
• Fast, probabilistic search for “routing cache”
– Built from attenuated Bloom filters– Approximation to gradient search– Not going to say more about this today
• Redundant Plaxton Mesh used for underlying routing infrastructure:
– Randomized data structure with locality properties– Redundant, insensitive to faults, and repairable– Amenable to continuous adaptation to adjust for:
» Changing network behavior» Faulty servers» Denial of service attacks
• As in original Plaxton scheme:– Scheme to directly map GUIDs to root node IDs– Replicas publish toward a document root– Search walks toward root until pointer locatedlocality!
• OceanStore enhancements for reliability:– Documents have multiple roots (Salted hash of GUID)– Each node has multiple neighbor links– Searches proceed along multiple paths
» Tradeoff between reliability and bandwidth?– Routing-level validation of query results
• Dynamic node insertion and deletion algorithms
– Continuous repair and incremental optimization of links
John Kubiatowicz
11
OceanStore Domains for Introspection
• Network Connectivity, Latency– Location tree optimization, link failure recovery
• Database Provides Powerful, Flexible Storage– Persistent data allows long-term analysis– Standard interface for event handler scripting language– Leverage existing aggregation functionality
» Considerable work from Telegraph Project– Can be lightweight
• Sophisticated Algorithms Run On Databases– Too resource-intensive to operate directly on events– Allow use of full programming language– Security, termination still checkable; should use common
mechanisms
• E.g., expensive clustering algorithm operating over edge graph, using sparse-matrix operations to extract eigenvectors representing related filesDennis Geels,
• Not a very good name for a rather simple idea. Interesting introspective problems are inherent-ly distributed. Coodination among nodes is difficult. Needed:
– Automatically create/locate parents in aggregation hierarchy
– Path redundancy for stability, availability– Scalability– Fault tolerance, responsiveness to fluctuation in
workload
• OceanStore data location system shares these requirements. This coincidence is not surprising, as each are instances of wide-area distributed problem solving.
• Introspection Concept and Methods• SPAND Content Level Adaptation• MIT Congestion Manager/TCP Layer
Adaptation• ICAP Cache-Layer Adaptation
19
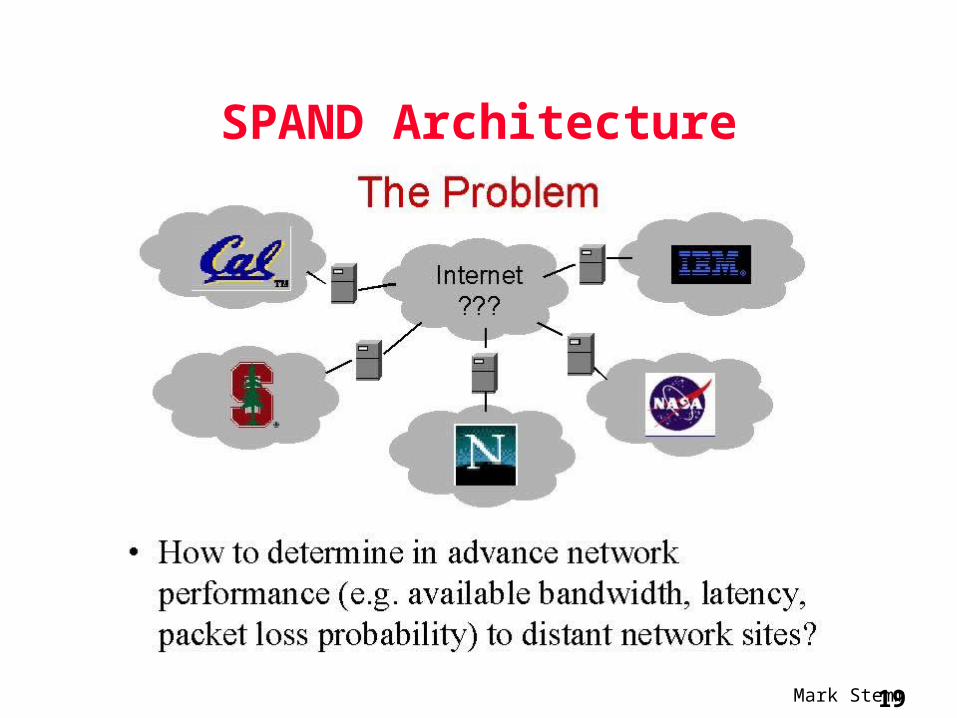
SPAND Architecture
Mark Stemm
20
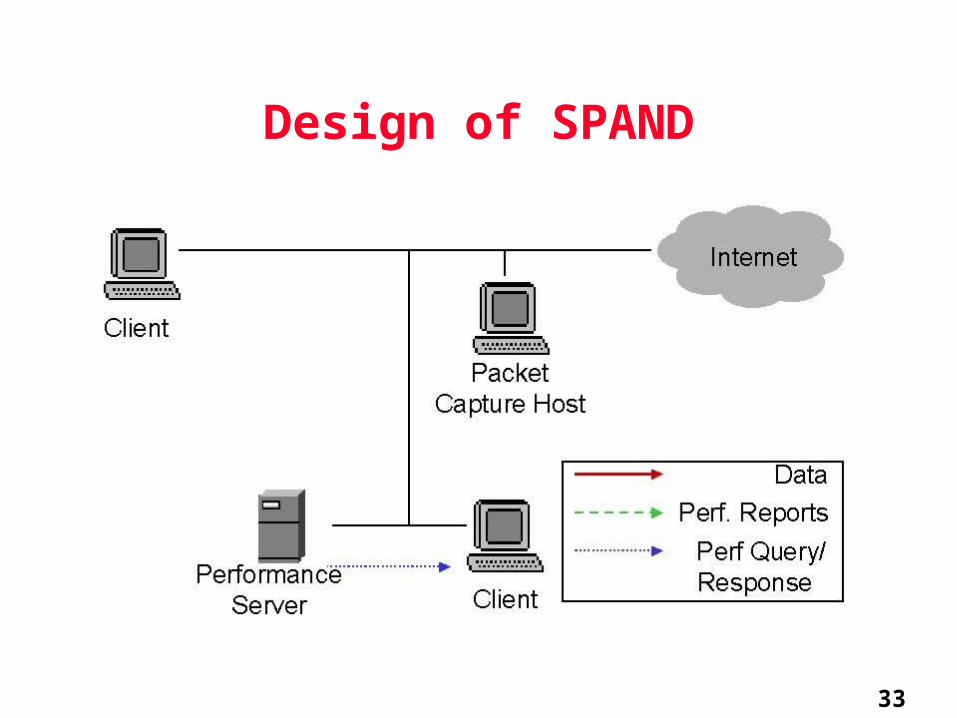
SPAND Architecture
Mark Stemm
21
What is Needed
• An efficient, accurate, extensible and time-aware system that makes shared, passive measurements of network performance
• Applications that use this performance measurement system to enable or improve their functionality
Mark Stemm
22
Issues to Address
• Efficiency: What are the bandwidth and response time overheads of the system?
• Accuracy: How closely does predicted value match actual client performance?
• Extensibility: How difficult is it to add new types of applications to the measurement system?
• Time-aware: How well does the system adapt to and take advantage of temporal changes in network characteristics?
Mark Stemm
23
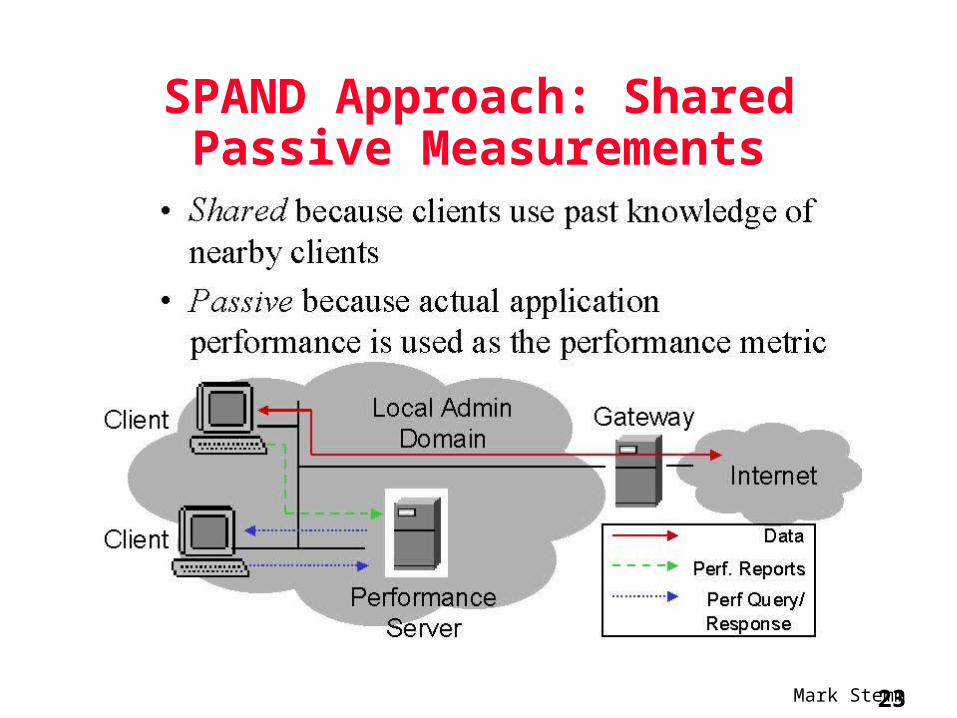
SPAND Approach: Shared Passive Measurements
Mark Stemm
24
Related Work
• Previous work to solve this problem– Use active probing of network– Depend on results from a single host (no sharing)– Measure the wrong metrics (latency, hop count)
• NetDyn, NetNow, Imeter– Measure latency and packet loss probability
• Packet Pair, bprobes– If Fair Queuing, measures “fair share” of bottleneck link b/w)– Without Fair Queuing, unknown (min close to link b/w)
» Telnet: uses reliability» Real-time: uses flow control and reliability
– (Addr, Application Class) is target of a Performance Request/Report
Mark Stemm
35
Issues
• Accuracy– Is net performance stable enough to make meaningful
Performance Reports?– How long does it take before the system can service
the bulk of the Performance Requests?– In steady state, what % of Performance Requests does
the system service?– How accurate are Performance Responses?
• Stability– Performance results must not vary much with time
• Implications of Connection Lengths– Short TCP connections dominated by round trip time;
long connections by available bandwidth
Mark Stemm
36
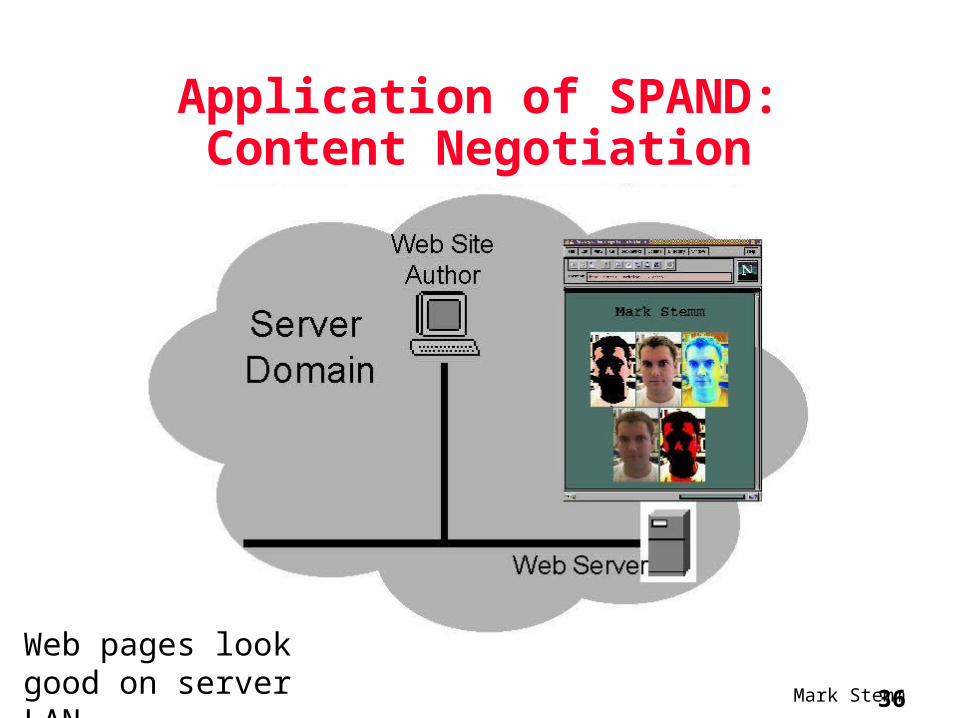
Application of SPAND:Content Negotiation
Mark Stemm
Web pages look good on server LAN
37Mark Stemm
Implications for Distant Access,
Overwhelmed Servers
38
Content Negotiation
Mark Stemm
39
Client-Side Negotiation Results
Mark Stemm
40
Server-Side Dynamics
Mark Stemm
41
Server-Side Negotiation: Results
Mark Stemm
42
Content Negotiation Results
• Network is the bottleneck for clients and servers
• Content negotiation can reduce download times of web clients
• Content negotiation can increase throughput of web servers
• Actual benefit depends on fraction of negotiable documents
Mark Stemm
43
Outline
• Introspection Concept and Methods• SPAND Content Level Adaptation• MIT Congestion Manager/TCP Layer
Adaptation• ICAP Cache-Layer Adaptation
44
Congestion Manager(Hari@MIT, Srini@CMU)
• The Problem:– Communications flows compete for same limited bandwidth
resource (especially on slow start!), implement own congestion response, no shared learning, inefficient, within end node
• The Power of Shared Learning and Information Sharing
f(n)f(n)
f2f2
f1f1
ServerClient
Internet
45
Adapting to Network
f1f1
Server
• New applications may not use TCP– Implement new protocol– Often do not adapt to congestion: not “TCP-friendly”
Internet
Client
?
Need system that helps applications learnand adapt to congestion
Need system that helps applications learnand adapt to congestion
46
State of Congestion Control
• Increasing number of concurrent flows
• Increasing number of non-TCP apps
Congestion Manager (CM): An end-system architecture for congestion management
Congestion Manager (CM): An end-system architecture for congestion management
47
The Big Picture
IP
HTTP Video1
TCP1 TCP2 UDP
Audio Video2
All congestion management tasks performed in CMApplications learn and adapt using API
All congestion management tasks performed in CMApplications learn and adapt using API
CongestionManager
Per-macroflow statistics
(cwnd, rtt, etc.)API
48
Problems
• How does CM control when and whose transmissions occur?
– Keep application in control of what to send
• How does CM discover network state?– What information is shared?– What is the granularity of sharing?
Key issues: API and information sharingKey issues: API and information sharing
49
The CM Architecture
Applications (TCP, conferencing app, etc)
Prober
CongestionController
Scheduler
Responder
Congestion Detector
Sender Receiver
CM protocol
API
50
Feedback about Network State
• Monitoring successes and losses– Application hints– Probing system
• Notification API (application hints)
51
IP header
Probing System
• Receiver modifications necessary– Support for separate CM header– Uses sequence number to detect losses– Sender can request count of packets received
• Receiver modifications detected/negotiated via handshake– Enables incremental deployment
IP payload CM headerIP payload
52
Congestion Controller
• Responsible for deciding when to send a packet
• Window-based AIMD with traffic shaping• Exponential aging when feedback low
– Halve window every RTT (minimum)
• Plug in other algorithms– Selected on a “macro-flow” granularity
53
Scheduler
• Responsible for deciding who should send a packet
• Hierarchical round robin• Hints from application or receiver
– Used to prioritize flows
• Plug in other algorithms– Selected on a “macro-flow” granularity– Prioritization interface may be different
54
CM Web Performance
With CM
CM greatly improvespredictabilityand consistency
TCP Newreno
Time (s)
Seq
uen
ce n
um
ber
55
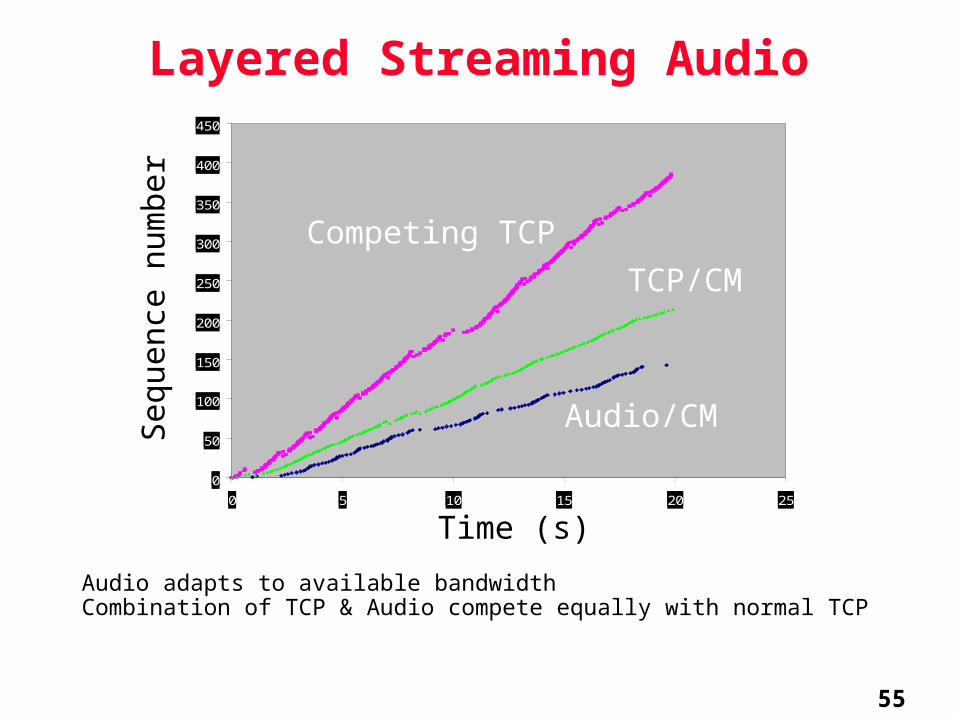
Layered Streaming Audio
Audio adapts to available bandwidthCombination of TCP & Audio compete equally with normal TCP
0
50
100
150
200
250
300
350
400
450
0 5 10 15 20 25
Time (s)
Seq
uen
ce n
um
ber
Competing TCP
TCP/CM
Audio/CM
56
Congestion Manager Summary
• CM enables proper & stable congestion behavior
• Simple API enables app to learn/adapt to network state
• Improves consistency/predictability of net xfers• CM provides benefit even when deployed at
senders alone
57
Outline
• Introspection Concept and Methods• SPAND Content Level Adaptation• MIT Congestion Manager/TCP Layer
• Very simple operation– ICAP builds on HTTP GET and POST
• No proprietary APIs Required• Standards-based• Leverages the latest Internet infrastructure
developments• Fast, simple, scalable, and reliable• Allows you to customise services
64
iCAP general design
• Simple, simple, simple: CGI should be able to turn a web server to an ICAP server
• Based on HTTP (+special headers)• Three modes:
– Modify a request– Satisfy a request (like any other proxy)– Modify a response
65
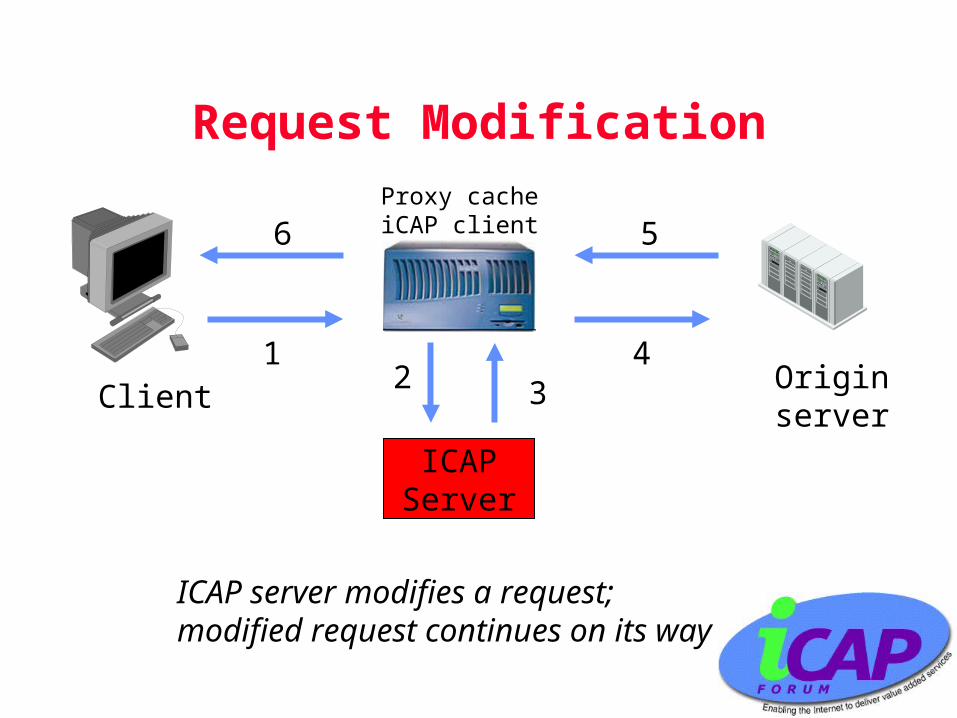
Request Modification
• The request is passed to the ICAP server (almost) unmodified; just like a proxy would
• The ICAP server sends back a modified request, encapsulated in response headers
– Body, if any (e.g. POST), may also be modified
66
Request Modification
Client
ICAPServer
6
2 31
5
4
ICAP server modifies a request;modified request continues on its way
Originserver
Proxy cacheiCAP client
67
Response Modification
• ICAP client always uses POST to send body• Encapsulated in POST headers may also
be:– Headers used by user to request the object– Headers used by origin server in its reply
• ICAP server replies with modified content
68
Response Modification
Origin ServerClientProxy Cache(ICAP Client)
ICAPServer
4 5
2
3
1
6
ICAP server modifies a response from an origin server;might be once, as the object is cached, or once per client served
69
Request Satisfaction
Origin Server
ClientProxy Cache(ICAP Client)
ICAPServer
2 5
3
4
1
6
ICAP server satisfies a request just like a proxy;origin server MAY be contacted by ICAP server (or not)
70
Infinite Variations
• Allows innovations. You choose 3rd party applications.
• iCAP enables many different kinds of apps!– Edge content sources can pass pages to ad servers– Expensive operations can be offloaded– Content filters can respond either with an unmodified
request or HTML (“Get Back to Work!”)
71
Next Steps
• ICAP Supporters continue to enhance protocol
– Learn from solutions and fix “bugs”– Build future functionality later
• IETF– ICAP Forum will submit the specification to IETF for
draft RFC status in mid 2000
• Additional partners – Software developers, infrastructure companies and
Internet content delivery service providers will be solicited for participation
– Need to get on same page
72
More on – Important iCAP info at this site http://www.i-cap.org.
– Become an iCAP Participant by sending an e-mail to mailto:[email protected]. A reply will be sent outlining requirements.