27
1 Databases in Bioinformatics (Roald Forsberg)
| Date post: | 20-Dec-2015 |
| Category: |
Documents |
| View: | 222 times |
| Download: | 1 times |

1
Databases in Bioinformatics
(Roald Forsberg)

2
Overview
The role of databases in bioinformatics
The structure of databases– Relational databases
– Database Management Systems
– Accessing databases
Types of databases– Data types
– Integrated databases (Entrez)
Nucleotide sequence formats– FASTA format
– GenBank format
– XML formats

3
Databases in BioinformaticsBioinformatics – attempted definition:
“The application of computational techniques to understand and organise the information associated with biological macromolecules”
Adapted from Oxford English Dictionary
Biological experiments
Databases
Computational Biology

4
Ask your neighbour
• What would you like to do with a database?
• Which types of biological information could be stored in a database?

5
Use of databases
• Homology searching:– Use of knowledge from other often more well described organisms such
as the model organisms Mouse, Drosophila, Fugu, C.Elegans etc..– Sequence level – position, annotation– Structural level – proteins, RNA
• Evolutionary analyses:– Phylogenetics– Population genetics– Molecular evolution of genetic elements– Genome evolution
• Primer design• Microarray design• Drug design• Many more……

6
General types of databases
• Primary– Raw and non-processed data
• Secondary– Curated – data chosen from criteria– E.g non-redundance, fold
• Tertiary– Data processed– HMM profile

7
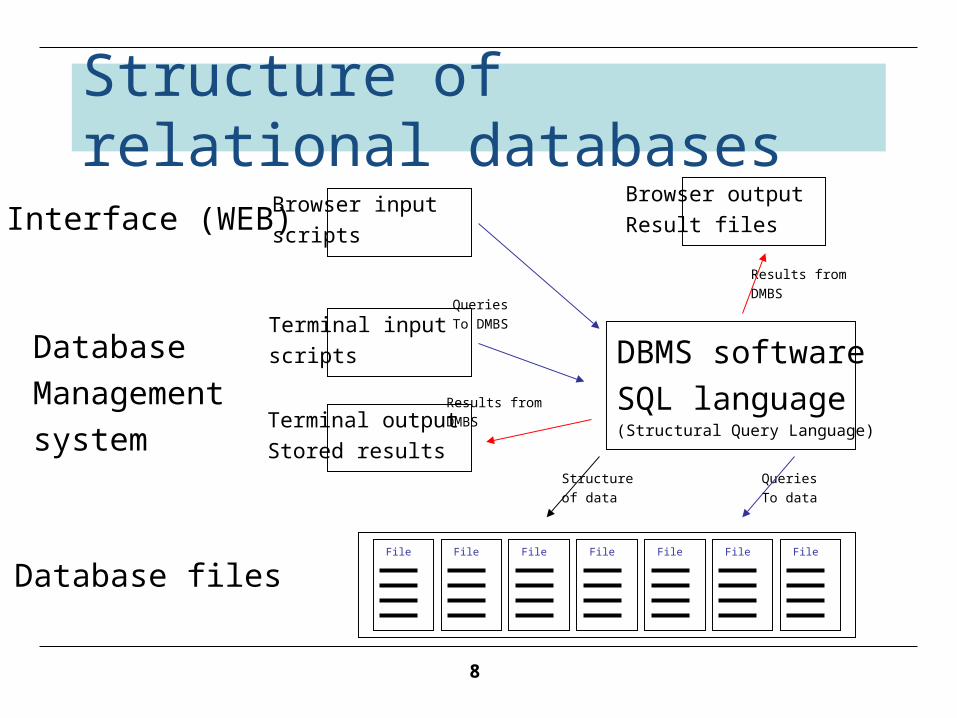
Structure of relational databases
MEQ147631MEQ147632MEQ147633MEQ147634MEQ147635MEQ147636MEQ147637MEQ147638MEQ147639MEQ147640MEQ147641
EntriesTable 1
Table 2
Table = genetic element
Field = position = chr. 4
Field = size = 3540 bp
Field = coding = true
Field = known EST = true
Field = known structure = false
8
Structure of relational databases
File
Database files
Database
Management
system
Interface (WEB)
File File File File File File
Terminal input
scripts DBMS software
SQL language (Structural Query Language)Terminal output
Stored results
Queries
To DMBS
Browser input
scripts
Results from
DMBS
Queries
To data
Structure
of data
Browser output
Result files
Results from
DMBS

9
Database management systems
• A software package designed to store and manage databases.
• A computerized record-keeping system• Allows operations such as:
– Adding new files– Inserting data into existing files– Retrieving data from existing files– Changing data– Deleting data– Removing existing files from the database

10
Accessing a database
• WEB – graphical user interface (GUI)
• WEB – automated procedures– Batch search with script (Entrez)– Search robots with e-mail updates
• Local– Buy a big computer and a thick cable– Speed improvement

11
Protein sequence databasesDatabase URL
Protein sequence(primary)SWISS-PROT www.expasy.ch/sprot/sprot-top.htmlPIR-International www.mips.biochem.mpg.de/proj/protseqdb Protein sequence (composite)OWL www.bioinf.man.ac.uk/dbbrowser/OWL
NRDB www.ncbi.nlm.nih.gov/entrez/query.fcgi?db=Protein
Protein sequence (secondary)PROSITE www.expasy.ch/prosite
PRINTS www.bioinf.man.ac.uk/dbbrowser/PRINTS/PRINTS.html
Pfam www.sanger.ac.uk/Pfam/

12
Nucleotide sequence databases
• GenBank www.ncbi.nlm.nih.gov/Genbank
• EMBL www.ebi.ac.uk/embl
• DDBJ www.ddbj.nig.ac.jp

13
Types of nucleotide data
• cDNA– Reversely transcribed from mRNA
• Genomic sequences– Directly sequenced from DNA strings of
various species
• EST’s– a tiny portion of an entire gene derived from
mRNA

14
Macromolecular structure databases
• Protein Data Bank (PDB) www.rcsb.org/pdb
• Nucleic Acids Database (NDB) http://ndbserver.rutgers.edu//
• PDBsum www.biochem.ucl.ac.uk/bsm/pdbsum
• CATHwww.biochem.ucl.ac.uk/bsm/cath
• SCOP http://scop.mrc-lmb.cam.ac.uk/scop/
• FSSP www.embl-ebi.ac.uk/dali/fssp

15
Molecular interaction databases
• General– Biomolecular Interaction Network Database http://bioinfo.mshri.on.ca/cgi-bin/bind/dataman
– Molecular interactions Database (MINT) http://cbm.bio.uniroma2.it/mint/
• Protein-Protein interactions– Database of interacting proteins http://dip.doe-mbi.ucla.edu/
• Biochemical pathways– KEGG Metabolic Pathways http://www.genome.ad. jp/kegg
/metabolism.html

16
Proteomics databases
• Yeast Proteome Database http://www.incyte
.com/sequence/proteome/databases/YPD.shtml
• SWISS-2DPAGEhttp://us.expasy.org/ch2d/
• TMIG-2DPAGEhttp://proteome.tmig.or.jp/2D/

17
Genome databases
• Entrez genomes www.ncbi.nlm.nih.gov/entrez/query.fcgi?db=Genome
• Ensemble genomes http://www.ensembl.org/
• HIV Sequence Database
http://hiv-web.lanl.gov/content/hiv-db/mainpage.html
• FlyBase http://flybase.bio.indiana.edu/
• COGs www.ncbi.nlm.nih.gov/COG

18
Integrated databases
Increasing the value of information
• InterPro www.ebi.ac.uk/interpro
• Sequence retrieval system (SRS) www.expasy.ch/srs5
• Entrez www.ncbi.nlm.nih.gov/Entrez

19
Entrez
Journals
UniGenePubMed Nucleotide
Protein
SNP
Genome
BooksProbeSet
OMIM
CDD
Taxonomy
3D Domains
UniSTS
PopSet
Structure
The (ever) Expanding Entrez System

20
EBI services
• http://www.ebi.ac.uk/services/index.html

EBI
GenBankGenBank
DDBJDDBJ
EMBLEMBL
EMBLEMBL
Entrez
SRS
getentry
NIGNIGCIB
NCBI
NIHNIH
•Submissions•Updates •Submissions
•Updates
•Submissions•Updates
The International Sequence Database Collaboration

22
A closer look at GenBank
• Maintained by NCBI
• Accessed through
Entrez
• Synchonized with
DDBJ and EMBL

23
Sequence file formats
• Ideally – a stringent, easy to parse, specified format to facilitate the dissemination of information
• Reality – a plethora of coincidental and badly specified formats
• Different levels of information
• Some common formats– FASTA
– GenBank
– PHYLIP (PHYLIP package and others)
– Nexus (PAUP package, MacClade and others)
– Up and coming: XML
• Simple – sequence and name attribute
• Advanced – several attributes

24
FASTA format
>gi|532319|pir|TVFV2E|TVFV2E envelope protein ELRLRYCAPAGFALLKCNDADYDGFKTNCSNVSVVHCTNLMNTTVTTGLLLNGSYSENRTQIWQKHRTSNDSALILLNKHYNLTVTCKRPGNKTVLPVTIMAGLVFHSQKYNLRLRQAWCHFPSNWKGAWKEVKEEIVNLPKERYRGTNDPKRIFFQRQWGDPETANLWFNCHGEFFYCKMDWFLNYLNNLTVDADHNECKNTSGTKSGNKRAPGPCVQRTYVACHIRSVIIWLETISKKTYAPPREGHLECTSTVTGMTVELNYIPKNRTNVTLSPQIESIWAAELDRYKLVEITPIGFAPTEVRRYTGGHERQKRVPFVXXXXXXXXXXXXXXXXXXXXXXVQSQHLLAGILQQQKNL LAAVEAQQQMLKLTIWGVK
http://www.ncbi.nlm.nih.gov/BLAST/fasta.html

25
GenBank format
A verbose but very informative format
Contains much information in carefully specified format
Harder to parse than FASTA
http://www.ncbi.nlm.nih.gov/Sitemap/samplerecord.html

26
eXtensible Markup Language (XML)
• Markup language for data-representation – derived from SGML, sib of HTML
• Stringent simple language with rigid rules
• Human readable and versatile
• Good parsers exists for multiple platforms
• The ability to design own Document Type Definitions that parsers can use to validate a
document permits complex data structures and grammars
• Examples of use for sequence data:
– NCBI GBSeqXML
– NCBI TinySeqXML

27
Links
http://www.ncbi.nlm.nih.gov/Education/
http://www.infobiogen.fr/services/dbcat/
http://www.science.gmu.edu/~ntongvic/Bioinformatics/database.html
http://www.hgmp.mrc.ac.uk/GenomeWeb/prot-interaction.html
http://www.no.embnet.org/Programs/DB/srs.php3

















