1 Efficient Search Ranking in Social Network ACM CIKM2007 Monique V. Vieira, Bruno M. Fonseca, Rodrigo Damazio, Paulo B. Golgher, Davi de Castro Reis, Berthier Ribeir o-Neto Date:2008/10/02 Speaker: Hsu, YuWen Advisor: Dr. Koh, JiaLing
Transcript
1
Efficient Search Ranking in Social Network
ACM CIKM2007Monique V. Vieira, Bruno M. Fonseca, Rodrigo Damazio, Paulo B. Golgher,
Davi de Castro Reis, Berthier Ribeiro-Neto
Date:2008/10/02Speaker: Hsu, YuWen
Advisor: Dr. Koh, JiaLing
2
Outline
Introduction The ranking function Algorithm for computing the ranking Seeds-based Ranking Algorithm for computing seeds-based ranking Results Conclusion
3
Introduction Social networks: interact and share social ex
periences through the exchange of multimedia objects (text, audio, video) associated with the people themselves and their actions.
MySpace (www.myspace.com) with over 100 million registered users, Orkut (www.orkut.com) with over 40 million , Facebook and Friendster.
4
Introduction (cont.) In a social network with a large number of us
ers, a common operation is to search for people.
Randomly selected 750 queries from the Orkut logs, all of them specify just user names.
counted the average number of answers per query. exact matches: avg. result per query is 48 partial matches : avg. result per query is 6,034
5
Introduction (cont.)
Designing a ranking function which takes as input distances in a friendship graph nodes : users edges : friendship relationship based on a set of pre-selected landmark nodes
(called seeds). Our results show that effective ranking can
be attained, while keeping query processing time small enough to be practical.
6
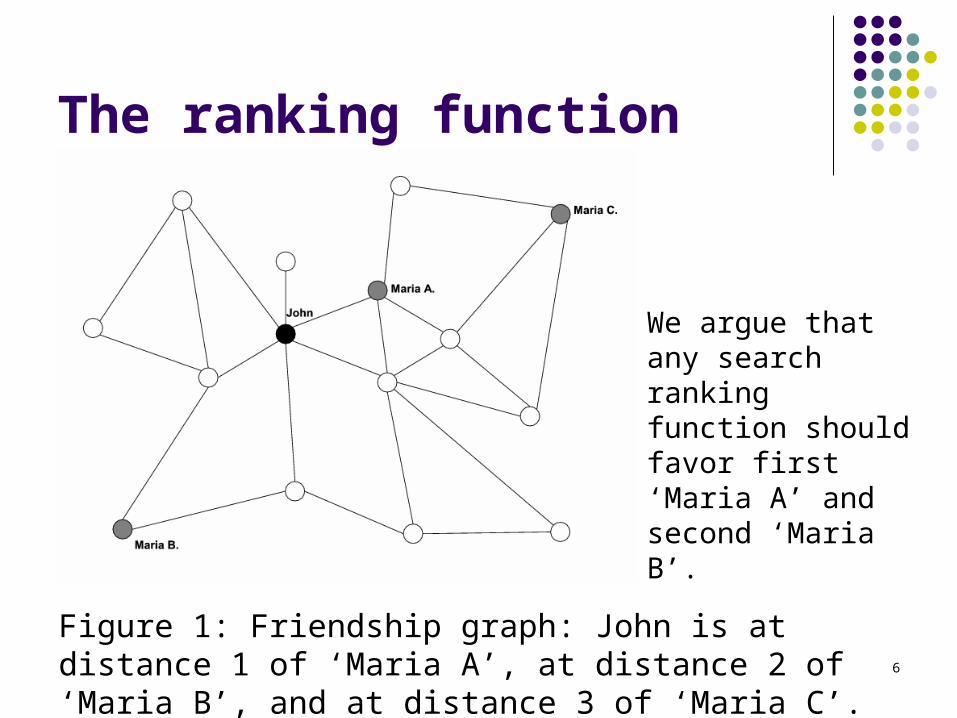
The ranking function
Figure 1: Friendship graph: John is at distance 1 of ‘Maria A’, at distance 2 of ‘Maria B’, and at distance 3 of ‘Maria C’.
We argue that any search ranking function should favor first ‘Maria A’ and second ‘Maria B’.
7
The ranking function (cont.)
This reasoning leads us to propose the following simple ranking function:
:the shortest path between John and Maria
:the rank of the user Maria,with the regard to the query ‘Maria’ posed by John
)(_1)(
MariaJ
pathshortestMaria
JRank
)(MariaJ
Rank
)(_ MariaJ
pathshortest
8
Algorithms for computing the ranking*Pre-compute all distances
between any pair of users and indexing them do not work : 40 million users be stored is in the
order [ ], which is too large. if each user has 100 friends on average, then the
average number of friends at a distance 3 or smaller of a given user is , resulting in a still very large index size in [ ]
pre-computing all friendship pairs presents no scalability. The number of friendship distances that needs to be stored becomes overwhelming.
1210240
121040
610
9
Algorithms for computing the ranking*On-the-fly Ranking
calculating all the distances on-the-fly at scoring time. simply run a breadth first search for Maria starting
from John avg. 100 friends per user, need to expand more th
an users if we limit ourselves to people at most 3 hops from John
superior alternative run a bidirected breadth-first search, looking for intersections in the list of users reached in the new level.
610
10
Algorithms for computing the ranking*Co-friends Ranking
mix of the first two: index their list of friends and at scoring time intersect both lists. advantage: fast, little space disadvantage: only captures friends or friends-of-friends
relations.
pre-compute a co-friends list and intersect it with the list of friends of the user submitting the query.
friendship distances up to 3 the space and time requirements are pretty high unfeasible to be used cost effectively in a huge Web live service
11
Seeds-based Ranking
key purpose: to produce results of high precision but that can be computed efficiently
based on estimates, approximations of shortest paths and has a more complex composition
: the number of seeds whose sum of distances to both John and Maria is exactly i.
:the number of seeds with a finite distance to Maria and is used as a normalization factor.
: the rank of the answer ‘Maria’ with regard to the query posed by John.
idistseedsnumber ___
)(_ Mariaseedsnumber
)(Mariarank J
16
Seed distances vectors for usersDJohn = [2, 1, 1] DMaria A = [1, 1, 2] DMaria B = [4, 3, 1] DMaria C = [1, 2, 4]
‘Maria A’ > ‘Maria B’ > ‘Maria C’
S1
S3
S2
21378.213
20961.128
419.18
17
Algorithm for computing seeds-based ranks*Sparse Seed Distances Vectors
18
If a seed distance is higher than 3, we consider it to be infinite.
these vectors become more sparse. a large number of seed distances is set to infinite no need to be stored in the seed distances vectors fast computation and reduces query processing time producing high precision rankings
DJohn = [2, 1, 1] DMaria A = [1, 1, 2] DMaria B = [∞, ∞, 1] DMaria C = [1, 2, ∞]
19
Algorithm for computing seeds-based ranks*Map-reduce Computation of Seed Distances
20
Algorithm for computing seeds-based ranks*computing seeds-based ranks
match user names to the query and retrieve those that partially match the query terms.
generate the seeds-based ranks.
21
Result* Precision Results
compare Ranking Precision(crP) the ideal answer set : the set of documents most li
kely to be relevant to the users
On-the-fly Ranking algorithm as the ideal answer set and compute the P@10 metric for the Seeds-based Ranking algorithm, we get a precision value of 90%.
22
Definition of the ideal answer set: : the set of top 10 users returned by the On-the-fly Ran
king algorithm : the 10th answer in the result set : the distance of to the user who posed the query A : the set of all answers : the ith answer in the result set : For any , the distance between and the user wh
o posed the query
Define the subset as
The ideal answer set of I is define as
)( iaD ia
)}()({ 10oDaDAaaA iiio
topO
topOo 10
)( 10oD 10o
Aai ia
AAo
otop AOI
23
Since the set I includes no relevance judgements, we call our metric compare-rankings Precision (also cr-precision).
crP@10 refers to the compare-rankings precision at the 10th position of the ranking.
24
Seeds-based Ranking algorithm 100,000 seeds :avg. cr-precision starts at 71.48% 2,000,000 seeds: avg. cr-precision reaches the 90% range
Co-friends Ranking algorithm pretty good avg. cr-precision of 87.02%.
summary : high precision can be attained using ranking functions that requir
e much less computational resources the Seeds-based Ranking is highly competitive in terms of precisi
on.
25
In addition to standard crP@10 metric, we also present our results based on generalized precision.
In the context of generalized precision, the relevance decision is not binary. Instead, weights are assigned to the answers as follows.
26
Definition:generalize compare-rankings precision ( gerP) : On-the-flying Ranking : the alternative ranking we want to evaluate , :the ith answers in the respective ran
kings , :the friendship distances from and
i i
irr oweight
aweightAOgerP )()(),(
ri Oo ri Aa
)( iaD )( ioD ia io
5)(,5)( ii aDoD
)(5)( ii aDaweight
)(5)( ii oDoweight
rO
rA
27
Seeds-based Ranking algorithm 100,000 seeds :avg. cr-precision starts at 60% 2,000,000 seeds: avg. cr-precision reaches the 83-85% range
summary: high precision is attained by ranking algorithms that require less
computational resources the Seeds-based Ranking algorithm produces the best results, w
hen 2,000,000 seeds or more are used.
28
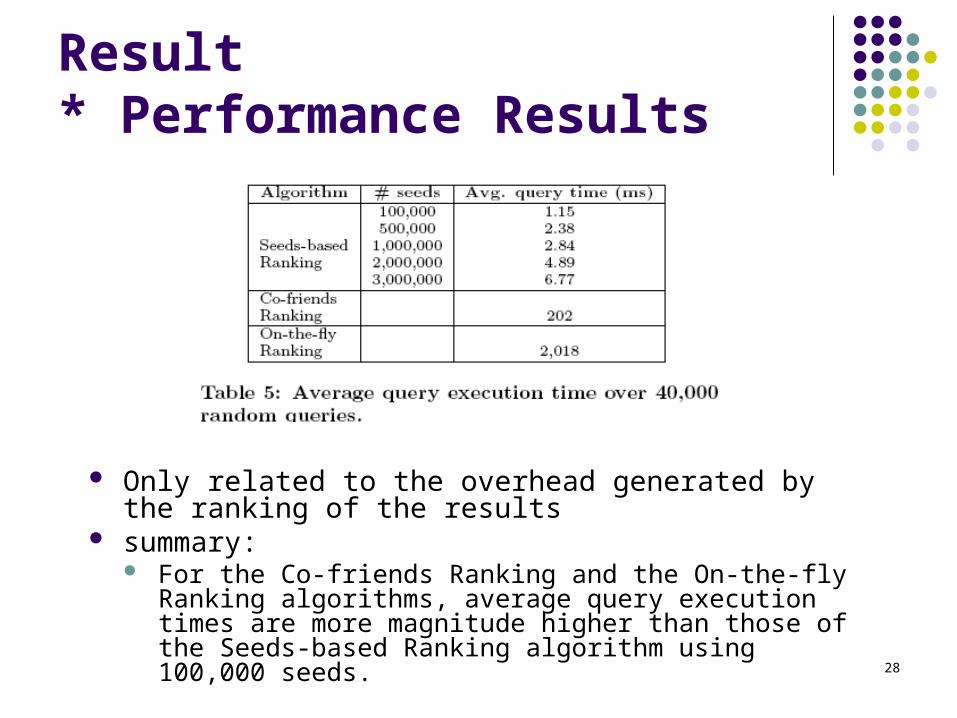
Result* Performance Results
Only related to the overhead generated by the ranking of the results
summary: For the Co-friends Ranking and the On-the-fly Ranking
algorithms, average query execution times are more magnitude higher than those of the Seeds-based Ranking algorithm using 100,000 seeds.
29
While there is no need for an extremely fast procedure, as it is carried out offline, this still needs to be fast enough to be usable in a live Web system
2,000,000 seeds of distances can be computed in basically 12 minutes (725seconds)
30
Result* Space Results
On-the-fly Ranking Space Requirements This graph takes roughly 16GB of space. the number of machines in the cluster, N = 128. the space
required is actually 128 * 16GB= 2,048GB. Co-friends Ranking Space Requirements
user id :4 bytes integer. the list of friend-of-friends :40 million users each user has avg. 90 friends the space requirements are roughly 40M * 90* 90 * 4 = 1,260GB.
31
Result* Analysis Of the Results
32
Conclusion
Social Networks are a new and important trend in the Web
how to add this new signal in a distributed architecture, and how the strategy we have developed for that outperforms naive approaches, both in terms of precision and performance
we moved from a text based ranking, almost meaningless to users, to a ranking where one can easily recognize the people in the search results.