1 Indexing Mechanism for Separating logical organization of files from their physical organization The physical file may be unorganized, but there may be logically ordered indexes for accessing it Conducting efficient searches on the files Indexes hold information about location of records with specific values Index structures (hopefully) fit in main memory so index searching is fast Indexing is an issue for both file systems and DBMSs Remember that databases are eventually mapped to files (e.G., Each relation stored in one file) In DBMSs, the query processor accesses the index structures in processing a query
Transcript
1
Indexing Mechanism for
Separating logical organization of files from their physical organization
The physical file may be unorganized, but there may be logically ordered indexes for accessing it
Conducting efficient searches on the files Indexes hold information about location of records with specific
values Index structures (hopefully) fit in main memory so index searching
is fast Indexing is an issue for both file systems and DBMSs
Remember that databases are eventually mapped to files (e.G., Each relation stored in one file)
In DBMSs, the query processor accesses the index structures in processing a query
2
Types of Indexes
Indexes on ordered vs unordered files Dense vs sparse indexes
Primary indexes vs secondary indexes Single-level vs multi-level
Single-level ones allow binary search on the index table and access to the physical records/blocks directly from the index table
Multi-level ones are tree-structured and require a more elaborate search algorithm
3
Single-Level Indexes on Unordered Files
The physical records are not ordered; the index provides a physical order
Physical files are called entry-sequenced since the order of physical records is that of entry order. Append records to the physical file as they are inserted Build an index (primary and/or secondary) on this file Deletion/Update of physical records require
reorganization of the file and the reorganization of primary index
4
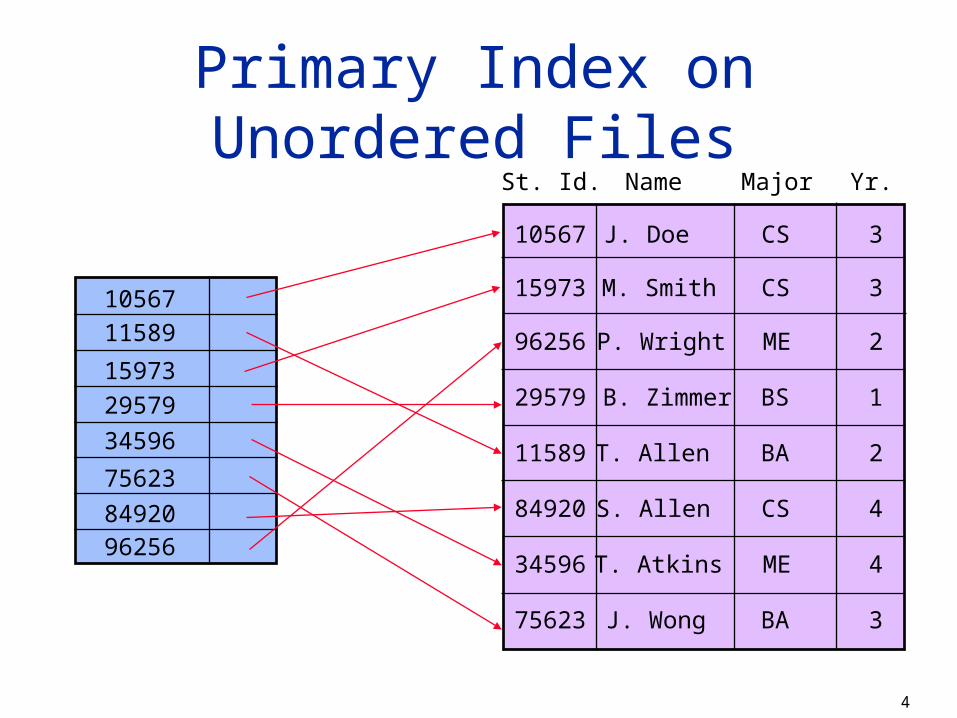
Primary Index on Unordered FilesSt. Id. Name Major Yr.
10567
15973
96256
29579
11589
84920
34596
75623
J. Doe CS 3
M. Smith
P. Wright
B. Zimmer
T. Allen
S. Allen
T. Atkins
J. Wong
CS
ME
BS
BA
CS
ME
BA
3
2
1
2
4
4
3
10567
11589
15973
29579
34596
75623
8492096256
5
Operations
Record addition Append the record to the end; Insert a record to the
appropriate place in the index Requires reorganization of the index
Record deletion Delete the physical record using any feasible technique Delete the index record and reorganize
Record updates If key field is affected, treat as delete/add If key field is not affected, no problem.
6
Primary Index on Ordered Files
Physical records may be kept ordered on the primary key
The index is ordered but only one index record for each block
Reduces the index requirement, enabling binary search over the values (without having to read all of the file to perform binary search).
7
Primary Index on Ordered Files
10567 J. Doe CS 3
15973 M. Smith CS 3
11589 T. Allen BA 2
10567
29579
84920
29579 B. Zimmer BS 1
34596 T. Atkins ME 4
75623 J. Wong BA 3
84920 S. Allen CS 4
96256 P. Wright ME 2
Also calledinverted file index.
8
Clustering Index on Ordered Files
CS
BA
ME
34596 T. Atkins ME 4
10567 J. Doe CS 3
15973 M. Smith CS 3
84920 S. Allen CS 4
96256 P. Wright ME 2
BS
75623 J. Wong BA 3
11589 T. Allen BA 2
29579 B. Zimmer BS 1
34596 T. Atkins ME 4There should be no primaryindex if clustering index isto exist.
9
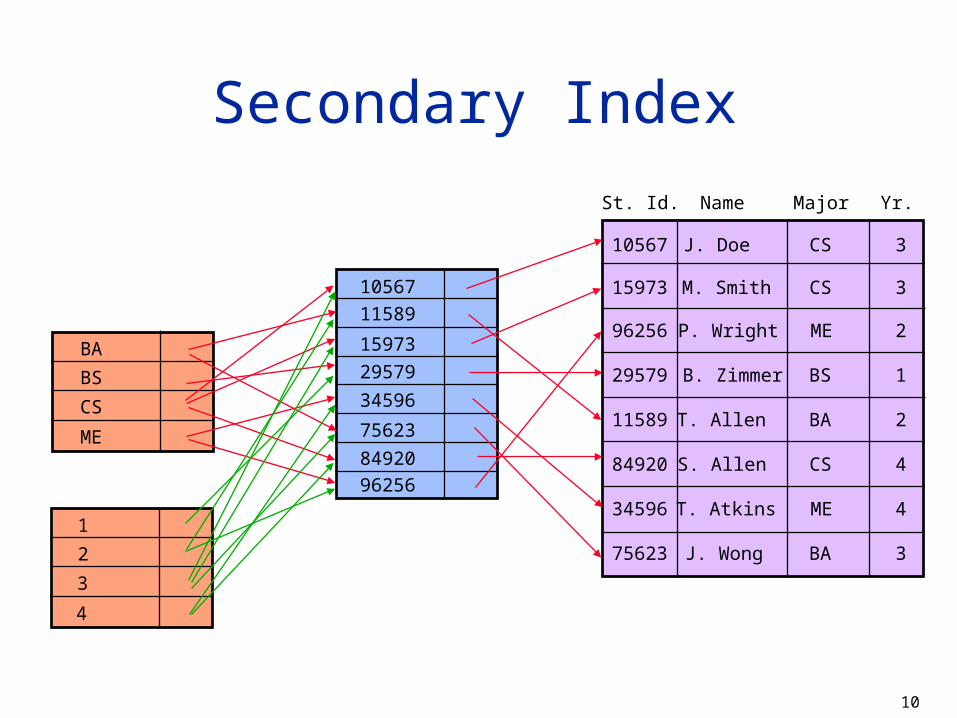
Secondary Index
In addition to the primary index, establish indexes on non-key attributes to facilitate faster access
Secondary indexes typically point to primary index Advantage:
Record deletion and update causes less work
Disadvantage: Less efficient
10
Secondary Index
St. Id. Name Major Yr.
10567
15973
96256
29579
11589
84920
34596
75623
J. Doe CS 3
M. Smith
P. Wright
B. Zimmer
T. Allen
S. Allen
T. Atkins
J. Wong
CS
ME
BS
BA
CS
ME
BA
3
2
1
2
4
4
3
10567
11589
15973
29579
34596
75623
84920
96256
CS
BA
ME
BS
3
1
4
2
11
Problems With Inverted Files
Inverted file indexes cannot be maintained in main memory as the database sizes and number of keywords increase.
Binary search over indexes that are stored in secondary storage is expensive. Too many seeks and I/Os.
Maintaining the indexes in sorted key order is difficult and expensive.
12
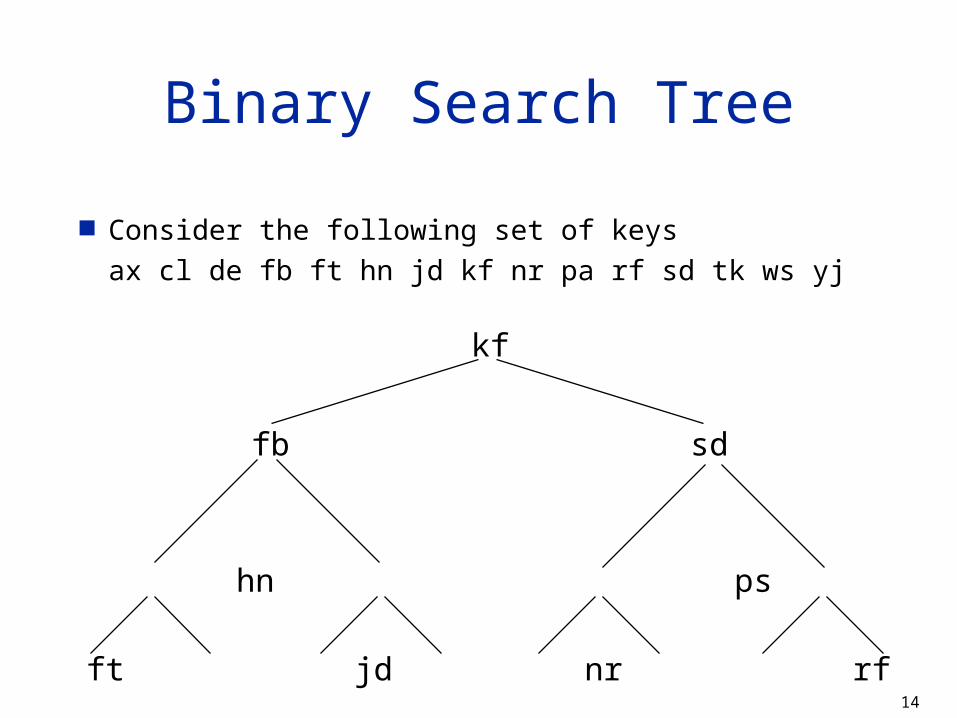
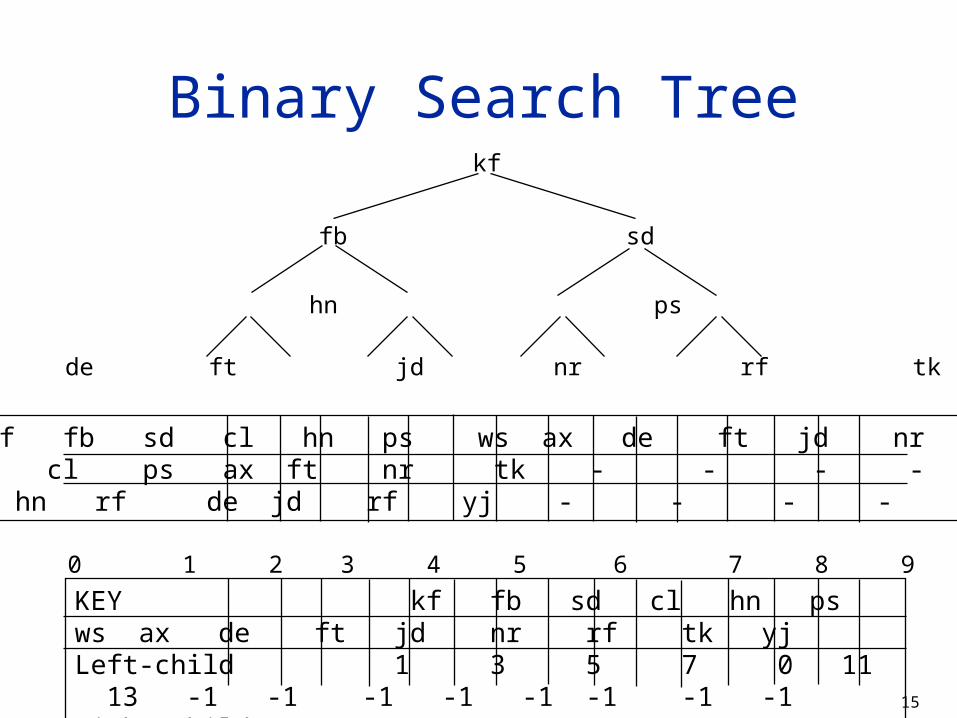
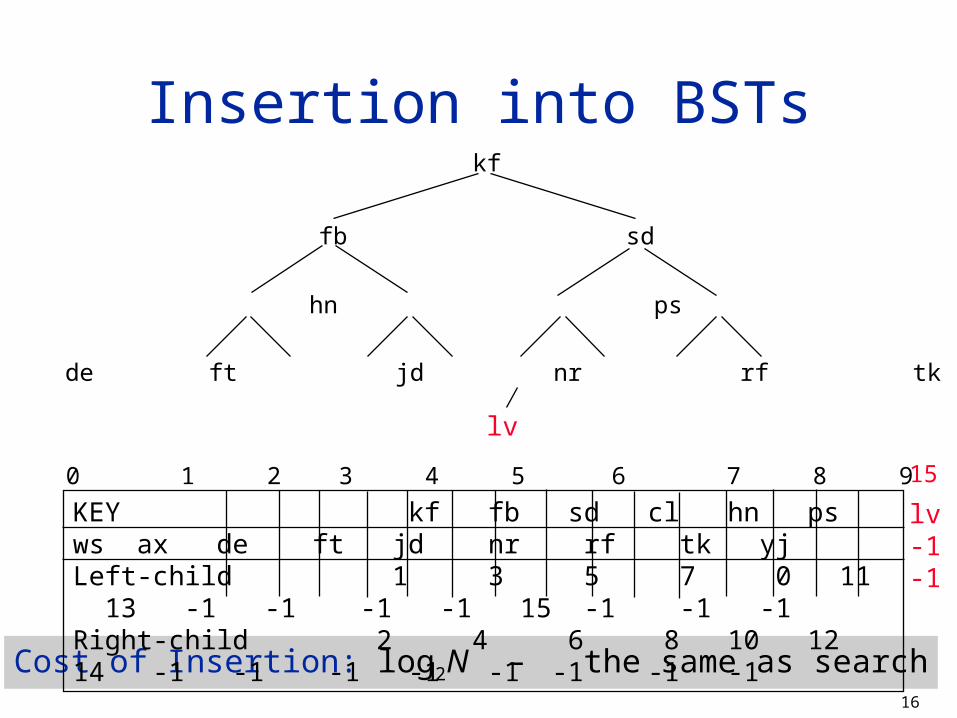
Binary Search Tree
Binary search is effective (for in memory searches) but the sorting is too expensive.
Sorting is not necessary for binary search. The purpose of sorting is to find the central item in a
part of the list, and this can be done by indexing. This can be accomplished by building a binary tree of
the keys such that left child of a node has a smaller value and the right child has a larger value.
13
Binary Search Tree
A binary tree is a tree such that Each child of a vertex is distinguished as either a left
child or a right child, and No vertex has more than one left (right) child.
A binary search tree for a set S is a labeled binary tree such that For each vertex u in the left subtree of v, u < v , For each vertex u in the right subtree of v , u > v , and For each element a in S, there exists exactly one vertex v in the tree such that a = v.
An AVL tree is a binary search tree such that the height of the two subtrees at any vertex differ by at most one
Height-balanced: there is a relationship between the number of nodes and the height of the tree In AVL trees, if there are N nodes and the height is h,
the following relationship holds
5+2 55 (1+ 5)
5 )h+ 5−2 55 (1− 5
5 )h≤N≤2h+1−1
B D
CE
F
G
A
B C G E F D A
19
AVL Tree
Features: Height balancing guarantees a certain level of search
performance [O(log2N)] Height balancing requires tree to be adjusted by
rotations – in AVL trees, the rotations are localized Performance
Solves problem #3 – index is not maintained in sorted order.
20
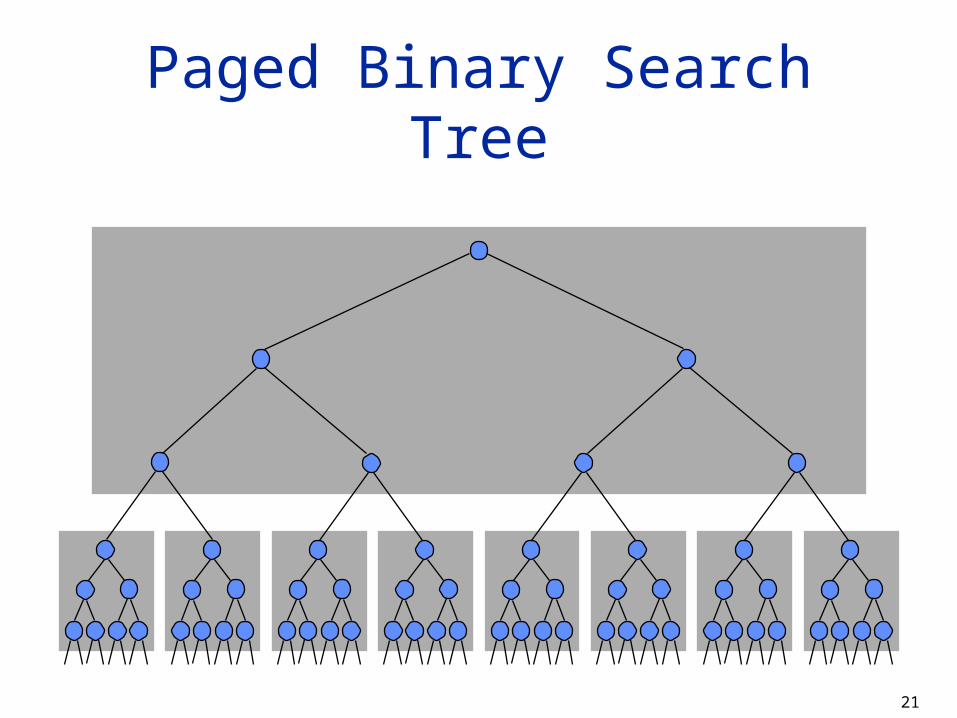
Paged Binary Search Tree Tackle the problem of high seek time/fast transfer
time by collecting indexes on pages Assuming you can store 7 indexes on a page:
63 index nodes require two levels of pages; 4 levels can accommodate 4,095 nodes (which requires
12 seeks in the case of binary search The basic idea
A balanced M-ary search tree such that both search and maintenance can be done at O(logMN)
Place a vertex and its descendants down to a fixed level (log2M) into a single page (cluster) such that the search on the whole subtree of log2M levels can be done in one disk access. Therefore, the average search and maintenance can be done at O( O(loglog2
log2 M
NM N) )=
21
Paged Binary Search Tree
22
Paged Binary Search Tree
Perspective Assume
N = 20,000,000 recordsM = 512 records.
Then logMN = log51220,000,000 = 2.69 This implies that it takes three disk accesses to retrieve
a record from a file of 20 million records. Difficulties
Balancing Maintenance cost
23
B-Trees
A B-tree of order m is a paged binary search tree such that Each page contains a maximum of m-1 keys Each page, except the root, contains at least
Root has at least 2 descedants unless it is the only node A non-leaf page with k keys has k+1 descendants All the leaves appear at the same level
Build the tree bottom-up to maintain balance Split & promotion for overflow during insertion Redistribution & concatenation for underflow during
deletion
m2
⎡ ⎢ ⎢
⎤ ⎥ ⎥ −1 keys
24
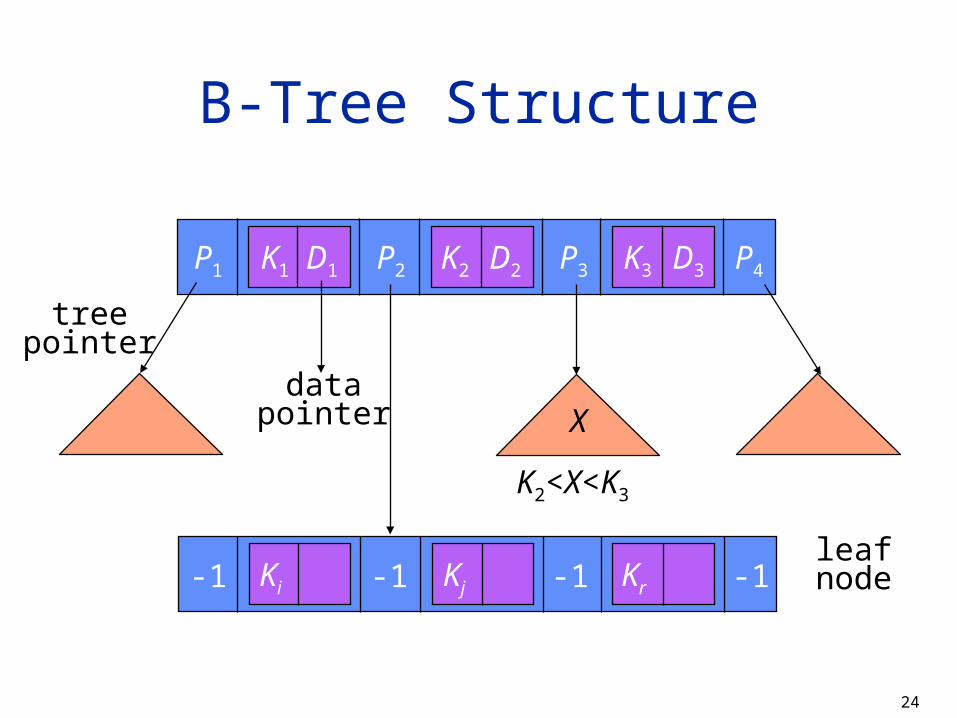
B-Tree Structure
P1 P2 P3 P4K1 K2 K3D1 D2 D3
-1 -1 -1 -1
treepointer
datapointer
Ki Kj Krleafnode
K2<X<K3
X
25
B-Tree Properties
Given a B-tree of order m Root page
1 keys m 1 2 descendents m
Other pages K1 < K1 < … < Km-1
Leaf pages all at the same level; tree pointers are null
m2⎡ ⎤−1≤ keys ≤m−1 m2⎡ ⎤≤ descendents ≤m
26
Operations
Insertion Insert the key into an appropriate leaf page (by
search) When overflow: split and promotion
Split the overflow page into two pagesPromote a key to a parent page
If the promotion in the previous step causes additional overflow, then repeat the split-promotion
27
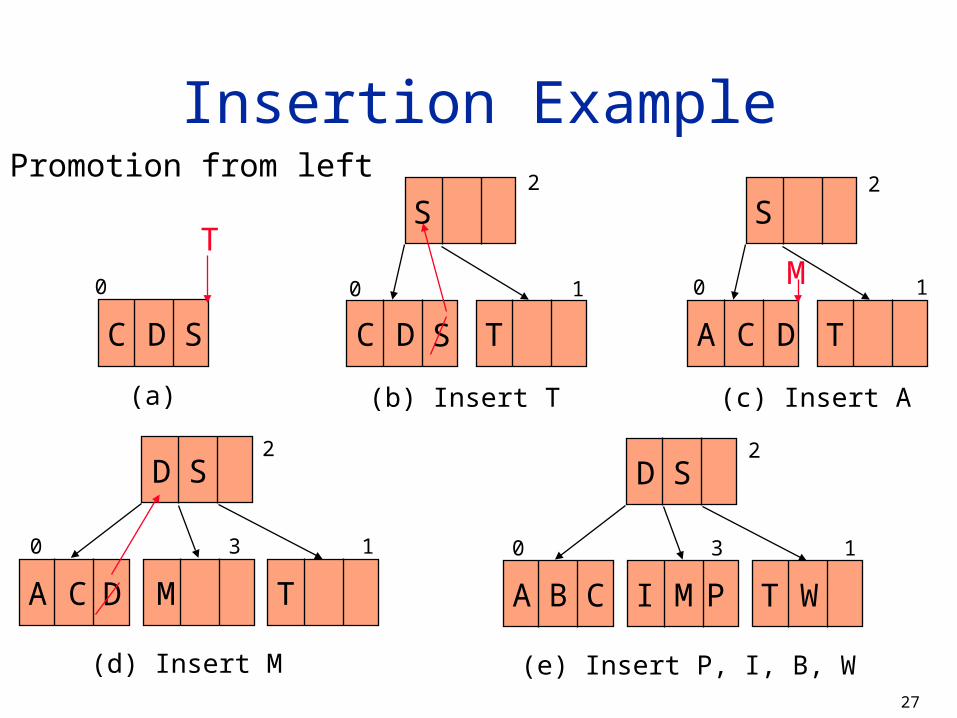
Insertion Example
(c) Insert A
(d) Insert M (e) Insert P, I, B, W
C D S
(a)
0
2
S
C D TA
2
0 1
D
C IA T
S
B M WP
2
0 3 1
Promotion from left
C D T
0 1
S
S
(b) Insert T
TM
C MA T
0 3 1
D
D2
S
28
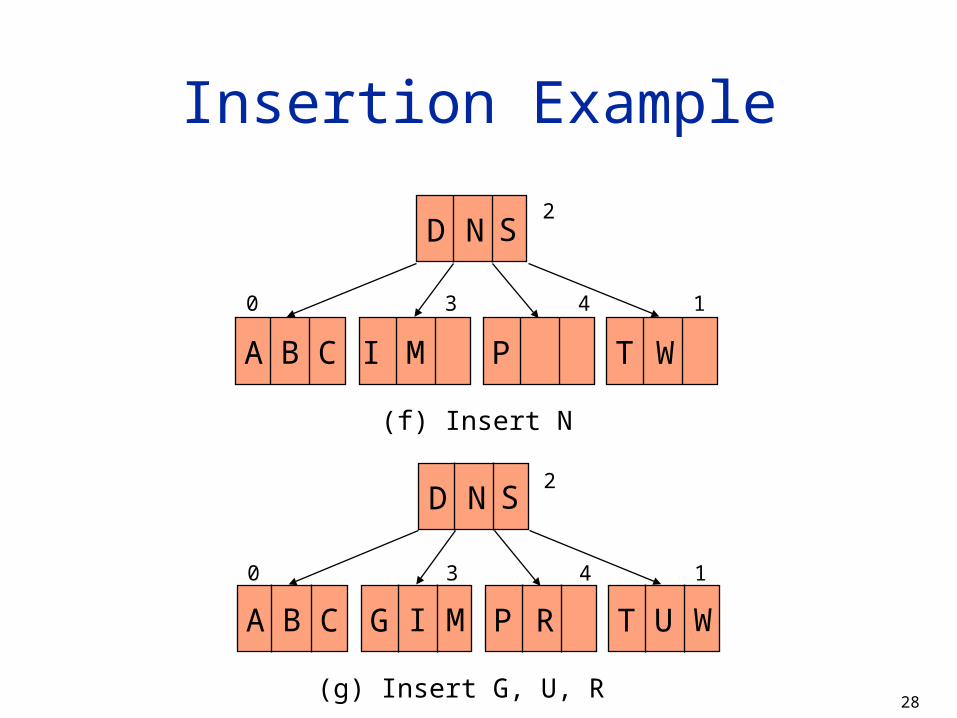
Insertion Example
(f) Insert N
(g) Insert G, U, R
D
I P
N
CA B M T W
S
0 3 4 1
2
D
G P
N
CA B I RM T U W
S
0 3 4 1
2
29
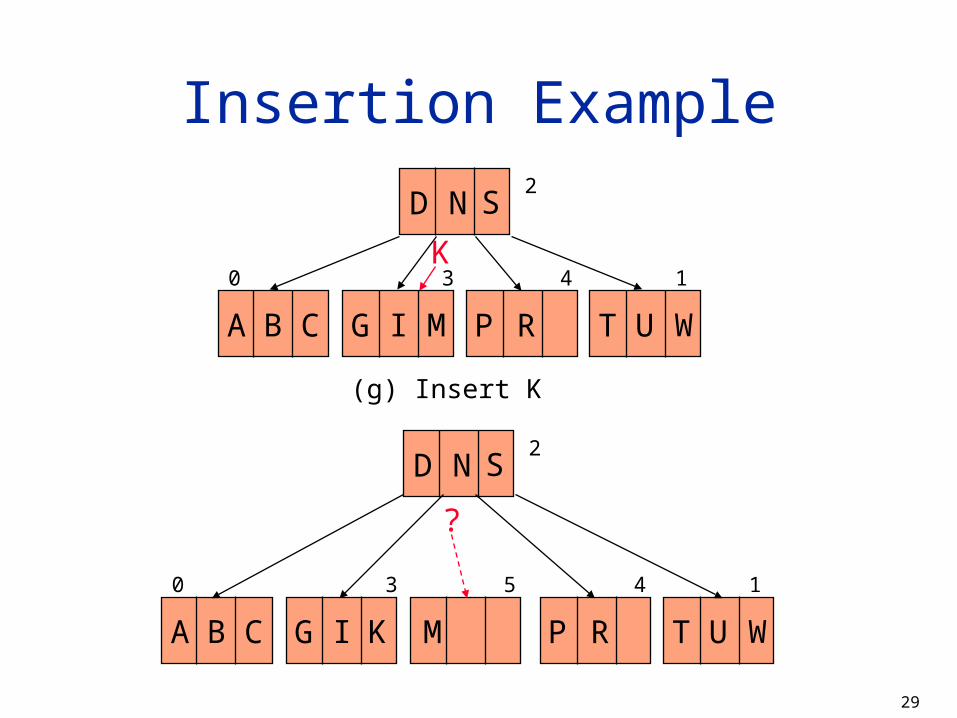
Insertion Example
(g) Insert K
D
G P
N
CA B I RM T U W
S
0 3 4 1
2
K
G MCA B I K
0 3 5
P R T U W
4 1
D N S2
?
30
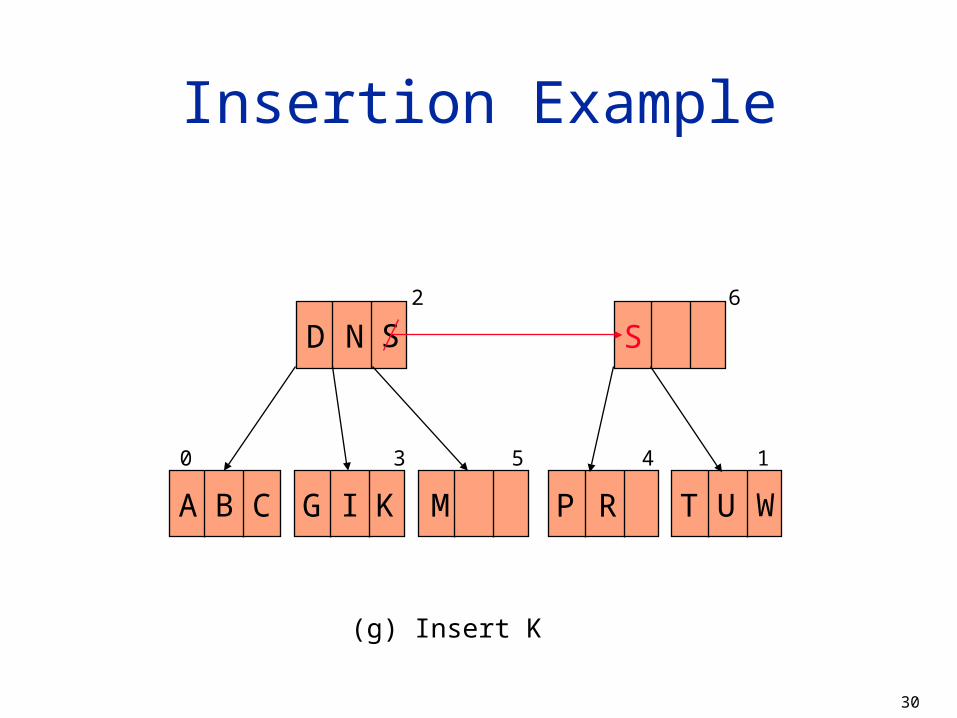
Insertion Example
(g) Insert K
0
S
G MCB I K
3 5
P R T U W
4 1
D N2 6
S
A
S
31
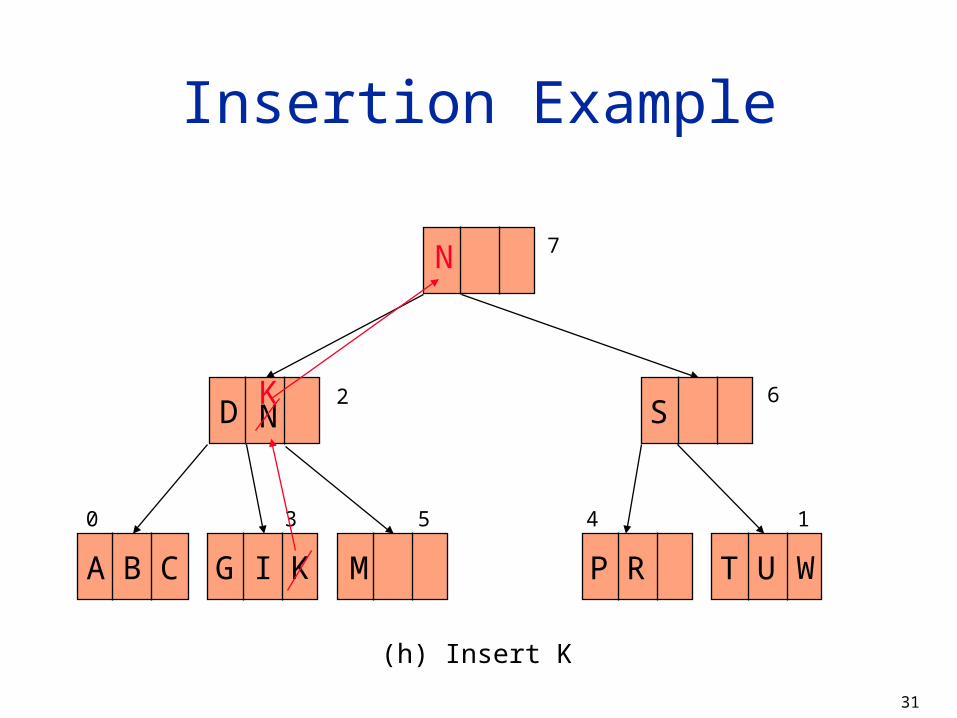
Insertion Example
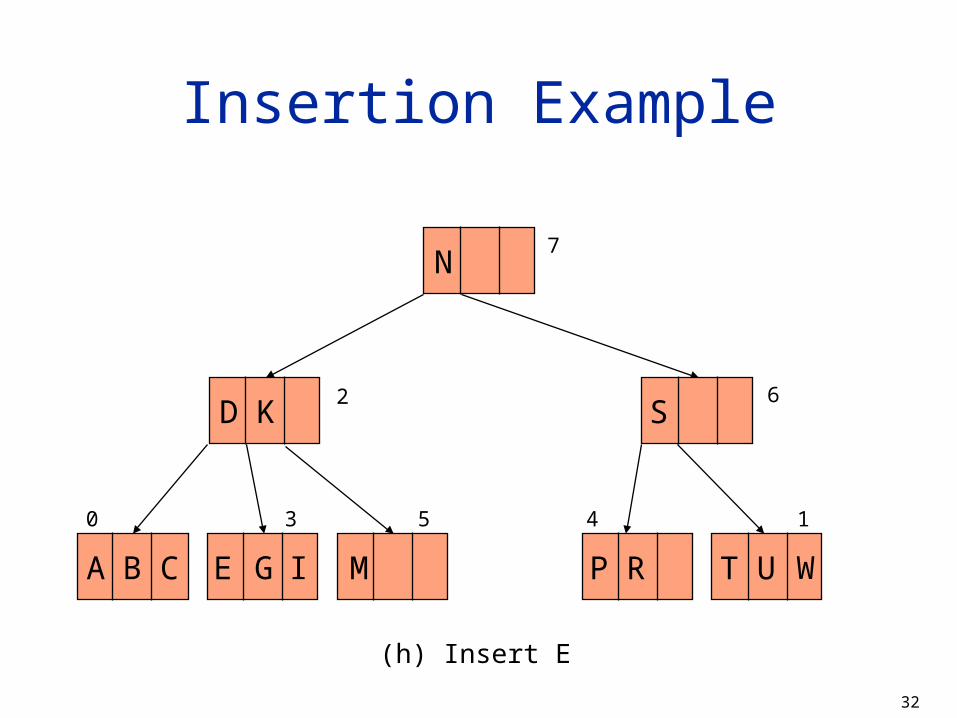
(h) Insert K
MCA B G I P R T U W
D S
K
0 3 5 4
2
1
6
7
N
N
K
32
Insertion Example
N
(h) Insert E
MCA B E G I P R T U W
D SK
0 3 5 4
2
1
6
7
33
Operations Search
Recursively traverse the tree What is the search performance?
What is the depth of the B-tree? B-tree of order m with N keys and depth d
Best case: maximum number of descendents at each node
N = md Worst case: minimal number of descendents at each node
TheoremN =2×
m2
⎡ ⎢ ⎢
⎤ ⎥ ⎥ d−1
logm(N+1) ≤d≤ logm2
⎡ ⎢ ⎢
⎤ ⎥ ⎥ (N+1
2)+1
34
Operations
Deletions Search B-tree to find the key to be deleted Swap the key with its immediate successor, if the key is
not in a leaf page Note only keys in a leaf may be deleted
When underflow: redistribution or concatenation Redistribute keys among an adjacent sibling page, the parent
page, and the underflow page if possible (need a rich sibling) Otherwise, concatenate with an adjacent page, demoting a key
from the parent page to the newly formed page.
If the demotion causes underflow, repeat redistribution-concatenation
35
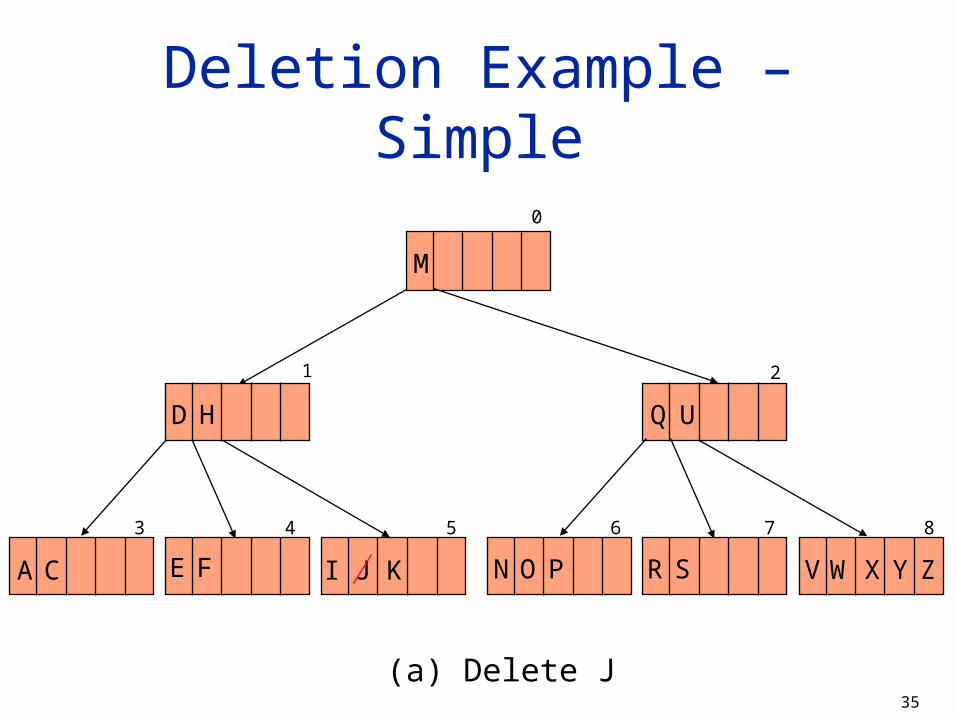
Deletion Example – Simple
3 4 5 6
1
7
2
0
H
M
D
CA FE JI K
Q U
N O P R S V W X Y Z
8
(a) Delete J
36
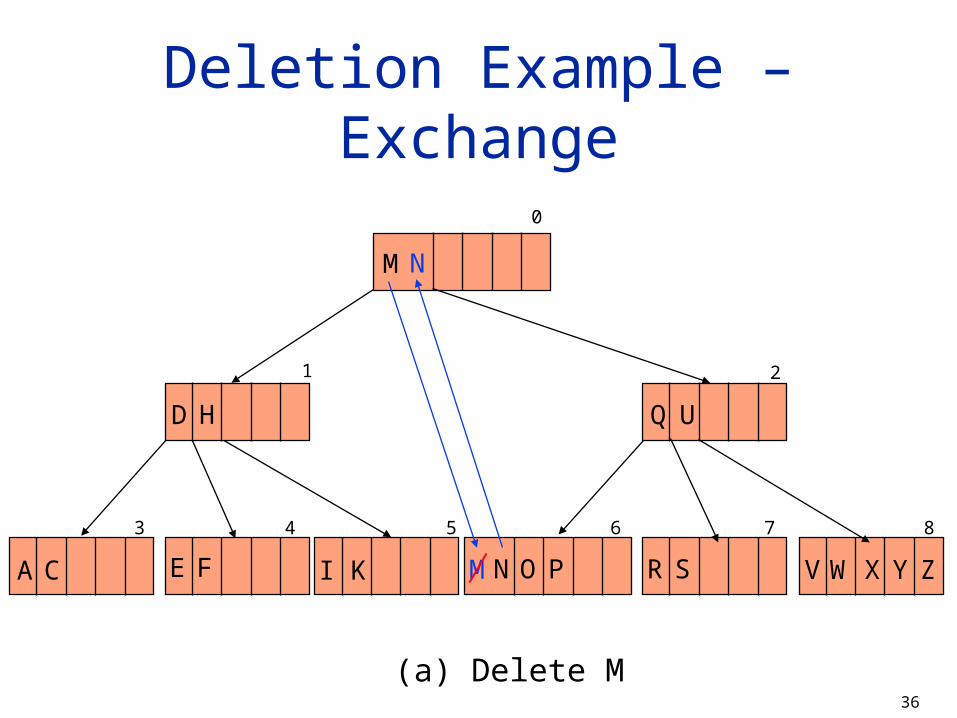
Deletion Example – Exchange
3 4 5 6
1
7
2
0
H
M
D
CA FE I K
Q U
N O P R S V W X Y Z
8
(a) Delete M
M
N
37
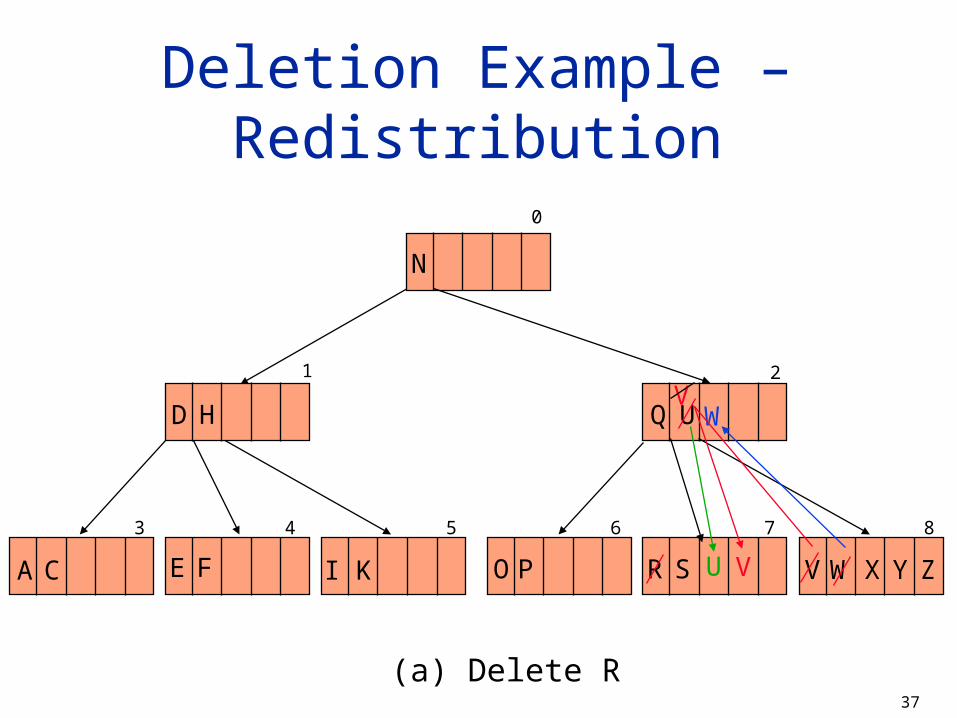
Deletion Example – Redistribution
(a) Delete R
3 4 5 6
1
7
2
0
H
N
D
CA FE I K
Q U
O P R S V W X Y Z
8
U
WV
V
38
Deletion Example – Concatenation
3 4 5 6
1
7
2
0
H
N
D
CA FE I K
Q
O P S X Y Z
8
U V
W
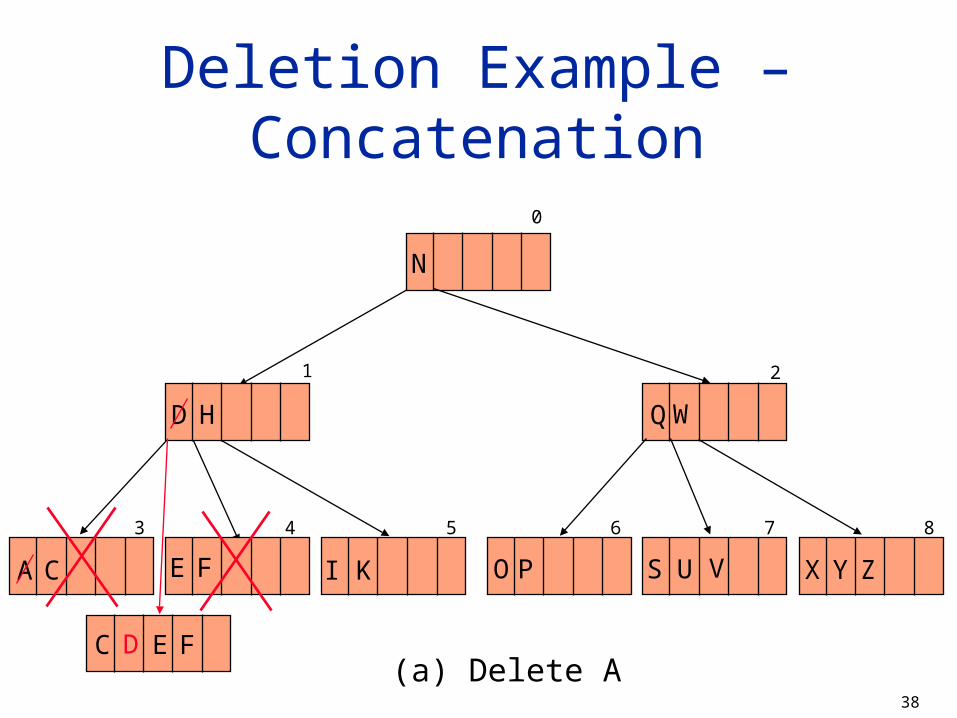
(a) Delete AC FED
39
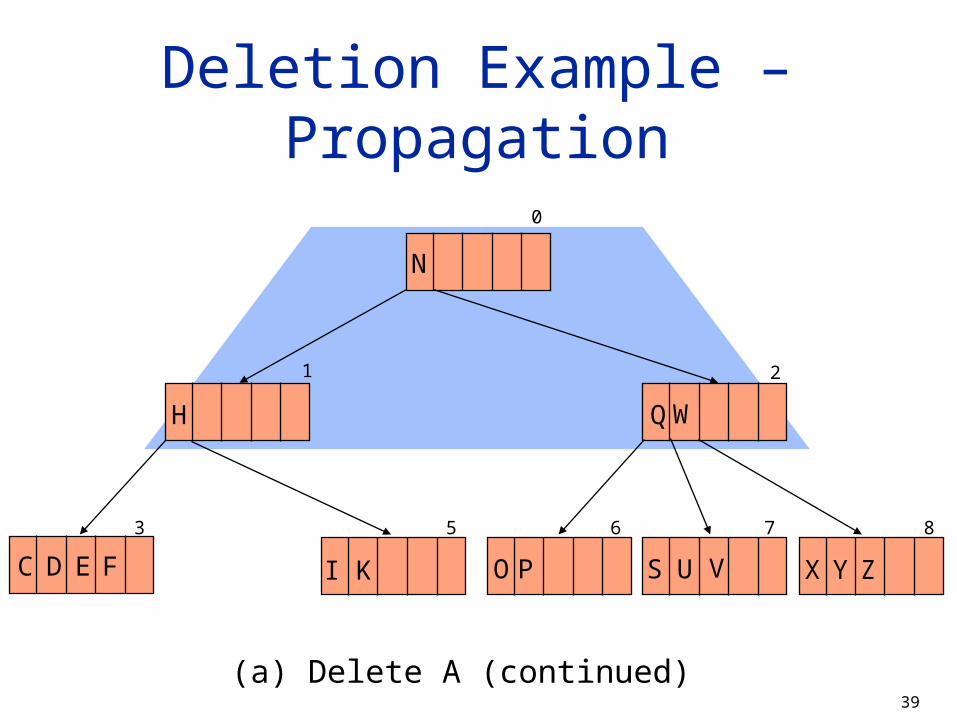
Deletion Example – Propagation
(a) Delete A (continued)
3 5 6
1
7
2
0
N
H
CA FE I K
Q
O P S X Y Z
8
U V
W
C FED
40
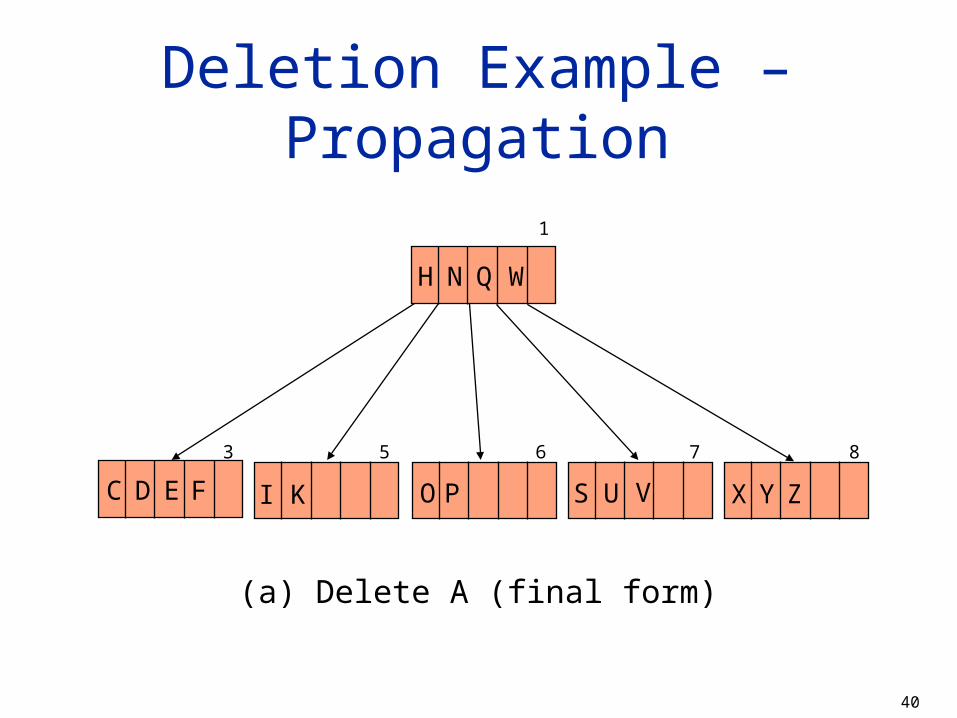
Deletion Example – Propagation
3 5 6
1
7
H
CA
FE I K
Q
O P S X Y Z
8
(a) Delete A (final form)
U V
W
C FED
N Q W
41
Improvements
Redistribution during insertion A way of avoiding, or at least, postponing the creation of a
new page by redistributing overflow keys into its sibling pages
Improve space utilization: 67% 86% B*-trees
If redistribution takes placed during insertion, at time of overflow, at least one other sibling is full
Two-to-three split Distribute all keys in two full pages into three sibling pages evenly
Each page contains at least Special handling of the root 2m−1
3⎢ ⎣ ⎢
⎥ ⎦ ⎥ keys
42
Improvements
Virtual B-trees B-trees that uses RAM page buffers Buffer strategies
Keep the root page Retain the pages of higher levels LRU (the Least Recently Uses page is the buffer is replaced
by a new page)
43
Primary problem: Efficient sequential access and indexed search
(dual mode applications) Possible solutions:
Sorted files: good for sequential accesses unacceptable performance for random access maintenance costs too high
B-trees: good for indexed search very slow for sequential accesses (tree traversal) maintenance costs low
B+ trees: a file with a B-tree structure + a sequence set
Indexed Sequential Access
44
Arrange the file into blocks Usually clusters or pages
Records within blocks are sorted Blocks are logically ordered
Using a linked list
If each block contains b records, then sequential access can be performed in N/b disk accesses
1 D, E, F, G 4 2 A, B, C 13 J, K, L, M, N -14 H, I 3
head = 2
Sequence Sets
45
Changes to blocks Goal: keep blocks at least half full
Accommodates variable length records
file updates problems solutions
insertion overflow split w/o promotion
deletion underflow redistribution concatenation
Maintenance of Sequence Sets
Choice of block sizeThe bigger the betterRestricted by size of RAM, buffer, access speed
46
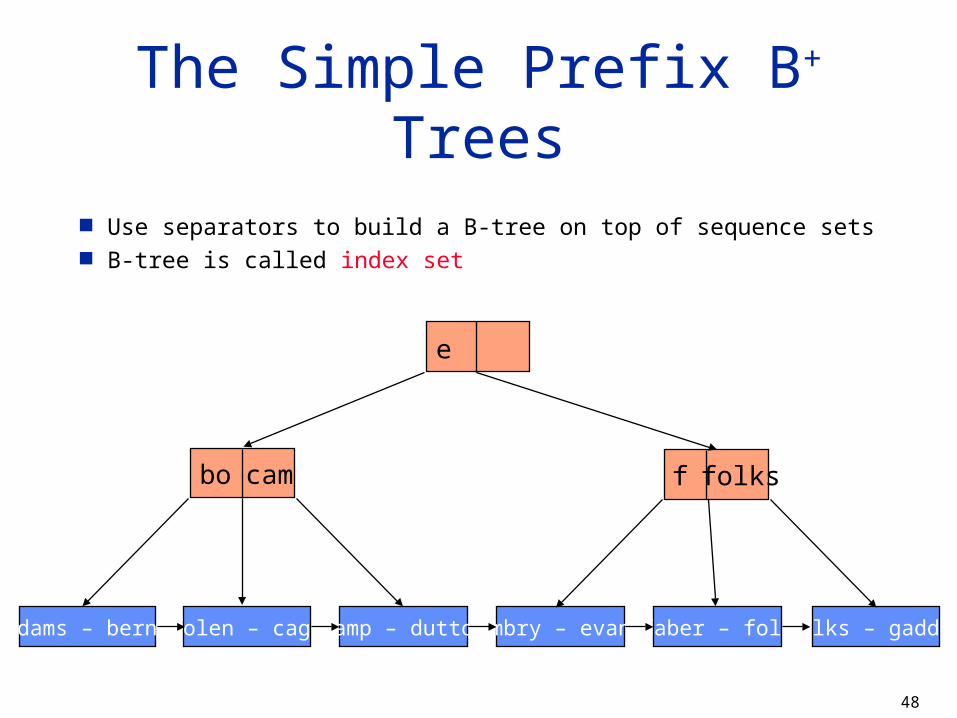
Keys of last record in each block Similar to what you find on dictionary pages Creates a one-level index Has to be able to fit memory
binary search index maintenance
Separator: a shortest string that separates keys in two consecutive blocks Increases the size of the index that can be maintained
Use separators to build a B-tree on top of sequence sets B-tree is called index set
49
Updates are first made to the sequence set and then changes to the index set are made if necessary If blocks are split, add a new separator If blocks are concatenated, remove a separator If records in the sequence set are redistributed, change the
value of the separator
Maintenance of B+ Trees
50
Index Set Maintenance
Index set block size Index node size = sequence set physical block size
Block size that is best for sequence sets is also best for index set
Easier to build virtual simple prefix B+ trees Index set blocks and sequence set blocks are intermingled in
the same file
Variable-order B-tree Separators are variable length; Can store variable
number of them in a block How to identify begin-end points of separators for