1 Lexical Analysis • Why split it from parsing? – Simplifies design • Parsers with whitespace and comments are more awkward – Efficiency • Only use the most powerful technique that works • And nothing more – No parsing sledgehammers for lexical nuts – Portability • More modular code • More code re-use
Transcript
1
Lexical Analysis
• Why split it from parsing?– Simplifies design
• Parsers with whitespace and comments are more awkward
– Efficiency• Only use the most powerful technique that works• And nothing more
– No parsing sledgehammers for lexical nuts
– Portability• More modular code • More code re-use
2
Source Code Characteristics
• Code– Identifiers
• Count, max, get_num
– Language keywords: reserved or predefined• switch, if .. then.. else, printf, return, void • Mathematical operators
– +, *, >> ….– <=, =, != …
– Literals• “Hello World”
• Comments• Whitespace
3
Reserved words versus predefined identifiers
• Reserved words cannot be used as the name of anything in a definition (i.e., as an identifier).
• Predefined identifiers have special meanings, but can be redefined (although they probably shouldn’t).
• Examples of predefined identifiers in Java:anything in java.lang package, such as String, Object, System, Integer.
4
Language of Lexical Analysis
Tokens: category
Patterns: regular expression
Lexemes:actual string matched
5
Tokens are not enough…
• Clearly, if we replaced every occurrence of a variable with a token then ….
We would lose other valuable information (value, name)
• Other data items are attributes of the tokens
• Stored in the symbol table
6
Token delimiters
• When does a token/lexeme end?
e.g xtemp=ytemp
7
Ambiguity in identifying tokens• A programming language definition will
state how to resolve uncertain token assignment
• <> Is it 1 or 2 tokens?
• Reserved keywords (e.g. if) take precedence over identifiers (rules are same for both)
• Disambiguating rules state what to do
• ‘Principle of longest substring’: greedy match
8
Regular Expressions
• To represent patterns of strings of characters• REs
– Alphabet – set of legal symbols– Meta-characters – characters with special meanings
is the empty string
• 3 basic operations– Choice – choice1|choice2,
• a|b matches either a or b– Concatenation – firstthing secondthing
• (a|b)c matches the strings { ac, bc }– Repetition (Kleene closure)– repeatme*
• a* matches { , a, aa, aaa, aaaa, ….}
• Precedence: * is highest, | is lowest– Thus a|bc* is a|(b(c*))
9
Regular Expressions…
• We can add in regular definitions– digit = 0|1|2 …|9
• And then use them:– digit digit*
• A sequence of 1 or more digits
• One or more repetitions:– (a|b)(a|b)* (a|b)+
• Any character in the alphabet .– .*b.* - strings containing at least one b
• Ranges [a-z], [a-zA-Z], [0-9], (assume character set ordering)
In JavaCC, you specifyyour tokens using regularexpression.
11
Some exercises
• Describe the languages denoted by the following regular expressions1. 0 ( 0 | 1 ) * 02. ( ( | 0 ) * ) *3. 0* 1 0* 1 0* 1 0 *
• Write regular definitions for the following regular expressions1. All strings that contain the five vowels in
order (but not necessarily adjacent) aabcaadggge is okay
2. All strings of letters in which the letters are in ascending lexicographic order
3. All strings of 0’s and 1’s that do not contain the substring 011
12
Limitations of REs• REs can describe many language constructs but not
all
• For example
Alphabet = {a,b}, describe the set of strings consisting of a single a surrounded by an equal number of b’s
S= {a, bab, bbabb, bbbabbb, …}
• For example, nested Tags in HTML
13
Lookahead
• <=, <>, <
• When we read a token delimiter to establish a token we need to make sure that it is still available as part of next token
– It is the start of the next token!
• This is lookahead
– Decide what to do based on the character we ‘haven’t read’
• Sometimes implemented by reading from a buffer and then pushing the input back into the buffer
• And then starting with recognizing the next token
14
Classic Fortran example
• DO 99 I=1,10 becomes DO99I=1,10 versus
DO99I=1.10 The first is a do loop, the second an assignment.
We need lots of lookahead to distinguish.• When can the lexical analyzer assign a token?Push back into input buffer
– or ‘backtracking’
15
Finite Automata
• A recognizer determines if an input string is a sentence in a language
• Uses a regular expression• Turn the regular expression into a finite
automaton• Could be deterministic or non-
deterministic
16
Transition diagram for identifiers
• RE – Identifier -> letter (letter | digit)*
start 0 letter
letter
digit
other1 2accept
17
• An NFA is similar to a DFA but it also permits multiple transitions over the same character and transitions over . In the case of multiple transitions from a state over the same character, when we are at this state and we read this character, we have more than one choice; the NFA succeeds if at least one of these choices succeeds. The transition doesn't consume any input characters, so you may jump to another state for free.
• Clearly DFAs are a subset of NFAs. But it turns out that DFAs and NFAs have the same expressive power.
18
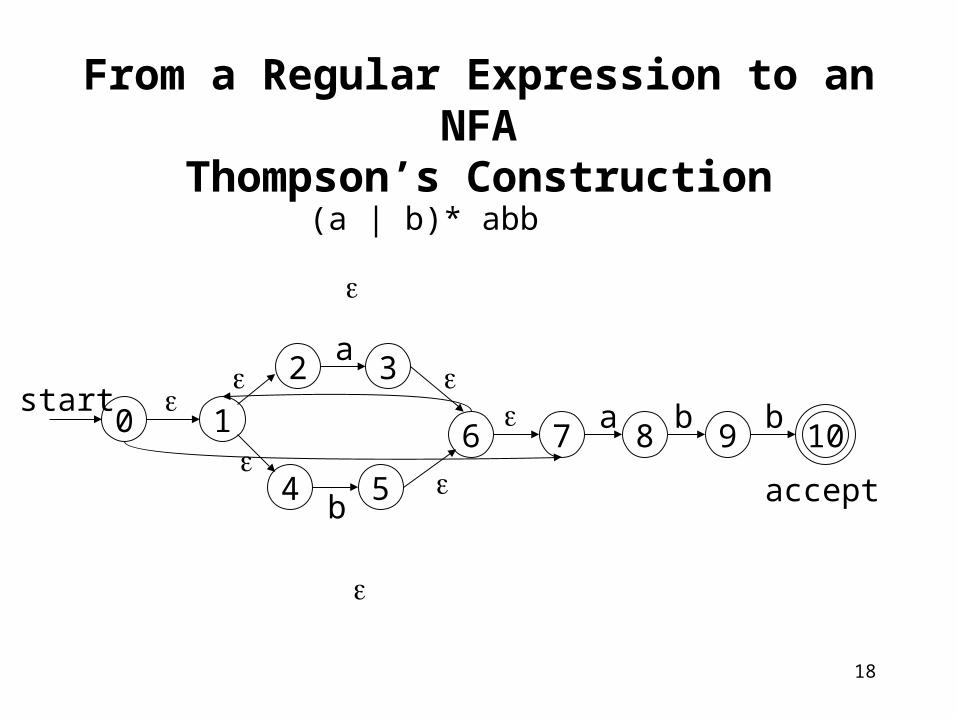
From a Regular Expression to an NFA
Thompson’s Construction(a | b)* abb
0
2
76
3
1
4 5
1098
accept
start
a
b
a b b
19
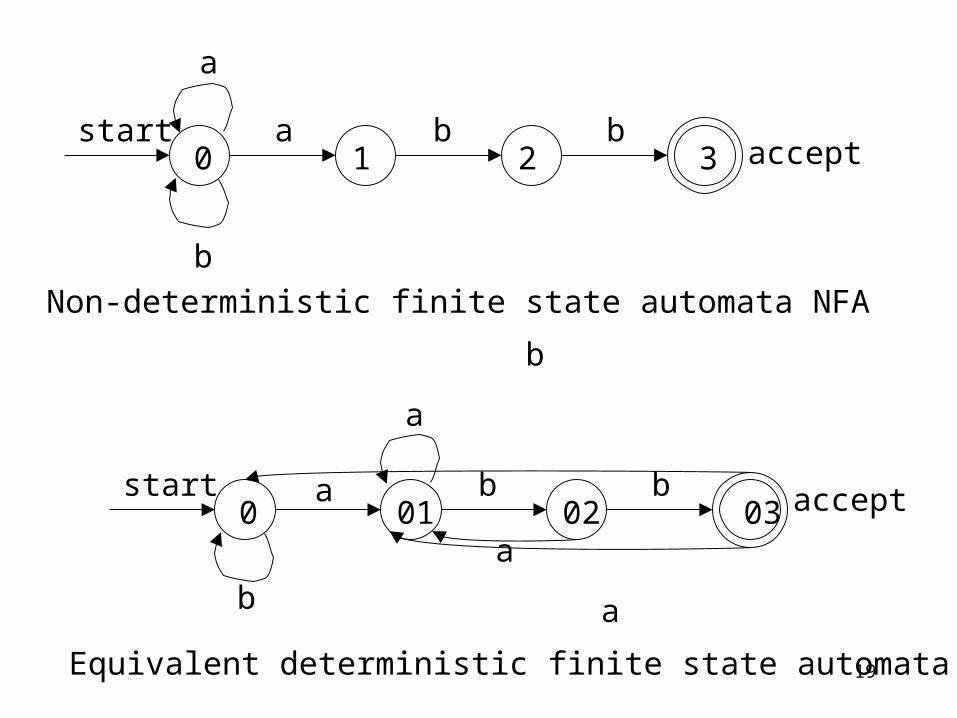
start a
a
b
b b0 1 2 3
Non-deterministic finite state automata NFA
start a
a
b b0 01 02 03
b a
a
b
Equivalent deterministic finite state automata DFA
accept
accept
20
NFA -> DFA (subset construction)
• We can covert from an NFA to a DFA using subset construction.• To perform this operation, let us define two functions: • The -closure function takes a state and returns the set of
states reachable from it based on (one or more) -transitions. Note that this will always include the state tself. We should be able to get from a state to any state in its -closure without consuming any input.
• The function move takes a state and a character, and returns the set of states reachable by one transition on this character.
• We can generalize both these functions to apply to sets of states by taking the union of the application to individual states.
• Eg. If A, B and C are states, move({A,B,C},`a') = move(A,`a') move(B,`a') move(C,`a').
21
NFA -> DFA (cont)
• The Subset Construction Algorithm • Create the start state of the DFA by taking the -closure
of the start state of the NFA. • Perform the following for the new DFA state:
For each possible input symbol: – Apply move to the newly-created state and the input
symbol; this will return a set of states. – Apply the -closure to this set of states, possibly resulting
in a new set. • This set of NFA states will be a single state in the DFA. • Each time we generate a new DFA state, we must apply
step 2 to it. The process is complete when applying step 2 does not yield any new states.
• The finish states of the DFA are those which contain any of the finish states of the NFA.
22
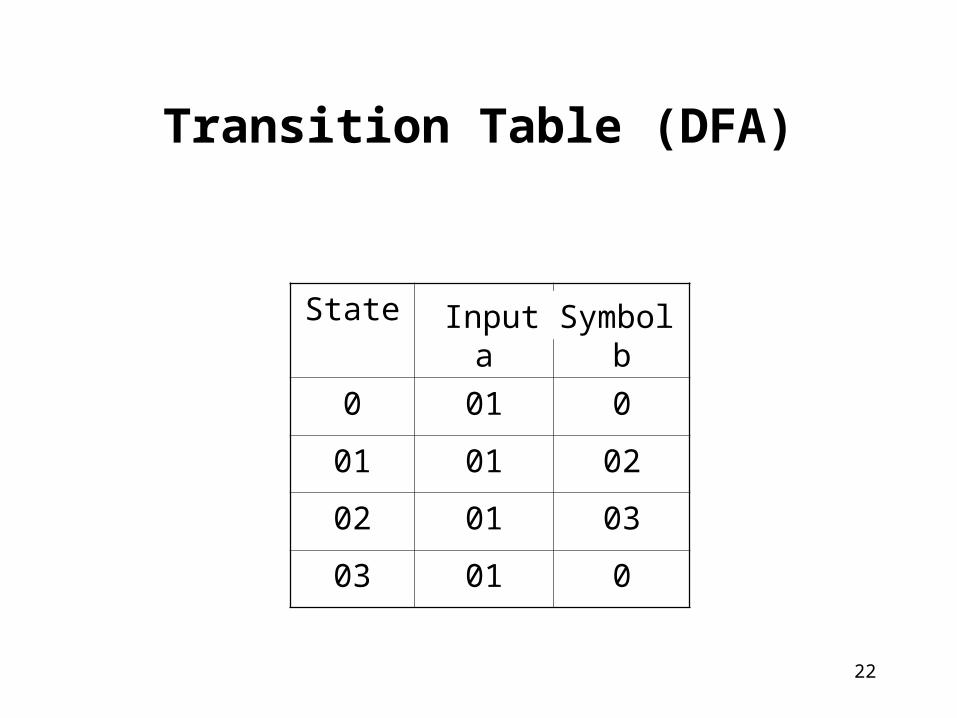
Transition Table (DFA)
Statea b
0 01 0
01 01 02
02 01 03
03 01 0
Input Symbol
23
Writing a lexical analyzer
• The DFA helps us to write the scanner. • Figure 4.1 in your text gives a good
example of what a scanner might look like.
24
LEX (FLEX)
• Tool for generating programs which recognize lexical patterns in text
• Takes regular expressions and turns them into a program
25
Lexical Errors
• Only a small percentage of errors can be recognized during Lexical Analysis
Consider if (good == “bad)
26
– Line ends inside literal string – Illegal character in input file – missing semi-colon– missing operator– missing paren– unquoted string– unopened file handle
Examples from the PERL language
27
In general
• What does a lexical error mean?
• Strategies for dealing with:
– “Panic-mode”
• Delete chars from input until something matches
– Inserting characters
– Re-ordering characters
– Replacing characters
• For an error like “illegal character” then we should report it sensibly
28
Syntax Analysis
• also known as Parsing
• Grouping together tokens into larger structures
• Analogous to lexical analysis
• Input:
– Tokens (output of Lexical Analyzer)
• Output:
– Structured representation of original program
29
A Context Free Grammar
• A grammar is a four tuple (, N,P,S) where
is the terminal alphabet • N is the non terminal alphabet • P is the set of productions • S is a designated start symbol in N
30
Parsing• Need to express series of added operands• Expression number plus Expression | number
– Similar to regular definitions:• Concatenation• Choice• No Kleene closure – repetition by recursion
Expression number Operator Expression
operator + | - | * | /
31
BNF Grammar
Operator + | - | * | /
Meta-symbols: |
Expression number Operator number
Structure on the left is defined to consist of the choiceson the right hand side
Expression number Operator number
Different conventions for writing BNF Grammars:
<expression> ::= number <operator> number
32
Derivations• Derivation:
– Sequence of replacements of structure names by choices on the RHS of grammar rules
– Begin: start symbol– End: string of token symbols– Each step one replacement is made
Exp Exp Op Exp | number
Op + | - | * | /
33
Example Derivation
Note the different arrows:
Derivation applies grammar rules
Used to define grammar rules
Non-terminals: Exp, Op Terminals: number, *
Terminals: because they terminate the derivation
34
• E ( E ) | a
• What sentences does this grammar generate?
An example derivation: • E ( E ) ((E)) ((a))• Note that this is what we couldn’t
achieve with regular definitions
35
Recursive Grammars
– At seats, try using grammar to generate– anbn
• E E | – derives , , , , ….– All strings beginning with followed by zero
or more repetitions of *
36
Given the grammar rules shown below, derive the sentence This is the house that Jack built. Draw the parse tree, labeling your subtrees with the numbers of the grammar rules used to derive them.
• Grammar rules: • S → NP VP• NP → NP REL S | PRO | N | ART N | NAME• VP → V | V NP• N → house• PRO →this |that• REL→ that• ART→ the• V→ built | is• NAME → Jack
Which is easier – bottom up or top down?
37
Parse Trees & Derivations
• Leafs = terminals• Interior nodes = non-terminals• If we replace the non-terminals right to
left– The parse tree sequence is right to left– A rightmost derivation -> reverse post-
order traversal
• If we derive left to right:– A leftmost derivation– pre-order traversal– parse trees encode information about the
derivation process
38
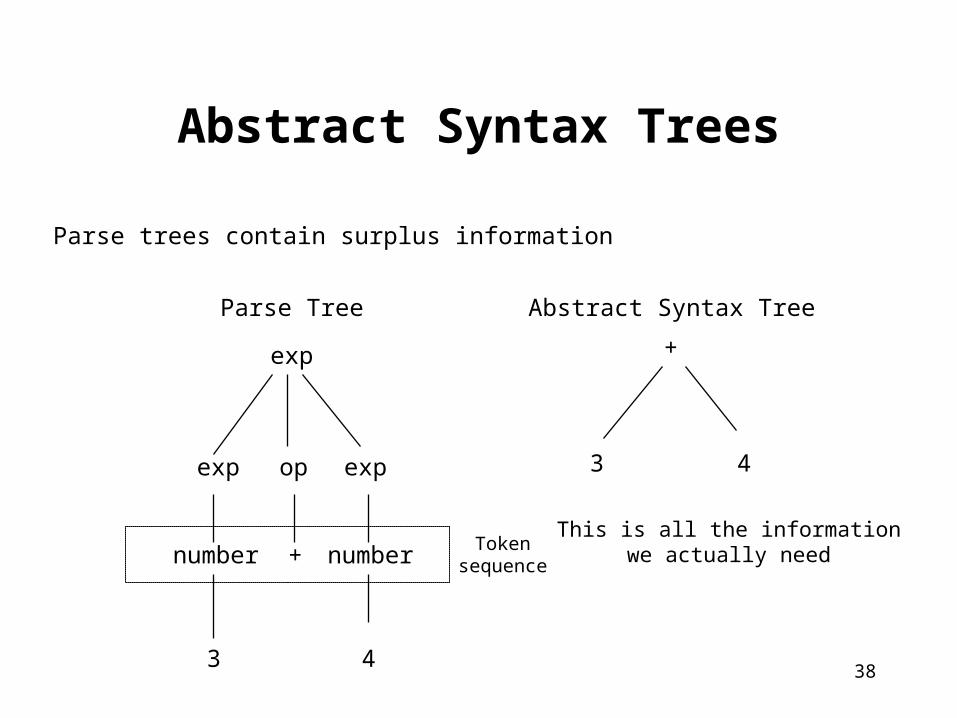
Abstract Syntax Trees
exp
exp
expop
3
+
4
Parse Tree
+
3 4
Abstract Syntax Tree
number number Tokensequence
This is all the informationwe actually need
Parse trees contain surplus information
39
An exercise
• Consider the grammar S->(L) | aL->L,S |S
(a) What are the terminals, nonterminals and start symbol(b) Find leftmost and rightmost derivations and parse trees
for the following sentencesi. (a,a)ii. (a, (a,a))iii. (a, ((a,a), (a,a)))
40
Parsing token sequence: id + id * id
E E + E | E * E | ( E ) | - E | id
How many ways can you find a tree which matches the expression?
41
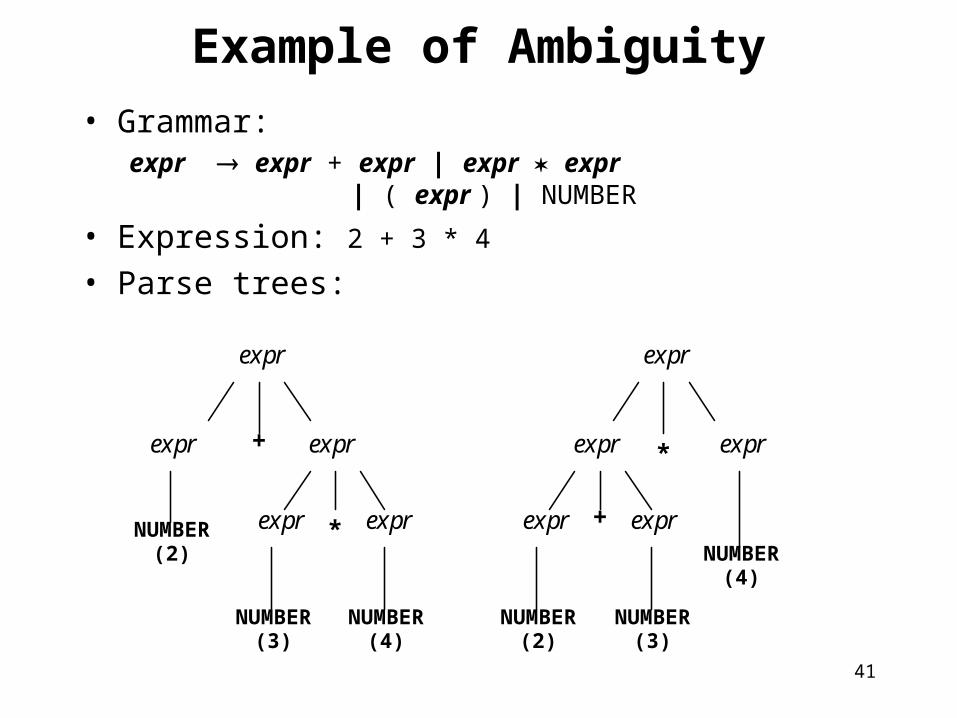
Example of Ambiguity• Grammar:
expr expr + expr | expr expr | ( expr ) | NUMBER
• Expression: 2 + 3 * 4
• Parse trees:
expr
expr expr
expr
+
* expr
expr
expr
+
* expr
expr expr NUMBER (2)
NUMBER (3)
NUMBER (4)
NUMBER (2)
NUMBER (3)
NUMBER (4)
42
Ambiguity
• If a sentence has two distinct parse trees, the grammar is ambiguous
• Or alternatively:is ambiguous if there are two different right-most derivations for the same string.
• In English, the phrase ``small dogs and cats'' is ambiguous as we aren't sure if the cats are small or not.
• `I see flying planes' is also ambiguous • A language is said to be ambiguous if no
unambiguous grammar exists for it. • Dance is at the old main gym. How it is parsed?
43
Ambiguous Grammars• Problem – no clear structure is expressed• A grammar that generates a string with 2 distinct
parse trees is called an ambiguous grammar
– 2+3*4 = 2 + (3*4) = 14– 2+3*4 = (2+3) * 4 = 20
• How does the grammar relate to meaning?• Our experience of math says interpretation
1 is correct but the grammar does not express this:
– E E + E | E * E | ( E ) | - E | id
44
Removing AmbiguityTwo methods1. Disambiguating RulesThe basic notion is to write grammar rules of the
form • expr : expr OP expr and • expr : UNARY expr for all binary and unary
operators desired. • This creates a very ambiguous grammar with
many parsing conflicts. • You specify as disambiguating rules the
precedence of all the operators and the associativity of the binary operators.
positives: leaves grammar unchangednegatives: grammar is not sole source of syntactic
knowledge
45
Removing AmbiguityTwo methods
2. Rewrite the Grammar
Using knowledge of the meaning that we want to use later in the translation into object code to guide grammar alteration
46
• Sometimes we can remove ambiguity from a grammar by by restructuring the productions, but sometimes the language is inherently ambiguous.
• For example, L={aibjck|i=j or j=k for i,j,k>=1}• An ambiguous grammar to generate
this language is shown below:
47
Precedence
E E addop Term | TermAddop + | -Term Term * Factor | Term/Factor |FactorFactor ( exp ) | number | id
• Operators of equal precedence are grouped together at the same ‘level’ of the grammar ’precedence cascade’
• The lowest level operators have highest precedence
• (The first shall be last and the last shall be first.)
48
Associativity
• 45-10-5 ?
30 or 40Subtraction is left associative, left to right (=30)
• E E addop E | TermDoes not tell us how to split up 45-10-5
• E E addop Term | TermForces left associativity via left recursion
• Precedence & associativity remove ambiguity of arithmetic expressions
– Which is what our math teachers took years telling us!
49
Extended BNF Notation
• Notation for repetition and optional features.• {…} expresses repetition:
expr expr + term | term becomes expr term { + term }
• Use {…} only for left recursive rules:expr term + expr | termshould become expr term [ + expr ]
• Do not start a rule with {…}: writeexpr term { + term }, notexpr { term + } term
• Exception to previous rule: simple token repetition, e.g. expr { - } term …• Square brackets can be used anywhere, however:
expr expr + term | term | unaryop termshould be written asexpr [ unaryop ] term { + term }
51
Syntax Diagrams
• An alternative to EBNF.• Rarely seen any more: EBNF is much
more compact.• Example (if-statement, p. 101):
if-statement expression
statement
if ( )
else statement
52
Formal Methods of Describing Syntax• 1950: Noam Chomsky (noted linguist) described generative
devices which describe four classes of languages (in order of decreasing power)
• recursively enumerable x y where x and y can be any string of nonterminals and terminals.
• context-sensitive x y where x and y can be string of terminals and non-terminals but y must be the same length or longer than x. – Can recognize anbncn
• context-free (yacc) - nonterminals appear singly on left-side of productions. Any nonterminal can be replaced by its right hand side regardless of the context it appears in. – Ex: If you were in the boxing ring and said ``Hit me'' it would imply
a different action than if you were playing cards. – Ex: If a IDENTSY which is between brackets is treated differently in
terms of what it matches than an IDENTSY between parens, this is context sensitive
– Can recognize anbn, palindromes • regular (lex)
– Can recognize anbm
Chomsky was interested in the theoretic nature of natural languages.
53
Context Sensitive
• Allows for left hand side to be more than just a single non-terminal. It allows for “context”
• Context - sensitive : context dependentRules have the form xYz->xuz with Y being a non-terminal and x,u,z being terminals or non-terminals.
54
.
Consider the following context sensitive grammar G=(S,B,C,x,y,z,P,S) where P are 1.S xSBC 2.S xyC 3.CB BC 4.yB yy 5.yC yz 6.zC zz
At seats, what strings does this generate?
55
How is Parsing done?
1. Recursive descent (top down).2. Bottom up – tries to match input with
the right hand side of a rule. Sometimes called shift-reduce parsers.
56
Predictive Parsing• Which rule to use?• I need to generate a symbol, which
rule?• Top down parsing• LL(1) parsing• Table driven predictive parsing (no
recursion) versus recursive descent parsing where each nonterminal is associated with a procedure call
• No backtracking
E -> E + T | TT -> T * F | FF -> (E) | id
57
Two grammar problems1. Eliminating left recursion
(without changing associativity) E-> E+a|a
I can’t tell which rule to use as both generate same symbol
2. removing two rules with same prefix E->aB|aC
I can’t tell which rule to use as both generate same symbol
58
Removing Left Recursion
Before• A --> A x• A --> y After• A --> yB• B --> x B • B -->
59
Removing common prefix (left factoring)
Stmt -> if Exp then Stmt else Stmt | if Expr then Stmt
Change so you don’t have to pick rule until laterBefore:
A -> 1 | 2
After:
A -> A’
A’ -> 1 | 2
60
Exercises
Eliminate left recursion from the following grammars.a) S->(L) | a
L->L,S | S
b) Bexpr ->Bexpr or Bterm | BtermBterm -> Bterm and Bfactor | BfactorBfactor -> not Bfactor | (Bexpr) | true | false
61
Table Driven Predictive Parsing
a + b $
Predictive ParsingProgram
Parsing Table
Output
Stack
Input
X
Y
Z
$
id + id * id
Partial derivationNot yet matched
62
Table Driven Predictive Parsing
NonTerminal
Input Symbol
id + ( ) $
E
E’
T
T’
F
E->TE’
E’->+TE’
E->TE’
E’-> E’->
T->FT’
T’-> T’-> T’->
F->id F->(E)
T’->*FT’
T->FT’
*
Use parse table to derive: a*(a+a)*a
63
Table Driven Predictive Parsing
Parse id + id * id
Leftmost derivation and parse tree using the grammar
E -> TE’E’ -> +TE’ | T -> FT’T’ -> *FT’ | F -> (E) | id
64
But where did the parse table come from?
First and Follow Sets• First and Follow sets tell when it is
appropriate to put the right hand side of some production on the stack.
(i.e. for which input symbols)
E -> TE’E’ -> +TE’ | T -> FT’T’ -> *FT | F -> (E) | id
id + id * id
65
First Sets1. If X is a terminal, then FIRST(X) is {X}
2. IF X -> is a production, then add to FIRST(X)
3. IF X is a non terminal and X -> Y1Y2…Yk is a
production, then place a in FIRST(X) if for some i, a is in FIRST(Yi), and is in all of First(Y1), …
First(Yi-1). If is in FIRST(Yj) for all j = 1, 2, …k,
then add to FIRST(X).
E -> E + T | TT -> T * F | FF -> (E) | id
Get rid of left recursion
Left FactorE -> TE’ E’->+TE’|єT -> FT’T’->*FT’ |єF -> (E) | id
66
At seats – what are the FIRST sets
E -> TE’E’ -> +TE’ | T -> FT’T’ -> *FT | F -> (E) | id
67
Follow Sets1. Place $ in FOLLOW(S), where S is the start
symbol and $ is the input right endmarker
2. If there is a production A -> B, then everything in FIRST() except for is placed in FOLLOW(B). Notice that can be a combination of terminals and non-terminals. You need to compute FIRST
using your rules.
3. For each production A -> B or A -> B where FIRST() contains (i.e., ), then everything in FOLLOW(A) is in FOLLOW(B)
68
At seats – what are Follow Sets
E -> TE’E’ -> +TE’ | T -> FT’T’ -> *FT | F -> (E) | a
69
• First E = { a ( } • First E' = {+ } • First T = { a ( } • First T' = {* } • First F = { a ( } • Follow E = { ) $} • Follow E' = { ) $} • Follow T = {+ ) $ } • Follow T' = {+ ) $ } • Follow F = {+ * ) $ }
70
FIRST and FOLLOW sets
Construct first and follow sets for the following grammar after left recursion has been eliminated
a) S->(L) | aL->L,S | S
71
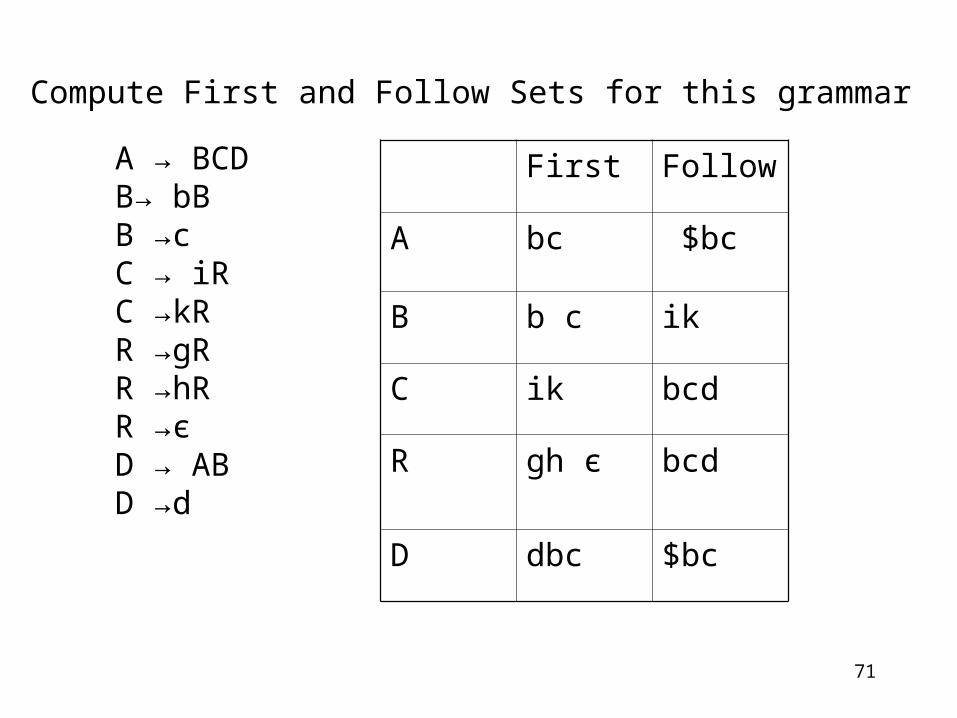
Compute First and Follow Sets for this grammar
A → BCDB→ bBB →cC → iRC →kRR →gRR →hRR →єD → ABD →d
First Follow
A bc $bc
B b c ik
C ik bcd
R gh є bcd
D dbc $bc
72
b c d g h i k $
A
B
C
R
D
73
Construction of the Predictive
Parsing Table For each production A -> of the grammar do
a. For each terminal a in FIRST(), add A -> to M[A,a]. Note that you are asked to find the FIRST of the whole right hand side (but you have only computed FIRST for non-terminals).
b. If is in FIRST(), add A -> to M[A, b] for each terminal b in FOLLOW(A). If is in FIRST() and $ is in FOLLOW(A), add A -> to M[A, $].
Make each undefined entry of M be error
74
First E = { a ( } First E' = {+ } First T = { a ( } First T' = {* } First F = { a ( }
• An LL(1) grammar has no multiply defined entries in its parsing table
• Left-recursive and ambiguous grammars are not LL(1)
• A grammar G is LL(1) iff whenever A -> | are two distinct productions of G1. For no terminal a do both and derive strings beginning
with a2. At most one of and can derive the empty string3. If then does not derive any string beginning with a
terminal in FOLL0W(A)
*
77
Recursive Descent Parsers
• A function for each nonterminal
example expression grammar
Function ExprIf the next input symbol is a ( or id then
call function Term followed by function Expr’Else Error
Expr -> Term Expr’Expr’ -> +Term Expr’ | Term -> Factor Term’Term’ -> *Factor Term’ | Factor -> (Expr) | id
78
Bottom Up Parsing
• The correct RHS in a given right sentential form to rewrite to get the previous right sentential form, is called a handle.
• Consider the following grammar:• EE + T|T • T T * F |F • F (E) |a• • Show the rightmost derivation for a+a*a • E E + T
E + T*F E + T*a E + F*a E + a*a T + a*a F + a*a a + a*a
79
•Now, start at the last step of the rightmost derivation and go backwards. •This is what we are trying to do with a bottom up parser. •We need to first determine that the a becomes an F, then that the F becomes a T, etc. •In order to do bottom up parsing, we will rewrite the grammar only slightly so we can distinguish between the two productions shown on the same line. And we will give the productions numbers so we can refer to them1. EE + T2. E T3. T T * F4. TF 5. F (E)6. Fa
80
• The parsing table is generated by a tool like YACC, and the generation is beyond the scope of this course. However, we need to be able to use the parsing table. We want to read the input one symbol at a time and make a decision as to what to do, given a history of what we have done in the past. We have a parse stack to help us remember these important details. As we look at an input, there are only two choices of actions we take:
• We read the input and shift it over to our stack along with a “state”. Thus, the action S4 means to shift the current symbol to the stack and then push the state 4 to the stack.
• We look at the input and decide not to delete it from the input. Instead, we look at the top symbols of our stack and remove some and place others on. This step is called a reduce step.
81
• The number of the reduce does NOT refer to a state. It refers to the production which you use. For R5 (for example), the steps are as follows:
– Look at production 5 F(E). In our case, there are three symbols on the right hand side. This means for us to remove three sets of symbols from our stack.
– You should see a “(“, an “E”, and a “)” (along with their states) on the top of the stack. Remove these.
– They want to become an F (going backwards on the production).
– Before you place the F on the stack, look at the exposed state on the stack. Use that exposed state and F to determine the new state (using the Goto part of the table).
– That new state is then placed after F on the stack.