43
1 Parallel Applications 15-740 Computer Architecture Ning Hu, Stefan Niculescu & Vahe Poladian November 22, 2002
| Date post: | 02-Jan-2016 |
| Category: |
Documents |
| Upload: | cathleen-willis |
| View: | 218 times |
| Download: | 2 times |

1
Parallel Applications
15-740
Computer Architecture
Ning Hu, Stefan Niculescu & Vahe Poladian
November 22, 2002

2
Papers surveyed
Application and Architectural Bottlenecks in Distributed Shared Memory Multiprocessors by Chris Holt, Jaswinder Pal Singh and John Hennessy
Scaling Application Performance on a Cache-coherent Multiprocessor by Dongming Jiang and Jaswinder Pal Singh
A Comparison of the MPI, SHMEM and Cache-coherent Shared Address Space Programming Models on the SGI Origin2000 by Hongzhang Shan and Jaswinder Pal Singh

Application and Architectural Bottlenecks in Distributed
Shared Memory Multiprocessors

4
Question
Can realistic applications achieve reasonable performance on large scale DSM machines?
Problem Size
Programming effort and Optimization
Main architectural bottlenecks

5
Metrics
Minimum problem size to achieve a desired level of parallel efficiency
Parallel Efficiency >= 70%
Assumption: Problem size↗Performance ↗
Question: Is the assumption always true? Why or Why not?
usedProcessorsofNumber
tionImplementaSequentialoverSpeedupEfficiencyParallel

6
Programming Difficulty and Optimization
Techniques already employed
Balance the workload
Reduce inherent communication
Incorporate major form of data locality(temporal and/or spatial)
Further optimization
Place the data appropriately in physically distributed memory instead of allowing pages of data to be placed round-robin across memories
Modify major data structures substantially to reduce unnecessary communication and to facilitate proper data placement
Algorithmic enhancements to further improve the load imbalance or reduce the amount of necessary communication
Prefetching
Software-controlled
Insert prefetches by hand

7
Simulation Environment and Validation
Simulated Architecture
Stanford FLASH multiprocessor
Validation
Stanford DASH machine vs. Simulator
Speedups: Simulator ≈ DASH machine

8
Applications
Subset of SPLASH2
Important scientific & engineering computations
Different communication patterns & requirements
Indicative of several types of applications running on large scale DSMs

9
Results – With & w/o prefetching

10
Architectural Bottleneck

11
Conclusion
Problem size Possible to get good performance on large scale DSMs,
using problem sizes that are often surprisingly small, except Radix
Program difficulty In most case not difficult to program Scalable performance can be achieved without changing
the code too much
Architectural bottleneck End-point contention Require extremely efficient communication controllers


Scaling Application Performance on a Cache-coherent
Multiprocessor

14
The Question
Can distributed shared memory, cache coherent, non-uniform memory access architectures scale on parallel apps?
What do we mean by scale:
Achieve parallel efficiency of 60%,
For a fixed problem size,
Increasing the number of processors,

15
DSM, cc-NUMA
Each processor has private cache,
Shared address space constructed from “public” memory of each processor,
Loads / stores used to access memory,
Hardware ensures cache coherence,
Non-uniform: miss penalty for remote data higher,
SGI Origin2000 chosen as an aggressive representative in this architectural family,

16
Origin 2000 overview
Nodes placed as vertices of hypercubes:
Ensures that communication latency grows linearly, as number of nodes doubles,
Each node is dual 195 MHz proc, with own 32KB 1st level cache, 4 MB second level cache
Total addressible memory is 32GB
Most aggressive in terms of remote to local memory access latency ratio

17
Benchmarks
SPLASH-2: Barnes-Hut, Ocean, Radix Sort, etc,
3 new: Shear Warp, Infer, and Protein,
Range of communication-to-computation ratio, temporal and spatial locality,
Initial sizes of problems determined from earlier experiments:
Simulation with 256 processors,
Implementation with 32 processors,

18
Initial Experiments
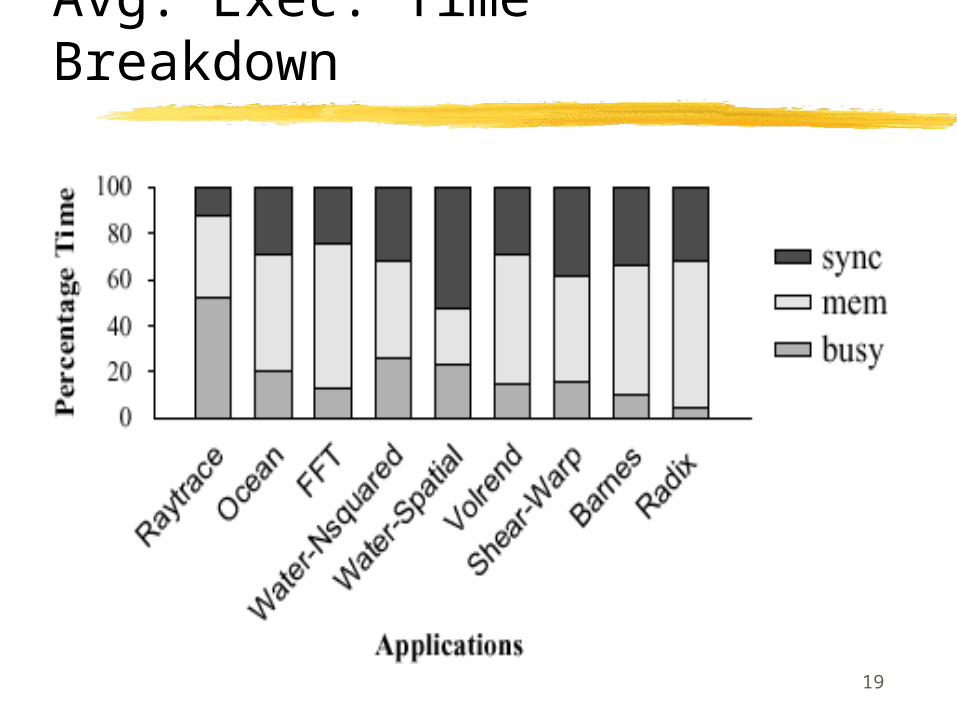
19
Avg. Exec. Time Breakdown

20
Problem Size
Idea:
increase problem size until desired level of efficiency is achieved,
Question:
Feasible?
Question:
Even if feasible, is it desirable?
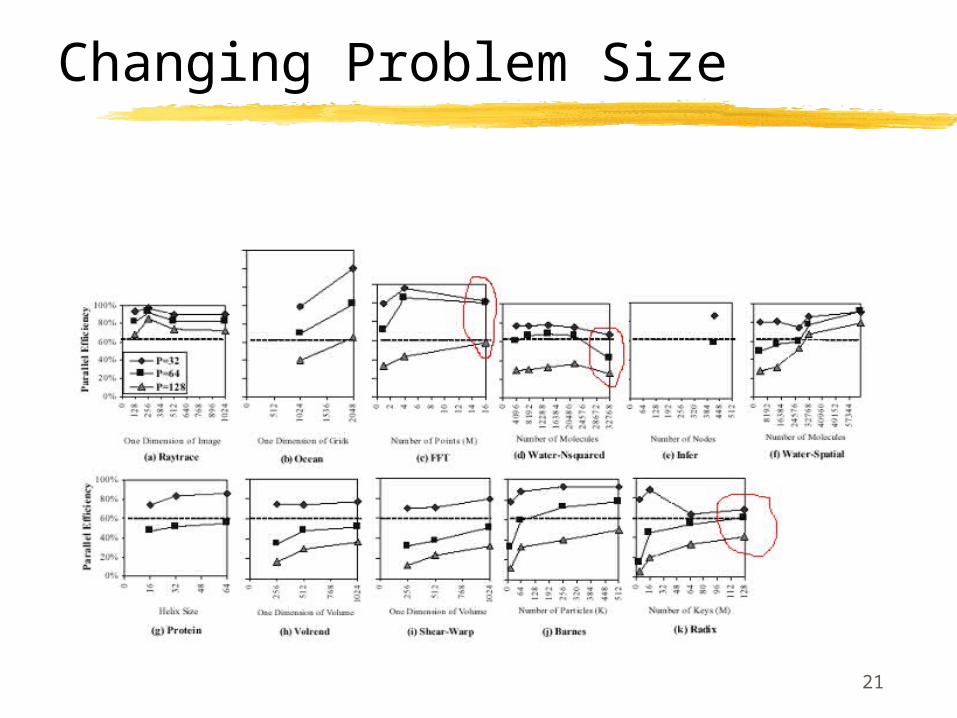
21
Changing Problem Size

22
Why problem size helps
Communication to computation ratio improved
Less load imbalance, both in computation and communication costsLess waiting in synch
Superlienarity effects of cache sizeHelps larger processor counts,
Hurts smaller processor counts
Less false sharing

23
Application Restructuring
What kind of restructuring:Algorithmic changes, data partitioning
Ways restructuring helps:Reduced communication,
Better data placement,
Static partitioning for better load balance,
Restructuring is app specific and complex,
Bonus side-effect:Scale well on Shared Virtual Memory (clustered
workstations) systems,

24
Application Restructuring

25
Conclusions
Original versions not scalable on cc-NUMA
Simulation not accurate for quantitative results; implementation needed
Increasing size a poor solution
App restructuring works:Restructured apps perform well also on SVM,
Parallel efficiency of these versions better
However, to validate results, good idea to run restructured apps on larger number of processors


A Comparison of the MPI, SHMEM and Cache-coherent
Programming Models on the SGI Origin2000

28
Purpose
Compare the three programming
models on Origin2000
We focus on scientific applications that
access data regularly or predictably
Or do not require fine grained
replication of irregularly accessed data

29
SGI Origin2000
Cache coherent, NUMA machine
64 processors32 nodes, 2 MIPS R10000 processors
each
512 MB memory per node
Interconnection Network 16 vertices hypercube
Pair of nodes associated with each vertex

30
Three Programming Models
CC-SAS
Linear address space for shared memory
MP
Communicate with other processes explicitly via message passing interface (MPI)
SHMEM
Shared memory one sided communication library
Via get and put primitives

31
Applications and Algorithms
FFTAll-to-all communication(regular)
OceanNearest-neighbor communication
RadixAll-to-all communication(irregular)
LUOne-to-many communication

32
Questions to be answered
Can parallel algorithms be structured in the same way for good performance in all three models?
If there are substantial differences in performance under three models, where are the key bottlenecks?
Do we need to change the data structures or algorithms substantially to solve those bottlenecks?

33
Performance Result

34
Questions:
Anything unusual in the previous slide?
Working sets fit in the cache for multiprocessors but not for uniprocessors
Why MP is much worse than CC-SAS and SHMEM?

35
Analysis:
Execution time = BUSY + LMEM + RMEM + SYNC
where
BUSY: CPU computation time
LMEM: CPU stall time for local cache miss
RMEM: CPU stall time for sending/receiving remote data
SYNC: CPU time spend at synchronization events

36
Time breakdown for MP

37
Improving MP performance
Remove extra data copy
Allocate all data involved in communication in shared address space
Reduce SYNC time
Use lock-free queue management instead in communication
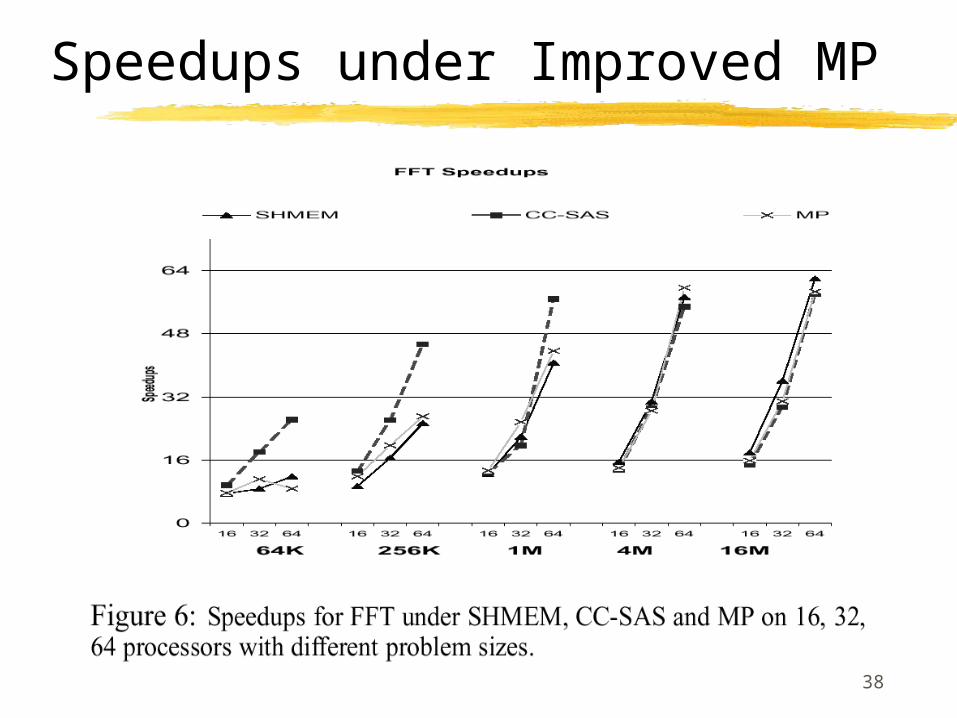
38
Speedups under Improved MP

39
Question:
Why does CC-SAS perform best for small problem size?
Extra packing/unpacking operation in MP and SHMEM
Extra packet queue management in MP
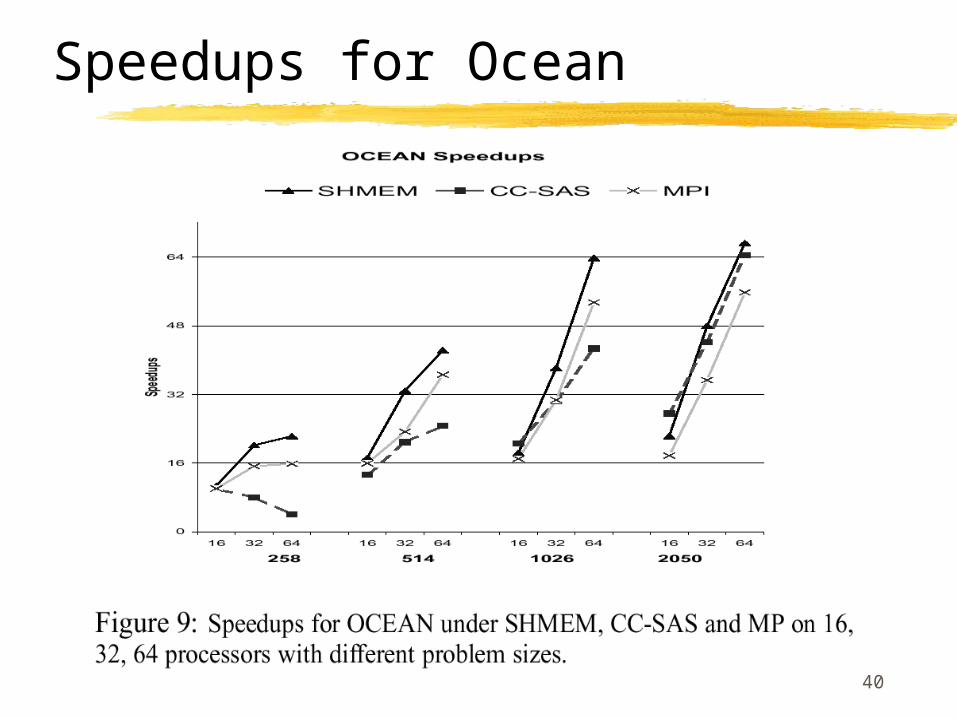
40
Speedups for Ocean

41
Speedups for Radix

42
Speedups for LU

43
Conclusions
Good algorithm structures are portable among programming models.
MP is much worse than CC-SAS and SHMEM.
We can achieve similar performance if extra data copy and queue synchronization are well solved.

















