1 Prosody-Based Automatic Segmentation of Speech into Sentences and Topics Elizabeth Shriberg Andreas Stolcke Speech Technology and Research Laboratory Dilek Hakkani-Tur Gokhan Tur Depatment of Computer Engineering, Bilkent Uni versity To appear in Speech Communication 32(1-2) Special Issue on Accessing Information in Spoken A udio Presenter: Yi-Ting Chen
Transcript
1
Prosody-Based Automatic Segmentation of Speech into Sentences and Topics
Elizabeth Shriberg Andreas Stolcke
Speech Technology and Research Laboratory
Dilek Hakkani-Tur Gokhan Tur
Depatment of Computer Engineering, Bilkent University
To appear in Speech Communication 32(1-2)Special Issue on Accessing Information in Spoken Audio
Presenter: Yi-Ting Chen
2
Outline
• Introduction• Method
– Prosodic modeling– Language modeling– Model combination– Data
• Results and discussion• Summary and conclusion
3
Introduction (1/2)
• Why process audio data?• Why automatic segmentation?
– A crucial step toward robust information extraction from speech is the automatic determination of topic, sentence, and phrase boundaries
• Why used prosody?– In all languages, prosody is used to convey structural, semantic,
and functional information– Prosodic cues by their nature are relatively unaffected by word
identity– Unlike spectral features, some prosodic features are largely
invariant to changes in channel characteristics– Prosodic feature extraction can be achieved with minimal
additional computational load and no additional training data
4
Introduction (2/2)
• In this paper we describe the prosodic modeling in detail
• Using decision tree and hidden Markov modeling techniques to combine prosodic cues with word-based approaches, and evaluate performance on two speech corpora
• To look at results for both true word, and word as hypothesized by a speech recognizer.
5
Method (1/6) –Prosodic modeling
• Feature extraction regions– For each inter-word boundary, we looked at prosodic features of
the word immediately preceding and following the boundary, or alternatively within a window of 20 frames (200ms) befor and after the boundary
– They extracted prosodic features reflecting pause durations, phone durations, pitch information, and voice quality information
– They chose not to use amplitude- or energy-based features, since previous word showed these features to be both less reliable than and largely redundant with duration and pitch features
6
Method (2/6) –Prosodic modeling
• Features:– The features were designed to be independent of word identities– They began with a set of over 100 features, was pared down to
a smaller set by eliminating features
– Pause features: Important cues to boundaries between semantic units
• The pause model was trained as an individual phone• In the case of no pause at the boundary, this pause duration
feature was output as 0• The duration of the pause preceding the word before the
boundary• Raw durations and durations normalized were investigated
for pause duration distributions from the particular speaker
7
Method (3/6) –Prosodic modeling
• Features:– Phone and rhyme duration features: a slowing down toward the
ends of units, or preboundary lengthening• Preboundary lengthening typically affects the nucleus and co
da of syllables• Duration characteristics of the last rhyme of the syllable prec
eding the boundary• Each phone in the rhyme was normalized for inherent duratio
n as
i i
ii
durphonedevstd
durphonemeandurphone
___
___
8
Method (4/6) –Prosodic modeling
• Features:– F0 features:
• Pitch information is typically less robust and more difficult to model than other prosodic features
• To smooth out microintonation and tracking errors, simplify F0 feature computation, and identify speaking-range parameters for each speaker
9
Method (5/6) –Prosodic modeling
• Features:– F0 features:
• Reset features• Range features• F0 slope features• F0 continuity features
– Estimated voice quality features
– Other features: • speaker gender、• turn boundaries、• time elapsed from the start of turn and the turn count in the c
onversation
10
Method (6/6) –Prosodic modeling
• Decision trees– Decision trees are probabilistic classifiers– Given a set of features and a labeled training set, the decision
tree construction algorithm repeatedly selects a single feature that has the highest predictive value
– The leaves of the tree store probabilities about the class distribution of all samples falling into the corresponding region of the feature space
– Decision trees make no assumptions about the shape of feature distributions
– It is not necessary to convert feature values to some standard scale
• Feature selection algorithm
11
Method (1/3) –Language modeling
• The goal: to capture information about segment boundaries contained in the word sequences
• To model the joint distribution of boundary types and words in a hidden Markov model (HMM)
• To denote boundary classification by and use for the word sequencesthe structure of the HMM :
• Using the slightly more complex forward-backward algorithm to maximize the posterior probability of each individual boundary classification
KTTT ,......,1NWWW ,......,1
)|(maxarg WTPT
)|(maxarg WTP iTi
iT
12
Method (2/3) –Language modeling
• Sentence segmentation– A hidden-event N-gram language model
– The states of the HMM consist of the end-of sentence status of each word, plus any preceding words and possibly boundary tags to fill up the N-gram context
– Transition probabilities are given by N-gram probabilities estimated from annotated
– Boundary-tagged training data using Katz backoff
e models using the Multipass k-means algorithm (Using TDT)
– Then to built an HMM in which the states are topic clusters, and the observation are sentences
– In addition to the basic HMM segmenter, incorporating two states for modeling the initial and final sentences of a topic segment
14
Method (1/3) –Model combination
• Expecting prosodic and lexical segmentation cues to be partly complementary– Posterior Probability interpolation
– Integrated hidden Markov modeling• With suitable independence assumption to apply the familiar t
echniques to compute:
or• To incorporate the prosodic information into the HMM, prosod
ic features are modeled as emissions from relecant HMM states, with likelihoods
• So, a complete path through the HMM is associated with the total probability
),|()1()|(),|( WFTPWTPFWTP iiDTiLMi
),|(maxarg FWTPT
),|(maxarg FWTP iTi
),|( WTFP ii
),,(),|(),( TFWPWTFPTWPi
ii
15
Method (2/3) –Model combination
• Expecting prosodic and lexical segmentation cues to be partly complementary– Integrated hidden Markov modeling
• How to estimate the likelihoods – Note that the decision tree estimates posteriors– These can be converted to likelihoods using Bayes’ rule
as in
– A beneficial side effect of this approach is that the decision tress models the lower-frequency events in greater detail than if presented with the raw, highly skewed class distribution
– A tunable model combination weight (MCW) was introduced
),|( WFTP ii
),|( WTFP ii
)|(
),|()|(),|(
WTP
WFTPWFPWTFP
i
iiDTiii
16
Method (3/3) –Model combination
• Expecting prosodic and lexical segmentation cues to be partly complementary– HMM posteriors as decision tress features
• For practical reasons we chose not to use it in this work• Drawback: overestimate the informativeness of the word-bas
ed posteriors based on automatic transcriptions
– Alternative models• HMM: A drawback is that the independence assumptions ma
y be inappropriate and inherently lime the performance of the model
• The decision trees:
advantages: enhances discrimination between the target classifications and input features can be combined easily
drawbacks: the sensitivity to skewed class distribution expensive to model multiple target variables
17
Method (1/2) –Data
• Speech data and annotations– Switchboard data: a sub set of the corpus that had been hand-
labeled for sentence boundaries by LDC– Broadcast News data for topic and sentence segmentation was
extracted from the LDC’ 1997 Broadcast News (BN) release– Training of Broadcast News language models used an additional
130 million word of text-only transcripts from the 1996 Hub-4 language model corpus (for sentence segmentation )
• Training, tuning, and test sets
18
Method (2/2) –Data
• Word recognition– 1-best output from SRI’s DECIPHER large-vocabulary speech re
cognizer– Skipping several of the computationally expensive or cumbersom
e steps (such as acoustic adaptation)– Switchboard test set:46.7% WER– Broadcast News: 30.5% WER
• Evaluation metrics– Sentence segmentation performance for true words was measur
ed by boundary classification error– For recognized words, a string alignment of the automatically lab
eled recognition hypothesis are performed– Then to calculate error rate– Topic segmentation was evaluated using the metric defined by N
IST for TDT-2 evaluation
19
Results and discussion (1/10)
• Task 1: Sentence segmentation of Broadcast New data– Prosodic features usage
• The best-performing tree identified six features for this task, which fall into four groups
• Pause > turn > F0 > Rhyme duration
• Based on descriptive literature, the behavior of the features is precisely
20
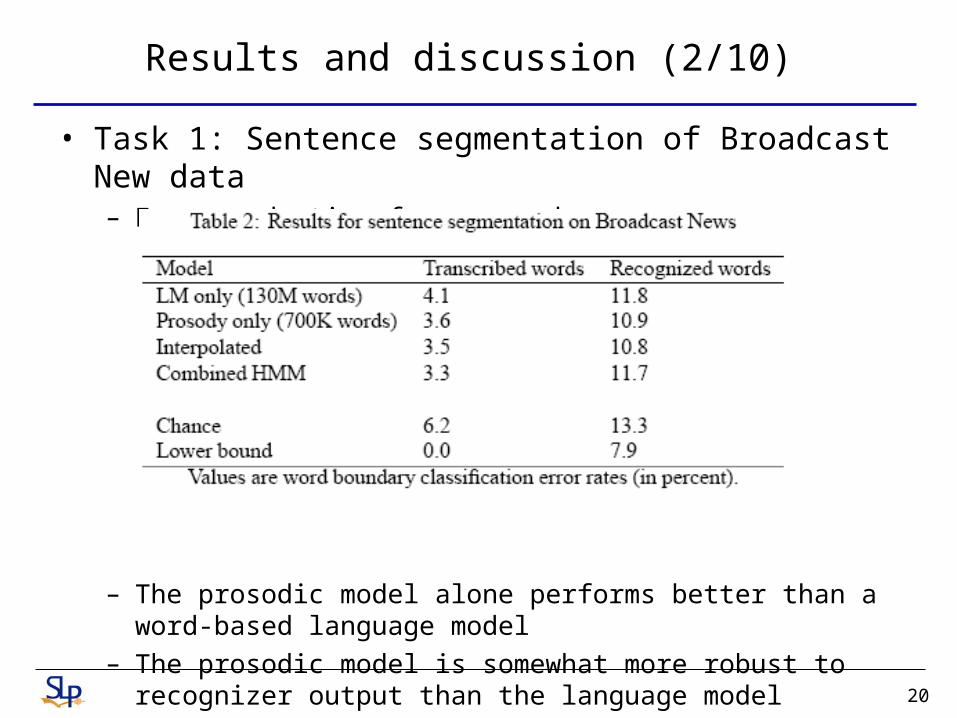
Results and discussion (2/10)
• Task 1: Sentence segmentation of Broadcast New data– Error reduction from prosody
– The prosodic model alone performs better than a word-based language model
– The prosodic model is somewhat more robust to recognizer output than the language model
21
Results and discussion (3/10)
• Task 1: Sentence segmentation of Broadcast New data– Performance without F0 features
• The F0 features used are not typically extracted or computed in most ASR systems
• Removing all F0 features:
• It could also indicate a higher degree of correlation between true words and the prosodic features?
• A different distribution of features than observed for Broadcast News
• The primary feature type used here is pre-boundary duration• Pause duration at the boundary was also useful• Most interesting about this tree was the consistent behavior
of duration features, which gave higher probability to a sentence boundary
23
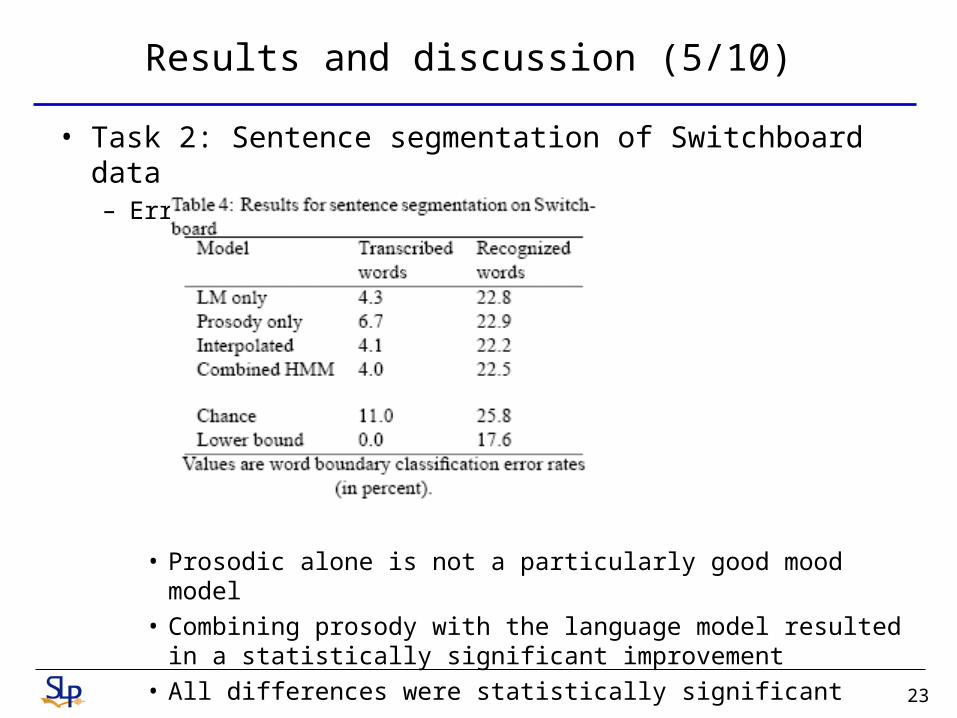
Results and discussion (5/10)
• Task 2: Sentence segmentation of Switchboard data– Error reduction from prosody
• Prosodic alone is not a particularly good mood model• Combining prosody with the language model resulted in a
statistically significant improvement• All differences were statistically significant
• The speaker-gender feature– The women in a sense behave more “neatly” than the me
n– One possible explanation
is that men are more likely than women toproduce regions of nonmodal voicing oftopic boundaries
26
Results and discussion (8/10)
• Task 3: Topic segmentation of Broadcast News data– Error reduction from prosody
• All results reflect the word-averaged, weighted error metric used in the TDT-2 evaluation
• Chance here correspond to outputting the “no boundary” class at all locations, meaning that the false alarm rate will be zero and miss rate will be 1
• A weight of 0.7 to false alarms and 0.3 to miss
27
Results and discussion (9/10)
• Task 3: Topic segmentation of Broadcast News data– Performance without F0 features
• The experiments were conducted only for true word, since as shown in table 5, results are similar to those for recognized words
28
Results and discussion (10/10)
• Comparisons of error reduction across conditions– Performance without F0 features
• While researcher typically have found Switchboard a difficult corpus to process, in the case of sentence segmentation on true word it just the opposite-atypically
• Previous word on automatic segmentation on Switchboard transcripts is likely to overestimate success for other corpora
29
Summary and conclusion
• The use of prosodic information for sentence and topic segmentation have studied
• Results showed that on Broadcast News the prosodic model alone performed as well as purely word0based statistical language models
• Interestingly, the integrated HMM worded best on transcribed words, while the posterior interpolation approach was much more robust in the case of recognized