72
1 SIMS 290-2: Applied Natural Language Processing Marti Hearst October 30, 2006 Some slides by Preslav Nakov and Eibe Frank
| Date post: | 22-Dec-2015 |
| Category: |
Documents |
| View: | 216 times |
| Download: | 1 times |

1
SIMS 290-2: Applied Natural Language Processing
Marti HearstOctober 30, 2006
Some slides by Preslav Nakov and Eibe Frank

2
Today
The Newsgroups Text Collection
WEKA: Exporer
WEKA: Experimenter
Python Interface to WEKA

3
Source: originally collected by Ken LangContent and structure:
approximately 20,000 newsgroup documents– 19,997 originally– 18,828 without duplicates
partitioned evenly across 20 different newsgroups we are only using a subset (6 newsgroups)
Some categories are strongly related (and thus hard to discriminate):
20 Newsgroups Data Sethttp://people.csail.mit.edu/u/j/jrennie/public_html/20Newsgroups/
comp.graphicscomp.os.ms-windows.misccomp.sys.ibm.pc.hardwarecomp.sys.mac.hardwarecomp.windows.x
rec.autosrec.motorcyclesrec.sport.baseballrec.sport.hockey
sci.cryptsci.electronicssci.medsci.space
misc.forsale talk.politics.misctalk.politics.gunstalk.politics.mideast
talk.religion.miscalt.atheismsoc.religion.christian
computers

4
Sample Posting: “talk.politics.guns”From: [email protected] (C. D. Tavares)Subject: Re: Congress to review ATF's status
In article <[email protected]>, [email protected] (Larry Cipriani) writes:
> WASHINGTON (UPI) -- As part of its investigation of the deadly> confrontation with a Texas cult, Congress will consider whether the> Bureau of Alcohol, Tobacco and Firearms should be moved from the> Treasury Department to the Justice Department, senators said Wednesday.> The idea will be considered because of the violent and fatal events> at the beginning and end of the agency's confrontation with the Branch> Davidian cult.
Of course. When the catbox begines to smell, simply transfer itscontents into the potted plant in the foyer.
"Why Hillary! Your government smells so... FRESH!"--
[email protected] --If you believe that I speak for my company,OR [email protected] write today for my special Investors' Packet...
reply
from
subject
signature
Need special handling during
feature extraction…
… writes:

5
The 20 Newsgroups Text Collection
WEKA: Exporer
WEKA: Experimenter
Python Interface to WEKA
WEKA: Real-time Demo

6Slide adapted from Eibe Frank's
WEKA: The Bird
Copyright: Martin Kramer ([email protected]), University of Waikato, New Zealand

7Slide by Eibe Frank
WEKA: the softwareWaikato Environment for Knowledge AnalysisCollection of state-of-the-art machine learning algorithms and data processing tools implemented in Java
Released under the GPL
Support for the whole process of experimental data miningPreparation of input dataStatistical evaluation of learning schemesVisualization of input data and the result of learning
Used for education, research and applicationsComplements “Data Mining” by Witten & Frank

8Slide by Eibe Frank
Main Features49 data preprocessing tools76 classification/regression algorithms8 clustering algorithms15 attribute/subset evaluators + 10 search algorithms for feature selection3 algorithms for finding association rules3 graphical user interfaces
“The Explorer” (exploratory data analysis)“The Experimenter” (experimental environment)“The KnowledgeFlow” (new process model inspired interface)

9Slide by Eibe Frank
Projects based on WEKAIncorporate/wrap WEKA
GRB Tool Shed - a tool to aid gamma ray burst researchYALE - facility for large scale ML experimentsGATE - NLP workbench with a WEKA interfaceJudge - document clustering and classification
Extend/modify WEKABioWeka - extension library for knowledge discovery in biologyWekaMetal - meta learning extension to WEKAWeka-Parallel - parallel processing for WEKAGrid Weka - grid computing using WEKAWeka-CG - computational genetics tool library

10Slide by Eibe Frank
The WEKA Project Today (2006)
Funding for the next two yearsGoal of the project remains the samePeople
6 staff2 postdocs3 PhD students3 MSc students2 research programmers

11Slide adapted from Eibe Frank's
WEKA: The Software Toolkit
Machine learning/data mining software in JavaGNU LicenseUsed for research, education and applicationsComplements “Data Mining” by Witten & FrankMain features:
data pre-processing tools learning algorithms evaluation methods graphical interface (incl. data visualization) environment for comparing learning algorithms
http://www.cs.waikato.ac.nz/ml/weka
http://sourceforge.net/projects/weka/

12
WEKA: Terminology
Some synonyms/explanations for the terms used by WEKA, which may differ from what we use:
Attribute: feature Relation: collection of examples Instance: collection in use Class: category

13Slide adapted from Eibe Frank's
WEKA GUI Chooser java -Xmx1000M -jar weka.jar

14Slide adapted from Eibe Frank's
Our Toy Example
We demonstrate WEKA on a simple example:
3 categories from “Newsgroups”:– misc.forsale, – rec.sport.hockey, – comp.graphics
20 documents per category features:– words converted to lowercase– frequency 2 or more required– stopwords removed

15Slide adapted from Eibe Frank's
Explorer: Pre-Processing The Data
WEKA can import data from:files: ARFF, CSV, C4.5, binaryURL SQL database (using JDBC)
Pre-processing tools (filters) are used for:Discretization, normalization, resampling, attribute selection, transforming and combining attributes, etc.

16
List of attributes (last: class variable)
Frequency and categories for the selected
attribute
Statistics about the values of the selected attribute
Classification
Filter selection
Manual attribute selection
Statistical attribute selection
Preprocessing
The Preprocessing Tab

17Slide adapted from Eibe Frank's
Explorer: Building “Classifiers”
Classifiers in WEKA are models for:classification (predict a nominal class)regression (predict a numerical quantity)
Learning algorithms:Naïve Bayes, decision trees, kNN, support vector machines, multi-layer perceptron, logistic regression, etc.
Meta-classifiers:cannot be used alonealways combined with a learning algorithmexamples: boosting, bagging etc.
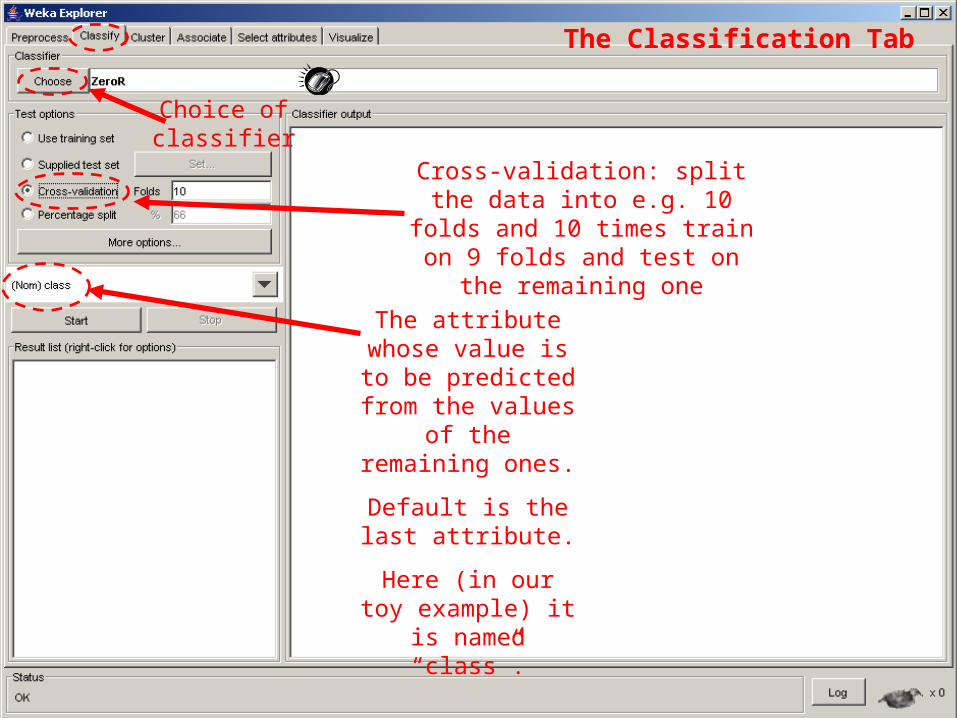
18
Choice of classifier
The attribute whose value is to be predicted from the values of the remaining ones.
Default is the last attribute.
Here (in our toy example) it is
named “class”.
Cross-validation: split the data into e.g. 10 folds and
10 times train on 9 folds and test on the remaining one
The Classification Tab
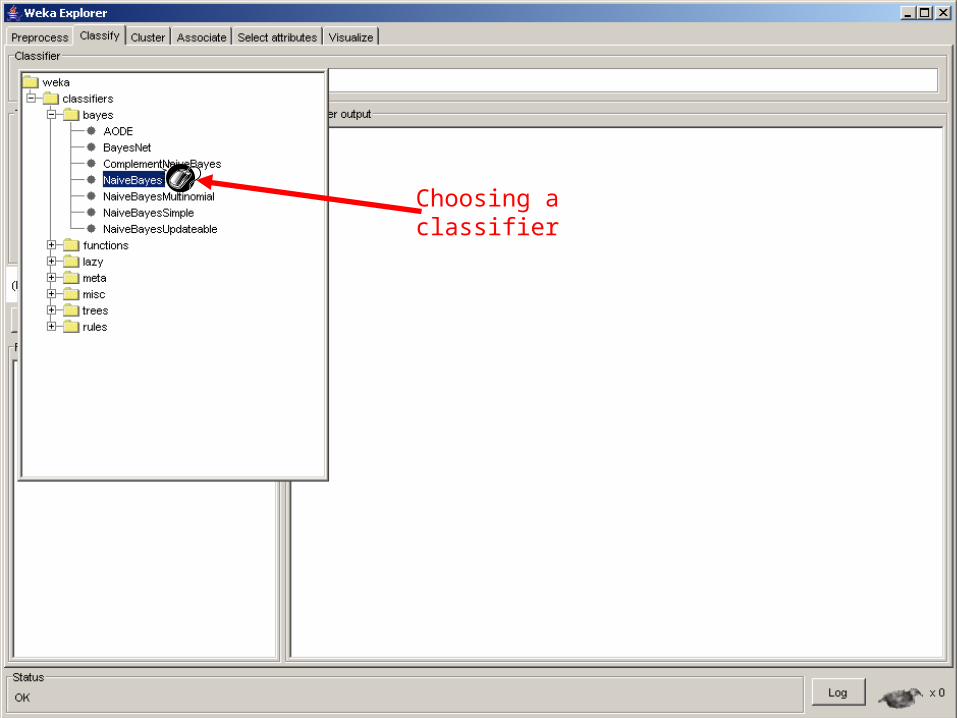
19
Choosing a classifier
20
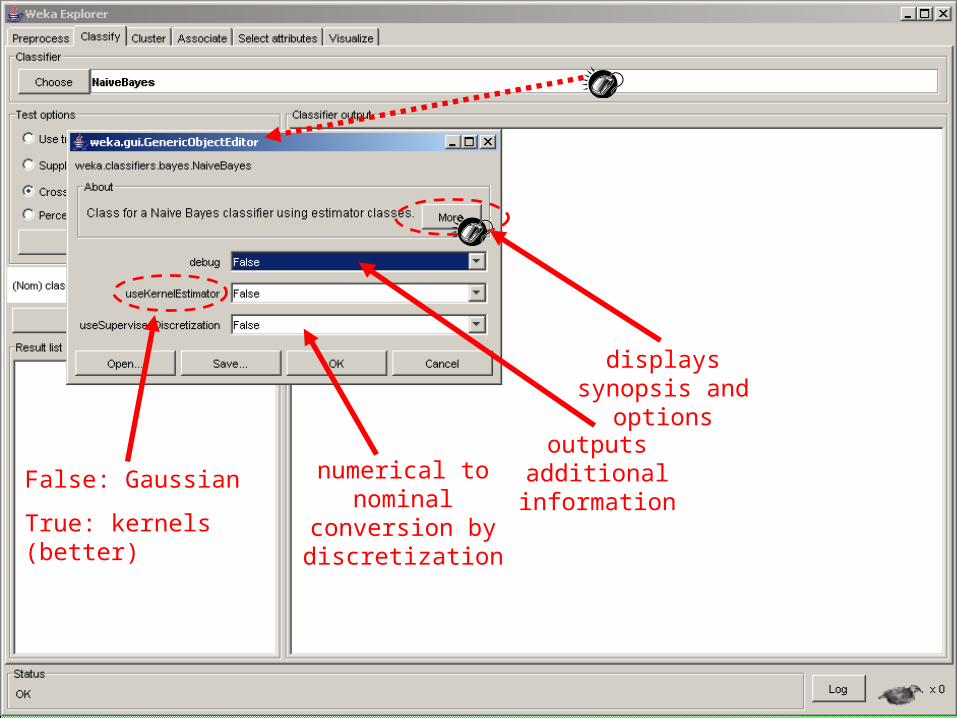
21
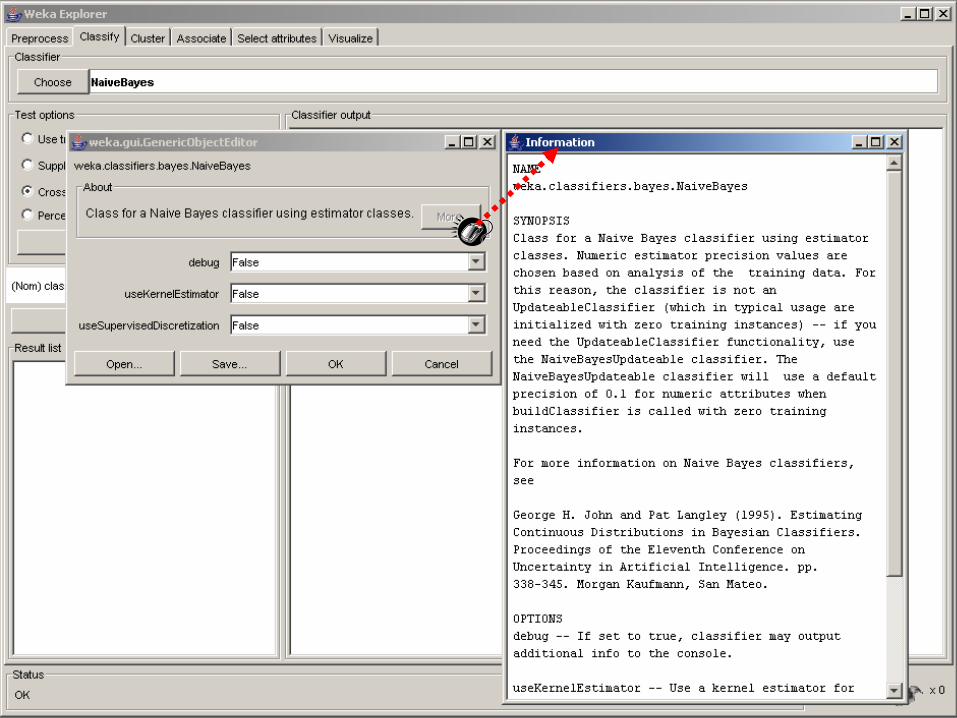
False: Gaussian
True: kernels (better)
displays synopsis and options
numerical to nominal
conversion by discretization
outputs additional information
22

23

24
all other numbers can be obtained from it
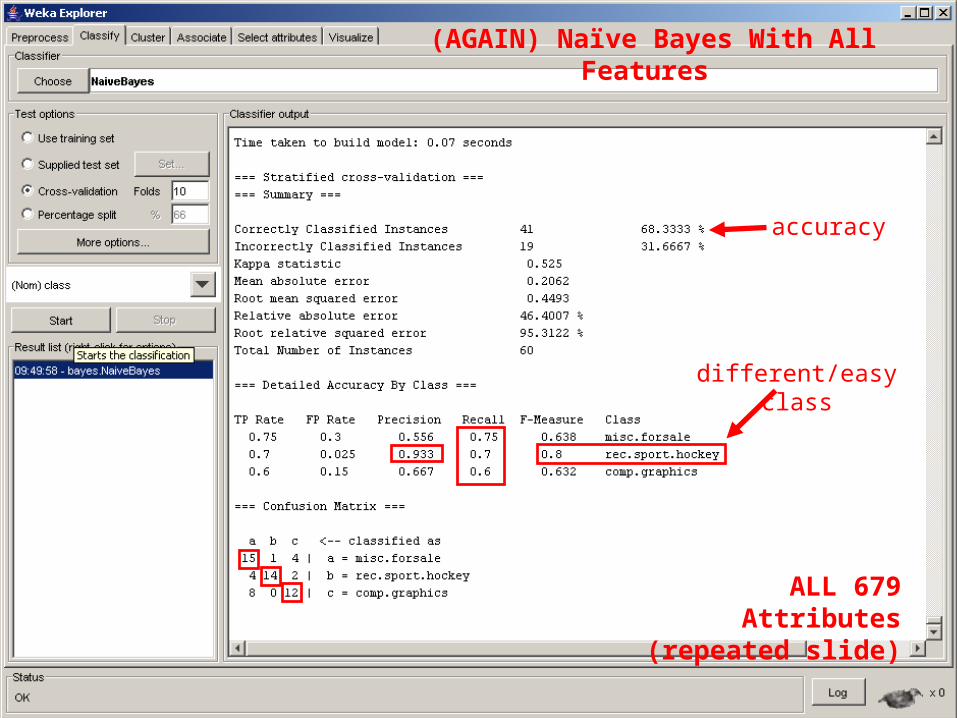
different/easy class
accuracy

25
Contains information about the actual and the predicted classification
All measures can be derived from it: accuracy: (a+d)/(a+b+c+d) recall: d/(c+d) => R precision: d/(b+d) => P F-measure: 2PR/(P+R) false positive (FP) rate: b/(a+b) true negative (TN) rate: a/(a+b) false negative (FN) rate: c/(c+d)
These extend for more than 2 classes: see previous lecture slides for details
Confusion matrix
predicted
– +
true
– a b
+ c d

26
Outputs the probability
distribution for each example
Predictions Output
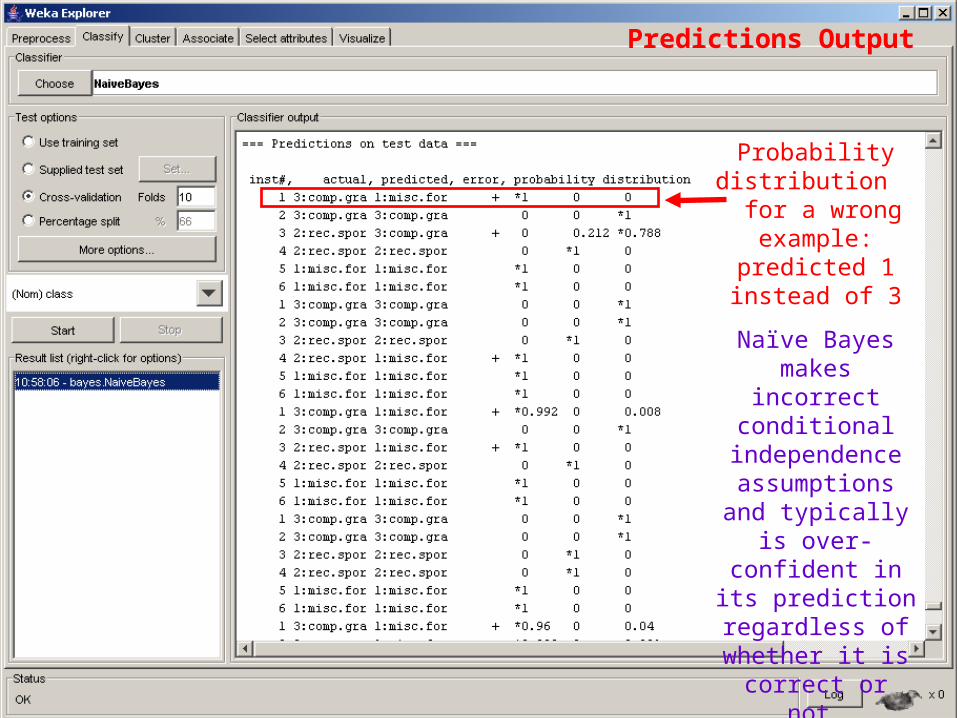
27
Probability distribution for
a wrong example:
predicted 1 instead of 3
Naïve Bayes makes incorrect
conditional independence assumptions
and typically is over-confident in its prediction regardless of whether it is
correct or not.
Predictions Output

28
Error Visualization
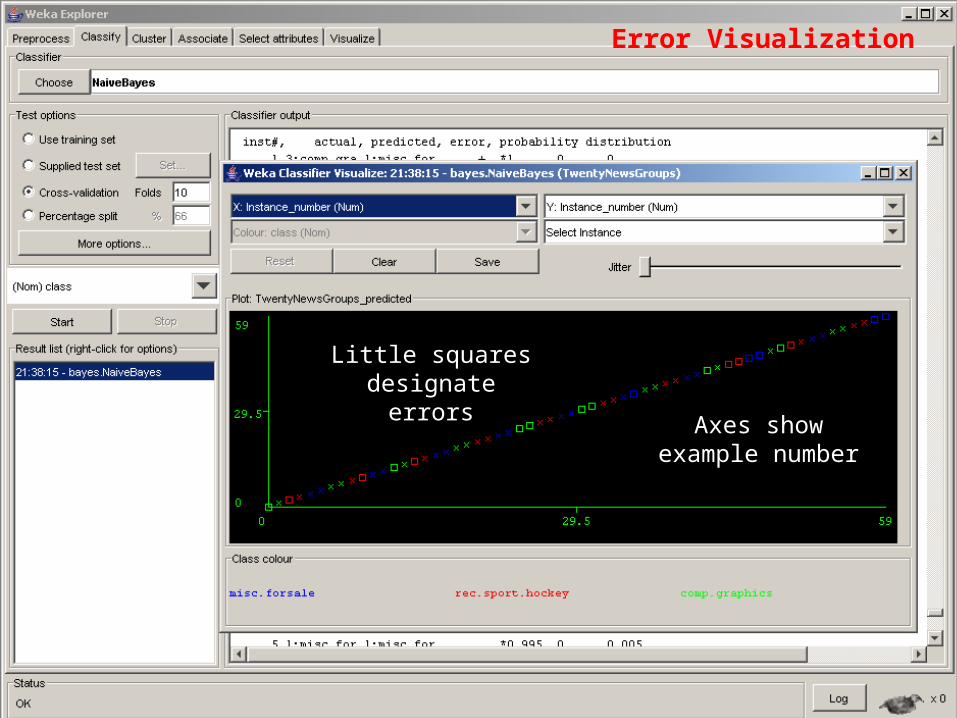
29
Error Visualization
Little squares designate errors
Axes show example number

30
Running on Test Set

31Slide adapted from Eibe Frank's
Find which attributes are the most predictive ones
Two parts: search method: – best-first, forward selection, random, exhaustive, genetic
algorithm, ranking
evaluation method: – information gain, chi-squared, etc.
Very flexible: WEKA allows (almost) arbitrary combinations of these two
Explorer: Attribute Selection
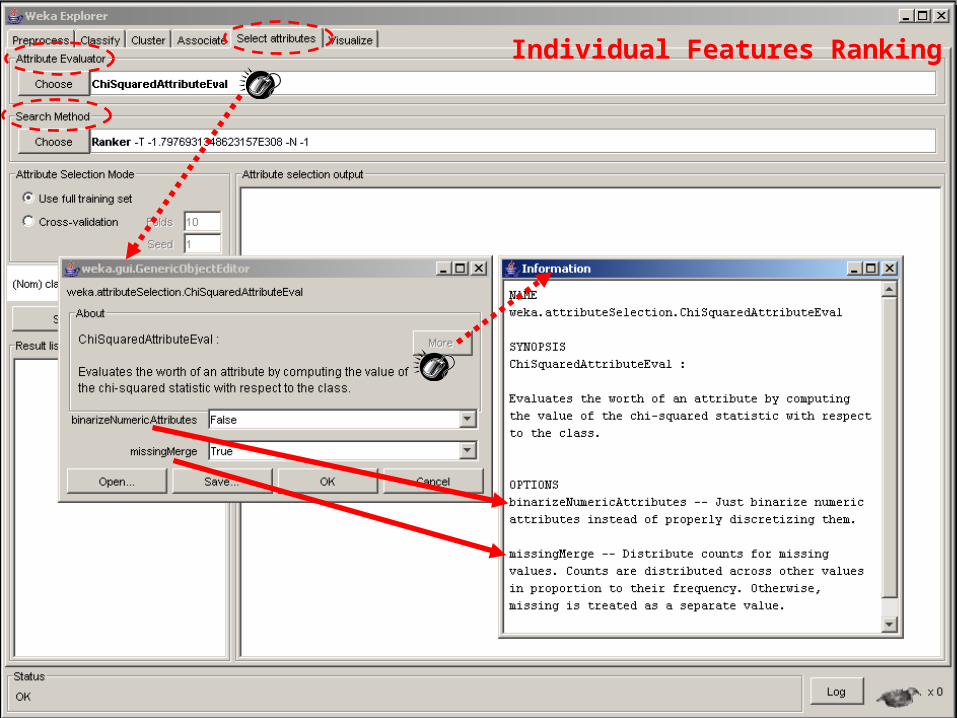
32
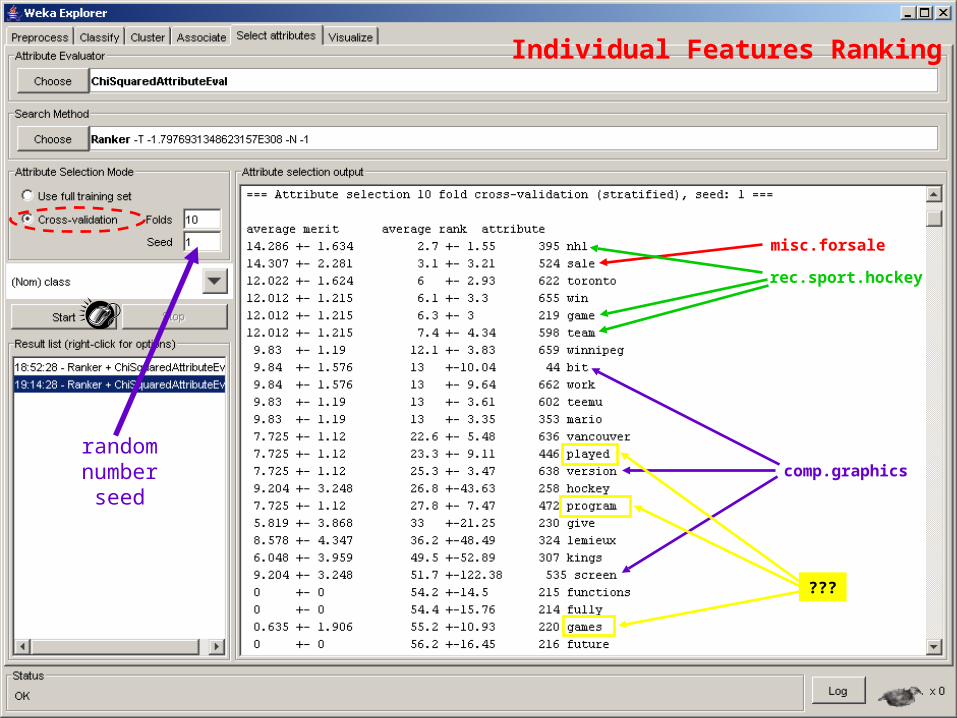
Individual Features Ranking

33
misc.forsale
comp.graphics
rec.sport.hockey
Individual Features Ranking
34
misc.forsale
comp.graphics
rec.sport.hockey
???
random number
seed
Individual Features Ranking
40
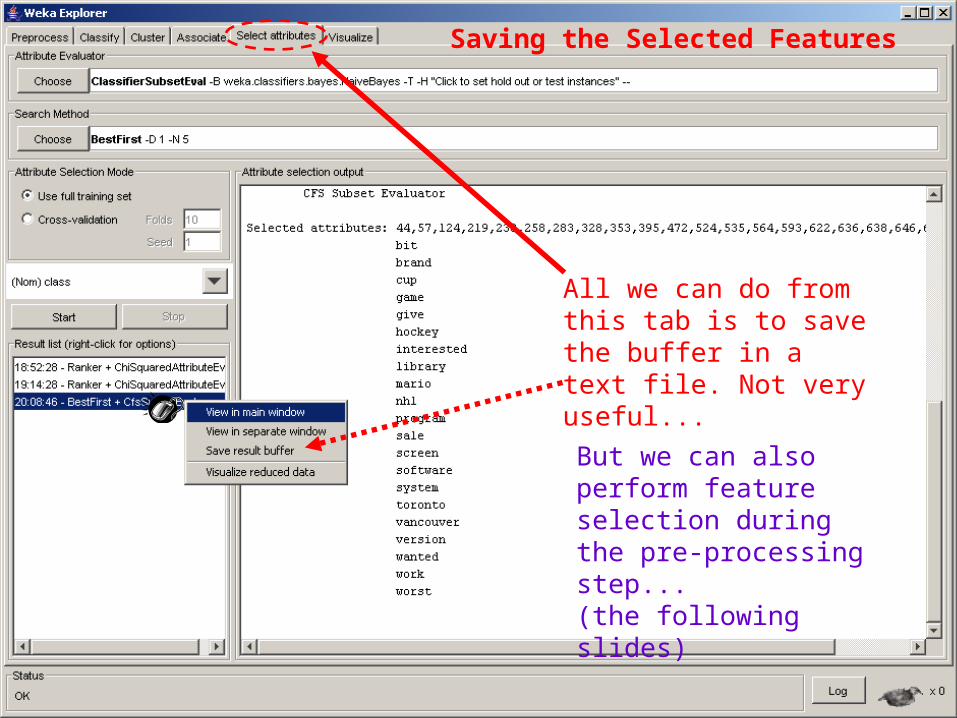
Saving the Selected Features
All we can do from this tab is to save the buffer in a text file. Not very useful...
But we can also perform feature selection during the pre-processing step...(the following slides)

41
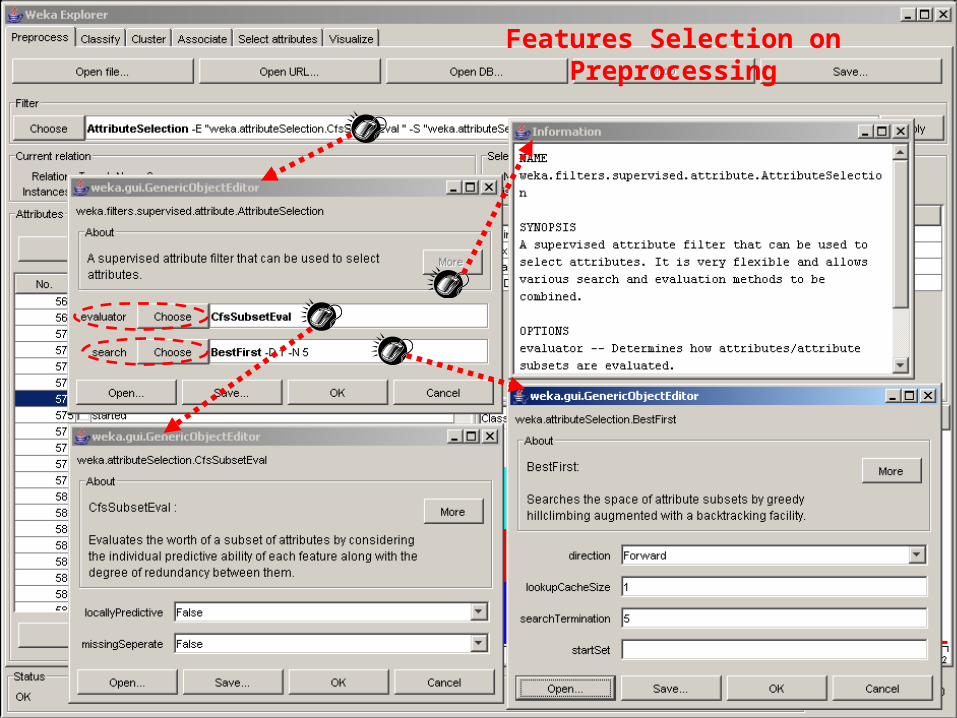
Features Selection on Preprocessing
42
Features Selection on Preprocessing

43
Features Selection on Preprocessing
679 attributes: 678 + 1 (for the class)

44
Features Selection on Preprocessing
Just 22 attributes remain:
21 + 1 (for the class)
45
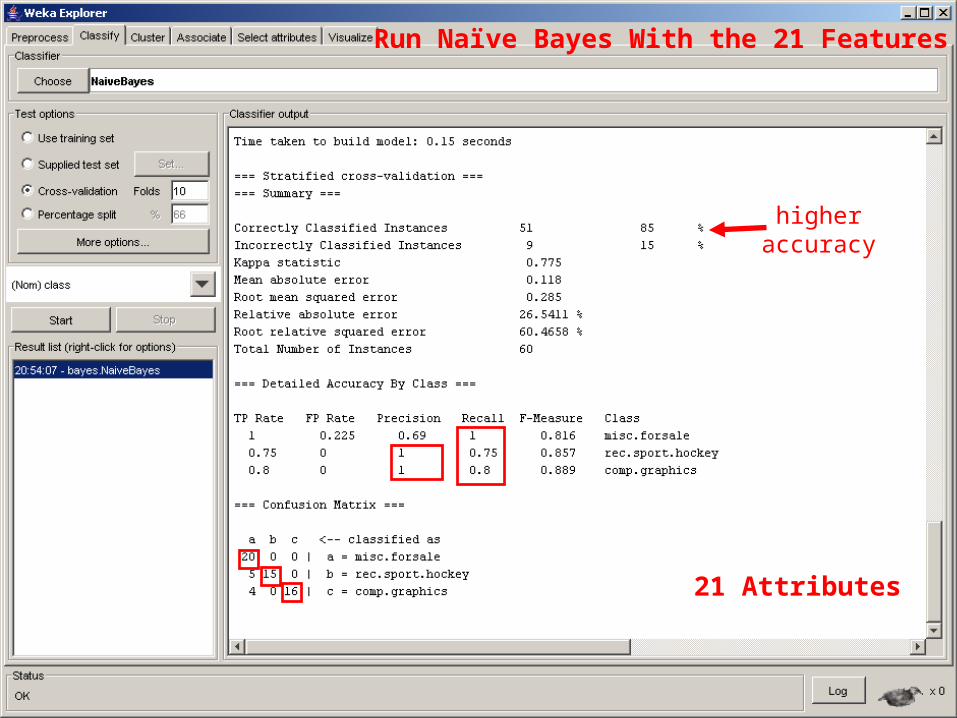
Run Naïve Bayes With the 21 Features
higher accuracy
21 Attributes
46
different/easy class
accuracy
(AGAIN) Naïve Bayes With All Features
ALL 679 Attributes(repeated slide)

47
WEKA has weird naming for some algorithms
Here are some translations: Naïve Bayes: weka.classifiers.bayes.NaiveBayes Perceptron: weka.classifiers.functions.VotedPerceptron Decision tree: weka.classifiers.trees.J48 Support vector machines: weka.classifiers.functions.SMO k nearest neighbor: weka.classifiers.lazy.IBk
Some of these are more sophisticated versions of the classic algorithms
e.g. the classic Naïve Bayes seems to be missing A good alternative is the Multinomial Naïve Bayes model
Some Important Algorithms

48
The 20 Newsgroups Text Collection
WEKA: Explorer
WEKA: Experimenter
Python Interface to WEKA
WEKA: Real-time Demo

49Slide adapted from Eibe Frank's
Experimenter makes it easy to compare the performance of different learning schemes
Problems: classification regression
Results: written into file or databaseEvaluation options:
cross-validation learning curve hold-out
Can also iterate over different parameter settingsSignificance-testing built in!
Performing Experiments
50
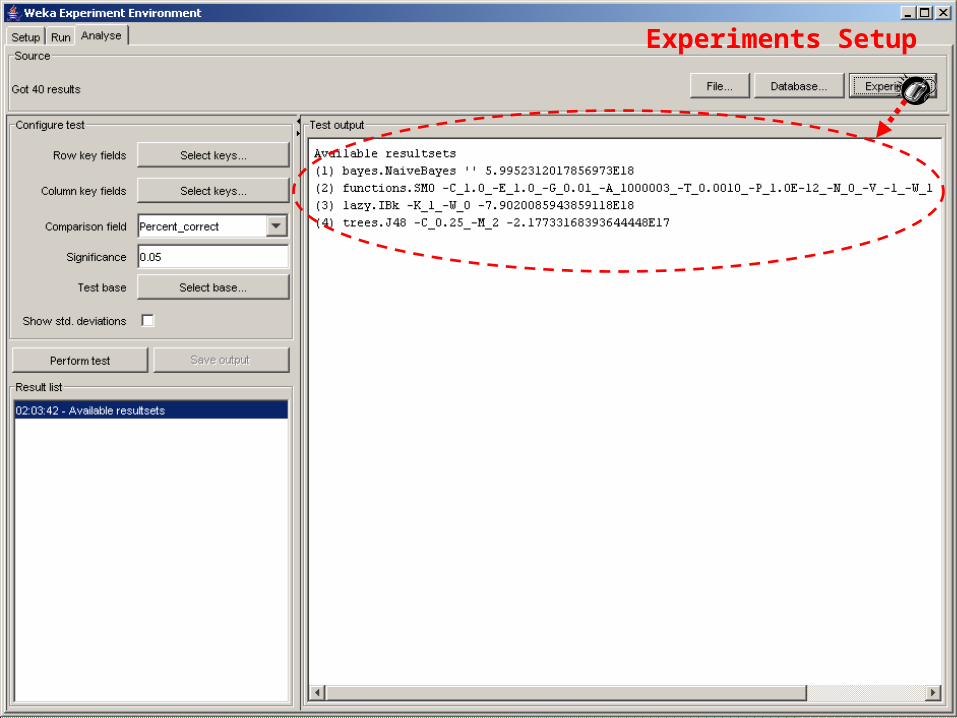
Experiments Setup
51
Experiments Setup

52
Experiments Setup
CSV file: can be open in Exceldatasets
algorithms

53
Experiments Setup
54
Experiments Setup
55
Experiments Setup

56
Experiments Setup
57
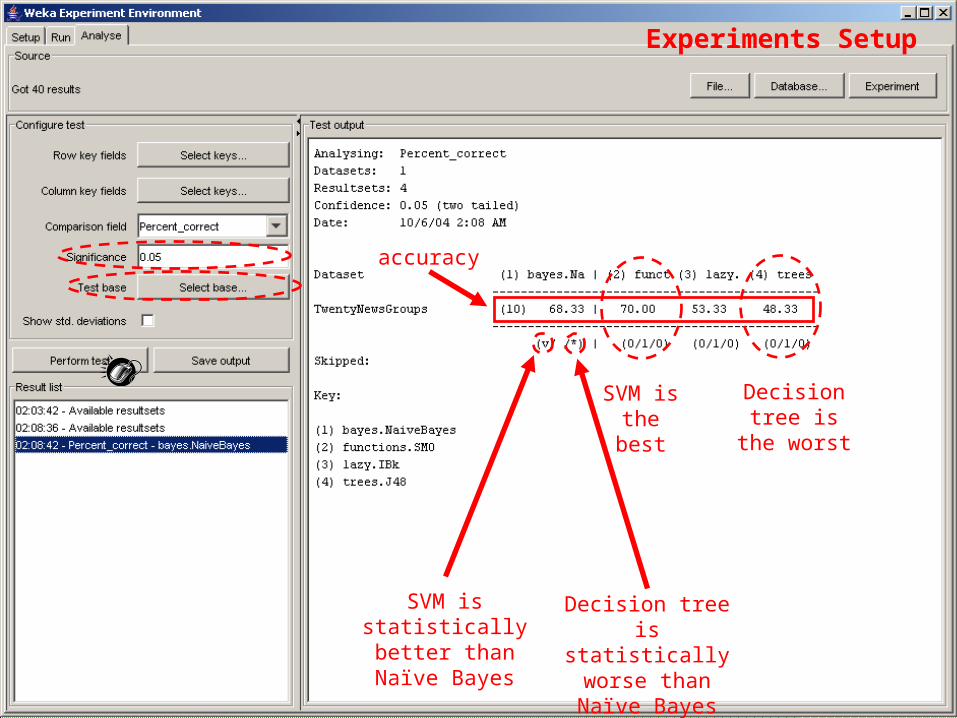
Experiments Setup
accuracy
SVM is the best
Decision tree is the
worst
SVM is statistically better than Naïve Bayes
Decision tree is statistically worse than Naïve Bayes
58
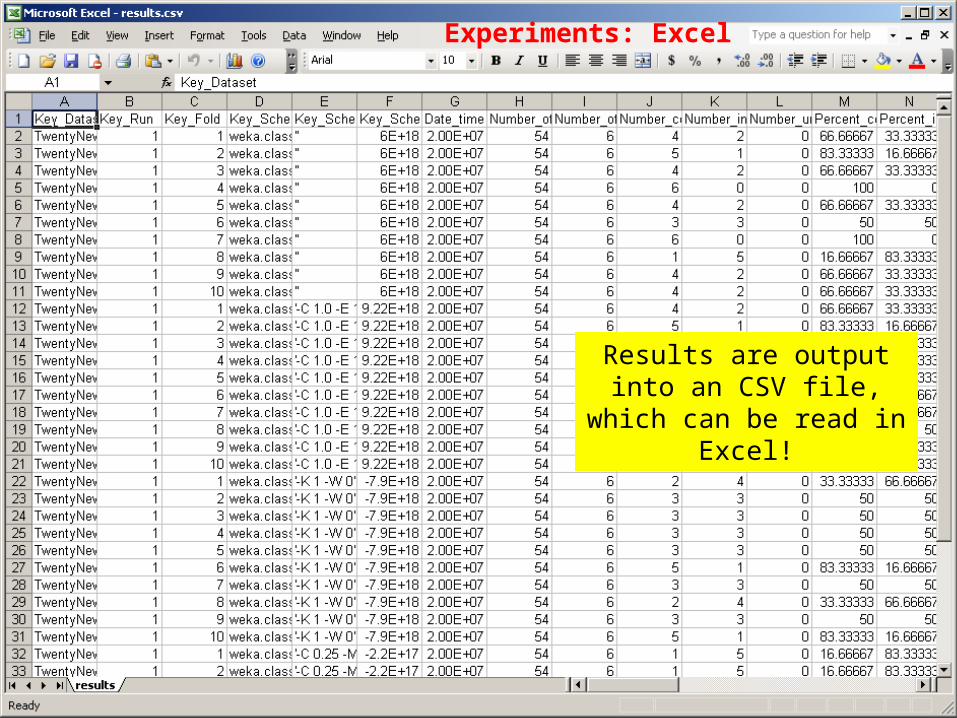
Experiments: Excel
Results are output into an CSV file, which can
be read in Excel!

59
The Newsgroups Text Collection
WEKA: Explorer
WEKA: Experimenter
Python Interface to WEKA

60Slide adapted from Eibe Frank's
@relation heart-disease-simplified
@attribute age numeric@attribute sex { female, male}@attribute chest_pain_type { typ_angina, asympt, non_anginal, atyp_angina}@attribute cholesterol numeric@attribute exercise_induced_angina { no, yes}@attribute class { present, not_present}
@data63,male,typ_angina,233,no,not_present67,male,asympt,286,yes,present67,male,asympt,229,yes,present38,female,non_anginal,?,no,not_present...
WEKA File Format: ARFF
Other attribute types:
• String
• Date
Numerical attribute
Nominal attribute
Missing value

61
Value 0 is not represented explicitlySame header (i.e @relation and @attribute tags)the @data section is different
Instead of @data
0, X, 0, Y, "class A"0, 0, W, 0, "class B"
We have
@data
{1 X, 3 Y, 4 "class A"} {2 W, 4 "class B"}
This is especially useful for textual data (why?)
WEKA File Format: Sparse ARFF

62
Python Interface to WEKA
This is just to get you startedAssumes the newsgroups collectionExtracts simple features
currently just single word features– Uses a simple tokenizer which removes punctuation
uses a stoplist lowercases the words
Includes filtering code currently eliminates numbers
Features are weighted by frequency within document
Produces a sparse ARFF file to be used by WEKA

63
Python Interface to WEKA
Allows you to specify: Which directory to read files from which newsgroups to use the number of documents for training each newsgroup the number of features to retain

64
Python Interface to WEKA
Things to (optionally) add or change: an option to not use stopwords an option to retain capitalization regular expression pattern a feature should match other non-word-based features morphological normalization a minimum threshold for the number of time a term
occurs before it can be counted as a feature tf.idf weighting on terms your idea goes here

65
Python Interface to WEKA
TF.IDF: tij log(N/ni) TF– tij: frequency of term i in document j
– this is how features are currently weighted
IDF: log(N/ni)
– ni: number of documents containing term i
– N: total number of documents

66
Python Weka Code

67
Python Weka Code

68
Python Weka Code

69
Python Weka Code

70
Python Weka Code

71
Python Weka Code

72
Python Weka Code

73
Python Weka Code

74
ARFF file
…
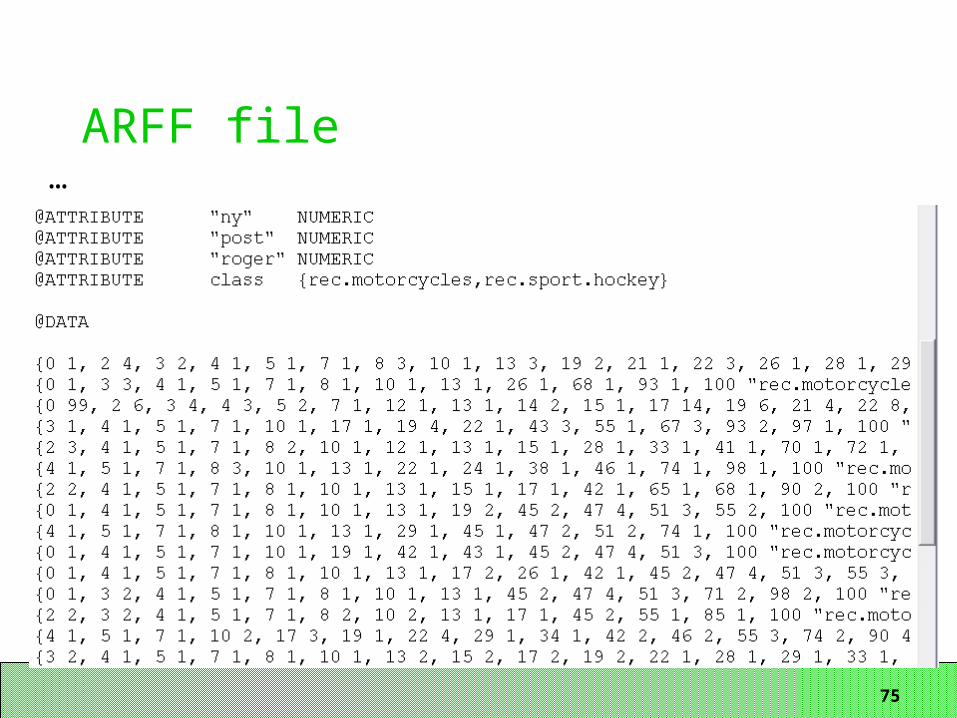
75
ARFF file…

76
Assignment
Due November 13.Work individually on this oneObjective is to use the training set to get the best features and learning model you can.FREEZE this.Then run one time only on the test set.This is a realistic way to see how well your algorithm does on unseen data.

77
Next Time
Machine learning algorithms

















