26
1 TMT.AOS.PRE.13.086.DRF01 Design and Testing of GPU Server based RTC for TMT NFIRAOS Lianqi Wang AO4ELT3 Florence, Italy 5/31/2013 Thirty Meter Telescope Project
| Date post: | 31-Dec-2015 |
| Category: |
Documents |
| Upload: | rudolf-thompson |
| View: | 217 times |
| Download: | 0 times |

1TMT.AOS.PRE.13.086.DRF01
Design and Testing of GPU Server based RTC for TMT NFIRAOS
Lianqi Wang
AO4ELT3 Florence, Italy 5/31/2013
Thirty Meter Telescope Project

2TMT.AOS.PRE.13.086.DRF01
Part of the on-going RTC architecture trade study for NFIRAOS– Handle MCAO and NGS SCAO Mode– Iterative algorithms
Hardware: FPGA, GPU, etc.– Matrix Vector Multiply (MVM) algorithm
Made possible by using GPUs to compute the control matrix
Hardware: GPU, Xeon Phi, or just CPUS
In this talk– GPU server based RTC design– Benchmarking the 10 GbE interface and the whole real time chain– Updating the control matrix as seeing changes
Introduction

3TMT.AOS.PRE.13.086.DRF01
LGS WFS Reconstruction:– Processing pixels from 6 order 60x60 LGS WFS
2896 subapertures per WFS.
Average 70 pixels per sub-aps.(0.4MB per WFS, 2.3MB total)
CCD read out: 0.5 ms.– Compute DM commands from gradients
6981 active (7673 total) DM actuators from 35k grads
Using Iterative algorithms or matrix vector multiply (MVM).– At 800 Hz. All has to finish in ~1.25ms
This talk focuses on MVM, in GPUs.
Most Challenging Requirements
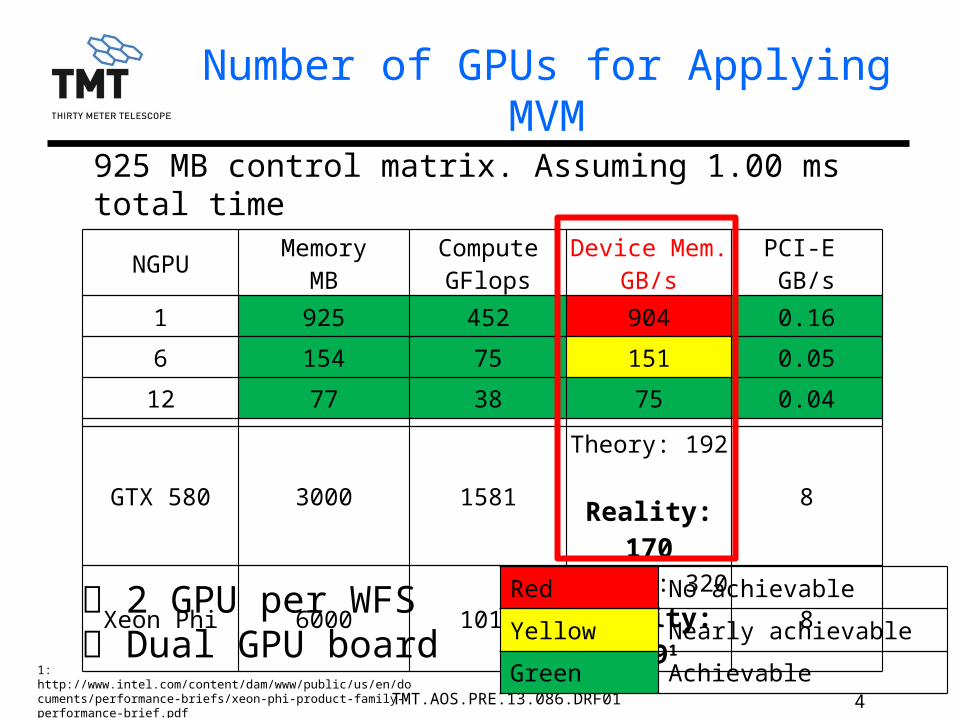
4TMT.AOS.PRE.13.086.DRF01
Number of GPUs for Applying MVM
NGPUMemory
MBComputeGFlops
Device Mem. GB/s
PCI-E GB/s
1 925 452 904 0.16
6 154 75 151 0.05
12 77 38 75 0.04
GTX 580 3000 1581Theory: 192 Reality: 170 8
Xeon Phi 6000 1011Theory: 320
Reality: 1591 8
Red No achievable
Yellow Nearly achievable
Green Achievable
925 MB control matrix. Assuming 1.00 ms total time
2 GPU per WFS Dual GPU board
1: http://www.intel.com/content/dam/www/public/us/en/documents/performance-briefs/xeon-phi-product-family-performance-brief.pdf
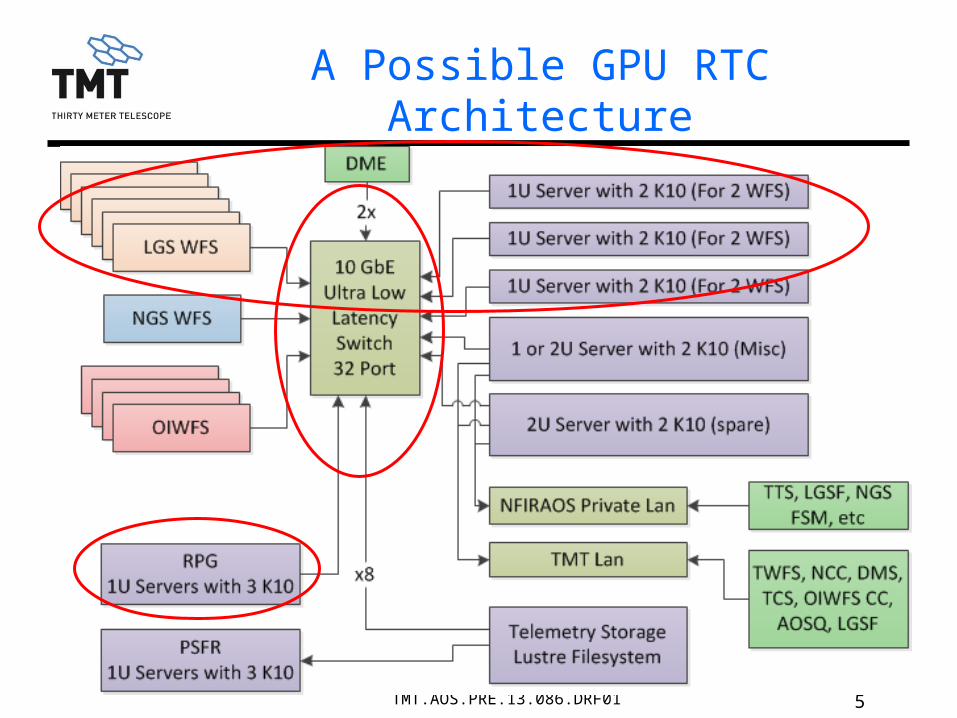
5TMT.AOS.PRE.13.086.DRF01
A Possible GPU RTC Architecture

6TMT.AOS.PRE.13.086.DRF01
10GbE surpasses the requirement of 800 MB/s– Widely deployed– Low cost
Alternatives:– sFPDP, Camera Link, etc
Testing with our Emulex 10 GbE PCI-E Board– Plain TCP/IP– No special feature
LGS WFS to RTC Interface
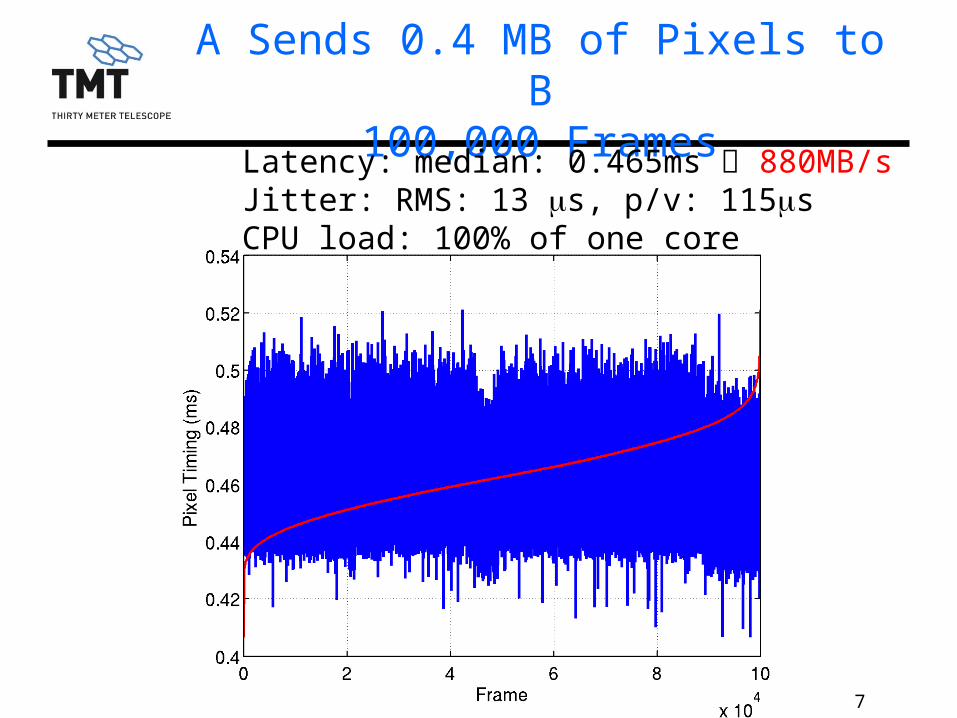
7TMT.AOS.PRE.13.086.DRF01
A Sends 0.4 MB of Pixels to B100,000 Frames
Latency: median: 0.465ms 880MB/sJitter: RMS: 13 ms, p/v: 115msCPU load: 100% of one core
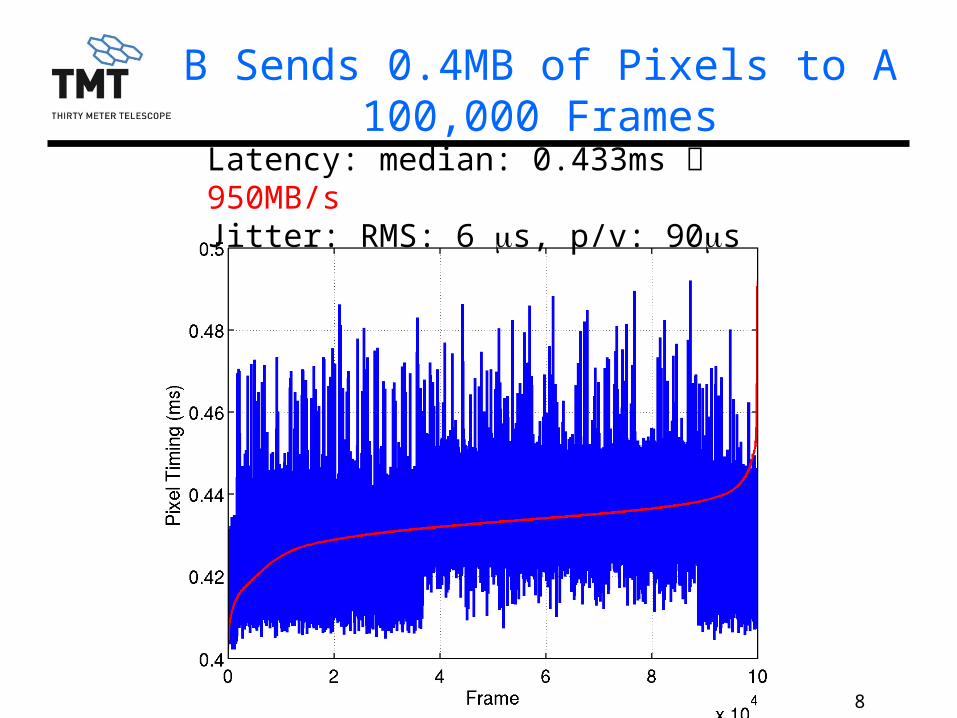
8TMT.AOS.PRE.13.086.DRF01
B Sends 0.4MB of Pixels to A100,000 Frames
Latency: median: 0.433ms 950MB/sJitter: RMS: 6 ms, p/v: 90ms
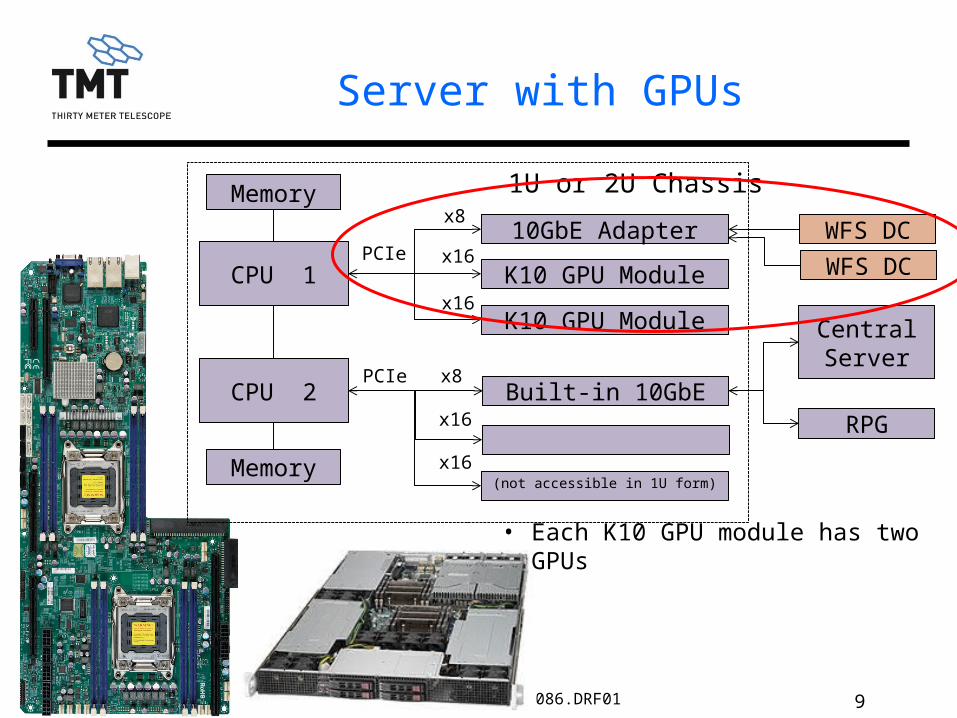
9TMT.AOS.PRE.13.086.DRF01
Server with GPUs
• Each K10 GPU module has two GPUs
CPU 1
CPU 2
K10 GPU Module
K10 GPU Module
10GbE AdapterPCIe
x8
x16
x16
Memory
Memory
Built-in 10GbEPCIe
WFS DC
1U or 2U Chassis
RPG
Central Server
WFS DC
(not accessible in 1U form)
x8
x16
x16
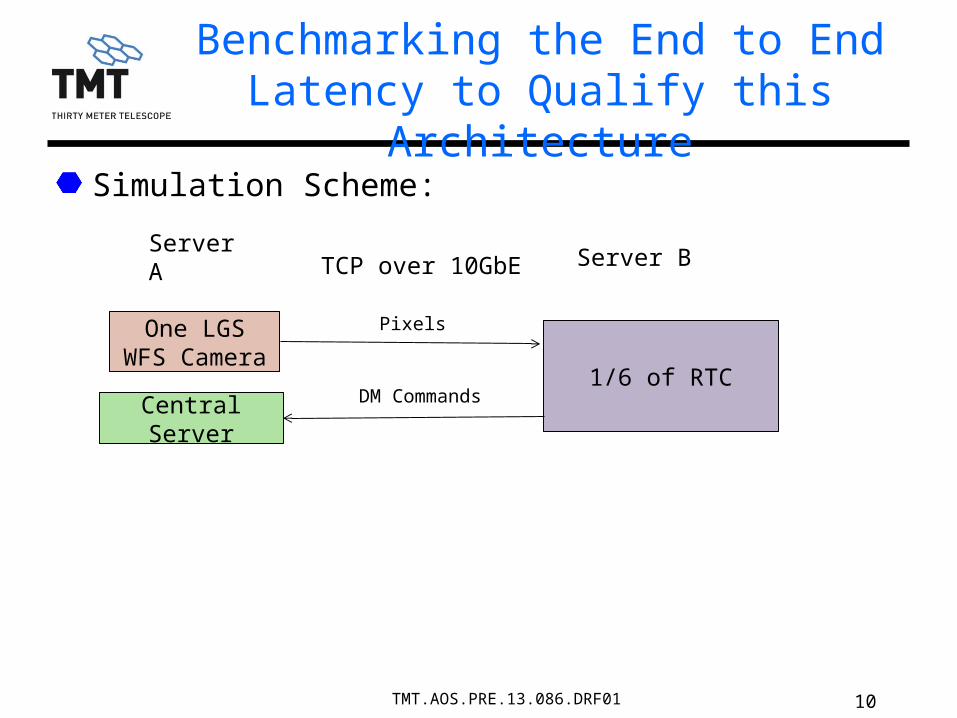
10TMT.AOS.PRE.13.086.DRF01
Simulation Scheme:
Benchmarking the End to End Latency to Qualify this Architecture
One LGS WFS Camera
1/6 of RTC
Server A
Central Server
Server B TCP over 10GbE
Pixels
DM Commands

11TMT.AOS.PRE.13.086.DRF01
Hardware– Server A: Dual Xeon W5590 @3.33Ghz– Server B: Intel Core i7 3820 @ 3.60 GHz
Two NVIDIA GTX 580 GPU board
or One NVIDIA GTX 590 dual GPU board– Emulex OCe11102-NX PCIe 2.0 10Gbase-CR
Connected back to back
Benchmarking Hardware Configuration

12TMT.AOS.PRE.13.086.DRF01
Servers optimization for low latency– Runs real time preempt Linux kernel (rt-linux-3.6)
CPU affinity set to core 0.
Lock all memory pages
Scheduler: SCHED_FIFO at maximum priority
Priority: -18– Disable hyper-threading– Disable virtualization technology and Vt-d in bios (critical)– Disable all non-essential services– No other tasks running
CUDA 4.0 C runtime library
Vanilla TCP/IP
Benchmarking Software Configuration
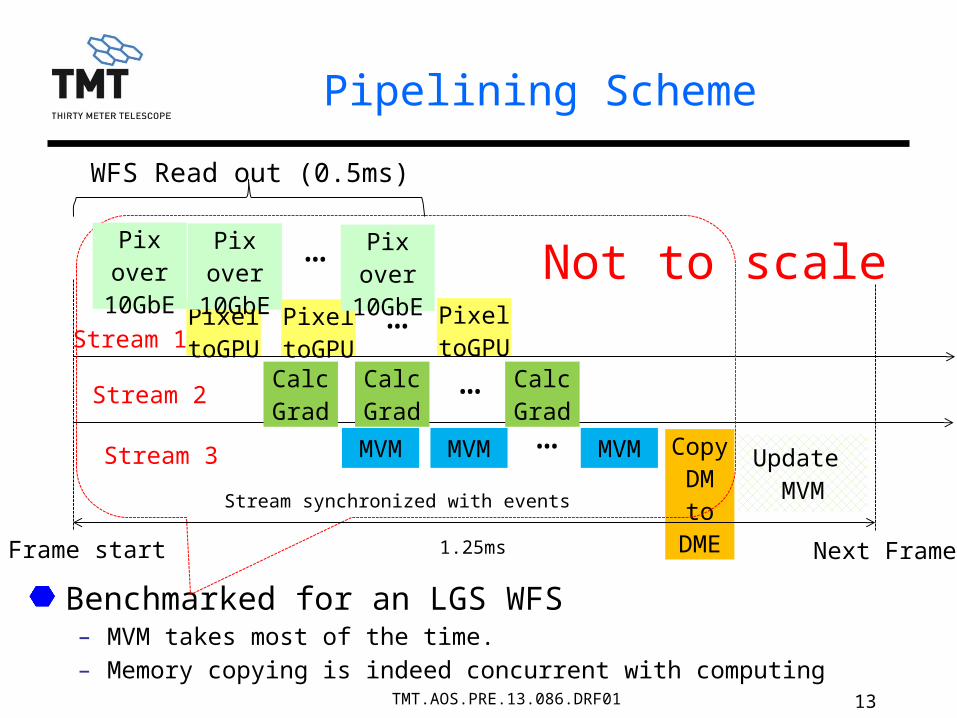
13TMT.AOS.PRE.13.086.DRF01
Benchmarked for an LGS WFS– MVM takes most of the time.– Memory copying is indeed concurrent with computing
Pipelining Scheme
Calc Grad
MVM Copy DM to DME
Update MVM
Calc Grad
Calc Grad
MVM MVM
…
…
Pixel toGPU
Pixel toGPU
Pixel toGPU
…
Frame start Next Frame
WFS Read out (0.5ms)
1.25ms
Pix over 10GbE
Pix over 10GbE
Pix over 10GbE
… Not to scale
Stream 1
Stream 2
Stream 3
Stream synchronized with events
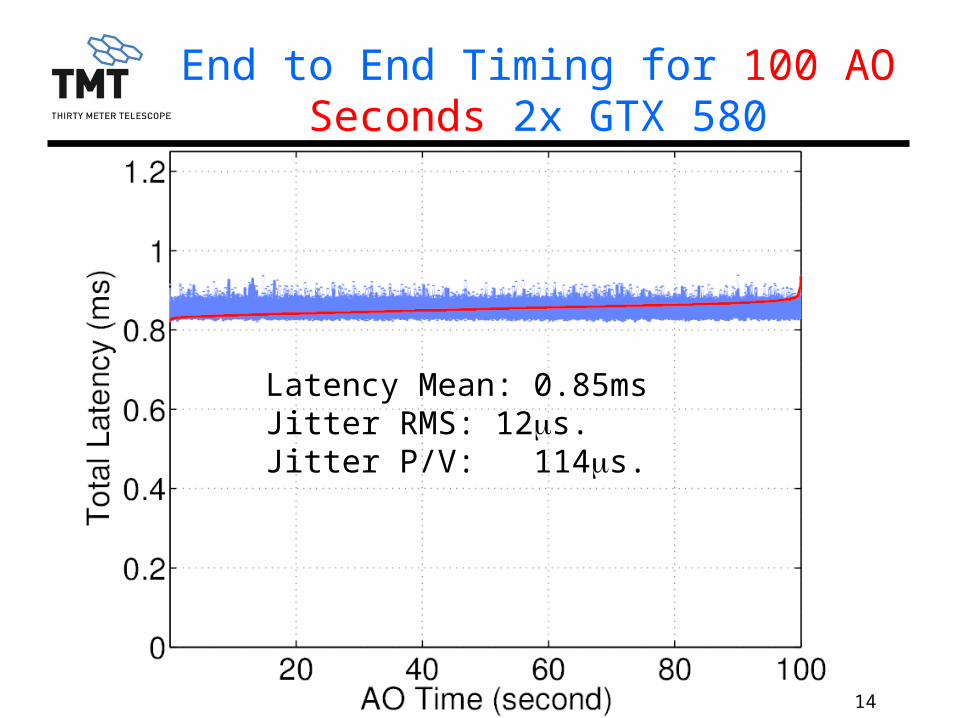
14TMT.AOS.PRE.13.086.DRF01
End to End Timing for 100 AO Seconds 2x GTX 580
Latency Mean: 0.85msJitter RMS: 12ms. Jitter P/V: 114ms.
15TMT.AOS.PRE.13.086.DRF01
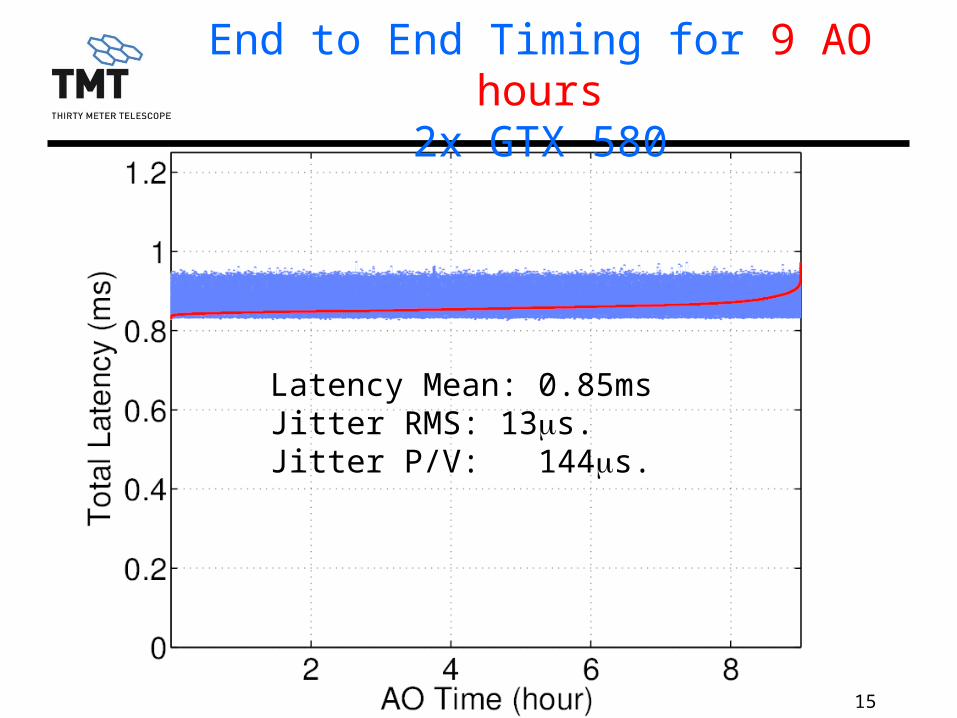
End to End Timing for 9 AO hours2x GTX 580
Latency Mean: 0.85msJitter RMS: 13ms. Jitter P/V: 144ms.
16TMT.AOS.PRE.13.086.DRF01
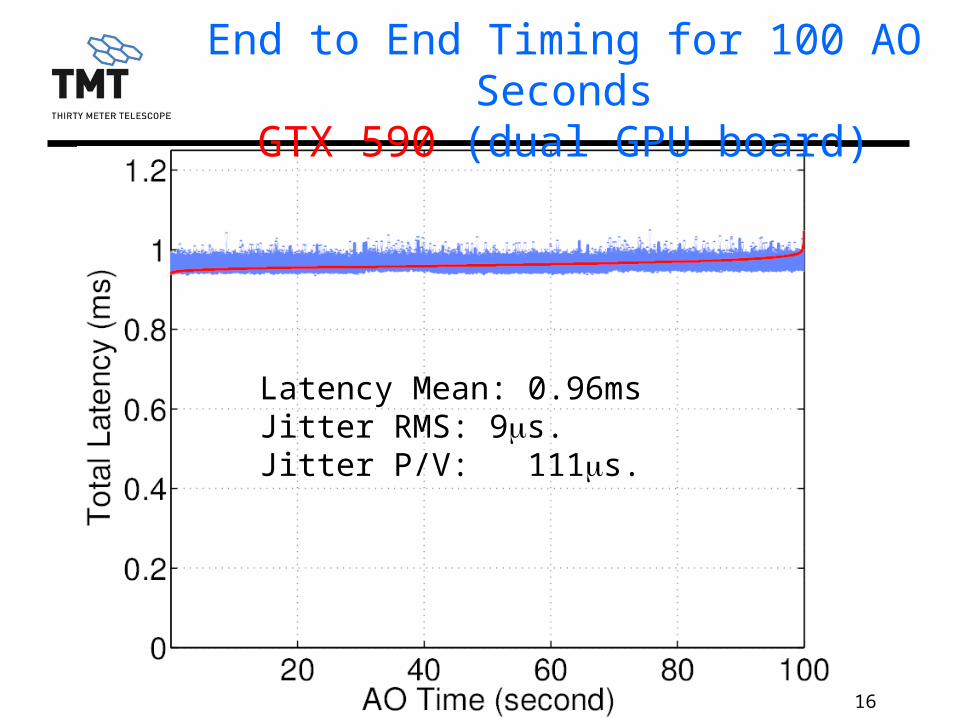
End to End Timing for 100 AO SecondsGTX 590 (dual GPU board)
Latency Mean: 0.96msJitter RMS: 9ms. Jitter P/V: 111ms.

17TMT.AOS.PRE.13.086.DRF01
For one LGS WFS– With 1 Nvidia GTX 590 board and 10 GbE interface– <1 ms from end of exposure to DM command ready
Pixel read out and transport (0.5ms)
Gradient computation
MVM computation
RTC is made up of 6 such subsystems
And one more for soft real-time or background task.
Plus one more for (online) spare.
Summary

18TMT.AOS.PRE.13.086.DRF01
by solving the minimum variance reconstructor in GPUs.
(34752x6981)=(34752x62311) x(62311x62311)-1
x(62311x6981) x(6981x6981)-1
Cn2 profile is used for regularization– It needs to be updated frequently– Control matrix need to be updated, using warm restart FDPCG
how many iterations?
Benchmarking results of iterative algorithms in GPUs
Compute the Control Matrix
19TMT.AOS.PRE.13.086.DRF01
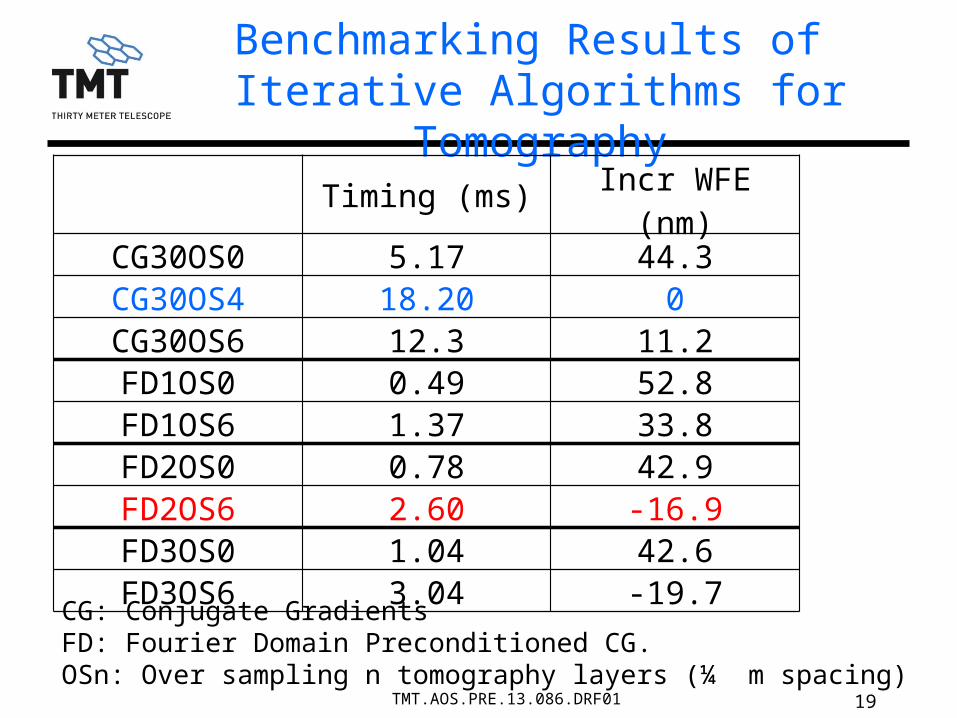
Benchmarking Results of Iterative Algorithms for Tomography
CG: Conjugate GradientsFD: Fourier Domain Preconditioned CG. OSn: Over sampling n tomography layers (¼ m spacing)
Timing (ms) Incr WFE (nm)CG30OS0 5.17 44.3CG30OS4 18.20 0CG30OS6 12.3 11.2FD1OS0 0.49 52.8FD1OS6 1.37 33.8FD2OS0 0.78 42.9FD2OS6 2.60 -16.9FD3OS0 1.04 42.6FD3OS6 3.04 -19.7

20TMT.AOS.PRE.13.086.DRF01
Tony Travouillon (TMT) computed covariance function of Cn2 profile from 5 years of site testing data– One function per layer. Independent between layers– Measurement has minimum separation of 1 minute– Interpolate the covariance to finer time scale
Generate Cn2 profile time series at 10 second separation– Pick a case every 500 seconds (60 total for 8 hour duration)– Run MAOS simulations (2000 time steps) with
Initializing control matrix with “true” Cn2 profile– FD100 Cold (start)
Update control matrix using results from 10 seconds earlier– FD10 or FD20 Warm (restart)
How Often to Update the Reconstructor?
21TMT.AOS.PRE.13.086.DRF01
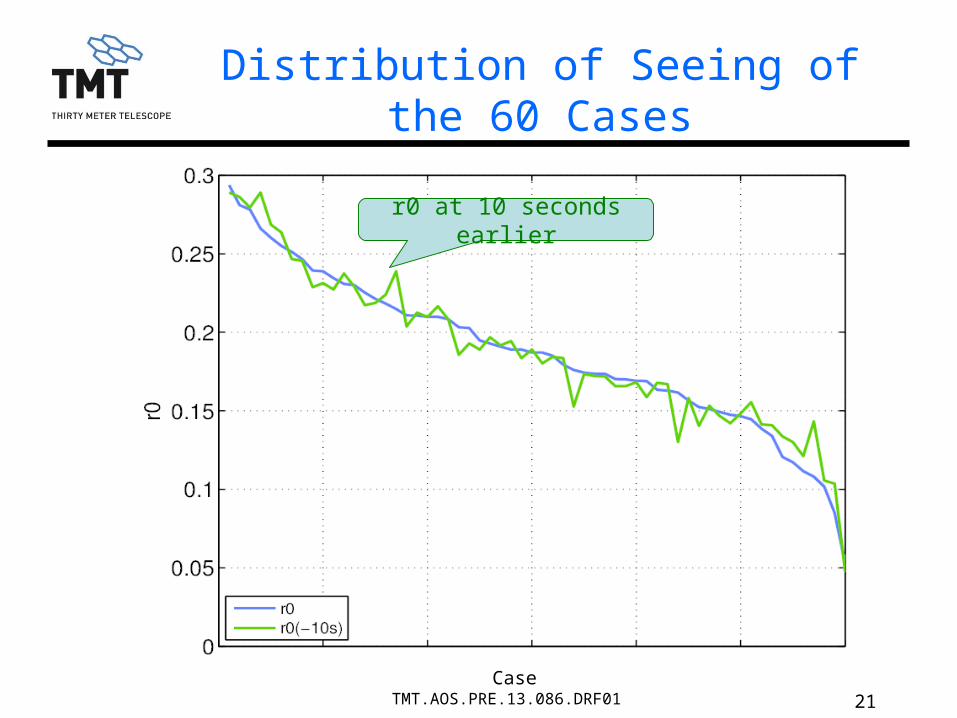
Distribution of Seeing of the 60 Cases
Case
r0 at 10 seconds earlier
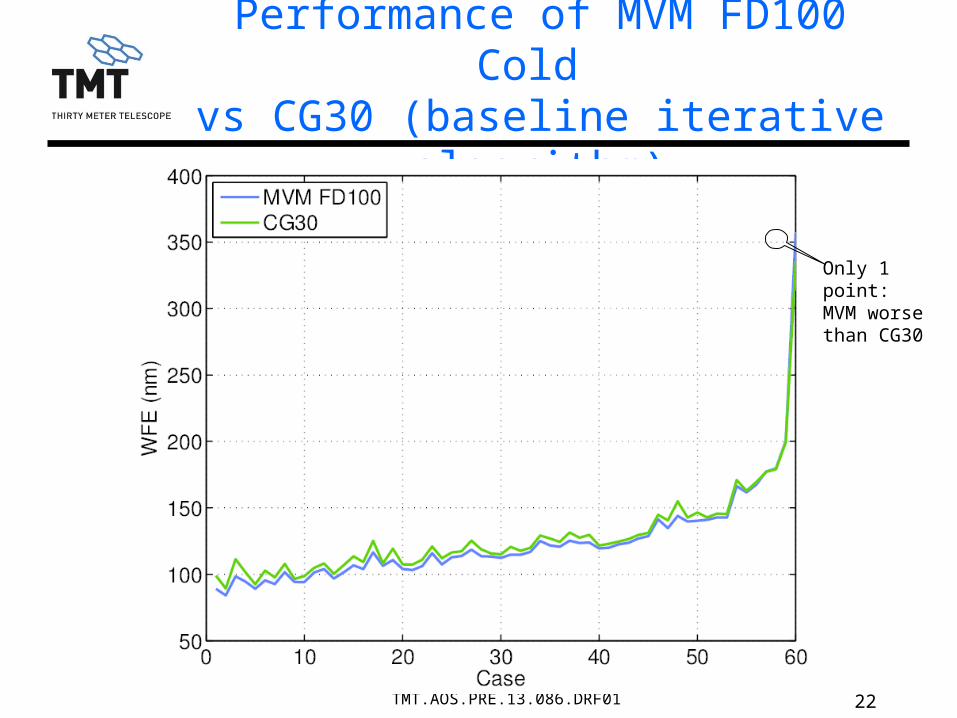
22TMT.AOS.PRE.13.086.DRF01
Performance of MVM FD100 Cold vs CG30 (baseline iterative algorithm)
Only 1 point: MVM worse than CG30
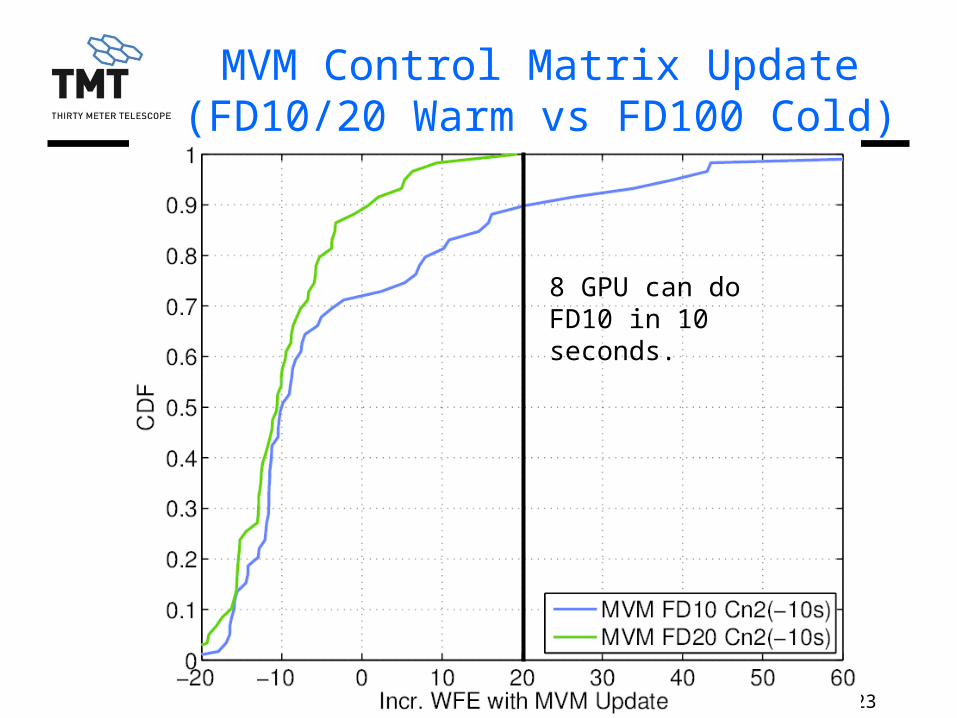
23TMT.AOS.PRE.13.086.DRF01
MVM Control Matrix Update(FD10/20 Warm vs FD100 Cold)
8 GPU can do FD10 in 10 seconds.

24TMT.AOS.PRE.13.086.DRF01
We demonstrated that end to end hard real time process of the RTC can be done using 10 GbE and GPUs– Pixel transfer over 10GbE– Gradient computation and MVM in 1 GPU board per WFS– Total latency is 0.95 ms. P/V jitter is ~0.1 ms.
Control matrix update– Largely sufficient with FD10 warm restart for 10 second stale
Cn2 profile.
Conclusions

25TMT.AOS.PRE.13.086.DRF01
Acknowledgements
The author gratefully acknowledges the support of the TMT collaborating institutions. They are
– the Association of Canadian Universities for Research in Astronomy (ACURA), – the California Institute of Technology, – the University of California, – the National Astronomical Observatory of Japan, – the National Astronomical Observatories of China and their consortium partners, – and the Department of Science and Technology of India and their supported institutes.
This work was supported as well by – the Gordon and Betty Moore Foundation, – the Canada Foundation for Innovation, – the Ontario Ministry of Research and Innovation, – the National Research Council of Canada,– the Natural Sciences and Engineering Research Council of Canada, – the British Columbia Knowledge Development Fund, – the Association of Universities for Research in Astronomy (AURA) – and the U.S. National Science Foundation.

26TMT.AOS.PRE.13.086.DRF01
Copying updated MVM matrix to RTC– Do so after DM actuator commands are ready– Measured 0.1 ms for 10 columns– 579 time steps to copy 5790 columns.
Collect statistics to update matched filter coefficients– Do so after DM actuator commands are ready or in CPUs
Complete before next frame arrives.
Other tasks
















