59
1 Web Mining and Privacy Bettina Berendt K.U. Leuven, Belgium www.berendt.d e
| Date post: | 18-Dec-2015 |
| Category: |
Documents |
| Upload: | melvin-jennings |
| View: | 216 times |
| Download: | 0 times |

1
Web Mining
and
Privacy
Bettina BerendtK.U. Leuven, Belgium
www.berendt.de

2
About me: (Some of) my public and mine-able profile
: Information Systems: Computer Science / Cognitive Science: Artificial Intelligence: Business Science: Economics
: Computer Science

3
Agenda
What is Web Mining?
The good: Web Mining for supporting Web users
The bad: Web Mining for surveillance?!
The WM deployment process
The reverse: Web Mining for watching back
The repair?: “Privacy-preserving data mining" et al.
The hidden: Distributed collaborative filtering
Whose privacy?

5
Agenda
What is Web Mining?
The good: Web Mining for supporting Web users
The bad: Web Mining for surveillance?!
The WM deployment process
The reverse: Web Mining for watching back
The repair?: “Privacy-preserving data mining" et al.
The hidden: Distributed collaborative filtering
Whose privacy?

6
Web Mining
Knowledge discovery (aka Data mining):
“the non-trivial process of identifying valid, novel, potentially useful, and ultimately understandable patterns in data.” 1
Web Mining: the application of data mining techniques on the content, (hyperlink) structure, and usage of Web resources. Web mining areas:
Web content mining
Web structure mining
Web usage mining
1 Fayyad, U.M., Piatetsky-Shapiro, G., Smyth, P., & Uthurusamy, R. (Eds.) (1996). Advances in Knowledge Discovery and Data Mining. Boston, MA: AAAI/MIT Press
Navigation, queries, content access & creation

7
Agenda
What is Web Mining?
The good: Web Mining for supporting Web users
The bad: Web Mining for surveillance?!
The WM deployment process
The reverse: Web Mining for watching back
The repair?: “Privacy-preserving data mining" et al.
The hidden: Distributed collaborative filtering
Whose privacy?

8
Content (1) - Classification

9
Content (2) – Clustering
10
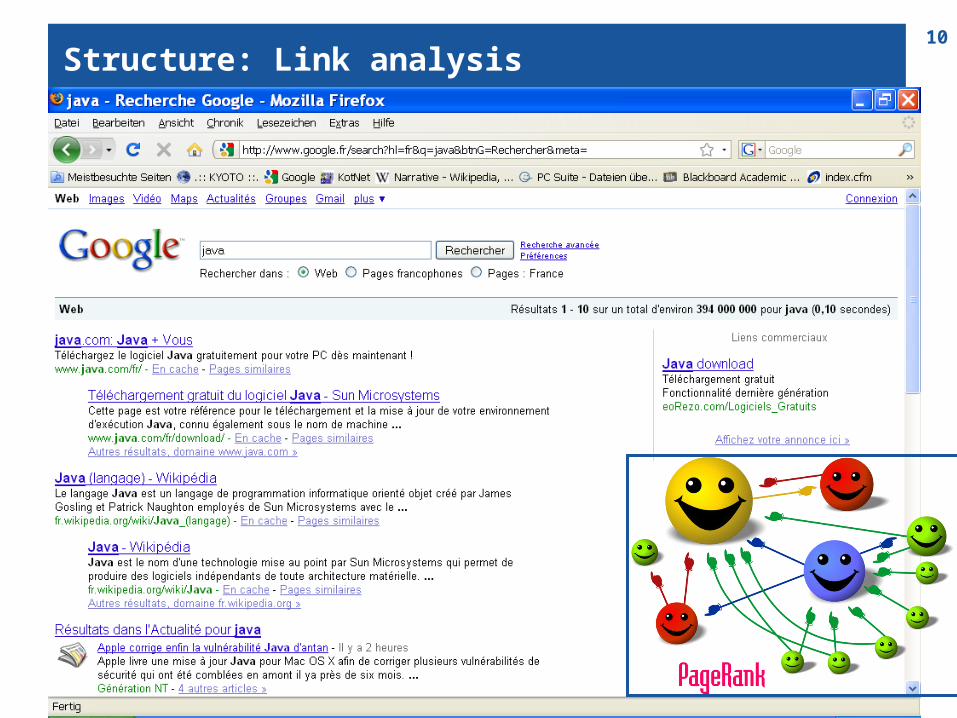
Structure: Link analysis
11
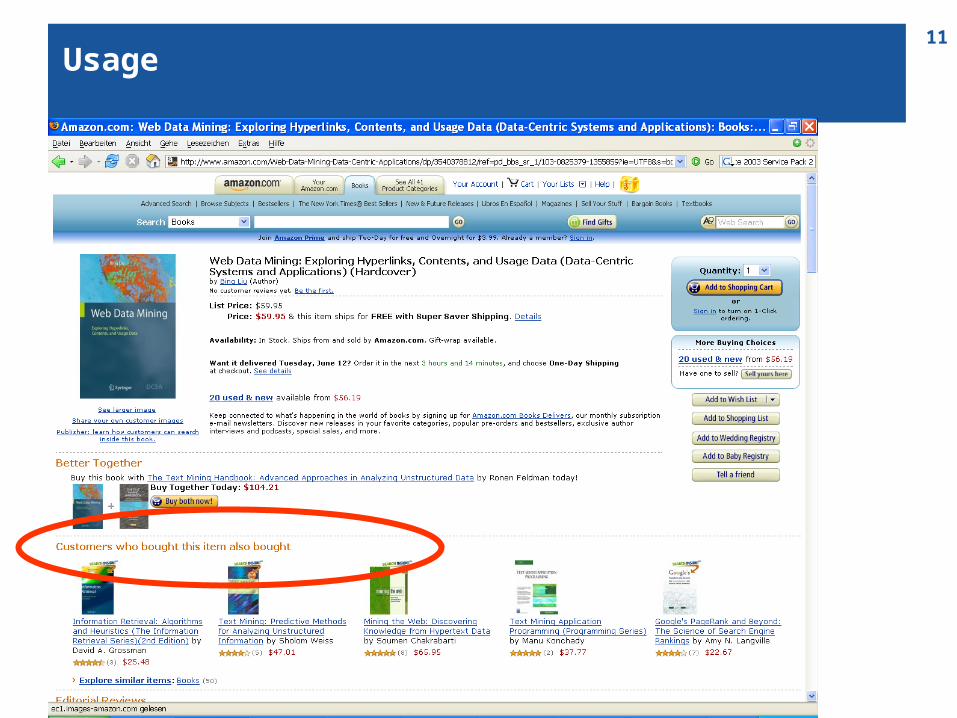
Usage

12
Agenda
What is Web Mining?
The good: Web Mining for supporting Web users
The bad: Web Mining for surveillance?!
The WM deployment process
The reverse: Web Mining for watching back
The repair?: “Privacy-preserving data mining" et al.
The hidden: Distributed collaborative filtering
Whose privacy?

13
Is this lady interested in singles bars?

14
Is this the same person?

15
Is this an extremist Web site?

16
Re-identification

17
„The story“

18
Usage data: her queries (sample from an anonymized search-query log)
http://www.nytimes.com/2006/08/09/technology/09aol.html

19
Usage (2): Automated analysis

23
Merging identities

24
Keeping identities apart – the basic setting
Paper published by the MovieLens team (collaborative-filtering movie ratings) who were considering publishing a ratings dataset, see http://movielens.umn.edu/
Public dataset: users mention films in forum posts
Private dataset (may be released e.g. for research purposes): users‘ ratings
Film IDs can easily be extracted from the posts
Observation: Every user will talk about items from a sparse relation space (those – generally few – films s/he has seen)
[Frankowski, D., Cosley, D., Sen, S., Terveen, L., & Riedl, J. (2006). You are what you say: Privacy risks of public mentions. In Proc. SIGIR‘06]

25
Keeping identities apart – the computational problem
Given a target user t from the forum users, find similar users (in terms of which items they related to) in the ratings dataset
Rank these users u by their likelihood of being t
Evalute:
If t is in the top k of this list, then t is k-identified
Count percentage of users who are k-identified
E.g. measure likelihood by TF.IDF (m: item)

27
Results

28
What do you think helps?

29
Classifying extremists

30
Structure

31
Procedure behind this social network analysis
Zhou, Reid, Qin, Chen, and Lai (2005). IEEE Intelligent Systems.

32
Agenda
What is Web Mining?
The good: Web Mining for supporting Web users
The bad: Web Mining for surveillance?!
The WM deployment process
The reverse: Web Mining for watching back
The repair?: “Privacy-preserving data mining" et al.
The hidden: Distributed collaborative filtering
Whose privacy?

33
Whose mining? Whose privacy?
Web usage
(in the widest sense)
Knowledge
Web mining
Data/Information
Web mining
Data/Information

34
Agenda
What is Web Mining?
The good: Web Mining for supporting Web users
The bad: Web Mining for surveillance?!
The WM deployment process
The reverse: Web Mining for watching back
The repair?: “Privacy-preserving data mining" et al.
The hidden: Distributed collaborative filtering
Whose privacy?

35
Who am I?

36
How do embattled politicians minimize their responsibility?
I acknowledgethat mistakes
were made here(just not be me)

37
Why is atomic energy safe?

38
Knowing what‘s out there
39
Content (1): „What‘s known about me?“
... and what follows from it?
Awareness tools (see presentations next Monday: Geerts/Gürses)

40
Content (2)
“... I want to make three brief points about the resignations of the eight United States' attorneys, a topic that I know is foremost in your minds. First, those eight attorneys deserved better. ... Each is a fine lawyer and dedicated professional. I regret how they were treated, and I apologize to them and to their families for allowing this matter to become an unfortunate and undignified public spectacle. I accept full responsibility for this. Second, I want to address allegations that I have failed to tell the truth about my involvement in these resignations. These attacks on my integrity have been very painful to me. ...“

41
... but ...... but ...[Method: Learning a trie from the string sequences]
http://services.alphaworks.ibm.com/manyeyes/view/SgoRsIsOtha6bhEf6arzI2-

42Content (3): Going further in analysing implicit messages:What differentiates news souces?
[Fortuna, Galleguillos, & Cristianini, 2007, http://patterns.enm.bris.ac.uk/publications/media-bias#]
[Method: Nearest neighbour / best reciprocal hit for document matching;Kernel Canonical Correlation Analysisand vector operationsfor finding topics and characteristic keywords]

43
Content (4) and structure

44
Atomic energy is safe?- Structure and usage

45
How was the information sent?

46
Tracing anonymous editshttp://wikiscanner.virgil.gr/

47
[Method: Attribute matching]

48
Results (an example)

49
Agenda
What is Web Mining?
The good: Web Mining for supporting Web users
The bad: Web Mining for surveillance?!
The WM deployment process
The reverse: Web Mining for watching back
The repair?: “Privacy-preserving data mining" et al.
The hidden: Distributed collaborative filtering
Whose privacy?

50
Recall: Whose mining? Whose privacy?
Web usage
(in the widest sense)
Knowledge
Web mining
Data/Information

51
A solution?
Web usage
(in the widest sense)
Web mining
Data/Information
Privacy-preservingKnowledge(No or less)

52
Agenda
What is Web Mining?
The good: Web Mining for supporting Web users
The bad: Web Mining for surveillance?!
The WM deployment process
The reverse: Web Mining for watching back
The repair?: “Privacy-preserving data mining" et al.
The hidden: Distributed collaborative filtering
Whose privacy?

53
Collaborative filtering: basic idea[for specialistis: the model-based variant]
Basic idea of collaborative filtering: „Users who liked this also liked ...“ generalize from „similar profiles“
Standard solution:
At the community site / centralized:
Compute, from all users and their ratings/purchases, etc., a global model
To derive a recommendation for a given user: find „similar profiles“ in this model and derive a prediction
Mathematically: depends on simple vector computations in the user-item space

54Distributed data mining / secure multi-party computation:
The principle explained by secure sum Given a number of values x1,...,xn belonging to n entities
compute xi
such that each entity ONLY knows its input and the result of the computation (The aggregate sum of the data)

55
Canny: Collaborative filtering with privacy
Each user starts with their own preference data, and knowledge of who their peers are in their community.
By running the protocol, users exchange various encrypted messages.
At the end of the protocol, every user has an unencrypted copy of the linear model Λ, ψ of the community’s preferences.
They can then use this to extrapolate their own ratings
At no stage does unencypted information about a user’s preferences leave their own machine.
Users outside the community can request a copy of the model Λ, ψ from any community member, and derive recommendations for themselves
Canny (2002), Proc. IEEE Symp. Security and Privacy; Proc. SIGIR

56
Agenda
What is Web Mining?
The good: Web Mining for supporting Web users
The bad: Web Mining for surveillance?!
The WM deployment process
The reverse: Web Mining for watching back
The repair?: “Privacy-preserving data mining" et al.
The hidden: Distributed collaborative filtering
Whose privacy?

57
„Privacy roles“: the Canny case
=

58
„Privacy roles“: The general case
§
$
Data ownersData subjects Data users

59
Privacy roles and research areas[modified classification based on Domingo-Ferrer, Secure Data Mgt. 2007] Data subject P: a data owner wants to make a database available to
third parties, but want to avoid that data subjects be re-identified. Solutions mainly come from statistical disclosure control.
Data owner P: 2 or more data owners want to compute something and agree to the results being shared, but do not want to disclose the data.
Solutions mainly come from privacy-preserving data mining (PPDM) and from secure multi-party computation, the latter also known as (a form of) PPDM.
“Hippocratic databases” and negative databases are a solution approach to address both DSP and DOP.
Data user P: a user wants to query a database, but does not want to be profiled based on these queries.
Solutions mainly come from private information retrieval
All 3 types of privacy can exist independently of each other!

60
Example: Data subject privacy without data owner privacy
All patients in the dataset suffered from hypertension before starting the treatment.
Direct identifiers have been suppressed.
Height and weight are key attributes: an intruder can easily gauge the height and weight of an individual he knows so as to link her identity to a record in the dataset.
The remaining attributes (systolic blood pressure and AIDS) are confidential attributes.
The dataset spontaneously satisfies 3-anonymity for the key attributes height andweight.
If 3-anonymity is enough protection for patients, release of the dataset results does not harm respondent privacy but it harms owner privacy.

61
Example: Data owner privacy without data subject privacy
This dataset is no longer 3-anonymous with respect to key attributes height and weight.
Releasing a single record is a violation of respondent privacy: the patient’s blood pressure and AIDS condition can be linked to her identity and her hypertension is leaked out.
However, neither revealing a single record nor the name of someone who took part in the trial can be said to violate the data owner’s privacy (especially if the dataset is large).

62
AND ... Don‘t forget:
data mining is a process! need to also consider: re-purposing, collusion by
insiders, data combination, different/new mining
algorithms, ...

63
Elements of a solution
Data sparsity
Web mining
Web mining
Distributed computing Restrictions(computational, legal)
Awareness
(whoever)

64
Thank you!














![1 Bettina Berendt KU Leuven, Dept. of Computer Science, Hypermedia & Databases berendt 3 December 2007 [updated version] Intelligent.](https://static.documents.pub/doc/80x56/56649e5c5503460f94b53c9e/1-bettina-berendt-ku-leuven-dept-of-computer-science-hypermedia-databases.jpg)


