63
From Hadoop to Spark 1/2 Dr. Fabio Fumarola
| Date post: | 28-Jul-2015 |
| Category: |
Data & Analytics |
| Upload: | fabio-fumarola |
| View: | 2,417 times |
| Download: | 3 times |

From Hadoop to Spark1/2
Dr. Fabio Fumarola

Contents• Aggregate and Cluster• Scatter Gather and MapReduce• MapReduce • Why Spark?• Spark:
– Example, task and stages– Docker Example– Scala and Anonymous Functions
• Next Topics in 2/2
2

Aggregates and Clusters• Aggregate-oriented databases change the rules for
data storage (CAP)• But running on a cluster changes also computation
models• When you store data on a cluster you can process
data in parallel
3

Database vs Client Processing • With a centralized database data can be processed
on the database server or on the client machine• Running on the client:
– Pros: flexibility and programming languages– Cons: data transfer from the server to the client
• Running on the server:– Pros: Data locality– Cons: programming languages and debugging
4

Cluster and Computation• We can spread the computation across the cluster• However, we have to reduce the amount of data
transferred over the network• We need have computation locality• That is process the data in the same node where is
stored
5

Scatter-Gather
6
Use a Scatter-Gather that broadcasts a message to multiple recipients and re-aggregates the responses back into a single message.
2003

Map-Reduce• It is a way to organize processing by taking advantage
of clusters• It gained prominence with Google’s MapReduce
framework (Dean and Ghemawat 2004)• It was then implemented in Hadoop Framework
7
http://research.google.com/archive/mapreduce.html
https://hadoop.apache.org/

Programming Model: MapReduce
• We have a huge text document• Count the number of times each distinct word
appears in the file• Sample applications
– Analyze web server logs to find popular URLs – Term statistics for search
8

Word Count• Assumption: the input file is too large for memory,
but all <word, count> pairs fit in memory• We can compute the pairs by
– wc file.txt | sort | uniq -c
• Encyclopedia Britannica, 11th Edition, Volume 4, Part 3 (http://www.gutenberg.org/files/19699/19699.zip)
9

Word Count Stepswc file.txt | sort | uniq –c
•Map• Scan input file record-at-a-time• Extract keys from each record
•Group by key• Sort and shuffle
•Reduce• Aggregate, summarize, filter or transform• Write the results
10

MapReduce: Logical Steps
• Map
• Group by Key
• Reduce
11

Map Phase
12

Group and Reduce Phase
13
Partition and shuffling

MapReduce: Word Counting
14

Word Count with MapReduce
15

Example: Language Model• Count the number of times each 5-word sequence
occurs in a large corpus of documents• Map
– Extract <5-word sequence, count> pairs from each document
• Reduce– Combine the counts
16

MapReduce: Physical Execution
17

Physical Execution: Concerns• Mapper intermediate results are send to a single
reduces: – This is the only steps that require a communication over
the network
• Thus the Partition and Shuffle phase are critical
18

Partition and Shuffle Reducing the cost of these steps, dramatically reduces the cost in time of the computation:•The Partitioner determines which partition a given (key, value) pair will go to.•The default partitioner computes a hash value for the key and assigns the partition based on this result.•The Shuffler moves map outputs to the reducers.
19

MapReduce: Features• Partioning the input data• Scheduling the program’s execution across a set of
machines• Performing the group by key step • Handling node failures• Managing required inter-machine communication
20

HadoopMapReduce
21

Hadoop• An Open-Source software for distributed storage of large
dataset on commodity hardware• Provides a programming model/framework for processing
large dataset in parallel
22
Map
Map
Map
Reduce
Reduce
Input Output

Hadoop: Architecture
23

Distributed File System• Data is kept in “chunks” spread across machines• Each chink is replicated on different machines
(Persistence and Availability)
24

Distributed File System• Chunk Servers
– File is split into contiguous chunks (16-64 MB)– Each chunk is replicated 3 times– Try to keep replicas on different machines
• Master Node– Name Node in Hadoop’s HDFS– Stores metadata about where files are stored– Might be replicated
25

Hadoop’s Limitations
26

Limitations of Map Reduce
• Slow due to replication, serialization, and disk IO• Inefficient for:
– Iterative algorithms (Machine Learning, Graphs & Network Analysis)– Interactive Data Mining (R, Excel, Ad hoc Reporting, Searching)
27
Input iter. 1iter. 1 iter. 2iter. 2 . . .
HDFSread
HDFSwrite
HDFSread
HDFSwrite
Map
Map
Map
Reduce
Reduce
Input Output

Solutions?• Leverage to memory:
– load Data into Memory– Replace disks with SSD
28

Apache Spark• A big data analytics cluster-computing framework written in
Scala.• Open Sourced originally in AMPLab at UC Berkley• Provides in-memory analytics based on RDD• Highly compatible with Hadoop Storage API
– Can run on top of an Hadoop cluster
• Developer can write programs using multiple programming languages
29

Spark architecture
30
HDFS
Datanode Datanode Datanode....Spark
WorkerSpark
WorkerSpark
Worker....
CacheCache CacheCache CacheCache
Block Block Block
Cluster Manager
Spark Driver (Master)

Hadoop Data Flow
31
iter. 1iter. 1 iter. 2iter. 2 . . .
Input
HDFSread
HDFSwrite
HDFSread
HDFSwrite

Spark Data Flow
32
iter. 1iter. 1 iter. 2iter. 2 . . .
Input
Not tied to 2 stage Map Reduce paradigm
1. Extract a working set2. Cache it3. Query it repeatedly
Logistic regression in Hadoop and Spark
HDFSread

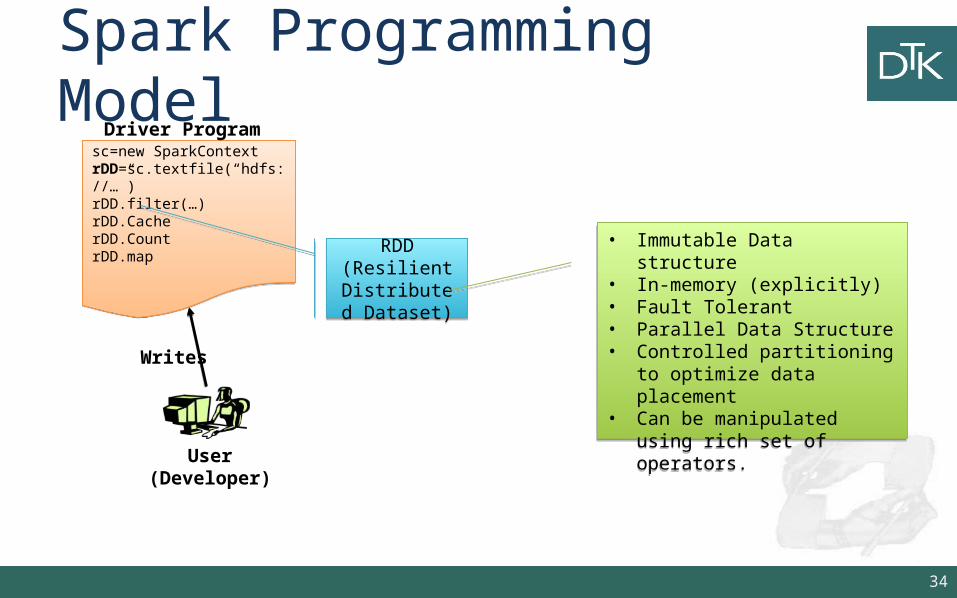
Spark Programming Model
33
Datanode
HDFS
Datanode…User
(Developer)
Writes
sc=new SparkContextrDD=sc.textfile(“hdfs://…”)rDD.filter(…)rDD.CacherDD.CountrDD.map
sc=new SparkContextrDD=sc.textfile(“hdfs://…”)rDD.filter(…)rDD.CacherDD.CountrDD.map
Driver Program
SparkContextSparkContext Cluster ManagerCluster
Manager
Worker Node
ExecuterExecuter CacheCache
TaskTask TaskTask
Worker Node
ExecuterExecuter CacheCache
TaskTask TaskTask
Spark Programming Model
34
User (Developer)
Writes
sc=new SparkContextrDD=sc.textfile(“hdfs://…”)rDD.filter(…)rDD.CacherDD.CountrDD.map
sc=new SparkContextrDD=sc.textfile(“hdfs://…”)rDD.filter(…)rDD.CacherDD.CountrDD.map
Driver Program
RDD(Resilient
Distributed Dataset)
RDD(Resilient
Distributed Dataset)
• Immutable Data structure• In-memory (explicitly)• Fault Tolerant• Parallel Data Structure• Controlled partitioning to
optimize data placement• Can be manipulated using rich set
of operators.
• Immutable Data structure• In-memory (explicitly)• Fault Tolerant• Parallel Data Structure• Controlled partitioning to
optimize data placement• Can be manipulated using rich set
of operators.

RDD• Programming Interface: Programmer can perform 3 types of
operations
35
Transformations
•Create a new dataset from and existing one.
•Lazy in nature. They are executed only when some action is performed.
•Example :• Map(func)• Filter(func)• Distinct()
Transformations
•Create a new dataset from and existing one.
•Lazy in nature. They are executed only when some action is performed.
•Example :• Map(func)• Filter(func)• Distinct()
Actions
•Returns to the driver program a value or exports data to a storage system after performing a computation.
•Example:• Count()• Reduce(funct)• Collect• Take()
Actions
•Returns to the driver program a value or exports data to a storage system after performing a computation.
•Example:• Count()• Reduce(funct)• Collect• Take()
Persistence
•For caching datasets in-memory for future operations.
•Option to store on disk or RAM or mixed (Storage Level).
•Example:• Persist() • Cache()
Persistence
•For caching datasets in-memory for future operations.
•Option to store on disk or RAM or mixed (Storage Level).
•Example:• Persist() • Cache()

How Spark works• RDD: Parallel collection with partitions• User application create RDDs, transform them, and
run actions.• This results in a DAG (Directed Acyclic Graph) of
operators.• DAG is compiled into stages• Each stage is executed as a series of Task (one Task
for each Partition).
36

Example
37
sc.textFile(“/wiki/pagecounts”) RDD[String]
textFile

Example
38
sc.textFile(“/wiki/pagecounts”).map(line => line.split(“\t”))
RDD[String]
textFile map
RDD[List[String]]

Example
39
sc.textFile(“/wiki/pagecounts”).map(line => line.split(“\t”)).map(R => (R[0], int(R[1])))
RDD[String]
textFile map
RDD[List[String]]RDD[(String, Int)]
map

Example
40
sc.textFile(“/wiki/pagecounts”).map(line => line.split(“\t”)).map(R => (R[0], int(R[1]))).reduceByKey(_+_)
RDD[String]
textFile map
RDD[List[String]]RDD[(String, Int)]
map
RDD[(String, Int)]
reduceByKey

Example
41
sc.textFile(“/wiki/pagecounts”).map(line => line.split(“\t”)).map(R => (R[0], int(R[1]))).reduceByKey(_+_, 3).collect()
RDD[String]RDD[List[String]]RDD[(String, Int)]
RDD[(String, Int)]
reduceByKey
Array[(String, Int)]
collect

Execution Plan
Stages are sequences of RDDs, that don’t have a Shuffle in between
42
textFile map map reduceByKey
collect
Stage 1 Stage 2

Execution Plan
43
textFile map map reduceByKey
collect
Stage 1
Stage 2
Stage 1
Stage 2
1. Read HDFS split2. Apply both the maps3. Start Partial reduce4. Write shuffle data
1. Read shuffle data2. Final reduce3. Send result to driver
program

Stage Execution
• Create a task for each Partition in the new RDD• Serialize the Task• Schedule and ship Tasks to Slaves
And all this happens internally (you need to do anything)
44
Task 1
Task 2
Task 2
Task 2

Spark Executor (Slaves)
45
Fetch Input
Execute Task
Write Output
Fetch Input
Execute Task
Write Output
Fetch Input
Execute Task
Write Output
Fetch Input
Execute Task
Write Output
Fetch Input
Execute Task
Write Output
Fetch Input
Execute Task
Write Output
Fetch Input
Execute Task
Write Output
Core 1
Core 2
Core 3

Summary of Components
• Task : The fundamental unit of execution in Spark
• Stage: Set of Tasks that run parallel
• DAG : Logical Graph of RDD operations
• RDD : Parallel dataset with partitions
46

Start the docker containerFrom•https://github.com/sequenceiq/docker-spark docker pull sequenceiq/spark:1.3.0
docker run -i -t -h sandbox sequenceiq/spark:1.3.0-ubuntu /etc/ bootstrap.sh bash
•Run the spark shell using yarn or localspark-shell --master yarn-client --driver-memory 1g --executor-memory 1g --executor-cores 2
47

Separate Container Master/Worker$ docker pull snufkin/spark-master$ docker pull snufkin/spark-worker
•These images are based on snufkin/spark-base
$ docker run … master$ docker run … worker
48

Running the example and Shell• To Run an example
$ run-example SparkPi 10
• We can start a spark shell via–spark-shell -- master local n
• The -- master specifies the master URL for a distributed cluster
• Example applications are also provided in Python–spark-submit example/src/main/python/pi.py 10
49

Scala Base Course - Start
50

Scala vs Java vs Python• Spark was originally written in Scala, which allows
concise function syntax and interactive use• Java API added for standalone applications• Python API added more recently along with an
interactive shell.
51

Why Scala?• High-level language for the JVM
– Object oriented + functional programming
• Statistically typed– Type Inference
• Interoperates with Java– Can use any Java Class– Can be called from Java code
52

Quick Tour of Scala
53

Laziness• For variables we can define lazy val, that are evaluated when
calledlazy val x = 10 * 10 * 10 * 10 //long computation
• For methods we can define call by value and call by name for the parameters
def square(x: Double) // call by valuedef square(x: => Double) // call by name
• It changes the order the parameter are evaluated
54

Anonymous functions
55
scala> val square = (x: Int) => x * xsquare: Int => Int = <function1>
We define an anonymous function from Int to Int
The square is a val square of type Function1, which is equivalent to
scala> def square(x: Int) = x * xsquare: (x: Int)Int

Anonymous Functions(x: Int) => x * x
This is a syntactic sugar for
new Function1[Int ,Int] { def apply(x: Int): Int = x * x}
56

CurryingConverting a function with multiple arguments into a function with a single argument that returns another function.
def gen(f: Int => Int)(x: Int) = f(x)def identity(x: Int) = gen(i => i)(x)def square(x: Int) = gen(i => i * i)(x)def cube(x: Int) = gen(i => i * i * i)(x)
57

Anonymous Functions//Explicit type declaration val call1 = doWithOneAndTwo((x: Int, y: Int) => x + y)
//The compiler expects 2 ints so x and y types are inferred val call2 = doWithOneAndTwo((x, y) => x + y)
//Even more concise syntax val call3 = doWithOneAndTwo(_ + _)
58

Returning multiple variablesdef swap(x:String, y:String) = (y, x)val (a,b) = swap("hello","world")println(a, b)
59

High Order FunctionsMethods that take as parameter functionsval list = (1 to 4).toListlist.foreach( x => println(x))list.foreach(println)
list.map(x => x + 2)list.map(_ + 2)list.filter(x => x % 2 == 1)list.filter(_ % 2 == 1)
list.reduce((x,y) => x + y)list.reduce(_ + _)
60

Function Methods on Collections
61
http://www.scala-lang.org/api/2.11.6/index.html#scala.collection.Seq

Scala Base Course - Endhttp://scalatutorials.com/
62

Next Topics• Spark Shell
– Scala– Python
• Shark Shell• Data Frames• Spark Streaming• Code Examples: Processing and Machine Learning
63

















