14. Análisis de regresión lineal múltiple En capítulos anteriores tratamos el análisis de regresión simple que trata de relacionar una variable explicativa cuantitativa con una variable respuesta cuantitativa. Todos los elementos de ese capítulo nos van a servir ahora para continuar con el caso más general y de mayor utilidad práctica, que es la regresión lineal múltiple. Por regresión lineal múltiple entenderemos el análisis de regresión lineal pero ahora con más de una variable explicativa. Datos para regresión múltiple Los datos para regresión lineal simple consisten en pares de observaciones (x i , y i ) de dos variables cuantitativas. Ahora tendremos múltiples variables explicativas, por lo que la notación será más elaborada. Llamaremos x ij el valor de la j-ésima variable del i-ésimo sujeto o unidad (i=1,2,...,n ; j=1,2,...,p). Los datos se pueden organizar de la siguiente forma en una base: 1 x 11 x 12 .. . x 1p y 1 2 x 21 x 22 .. . x 2p y 2 : n x n1 x n2 .. . x np y n Donde n es el número de casos o tamaño muestral y p es el número de variables explicatorias. Esta es una forma de organizar la base de datos, no importa el orden de las variables. Modelo de regresión lineal múltiple: El modelo estadístico de regresión lineal múltiple es: para i= 1, 2, ...,n La respuesta media es una función lineal de las variables explicatorias: 1
Transcript
14. Análisis de regresión lineal múltiple
En capítulos anteriores tratamos el análisis de regresión simple que trata de relacionar una variable explicativa cuantitativa con una variable respuesta cuantitativa. Todos los elementos de ese capítulo nos van a servir ahora para continuar con el caso más general y de mayor utilidad práctica, que es la regresión lineal múltiple. Por regresión lineal múltiple entenderemos el análisis de regresión lineal pero ahora con más de una variable explicativa.
Datos para regresión múltiple
Los datos para regresión lineal simple consisten en pares de observaciones (xi, yi) de dos variables cuantitativas. Ahora tendremos múltiples variables explicativas, por lo que la notación será más elaborada. Llamaremos xij el valor de la j-ésima variable del i-ésimo sujeto o unidad (i=1,2,...,n ; j=1,2,...,p). Los datos se pueden organizar de la siguiente forma en una base:
1 x11 x12 ... x1p y1
2 x21 x22 ... x2p y2
:n xn1 xn2 ... xnp yn
Donde n es el número de casos o tamaño muestral y p es el número de variables explicatorias. Esta es una forma de organizar la base de datos, no importa el orden de las variables.
Modelo de regresión lineal múltiple:
El modelo estadístico de regresión lineal múltiple es:
para i= 1, 2, ...,n
La respuesta media es una función lineal de las variables explicatorias:
Las desviaciones son independientes y normalmente distribuidas con media 0 y desviación estándar :
Los parámetros del modelo son: y , los coeficiente de regresión y la estimación de la variabilidad, es decir son en total (p + 2) parámetros.
Si suponemos que la respuesta media está relacionada con los parámetros a través de la ecuación:, esto quiere decir que podemos estimar la media de la variable
respuesta a través de la estimación de los parámetros de regresión. Si esta ecuación se ajusta a la realidad entonces tenemos una forma de describir cómo la media de la variable respuesta y varía con las variables explicatorias .Estimación de los parámetros de regresión múltiple.
1
En regresión lineal simple usamos el método de mínimos cuadrados para obtener estimadores del intercepto y de la pendiente. En regresión lineal múltiple el principio es el mismo, pero necesitamos estimar más parámetros.
Llamaremos a los estimadores de los parámetros
La respuesta estimada por el modelo para la i-ésima observación es:
El i-ésimo residuo es la diferencia entre la respuesta observada y la predicha:
residuo =
El i-ésimo residuo =
El método mínimos cuadrados elige los valores de los estimadores óptimos, es decir, que hacen la suma de cuadrados de los residuos menor posible. En otras palabras, los parámetros estimados minimizan la diferencia entre la respuesta observada y la respuesta estimada, lo que equivale a minimizar: .
La fórmula de los estimadores de mínimos cuadrados para regresión múltiple se complica porque necesitamos notación matricial, sin embargo estamos a salvo si entendemos el concepto y dejaremos a SPSS hacer los cálculos.
El parámetro mide la variabilidad de la respuesta alrededor de la ecuación de regresión en la población. Como en regresión lineal simple estimamos como el promedio de los residuos al cuadrado:
La cantidad (n-p-1) son los grados de libertad asociados con la estimación de la variabilidad: es entonces el estimador de la variabilidad de la respuesta y, tomando en cuenta las variables
explicatorias xj.
Lo distinguimos de que es la variabilidad de y sin tomar en cuenta las variables
explicativas xj.
2
Pruebas de significancia e Intervalos de confianza para los coeficientes de regresión
Podemos obtener intervalos de confianza y test de hipótesis para cada uno de los coeficientes de regresión como lo hicimos en regresión simple. Los errores estándar de los estadísticos muestrales
tienen fórmulas más complicadas, así es que nuevamente dejaremos que SPSS haga su trabajo.
Test de hipótesis para :
Para docimar la hipótesis se usa el test t:
Donde es el error estándar de
Notas: - Vamos a dejar a SPSS el cálculo del error estándar de - Tendremos entonces un test de hipótesis asociado a cada variable explicatoria en el modelo.- Podemos realizar hipótesis de una cola, donde H1: o H1: , pero lo usual es hacer el
test bilateral.
Intervalo de confianza para :Un intervalo de confianza ( )*100% para está dado por:
donde es el percentil apropiado de la distribución t con (n-p-1) grados de libertad, es el
error estándar de
Intervalos de confianza para la respuesta media e intervalos de predicción individual:
Si queremos obtener intervalos de confianza para la respuesta media o intervalos de confianza para futuras observaciones en los modelos de regresión múltiple, las ideas básicas son las mismas que ya vimos en regresión simple y dejaremos el cálculo a SPSS.
3
Tabla de ANOVA para regresión múltiple
La tabla de análisis de varianza para la regresión múltiple es la siguiente:
Fuente de variación
glGrados de libertad
SCSuma de Cuadrados
CMCuadrados
Medios
Modelo p
Residuo
Total
La tabla ANOVA es similar a la de regresión simple. Los grados de libertad del modelo son ahora p en vez de 1, lo que refleja que ahora tenemos p variables explicatorias en vez de sólo una. Las sumas de cuadrados representan las fuentes de variación. Recordemos que la suma de cuadrados total es igual a la suma de los cuadrados del modelo de regresión más la suma de los cuadrados del residuo:
SCT = SCMod + SCRes
El estimador de la varianza de nuestro modelo está dado por la media cuadrática residual MCRes=SCRes/(n-p-1)
Estadístico FLa razón entre el cuadrado medio del modelo y el residuo , permite estimar si la relación entre las variables explicatorias y la respuesta es significativa. La hipótesis que docima el test F es:
La hipótesis nula dice que ninguna de las variables explicatorias son predictoras de la variable respuesta. La hipótesis alternativa dice que al menos una de las variables explicatorias está linealmente relacionada con la respuesta. Como en regresión simple, valores grandes de F nos dan evidencia en contra de hipótesis nula. Cuando H0 es verdadera, el estadístico F tiene distribución F de Fisher con (p, n-p-1) grados de libertad. Los grados de libertad están asociados a los grados de libertad del modelo y del residuo en la tabla ANOVA.
Recordemos que en regresión lineal simple el test F de la tabla ANOVA es equivalente al test t bilateral para la hipótesis de que la pendiente es cero. Ahora, el test F de regresión múltiple docima la hipótesis de que todos los coeficientes de regresión (con excepción del intercepto) son cero, hipótesis que no es de mucho interés. En el problema de regresión múltiple interesan más las hipótesis individuales para cada parámetro asociado a cada variable explicatoria.
4
Coeficiente de determinación (R2)
En regresión lineal simple vimos que el cuadrado del coeficiente de correlación era y se
podía interpretar como la proporción de la variabilidad de y que podía ser explicada por x. Un coeficiente similar se calcula en regresión múltiple:
Donde R2 es la proporción de la variabilidad de la variable respuesta y que es explicada por las variables explicatorias en la regresión lineal múltiple.A menudo se multiplica R2 por 100 y se expresa como porcentaje. La raíz cuadrada de R2 es el coeficiente de correlación múltiple, es la correlación entre las observaciones y los valores predichos
.
Coeficiente de determinación (R2) ajustadoCuando evaluamos un modelo de regresión lineal múltiple nos interesa decidir si una variable dada mejora la capacidad para predecir la respuesta comparando el R2 de un modelo que contiene la variable, con el R2 del modelo sin la variable. El modelo con mejor R2 debería ser el mejor modelo. Pero debemos ser cuidadosos cuando comparamos los coeficientes de determinación de dos modelos diferentes. La inclusión de una variable adicional en el modelo nunca provoca la reducción de R2. Para manejar este problema, podemos utilizar el R2 ajustado, que ajusta por el número de variables que hay en el modelo. El R2 ajustado es:
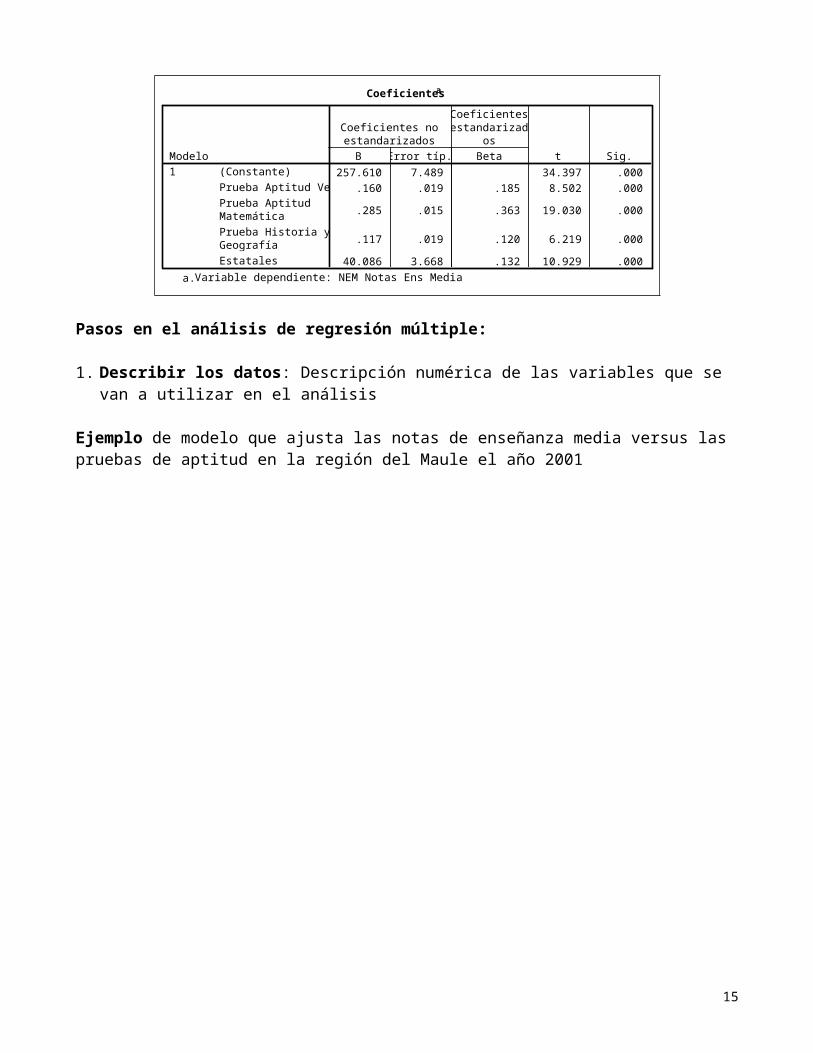
Un ejemploEn educación existe polémica acerca de las notas de los colegios que se creen están infladas. Si no estuvieran infladas esperaríamos que las pruebas de ingreso a la Universidad estén altamente correlacionadas con las notas de enseñanza media. Revisemos, con datos de la Prueba de Aptitud Académica (PAA) del año 2001 en la región del Maule, si podemos explicar las notas de enseñanza media con la PAA.
(Constante)Prueba Aptitud VerbalPrueba AptitudMatemáticaPrueba Historia yGeografía
Modelo1
B Error típ.
Coeficientes noestandarizados
Beta
Coeficientesestandarizad
os
t Sig. Límite inferiorLímite
superior
Intervalo de confianza paraB al 95%
Variable dependiente: NEM Notas Ens Mediaa.
Verificando supuestos en la regresión lineal múltiple
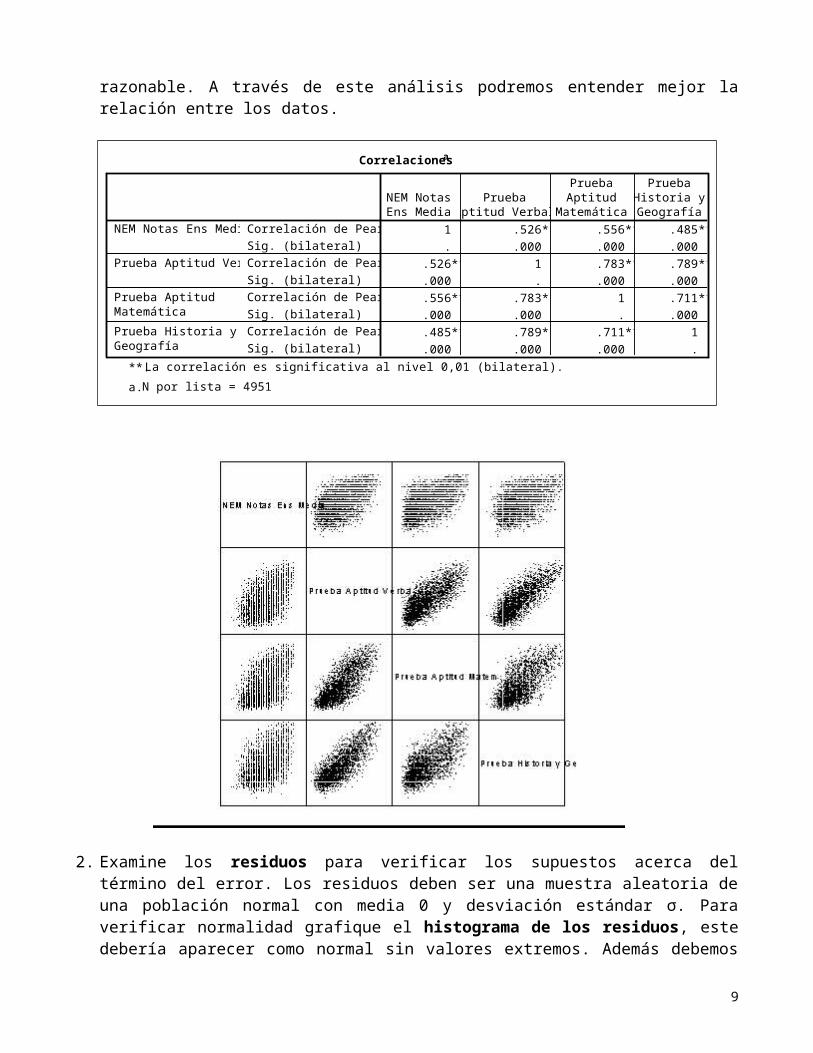
1. Examine los gráficos de dispersión entre la variable respuesta y versus las variables explicatorias x para investigar si la relación entre estas variables es lineal y por lo tanto si el modelo es razonable. A través de este análisis podremos entender mejor la relación entre los datos.
Correlacionesa
1 .526** .556** .485**. .000 .000 .000
.526** 1 .783** .789**
.000 . .000 .000
.556** .783** 1 .711**
.000 .000 . .000
.485** .789** .711** 1
.000 .000 .000 .
Correlación de PearsonSig. (bilateral)Correlación de PearsonSig. (bilateral)Correlación de PearsonSig. (bilateral)Correlación de PearsonSig. (bilateral)
NEM Notas Ens Media
Prueba Aptitud Verbal
Prueba AptitudMatemática
Prueba Historia yGeografía
NEM NotasEns Media
PruebaAptitud Verbal
PruebaAptitud
Matemática
PruebaHistoria yGeografía
La correlación es significativa al nivel 0,01 (bilateral).**.
N por lista = 4951a.
6
2. Examine los residuos para verificar los supuestos acerca del término del error. Los residuos deben ser una muestra aleatoria de una población normal con media 0 y desviación estándar σ. Para verificar normalidad grafique el histograma de los residuos, este debería aparecer como normal sin valores extremos. Además debemos revisar los residuos individuales para detectar valores extremos y/o influyentes. Por último debemos detectar si la distribución de los residuos es al azar y no hay formas que muestren un problema en el ajuste, o que la varianza no sea constante.
Regresión Residuo tipificado
3.002.50
2.001.50
1.00.500.00
-.50-1.00
-1.50-2.00
-2.50-3.00
Histograma de residuos
Notas de Enseñanza Media versus PAA
Frec
uenc
ia
500
400
300
200
100
0
Desv. típ. = 1.00
Media = 0.00
N = 4951.00
Gráfico P-P normal de regresión Residuo tipificado
ColinealidadAparte de los supuestos antes mencionados, siempre hay que verificar la presencia de colinealidad. La colinealidad ocurre cuando dos o más variables explicativas se relacionan entre sí, hasta el punto de que comunican esencialmente la misma información sobre la variación observada en y. Un síntoma de la existencia de colinealidad es la inestabilidad de los coeficientes calculados y sus errores estándares. En particular los errores estándares a menudo se tornan muy grandes; esto implica que hay un alto grado de variabilidad de muestreo en los coeficientes calculados.
Detección de multicolinealidad en el modelo de regresiónLos siguientes son indicadores de multicolinealidad:1. Correlaciones significativas entre pares de variables independientes en el modelo.2. Pruebas t no significativas para los parámetros individuales cuando la prueba F global del modelo
es significativa.3. Signos opuestos (a lo esperado) en los parámetros estimados.
8
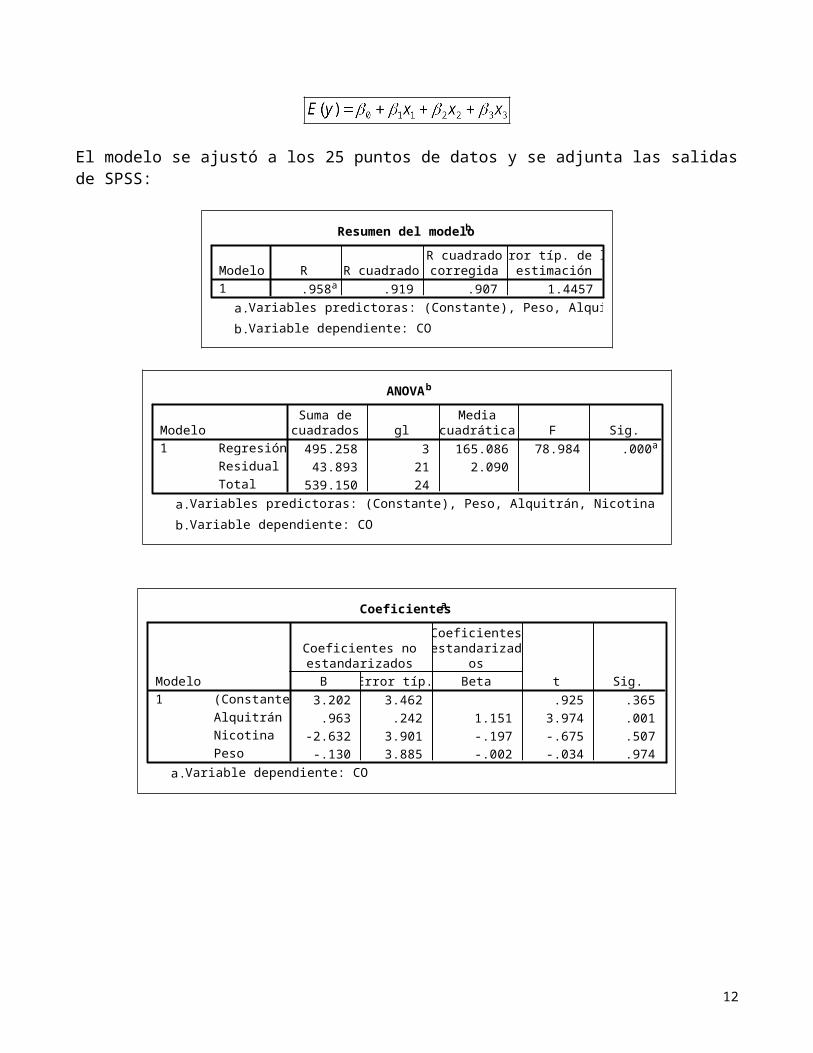
Ejemplo:La Comisión Federal de Comercio (Federal Trade Commission) de Estados Unidos clasifica anualmente las variedades de cigarrillos según su contenido de alquitrán, nicotina y monóxido de carbono. Se sabe que estas tres sustancias son peligrosas para la salud de los fumadores. Estudios anteriores han revelado que los incrementos en el contenido de alquitrán y nicotina de un cigarrillo van acompañados por un incremento en el monóxido de carbono emitido en el humo de cigarrillo. La base de datos CO_multiple.sav (en sitio del curso) contiene los datos sobre contenido de alquitrán (en miligramos), nicotina (en miligramos) y monóxido de carbono (en miligramos) y peso (en gramos) de una muestra de 25 marcas (con filtro) ensayadas en un año reciente. Suponga que se desea modelar el contenido de monóxido de carbono, y, en función del contenido de alquitrán, x1, el contenido de nicotina, x2, y el peso, x3, utilizando el modelo:
El modelo se ajustó a los 25 puntos de datos y se adjunta las salidas de SPSS:
Correlación de PearsonSig. (bilateral)Correlación de PearsonSig. (bilateral)Correlación de PearsonSig. (bilateral)Correlación de PearsonSig. (bilateral)
CO
Alquitrán
Nicotina
Peso
CO Alquitrán Nicotina Peso
La correlación es significativa al nivel 0,01 (bilateral).**.
La correlación es significante al nivel 0,05 (bilateral).*.
N por lista = 25a.
Selección de modelosComo regla general, normalmente es preferible incluir en un modelo de regresión sólo las variables explicativas que ayudan a predecir o explicar la variabilidad observada en la respuesta y, a este modelo lo llamamos parsimonioso. En consecuencia, si tenemos diversas variables explicativas potenciales, ¿cómo decidir cuáles se deben retener en el modelo y cuáles dejar afuera? Por lo general, la decisión se toma en base a una combinación de consideraciones estadísticas y no estadísticas. Es fundamental identificar o conocer cuáles variables podrían ser importantes. Sin embargo, para estudiar cabalmente el efecto de cada una de estas variables explicativas, sería necesario llevar a cabo análisis por separado de cada posible combinación de variables. Los modelos resultantes podrían evaluarse enseguida de acuerdo con algún criterio estadístico. Este es el método más completo, pero también el que ocupa más tiempo. Si tenemos una gran cantidad de variables explicativas el procedimiento podría no ser factible. Existen otros métodos paso a paso (stepwise en inglés) que son útiles, pero que hay que usarlos con cautela porque los resultados pudieran ser dependientes de los datos (la muestra) más que basados en el conocimiento del problema que estamos estudiando. Entonces la recomendación es buscar un equilibrio entre la tecnología, el conocimiento que tenemos de las variables y los resultados de la muestra.
Variables indicadorasLas variables explicativas que hemos considerado hasta este momento se midieron sobre una escala cuantitativa. Sin embargo, el análisis de regresión puede generalizarse para incluir asimismo, variables explicativas cualitativas. Por ejemplo, podríamos preguntarnos si las notas en la enseñanza media pueden ser explicadas además por la dependencia del establecimiento. Para simplificar supongamos que nos interesa solamente distinguir entre colegios particulares y municipales o subvencionados, esta variable tendría dos categorías. Puesto que las variables explicativas en un análisis de regresión deben tomar valores numéricos, designamos a los colegios estatales (municipales y subvencionados) con 1 y a los colegios particulares con 0. Estos números no representan mediciones reales; sencillamente identifican las categorías de la variable aleatoria nominal. Debido a que estos valores no tienen significado cuantitativo, una variable explicativa de esta clase se denomina variable indicadora o variable muda (en inglés dummy variable).
10
Resumen del modelo
.592a .350 .349 80.29730Modelo1
R R cuadradoR cuadradocorregida
Error típ. de laestimación
Variables predictoras: (Constante), Estatales, Prueba AptitudMatemática, Prueba Historia y Geografía, Prueba AptitudVerbal
(Constante)Prueba Aptitud VerbalPrueba AptitudMatemáticaPrueba Historia yGeografíaEstatales
Modelo1
B Error típ.
Coeficientes noestandarizados
Beta
Coeficientesestandarizad
ost Sig.
Variable dependiente: NEM Notas Ens Mediaa.
Pasos en el análisis de regresión múltiple:
1. Describir los datos: Descripción numérica de las variables que se van a utilizar en el análisis
Ejemplo de modelo que ajusta las notas de enseñanza media versus las pruebas de aptitud en la región del Maule el año 2001
11
Tabla del SPSS con descripción de variables cuantitativas:
Estadísticos descriptivos
561.6451 99.55509 4951471.9234 114.74092 4951
477.4286 126.43221 4951
483.8259 101.92995 4951
NEM Notas Ens MediaPrueba Aptitud VerbalPrueba AptitudMatemáticaPrueba Historia yGeografía
MediaDesviación
típ. N
Tabla con descripción de variable cualitativa:Dependencia Frecuencia %Estatales 4346 87,8Particular 605 12,2Total 4951 100,0
Descripción gráfica:
4951495149514951N =
Prueba Historia y Ge
Prueba Aptitud Matem
Prueba Aptitud Verba
NEM Notas Ens Media
900
800
700
600
500
400
300
200
100
Nota: En este caso podemos hacer gráficos de caja conjuntos porque todas las variables están medidas en la misma escala.
2. Verificar los supuestos:
- linealidad (y vs x)- no colinealidad (correlación entre las x)
12
Gráficos de dispersión
NEM Notas Ens Media
Prueba Aptitud Verba
Prueba Aptitud Matem
Prueba Historia y Ge
Correlacionesa
1 .526** .556** .485**. .000 .000 .000
.526** 1 .783** .789**
.000 . .000 .000
.556** .783** 1 .711**
.000 .000 . .000
.485** .789** .711** 1
.000 .000 .000 .
Correlación de PearsonSig. (bilateral)Correlación de PearsonSig. (bilateral)Correlación de PearsonSig. (bilateral)Correlación de PearsonSig. (bilateral)
NEM Notas Ens Media
Prueba Aptitud Verbal
Prueba AptitudMatemática
Prueba Historia yGeografía
NEM NotasEns Media
PruebaAptitud Verbal
PruebaAptitud
Matemática
PruebaHistoria yGeografía
La correlación es significativa al nivel 0,01 (bilateral).**.
N por lista = 4951a.
13
3. Búsqueda del mejor modelo (R2 y test de hipótesis de los coeficientes de regresión).




























![TRABAJOS FIN DE CARRERA - perso.wanadoo.esperso.wanadoo.es/se915093340/CEU/InstruccTFCyAPA.doc · Web viewEs útil emplear el corrector de Word, ... [Documento PDF] Obtenido en](https://static.documents.pub/doc/80x56/5bb32f5909d3f25d0f8d9c25/trabajos-fin-de-carrera-perso-web-viewes-util-emplear-el-corrector-de-word.jpg)
