20
2011 CENSUS Coverage Assessment – What’s new? OWEN ABBOTT
| Date post: | 30-Dec-2015 |
| Category: |
Documents |
| Upload: | ambrose-phillips |
| View: | 217 times |
| Download: | 3 times |

2011 CENSUS
Coverage Assessment – What’s new?
OWEN ABBOTT

AGENDA
1. Background2. Coverage in the 2001 Census3. 2011 Methodology overview4. Key changes5. Summary

WHAT IS THE PROBLEM?
• Despite best efforts, census won’t count every household or person
• It will also count some people twice
• Users need robust census estimates - counts not enough
• In 2001:– One Number Census (ONC) methodology was developed to
measure undercount– estimated 1.5 million households missed– 3 million persons missed (most from the missing
households but some from counted households)– Subsequent studies estimated a further 0.3 million missed
• In 2011 we want to build on the ONC, as broadly it was successful

2001 CENSUS UNDERCOUNT BY AGE-SEX
Underenumeration of Census by agegroup
0.0%
2.0%
4.0%
6.0%
8.0%
10.0%
12.0%
14.0%
16.0%
0 1-4 5-9 10-14 15-19 20-24 25-29 30-34 35-39 40-44 45-49 50-54 55-59 60-64 65-69 70-74 75-79 80-84 85+
Agegroup
ON
C/C
en
sus
Males Females
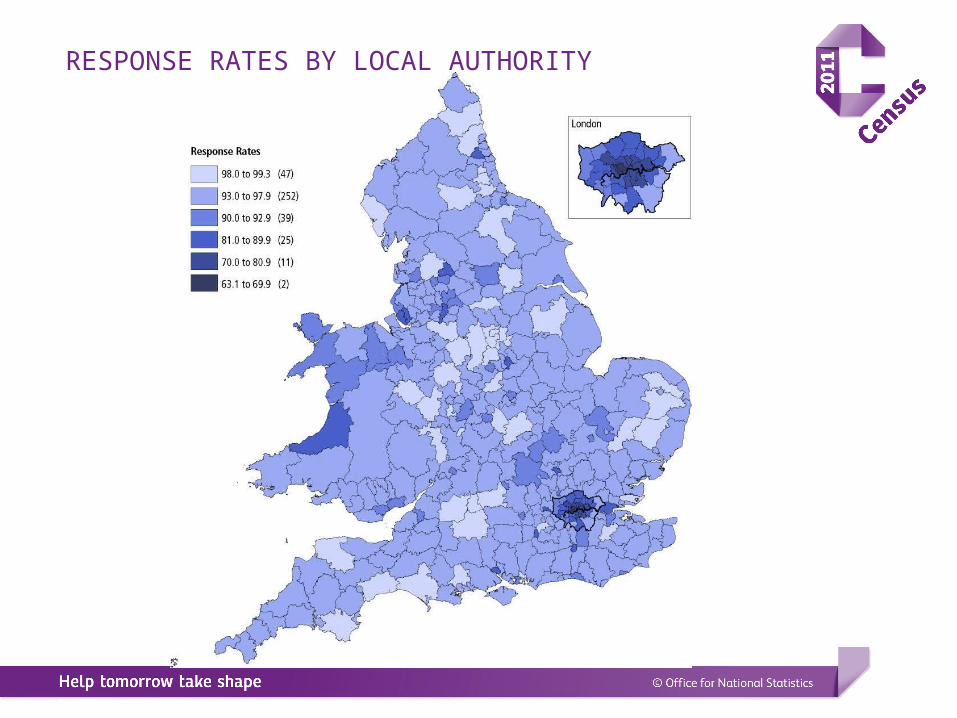
RESPONSE RATES BY LOCAL AUTHORITY

COVERAGE ASSESSMENT PROCESS OVERVIEW
Estimation
Matching
Adjustment
2011 Census
Quality Assurance
Census Coverage
Survey

AREAS OF IMPROVEMENT
• Elements of CCS Design• Estimation methodology• Measuring overcount• Adjustments for bias in DSE• Imputation
• Motivated by:– lessons learnt from 2001– 2011 Census design e.g. use of
internet

THE CCS DESIGN
• Similar to 2001 CCS:– 300,000 Households– Sample of small areas (postcodes)– 6 weeks after Census Day– Fieldwork almost identical
• Improvements:– Designed at LA level, not for LA groups– Refined Hard to Count index (5 levels) using up to date data
sources– Use Output Areas as PSUs– Select 3 postcodes per OA– Revised allocation of sample (using 2001 patterns)

THE CCS DESIGN (2)
• What does this mean?– Each LA will have its own sample – at least 1 OA for each
hard to count level– Sample is more skewed to LAs with ‘hardest to count’
populations (with an upper limit of 60 OAs)• More LAs will have estimates based on their own data
• Especially in London and for big cities
– HtC index will be ‘up to date’– Most LAs will have 3 HtC levels
• Most London areas only had one in 2001
• Looking at a 40%, 40%, 10%, 8%, 2% distribution

ESTIMATION
• Obtained lots of data from 2001 to be able to explore whether improvements can be made
• One key issue was whether we should group LAs by geography or by ‘type’
• Improvements:• Confirmed that using DSE at OA level is sensible• Confirmed that we should group LAs by geography• Use simple Ratio estimator• Confirmed that LA estimation method is still best

ESTIMATION (2)
• What does this mean?– The estimation methodology is much the same as it
was– Should be slightly easier to explain– We will group LAs that don’t have enough sample
with their neighbours until that group has enough sample
– More LAs will have enough sample to produce direct estimates

OVERCOUNT
• In 2001, estimated around 0.4% overcount (duplication)– No adjustments made– Not integrated into methodology
• For 2011, expecting overcount to be higher– More complex population– Use of internet in 2011 Census
• Strategy is to:– A) identify and remove obvious cases (multiple response
resolution)
– B) measure and make net adjustments on the remainder
– i.e. for the latter we are NOT removing duplicates

OVERCOUNT (2)
• Methodology:– Select targeted samples of census records
• Second residences• Students• Children
– Very large sample (~600,000k records)
– Automatic matching algorithm to identify duplicates
– Clerical checking of matches• expect to see ~13,000 duplicates• Also use the LS to QA the estimates
– Estimation of duplication rates by GOR and characteristics• estimating which is the correct record
– Why not do whole database and remove them?• High risk of making false positives and thus removing too many!

OVERCOUNT (3)
• What does this mean?– Population estimates will be reduced where there is overcount
– We will be able to say how much adjustment was made due to overcount
– The duplicates will still be in the data, we just won’t impute as much for undercount

DSE BIAS ADJUSTMENTS
• Assumptions underpinning DSE:– Homogeneity
– Independence
– Accurate Matching
– Closure
• DSEs usually have some bias, mostly due to failure of homogeneity assumption
• In 2001 Census we made a ‘dependence’ adjustment
• This showed that we need to have a strategy for measuring this

DSE BIAS ADJUSTMENTS (2)• Mitigate as much as possible:
i. Post-stratify DSE so heterogeneity is minimised
ii.Independence in CCS field processesiii.Design Matching to get accuracyiv.Collect CCS on same basis as Census
• Measure remaining bias– Specific adjustments – e.g. Movers, Overcount– Residual biases global adjustment
• Improved adjustment using Census address register
• Looking at improving age-sex distribution

DSE BIAS ADJUSTMENTS (3)• What does this mean?
– We will be making adjustments to the estimates based on plausible external data• Household counts• Sex ratios
– This will be part of the methodology
– Also can be used if QA determines estimates are
implausible

COVERAGE ADJUSTMENT
• Imputation methodology had problems converging– Sometimes resulted in poor quality results
• Improvements:– Model characteristics at higher geographies– Allows more details to be modelled– Some additional topics in the CCS included in
models:• Migration variable (internal, international)• Country of birth (UK and non-UK)
– Non-controlled variables imputed by CANCEIS
• What does this mean?– Better Imputation quality– Characteristics of imputed improved

SUMMARY
• Coverage assessment is an integral part of the 2011 Census
• It will again define the key census outputs (estimates at LA level by age and sex) and adjust the database
• We learnt a lot of lessons in 2001 and have been working to address them


















