35
22/3/23 1 22/3/23 EIE426-AICV 1 Machine Learning Filename: eie426-machine-learning-0809.ppt
| Date post: | 29-Dec-2015 |
| Category: |
Documents |
| Upload: | amber-york |
| View: | 223 times |
| Download: | 1 times |

23/4/19 123/4/19 EIE426-AICV 1
Machine Learning
Filename: eie426-machine-learning-0809.ppt

23/4/19 223/4/19 EIE426-AICV 2
Contents
Machine learning concepts and procedures
Learning by recording cases
Learning by building identification trees
Simplification of decision rules

23/4/19 3
Machine Learning
Learning is based on coupling new information to previously acquired knowledge. Usually, a great deal of reasoning is involved.
(1) Learning by analyzing differences
(2) Learning by managing multiple models
(3) Learning by explaining experience
(4) Learning by correcting mistakes Learning is based on digging useful regularity out of data
(1) Learning by recording cases
(2) Learning by building identification trees
(3) Learning by training neural nets
(4) Learning by simulation evolution
Two kinds of learning:
EIE426-AICV

23/4/19 4
Learning by Recording Cases
The consistency heuristic: whenever you want to guess a property of something, given nothing
else to go on but a set of reference cases, find the most similar case, as measured by known properties, for which the property is known. Guess that the unknown property is the same as that known property.
This technique is good for problem domains in which good models are impossible to build.
The learning will do nothing to the information in the recorded cases until that information is used.
EIE426-AICV

23/4/19 5EIE426-AICV
Learning by Recording Cases (cont.)

23/4/19 6EIE426-AICV
Learning by Recording Cases (cont.)

23/4/19 7
Finding Nearest Neighbors
The straightforward way: calculate the distance to each other object and find the minimum among those distances. For n other objects, there are n distances to compute and (n-1) distance comparisons to do.
EIE426-AICV

Decision Trees
A decision tree is a representation
that is a semantic tree
in which
Each leaf node is connected to a set of possible answers.
Each non-leaf node is connected to a test that splits its set of
possible answers into subsets corresponding to different test
results.
Each branch carries a particular test result’s subset to another
node.
23/4/19 EIE426-AICV 8

Decision Trees (cont.)
23/4/19 EIE426-AICV 9

K-D Tree
A k-d tree is a representationThat is a decision treeIn which
The set of possible answers consists of points, one of which may
be the nearest neighbor to a given point.
Each test specifies a coordinate, a threshold, and a neutral zone
around the threshold containing no points.
Each test divides a set of points into two sets, according to on
which side of the threshold each point lies.
23/4/19 EIE426-AICV 10

23/4/19 11
00
2
2
4
4
6
6
Height
Width
Red
Orange
Yellow
Purple
RedViolet
Blue
Green
2.00
U4.00
U
2.00
U
EIE426-AICV
K-D Tree(cont.)

23/4/19 12
Height > 3.5
Height > 5.5?
Orange
No
No
Width > 3.5
Yes
Width > 3.0
Height > 1.5? Height > 1.5?
Violet Red Green Blue
No
No
NoNo
Yes
Yes Yes
Red
Yes
Height > 5.5?
Purple Yellow
No
Yes
Yes
EIE426-AICV
K-D Tree(cont.)

K-D Tree (cont.)
To divide the cases into sets,
If there is only one case, stop.
If this is the first division of cases, pick the vertical axis for comparison;
otherwise, pick the axis that is different from the axis at the next higher level.
Considering only the axis of comparison, find the average position of the two
middle objects. Call this average position the threshold, and construct a
decision-tree test that compares unknowns in the axis of comparison against
the threshold. Also note the position of the two middle objects in the axis of
comparison. Call these positions the upper and lower boundaries.
Divide up all the objects into two subsets, according to on which side of the
average position they lie.
Divide up the objects in each subset, forming a subtree for each, using this
procedure.
23/4/19 EIE426-AICV 13

23/4/19 14
To find the nearest neighbor using the K-D procedure,
Determine whether there is only one element in the set under
consideration.
If there is only one, report it.
Otherwise, compare the unknown, in the axis of comparison,
against the current node’s threshold. The result determines the
likely set.
Find the nearest neighbor in the likely set using this procedure.
Determine whether the distance to the nearest neighbor in the
likely set is less than or equal to the distance to the other set’s
boundary in the axis of comparison:
If it is, then report the nearest neighbor in the likely set.
If it is not, check the unlikely set using this procedure; return
the nearer of the nearest neighbors in the likely set and in
the unlikely set.
EIE426-AICV
K-D Tree(cont.)

23/4/19 15
Learning by Building Identification Trees
Identification-tree building is the most widely used learning method. Thousands of practical identification trees, for applications ranging from medical diagnosis to process control, has been built using the method.
EIE426-AICV

23/4/19 16
From Data to Identification Trees
Name Hair Height Weight Lotion ResultSarah blonde average light no sunburnedDana blonde tall average yes noneAlex brown short average yes noneAnnie blonde short average no sunburnedEmily red average heavy no sunburnedPete brown tall heavy no noneJohn brown average heavy no noneKatie blonde short light yes none
EIE426-AICV

23/4/19 17
An identification tree is a representation
That is a decision tree
In Which Each set of possible conclusions is established implicitly by a
list of samples of known class.
In the table, there are 3 x 3 x 3 x 2 = 54 possible combinations. The probability of an exact match with someone already observed is 8/54. It can be impractical to classify an unknown object by looking for an exact match.
EIE426-AICV
From Data to Identification Trees (cont.)
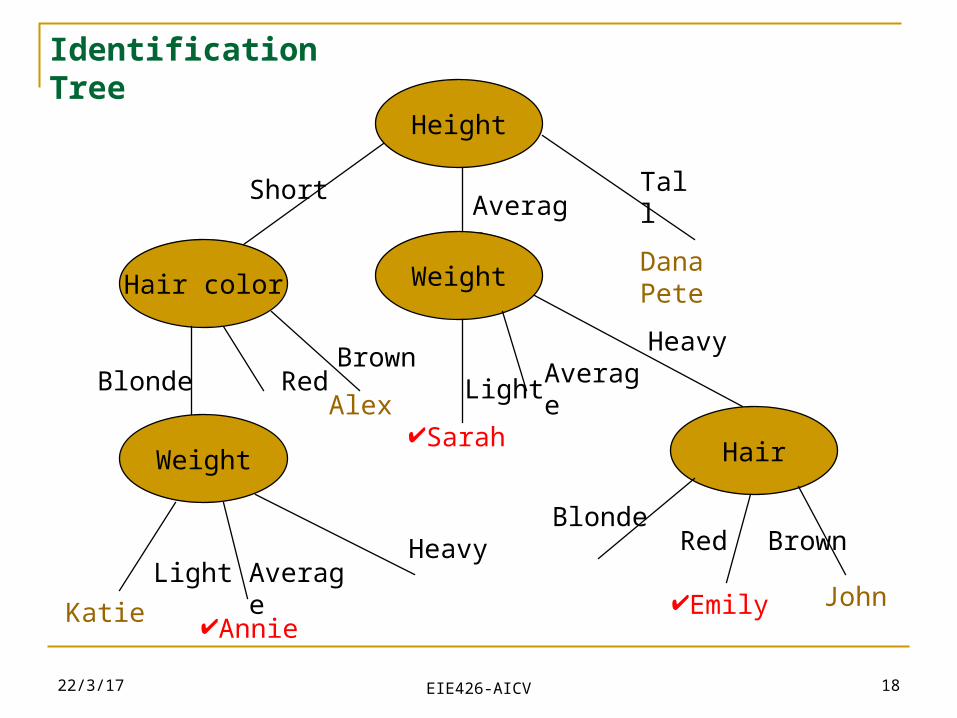
23/4/19 18
Height
TallAverage
Short
Dana PeteWeight
Sarah
LightAverage
Heavy
Hair color
Blonde RedBrown
Alex
Weight
Light AverageHeavy
Katie Annie
Hair
BlondeRed Brown
Emily John
EIE426-AICV
Identification Tree

23/4/19 19
The world is inherently simple. Therefore the smallest identification tree that is consistent with the samples is the one that is most likely to identify unknown objects correctly.
Which is the right identification tree?
How can you construct the smallest identification tree?
EIE426-AICV
Identification Tree (cont.)

23/4/19 20
Tests Should Minimize Disorder
EIE426-AICV

23/4/19 21EIE426-AICV
Tests Should Minimize Disorder (cont.)
Hair Color: Blonde4 Samples: Sarah, Dana, Annie, Katie

23/4/19 22
Information Theory Supplies a Disorder Formula
Where
nb is the number of samples in branch b,
nt is the total number of samples in all branches,
nbc is the number of samples in branch b of class c.
c b
bc
b
bc
n
n
n
n)(logDisorder 2
b c b
bc
b
bc
t
b
n
n
n
n
n
n)(log)(disorder Average 2
EIE426-AICV

Disorder Formula
23/4/19 EIE426-AICV 23
For two classes, A and B:
If they are perfectly balanced, that is, nbc = 0.5 (c=1,2), then
1 2
1log
2
1
2
1log
2
1
)(logDisorder
22
2
c b
bc
b
bc
n
n
n
n
If there are only A’s or only B’s (perfect homogeneity), then
0
0log01log1
)(logDisorder
22
2
c b
bc
b
bc
n
n
n
n

23/4/19 24
As it moves from perfect homogeneity to perfect balance, disorder varies smoothly between zero and one.
EIE426-AICV
Disorder Measure

23/4/19 25
Test Disorder
Hair 0.5
Height 0.69
Weight 0.94
Lotion 0.61
The first test:
Thus, the hair-color test is the winner.
5.008
30
8
1
4
2log
4
2
4
2log
4
2
8
4
color)-(hairDisorder Average
22
EIE426-AICV
Disorder Measure (cont.)

23/4/19 26
Test Disorder
Height 0.5
Weight 1
Lotion 0
Once the hair test is selected, the choice of another test to separate out the sunburned people from among Sarah, Dana, Annie, and Katie is decided by the following calculations:
Thus, the lotion-used test is the clear winner.
EIE426-AICV
Disorder Measure (cont.)

Identification Tree AlgorithmTo generate an identification tree using SPROUTER,
Until each leaf node is populated by as homogeneous a sample
set as possible:
Select a leaf node with an inhomogeneous sample set.
Replace that leaf node by a test node that divides the
inhomogeneous sample set into minimally inhomogeneous
subsets, according to some measure of disorder.
23/4/19 EIE426-AICV 27

23/4/19 28
From Trees to Rules
If the person’s hair color is blonde and
the person uses lotion,
then nothing happens.
If the person’s hair color is blonde and
the person uses no lotion,
then the person turns red.
If the person’s hair color is red,
then the person turns red.
If the person’s hair color is brown,
then nothing happens.
EIE426-AICV

23/4/19 29
Unnecessary Rule Antecedents Should be Eliminated
If the person’s hair color is blonde and
the person uses lotion.
then nothing happens.
If the person uses lotion,then nothing happens.
EIE426-AICV
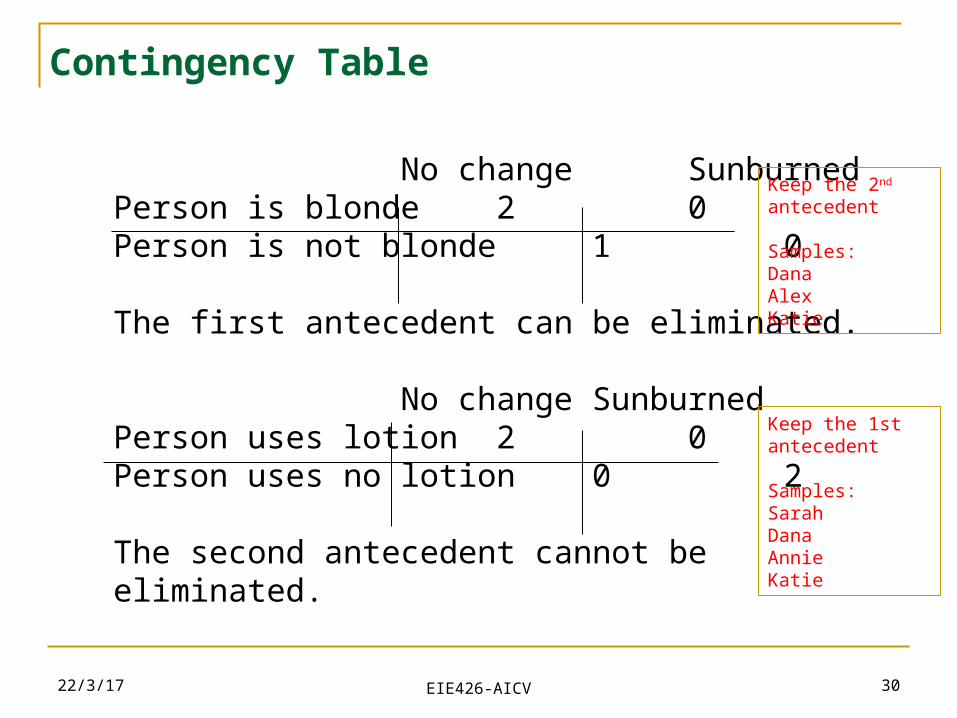
23/4/19 30
Contingency Table
No change SunburnedPerson is blonde 2 0Person is not blonde 1 0
The first antecedent can be eliminated.
No change SunburnedPerson uses lotion 2 0Person uses no lotion 0 2
The second antecedent cannot be eliminated.
EIE426-AICV
Keep the 2nd antecedent
Samples:DanaAlexKatie
Keep the 1stantecedent
Samples:SarahDanaAnnieKatie

23/4/19 31
If the person’s hair color is blondethe person does not use lotion
then the person turns red
No change Sunburned Person is blonde 0
2Person is not blonde 2 1
The first antecedent cannot be eliminated.
No change SunburnedPerson uses no lotion 0 2Person uses lotion 2 0
The second antecedent cannot be eliminated either.
EIE426-AICV
Contingency Table (cont.) Keep the 2nd antecedent
Samples:Sarah, AnnieEmily, PeteJohn
Keep the 1stantecedent
Samples:SarahDanaAnnieKatie

23/4/19 32
If the person’s hair color is red,then the person turns red.
No change SunburnedPerson is red haired 0 1Person is not red haired 5 2
The antecedent cannot be eliminated.
If the person’s hair color is brown,then nothing happens.
No change SunburnedPerson is brown haired 3 0Person is not brown haired 2 3
The antecedent cannot be eliminated.
EIE426-AICV
Contingency Table (cont.) No antecedent
All 8 samples are considered.
No antecedent
All 8 samples are considered.

23/4/19 33
Unnecessary Rules Should be Eliminated
If the person’s hair color is blonde and
the person uses no lotion,
then the person turns red. ----- Rule 1
If the person uses lotion,
then nothing happens. ----- Rule 2
If the person’s hair color is red,
then the person turns red. ----- Rule 3
If the person’s hair color is brown,
then nothing happens. ----- Rule 4
EIE426-AICV

Default Rules and Tie BreakerDefault rule:
If no other rule applies,
then the person turns red, ----- Rule 5
or
If no other rule applies,
then nothing happens. ----- Rule 6
23/4/19 EIE426-AICV 34
Choose the default rule to minimize the total number of rules.
Tie breaker 1: Choose the default rule that covers the most common consequent in the sample set.
Rule 6 is used together with Rules 1 and 3.
Tie breaker 2: Choose the default rule that produces the simplest rules.
Rule 5 is used together with Rules 2 and 4.

Rule Generation Algorithm
To generate rules from an identification tree using PRUNER,
Create one rule for each root-to-leaf path in the identification
tree.
Simplify each rule by discarding antecedents that have no effect
on the conclusion reached by the rule.
Replace those rules that share the most common consequent by
a default rule that is triggered when on other rule is triggered
(eliminating as many other rules as possible). In the event of a
tie, use some heuristic tie breaker to choose a default rule.
23/4/19 EIE426-AICV 35
















