IBM Systems Anand Haridass Chief Engineer POWER Integrated Solutions (BD&A) Senior Technical Staff Member India Systems Development Lab [email protected]https://www.linkedin.com/in/anandharidass Big Data & Analytics - POWER Up Your Insights
Transcript
IBM Systems
Anand HaridassChief Engineer POWER Integrated Solutions (BD&A)Senior Technical Staff MemberIndia Systems Development [email protected]://www.linkedin.com/in/anandharidass
Big Data & Analytics -POWER Up Your Insights
IBM Systems
Acknowledgement
Sources of these slides are numerous IBM presentations/tutorial/slides
Thank you
Special thanks to Steve Roberts (https://www.linkedin.com/in/steve-roberts-a5246a3b)
| 2
IBM Systems
Agenda
� The Big Picture about Big Data
� Hadoop & Spark Market
� IBM POWER / OpenPOWER
� POWER Big Data Offerings
IBM Systems
Big Data & Analytics
IBM Systems
DATA is THE resource of the 21st CenturyAn unprecedented increase in use of digital devices is causing humungous amount of data to begenerated and captured by businesses. This tremendous amount of digital data, also known as
Big Data has the potential to transform businesses and create value.
IBM Systems 6
There will be over 200 billion connected devices
There will be over 12 billion machine-to-machine devices
Machine generated data will be 42% of all data
4x more digital data than all the grains of sand on earth
By 20202020
Internet of Things
And this just the beginning ….
IBM Systems
Big data has swept into every sector and business function
7
Retail Telco Financial Services
Energy & Utilities
Pharma Healthcare
Auto Public Sector Industrial
Big data and analytics are impacting innovation across
multiple industries
Dynamic Pricing
Forecasting
Predicating Trends
CRM
Responsive Design
Revenue Models
Fraud Prevention
Risk Mitigation
Power Management
Utility Billing
Personalized Medicine
Target Therapy
PredicativeAnalysis
E-Health
Traffic Reduction
Connected Vehicles
Resource
Planning
Management
Reduce Waste
Consumption Planning
Big Data
Communications Sector
Distribution Sector
PublicSector
Financial Sector
Industrial Sector
IBM Systems
Big Data : Value from Insights
DescriptiveWhat is happening
CognitiveWhat did I learn
Value
PrescriptiveWhat should I do
PredictiveWhat could happen
DiagnosticWhy did it happen
Cognitive computing defines systems that
learn at scale, reason with purpose &
interact with humans naturally. Cognitive
systems are probabilistic, this is a core point
of difference as it means they are not
programmed, instead they have been
trained. Cognitive systems can generate not
just answers to questions but hypotheses,
reassured responses & recommendations
about more complex & meaningful data.
IBM Systems
Infrastructure : Needs to have
9
Evolving BD&A priorities
�Enable emerging BD&A workloads
�Manage elevated service levels
�Increase agility and elasticity
�Reduce costs
Extreme Speed and Flexibility for dynamic, real-time business demands
• Use real workloads/workflows to drive design points that accelerate insights in real-time at the point of impact
• Adapt to business and application changes quickly
Continuous Availability for the most demanding workloads
• To consistently deliver insights to the people and processes that need them
• Efficient high availability & disaster recovery
• Seamless transition to new technology
Ability to manage and analyze data volume, velocity and variety to gain unprecedented business insight
• Innovation across the system elements to minimize data movement and maximize use of all types of data to accelerate decisions
IBM Systems
Hadoop & Spark Market
IBM Systems
What is Hadoop?� Open source project to enable processing of large data sets
� Rapid in-memory processing of resilient distributed datasets (RDDs)
� Multiple Workflows
� Multiple Libraries
� Multiple API’s
Fast flexible engine for big data processing - 10x (on disk) to 100x (in memory)
faster than MapReduce
IBM Systems 13
+
IBM Systems
Hadoop and Spark Offer Significant Business Benefits
14
Operations Data Warehousing Line of Business and
Analytics
New Business
Imperatives
Big Data Maturity High
High
Low
Data-Informed
Decision Making
• Full dataset analysis
(no more sampling)
• Extract value from
non-relational data
• 360o
view of all
enterprise data
• Exploratory analysis
and discovery
Warehouse
Modernization
• Data lake
• Data offload
• ETL offload
• Queryable archive
and staging
Lower the Cost
of Storage
Business
Transformation
• Create new business
models
• Risk-aware decision
making
• Fight fraud and
counter threats
• Optimize operations
• Attract, grow, retain
customers
Value
IBM Systems
Market trends� Forrester estimates that 100% of all large enterprises will adopt Hadoop and related
technologies such as Spark for big data analytics within the next two years. (Jan/2016)
� Global Hadoop market is expected to garner revenue of $84.6B by 2021, a CAGR of 63.4% during 2016 to 2021. North America accounted for 52% share of overall market revenue in 2015, owing to higher rate of adoption in industries such as IT, banking, & government sector. Europe is anticipated to witness the fastest CAGR of 65.7% during the forecast period (2016 - 2021). (Allied Market Research, Jan/2016)
� Global spending by large enterprises on machine learning solutions is forecast to grow from $416 million to $2,194 million by 2019 at a CAGR of 39.5% (Markets&Markets, May/2015)
Spark will reinvigorate Hadoop
and, in 2016, nine out of every 10
projects on Hadoop will be Spark-
related projects.
By 2020, 40% of all business
analytics software will incorporate
prescriptive analytics built on
cognitive computing functionality
IBM Systems
IBM POWER / OpenPOWER
IBM Systems
Innovation Beyond The Microprocessor
17
Microprocessors alone no longer drive sufficient Cost/Performance improvements
Full System & Stack
Open Innovation Required
Microprocessor Trends
Over The Last 40+ Years
Price/P
erf
orm
ance
Moore’s Law
Processor Technology
2000 2020
Firmware / OS
Accelerators
Software
Storage
Network
IBM Systems
OpenPOWER
18
Accelerated innovation through
collaboration of partners
Accelerated innovation through
collaboration of partners
Amplified capabilities driving
industry performance leadership
Amplified capabilities driving
industry performance leadership
Vibrant ecosystem through open
development
Vibrant ecosystem through open
development
Cloud ComputingHyper-scale & Large scale
Datacenters
High PerformanceComputing & Analytics
Domestic IT Agendas
Industry adoption, Open choice
OpenPOWER Strategy
Moore’s law no longer satisfies performance gain
Numerous IT consumption models
Growing workload demands
Mature Open software ecosystem
Market Shifts
OpenPOWER is an open development community, using the POWER Architecture to serve the evolving needs of customers.
IBM Systems 19
Fueling ecosystem innovation with OpenPOWER
IBM Systems 20
Fueling ecosystem innovation with OpenPOWER
230+ Members 24 Countries 6 Continents
100+ Collaborative innovations under way
50+ Hardware and technology providers
…IN 2+ YEARS
IBM Systems 21
POWER Processor Roadmap
POWER8 Architecture POWER9 Architecture
2014POWER8
12 cores
22nm
New Micro-Architecture
New ProcessTechnology
2016POWER8w/ NVLink
12 cores22nm
EnhancedMicro-
ArchitectureWith NVLink
2017P9 SO24 cores
14nm
New Micro-Architecture
Direct attachmemory
New ProcessTechnology
Optimized for Data-Centric Workloads
Integrated PCIe
CAPI Acceleration / I/O
Scale-Out Datacenter TCO Optimization
Scale-up performance Optimization
Acceleration Enhancements to CAPI and NVLINK
Modularity for OpenPOWER
TBDP9 SU
TBD cores
14nm
EnhancedMicro-
Architecture
BufferedMemory
POWER6 Architecture POWER7 Architecture
2007POWER6
2 cores
65nm
New Micro-Architecture
New ProcessTechnology
2008POWER6+
2 cores
65nm+
EnhancedMicro-
Architecture
EnhancedProcess
Technology
2010POWER7
8 cores
45nm
New Micro-Architecture
New ProcessTechnology
2012POWER7+
8 cores
32nm
EnhancedMicro-
Architecture
New ProcessTechnology
High Frequency
Enhanced RAS
Dynamic Energy Management
Large eDRAM L3 Cache
Optimized VSX
Enhanced Memory Subsystem
Focus on EnterpriseTechnology and Performance Driven
Focus on Scale-Out and EnterpriseCost and Acceleration Driven
2018 - 20P8/9 SO
10nm - 7nm
Existing Micro-
Architecture
FoundryTechnology
Partner ChipPOWER8/9
OpenPOWEREcosystem
DesignTargeting
Partner Markets & SystemsLeveraging Modulatrity
2020+
New Micro-Architecture
NewTechnology
POWER10
New Features and
Functions
Future
TBD
Price, performance, feature, and ecosystem innovation
IBM Systems
POWER8 Processor
Bus Interfaces� Integrated PCIe Gen3� SMP Interconnect� CAPI
Accelerators� Crypto & memory expansion� Transactional Memory � Data Move / VM Mobility
Caches� 64K Data cache (L1)� 512 KB SRAM L2 / core� 96 MB eDRAM shared L3� Up to 128 MB eDRAM L4 (off-chip)
Power Systems: Expanding to serve a broader Linux market
26
Offering OS capability Positioning in the Linux portfolio
Sca
le-u
p E LineE880
E870
E850
Equally run AIX, IBM i and
Linux with IFLs
Enterprise systems; Scale Up
Leadership Performance and Reliability
Utilization Guarantee (PowerVM – 70%/80%)
Flexible, dynamic Capacity on Demand & Enterprise
Pools
Sca
le-O
ut
S LineS824
S822
S814
Equally Run AIX, IBM i
and Linux
Scale out Systems; Commercial Entry
Utilization Guarantee (PowerVM – 65)
High performance, availability and resiliency
L lineS824L
S822L
S812L
Linux Only
Scale out Linux Systems
Price/Performance Leadership vs. X86
PowerVM, KVM
LC lineS812LC
S822LC
Linux Only
Cluster-optimized Linux Systems
Lowest cost Power System
KVM
Tra
dit
ion
al
PO
WE
RE
na
ble
d
IBM Systems
POWER Big Data & Analytics
IBM Systems
Power Systems integrated in-memory database solution
28
� Accelerates existing data analytics without expensive upgrades or replacement
� Easier data administration with no tuning or aggregates
� Factory-installed software reduces time to deployment
Power Systems (POWER8)
• DB2 Advanced Workgroup or Advanced Enterprise Edition
• Red Hat or Ubuntu Linux, AIX
• Optional InfoSphere DataStage for data Extract, Transform and Load
Gain new business insights from reports that complete faster
Reduce time generating reports and focus on business initiatives
BLU Acceleration – Power Systems Edition
20-hour analytics queries in an x86
environment complete in <15 minutesvs. comparable Power server configuration
1 Assumes 82x calculation based on geometric mean calculation giving equal weighting to the report per hour (RPH) improvements in the three categories of simple, intermediate, and complex reports. GEOMEAN(RPH_simple,RPH_intermediate,RPH_complex) = GEOMEAN(18.85,40.07,747.63)=82.66. This is
based on IBM internal tests as of April 7, 2014 comparing IBM DB2 with BLU Acceleration on Power with a comparably tuned competitor row store database server on x86 executing a materially identical 2.6TB BI workload in a controlled laboratory environment. Test measured 60 concurrent user report
throughput executing identical Cognos report workloads. Competitor configuration: HP DL380p, 24 cores, 256GB RAM, Competitor row-store database, SuSE Linux 11SP3 (Database) and HP DL380p, 16 cores, 384GB RAM, Cognos 10.2.1.1, SuSE Linux 11SP3 (Cognos). IBM configuration: IBM S824, 24
cores, 256GB RAM, DB2 10.5, AIX 7.1 TL2 (Database) and IBM S824, 16 of 20 cores activated, 384GB RAM, Cognos 10.2.1.1, SuSE Linux 11SP3 (Cognos). Results may not be typical and will vary based on actual workload, configuration, applications, queries and other variables in a production environment.
IBM Systems
Power Systems Integrated Solution for Analytics
29
� Fast business analytics for increasing data volumes, and concurrent users
� BI and/or predictive reports
� Factory-installed software reduces time to deployment
View business performance through stunning dashboards and reports
IBM Analytics Solution – Power Systems Edition
Reduce analytics reporting times
nearly1/2 1and predictive scoring by
up to 1/3 2vs. comparable x86
environments
Generate hypotheses and scoring with recommended actions
CognosSPSS
IBM Systems
� Reduce server footprint with DRAM-FLASH consolidation
� 100% Redis compliant (no application changes)
Game-changing innovation for fast access NoSQL data stores
30
IBM Data Engine for NoSQL
IBM Data Engine for NoSQL
• IBM Power S822L
• CAPI-Attached FPGA Accelerator
• IBM FlashSystem
• Ubuntu Linux
• Redis Software
source: for 24:1 system consolidation ratio (12:1 rack density improvement) based on a single IBM S824, (24 cores, POWER8 3.5 GHz), 256GB RAM, AIX 7.1 with 40 TB memory based Flash replacing 24 HP DL380p, 24 cores, E5-2697 v2 2.7 GHz), 256GB RAM, SuSE Linux 11SP3 . Inbound network limits performance to 1M IOPs in both scenarios, equal capacity (#user, data) in both cases. x86 cost includes 10k$ for 2x 1U switches
Load Balancer
500GB Cache Node
10Gb Uplink
POWER8 Server
Flash Array w/ up to 40TB
After: NoSQL POWER8 + CAPI Flash
WWW10Gb Uplink
WWW
Backup Nodes
500GB Cache Node500GB Cache
Node500GB Cache Node500GB Cache
Node
Before: NoSQL in memory
24U4U
Less is More24:1 physical server consolidation =
6x less rack space
Infrastructure Requirements
- Large Distributed (Scale out)
- Large Memory per node
- Networking Bandwidth Needs
- Load Balancing
Acceptable latency
CAPI
Memory
Conventional PCIe I/O
network
network
network
Ecosystem expansion to include Neo4J, Cassandra, Ubuntu version 15.10 with CAPI API’s open for customers & partners
Update
IBM Systems
IBM Big Data on Power Offerings
31
Stage 1: Prove Value
Stage 2: Scale for Multiple Projects Stage 3: Scale for Mixed Analytics
Digital Start for Big Data on Power
IBM Data Engine for Hadoop and
Spark
IBM Data Engine for Analytics
�Ready access for Power customers
�On Premise or Cloud
� Organization: Line of Business (LOB) or Data Science team
�Simplify operations: easy to deploy & manage
�Advanced resource & storage management
�Better resilience for big data
�Spark: 2X better price perf vs x86
� Organization: LOB or Data Science team
�Designed for consolidation and mixed analytics workloads: streams, at rest, text
�Lowest $/TB and less than half storage infrastructure
�Leadership resilience for big data environment
�Adapt and scale to your changing analytics needs
� Organization: IT infrastructure team supporting LoB’sand data team
Limited data investment per project, often <10TB
Single project, limited use cases
Moderate data investment per project50TB to PB
Many independent use case projects across LOB’s
Significant data investment per project1/2 to multi PB
Multiple use cases with diverse SLA’s
Now on IBM Cloud
Marketplace
31
IBM Systems
IBM Data Engine for Hadoop and Spark: IDE-HS
OpenPOWER
IOP +
OpenPOWER
IOP +
OpenPOWER
IOP +
Spectrum Scale FPO Option
• Internal replicated disk
• POSIX compliant
• Encryption/replication
Opt. SpectrumSymphony
• Higher utilization
• Shared cluster
• Better throughput
OpenPOWER (POWER8)
• 2X x86 core performance
• Lowest cost Power HW
Solution
• Pre-assembled/tested cluster
• On-site services
• Lower risk & faster time to value
IBM Open Platform
• Open Hadoop
• Spectrum Scale /
Symphony Options
PlatformCluster Mgr.
Simplified physical
cluster management
IBM Systems 33
IBM Data Engine for Hadoop and Spark
Single vendor support
Up to 2x better price performance for Spark workloads*
Delivered as a fully integrated cluster ready to run
OpenPOWER innovation with IBM S812LC servers
�Optimized configurations for Hadoop or Spark workloads
�Based on S812LC servers with up to 14*6TB disk drives per server
�Optionally preloaded with IBM Open Platform
�Simplify operations – easy to deploy and manage
�Adapt and scale to your changing analytics needs
OpenPOWER innovation with IBM Open Platform with Apache Hadoop for a high performance, storage dense and fully integrated cluster offering.
• All results are based on IBM Internal Testing of 3 SparkBench benchmarks consisting of SQL RDD
Relation, Logistic Regression, SVM
IBM Systems
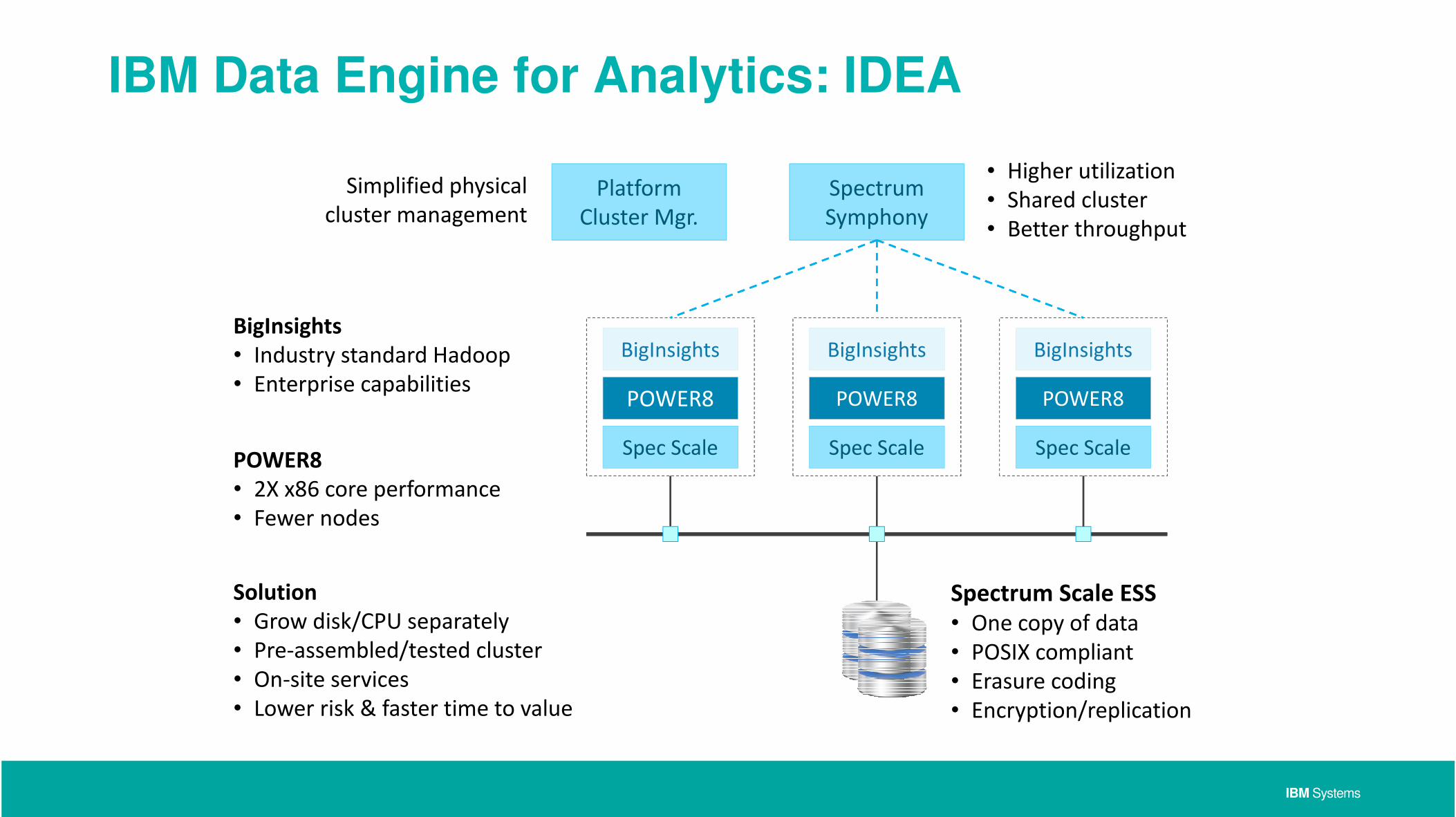
IBM Data Engine for Analytics: IDEA
Platform
Cluster Mgr.
POWER8
BigInsights
POWER8
BigInsights
POWER8
BigInsights
Spectrum
Symphony
Spectrum Scale ESS
• One copy of data
• POSIX compliant
• Erasure coding
• Encryption/replication
POWER8
• 2X x86 core performance
• Fewer nodes
BigInsights
• Industry standard Hadoop
• Enterprise capabilities
Solution
• Grow disk/CPU separately
• Pre-assembled/tested cluster
• On-site services
• Lower risk & faster time to value
Simplified physical
cluster management
• Higher utilization
• Shared cluster
• Better throughput
Spec ScaleSpec ScaleSpec Scale
IBM Systems
IBM Data Engine for Analytics
Single vendor support
Less than half storage infrastructure*
One third rack space reduction vs x86 at Petabyte scale
Lowest $/TB and over a third more usable storage**
� Simplify operations – easy to deploy and manage
� Designed for mixed analytics workloads: streams, at rest, text
� Optionally preloaded with IBM Open Platform
� Enterprise grade Hadoop with advanced resource and storage management
� Adapt and scale to your changing analytics needs
A fully integrated solution with software and infrastructure optimized for Big Data & Analytics
* Compared with a standard triple replica Hadoop configuration** List price vs full rack configuration vs Oracle Big Data Appliance with data connectors and BigSQL
Appliance-Like but much more Versatile!
S822L
35
IBM Systems36
Storage Intensive
Com
pute
Inte
nsiv
e
Add M
ore
Serv
ers
Add More Storage
• Add servers or storage or both as needed
• Adjust compute to storage ratio as workload needs change
• Standard Hadoop configs with local storage and triple replica can result in overprovisioned compute to meet the storage demands
• Data Engine for Analytics allows right sizing of compute and storage independently to create an optimized configuration
Data Engine for Analytics offers Independent Scaling of Servers & Storage
IBM Systems 37
� Streaming and SQL benefit from High Thread Density and Concurrency
• Processing multiple packets of a stream and different stages of a message stream pipeline
• Processing multiple rows from a query
� Machine Learning benefits from Large Caches and Memory Bandwidth
• Iterative Algorithms on the same data
• Fewer core pipeline stalls and overall higher throughput
� Graph also benefits from Large Caches, Memory Bandwidth and Higher Thread Strength
• Flexibility to go from 8 SMT threads per core to 4 or 2
• Manage Balance between thread performance and throughput
� Headroom
• Balanced resource utilization, more efficient scale-out
• Multi-tenant deployments
POWER Advantages for Spark
IBM Systems 38 38
System Performance of Spark on POWER
Machine Learning SQL Graph
1.7X
IBM Systems
More efficient use of resources (Spark 1TB Logistic Regression Example)
39
0
10
20
30
40
50
60
70
80
90
100
22:4
422:4
422:4
422:4
522:4
522:4
522:4
622:4
622:4
622:4
722:4
722:4
722:4
822:4
822:4
822:4
922:4
922:4
922:5
022:5
022:5
022:5
122:5
122:5
122:5
222:5
222:5
222:5
322:5
322:5
322:5
422:5
422:5
422:5
5
CPU POWER
User% Sys% Wait%
0
10
20
30
40
50
60
70
80
90
100
10:1
4
10:1
4
10:1
5
10:1
5
10:1
6
10:1
7
10:1
7
10:1
8
10:1
8
10:1
9
10:1
9
10:2
0
10:2
1
10:2
1
10:2
2
10:2
2
10:2
3
10:2
4
10:2
4
10:2
5
10:2
5
10:2
6
10:2
6
10:2
7
10:2
8
10:2
8
CPU Haswell
User% Sys% Wait%
-1200
-1000
-800
-600
-400
-200
0
200
400
600
800
22:4
4
22:4
4
22:4
4
22:4
5
22:4
5
22:4
6
22:4
6
22:4
7
22:4
7
22:4
7
22:4
8
22:4
8
22:4
9
22:4
9
22:4
9
22:5
0
22:5
0
22:5
1
22:5
1
22:5
2
22:5
2
22:5
2
22:5
3
22:5
3
22:5
4
22:5
4
22:5
4
MB
/se
c
Network I/O POWER
Total-Read Total-Write (-ve)
-600
-500
-400
-300
-200
-100
0
100
200
300
400
10:1
41
0:1
41
0:1
51
0:1
51
0:1
61
0:1
61
0:1
71
0:1
71
0:1
81
0:1
81
0:1
91
0:1
91
0:2
01
0:2
01
0:2
11
0:2
11
0:2
21
0:2
21
0:2
31
0:2
31
0:2
41
0:2
41
0:2
51
0:2
51
0:2
61
0:2
61
0:2
71
0:2
71
0:2
81
0:2
81
0:2
9
MB
/se
c
Network I/O Haswell
Total-Read Total-Write (-ve)
POWER
� CPU headroom to host higher density
� More data pushed over network due to higher thread density
Haswell
� CPU fully pegged on just this workload
� Underutilizing the Network Resource
IBM Systems
What’s in the works ?
40
GPUs and FPGAs for Compute offload, Machine Learning, Graph and other specialized acceleration
CAPI Flash for Memory consolidation/expansion, and Storage acceleration
RDMA for better latency, better network utilization, lower CPU utilization, lower Memory utilization
Please Look For Big Announce @ EDGE 2016
IBM Systems
Apache Spark on IBM POWERTry Open Source Spark on Softlayer Power Servers
• Ideal for Initial Trials of Spark on Power leading to On Premise deals or client continuing with Softlayer• Experience improved response times for Data Scientist graphing workloads using Zeppelin notebook*