35
490dp Prelude I: Group Membership Prelude II: Team Presentations Tuples Robert Grimm
| Date post: | 22-Dec-2015 |
| Category: |
Documents |
| View: | 214 times |
| Download: | 1 times |

490dpPrelude I: Group MembershipPrelude II: Team Presentations
Tuples
Robert Grimm

Group Membership
• c490dp-a– awong– boriss– dancheah– ishafe– sfanous
• c490dp-b– bret– cyhung– davidjc– kphilbri– muliawan
Try to edit /projects/instr/01wi/cse490dp/[group name]/foo

Team Presentations
• Problem(s)– The problem(s) your application is
addressing• Features
– The functionality of the application• Assumptions
– Premises about the application domain

Team Presentations
• Components– The structure of the application
• Unknowns– Things you aren’t sure about– The plan for resolving them
• Evaluation– The plan for showing that the application
• Solves the problem(s)• Works as advertised

Tuples

Parallel Computing
• How to coordinate processes?– Use message passing
• Point-to-point or group communication• Synchronization
– Problem• Relatively tight coupling
– Can we do better?

Gelernter Did Better
• Linda [Carriero & Gelernter 86]
– Tuple• Ordered collection of typed fields• <“P”, 5, false>
– Tuple space• Globally shared collection of tuples

Operations
• Three basic operations– out: Write a tuple– in: Consume a tuple– read: Read a tuple
• Unblocking and blocking versions– Blocking: Wait for result

Template Matching
• in and read use templates– Ordered collection of formals and values
• <“P”, int i, bool b>– A template matches a tuple if
• They have the same size• Corresponding values are equal• Corresponding formals and values agree
– Multiple matches: pick any of them

A Simple Application Example
• Main program– Write out job descriptions– Start helper programs– Collect results
• Helper programs– Take job description– Perform computation– Write out result

Advantages of Tuple Spaces
• Destination uncoupling– Fully anonymous communications
• Space uncoupling– Associative access independent
of local process• Time uncoupling
– Tuples stored independentof creating process

Distributed Computing
• Coordination– Similar problems as for parallel computing– Considerably more dynamic environment
• More generally: Data management– How to represent data?– How to store data?– How to exchange data?

Advantages of Tuple Spaces
• Destination uncoupling• Space uncoupling• Time uncoupling
• Idea: Adopt tuple spaces for distributed computing

Systems
• Three systems– JavaSpaces– T Spaces– Structured I/O in one.world
• In common– Data represented as tuples

JavaSpaces
• Tuple space in / for Java– Typing– Leases– Transactions– Architecture– Potpourri

Typed Tuples
• Convention in Linda– First field is a string denoting the type
• Strongly typed language: Java– Type provided by class– Unordered collection of
named and typed fields• Public instance fields
–References, but not primitive types

Template Matching
• Template is a tuple– Fields may be null
• A template matches a tuple if– The tuple has a subtype of the template– Corresponding values are equal
• Fields are serialized separately– Possible to compare serialized form

Leases
• Problem– How to reclaim obsolete tuples?
• Solution– Limit their lifetime through leases
• Acquire• Renew• Cancel

Transactions
• Problem– How to group operations into one unit?
• Solution: Transactions– Either all operations complete (commit)– Or no operation complete (abort)– Operations become visible only at commit– Affected tuples are locked down
• Serializability
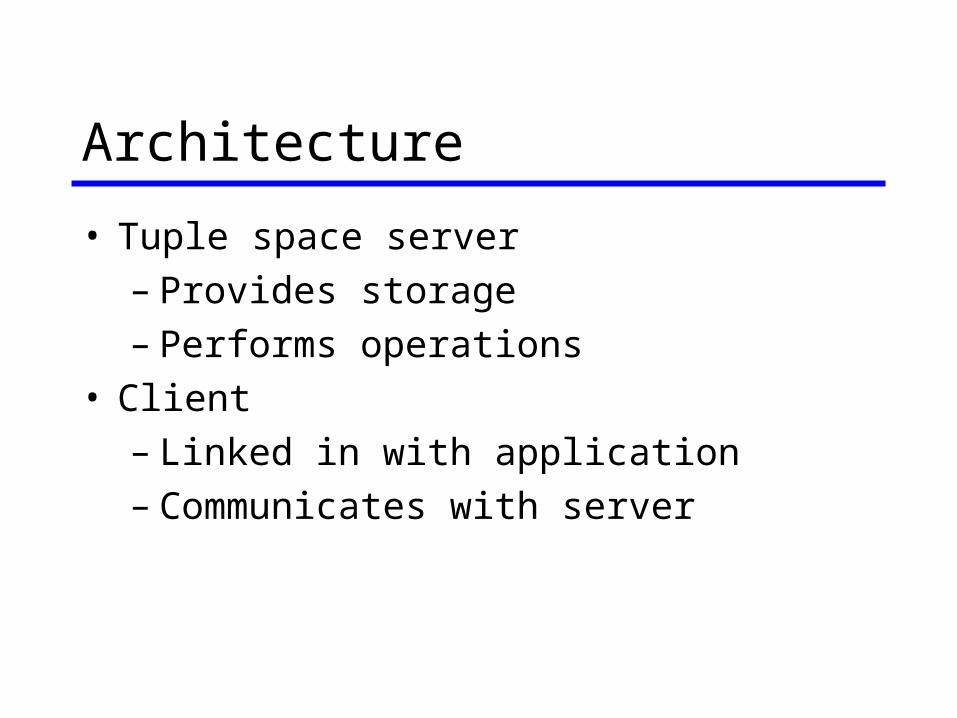
Architecture
• Tuple space server– Provides storage– Performs operations
• Client– Linked in with application– Communicates with server

Potpourri
• notify operation– Triggered when matching tuple is written
• Unblocking versions– readIfExists, takeIfExists
• Blocking versions– read, take
• Implementation may be persistent

T Spaces
• How does T Spaces differ from JavaSpaces?

T Spaces
• Hierarchy of tuple spaces– More flexible structuring
• Support for queries– Data management
• Support for access control– Security
• Extensible implementation– Application-specific functionality

Issues
• What’s wrong with JavaSpaces or T Spaces?

Issues
• Single point of failure– Tuples stored on centralized server
• Relatively heavy-weight– Client to server to client– Real-time communications
• Multimedia

How to Address These Issues?
• Localize storage– Add support for replication
• Offer light-weight communications

Structured I/O
• Tuple-based• Storage
– Local within environment hierarchy• Communication channels
– Unreliable• On top of UDP
– Reliable• On top of TCP

Detour: Environments
• Containers for– Stored tuples– Application components– Other environments
• Combination of file system directories and nested processes
• Local root functions as the kernel

Tuples in one.world
• Statically typed tuples: Subclasses of Tuple– All instance fields must be public– Fields may be of any type– Default fields: id, metaData
• Dynamically typed tuples: DynamicTuple– Field declared and typed dynamically
• Tuples may be nested

Operations
• Basic operations– Communications and storage– put, read, listen
• Extended operations– Storage only– May be transactional (not implemented)– put, read, listen, query, delete

Queries
• Used by read, listen, and query operations• Empty query: always true• Unary query: Negation• Binary query: Conjunction, disjunction• Comparisons
– Including ==, <, >, beginsWith, …– hasType, hasSubType, hasDeclaredType, hasField

Support for Replication
• Replication 101– Log modifying operations– Propagate operations to other nodes
• How to name data?• How to layer replication on top of storage?

The Use of IDs
• Modifying operations use ID as primary key– put operation
• ID differentiates between–Adding a tuple
»No tuple with same ID in store–Overwriting a tuple
»Tuple with same ID in store– delete operation: By ID only

Why No take Operation?
• Result only known at end of operation– Harder to log
• Can still be expressed– Transactional read & delete

Discussion
• Questions?

















