7. Regression with a binary dependent variable Up to now: • Dependent variable Y has a metric scale (it can take on any value on the real line) In this section: • Y takes on either the value 1 or 0 (binary variable) • We aim at finding out and modeling which determinants (X - regressors) cause Y to take on the values 1 or 0 189
Transcript
7. Regression with a binary dependent variable
Up to now:
• Dependent variable Y has a metric scale(it can take on any value on the real line)
In this section:
• Y takes on either the value 1 or 0(binary variable)
• We aim at finding out and modeling which determinants (X-regressors) cause Y to take on the values 1 or 0
189
Examples:
• What is the effect of a tuition subsidy on an individual’sdecision to go to college (Y = 1)?
• Which factors determine whether a teenager takes up smok-ing (Y = 1)?
• What determines if a country receives foreign aid (Y = 1)?
• What determines if a job applicant is successful (Y = 1)?
190
Data set examined in this section:
• Boston Home Mortgage Disclosure Act (HMDA) data set
• Which factors determine whether a mortgage application isdenied (Y ≡ DENY = 1) or approved (Y ≡ DENY = 0)
• Potential factors (regressors):
The required loan payment (P ) relative to the applicantsincome (I):
X1 ≡ P/I RATIO
The applicant’s race
X2 ≡ BLACK =
{
1 if the applicant is black0 if the applicant is white
191
7.1. The linear probability model
Scatterplot of mortgage application denial and the payment-to-income ratio
192
Meaning of the OLS regression line:
• Plot of the predicted value of Y = DENY as a function of theregressor X1 = P/I RATIO
• For example, when P/I RATIO = 0.3 the predicted value ofDENY is 0.2
• The coefficient βj is the change in the probability that Y = 1associated with a unit change in Xj holding constant theother regressors
194
Remarks: [continued]
• The regression coefficients can be estimated by OLS
• The errors of the linear probability model are always het-eroskedastic
−→ Use heteroskedasticity-robust standard errors for confi-dence intervals and hypothesis tests
• The R2 is not a useful measure-of-fit(alternative measures-of-fit are discussed later)
195
Application to Boston HMDA data:
• OLS regression of DENY on P/I RATIO yields
DENY = −0.080 + 0.604 · P/I RATIO
(0.032) (0.098)
• Coefficient on DENY is positive and significant at the 1% level
• If P/I RATIO increases by 0.1, the probability of denial in-creases by 0.604× 0.1 ≈ 0.060 = 6%(predicted change in the probability of denial given a changein the regressor)
196
Application to Boston HMDA data: [continued]
• Effect of race on the probability of denial holding constantthe P/I RATIO
where F (·) denotes the cdf of the logistic distribution defined as
F (x) =1
1 + exp{−x}.
Remarks:• The logit regression is similar to the probit regression, but
using a different cdf
• The computation of predicted probabilities are performedanalogously to the probit model
• The logit coefficients and standard errors are estimated bythe maximum likelihood technique
205
Remarks: [continued]
• In practice, logit and probit regressions often produce similarresults
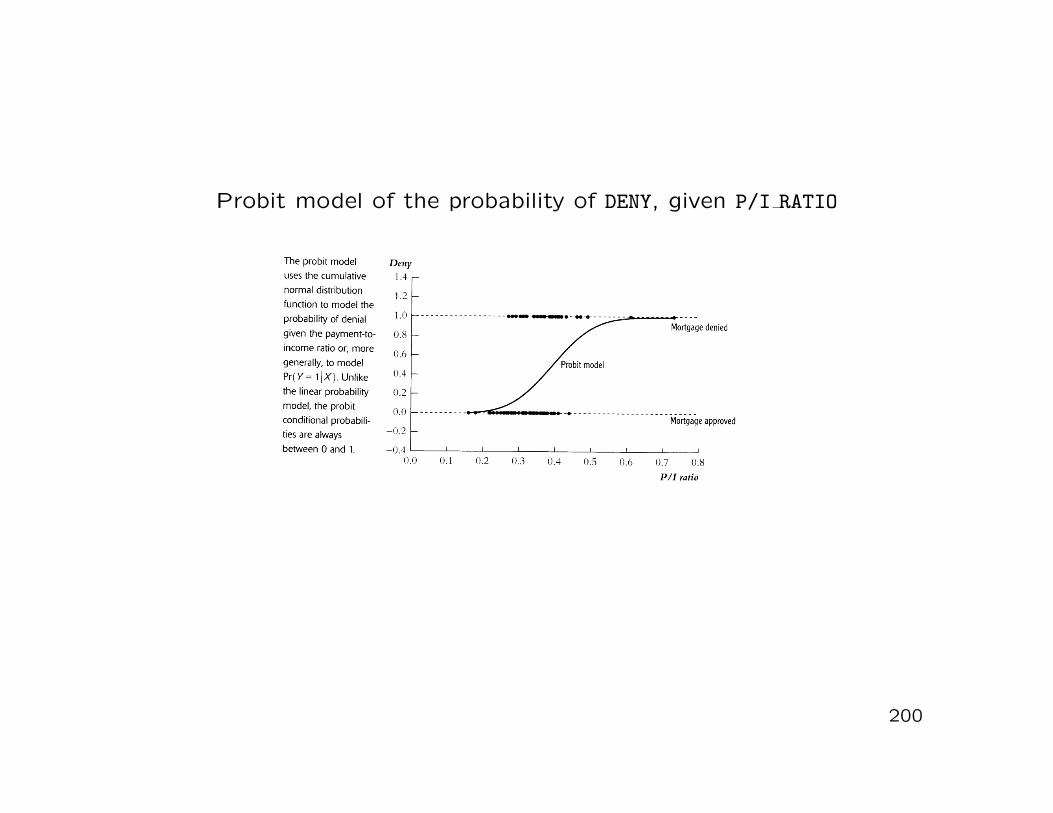
Probit and logit models of the probability of DENY, given P/I RATIO
206
7.3. Estimation and inference in the logit andprobit models
Alternative estimation techniques:
• Nonlinear least squares estimation by minimizing the sum ofsquared prediction mistakes:
n∑
i=1[Yi −Φ(b0 + b1X1i + . . . + bkXki)]
2 −→ minb0,...,bk
(7.4)
(see Eq. (2.2) on Slide 12)
• Maximum likelihood estimation
207
Nonlinear least squares estimation:
• NLS estimators are
consistent
normally distributed in large samples
• However, NLS estimators are inefficient, that is there areother estimators having a smaller variance than the NLS es-timators
−→ Use of maximum likelihood estimators
208
Maximum likelihood estimation:
• ML estimators are
consistent
normally distributed in large samples
• More efficient than NLS estimators
• ML estimation is discussed in the lecture Advanced Statistics
Statistical inference based on MLE:
• Since ML estimators are normally distributed in large sam-ples, statistical inference about probit and logit coefficientsbased on MLE proceeds in the same way as inference aboutthe linear regression functions coefficients based on the OLSestimator
209
In particular:
• Hypothesis tests are performed using the t- and F -statistics(see Sections 3.2.–3.4.)
• Confidence intervals are constructed according to Formula(3.3) on Slide 55
Measures-of-fit:
• The conventional R2 is inappropriate for probit and logit re-gression models
• Two frequently encountered measures-of-fit with binary de-pendent variables are the
Fraction correctly predicted
Pseudo-R2
210
Fraction correctly predicted:
• This measure-of-fit is based on a simple classification rule
• An observation Yi is said to be correctly predicted,
if Yi = 1 and Pr(Yi = 1|X1i, . . . , Xki) > 0.5 or
if Yi = 0 and Pr(Yi = 1|X1i, . . . , Xki) < 0.5
• Otherwise Yi is said to be incorrectly predicted
• The fraction correctly predicted is the fraction of the n ob-servations Y1, . . . , Yn that are correctly predicted
Pseudo-R2:
• The Pseudo-R2 compares values of the maximized likelihood-function with all regressors to the value of the likelihoodfunction with no regressor
211
Case study:
• Application to Boston HMDA data(see class)
Other limited dependent variable models:
• Censored and truncated regression models
• Sample selection models
• Count data
• Ordered responses
• Discrete choice data
• For details see Ruud (2000) and Wooldridge (2002)