34
A Brief Look at Op/miza/on Slides adapted from last year’s version

ABriefLookatOp/miza/on
Slidesadaptedfromlastyear’sversion

Whatisop/miza/on?• Typicalsetup(inmachinelearning,life):
– Formulateaproblem– Designasolu/on(usuallyamodel)– Usesomequan/ta/vemeasuretodeterminehowgoodthesolu/onis.
• E.g.,classifica/on:– Createasystemtoclassifyimages– Modelissomesimpleclassifier,likelogis/cregression– Quan/ta/vemeasureisclassifica/onerror(lowerisbeQerinthiscase)
• Thenaturalques/ontoaskis:canwefindasolu/onwithabeQerscore?
• Ques/on:whatcouldwechangeintheclassifica/onsetuptolowertheclassifica/onerror(whatarethefreevariables)?

Formaldefini/on
• f(θ):somearbitraryfunc/on• c(θ):somearbitraryconstraints• Minimizingf(θ)isequivalenttomaximizing-f(θ),sowecanjusttalkaboutminimiza/onandbeOK.

Typesofop/miza/onproblems
• Dependingonf,c,andthedomainofθwegetmanyproblemswithmanydifferentcharacteris/cs.
• Generalop/miza/onofarbitraryfunc/onswitharbitraryconstraintsisextremelyhard.
• Mosttechniquesexploitstructureintheproblemtofindasolu/onmoreefficiently.

Typesofop/miza/on• Simpleenoughproblemshaveaclosedformsolu/on:
• f(x)=x2• Linearregression
• Iffandcarelinearfunc/onsthenwecanuselinearprogramming(solvableinpolynomial/me).
• Iffandcareconvexthenwecanuseconvexop/miza/ontechnique(mostofmachinelearningusesthese).
• Iffandcarenon-convexweusuallypretendit’sconvexandfindasub-op/mal,buthopefullygoodenoughsolu/on(e.g.,deeplearning).
• Intheworstcasethereareglobalop/miza/ontechniques(opera/onsresearchisverygoodatthese).
• Thereareyetmoretechniqueswhenthedomainofθisdiscrete.• Thislistisfarfromexhaus/ve.

Typesofop/miza/on
• Takeaway:Thinkhardaboutyourproblem,findthesimplestcategorythatitfitsinto,usethetoolsfromthatbranchofop/miza/on.
• Some/mesyoucansolveahardproblemwithaspecial-purposealgorithm,butmost/meswefavorablack-boxapproachbecauseit’ssimpleandusuallyworks.

Reallynaïveop/miza/onalgorithm• Suppose
– D-dimensionalvectorofparameterswhereeachdimensionisboundedaboveandbelow.
• ForeachdimensionIpicksomesetofvaluestotry:
• Tryallcombina/onsofvaluesforeachdimension,recordfforeachone.
• Pickthecombina/onthatminimizesf.

Reallynaïveop/miza/onalgorithm
• Thisiscalledgridsearch.Itworksreallywellinlowdimensionswhenyoucanaffordtoevaluatefmany/mes.
• Lessappealingwhenfisexpensiveorinhighdimensions.
• YoumayhavealreadydonethiswhensearchingforagoodL2penaltyvalue.

Convexfunc/ons
Usethelinetest.
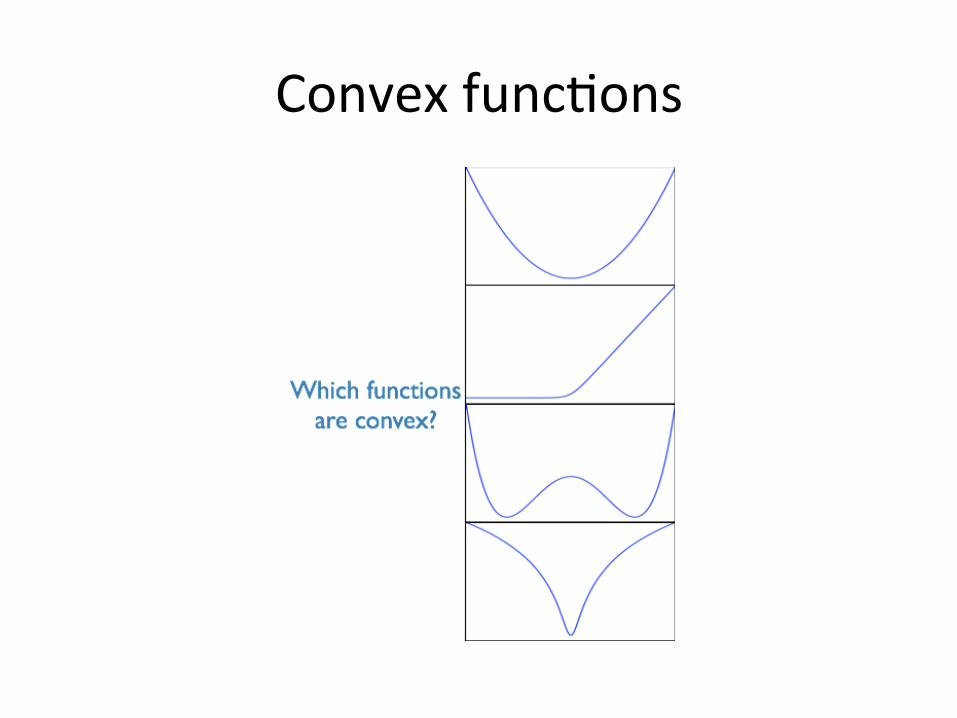
Convexfunc/ons

Convexop/miza/on
• We’vetalkedabout1Dfunc/ons,butthedefini/ons/llappliestohigherdimensions.
• Whydowecareaboutconvexfunc/ons?• Inaconvexfunc/on,anylocalminimumisautoma/callyaglobalminimum.
• Thismeanswecanapplyfairlynaïvetechniquestofindthenearestlocalminimumands/llguaranteethatwe’vefoundthebestsolu/on!

Steepest(gradient)descent
• Cauchy(1847)


Aside:Taylorseries
• ATaylorseriesisapolynomialseriesthatconvergestoafunc/onf.
• WesaythattheTaylorseriesexpansionofatxaroundapointa,f(x+a)is:
• Trunca/ngthisseriesgivesapolynomialapproxima/ontoafunc/on.

Blue:exponen/alfunc/on;Red:Taylorseriesapproxima/on

Mul/variateTaylorSeries
• Thefirst-orderTaylorseriesexpansionofafunc/onf(θ)aroundapointdis:

Steepestdescentderiva/on• Supposeweareatθandwewanttopickadirec/ond(withnorm1)suchthatf(θ+ηd)isassmallaspossibleforsomestepsizeη.Thisisequivalenttomaximizingf(θ)-f(θ+ηd).
• Usingalinearapproxima/on:
• Thisapproxima/ongetsbeQerasηgetssmallersinceaswezoominonadifferen/ablefunc/onitwilllookmoreandmorelinear.

Steepestdescentderiva/on• Weneedtofindthevaluefordthatmaximizessubjectto
• Usingthedefini/onofcosineastheanglebetweentwovectors:

Howtochoosethestepsize?• Atitera/ont• Generalidea:varyηtun/lwefindtheminimumalong
• Thisisa1Dop/miza/onproblem.• Intheworstcasewecanjustmakeηtverysmall,butthenweneedtotakealotmoresteps.
• Generalstrategy:startwithabigηtandprogressivelymakeitsmallerbye.g.,halvingitun/lthefunc/ondecreases.

Whenhaveweconverged?
• When• Ifthefunc/onisconvexthenwehavereachedaglobalminimum.

Theproblemwithgradientdescent
source:hQp://trond.hjorteland.com/thesis/img208.gif

Newton’smethod
• Tospeedupconvergence,wecanuseamoreaccurateapproxima/on.
• SecondorderTaylorexpansion:
• HistheHessianmatrixcontainingsecondderiva/ves.

Newton’smethod

Whatisitdoing?
• Ateachstep,Newton’smethodapproximatesthefunc/onwithaquadra/cbowl,thengoestotheminimumofthisbowl.
• Fortwiceormoredifferen/ableconvexfunc/ons,thisisusuallymuchfasterthansteepestdescent(provably).
• Con:compu/ngHessianrequiresO(D2)/meandstorage.Inver/ngtheHessianisevenmoreexpensive(uptoO(D3)).Thisisproblema/cinhighdimensions.

Quasi-Newtonmethods
• Computa/oninvolvingtheHessianisexpensive.• Modernapproachesusecomputa/onallycheaperapproxima,onstotheHessianorit’sinverse.
• Derivingtheseisbeyondthescopeofthistutorial,butwe’lloutlinesomeofthekeyideas.
• Theseareimplementedinmanygoodsonwarepackagesinmanylanguagesandcanbetreatedasblackboxsolvers,butit’sgoodtoknowwheretheycomefromsothatyouknowwhenyouusethem.

BFGS
• Maintainarunninges/mateoftheHessianBt.• Ateachitera/on,setBt+1=Bt+Ut+VtwhereUandVarerank1matrices(thesearederivedspecificallyforthealgorithm).
• Theadvantageofusingalow-rankupdatetoimprovetheHessianes/mateisthatBcanbecheaplyinvertedateachitera/on.

LimitedmemoryBFGS• BFGSprogressivelyupdatesBandsoonecanthinkofBtasa
sumofrank-1matricesfromsteps1tot.WecouldinsteadstoretheseupdatesandrecomputeBtateachitera/on(althoughthiswouldinvolvealotofredundantwork).
• L-BFGSonlystoresthemostrecentupdates,thereforetheapproxima/onitselfisalwayslowrankandonlyalimitedamountofmemoryneedstobeused(linearinD).
• L-BFGSworksextremelywellinprac/ce.• L-BFGS-BextendsL-BFGStohandleboundconstraintsonthe
variables.

Conjugategradients• Steepestdescentonenpicksadirec/onit’stravelledinbefore
(thisresultsinthewigglybehavior).• Conjugategradientsmakesurewedon’ttravelinthesame
direc/onagain.• Thederiva/onforquadra/csismoreinvolvedthanwehave
/mefor.• Thederiva/onforgeneralconvexfunc/onsisfairlyhacky,but
reducestothequadra/cversionwhenthefunc/onisindeedquadra/c.
• Takeaway:conjugategradientworksbeQerthansteepestdescent,almostasgoodasL-BFGS.Italsohasamuchcheaperper-itera/oncost(s/lllinear,butbeQerconstants).

Stochas/cGradientDescent
• Recallthatwecanwritethelog-likelihoodofadistribu/onas:

Stochas/cgradientdescent• Anyitera/onofagradientdescent(orquasi-Newton)methodrequiresthatwesumovertheen/redatasettocomputethegradient.
• SGDidea:ateachitera/on,sub-sampleasmallamountofdata(evenjust1pointcanwork)andusethattoes/matethegradient.
• Eachupdateisnoisy,butveryfast!• Thisisthebasisofop/mizingMLalgorithmswithhugedatasets(e.g.,recentdeeplearning).
• Compu/nggradientsusingthefulldatasetiscalledbatchlearning,usingsubsetsofdataiscalledmini-batchlearning.

Stochas/cgradientdescent• Supposewemadeacopyofeachpoint,y=xsothatwenowhavetwiceasmuchdata.Thelog-likelihoodisnow:
• Inotherwords,theop/malparametersdon’tchange,butwehavetodotwiceasmuchworktocomputethelog-likelihoodandit’sgradient!
• ThereasonSGDworksisbecausesimilardatayieldssimilargradients,soifthereisenoughredundancyinthedata,thenoisyfromsubsamplingwon’tbesobad.

Stochas/cgradientdescent• Inthestochas/csepng,linesearchesbreakdownandsodoes/matesoftheHessian,sostochas/cquasi-Newtonmethodsareverydifficulttogetright.
• Sohowdowechooseanappropriatestepsize?• RobbinsandMonro(1951):pickasequenceofηtsuchthat:
• Sa/sfiedby(asoneexample).• Balances“makingprogress”withaveragingoutnoise.

FinalwordsonSGD
• SGDisveryeasytoimplementcomparedtoothermethods,butthestepsizesneedtobetunedtodifferentproblems,whereasbatchlearningtypically“justworks”.
• Tip1:dividethelog-likelihoodes/matebythesizeofyourmini-batches.Thismakesthelearningrateinvarianttomini-batchsize.
• Tip2:subsamplewithoutreplacementsothatyouvisiteachpointoneachpassthroughthedataset(thisisknownasanepoch).

UsefulReferences• Linearprogramming:
- LinearProgramming:Founda/onsandExtensions(hQp://www.princeton.edu/~rvdb/LPbook/
• Convexop/miza/on:- hQp://web.stanford.edu/class/ee364a/index.html- hQp://stanford.edu/~boyd/cvxbook/bv_cvxbook.pdf
• LPsolver:– Gurobi:hQp://www.gurobi.com/
• Stats(python):– Scipystats:hQp://docs.scipy.org/doc/scipy-0.14.0/reference/stats.html
• Op/miza/on(python):– Scipyop/mize:hQp://docs.scipy.org/doc/scipy/reference/op/mize.html
• Op/miza/on(Matlab):– minFunc:hQp://www.cs.ubc.ca/~schmidtm/Sonware/minFunc.html
• GeneralML:– Scikit-Learn:hQp://scikit-learn.org/stable/

















