ORIGINAL ARTICLE A clustering-based modified variable neighborhood search algorithm for a dynamic job shop scheduling problem Mohammad Amin Adibi & Jamal Shahrabi Received: 8 October 2011 /Accepted: 26 September 2013 # Springer-Verlag London 2013 Abstract The dynamic job shop scheduling (DJSS) problem occurs when some real-time events are taken into account in the ordinary job shop scheduling problem. Most researches about the DJSS problem have focused on methods in which the problem’ s input data structure and their probable relation- ship are not considered in the optimization process while some useful information can be extracted from such data. In this paper, the variable neighborhood search (VNS) combined with the k-means algorithm as a modified VNS (MVNS) algorithm is proposed to address the DJSS problem. The k- means algorithm as a cluster analysis algorithm is used to place similar jobs according to their processing time into the same clusters. Jobs from different clusters are considered to have greater probability to be selected when an adjacent for a solution is made in an optimization process using the MVNS algorithm. To deal with the dynamic nature of the problem, an event-driven policy is also selected. Computational results obtained using the proposed method in comparison with VNS and other common algorithms illustrate better performance in a variety of shop floor conditions. Keywords Dynamic job shop scheduling . Variable neighborhood search . Cluster analysis . K-means algorithm 1 Introduction The job shop scheduling (JSS) problem is an optimization problem in which a schedule of jobs that have known opera- tional sequences and time, in a multi-machine environment, is determined. This is one of the most interesting realms for researchers and practitioners, having attracted extensive in- vestigations both in academic and applied fields. The JSS problem is also a combinatorial optimization problem and well-known to be NP-hard. The dynamic job shop scheduling (DJSS) problem emerges when real-time events such as ran- dom job arrivals and machine breakdowns are taken into account in ordinary JSS problems. Most researches in the DJSS problem are about introducing new solving methods or enhance existing methods to improve solution quality only by focusing on the solving method capabilities ignoring input data structure and their probable relationship. Qi et al. [1] proposed a genetic algorithm (GA) approach to address the DJSS problem. Chryssolouris and Subramanian [2] used a scheduling method based on GA for a dynamic job shop with unreliable machines, multiple routes, and multiple scheduling criteria. Dewan and Joshi [3] presented an auction-based distributed scheduling mechanism to address the DJSS prob- lem. Dominic et al. [4] proposed combined dispatching rules for scheduling in a dynamic job shop environment. Yang et al. [5] proposed a layered hybrid algorithm for the DJSS problem that was composed of an improved ant colony optimization (ACO) algorithm to select machines in the outer layer and a GA with neighborhood search to sort jobs in the inner layer. Li and Chen [6] presented a hybrid approach combining the back propagation neural network (BPNN) with GA for solving the problem when machine breakdown and new job arrivals oc- cur. In their research, the BPNN was used to obtain feasible solution during the iterations, and GA is adapted to the global optimal searching. Cunli [7] proposed an assorted dynamic job shop scheduling algorithm based on impact degree. Vinod and Sridharan [8] developed a discrete-event simulation model for a DJSS problem with sequence-dependent setup time. Zhou et al. [9] explored the applicability of the ACO algorithm in DJSS problems comparing the most adopted approaches in the real world. Wang et al. [10] developed an improved hybrid discrete genetic algorithm particle swarm optimization to solve M. A. Adibi : J. Shahrabi (*) Industrial Engineering and Management Systems Department, Amirkabir University of Technology, Tehran, Iran e-mail: [email protected]Int J Adv Manuf Technol DOI 10.1007/s00170-013-5354-6
Transcript
ORIGINAL ARTICLE
A clustering-based modified variable neighborhood searchalgorithm for a dynamic job shop scheduling problem
Mohammad Amin Adibi & Jamal Shahrabi
Received: 8 October 2011 /Accepted: 26 September 2013# Springer-Verlag London 2013
Abstract The dynamic job shop scheduling (DJSS) problemoccurs when some real-time events are taken into account inthe ordinary job shop scheduling problem. Most researchesabout the DJSS problem have focused on methods in whichthe problem’s input data structure and their probable relation-ship are not considered in the optimization process while someuseful information can be extracted from such data. In thispaper, the variable neighborhood search (VNS) combinedwith the k-means algorithm as a modified VNS (MVNS)algorithm is proposed to address the DJSS problem. The k-means algorithm as a cluster analysis algorithm is used toplace similar jobs according to their processing time into thesame clusters. Jobs from different clusters are considered tohave greater probability to be selected when an adjacent for asolution is made in an optimization process using the MVNSalgorithm. To deal with the dynamic nature of the problem, anevent-driven policy is also selected. Computational resultsobtained using the proposed method in comparison with VNSand other common algorithms illustrate better performance in avariety of shop floor conditions.
The job shop scheduling (JSS) problem is an optimizationproblem in which a schedule of jobs that have known opera-tional sequences and time, in a multi-machine environment, isdetermined. This is one of the most interesting realms for
researchers and practitioners, having attracted extensive in-vestigations both in academic and applied fields. The JSSproblem is also a combinatorial optimization problem andwell-known to be NP-hard. The dynamic job shop scheduling(DJSS) problem emerges when real-time events such as ran-dom job arrivals and machine breakdowns are taken intoaccount in ordinary JSS problems. Most researches in theDJSS problem are about introducing new solving methodsor enhance existing methods to improve solution quality onlyby focusing on the solving method capabilities ignoring inputdata structure and their probable relationship. Qi et al. [1]proposed a genetic algorithm (GA) approach to address theDJSS problem. Chryssolouris and Subramanian [2] used ascheduling method based on GA for a dynamic job shop withunreliable machines, multiple routes, and multiple schedulingcriteria. Dewan and Joshi [3] presented an auction-baseddistributed scheduling mechanism to address the DJSS prob-lem. Dominic et al. [4] proposed combined dispatching rulesfor scheduling in a dynamic job shop environment. Yang et al.[5] proposed a layered hybrid algorithm for the DJSS problemthat was composed of an improved ant colony optimization(ACO) algorithm to select machines in the outer layer and aGAwith neighborhood search to sort jobs in the inner layer. Liand Chen [6] presented a hybrid approach combining the backpropagation neural network (BPNN) with GA for solving theproblem when machine breakdown and new job arrivals oc-cur. In their research, the BPNN was used to obtain feasiblesolution during the iterations, and GA is adapted to the globaloptimal searching. Cunli [7] proposed an assorted dynamicjob shop scheduling algorithm based on impact degree. Vinodand Sridharan [8] developed a discrete-event simulation modelfor a DJSS problemwith sequence-dependent setup time. Zhouet al. [9] explored the applicability of the ACO algorithm inDJSS problems comparing the most adopted approaches in thereal world. Wang et al. [10] developed an improved hybriddiscrete genetic algorithm particle swarm optimization to solve
M. A. Adibi : J. Shahrabi (*)Industrial Engineering and Management Systems Department,Amirkabir University of Technology, Tehran, Irane-mail: [email protected]
Int J Adv Manuf TechnolDOI 10.1007/s00170-013-5354-6
the JSS and DJSS problem. Fatemi Ghomi and Iranpoor [11]proposed a mixed integer programming mathematical formu-lation of the DJSS problem and developed a metaheuristicalgorithm which is composed of GA and simulated annealingcalled GA-SA algorithm to solve it. Vinod and Sridharan [12]studied the effects of due-date assignment methods and sched-uling rules on the performance of a job shop production systemin a dynamic environment.
In addition to solvingmethod capabilities to improve, someinformation in the problem’s input data such as necessaryoperations for each job, operation processing time, operationsequence, and etc. can be used in the optimization process toenhance solution quality and reduce required processing time.Chang [13] proposed an approach that can be used to providereal-time estimates of the queuing times for the remainingoperations of the jobs in a dynamic job shop and to incorpo-rate this estimated queuing time information into existingscheduling heuristics to improve their performance. Aydinand Oztmel [14] used a reinforcement learning agent to selectappropriate dispatching rules for scheduling according to theshop floor condition in the real-time job shop. Wei et al. [15]presented an iterative optimization framework for the dynamicscheduling system using reinforcement learning. Wang et al.[16] used the ACO algorithm to minimize make span in jobshop scheduling in which the ACO algorithm parameters areupdated according to shop floor conditions. Zandieh andAdibi [17] used a trained artificial neural network to updateparameters of a metaheuristic method at any reschedulingpoint in a DJSS problem according to the problem conditions.Chen et al. [18] proposed a rule driven dispatching methodbased on data envelopment analysis and reinforcement learn-ing for a multi-objective dynamic scheduling problem.Kapanoglo and Alikalfa [19] introduced an unsupervisedlearning scheduling system that builds “state” and “priorityrule” pairs depending on intervals of queue by using a rule-basedGA for a DJSS problem.
Among all approaches to knowledge extraction, clusteringis a data analysis task with numerous applications in a varietyof areas including bioinformatics, data mining, informationretrieval, information theory, machine learning, object, char-acter and pattern recognition, etc. [20]. Generally, clusteringtechniques are used to discover natural groups in datasets andto identify abstract structures that might exist without havingany background knowledge of the characteristics of the data.
In this study, to use both capable solving methods andextracted information from the problem’s input data, variableneighborhood search (VNS) [21] combined by cluster analysisalong with an event-driven policy is selected as a schedulingmethod to obtain an optimum solution (or a near optimum) atany rescheduling point for the DJSS problem.
VNS brings together a lot of desirable properties for ametaheuristic such as simplicity, efficiency, effectiveness,generality, etc. that has been widely used for combinatorial
optimization problems in recent years [22]. To enhance theefficiency and effectiveness of VNS, cluster analysis on inputdata at any rescheduling point is performed. As explained indetails in Sect. 4, by placing similar jobs according to theiroperational processing time into the same classes, uselessmovement in the VNS optimization process can be reducedby preventing similar sequence selections in replacementmechanism. K-means as a popular algorithm in clustering isalso used in this paper to identify similar sequences because ofits simplicity and low CPU time needs.
The rest of the paper is organized as follows: in Sect. 2, thedynamic job shop scheduling problem is defined in details.The k-means clustering analysis technique is described inSect. 3. The modified variable neighborhood search algorithmis argued in Sect. 4. The simulation study is presented inSect. 5, and the conclusion is put forth in Sect. 6.
2 Dynamic job shop scheduling problem
In the general job shop scheduling problem, n jobs should beprocessed on m machines, while minimizing a function ofcompletion time of jobs is considered alongwith the followingtechnological constraints and assumptions [17]:
& Each machine can perform only one operation at a time onany job.
& An operation of a job can be performed by only onemachine at a time.
& Once an operation has begun on a machine, it must not beinterrupted.
& An operation of a job cannot be performed until its precedingoperations are completed.
& There are no alternate routings, i.e., an operation of a jobcan be performed by only one type of machine.
& Operation processing time and the number of operablemachines are known in advance.
In this paper, mean flow timeminimization is selected as anoptimization objective. The flow time for the j th job can bedefined as f j=c j−r j;j =1,2,…n ., where r j and c j are j th jobready time (time at which a job arrives in the shop floor and is
Fig. 1 Gantt diagram of the solution represented by [2 1 3 2 3 3 1 1 2]
Int J Adv Manuf Technol
equal to 0 in case of ordinary or static JSS problems) andcompletion time, respectively. Thus, mean flow time is equalto∑ j =1
n (c j−r j)/n over the manufacturing horizon. The aim ofsolving a JSS problem is to find a sequence of jobs beingprocessed on each machine so that the objective function isminimized.
The operation-based representation method [23] whichencodes a schedule (equal to a JSS problem solution) as asequence of numbers is also selected to present a JSS problemsolution. In this method, each number stands for one opera-tion. The specific operation represented by a number isinterpreted according to the order of the numbers in the string.Each of the n numbers, representing n jobs, will appear mtimes spread over the entire string. For instance, consider onetime unit for each operation and [1 2 3; 2 3 1; 3 2 1] as a pre-defined required operation sequence for jobs 1, 2, and 3. Weare given a solution like 2 1 3 2 3 3 1 1 2½ � ,where {1, 2, 3} represents {job1, job2, job3}, respectively.Obviously, there are a total of nine operations, but threedifferent integers are repeated three times. The first integer,2, represents the first operation of the second job, O21, to beprocessed first on the corresponding machine. Likewise, thesecond integer, 1, represents the first operation of the first job,O11. Thus, the set of 2 1 3 2 3 3 1 1 2½ � isunderstood as [O21,O11,O31,O22,O32,O33,O12,O13,O23],where Oij stands for the j th operation of the i th job. Figure 1illustrates the Gantt diagram of the solution.
Random job arrivals and machine breakdowns that belongto job-related and resource-related real-time events, respec-tively, are considered in this paper in order to impose morereality in job shops. So contrary to ordinary JSS problem, alljobs are not ready at the beginning of the planning process butcome to the shop floor gradually. In addition, some machinerymay break down during the processing jobs. Finding jobsequences to be processed on machinery in such environmentis known as the DJSS problem [1].
In the job shop environment, the distribution of the jobarrival process closely follows the Poisson distribution.Hence, the time between arrivals of jobs is distributed expo-nentially [24–26]. The time between two breakdowns andrepair time are also assumed to follow an exponential distri-bution. Thus, the mean time between failure (MTBF) and themean time to repair (MTTR) are two parameters related tomachine breakdown.
In the dynamic job shop framework, considering an event-driven policy [27], in which rescheduling is triggered inresponse to a dynamic event that changes the current condition,a static job shop problem is generated whenever a new jobarrives or a machine breaks down. At that time, we consider anew job with the remaining operation of previous jobs or abroken machine that needs time to repair.
The new static problem is fed to the proposed schedulingmethod (MVNS) to produce an optimum or a nearly optimumschedule. The optimum solution will be used as productionschedule until the next event takes place.
3 K-means algorithm
Given n patterns, or data points, in d-dimensional space, theclustering problem refers to the process of partitioning the npatterns into k groups or clusters based on some similaritymetrics. An optimal clustering is a partitioning that minimizes
Step 1. Randomly choose k cluster center from all pattern in the data set D.
Step 2. Assign each pattern in D to the closest cluster center; then update the cluster centers.
Step 3. If the new cluster centers and the previous ones are the same, then terminate; otherwise, return to Step 2.
Fig. 2 Steps of the k-means algorithm
Start
Consider Jobsexist in shop floor
at beginning
Are you in planninghorizon?
Run optimizationalgorithm(MVNS) which uses
information extracted frominput data by clustering
Execute optimumschedule until next realtime event takes place
Finish
yes
No
Perform jobclustering
Fig. 3 Proposed strategyfor dynamic job shopscheduling problem
Int J Adv Manuf Technol
the intra-cluster distance and maximizes the inter-clusterdistance. In practice, the most popular metric is the sum ofsquared errors which is defined as Eq. (1).
SSE ¼Xk
i¼1
Xn
j¼1X ij−Ci
�� ��2 ð1Þ
Where
Ci ¼ 1
ni
Xn
j¼1X ij ð2Þ
denotes the mean of the i th cluster, k the number of clusters,Xij the j th pattern in the i th cluster, ni the number of patternsin the i th cluster, and
n ¼Xk
i¼1ni: ð3Þ
In this paper, a heuristic algorithm illustrated in Fig. 2[20,28] is used to do the clustering of n jobs based onsimilarity between m dimensional processing time vectorsfor each job in forms of the k-means clustering problem. It is
notable that the k-means clustering problem is computationallyhard (NP hard), but the selected heuristic algorithm is efficient interms of execution time and converges to a clustering structurequickly even though the obtained clustering structure is not aglobal optimum [29].
At any rescheduling point, the remaining jobs are clusteredby the k-means algorithm, and distances between clustercenters are calculated to be considered as a base to determinethe probability of selecting jobs to make neighborhoods asexplained in details in Sect. 4 (Fig. 3).
4 Modified VNS for the DJSS problem
The VNS algorithm as a metaheuristic method is widely usedto solve combinatorial problems. The algorithm searches theneighborhood of a solution until another solution better thanthe incumbent is found and then jumps to the new one. VNStries to escape from a local optimum by changing the neigh-borhood structure (NS) that is the manner in which the
Fig. 4 Steps of the modifiedVNS (MVNS) algorithm
Fig. 5 Steps of the local searchalgorithm
Int J Adv Manuf Technol
neighborhood is defined. Neighborhoods are usually rankedin such a way that solutions increasingly far from the currentone are explored [30,31].
The VNS algorithm begins with an initial solution, x ∊S ,where S is the set of search space, and uses a two-nested loop.The inner loop alters and explores using two main functions,namely “shake” and “local search,” respectively. The outerloop works as a refresher reiterating the inner loop. The localsearch explores a better solution within the local neighbor-hood, while the shake diversifies the solution by switching toanother local neighborhood. In this paper, using the k-meansalgorithm, neighborhoods are made by a knowledge extractedfrom input data so that more diversification is assured byselecting jobs from different clusters. In the proposed selec-tion mechanism, the distance between cluster centers is con-sidered to calculate the probability of selecting a job numberto make a new adjacent. In other words, in this approach, a jobthat belongs to a farther cluster has a greater probability to beselected in making a new adjacent than one belonging to acloser cluster. The rate of similar jobs that have operationswith zero processing time can be high in dynamic environ-ment because when a real-time event takes place, with a highprobability, some operations of the current jobs are done.Considering an event-driven policy, it causes a reduction inVNS efficiency.
In VNS, the inner loop iterates as long as it keeps improv-ing the solutions, where an integer ,i , controls the length of the
loop. Once an inner loop is completed, the outer loop reiteratesuntil the termination condition is met. The steps of the modifiedVNS (MVNS) structure are illustrated in Fig. 4.
To reduce computational time and enhance efficiency andeffectiveness, two famous neighborhood structures, insertionand swap [32], are modified to be used in the proposedoptimization algorithm process for both shake and local searchfunction. Such modification consists of determining theprobability of job selection in NSs using job clusteringresults. The two neighborhood structures employed in theproposed algorithm are defined below.
1. Conducted insertion : Identifies two particular operationsbased on probability obtained from clustering results andplaces one operation in the position that directly precedesthe other operation.
2. Conducted swap : Identifies two particular operationsbased on probability obtained from clustering resultsand places each operation in the position previously oc-cupied by the other operation.
A threshold accepting method local search [33] based onthe two mentioned NSs is used in this paper. The thresholdaccepting method is an iterative procedure in which x ′←x ′′
when f(x ′′)−f(x ′)≤dr ; where dr is the acceptance level. Localsearch function steps are illustrated in Fig. 5.
5 Simulation
To demonstrate the performance of the proposed method, ajob shop environment consisting of ten machines is simulated.It is noteworthy that a job shop with more than six machinespresents the complexity involved in a large dynamic job shopscheduling problem [2]. The simulation starts consideringinitial jobs in the shop floor at the beginning and continuesuntil the number of new job arriving at the shop floor reaches1,200. The mean flow time of the latest 1,000 jobs that leavethe shop floor during the planning horizon is selected as theperformance measure. The proposed method is compared toVNS in its basic form and to make a fair comparison betweenVNS andMVNS; optimization parameters are selected so thatthe same CPU time is generated. It is also compared to three
Table 1 Comparison of the MVNS and other algorithms
common heuristics that are widely used in the DJSS literaturenamely SPT, LIFO, and FIFO.
Furthermore, it is assumed that all machines have the sameMTTR and MTBF equal to 300 and 5,700 time unit, respec-tively. Thus, on an average of 5,700 time unit, a machine isavailable and then breaks down with a mean time to repair of300 time units. Increasing mean time between job arrivals(MTBJA) and considering fixed values of MTBF and MTTRleads to an increase in the number of jobs that simultaneouslyexist in the shop floor at the rescheduling point. During thesimulation, the number of jobs that simultaneously exist in theshop floor may reach more than 200 jobs. Simulation isrepeated at four states of MTBJA, 300, 250, 200, and 150time unit. The number of clusters is also considered over thesimulation process as a tradeoff between exploration andexploitation in the MVNS algorithm. Results are presentedin Table 1.
As presented in Table 1, the proposed method improves theperformance measure in comparison with VNS.
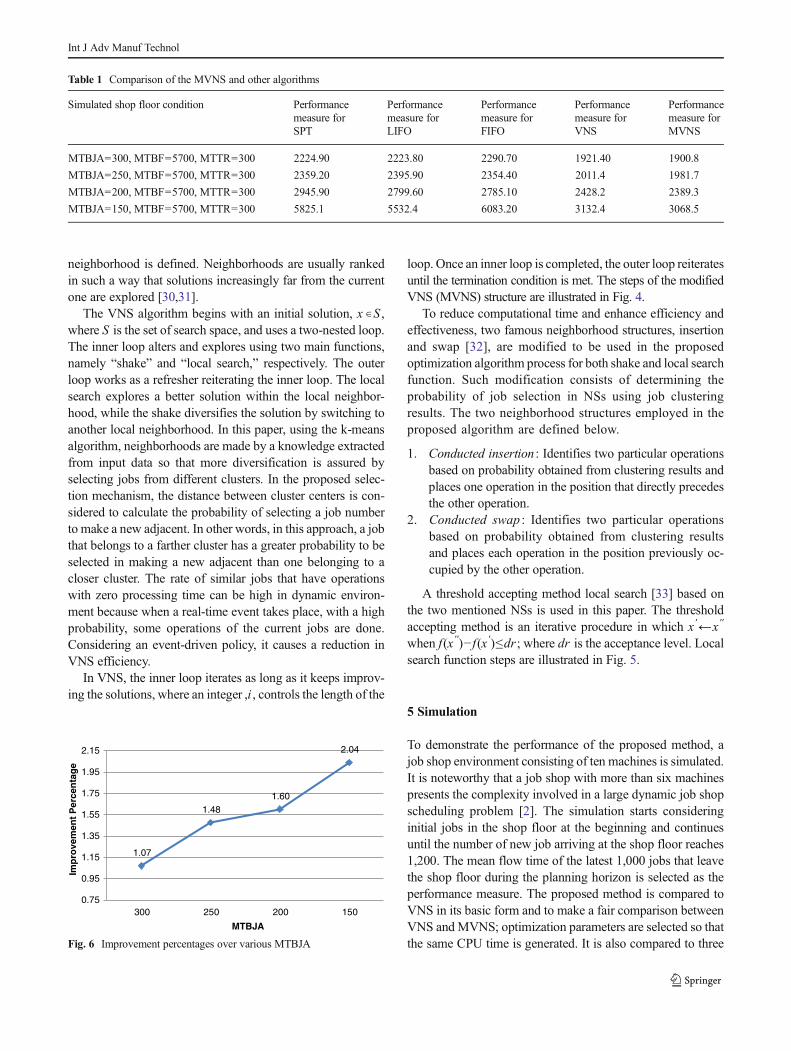
In Fig. 6, improvement percentages over different MTBJAare illustrated. It is obvious that as the problem gets harder, theproposed method generates better schedules.
6 Conclusion
In this paper, a cluster analysis algorithm is used to extractknowledge from the problem’s input data in a dynamic jobshop scheduling problem in order to improve optimizationresults. In fact, the extracted knowledge is used in optimiza-tion process by variable neighborhood search algorithm. In theoptimization process that is triggered when a real-time eventoccurs to make a new adjacent solution, jobs in the fartherclusters have greater probability to be selected in the replacementmechanism. The proposed method (MVNS) was compared toVNS and some common heuristics using a simulated jobshop under a range of different conditions. Results indicatethat the performance of the proposed method is significantlybetter than VNS and other methods including three heuristicsnamely SPT, LIFO, and FIFO.
Conflict of interest The authors declare that they have no conflict ofinterest.
References
1. Qi JG, Burns GR, Harrison DK (2000) The application of parallelmulti-population genetic algorithms to dynamic job shop scheduling.Int J Adv Manuf Technol 16:609–615
2. Chryssolouris G, Subramanian E (2001) Dynamic scheduling ofmanufacturing job shops using genetic algorithm. J Intell Manuf12:281–293
3. Dewan P, Joshi S (2001) Implementation of an auction-based distributedscheduling model for a dynamic job shop environment. Int J ComputIntegr Manuf 14:446–456
4. Dominic PDD, Kaliyamoorthy S, Saravana Kumar M (2004)Efficient dispatching rules for dynamic job shop scheduling. Int JAdv Manuf Technol 24:70–75
5. Yang G, Yu-si D, Hong-yu Z (2009) Job-shop Scheduling Consider-ing Rescheduling in Uncertain Dynamic Environment. InternationalConference on Management Science and Engineering - 16th AnnualConference Proceedings, ICMSE, art. no. 5317409, pp. 380–384
6. Li Y, Chen Y, (2009) Neural network and genetic algorithm-basedhybrid approach to dynamic job shop scheduling problem, Confer-ence Proceedings - IEEE International Conference on Systems, Manand Cybernetics , art. no. 5346060, pp. 4836–4841
7. Cunli S (2009) An Assorted Dynamic Job-Shop Scheduling AlgorithmBased on Impact Degree. Conference Proceedings - IEEE InternationalConference on Computational Intelligence and Software Engineering,art. no. 5365563
8. Vinod V, Sridharan R (2009) Simulation-based metamodels forscheduling a dynamic job shopwith sequence-dependent setup times.Int J Prod Res 47:1425–1447
9. Zhou R, Nee AYC, Lee HP (2009) Performance of an ant colonyoptimization algorithm in dynamic job shop scheduling problems. IntJ Prod Res 47:2903–2920
10. Wang S, Xiao X, Li F, Wang C (2010) Applied Research ofImproved Hybrid Discrete PSO for Dynamic Job-shop Sched-uling Problem. IEEE Proceedings of the 8th World Congresson Intelligent Control and Automation, art. no. 5553799, pp.4065–4068
11. Fatemi Ghomi SMT, Iranpoor M (2010) Earliness-tardiness-lost salesdynamic job shop scheduling. Prod Eng Res Devel 4:221–230
12. Vinod V, Sridharan R (2011) Simulation modeling and analysis ofdue-date assignment methods and scheduling decision rules in adynamic job shop production system. Int J Prod Econ 129:127–146
13. Chang FCR (1997) Heuristics for dynamic job shop schedul-ing with real-time updated queuing time estimates. Int J ProdRes 35:651–665
14. Aydin ME, Oztemel E (2000) Dynamic job-shop scheduling usingreinforcement learning agents. Robot Auton Syst 33:169–178
15. Wei Y, Jiang X, Hao P, Kanfeng G U, (2009) Multi-agent Co-evolutionary Scheduling Approach based on Genetic ReinforcementLearning. 5th International Conference on Natural Computation,ICNC, art. no. 5366784, pp. 573–577
16. Wang M, Zhang X, Dai Q, He J (2010) A Dynamic ScheduleMethodology for Discrete Job Shop Problem Based on Ant ColonyOptimization. 2nd IEEE International Conference on InformationManagement and Engineering 5, art. no. 5477648, pp. 306–309
17. Zandieh M, Adibi MA (2010) Dynamic job shop scheduling usingvariable neighborhood search. Int J Prod Res 48:2449–2458
18. Chen X, Hao X, Lin H W, Murata T (2010) Rule Driven MultiObjective Dynamic Scheduling by Data Envelopment Analysis andReinforcement Learning. IEEE International Conference on Auto-mation and Logistics, art. No. 5585316, pp. 396–401
19. Kapanoglo M, Alikalfa M (2011) Learning IF–THEN priority rulesfor dynamic job shops using genetic algorithms. Robot ComputIntegr Manuf 27:47–55
20. Kogan J (2007) Introduction to clustering large and high-dimensionaldata. Cambridge University Press, New York
21. Mladenovic N, Hansen P (1997) Variable neighborhood search.Comput Oper Res 24:1097–1100
22. Hansen P, Mladenovic N, Moreno Perez JA (2007) Variable neigh-borhood search. Eur J Oper Res 191:593–595
23. Amirthagadeswaran KS, Arunachalam VP (2006) Improved solu-tions for job shop scheduling problems through genetic algorithmwith a different method of schedule deduction. Int J Adv ManufTechnol 28:532–540
Int J Adv Manuf Technol
24. Rangsaritratsamee R, Ferrell WG, Kurz MB (2004) Dynamicrescheduling that simultaneously considers efficiency and stability.Comput Ind Eng 46:1–15
25. Sha DY, Liu CH (2005) Using data mining for due date assignment ina dynamic job shop environment. Int J AdvManuf Technol 25:1164–1174
26. Vinod V, Sridharan R (2007) Scheduling a dynamic job shop pro-duction system with sequence-dependent setups: an experimentalstudy. Robot Comput Integr Manuf 24:435–449
27. Sabuncuoglu I, Kizilisik OB (2003) Reactive scheduling in adynamic and stochastic FMS environment. Int J Prod Res 41:4211–4231
28. Jain AK (2010) Data clustering: 50 years beyond k-means. PatternRecogn Lett 31:651–666
29. Bard JF, Jarrah AI (2009) Large-scale constrained clustering for ratio-nalizing pickup and delivery operations. Transp Res B 43:542–561
30. Perez JAM, Vega JMM, Martin IR (2003) Variable neighborhoodtabu search and its application to the median cycle problem. Eur JOper Res 151:365–378
31. Hansen P, Mladenovic N (2001) J-MEANS: a new local searchheuristic for minimum sum of squares clustering. Pattern Recogn34:405–413
32. Liao CJ, Cheng CC (2007) A variable neighborhood search forminimizing single machine weighted earliness and tardiness withcommon due date. Comput Ind Eng 52:404–413
33. Bouffard Y, Ferland JA (2007) Improving simulated annealing withvariable neighborhood search to solve the resource-constrainedscheduling problem. J Sched 10:375–386