A COMPILER FRAMEWORK FOR LOOP NEST SOFTWARE-PIPELINING by Alban Douillet A dissertation submitted to the Faculty of the University of Delaware in partial fulfillment of the requirements for the degree of Doctor of Philosophy in Computer Sci- ence Summer 2006 c 2006 Alban Douillet All Rights Reserved
Transcript
A COMPILER FRAMEWORK
FOR LOOP NEST SOFTWARE-PIPELINING
by
Alban Douillet
A dissertation submitted to the Faculty of the University of Delaware in partialfulfillment of the requirements for the degree of Doctor of Philosophy in Computer Sci-ence
Approved:B. David Saunders, Ph.D.Chair of the Department of Computer and Information Sciences
Approved:Thomas M. Apple, Ph.D.Dean of the College of Arts and Sciences
Approved:Conrado M. Gempesaw II, Ph.D.Vice Provost for Academic and International Programs
I certify that I have read this dissertation and that in my opinion it meets theacademic and professional standard required by the University as a dissertationfor the degree of Doctor of Philosophy.
Signed:Guang R. Gao, Ph.D.Professor in charge of dissertation
I certify that I have read this dissertation and that in my opinion it meets theacademic and professional standard required by the University as a dissertationfor the degree of Doctor of Philosophy.
Signed:Lori Pollock, Ph.D.Professor in charge of dissertation
I certify that I have read this dissertation and that in my opinion it meets theacademic and professional standard required by the University as a dissertationfor the degree of Doctor of Philosophy.
Signed:Martin Swany, Ph.D.Member of dissertation committee
I certify that I have read this dissertation and that in my opinion it meets theacademic and professional standard required by the University as a dissertationfor the degree of Doctor of Philosophy.
Signed:Fouad Kiamilev, Ph.D.Member of dissertation committee
ACKNOWLEDGEMENTS
I would like to acknowledge my advisor, Prof. Guang R. Gao, for his support
during those years. He allowed me to work in very favorable conditions while made sure
that I had all the help I needed. His many pieces of advice always happened to be helpful
both on a professional and on a personal level.
This work would have never happened without Dr. Hongbo Rong. He let me work
with him on the SSP project in its early phases and then let me develop my own line of
research. I will always be grateful for his patience during our many heated discussions.
He taught me a lot about persevering and believing in your own work. He also set the bar
higher than I would have myself and motivated me to reach it and go beyond.
Such a large project would not have been possible without the participation of
others. First Dr. Shuxin Yang for porting the Open64 compiler to the IBM Cyclops
architecture in such a short time. Then Juan del Cuvillo for his very helpful answers to
my questions about the architecture. Finally the rest of the Cyclops development team at
ETI including Dr. Ziang Hu, Dr. Haiping Wu, and Weirong Zhu.
I also would like to thank my family for supporting me during all those years.
Despite the distance, they always approved any of my decisions.
Finally my girlfriend, Nina Hansen, was very supportive during the last busy
months of the writing. She showed me the bright side in everything and always kept
me in good spirits.
iv
In memory of my grandfathers Georges Douillet and Charles Binaux.
8.1 Code Generation Issues and Solutions for Both Target Architectures . . 172
xxi
ABSTRACT
While improving the performance of micro-processors, computer architects have
recently reached a technology wall. Higher frequencies are not sustainable anymore.
The high and expensive power consumption and the lack of performance improvement
on those uniprocessors have lead chip manufacturer to instead provide multi-threading
capabilities to their current processor line. The trend goes further with multi-threaded
cellular architectures where a chip is composed of hundred of thread units interconnected
by an on-chip network and showing impressive raw performance numbers.
However, the problem of harnessing so much computational power has yet to be
solved. Several issues such as thread synchronization and programmability still exist.
This dissertation proposes an elegant method, named Single-dimension Software Pipelin-
ing (SSP) to address those issues for an important class of programming structures, espe-
cially in the scientific domain: loop nests, perfect and imperfect.
This dissertation shows how loop nests can be software-pipelined on both unipro-
cessor architectures and cellular architectures. The method subsumes modulo-scheduling
as a special case for single loops. The entire framework is explained and includes: the
handling of multi-dimensional dependences, the loop selection, the kernel generation, the
register pressure evaluation, the register allocation and the code generation for both cel-
lular architecture and uniprocessor architectures with dedicated loop hardware support.
The method was implemented in the Open64 compiler and tested on the Intel
Itanium architecture and on the IBM Cyclops64 architecture. Results show that SSP
schedules outperform modulo-scheduling schedules on uniprocessor architectures and ef-
ficiently use the computational power of the cellular architectures.
xxii
Chapter 1
INTRODUCTION
Parallel processing and data-flow were the buzz words of the 1980’s. Several com-
panies spurred in order to bring to market implementation ideas that had been developed
in research and academic labs. Computer performance was to come from highly parallel
machines. However, the results did not live up to the expectations. All those companies
either went bankrupt or redirected their efforts to dedicated niche markets.
The failure of parallel processing can be explained by several reasons [The99].
Mainly developing a whole new family of processors represents a huge investment which
requires immediate results in order to convince customers to switch to the new architec-
ture. Intel’s recent struggles with the Itanium architecture despite the enormous amount
of investment poured into the project is another example of those difficulties. However
performance is not the only criterion. The main reason behind the lack of success was
the lack of programmability. There was no easy way to extract performance from those
machines. Only institutions with the adequate budget and man power could afford using
this new breed of computers.
To fill the need for more computing power, computer architects turned their efforts
to other types of architectures. A standard von Neumann processor consists of a single
program counter which points to the instruction to be executed. Therefore, the number
of instructions executed per cycle (IPC) never exceeds 1. Increasing the performance of
computers would have to be achieved through going beyond an IPC of 1 and exploit-
ing the instruction level parallelism (ILP). That barrier was breached by the superscalar
1
and VLIW (Very-Long Instruction Word) architectures [HP03]. A superscalar processor
includes several functional units. At run-time, instructions within a given window may
be shuffled from their sequential order in order to be executed as soon as input data are
ready and a functional unit is available. The sequential order semantics is guaranteed.
VLIW processors are similar but the instructions are instead reordered by the compiler.
Instructions that are to be executed in parallel are packed in a single very long instruction
word.
Those two architectures represent the bulk of today’s processors. Unfortunately
the point of diminishing return has been reached. In order to continuously improve the
performance of the processors, architects increased the chip clock speed to unprecedented
levels. Intel even forecast that Xeon processors would be running at more than 10GHz
by the end of the decade. But such a speed comes with a cost. The instructions are
decomposed into micro-instructions and the pipelines of the functional units are made
deeper and deeper. Any interrupt then forces the entire pipeline to be flushed resulting
in an increased waste of precious computing cycles. Also, the use of micro-instructions
only artificially increases the IPC of a processor as the whole original instruction might
actually take longer to execute. Moreover, in order to bridge the performance gap between
the processor and the memory, increasing amounts of cache are moved onto the processor
itself. The result is a chip which computing power is concentrated in a small area. Because
of the high clock speed, that area heats up enormously leading to cooling and power
consumption problems. As a technological wall has been reached, it is now time to move
up to a new type of architecture.
1.1 Towards Cellular Architectures
To cope with the ever increasing power consumption, new architecture classes
were introduced. All have in common the duplication of the processing units within
a single chip. Because the number of transistors on a single chip doubles somewhat
every 18 months, multi-core processing was probably the easiest step towards a more
2
power-friendly solution. As more space on the chip is available, extra processors are
inserted. Each processor is independent from the others with its own L1 cache. They
might share the L2 cache though. As long as there are enough independent tasks to feed
each processor, the computing power of a chip is then a linear function of the number of
processors.
However, the multi-core solution duplicates a large number of functional units
that are continuously dissipating heat. If a processor does not use all of its functional
units at every cycle, that energy is wasted. A solution is to use Simultaneous Multi-
Threading (SMT) [ACC+90, TEL95, TEE+96, CWT+01]. Then several processors share
a pool of functional units. An extra hardware arbiter is in charge of fairly distributing the
instructions of each processor over the available functional units. It is the current solution
used by Intel for the Pentium processor family.
A bigger architectural leap is made with cellular architectures [CCC+02,
ACC+03]. A single chip is composed of one hundred or more thread units. Each thread
unit is a simplified processor with a very limited number of functional units. All the thread
units have access to on-chip shared memory and are interconnected by a network. The
ILP paradigm then shifts to Thread-Level Parallelism (TLP). Such architectures present
several advantages. They consume much less power than the multi-core or SMT archi-
tectures. The heat is evenly distributed through the entire chip. Computing performance
comes from the large number of thread units, not from the processing power of few pro-
cessors. Those chips are also easy and therefore cheaper to manufacture. If few thread
units or memory units are not functional, the chip itself is still functional. The chip design
is highly modular. The number of thread units may vary depending if more memory is
required for instance.
1.2 Problem Description
Therefore cellular architectures are very similar to the paralleling processors pro-
posed in the 1980’s. The large gap between the processors then and today’s cellular
3
architectures has been filled through smooth and economically sound modifications from
one processor generation to the next.
Unfortunately the programmability issues remain untackled: how to harness so
much computational power? How to program applications that will benefit from so much
parallelism? How to synchronize the threads executing on all the thread units? How to
communicate data from one thread to another in a timely fashion? It is the purpose of this
dissertation to propose a solution to these questions for a group of program structures:
loop nests.
Loop nests are present in almost all applications, especially in the scientific do-
main where they can represent 90% of the total execution time of the application. It is
therefore important to ensure their fast execution on any architecture.
The solution proposed in this dissertation, named Single-dimension Software-
Pipelining (SSP) is a complete compilation framework which generates a fully multi-
threaded schedule to execute any imperfect loop nests on cellular architectures. The orig-
inal source code remains unchanged as if the loop nest was to be executed on a unipro-
cessor. Synchronizations between the threads are automatically handled. The framework
includes several steps. In order those are: loop selection, dependences simplification,
kernel generation, register pressure evaluation, register allocation and code generation.
1.3 Contributions
The traditional and most efficient method to schedule a single loop or the
innermost loop of a loop nest on a single processor machine is called software-
pipelining [Lam88]. Rong’s theoretical preliminary work [Ron01] describes the foun-
dation for extending software-pipelining to perfect loop nests on an ideal uniprocessor
architecture. It is the starting point of this work.
The following original contributions are primarily the work of the author:
4
1. The definition and refinement of the level separation constraint for the schedule
functions into the innermost level separation constraint.
2. The design, construction and evaluation of several scheduling methods to generate
the kernel of operations on which an SSP schedule is based.
3. The formulation of an inexpensive but accurate method to evaluate the register pres-
sure of an SSP schedule in order to detect as early as possible infeasible schedules.
4. The specification and evaluation of the code generation scheme for SSP schedules
on cellular architectures with limited dedicated hardware support (rotating regis-
ters).
5. The design of a multi-threaded SSP scheduling solution on cellular architectures.
The solution automatically generates a synchronized software-pipelining schedule
to be executed on a given number of thread units.
The following original contributions are the joint work of the author and Dr. Rong :
5. The formulation of the theoretical schedule functions for perfect and imperfect loop
nests and their properties. The author played a major role in proving the correctness
of those functions.
6. The definition and implementation of heuristics to detect the most profitable loop
level to software pipeline within a loop nest.
7. The specification and evaluation of the code generation scheme for SSP schedules
on VLIW architectures with dedicated hardware support such as rotating registers,
predication, and loop counters.
8. The definition and evaluation of a normalized and complete representation of life-
times in a SSP schedule and a method to use the representation to allocate a mini-
mum of registers to the loop variants of the schedule.
5
1.4 Synopsis
This dissertation is organized as follows:
• The next chapter explains in detail the two target architectures used for the work in
this dissertation. The VLIW architecture is the Itanium architecture, which offers
hardware support for loop execution such as rotating registers, predication and loop
counters. Their usage and the related assembly instructions are detailed there. The
cellular architecture is the IBM 64-bit Cyclops architecture. It features a hundred
thread units and shared memory blocks on a single chip and interconnected by a
cross-bar network. Some useful definitions are also presented.
• Chapter 3 describes the Single-dimension Software-Pipelining (SSP) theory. The
compilation framework is also introduced, followed by the theoretical scheduling
functions. The correctness proofs for perfect and imperfect loop nests and the prop-
erties of SSP schedules are also present. The evaluation of the SSP schedules as
opposed to other loop scheduling methods are shown there.
• Chapter 4 presents two different heuristics to evaluate the most profitable loop level
in a loop nest. That level will be chosen to software-pipeline the loop nest. The first
heuristic is based on resource usage and dependences while the second considers
cache reuse potential.
• Chapter 5 introduces three different methods to generate the one-dimensional SSP
schedule: the kernel. The first method schedules the loop levels one after the other
starting from the innermost. The second schedules all the operations from all the
loop levels simultaneously. The third is an hybrid approach which tries to merge the
advantages of the two other methods. At the end the three methods are evaluated
over a set of benchmarks.
• Chapter 6 shows a fast and accurate solution scheme to evaluate the final register
pressure of the entire SSP schedule by only considering its kernel. If the register
6
pressure is too high, another kernel must be found. The speed and correctness of
the method are also evaluated there.
• Chapter 7 presents the normalized representation of the lifetimes of loop variants
in SSP schedules. This representation is then used to find a register allocation
solution that accommodates all the loop variants of the schedule while minimizing
the register usage. The efficiency of the representation and of the register allocation
solution are tested over a large set of benchmarks. The impact of a solution that
uses no more registers than available is also shown.
• Chapter 8 shows the code generation scheme used for VLIW architectures with
dedicated loop execution hardware support such as register rotation, predication
and loop counter. The method presented shows how to deal with a lack of a multiple
level rotating register file.
• Chapter 9 details the code generation scheme for a single thread unit on cellular
architectures like the IBM 64-bit Cyclops architecture. Then the scheme is extended
to use all the thread units available. The synchronization issues are also handled.
Experimental speedup curves are presented.
• Chapter 10 concludes this dissertation and presents some future work directions.
7
Chapter 2
BACKGROUND
2.1 Software-Pipelining
Because of their repetitive nature, loops represent the most significant part of the
total execution time of programs. Naturally, numerous optimizations, transformations and
scheduling methods have been proposed to reduce the execution time of loops, and soft-
ware pipelining (SWP) is probably the main scheduling method. When applicable, SWP
can be considered as the most powerful scheduling technique for single loops. For a small
cost in code size, SWP makes usage of the machine resources and available instruction-
level parallelism by overlapping the execution of two or more consecutive iterations of
the same loop.
2.1.1 Overview
Typically, without SWP, consecutive iterations of a loop are scheduled one after
the other. Iteration i+1 will start only once iteration i has terminated. Instructions within
a single iteration are scheduled using an instruction scheduler appropriate for the target ar-
chitecture such as list scheduling [Hu61], hyperblock scheduling [MLC+92], superblock
scheduling [WMC+93].
For instance, let us consider the loop example in Figure 2.1 that computes the sum
of the elements of one array and the product of the elements of a second array. Each
operation is assumed to have a latency of 1 cycle and both arrays have a size of N. On any
pipelined non-superscalar architecture and without SWP, the loop is computed as-is using
8
L1: for I = 1, N doop1 : load r1,r10,4 //load A[i] with post-incrementop2 : load r2,r11,4 //load B[i] with post-incrementop3 : add r20,r20,r1 //cumulative sumop4 : mul r21,r21,r2 //cumulative productop5 : store r30,r20,4 //store sum with post-incrementop6 : store r31,r21,4 //store product with post-increment
end for
Figure 2.1: Single Loop Example
list scheduling [AU77]. If N = 6 and if every instruction has a latency of one cycle, then
the total execution time of the loop is N ∗ 6 = 36 cycles, not counting loop overheads.
The schedule is shown in Figure 2.2. The horizontal axis represents the iterations of the
loop while the vertical axis represents time. Consecutive iterations do not overlap.
Although list scheduling sounds simple and intuitive, some challenges remain. For
instance, care must be taken when allocating registers: if a loop variant belongs to both
live-in and live-out sets of a loop, the register allocator must make sure that the variable
is placed in the same register at the entrance and exit of the loop body.
On the other hand, SWP tries to schedule iteration i+ 1 before iteration i finishes.
Data dependences and resource availability limit how much overlapping can be achieved.
An instruction cannot be scheduled before its input values are computed and the same
functional unit can only be used by one instruction at a time. The scheduling problem is
NP-complete when resource constraints are taken into consideration [GJ79].
2.1.2 Modulo Scheduling
There exist several different software-pipelining techniques. Modulo schedul-
ing (MS) is probably the most well-known [RST92, Rau94, Fea94, GAG94, EDA95,
AGG95]. An iteration is partitioned into S stages of T cycles. In one cycle of each stage
zero, one, or more operations can be scheduled. T , the initiation interval, is the same for
every stage. A new loop iteration is issued every T cycles and a maximum of S stages are
9
cycles
op1op2op3op4op5op6
op1op2op3op4op5op6
op1op2op3op4op5op6
op1op2op3op4op5op6
op1op2op3op4op5op6
op1op2op3op4op5op6
543210
one loop iteration
iterations
Figure 2.2: Single Loop Schedule Example
executed in parallel. The final schedule is usually partitioned into 3 phases: the prolog,
the stable phase and the epilog. The prolog initializes the loop execution and fills up the
pipeline. When S iterations can run in parallel, the kernel is executed repeatedly until the
last iteration is issued. Then, the epilog is executed to flush the pipeline.
Our loop example is easily software-pipelined. The loop body is partitioned into
S = 3 stages a, b, c of T = 2 cycles each. Each stage contains two instructions (i1
and i2 in c; i3 and i4 in b; i5 and i6 in a). This is an ideal case. In the general case,
stages may have slots containing no instruction at all because of data dependencies or
10
op1op2
op3op4
op5op6
abc
T=2
S=3
(a) MS kernel
c
b
a
c
b
a
c
b
a
c
b
a
c
b
a
c
b
a
543210
kernel
cycles
prolog
stable phase
epilog
(b) MS Schedule
Figure 2.3: Single Loop MS Schedule Example
hardware constraints. The prolog, kernel and epilog are shown on Figure 2.3. The kernel
is executed four times. A new iteration is issued every T cycles. Thanks to the overlapping
of consecutive iterations, the total execution time of the same loop is now 16 cycles.
There exist several modulo-scheduling techniques that can be separated into
two categories: optimal and heuristic-based. Optimal modulo-scheduling techniques
[AG86, EDA95, GAG94, NG93, RGSL96] are necessary for evaluation purposes but their
high computation time due to the NP-completeness of the scheduling problem makes
their implementation in a production compiler impractical. Among the heuristic-based
techniques, the most relevant methods are: Iterative Modulo-Scheduling [Rau94], Slack
Given the 1-D DDG and the resources of the target processor, shown in Fig-
ure 3.13(b), a 1-D schedule can be computed. The 1-D schedule is represented by a
kernel shown in Figure 3.13(c). The innermost stages have been grayed out. The op-
erations are scheduled so that the latencies between dependent operations are respected.
Also, at each given cycle, the number of scheduled operations never exceed the number of
available functional units (2). The kernel is composed of 2 outermost stages and S2 = 2
innermost stages for a total of S1 = 4 stages. The initiation interval of the outermost
kernel is equal to T1 = 3. However, the initiation interval of the innermost kernel, i.e. the
kernel used to generate the schedule corresponding to the execution of the innermost loop
and represented by the gray boxes, is lower and equal to T2 = 2. It is therefore a multiple
initiation interval kernel.
41
a
a
b
cc
cc
cc
b
b
bb
b
b
cc
cc
cc
b
b
bb
b
b
b
b
c
cd
a
a
b
b
c
cd
a
a
d
cc
cc
cc
b
b
bb
b
b
b
b
c
cd
ad
c
c
cb
b
b
cd
d 102 cycles
innermost iterations from
run concurrentlydifferent outermost iterations
outermost iteration
innermost iteration(runs sequentially with theother innermost iterationswithin the same outermostiteration)
time
(runs concurrently with theother outermost iterations)
1 outermostiterations
765432
1 2 3 4 scheduling groups
delay
T1=3
T2=2
Figure 3.14: Double Loop Nest Example: Final Schedule
42
The impact of multiple initiation interval kernel can be seen in the final schedule
shown in Figure 3.14. The stages are represented by their symbolic letters for readability
purposes. Small horizontal tics delimit the cycles within each stage. When an inner-
most stage is used alongside an outermost stage with a higher initiation interval, then its
initiation interval is adjusted with the schedule slots marked as ’unused’ in the kernel.
Otherwise, the innermost initiation interval of 2 is used. If the initiation interval of the
innermost kernel was always equal to T1 = 3 cycles, then the execution of the inner loops
would be delayed, and the final schedule would be 24 cycles longer in this particular
example.
The delay function used to enforce the resource constraints in the final schedule
has been represented by thick black arrows. Every stage that does not belong to an itera-
tion from the current group of outermost iterations is delayed. The start time of iterations
3 and above have been delayed accordingly in groups of Sn outermost iterations. Stage d
from the last outermost iteration of each scheduling group was also delayed.
The schedule illustrates how outermost iterations are executed in parallel whereas
the innermost iterations within the same outermost iteration are executed sequentially.
Innermost iterations from different outermost iterations, on the other hand, are also exe-
cuted in parallel. Because the number of outermost iterations is not a multiple of Sn, the
last outermost iteration is executed alone.
It is worth noting that the positive dependence from op4 to op2 in the original n-D
DDG is still respected. Indeed, op2 from innermost iteration J is always executed at least
1 cycle after op4 from innermost iteration J − 1.
3.4.3 Triple Loop Nest Example
The next example shows how the final schedule differs when the loop nest contains
three loops or more. The section of the schedule during the delay now also includes
the middle loops which leads to more complex patterns and a more complex schedule
43
function. The duration of the delay is also increased to take into account the newly added
loops.
We assume that the multiple initiation interval kernel of a triple loop nest is as
shown in Figure 3.15. Again, the innermost stages are grayed out while the unused sched-
ule slots are shown with hashes. The middle kernel, i.e. the kernel corresponding to the
middle loop of the original loop nest, is composed of S2 = 4 stages b, c, d, and e. As op-
posed to the previous example, the inner kernels, innermost and middle, are not scheduled
in the last schedule rows of the outermost kernel.
op6
op7
op8
op9
ef
T3
S3
op1
op2
op3
op4
op5
abcd
T2
S2
S1
T1
Figure 3.15: Triple Loop Nest Example: Kernel
The final schedule corresponding to the proposed kernel is shown in Figure 3.15.
We assume that the number of iterations for the loops are 8, 2, and 3, from the outermost
to the innermost level respectively. Indeed we have 8 columns corresponding to the 8
outermost iterations. Within each outermost iteration, the stages b and e appear only
twice, and between each appearances, the innermost stages c and d are executed three
times. Unlike the double nest example, stages are not represented in the figure according
to their to their initiation interval of the stages for space reasons.
This time the schedule has been decomposed into different sections that will later
useful for the code generation phase. The schedule starts with a Prolog, only composed
of stage a in this example. Then it is an alternation of two segments: the Outermost Loop
Pattern (OLP) and the Inner Loop Execution Segments (ILES). OLP corresponds to the
part of the schedule where outermost stages are executed. The ILES corresponds to the
44
time
a
aa
bbc
ccd
dc
cd
d
debc
cd
be
ccd
dc
cd
d
b ac b
d ce d
eff
d ce d
eff
eff
d c b ae d c b a
d c b ae d c b a
eff
Innermost LoopPattern (ILP)
Draining & FillingPattern (DFP)
Innermost LoopPattern (ILP)
Outermost LoopPattern (OLP)
Segment (ILES)Innermost Loop Execution
Outermost LoopPattern (OLP)
1 765432
1 32 4
8
scheduling groups
Epilog
Folded ILES
Prologoutermostiterations
Figure 3.16: Triple Loop Nest Example: Schedule
45
rest of the schedule and is composed of several patterns named the Innermost Loop Pat-
tern (ILP) and the Draining & Filling Pattern (DFP). The ILP corresponds to the execu-
tion of only the innermost stages. The DFP corresponds to the phases where the pipeline
of the last innermost iteration is drained and the pipeline of the next first innermost itera-
tion is filled. The ILES only appears in the cycles where the schedule is delayed because
of resource constraints. For space reasons, the other occurrences of the ILES are folded
and represented by a crossed-out box instead. Finally, the draining of the last outermost
iterations is called the Epilog.
As for the innermost level in the previous example, the inner iterations are all
executed sequentially within an outermost iteration, but in parallel between different out-
ermost iterations. The number of outermost iterations per scheduling group is again equal
to the number of innermost stages S3.
3.4.4 Kernel Notations
For future references we introduce here some notations about SSP kernels. The
generic kernel in Figure 3.17 illustrates those concepts.
unused
f2 f1
T2 T1nTKn
K2
K1
S2
Sn
fnlnl2l1
S1
T −11
stageindex
......01...
...
rowindex
Figure 3.17: Generic SSP Kernel
An SSP kernel of a loop nest of depth n is composed of n subkernels named K1
to Kn from the outermost to the innermost. K1 corresponds to the entire kernel. Each
46
subkernel Ki is made of Si = li− fi stages where fi and li are the indexes of the first and
last stage of Ki in K1. The initiation interval of each subkernel Ki is noted Ti. The used
schedule slots may contain 0, 1, or more operations. The number of operations within one
cycle, i.e. a row in the generic kernel, is limited by the resource constraints. The number
of unused cycles above subkernel Ki is noted Tai. The number of unused cycles below
subkernel Ki is noted Tbi.
The 1-D schedule function of an operation op in the kernel is noted σ(op, i1). i1
represents the outermost iteration index. Operations from the same instance of the kernel
share the same i1 value. The stage index and row index can be derived from the 1-D
schedule function. We can write σ(op, 0) = p ∗ T + q where q < T . Then p is the stage
index of op and q the row index of op in the kernel. We also have p = bσ(op, i1)/T cand q = σ(op, i1) modulo T . The stage and row indexes will be necessary for several
algorithms in subsequent chapters.
If the loop nest is perfect, the kernel is composed solely of the innermost kernel
Kn. Therefore a single initiation interval T = Tn is used. In the most general case, the
loop nest is imperfect and each loop level uses its own initiation interval. For theoretical
and practical issues, a kernel with multiple initiation interval can always be considered
as a schedule with single initiation interval from which the unused cycles have been re-
moved.
For clarity reasons, the unused slots of the subkernels are assumed to contain no
operations. However, the theory and algorithms presented in the dissertation consider
that operations may appear in those cycles. Indeed an operation from level i can appear
in any cycle within the boundaries of subkernel Ki. Some practical issues will limit such
freedom at the code generation level, as presented in Chapter 8.
3.5 One-Dimensional Schedule Constraints
The 1-D schedule must obey some constraints to be correct. This section presents
those constraints in three situations from the most specific to the most general: perfect
47
loop nests, imperfect loop nests with single initiation interval, and imperfect loop nests
with multiple initiation intervals.
3.5.1 Perfect Loop Nests
In the case of perfect loop nests, the 1-D schedule is uniquely composed of opera-
tions from the innermost loop. Therefore the kernel consists of only innermost stages and
all the stages have the same initiation interval T . The constraints to be respected by the
1-D schedule can then be written as shown in Figure 3.18.
• Modulo Property:
σ(op, i1 + 1) = σ(op, i1) + T (3.1)
• Dependence Constraints:
σ(op1, i1) + δ ≤ σ(op2, i1 + k) (3.2)
for all the dependences from the 1-D DDG from op1 to op2 where δ is thelatency of the dependence and k the distance.
• Resource Constraints:
At any given cycle of the 1-D schedule, a hardware resource is not allocatedto more than one operation.
• Sequential Constraints:
σ(op, 0) + δmax(op) ≤ S ∗ T (3.3)
where δmax(op) = max(δ) for all the positive dependences starting from opin the original n-D DDG.
Figure 3.18: 1-D Schedule Constraints in the case of Perfect Loop Nests
The first 3 constraints are the same as the constraints used in MS. The modulo
constraint ensures that a new outermost iteration is issued every T cycles. The dependence
constraint ensures that the dependences from the 1-D DDG are respected while taking into
48
account the modulo property. The resource constraints ensures that the target architecture
can actually execute the 1-D schedule.
The sequential constraint however is unique to the SSP method. It ensures that the
positive dependences, not present in the 1-D DDG, are respected. In the final schedule,
such a dependence only exist between operations from different slices (Figure 3.2). If the
dependence is already respected at the end of the slice of the originating operation, then it
will be guaranteed to be respected in the subsequent slices. In the first outermost iteration
of the first slice, as shown in Figure 3.19, the destination operation can be scheduled once
the positive dependence is respected, i.e. after cycle σ(op, 0) + δmax. The end of the
first slice is at cycle S ∗ T , where S ∗ T is the length of the 1-D schedule (S stages of T
cycles each). Therefore the positive dependence is always respected if we guarantee that
σ(op, 0) + δmax(op) ≤ S ∗ T . Because the destination operation is not necessarily in the
first cycle of the next slice, the constraint is not tight. However it simplifies the schedul-
ing process while making sure that positive dependences are respected. In practice, the
constraint is respected most of the time without taking any special action.
abcdabcdabcd
abcd
abcd
abcd
abcd
abcd
abcd
abcd
abcd
abcd
abcd
abcd
abcd
slice 0
slice 1
slice 2
positive dependence
S.T
σ
δ
Figure 3.19: Sequential Constraint Example
49
3.5.2 Imperfect Loop Nests & Single Initiation Interval
When considering imperfect loop nests, the constraints are slightly different. We
first consider the easier case where the initiation interval is the same for every subkernel.
The constraints are shown in Figure 3.20.
• Modulo Property:
σ(op, i1 + 1) = σ(op, i1) + T (3.4)
• Dependence Constraints:
σ(op1, i1) + δ ≤ σ(op2, i1 + k) (3.5)
for all the dependences from the 1-D DDG from op1 to op2 where δ is thelatency of the dependence and k the distance.
• Resource Constraints:
At any given cycle of the 1-D schedule, a hardware resource is not allocatedto more than one operation.
• Sequential Constraints:
σ(op, 0) + δ ≤ Sp ∗ T (3.6)
for every positive dependence−→d = (d1, ..., dn) originating from op in the
original n-D DDG and where dp is the first non-null element in the subvector(d2, ..., dn).
• Innermost Level Separation Constraint:
Only operations from the innermost loop can be scheduled in the innermoststages.
Figure 3.20: 1-D Schedule Constraints in the Case of Imperfect Loop Nests and SingleInitiation Interval
The first three constraints are identical to the perfect loop nest case. The sequential
constraint differs in the sense that positive dependences must now be respected at the end
of the execution of the loop at level pwhere dp is the first non-null element in the subvector
50
(d2, ..., dn). The size of corresponding slice is therefore Sp ∗ T instead of S ∗ T . Because
p may be different for each positive dependence originating from the same operation, the
latency δ is used instead of δmax.
The last constraint is new and not necessary in theory. In practice, however, it is
required to limit the code size of the final schedule during the code generation step. A 1-D
schedule that does not respect the innermost level separation constraint would be correct,
but too inefficient to use in practice. For more details, the reader is referred to Chapter 8.
If dp is the first non-null index of the positive dependence vector, then dp ≥ 1 and
we have:
k=n∑
k=2
(dk ∗
j=n+1∏
j=k+1
Nj
)
= dp ∗j=n+1∏
j=p+1
Nj +k=n∑
k=p+1
(dk ∗
j=n+1∏
j=k+1
Nj
)
≥ dp ∗j=n+1∏
j=p+1
Nj −k=n∑
k=p+1
(|dk| ∗
j=n+1∏
j=k+1
Nj
)because dk ≥ −|dk|
≥ dp ∗j=n+1∏
j=p+1
Nj +k=n∑
k=p+1
((1−Nk) ∗
j=n+1∏
j=k+1
Nj
)because |di| ≤ Ni − 1
≥ dp ∗j=n+1∏
j=p+1
Nj +k=n∑
k=p+1
j=n+1∏
j=k+1
Nj −k=n∑
k=p+1
(Nk ∗
j=n+1∏
j=k+1
Nj
)
≥ dp ∗j=n+1∏
j=p+1
Nj +k=n∑
k=p+1
j=n+1∏
j=k+1
Nj −k=n−1∑
k=p
j=n+1∏
j=k+1
Nj
≥ dp ∗j=n+1∏
j=p+1
Nj +Nn+1 −j=n+1∏
j=p+1
Nj
≥ (dp − 1) ∗j=n+1∏
j=p+1
Nj +Nn+1
≥ Nn+1 because dp ≥ 1
≥ 1 (3.22)
58
Therefore, using Equations 3.21 and 3.22, we can conclude that, in the case of a
positive dependence from op1 to op2, we have:
f(op2,−→I +−→d )− f(op1,
−→I ) ≥ 0 (3.23)
Using Equation 3.23 and Equation 3.20, we prove that both positive and zero depen-
dences, i.e. all the dependences from the original n-D DDG, are enforced.
Lastly, we need to prove that, at any cycle, no resource is used more than once.
Let op1 and op2 be two operations appearing in the same cycle in the final schedule at
iteration−→I = (i1, ..., in) and
−→I +−→d = (i1 +d1, ..., in+dn), respectively. Then we have:
f(op2,−→I +−→d )− f(op1,
−→I )
= σ(op2, i1)− σ(op1, i1) + d1 ∗ T + S ∗ T ∗k=n∑
k=2
(dk ∗
j=n+1∏
j=k+1
Nj
)
+S ∗ T ∗(⌊
i1 + d1
S
⌋−⌊i1S
⌋)∗(j=n∏
j=2
Nj − 1
)
= 0 (3.24)
If (d1, ..., dn) = (0, ..., 0), then σ(op1, i1) = σ(op2, i1). In other words, the two
operations belong to the same schedule slot of the kernel. Thanks to the resource con-
straint of the kernel, there cannot be any resource conflict between them. Therefore, if
there is a resource conflict, we must have (d1, ..., dn) 6= (0, ..., 0).
Because every term of the above equation, except σ(op2, i1) − σ(op1, i1), is a
multiple of T , then σ(op1, i1) and σ(op2, i1) have the same value modulo T . Therefore, if
there is a resource conflict, the two operations must appear in the same row in the kernel.
However, the resource constraint enforced on the kernel ensures that operations
scheduled in the same row have no resource conflict. Therefore, if there is a resource
conflict in the final schedule, at least one operation must have two instances scheduled at
the same cycle. If we can guarantee that at any cycle an operation appears no more than
once, then the schedule has no resource conflict.
59
Let us assume the contrary and prove that it is absurd. Let us assume that op1 =
op2. We have two cases depending on if the instances of the operation belong to the same
scheduling group or not:
• If the two instances of the operations belong to the same scheduling group, i.e. |d1|< S and
⌊i1S
⌋=⌊i1+d1
S
⌋, then we have:
f(op2,−→I +−→d )− f(op1,
−→I ) = 0
⇒ d1 ∗ T + S ∗ T ∗k=n∑
k=2
(dk ∗
j=n+1∏
j=k+1
Nj
)= 0
⇒ S ∗k=n∑
k=2
(dk ∗
j=n+1∏
j=k+1
Nj
)= −d1 (3.25)
⇒ S ∗∣∣∣∣∣k=n∑
k=2
(dk ∗
j=n+1∏
j=k+1
Nj
)∣∣∣∣∣ < S because |d1| < S
⇒∣∣∣∣∣k=n∑
k=2
(dk ∗
j=n+1∏
j=k+1
Nj
)∣∣∣∣∣ < 1
⇒k=n∑
k=2
(dk ∗
j=n+1∏
j=k+1
Nj
)= 0
We now prove by recurrence that the last equation implies that d2 to dn are equal
to zero. If n = 2, the property is obviously true. If the property is true for n = p,
i.e. we have the following recurrence property:k=p∑
k=2
(dk ∗
j=p+1∏
j=k+1
Nj
)= 0 =⇒ (d2, ..., dp) = (0, ..., 0)
we show that it is true if n = p+ 1:k=n∑
k=2
(dk ∗
j=n+1∏
j=k+1
Nj
)= 0
⇒ dn = −Nn ∗k=p∑
k=2
(dk ∗
j=p+1∏
j=k+1
Nj
)
⇒ |dn| = Nn ∗∣∣∣∣∣
k=p∑
k=2
(dk ∗
j=p+1∏
j=k+1
Nj
)∣∣∣∣∣
60
If the sum on the right-hand side is strictly positive, then |dn| > Nn, which is
impossible. Therefore the sum is equal to zero and dn = 0. Using the recurrence
property for n = p, we show that (d2, ..., dn − 1) = (0, ..., 0). Therefore our
recurrence property is also verified for n = p+ 1.
Thus, (d2, ..., dn) = (0, ..., 0). According to Equation 3.25, d1 is also equal to zero,
which is impossible because−→d 6= −→0 . Therefore op1 6= op2.
• If the two instances of the operations do not belong to the same scheduling group,
i.e.⌊i1+d1
S
⌋−⌊i1S
⌋≥ 1, then we have:
f(op2,−→I +−→d )− f(op1,
−→I )
≥ d1 ∗ T + S ∗ T ∗k=n∑
k=2
(dk ∗
j=n+1∏
j=k+1
Nj
)+ S ∗ T ∗
(j=n∏
j=2
Nj − 1
)
≥ d1 ∗ T − S ∗ T ∗k=n∑
k=2
(|dk| ∗
j=n+1∏
j=k+1
Nj
)+ S ∗ T ∗
(j=n∏
j=2
Nj − 1
)
Because |dk| ≤ Nk − 1, we can continue using Nn+1 = 1 later:
≥ d1 ∗ T + S ∗ T ∗[(
j=n∏
j=2
Nj − 1
)−
k=n∑
k=2
((Nk − 1) ∗
j=n+1∏
j=k+1
Nj
)]
≥ d1 ∗ T + S ∗ T ∗[j=n∏
j=2
Nj − 1−k=n∑
k=2
j=n+1∏
j=k
Nj +k=n∑
k=2
j=n+1∏
j=k+1
Nj
]
≥ d1 ∗ T + S ∗ T ∗[j=n+1∏
j=2
Nj − 1−k=n∑
k=2
j=n+1∏
j=k
Nj +k=n∑
k=2
j=n+1∏
j=k+1
Nj
]
≥ d1 ∗ T + S ∗ T ∗[j=n+1∏
j=2
Nj − 1−k=n−1∑
k=1
j=n+1∏
j=k+1
Nj +k=n∑
k=2
j=n+1∏
j=k+1
Nj
]
≥ d1 ∗ T + S ∗ T ∗[j=n+1∏
j=2
Nj − 1−j=n+1∏
j=2
Nj +Nn+1
]
≥ d1 ∗ T
Because f(op2,−→I +
−→d ) − f(op1,
−→I ) = 0 and T > 0, we have d1 = 0. However
we had by hypothesis d1 > 0. Therefore the result is absurd and op1 6= op2.
61
Therefore an operation cannot appear more than once at given cycle in the final schedule
and the final schedule has no resource conflict. �Next, we compare the execution time of the final SSP schedule with the most
optimistic MS schedule under the same initiation interval T and number of stages S. We
assume that the prolog and epilog phases of the MS schedule are entirely overlapped as
proposed in [MD01].
Theorem 3.2 Given a perfect loop nest with a number of outermost iterations N1 and an
SSP kernel and MS kernel with the same number of stages S and initiation interval T ,
if N1 is divisible by S, then the length of the final SSP schedule is not greater than the
length of the MS schedule.
Proof. In the most optimistic case, the MS schedule of a perfect loop nest overlapping
prologs and epilogs will issue a new iteration every T cycles. It will then take (S− 1) ∗Tcycles to flush the pipeline. Therefore the length of the MS schedule is:
lengthMS = T ∗ (
j=n∏
j=1
Nj + S − 1) (3.26)
The length of SSP final schedule can be computed using the schedule function
from Equation 3.16. The last cycle corresponds to an operation op scheduled in the last
cycle of the kernel (σ(op, 0) = S∗T−1) at iteration vector (N1−1, ..., Nn−1). Therefore
the length of the final schedule is equal to:
lengthSSP
= 1 + f(op, (N1 − 1, ..., Nn − 1))
= 1 + (S ∗ T − 1) + (N1 − 1) ∗ T + S ∗ T ∗⌊N1 − 1
S
⌋∗(j=n∏
j=2
Nj − 1
)
+S ∗ T ∗k=n∑
k=2
((Nk − 1) ∗
j=n+1∏
j=k+1
Nj
)
62
Because N1 is divisible by S,⌊N1−1S
⌋= N1
S− 1 and after expanding, we obtain:
= S ∗ T + (N1 − 1) ∗ T + S ∗ T ∗(N − 1
S− 1
)∗(j=n∏
j=2
Nj − 1
)
+S ∗ T ∗(k=n∑
k=2
j=n+1∏
j=k
Nj −k=n∑
k=2
j=n+1∏
j=k+1
Nj
)
= S ∗ T + (N1 − 1) ∗ T + S ∗ T ∗(N − 1
S− 1
)∗(j=n∏
j=2
Nj − 1
)
+S ∗ T ∗(k=n−1∑
k=1
j=n+1∏
j=k+1
Nj −k=n∑
k=2
j=n+1∏
j=k+1
Nj
)
= S ∗ T + (N1 − 1) ∗ T + S ∗ T ∗(N − 1
S− 1
)∗(j=n+1∏
j=2
Nj − 1
)
+S ∗ T ∗(j=n+1∏
j=2
Nj − 1
)by elimination and because Nn+1 = 1
= S ∗ T + (N1 − 1) ∗ T + S ∗ T ∗(N1 − 1
S
)∗(j=n+1∏
j=2
Nj − 1
)
= T ∗[S +N1 − 1 + (N1 − 1) ∗
(j=n+1∏
j=2
Nj − 1
)]
= T ∗[S +N1 − 1 +
j=n+1∏
j=1
Nj −N1
]
Therefore, we have:
lengthSSP = T ∗(S − 1 +
j=n+1∏
j=1
Nj
)(3.27)
Because Nn+1 = 1, Equations 3.26 and 3.27 are identical. Therefore, under the same
conditions, if N1 is divisible by S, then the SSP final schedule is at least as short as the
MS schedule. �If N1 is not divisible by S, loop peeling is always possible. Moreover, the extra
iterations are negligible compared to the execution of the loop nest and, in practice, the
result still holds even if N1 is not divisible by S.
63
3.6.2 Imperfect Loop Nests & Single Initiation Interval
In practice, most of the loop nests are imperfect. Even if the loop nest is perfect
at the source level, compiler optimizations, transformations and address calculations will
most likely make it imperfect by the time the loop nest is to be scheduled. In this section,
we present the schedule function of the SSP final schedule in the case of imperfect loop
nests. We assume here that all the subkernels share the same initiation interval T .
To compute the function, four terms must be taken into account. Let us consider
the instance of an operation op at iteration−→I = (i1, ..., in). As in the case of perfect
loop nests, the first term represents the cycle of the operation within the 1-D schedule,
σ(op, 0), and the second term is the starting cycle of an outermost iteration and is equal
to:
i1 ∗ T (3.28)
The third term corresponds to the execution time of the inner iterations within the
current outermost iteration:
k=n∑
k=2
ik ∗ timeLk (3.29)
where timeLk is the execution time of one iteration of the loop Lk within one outermost
iteration in the ideal schedule where operations have not been delayed yet:
timeLk =i=n∑
i=k
((Si − Si+1) ∗ T ∗
j=i∏
j=k+1
Nj
)
Sn+1 = 0
Finally the delay is added, incurred by the resource conflicts that may appear in
the ideal schedule. Every Sn stages, the non-innermost stages are pushed down. The
length of the push is equal to the execution time of all the inner iterations that appear in
the ILES, i.e. timeL1 − S1 ∗ T . The formula must also take into account that during
64
the prolog and epilog of the final schedule some pushes are omitted, leading to this rather
Ai is positive for i = 3. We now assume that Ai ≥ 0. Let us prove that Ai+1 is also
positive:
Ai+1 = d2 ∗ (Ni+1 − 1) ∗j=i∏
j=3
Nj − |di+1| − (Ni+1 − 1) ∗k=i∑
k=3
|dk| ∗j=i∏
j=k+1
Nj
= −|di+1|+ (Ni+1 − 1) ∗[d2 −
k=i∑
k=3
|dk| ∗j=i∏
j=k+1
Nj
]
= −|di+1|+ (Ni+1 − 1) ∗[(
d2 ∗ (Ni − 1) ∗j=i−1∏
j=3
Nj + d2 ∗j=i−1∏
j=3
Nj
)
−(|di|+
k=i−1∑
k=3
|dk| ∗j=i∏
j=k+1
Nj
)]
= −|di+1|+ (Ni+1 − 1) ∗[(
d2 ∗ (Ni − 1) ∗j=i−1∏
j=3
Nj + d2 ∗j=i−1∏
j=3
Nj
)
−(|di|+ (Ni − 1) ∗
k=i−1∑
k=3
|dk| ∗j=i−1∏
j=k+1
Nj +k=i−1∑
k=3
|dk| ∗j=i−1∏
j=k+1
Nj
)]
The term Ai appears in the equation. Because Ai ≥ 0, Ai + 1 is minored by:
(Ni+1 − 1) ∗[d2 ∗
j=i−1∏
j=3
Nj −k=i−1∑
k=3
|dk| ∗j=i−1∏
j=k+1
Nj
]− |di+1|
70
Since |dk| ≤ Nk − 1, we can continue:
Ai+1 ≥ (Ni+1 − 1) ∗[d2 ∗
j=i−1∏
j=3
Nj −k=i−1∑
k=3
|dk| ∗j=i−1∏
j=k+1
Nj
]− |di+1|
≥ (Ni+1 − 1) ∗[d2 ∗
j=i−1∏
j=3
Nj −k=i−1∑
k=3
(Nk − 1) ∗j=i−1∏
j=k+1
Nj
]− |di+1|
≥ (Ni+1 − 1) ∗[d2 ∗
j=i−1∏
j=3
Nj −k=i−1∑
k=3
j=i−1∏
j=k
Nj +k=i−1∑
k=3
j=i−1∏
j=k+1
Nj
]− |di+1|
≥ (Ni+1 − 1) ∗[d2 ∗
j=i−1∏
j=3
Nj −k=i−1∑
k=3
j=i−1∏
j=k
Nj +k=i∑
k=4
j=i−1∏
j=k
Nj
]− |di+1|
≥ (Ni+1 − 1) ∗[d2 ∗
j=i−1∏
j=3
Nj −j=i−1∏
j=3
Nj + 1
]− |di+1| by elimination
≥ (Ni+1 − 1) ∗ (d2 − 1) ∗j=i−1∏
j=3
Nj + (Ni+1 − 1− |di+1|)
≥ (Ni+1 − 1) ∗ (d2 − 1) ∗j=i−1∏
j=3
Nj because |di+1| ≤ Ni+1 − 1
≥ 0 because d2 ≥ 0,j=i−1∏
j=3
Nj ≥ 1, and Ni+1 ≥ 1
Therefore Ai+1 is also positive. Using the recurrence principle, we prove that Ai ≥0 for every value of i ≥ 3. And therefore, thanks to Equation 3.38 and because
d2 ≥ 0, we have:
k=n∑
k=2
dk ∗ timeLk ≥ S2 ∗ T (3.39)
Then we have to prove that the term 3.35 is positive for the positive dependences
as well. Several cases arise depending on the values of i2, ..., in. Unlike with zero
dependencies, because (d2, ..., dn) 6= (0, ..., 0), some cases are impossible.
71
– If (i2 + d2, ..., in + dn) < (N2 − 1, ..., Nn − 1), (i2, ..., in) = (0, ..., 0), and
Figure 3.30: Speedup of the jki Variant of MM after Unroll-and-Jam
Unroll-and-Jam applied to the same variant of MM in Figure 3.30 has the same
impact. The transformation was applied on the already loop tiled code, which is used as
a reference for the speedup curves. The optimization alone brings a performance boost,
which is decreased by MS but amplified with SSP at both the L3 and L5 levels.
Both transformations increase the depth of the loop nest and decrease the number
of iterations of the innermost loop. Therefore the relative execution time of the prolog
and epilog at the innermost level becomes more important. However, because SSP can be
applied to other levels than the innermost, this limitation does not exist and SSP schedules
can take advantage of both transformations.
3.7.4 Cache Misses Analysis
In this section, we consider the cache misses to help explain further the previous
results. Because our loop nests come from scientific applications rich in floating-point
78
0
0.2
0.4
0.6
0.8
1
1.2
1.4
1.6
U&J jkitiled jkikjikijjkijikikjijk
Rel
ativ
e C
ache
Mis
ses
Benchmarks
MSSSP L1SSP L2SSP L3SSP L5
(a) L2 Cache Misses
0
0.2
0.4
0.6
0.8
1
1.2
1.4
1.6
U&J jkitiled jkikjikijjkijikikjijk
Rel
ativ
e C
ache
Mis
ses
Benchmarks
MSSSP L1SSP L2SSP L3SSP L5
(b) L3 Cache Misses
Figure 3.31: Cache Misses Results for the MM Variants
79
operations and because floating-point values bypass the L1 cache in the Itanium archi-
tecture, only the L2 and L3 cache misses are of interest. The L1 cache misses are only
due to instruction cache misses. The L2 and L3 cache misses results are shown for all the
variants of MM in Figures 3.31(a) and 3.31(b) respectively.
Overall, without any form of tiling, SSP has no negative impact on the number of
cache misses. Every time SSP is applied to the outermost loop, they are even lowered,
which would explain the better execution times. With loop tiling and unroll-and-jam,
it is however not the case. Indeed the grouping of iterations in SSP induces some data
requests that are different from what both optimizations had anticipated. However the
quality of the SSP schedules and the higher level of instruction-level parallelism offsets
such a drawback. Also, not every cache miss results in a pipeline stall. The study of the
relationship between tile size and group size in SSP is left for further research however.
It is very likely that such research will lead to different solutions than MS because of the
different memory access patterns of the SSP schedules.
3.8 Related Work
3.8.1 Hierarchical Scheduling
Lam [Lam88] proposed using hierarchical scheduling to software-pipeline loop
nests. The innermost loop is first software-pipelined and then considered as a single
operation when software-pipelining the second loop in the nest. As opposed to Wood’s
work [Woo79], the already software-pipelined loop is not a black box and other operations
can be scheduled in the same cycle as long as resource and dependence constraints are
honored. The main limitation is the fact that the inner loops must be software-pipelined
first. The scheduler might run out of resources very quickly or earlier decisions made
for the inner loop might prevent getting the most out of the outer loops. An example is
shown in Figure 3.32. The innermost loop is software pipelined first. Then, the software
pipelined instructions formed a virtual instruction that is used to software pipeline the
outermost loop. Operation op1 now overlaps the instruction blocks and the loop nest takes
80
3 less cycles to execute than with SWP only. For SWP, the outermost loop is not software
pipelined and therefore the op1 instruction does not overlap any other instruction.
Moon and Ebcioglu [ME97] also uses hierarchical scheduling. The kernel of the
innermost loop is a single VLIW instruction word. The operations of the prolog and
epilog are reinjected in the outer loop as normal operations. Selective scheduling is then
applied to the outer loop. The algorithm suffers from the same limitations as [Lam88].
3.8.2 Software-Pipelining with Loop Nest Optimizations
Although SWP is very powerful, it has a very severe limitation: SWP can only be
applied to single loops. When scheduling a loop nest of two or more embedded loops,
only the innermost loop can be software-pipelined. However the innermost loop is not
necessarily the most profitable loop to optimize. The other loops might exhibit better
properties like instruction-level parallelism (ILP) or data locality. To overcome this hur-
dle, several loop optimizations have been applied to improve the scheduling properties of
the innermost loop in a loop nest [Muc97].
Loop interchange and loop permutation [AK84, WL91b, WL91a] can be applied
to move one of the outer loops to the innermost level. Then SWP can be used to schedule
the new innermost loop. Unfortunately this method may not solve the problem: strong
data dependencies might prevent the outer loop to be moved in place of the innermost
loop.
Loop skewing [Wol86, WL91b, WL91a] changes the shape of the iteration space
into a more useful form. Some negative dependences can be transformed into positive
dependence. Because negative data dependencies prevent the usage of other loop trans-
formations, loop skewing is often used to enable other loop optimizations. The transfor-
mation is performed by applying a linear function to the indices of the loops.
Loop tiling[Wol92, WL91a] groups iterations in the iteration space together into
tiles. Tiles are then processed one by one during the loop nest execution. Tiling allows for
better usage of data locality. However, the loop transformation increases the depth of the
81
L1: for I = 1, 4 doop1
L2: for J = 1, 4 doop2
op3
end forend for
(a) A double-nested loop
cycles 24 cycles
iterations
1 2 3 4
one innermost iteration
one outermost iteration
op1op2
op2 op3
op3
op2 op3op2 op3
op1op2
op2 op3
op3
op2 op3op2 op3
op1op2
op2 op3
op3
op2 op3op2 op3
op1op2
op2 op3
op3
op2 op3op2 op3
outermost
(b) Software-Pipelining
cycles
iterations
21 cycles
1 2 3 4
virtual operation
some overlapping
op1op2
op2 op3
op3
op2 op3op2 op3
op1op2
op2 op3
op3
op2 op3op2 op3
op1op2
op2 op3
op3
op2 op3op2 op3
op1op2
op2 op3
op3
op2 op3op2 op3
outermost
(c) Hierarchical Scheduling
Figure 3.32: Hierarchical Scheduling vs. Software-Pipelining Example
82
loop nest and the overall cost of loop control overheads. Moreover, finding the optimal
tile size remains a challenge, and performance of tiled loop nests quickly decreases if the
tile size is not carefully chosen.
Loop unrolling [DH79, Sar00] duplicates the body of the innermost loop by a
given unrolling factor n and divides the total number of iterations of the innermost loop
by n. Hopefully, the instruction-level parallelism of the innermost loop is increased.
The scheduler then has more opportunities to efficiently schedule the innermost loop.
Unfortunately loop unrolling multiplies the code size of the innermost loop by a factor of
n. Also, good heuristics must be used to choose the unrolling factor.
Unroll-and-jam [CCK88, CK94, CDS96] is a generalization of loop unrolling for
outer loops in a loop nest. The chosen loop level is unrolled and the inner loops are
duplicated and fused (or jammed) together. The inner loop body is therefore duplicated
as many times as the the outer loop was unrolled. The transformation is useful when the
innermost loop shows poor instruction-level parallelism and strong data dependencies.
Instead of running innermost iterations in parallel, outermost iterations are processed.
Loop unroll-and-squash [PHA02] is a code-size optimized version of loop unroll-
and-jam. There is only one copy of the inner loop body. Some register renaming tech-
niques and register copy instructions are used to preserve the correctness of the code.
A direct consequence is a reduction in code size and a better usage of the available re-
sources. The major drawback is an increase of dependences limiting the efficiency of the
SWP scheduling algorithm used afterwards.
Software thread-integration [SD05] jams procedures together to improve the
instruction-level parallelism of the code. The method can be extended to loop nests us-
ing Deep Jam [CCJ05] to generalize unroll-and-jam which brings together independent
instructions across control structures and removed memory-based dependences.
83
3.8.3 Loop Nest Linear Scheduling
Darte et al [DSRV99, DSRV02] proposed a theoretical method to enumerate all
the tight schedules for a loop nest on a given clustered processor. A tight schedule is a
schedule that fully utilizes the resources of the processor without overloading any proces-
sor. The solution is a linear schedule: the schedule time and the processor to which each
operation is assigned is a linear function of the loop indexes.
The method is theoretical and mainly used to synthesize specialized co-processors
for application-specific hardware. Therefore all hardware constraints are either not men-
tioned (such as register allocation) or solved using ad-hoc hardware solutions (loop con-
trol overheads for instance). Also the method is limited to perfect loop nests only and a
cluster of processors can only handle one iteration each cycle.
84
Chapter 4
LOOP SELECTION
The loop selection step determines which loop level will be software pipelined by
SSP. The intent is to find the most profitable loop level, where the profitability is deter-
mined by the user. For instance, the user might be interested into minimizing the power
consumption of the processor during the execution of the loop nest, or into minimizing
the execution time of the loop nest. Although loop selection heuristics are left for future
work, the computation of two important factors are presented in this chapter, both aimed
at minimizing the execution time. The first factor is the initiation interval of the selected
loop level, the second the number of cache misses.
Another factor is the number of iterations of the selected loop level. If too low, the
cost of filling and emptying the pipeline cannot be amortized. Therefore loop levels with
a low number of iterations should be avoided. The exact number depends on the target
processor.
4.1 Initiation Interval
Given a loop level, a lower initiation interval is synonymous with shorter execution
time. Indeed, if the outermost iterations are issued more often, the schedule will terminate
earlier. It is therefore important to minimize the initiation interval.
However, to compare the execution time of the entire loop nest, the initiation inter-
val of different loop levels cannot be compared with each other. The number of iterations
of each loop level and the scheduling method used for the enclosing loops not selected
for software-pipelining need to be taken into account.
85
We present here a method to compute the minimum initiation interval (MII) of a
given loop level. The method is the method used in modulo-scheduling but applied to the
1-D DDG instead of the DDG of the innermost loop.
Two types of constraints prevent the iterations of the selected loop level from be-
ing fully parallelized. The first constraint is the dependences between operations from
different iterations. The corresponding MII is named recurrence minimum initiation in-
terval (recMII). The second constraint is the number of operations that can be executed
at the same time by the target architecture. The related MII is referred as the resource
minimum initiation interval (resMII). The method to compute resMII and recMII is
described below. MII is then equal to:
MII = max(recMII, resMII) (4.1)
4.1.1 Recurrence Minimum Initiation Interval
Given the 1-D DDG of the selected loop level, recMII can be computed directly
using the following formula:
recMII = maxcycle C
δ(C)
d(C)(4.2)
where: C is a cycle in the 1-D DDG
δ(C) is the sum of the latencies of the arcs in C
d(c) is the sum of the distances of the arcs in C
Positive dependences, which are taken care of by the sequential constraint, have
no influence on recMII . Indeed, positive dependences increase the length of the 1-D
schedule (S ∗T ), by adding extra empty stages when necessary. But the initiation interval
remains constant.
86
4.1.2 Resource Minimum Initiation Interval
In the context of pipelined function units, resMII is computed for each type of
resource such integer function units, floating-point function units,...
resMII = maxresource type R
number of operations using Rnumber of resources of type R
(4.3)
For non-pipelined function units, the reader is referred to [GAG96].
4.2 Memory Accesses
The number of memory accesses per iteration can be approximated. As a rule of
thumb, if the number of memory accesses per iteration is limited, the schedule is less
likely to create cache misses and more likely to use values in registers instead. It is
therefore interesting to evaluate such factor when deciding which loop level should be
selected.
The number of memory accesses per iteration point is approximated by consider-
ing the first single scheduling group of Sn outermost iterations. Within that group, we
consider the first Sn successive slices. The iteration space is then defined by the iteration
points of the form (i1, ..., in) where 0 ≤ i1, in ≤ Sn − 1. It corresponds to a SnXSn
square in the original iteration space. The square is representative of the references that
occur normally in the SSP schedule as most of the time is spent in the innermost loops
while Sn outermost iterations are executed in parallel. The set of iteration points can be
abstracted as a localized vector space [WL91a] α = span{(1, 0, ..., 0), (0, ..., 0, 1)}.The problem can now be applied to the memory access formulation in [WL91a].
Using the same notations and definitions, we can derive the number of memory accesses
per iteration point in the square iteration space. For an uniformly generated set in this
localized space, let RST and RSS be the self-temporal and self-spatial reuse vectors, re-
spectively. Let gT and gS be the number of group-spatial equivalent classes. Then, for
the uniformly generated set, the number of memory accesses per iteration is equal to:
gS + gT−gSl
le ∗ SdimRSS ∩ α(4.4)
87
where:
l is the cache line size
e =
0 if RST ∩ α = RSS ∩ α1 otherwise
The total number of memory accesses per iteration point is then the sum of the memory
accesses per iteration point for each uniformly generated set.
88
Chapter 5
SCHEDULER
5.1 Introduction
In this chapter, we present solutions to the SSP kernel generation problem. The
kernel is generated after the loop selection and data dependence graph simplification steps
(Figure 3.6). The input data are the 1-D DDG and the set of loop nest operations to sched-
ule. The output is the 1-D schedule. Generating kernels is not a simple task - as it involves
the overlapping of operations from several iteration levels (dimensions) of a loop nest, a
challenge not encountered in traditional software pipelining. In SSP kernels, there is one
subkernel per loop level in the loop nest, each one with its own initiation interval. Those
subkernels interact with each other and optimizing one subkernel could have a negative
impact on the others. Moreover, when the scheduler fails and the initiation interval must
be increased, which subkernel should be chosen? The challenge is to generate a kernel
that will, at the same time, minimize the execution time of the final multi-dimensional
schedule.
Three approaches are proposed and studied. First, the level-by-level approach
schedules the subkernel one by one starting from the innermost. Once a subkernel has
been scheduled, it cannot be undone. Second, the flat approach does not lock a subkernel
once fully scheduled. Operations from any loop level may be considered and undo pre-
vious decisions made in a different subkernel. A larger solution space can therefore be
explored. Finally, the hybrid approach schedules the innermost subkernel first and locks
it. The other operations are then scheduled using the flat method. It allows for a shorter
89
compilation time than the fast method while exploring a large solution space and focusing
resources on the innermost loop.
The proposed approaches and heuristics associated with them have been imple-
mented in the Open64/ORC compiler and analyzed on loop nests from the Livermore,
SPEC2000, and NAS benchmarks. Experimental results show that the hybrid approach
avoids the pitfalls of the two other approaches and produces schedules on average twice
faster than modulo-scheduling schedules. Because of its large search space, the flat ap-
proach may not reach a good solution fast enough and showed poor results.
The rest of the chapter is organized as follows. In the next section, the SSP kernel
generation problem for SSP, along with the associated issues, is explained. Section 5.3
presents the scheduling methods in detail. The last three sections are devoted toward
experimental results, related work, and conclusion, respectively.
5.2 Problem Description
5.2.1 Problem Statement
The kernel generation step consists of computing a one-dimensional schedule for
the loop nests. Using the 1-D DDG, each operation is assigned a schedule time. That
time is the schedule of the first instance of the operation in the final schedule. Given an
operation op, its 1-D schedule time, i.e. its final schedule time of its outermost iteration
0 instance, is noted σ(op, 0).
The schedule time of the operations must obey the constraints presented in Sec-
tion 3.5 and shown in Figure 5.1 where the UnusedCycles function is defined as fol-
lows. Let p1 and p2 be the stage index of operations op1 and op2, respectively. If
The simplest form of a vector lifetime is a filtered version of the vector lifetime
136
where the cycles from the ILES segments have been omitted. The form is not equiva-
lent to the special case where the number of iterations of any inner loop is equal to 11.
The simplest form truncates intervals whereas a number of iterations equal to 1 removes
definitions and uses, which might in turn reduce the length of interval to a smaller value
than the length of the truncated interval. The simplest form of the space-time diagram is
only composed of the Prolog, OLP, and Epilog. Such representation allows us to “omit”
the lifetime features specific to SSP presented earlier such as stretched intervals. Fig-
ure 7.5 shows the simplest form of the space-time diagram with the 3 vector lifetimes
represented.
The ideal form corresponds to the ideal case where all the scalar lifetimes are
issued evenly every T cycles. Each outermost iteration are executed without stalls as if
there was no resource constraint. There are therefore no stretched intervals. The ideal
form can be constructed by adding the intervals from the ILES to the simplest form. The
ideal form for our example is shown in Figure 7.6.
The final form corresponds to the final schedule without any omission or simplifi-
cation. It is the real space-time diagram of the schedule. The final form of our example is
shown in Figure 7.7.
Note that, despite the simplifications brought into the simplest and ideal form of
the space-time diagrams, repetition patterns are still present and will be exploited by the
register allocator.
7.3.3.2 Register Distances
In order to decide if two vector lifetimes we introduce the notion of register dis-
tance. If vector lifetime x is allocated register Ri and vector lifetime is allocated register
Ri+d, then the register distance between x and y, noted dist[x, y], is equal to d. It implies
1 Unlike in [RDG05] where adjustment for the lifetimes representation is required. Thereader is referred to the definition of singleEnd later on for more information
Figure 7.12 shows an example. Loop variant x is defined in the outermost loop of
a triple loop nest and used in the middle loop. The length of the corresponding interval
is a factor of N2 and N3, which might not be known at compile-time. By inserting a
copy instruction x=x in the innermost loop, we partition the long interval into smaller
intervals of known length. Those intervals overlap and cover the entire length of the
original interval. The known length and repeating nature of the intervals will be later
exploiter when representing the lifetimes.
The lifetime normalization algorithm is shown in Figure 7.13. The routine returns
the set of all the references to the loop variant v including the dummy copy operation when
142
NORMALIZATION(loop variant v):refs set← {}
// Variant References Collectionfor each operation op dotime← 1-D schedule time of oplevel← loop level of opfor each source operand opnd of op such that opnd = v doomega← live-in distance of opndref ← (time,USE, omega, level)refs set← refs set ∪ {ref}
end forfor each result operand opnd of op such that opnd = v doref ← (time,DEF, 0, level)refs set← refs set ∪ {ref}
end forend for
// Dummy copy operation insertion in the innermost loopif v is live in Ln but not defined in it thenref1 ← (fn ∗ T,USE, 0, n)ref2 ← (fn ∗ T,DEF, 0, n)refs set← refs set ∪ {ref1, ref2}
end ifreturn refs set
Figure 7.13: Lifetime Normalization Algorithm
143
needed. A reference is a 4-tuple (time,type,omega,level) where is the 1-D schedule time
of the operation, type is either a definition or a use of v, omega is the live-in distance of
v for that specific operation and level is the loop level of the operation that refers to v.
7.4.3 Lifetimes Representation
Once the lifetimes have been normalized, they can be abstracted mathematically.
The representation uses two types of parameters: the core parameters (singleStart,
singleEnd, omega, alpha, start, end, nextStart) and the derived parameters
(firstStretch, lastStretch, top, bottom). The latter are deduced from the former. Their
definitions are given in the following subsections. The values of those parameters for our
Table 7.1: Register Allocation Parameters Values Example
To help computing the parameters a boolean value named
OutermostIntervalOnly is used. It is set to true when a loop variant is uniquely
defined in the outermost level only. The boolean is only used to compute the parameters
OutermostIntervalOnly =
true , if for any reference ref in refs settype(ref) =USE or level(ref) = 1
false , otherwise(7.1)
7.4.3.1 Core Parameters
singleStart and singleEnd define the first cycle and last cycle + 1 of the scalar
lifetime of the first outermost iteration in the simplest form, respectively. singleStart is
144
therefore equal to the cycle of the first definition of that loop variant in 1-D schedule and
singleEnd is the cycle+1 of the last reference in that same schedule, to which we add the
omega distance omega∗T 2. If the last reference is a definition before the first occurrence
of the ILES (not represented in the simplest form) and a use for that loop variant is present
in the ILES, then the loop variant is still live until the start cycle of that ILES. singleEnd
is then start cycle of the first ILES, namely ln ∗ T .
singleStart = min
{time(ref),
∀ref ∈ refs set such that type(ref) =DEF
}(7.2)
singleEnd = max
{time(ref) + 1 + omega(ref) ∗ T ,
∀ref ∈refs set ∪ {(adjustment,USE, 0, 1)}
}(7.3)
where,
adjustment =
−∞ , if OutermostIntervalOnly
ln ∗ T , otherwise
Omega and alpha are the maximum number of live-in and live-out values, respec-
tively, for the loop variant. Omega can be computed from the references whereas alpha
is assumed to have been computed by an earlier phase of the compiler.
omega = max{omega(r),∀ref ∈ refsset} (7.4)
Start[i] is the issue time of the definition of the variant at level i, which is equal
to its 1-D schedule time. End[i] is 1 + the latest issue time of all possible uses of the
definition. If the definition at level i has no use, end[i] is the 1-D schedule time of the
definition + 1. The variant is live for the duration of the definition. If there is no definition
of the variant at level i, then start[i] and end[i] are set to +∞ and −∞, respectively.
The arbitrary choice is compatible with the subsequent distance computation because we
would have end[i]− start[i] < 0.
2 In [RDG05], singleEnd needs to be adjusted because the simplest form was defineddifferently. Here the adjustment is directly included in the definition of singleEnd
145
The computation of start[i] is straightforward. However end[i] is harder to com-
pute. Let uses(d) be the set of uses of a definition d. An operation u is a use of a definition
d if the control-flow can reach u from d without encountering any redefinition of the loop
variant. Let loopbackOffset(d, u) be the offset due to the execution of a back loop edge.
It corresponds to the execution time of one iteration of the shallowest loop traversed by
the control-flow while flowing from d to u. If d is the definition of the loop variant at level
After being sorted, the vector lifetimes are inserted onto the surface of a space-time
cylinder of circumference equal to R, the number of physical rotating registers available
on the target architecture. It would be possible to insert lifetimes on a space-time cylinder
with an infinite circumference. However, because the number of physical registers is
154
limited, it is convenient to know as early as possible when there are not enough registers
available for a schedule. The algorithm is shown in Figure 7.19. Inserting a vector lifetime
on the space-time cylinder means assigning a physical register to that lifetime.
INSERTION():dist← cons or aggrstrategy ← best fit or first fit or end fitfor each vector lifetime v dolegal regs[v] = [0, R− 1]
end for
for each non-inserted vector lifetime v dorv ← choose register in legal regs[v] using strategy strategyassign register rv to vector lifetime vfor each other non-inserted vector lifetime u dolegal regs[u]← legal regs[u]− new illegal(u, v, R)
end forend for
where:
new illegal(u, v, r) = {i mod r such that i /∈ (rv − dist[u, v]) ∪ (rv + dist[v, u])}
Figure 7.19: Lifetime Insertion Algorithm
The algorithm does not backtrack and any assignment decision is final. For each
vector lifetime v, the set of legal registers that can be assigned to v without any risk of
overlapping with already placed lifetimes is stored in legal regs[v]. As more vector life-
times are placed on the space-time cylinder, the set of legal registers of the vector lifetimes
which have not been assigned any register yet is updated using new illegal(u, v, r).
new illegal(u, v, r) is the set of registers which cannot be assigned to u after
inserting v on a space-time cylinder of circumference of r. In other words, if u was
assigned any register in new illegal(u, v, r), then u and v would overlap. The set is
defined modulo r to take into consideration the cyclic nature of the cylinder. rv+dist[v, u]
155
represents the set of registers that can be allocated to u without any conflict with v if u is
to be inserted above v. Otherwise the set of legal registers is given by rv − dist[u, v].
The pseudo-code for the wait and signal instructions is shown in Figure 9.6. The
wait is active. It will continuously loop until the synchronization counter reaches the value
of the clock counter. The wait could be made more passive by using a sleep instruction
instead. However, the benefit would be limited. There is no other work to do for the
thread unit and the actual wait time is very limited as shown by the experimental results.
It may appear on the otherwise in the examples shown because the number of iterations
is extremely low (for clarity purposes). The signal instruction is non-blocking. On the
64-bit Cyclops architecture, a value can be directly incremented in memory in one atomic
operation.
The synchronization instructions are placed in positions that satisfy code emis-
sion constraints. As in Chapter 8, the multi-threaded final schedule is emitted using the
control-flow graph as a template. An example for a triple loop nest is shown in Figure 9.7.
202
Innermost LoopPattern
Prolog
Draining/FillingPattern
Epilog
previous iteration group
next iteration group
N
N
−1n
−1i
Figure 9.7: Multi-Threaded SSP Schedule Control-Flow Graph for a Triple Loop Nest
When the schedule is partitioned into loop patterns named prolog, DFP, ILP, and epilog).
A wait instruction is added before each pattern and a signal instruction after.
In order to minimize the execution time of the wait instruction, the synchronization
counter is placed in the scratch-pad memory of the thread unit being signaled. The value
can then be quickly read by the receiving thread unit without using the crossbar network.
Although the signal instruction travels over the crossbar network, the signal instruction
is non-blocking. Therefore, the sending thread unit does not pay the cost of accessing
the scratch-pad memory of the receiving thread unit. The clock counter, which cannot be
accessed by the other thread units, is placed in a dedicated register of the thread unit for
fast access.
9.4.3 Innermost Loop Tiling
To reduce the number of synchronization stalls on a thread unit, the execution of
the Nn − 1 instances of the innermost loop pattern is tiled into tiles of G iterations. If G
203
ThreadUnit
Scratch−PadMemory
ThreadUnit
Scratch−PadMemory
Crossbar
Network
C S C S
remote non−blocking signal
local wait
synchronization counterclock counter
Figure 9.8: Location of the Synchronization Counters
is not a multiple of Nn − 1, the last tile only contains the remaining instances. Instead of
issuing a wait and signal instruction at the entrance and exit, respectively, of each instance
of the pattern, the synchronizations are issued every G instances as shown in Figure 9.9.
The technique allows for the parameterization of the synchronization tiling.
Let w designates the average execution time of the wait instruction. We can now
give an estimate of the total execution time of the schedule using the definition of the
multi-threaded schedule function for the IBM 64-bit Cyclops architecture. The last term
of Equation 9.4 is now better expressed by:(⌊
i1Sn
⌋− 1
)∗ (ln ∗ T +G ∗ Sn ∗ T ) (9.9)
ln∗T is the number of cycles executed by a thread before sending the first signal. G∗Sn∗Tis the number of cycles between the first signal and the second signal sent to the next
thread unit. The ILP is Sn ∗ T cycles long and a signal is sent after G executions of the
ILP.
Unlike the theoretical multi-threaded schedule function in Equation 9.4, we also
take into account the synchronization stalls of the entire schedule. That cost is carried to
204
op4op2op3
op2op3
op4
op4op2op3
op2op3
op4
op4op2op3
op2op3
op4
op4op2op3
op2op3
op4
ILP instance
(a) Before Tiling
op4op2op3
op2op3
op4
op4op2op3
op2op3
op4
op4op2op3
op2op3
op4
op4op2op3
op2op3
op4
tiled ILP
(b) After Tiling
Figure 9.9: Synchronization Tiling Example (G=2)
the last iteration group where it adds up to:⌊N1
Sn
⌋∗ 2 ∗ w + (syncsPerGroup− 2) ∗ w (9.10)
The first term corresponds to the 2 wait instructions used for the synchronization delay.
The delay accumulates over the iteration groups executed earlier. The second term corre-
sponds to the remaining wait instructions within one outermost iteration group.
Then, the total execution time of the schedule for the IBM 64-bit Cyclops archi-
tecture can be approximated by:
ftotal(G) = constant+
(⌊N1
Sn
⌋− 1
)∗ Sn ∗ T ∗G+ syncsPerGroup ∗ w
= constant+
(⌊N1
Sn
⌋− 1
)∗ Sn ∗ T ∗G
+w ∗ (Nn − 1) ∗(
1 +
j=n−1∏
j=2
(Nj − 1)
)∗ 1
G
205
Using the first derivative of the function, the best loop tiling factor for which the total
execution time is minimized, Gbest, can be computed and is equal to:
Gbest =
√√√√√w ∗ (Nn − 1) ∗
(1 +
∏j=n−1j=2 (Nj − 1)
)
T ∗ Sn ∗(⌊
N1
Sn
⌋− 1) (9.11)
The best empiric value for G is studied in Section 9.5.
9.4.4 Synchronization Bootstrapping
The first iteration group, executed on the first thread unit, does not receive any
synchronization signal during its execution. Therefore, the flow of execution should fall
through the wait instructions of that iteration group. Such feature is achieved by setting
the synchronization counter to the number of synchronization signals that an iteration
group needs to receive to run to completion, defined as syncsPerGroup. That number is
equal to the number of instances of each pattern to which we add the extra wait instruction
used for the synchronization delay (extra = 1). In one iteration group, the prolog is
executed only once (P = 1). So is the epilog (E = 1). The number of times DFPi is
executed, noted Di with i ∈ [2, n− 1], is given by:
Di = (Ni − 1) ∗Di−1 with D1 = P =
j=i∏
j=2
(Nj − 1)
The number of times the tiled ILP is executed, noted I , can be expressed as:
I =Nn − 1
G∗ (Dn−1 + P ) =
Nn − 1
G∗(
1 +
j=n−1∏
j=2
(Nj − 1)
)
206
Then we have:
syncsPerGroup
= extra+ P + I + E +i=n−1∑
i=2
Di
= 3 +Nn − 1
G∗(
1 +
j=n−1∏
j=2
(Nj − 1)
)+
i=n−1∑
i=2
j=i∏
j=2
(Nj − 1)
= 3 +Nn − 1
G+Nn − 1
G∗j=n−1∏
j=2
(Nj − 1) +i=n−1∑
i=2
j=i∏
j=2
(Nj − 1) (9.12)
IfNn−1 is not a multiple ofG, (Nn−1)/Gmust be replaced by b(Nn−1)/Gc+1
to account for the extra wait instructions. If the loop nest is a double loop nest, then the
last two terms of Equation 9.12 are equal to zero.
The synchronizations signals sent by the thread unit that executes the last outer-
most iteration group are received by the next thread unit, even if that thread unit is not
required to execute any other outermost iteration. Afterward the completion signal is sent
to the first thread unit.
9.4.5 Cross-Iteration Register Dependences
When distributing iteration groups over the thread units, an issue arises with the
cross-iteration register dependences. Those dependences are dependences between out-
ermost iterations involving values in registers and not spilled in memory. It is typical
an outermost loop counter for instance. On a uniprocessor, the problem does not exist
as there is a single register file. However, in the IBM 64-bit Cyclops architecture, each
thread unit has its own private register file which cannot be accessed by any other thread
unit. Values involved in a cross-iteration register dependence need to be copied from one
thread unit to the next.
A solution is to transform the register dependence into a memory dependence.
We issue memory spill instructions to copy the value from the register to a buffer in the
scratch-pad memory of the destination thread unit. The value is then restored using a
207
single memory load. The scratch-pad memory of the receiving thread unit was chosen
because memory spills are non-blocking and memory restores from the local scratch-pad
memory does not involve the crossbar network and can be executed in a matter of few
cycles. As the cross-iteration register dependences are known at compile-time, the buffer
and offset to its respective values are statically allocated.
TU i+1TU i
scratch−pad memory
...=R
restore
spill
R=R+1
...=R
restore
spill
R=R+1
R=R+1...=R
...=RR=R+1
buffer
localaccess
remoteaccess
cross−iteratonregister dependence
memory dependencecross−iteration
unnecessary memory
not emittedspills and restores are
register value accessedin next outermost iteration
known offset
Figure 9.10: Cross-Iteration Register Dependence Example
Memory spill instructions only need to be issued by the last outermost iteration
208
of an iteration group and memory restore instructions by the first. Within an instruction
group, the value is transferred from one outermost iteration to the next using registers as
usual. If the value is to be used by another outermost iteration than the next (meaning
that the distance of the cross-iteration register dependence is greater than 1), register
copies and memory spills/restores will bring that value to the recipient outermost iteration
naturally in a cascade fashion.
The mechanism is implemented by adding memory spill and restore instructions
at the ends of each cross-iteration dependence during the loop selection phase in the SSP
framework. The kernel generator then produces an SSP kernel which contains those extra
operations. While emitting the assembly code, the memory spill operations are removed
from every iteration but the last of an iteration group, and the memory restore operations
are removed from every iteration but the first of an iteration group. The removal of those
operations is accompanied by some register renaming to take the change into account.
Figure 9.10 shows an example of a cross-iteration register dependence. Register
R is used and then incremented by one in the first outermost iteration. The next outer-
most iteration uses the incremented value and increments again the value in the register.
Because the two outermost iterations are executed on the same thread unit, the register
is accessible to both iterations. However, the third iteration cannot access that register.
Instead, the value is spilled into a known location by the second iteration. The third iter-
ation retrieves the value from the buffer before using it. The spill and restore instructions
only appear in the first and last outermost iterations of an iteration group.
9.4.6 Code Generation Algorithms
The pseudo-code skeleton of the multi-threaded final schedule is shown in Fig-
ure 9.11. The details of the loop patterns are shown in Figure 9.12. The code is common
to all thread units and loaded to each thread unit. Then the first thread unit will initiate
the execution of the entire schedule when sending its first synchronization to the next
thread unit. The main loop iterates over the iteration groups that each thread unit must
209
[Initialization]
// Iterate over the iteration groupsi1 ← my thread idwhile i1 < N1 do
Emit Stages(f1, l1, Sn −max(i− l1, 0), 1, 0, i− Sn + 1, l1 − ln + 1)rotate registers()
end forsignal()
Figure 9.12: Loop Patterns Expansion
Compared to the uniprocessor code for the Intel Itanium architecture presented in
Chapter 8, there is no outermost loop pattern anymore and the innermost loop pattern is
now tiled. Register rotation is still required in the prolog and epilog. The register rotation
emulation technique used for the other patterns is similar to the Itanium version and will
211
not be described here. The patterns are now surrounded by synchronization instructions: a
wait instruction before each pattern and a signal after. The synchronization instructions
for the innermost loop pattern are moved into the outer tiled loop.
EMIT STAGES(first stage, last stage, stage count, level, register offset,stage offset, total height)
for cycle = first cycle[level], f irst cycle[level] + T [level]− 1 dostage counter ← stage count
reg offset← register offsetstage← first stage+ stage offsetwhile stage ≤ last stage and stage counter > 0 do
if (operation is memory spill and stage counter 6= stage count)or (operation is memory restore and stage counter 6= 1) then
do not emit this operationend ifemit ops(level, stage, cycle, reg offset)stage counter ← stage counter − 1stage← stage+ 1
end while
reg offset← register offset+ total heightstage← first stagewhile stage counter > 0 do
if (operation is memory spill and stage counter 6= stage count)or (operation is memory restore and stage counter 6= 1) then
do not emit this operationend ifemit ops(level, stage, cycle, reg offset)stage counter ← stage counter − 1stage← stage+ 1
end whileend for
Figure 9.13: Stage Emission Algorithm
The stage emission routine, Emit Stages(), shown in Figure 9.13, also differs
from the Itanium version to take into account the features of the multi-threaded schedule
and the absence of predicate registers in the IBM 64-bit Cyclops architecture. The register
212
offsetting is now done manually to the function. For that purpose, the register offset is
passed as a parameter along total height, the number of instances of the kernel in the
pattern being emitted. Given the level level of the stages, the operations are emitted in
the order of their scheduling cycle. stage count stages are emitted starting from stage
first stage+ stage offset to stage last stage. If the number of emitted does not reach
stage count, then the emission continues starting from stage first stage. This cyclic
emission is required for the DFP and ILP patterns. Only the required memory spill/restore
operations are emitted. The others are discarded as explained in Section 9.4.5.
An operation is emitted using the emit ops() routine. Before emitting an oper-
ation in assembly code, some modification may occur. If the operations is a memory
spill/restore operation, then the address register must be switched to the register contain-
ing the address of the buffer in the next thread unit. That information is only known at
code-emission time and a dummy register had been used so far. Then, the register indexes
must adjusted according to the reg offset value.
[Initialization] =compute address of local buffercompute address of buffer in next thread unitcompute address of synchronization counter in next thread unitclock counter ← 1synchronization counter ← 0if current thread unit is first thread unit then
synchronization counter ← syncsPerGroupcopy live-in values in local buffer
end if
Figure 9.14: Initialization Code
The initialization code is shown in Figure 9.14. Each thread unit must compute
the address of the buffer and synchronization counter in the next thread unit. It differs
from one thread unit to the next. The synchronization counter is then initialized to 0 as
no synchronization signal has been received yet. The clock counter is set to 1 for all the
thread units but the first so that the thread units do not start until told so by the previous
213
thread unit. The clock counter of the first thread unit is initialized with the number of
synchronizations per iteration group to be able to execute the first iteration group without
requiring any synchronization signal. The live-in values are copied in the local buffer of
the first thread unit to bootstrap the execution.
[Conclusion] =if current thread unit executes last iteration group then
signal the first thread unitend ifif current thread unit is first thread unit then
wait()else
sleep()end if
Figure 9.15: Conclusion Code
The conclusion code is shown in Figure 9.15. The thread unit to execute the last
iteration group signals the first thread unit that the schedule is completed. All the thread
units, but the first, then go to sleep (or terminate). The first thread units waits for the
completion signal to arrive and returns.
In order to reduce the execution time of the schedule, the loop control instructions,
such as iteration index increment and trip count comparison, have been added to the
operations of the loop nest and therefore scheduled in the kernel. As such, the register
offset has been applied to the loop counter registers. The only instruction that has not been
scheduled in the kernel is the branch instruction. Therefore, the register offset must also
be applied to the branch instruction. The loop control register used should correspond to
the one last defined in the last outermost iteration in an iteration group.
9.4.7 Correctness
We present here two theorems that goes towards proving that the IBM 64-bit Cy-
clops multi-threaded schedule is correct.
214
Theorem 9.3 The synchronization signal guarantees that the memory accesses preceding
it have been committed.
Proof. The accesses to the crossbar network are managed in first-in first-out order at
the sending network port. A memory access will not travel across the network until the
receiving side can handle the memory access atomically. Therefore the memory accesses
issued over the network are guaranteed to be executed in sequential order from the point
of the view of the sending thread unit. In consequence, this property also guarantees that
when a signal instruction is issued, the preceding memory accesses have already been
committed. �
Theorem 9.4 The IBM 64-bit Cyclops multi-threaded final schedule is deadlock-free.
Proof. The signal instruction is non-blocking. We already proved in Theorem 9.1 that,
giving that condition, the multi-threaded final schedule was deadlock-free. The IBM 64-
bit Cyclops implementation adds the round-robin execution of the iteration groups and the
use of buffers. Buffer accesses are normal memory operations and do not change anything
to the correctness of the schedule. And the recurrence proof used in Theorem 9.1 can still
be applied despite the round-robin execution. �
9.5 Experimental Results
The multi-threaded SSP method was implemented in the Open64 compiler retar-
geted for the IBM 64-bit Cyclops architecture. The earlier steps up to the register alloca-
tion were also added unmodified to the compiler. Fourteen loop nests from the Livermore
Suite, SPEC2000 and NAS were compiled and evaluated using the simulator used by the
development team of the IBM 64-bit Cyclops architecture. Loop tiling factor of 1, 2, 4, 8,
16, 32, 64, and 128 were tested on the processor with 99 thread units. The execution time
absolute speedup was measured with 1, 3, 7, 15, 31, 63, and 99 thread units with the best
loop tiling factor measured. The issue width of a thread unit was assumed to be equal to
215
2 and the register file was assumed to be rotating. The problem size of each benchmark
was chosen as large as possible under the constraint that the simulator could compute the
output in 60 minutes for a total simulation time of 196 hours.
9.5.1 Execution Time Speedup
The scalability results for a representative set of benchmarks are shown in Fig-
ure 9.16. The best loop tiling factor for each benchmark was chosen. As the number of
thread units increases, the total execution time of the benchmarks dramatically reduces.
The ikj variant of matrix-multiply shows the best result with an absolute speedup of 81
for 100 thread units. The worst speedup, 42 for 100 thread units, was encountered when
evaluating benchmark livermore18.3.
0
20
40
60
80
100
100 64 32 16 8 4 2
Exe
cutio
n T
ime
Abs
olut
e Sp
eedu
p
Number of Thread Units
linear
speed
upmm-ikjsorg3hydroblaslivermore 18.3
Figure 9.16: Execution Time Absolute Speedup
Ideally, the execution time absolute speedup is linear. The difference is explained
by two facts. First, cross-iteration dependences prevent the outermost iteration group from
being executed in parallel and achieving a linear speedup. The second explanation is the
fixed cost of initializing the schedule. With 100 thread units, the cascaded initialization
of all the thread units is costly: thread unit i will not start before receiving two signals
from thread unit i − 1. Given a fixed number of outermost iterations, the more thread
units are used, the higher the initialization cost becomes. If the number of outermost
216
iterations is too small, the initialization becomes the dominant factor in the total execution
time. This explains why the difference between speedup curves and the linear speedup
curve increases as the number of thread units increases. When the number of outermost
iterations increases, so does the execution time speedup. For instance, when the number
of outermost iterations of the worst performing benchmark, livermore18.3, is multiplied
by a factor of only 4, the speedup for 99 thread units jumps from 42 to 67 1.
9.5.2 Loop Tiling Factor
The best loop tiling factor was searched for each of the benchmarks running on
the IBM 64-bit Cyclops processor with 99 thread units. A representative set of results are
shown in Figure 9.17. Overall, the benchmarks can be partitioned into 2 groups. In the
first group, loop tiling helps reducing the execution time of the benchmarks. For instance,
the ijk variant of matrix-multiply shows a speedup of 1.29 with a tile factor of 32 or
64. The second group, which includes blas, hydro and livermore18.3 in the graph, only
shows deteriorating speedup as the tiling factor increases.
0
0.2
0.4
0.6
0.8
1
1.2
1.4
1.6
128 64 32 16 8 4 2
Exe
cutio
n T
ime
Spee
dup
Loop Tiling Factor (G)
mm-ijkmm-kijg3blashydrolivermore 23
Figure 9.17: Loop Tiling Factor
1 Although increasing the problem size for all the benchmarks would improve thespeedup results, it was not attempted because of the time required to run the bench-marks on the IBM 64-bit Cyclops simulator.
217
The experimental results are in line with theoretical best value for G computed
in Equation 9.11. The best value for G for the benchmarks in the second group happens
to be 1 because the number of iterations of the inner loops is not large enough. Using
the measured average execution time of the wait instruction (14 cycles), the difference in
total execution time using the empirical best value for G and the theoretical best G value
(Gbest) was measured. The maximum recorded difference was 1.7% with an average of
0.3%. Gbest is therefore a very accurate approximation of the best value to be chosen for
G.
9.5.3 Synchronization Stalls
The stall cycles were measured for all the benchmarks and using 100 thread units
with the best loop tiling factor. The average execution time of the wait is 14 cycles
(synchronization delays excluded). It is exactly the time it takes to execute the instruction
when the data are already in the buffer. Therefore, the wait instruction never blocks.
The value could be further reduced by implementing the wait instruction as an atomic
instruction in the instruction set architecture.
However, such a dedicated instruction would have almost no impact on the total
execution time of the schedules. On average, the number of cycles to execute the wait
instructions represents only 0.2% of the total execution time with a maximum of 0.7%.
The cost of the wait instruction is therefore negligible.
9.5.4 Register Pressure
Finally, the register pressure was measured for each of the benchmark. The
average register pressure was measured at 55.1 registers with a maximum of 96 for
livermore8. That pressure is reasonable and much lower than for the Intel Itanium ar-
chitecture, considering that IBM 64-bit Cyclops registers are used both for floating-point
and integer values. Such difference is explained by the reduced issue width of the IBM
64-bit Cyclops processor. A limited issue width increases the initiation interval of the
218
0
16
32
48
64
80
96
112
128
Ave
rage
liver
mor
e23
liver
mor
e18.
3
liver
mor
e18.
2
liver
mor
e18.
1
liver
mor
e8
hydr
o
sor
blasg3
mm
-kji
mm
-kij
mm
-jki
mm
-jik
mm
-ikj
mm
-ijk
Reg
iste
r Pre
ssur
e
Figure 9.18: Register Pressure
kernel and therefore reduces the number of stages of the kernel. As a result, the number
of interfering lifetimes is also reduced.
The register pressure can be further reduced by tuning the register allocator to the
multi-threaded schedule. Indeed, the stretched intervals mentioned in Chapter 7 are now
non-existent and do not need to be accounted for anymore.
9.6 Related Work
There exists a very large number of related work that may be applied to schedule
loops on multi-threaded or multi-core architectures. However, they can only be applied to
single loops. MT-SSP is the first method to software-pipeline a loop nest on cellular archi-
tectures. The method produces a compact multi-threaded final schedule with minimized
synchronization costs. Some of the related work is presented here.
Several software-pipelining techniques [NE98, FLT99, SG00a, SG00b] were pro-
posed for clustered-VLIW architectures (Chapter 2). The IBM 64-bit Cyclops architec-
ture is fundamentally different as the thread units are independent from each other and
interconnected via a network instead of a bus. Extra synchronization is required for the
cellular architecture, which can easily step up the number of thread units to the hundreds
whereas clustered architectures are limited to tens of independent compute engines.
219
Decoupled Software-Pipelining [ORSA05] schedules a single loop over multiple
thread units. Instead of distributing the iterations over the thread units, the same thread
unit always executes the same group of operations. Thus, if an iteration can be partitioned
into groups, the first thread unit executes the first group of every iteration, the second
thread unit the second group and so on. However, if the number of thread units reaches
the hundreds, the thread units cannot be kept busy.
Other multi-threading techniques include speculative multi-threading with run-
time analysis, also called run-time parallelization of DOACROSS loops [Che94, TY96,
THA+99]. Threads are speculatively issued and killed as information about the execu-
tion of loops is known. Although those methods allow for a wider range of loops to be
scheduled, especially with pointer-chasing structures, the thread control overheads are
very high compared to MT-SSP.
Some work [dCZG06] was also done to efficiently port OpenMP to the IBM 64-bit
Cyclops architecture. However, OpenMP is high-level language requiring extra interven-
tion from the programmer and suffering from generic constructs overheads. MT-SSP is
directly applied at the instruction level and exclusively target loop nests.
9.7 Conclusion
In this chapter we presented a solution to software pipeline loop nests on multi-
threaded cellular architectures based on SSP. The method is named Multi-Threaded
Single-dimension Software-Pipelining (MT-SSP). Given the SSP kernel, a fully synchro-
nized multi-threaded final schedule is generated to efficiently execute the loop nest with-
out any modification to the source code. The schedule is proven deadlock-free and respect
all the dependence and resource constraints.
Code generation algorithms were presented for the IBM 64-bit Cyclops architec-
ture. Synchronization is done through the use of a Lamport’s clock on each thread unit.
The signal instruction is non-blocking to allow for faster execution. The synchroniza-
tion counter is placed in the local scratch-pad memory of the receiving thread unit to
220
limit network accesses and drastically reduce the execution time of the wait instruction.
Cross-iteration register dependences between thread units were handled through the use
of memory spill and restore operations to and from a buffer also in the scratch-pad mem-
ory of the receiving thread unit. Those operations are scheduled in the kernel.
Experimental results showed that multi-threaded SSP schedules scales up well
when the number of thread units increases. The implementation uses a very light-weight
synchronization method with only standard instructions of the IBM 64-bit Cyclops archi-
tecture. The loop tiling factor was shown to be correctly approximated using the definition
of Gbest. Finally, the register pressure appeared to be reasonable without taking any extra
steps to reduce it.
221
Chapter 10
CONCLUSION
10.1 Summary
This dissertation has introduced SSP, Single-dimension Software-Pipelining, as a
valid approach to schedule loop nests on both uniprocessors and cellular architectures. In
the search for more computational power, computer architects have reached a technology
wall. Increasing clock speed, on-chip cache, pipeline depth and the number of functional
units on uniprocessors does not suffice anymore. When power consumption and cooling
systems are added to the financial equation, the return on investments has clearly passed
the point of diminishing return.
This fact leads to a new generation of processor architectures based on a large
number of parallel threads running on simple but power-efficient thread units: cellular
architectures. The thread units are interconnected via a network and share memory dis-
tributed in banks also connected to the network. By distributing the computation power
over the entire chip and by reducing the hardware complexity, the power consumption
and cooling issues disappeared. Also, because a defect thread unit or memory bank does
not prevent the chip from running properly, defect chips can still be used. The production
of a cellular processor then shows a high yield and results in lower manufacturing costs,
alleviating the price barrier to enter the processor market.
However, the programmability issue still remained to be solved. How to program
applications that will rip the benefits of so much parallelism? How to synchronize the
threads executing on all the thread units? How to communicate data from one thread to
222
another in a timely fashion? This dissertation presented SSP, a method aimed at provid-
ing a solution to all those questions for loop nests, a program structure present in many
applications and which can represent up to 90% of the execution time in the scientific
domain.
SSP is a whole compilation framework which takes loop nests as an input at the
programming language level and produces the schedule in assembly code to execute the
loop nest on either a VLIW architecture or a cellular architecture. The different steps of
the methods were first implemented for a VLIW architecture with convenient loop dedi-
cated hardware support such as register rotation, predication and dedicated loop counters,
before being ported to cellular architectures. The entire framework for both VLIW and
cellular architectures are presented in this dissertation.
We first presented the theoretical framework behind SSP. Given a loop nest and
its multi-dimensional data dependence graph, the most profitable loop level is selected.
Profitability is based on criteria set by the user and is heuristic-based. The user might want
to reduce execution time, limit network traffic or reduce power consumption. Once a level
has been selected, the multi-dimensional dependence graph is simplified into a single-
dimension data dependence graph which will be used to generate the schedule for the loop
nest. The schedule functions for both perfect and imperfect loop nests are introduced,
along with their properties and correctness proofs. SSP is proved to subsume modulo
scheduling (MS) as a special case when the loop nest is a single loop. Experimental results
show that SSP schedules are faster than MS schedules for a large set of benchmarks, even
after loop nest transformations and optimizations such as loop tiling are used.
The different steps to generate the final schedule are then introduced. First, some
loop selection heuristics are presented. Then the design principles of three scheduling
methods are presented. All methods produce a kernel which is used to build the final
schedule of the loop nest. The first method schedules operations one loop level at a time
223
starting from the innermost. The second method schedules all the operations simulta-
neously, expanding the search space and therefore increasing the possibility of finding a
better solution. Finally, the last method is an hybrid approach between the first two in
order to overcome the disadvantages of both other methods. Experiments showed that
the second approach is too slow while the first and third methods find reasonably good
solutions.
When the kernel is computed, a fast and accurate scheme was presented to evaluate
the register pressure in the final schedule of the loop nest before even allocating register
to the loop variants of the loop nest. The evaluation is used to decide to continue with
computed kernel. If the register pressure is deemed too high and the architecture does not
provide enough registers to accommodate the schedule needs, then another loop level is
chosen or another kernel with a lower register pressure is computed. Experimental results
showed that the integer register pressure increases with the depth of the loop nest whereas
the floating-point register pressure tends to remain constant. With 128 integer registers
and 64 floating-point registers, most of the loop nests can be scheduled with SSP.
Then, we presented a normalized representation of the complex lifetimes of an
SSP schedule. The design allows for a fine-grain representation of the holes with those
lifetimes to allow for their interleaving on the register space-time cylinder. A method
is proposed to exploit the representation and compute a register allocation solution that
minimizes register usage. Results prove the importance of minimizing register usage and
show that the computed solutions are close to optimality.
A code generation scheme was also presented for the Intel Itanium VLIW archi-
tecture. The solution takes advantage of the available hardware support. To limit code
size expansion, register rotation, predication and dedicated loop counters were used. To
cope with the lack of multiple rotating register files, modulo-variable expansion with code
duplication was used. Experimental results showed that, despite the code size increase,
the memory footprint of the final schedule still fits in the L1 instruction cache.
224
Finally, we presented a code generation scheme for the IBM 64-bit Cyclops cellu-
lar architecture. The SSP schedule was modified into an Multi-Threaded SSP (MT-SSP)
schedule to accommodate the presence of the many thread units and the synchroniza-
tion needs. The provided solutions generate a multi-threaded synchronized schedule for
the loop nests that fully utilizes the computational power of the machine. Experimental
results showed that the performance increases linearly with the number of thread units.
10.2 Future Work
While this dissertation proved that SSP is a viable loop nest scheduling solution
for both VLIW and cellular architectures, there are many directions for future research.
The first direction is to increase the set of loop nests to which SSP can be applied
to. Currently, a loop level cannot be selected if it contains a negative dependence. How-
ever, it is entirely possible to transform the loop nest via loop skewing or loop retiming
to make the negative dependence disappear. It would transform the rectangular iteration
space into a parallelogram iteration space which would require some loop peeling. Also,
loop nests could include loop siblings, i.e. two or more consecutive loops at the same
loop level. Several kernels would have to be created and adjusted to match. The register
allocator would have to be modified to take into account the multiple kernels. Finally,
conditional statements should be accepted by SSP. The Itanium architecture offers a way
to convey the value of predicate register used as a guarding predicate of a predicated
instruction. Thus conditional statements could be if-converted and loop nests software-
pipelined. If the hardware does not support predication, reverse if-conversion could also
be used [WBHS92, WMHR93].
Second, the register pressure remains an issue, especially if more complex loop
nests with loop siblings and conditional statements are to be considered. Since the reg-
ister allocator already generates almost optimal solutions, the attention should be set to
the other steps of the SSP framework. One can imagine a set of loop nest transformations
before SSP that would reduce the register pressure of a given level. The loop selection
225
step could also avoid levels that are guaranteed to have a register pressure that is too high.
The register pressure evaluation mechanism could be modified to become incremental
and merged to the scheduler to generate register pressure oriented kernels. Also, inserting
register spill and restore instructions to the schedule to limit the number of stretched life-
times would strongly reduce the register pressure of SSP schedules. Finally, in MT-SSP,
the register allocator could be adapted to take into account the lifetimes features of the
multi-threaded final schedules. Currently, the register allocator conservatively assumes
an uniprocessor final schedule.
Third, some cross-iteration register dependences could be eliminated from the
ideal schedule in order to decrease the amount of memory accesses on a multi-threaded
cellular chip. Very often, those dependences concern the loop indexes whose values are
predictable. Their elimination would lead to a more compact kernel and buffer-free multi-
threaded schedule.
From a hardware point of view, the use of multiple rotating register files would
have to be considered to reduce the code size of the schedule in assembly code. The use
of multiple loop counters and shared registers between thread units could go a long way
to reduce synchronization costs, limit network traffic and reduce the memory footprint of
the schedule.
Finally, the user could have more influence on the schedule generated by SSP.
Currently, the number of outermost iterations executed in parallel is determined by the
number of stages of the innermost kernel (Sn). However, one can imagine that the user
could force the schedule to use fixed Sn value or a fixed initiation interval. Both have
a direct influence on the schedule itself and on the register pressure. The number of
available thread units could help determine the most profitable value for Sn. The impact
of fixed values would have to be investigated.
226
BIBLIOGRAPHY
[AAC+03] George Almasi, Eduard Ayguade, Calin Cascaval, Jose G. Castanos, Je-sus Labarta, Francisco Martınez, Xavier Martorell, and Jose E. Moreira.Evaluation of OpenMP for the Cyclops multithreaded architecture. InWorkshop on OpenMP Applications and Tools (WOMPAT) 2003, volume2716/2003, pages 69–83. Lecture Notes in Computer Science, January2003.
[ACC+90] Robert Alverson, David Callahan, Daniel Cummings, Brian Koblenz,Allan Portereld, and Burton Smith. The Tera computer system. In Pro-ceedings of the 1990 International Conference on Supercomputing, vol-ume 18(3), pages 1–6, Amsterdam, June 1990. ACM. Computer Archi-tecture News.
[ACC+03] George Almasi, Calin Cascaval, Jose G. Castanos, Monty Denneau,Derek Lieber, Jose E. Moreira, and Henry S. Warren, Jr. DissectingCyclops: a detailed analysis of a multithreaded architecture. ACMSIGARCH Computer Architecture News, 31(1):26–38, 2003.
[AG86] Erik Altman and Guang R. Gao. Optimal modulo-schedulingthrough enumeration. International Journal of Parallel Programming,26(3):313–344, 1986.
[AGG95] Erik R. Altman, R. Govindarajan, and Guang R. Gao. Scheduling andmapping: Software pipelining in the presence of structural hazards. InProceedings of the ACM SIGPLAN ’95 Conference on ProgrammingLanguage Design and Implementation, pages 139–150, La Jolla, Cali-fornia, June 18–21, 1995. SIGPLAN Notices, 30(6), June 1995.
[AJLA95] Vicki H. Allan, Reese B. Jones, Randall M. Lee, and Stephen J. Allan.Software pipelining. ACM Computing Surveys, 27(3):367–432, Septem-ber 1995.
[AK84] John R. Allen and Ken Kennedy. Automatic loop interchange. In Pro-ceedings of the SIGPLAN ’84 Symposium on Compiler Construction,pages 233–246, Montreal, Quebec, June 17–22, 1984. ACM SIGPLAN.SIGPLAN Notices, 19(6), June 1984.
227
[AKPW83] J. R. Allen, Ken Kennedy, Carrie Porterfield, and Joe Warren. Conver-sion of control dependence to data dependence. In Conference Recordof the Tenth Annual ACM Symposium on Principles of ProgrammingLanguages, pages 177–189, Austin, Texas, January 24–26, 1983. ACMSIGACT and SIGPLAN.
[AN88a] A. Aiken and A. Nicolau. Optimal loop parallelization. In Proceed-ings of the ACM SIGPLAN 1988 conference on Programming Languagedesign and Implementation, pages 308–317. ACM Press, 1988.
[AN88b] A. Aiken and A. Nicolau. Perfect pipelining: A new loop paralleliza-tion technique. In Proceedings of the 1988 European Symposium onProgramming, pages 308–317. Springer-Verlag, 1988.
[AN91] A. Aiken and A. Nicolau. A realistic resource-constrained software-pipelining algorithm. Advances in languages and compilers for parallelprocessing, 1991.
[ASR95] V. H. Allan, U. R. Shah, and K. M. Reddy. Petri net versus moduloscheduling for software pipelining. In Proceedings of the 28th AnnualInternational Symposium on Microarchitecture, pages 105–110, Ann Ar-bor, Michigan, November 29–December 1 1995. IEEE-CS TC-MICROand ACM SIGMICRO.
[AU77] A. V. Aho and J. D. Ullman. Principles of Compiler Design. Addison-Wesley Publishing Company, 1977.
[BG97] Doug Burger and James R. Goodman. Guest editors introduction:Billion-transistor architectures. Computer, 30(9):46–49, September1997. CPTRB4.
[BG04] Doug Burger and James R. Goodman. Billion-transistor architectures:There and back again. Computer, 37(3):22–28, March 2004.
[CCC+02] Calin Cascaval, Jose G. Castanos, Luis Ceze, Monty Denneau, ManishGupta, Derek Lieber, Jose E. Moreira, Karin Strauss, and Henry S. War-ren Jr. Evaluation of a multithreaded architecture for cellular computing.In Eighth International Symposium on High-Performance Computer Ar-chitecture (HPCA), page 311, February 2002.
[CCJ05] Patrick Carribault, Albert Cohen, and William Jalby. Deep Jam: Con-version of coarse-grain parallelism to instruction-level and vector paral-lelism for irregular applications. In Proceedings of the 2005 Conferenceon Parallel Architectures and Compilation Techniques (PACT’05), St-Louis, Missouri, USA, September 2005.
228
[CCK88] D. Callahan, J. Cocke, and K. Kennedy. Estimating interlock and im-proving balance for pipelined machines. Journal of Parallel and Dis-tributed Computing 5, pages 334–358, 1988.
[CDS96] S. Carr, C. Ding, and P. Sweany. Improving software-pipelining withunroll-and-jam. In Proc. 29th Annual Hawaii International Conferenceon System Sciences, pages 183–192, 1996.
[Cha81] Alan E. Charlesworth. An approach to scientific array processing:The architectural design of the AP-120B/FPS-164 family. Computer,14(9):18–27, September 1981.
[Cha82] G. J. Chaitin. Register allocation & spilling via graph coloring. In Pro-ceedings of the conference on Compiler Construction, pages 98–101.ACM Press, 1982.
[Che94] D.-K. Chen. Compiler Optimizations for Parallel Loops with Fine-grained Synchronization. Ph.D. dissertation, Department of ComputerScience, University of Illinois, Urbana, Illinois, 1994.
[CK91] David Callahan and Brian Koblenz. Register allocation via hierarchicalgraph coloring. In Proceedings of the ACM SIGPLAN 1991 conferenceon Programming language design and implementation (PLDI), pages192–203. ACM Press, 1991.
[CK94] S. Carr and K. Kennedy. Improving the ratio of memory operations offloating-point operations in loops. ACM Transactions on ProgrammingLanguages and Systems 16, 6:1768–1810, 1994.
[CLG02] J. Codina, J. Llosa, and A. Gonzalez. A comparative study of modulo-scheduling techniques. In Proc. of the 2002 International Conference onSupercomputing, June 2002.
[CNO+88] Robert P. Colwell, Robert P. Nix, John J. O’Donnell, David B. Papworth,and Paul K. Rodman. A VLIW architecture for a trace scheduling com-piler. IEEE Transactions on Computers, 37(8), August 1988.
[CR00] B. Calder and G. Reinman. A comparative survey of load speculationarchitectures. Journal of Instruction-Level Parallelism, volume 1, 2000.
[CWT+01] Jamison D. Collins, Hong Wang, Dean M. Tullsen, Christopher Hughes,Yong-Fong Lee, Dan Lavery, and John P. Shen. Speculative precom-putation: Long-range prefetching of delinquent loads. In Proceedingsof the 28th Annual International Symposium on Computer Architecture,
229
volume 29(2), pages 14–25, Goteborg, Sweden, June-July 2001. IEEEComputer Society and ACM SIGARCH. Computer Architecture News.
[dCZG06] Juan del Cuvillo, Weirong Zhu, and Guang R. Gao. Landing OpenMP onCyclops64: An efficient mapping of Open64 to a many-core system-on-a-chip. In Proceedings of the ACM International Conference on Com-puting Frontiers 2006, May 2006.
[dCZHG05] Juan del Cuvillo, Weirong Zhu, Ziang Hu, and Guang R. Gao. FAST:a functionally accurate simulation toolset for the Cyclops64 cellular ar-chitecture. In Proceedings of the Workshop on Modeling, Benchmarkingand Simulation, pages 11–20, June 2005.
[DG05] Alban Douillet and Guang R. Gao. Register pressure in software-pipelined nests: fast computation and impact on architecture design. InLCPC ’05: Proceedings of the 18th International Workshop on Lan-guages and Compilers for Parallel Computing, Hawthorne, NY, USA,October 2005. Lecture Notes in Computer Science.
[DH79] J. J. Dongarra and A. R. Hinds. Unrolling loops in FORTRAN. Software— Practice and Experience, 9(3):219–226, March 1979.
[DHB89] James C. Dehnert, Peter Y.-T. Hsu, and Joseph P. Bratt. Overlappedloop support in the Cydra 5. In Proceedings of the Third InternationalConference on Architectural Support for Programming Languages andOperating Systems, pages 26–38, April 3–6, 1989.
[DRG98] A. Dani, V. Ramanan, and R. Govindarajan. Register-sensitive softwarepipelining. In Proc. of the Merged 12th International Parallel Process-ing Symposium and 9th International Symposium on Parallel and Dis-tributed Systems, 1998.
[DRG06] Alban Douillet, Hongbo Rong, and Guang R. Gao. Multidimensionalkernel generation for loop nest software pipelining. In Proceedings of the2006 Europar, Dresden, Germany, August 29th–September 1st, 2006.Lecture Notes in Computer Science.
[DSRV99] A. Darte, R. Schreiber, B. R. Rau, and F. Vivien. A constructive solutionto the juggling problem of systolic array synthesis. Technical ReportRR1999-15, LIP, ENS-Lyon, January 1999.
[DSRV02] Alain Darte, Robert Schreiber, B. Ramakrishna Rau, and FredericVivien. Constructing and exploiting linear schedules with prescribedparallelism. ACM Trans. Des. Autom. Electron. Syst., 7(1):159–172,2002.
230
[DT93] James C. Dehnert and Ross A. Towle. Compiling for Cydra 5. Journalof Supercomputing, 7:181–227, May 1993.
[EDA94] Alexandre E. Eichenberger, Edward S. Davidson, and Santosh G. Abra-ham. Minimum register requirements for a modulo schedule. In Pro-ceedings of the 27th Annual International Symposium on Microarchi-tecture, pages 75–84, San Jose, California, November 30–December2,1994. ACM SIGMICRO and IEEE-CS TC-MICRO.
[EDA95] Alexandre E. Eichenberger, Edward S. Davidson, and Santosh G. Abra-ham. Optimum modulo schedules for minimum register requirements.In Conference Proceedings, 1995 International Conference on Super-computing, pages 31–40, Barcelona, Spain, July 3–7, 1995. ACMSIGARCH.
[EN90] Kemal Ebcioglu and Toshio Nakatani. A new compilation technique forparallelizing loops with unpredictable branches on a VLIW architecture.In David Gelernter, Alexandru Nicolau, and David Padua, editors, Lan-guages and Compilers for Parallel Computing, Research Monographs inParallel and Distributed Computing, chapter 12, pages 213–229. PitmanPublishing and the MIT Press, London, and Cambridge, Massachusetts,1990. Selected papers from the Second Workshop on Languages andCompilers for Parallel Computing, Urbana, Illinois, August 1–3, 1989.
[Fea94] Paul Feautrier. Fine-grain scheduling under resource constraints. In Ke-shav Pingali, Uptal Banerjee, David Gelernter, Alex Nicolau, and DavidPadua, editors, Proceedings of the 7th International Workshop on Lan-guages and Compilers for Parallel Computing, number 892 in LectureNotes in Computer Science, pages 1–15, Ithaca, New York, August 8–10, 1994. Springer-Verlag.
[FLT99] M.M. Fernandes, J. Llosa, and N. Topham. Distributed modulo-scheduling. In Procs. of the International Symposium on High-Performance Computer Architecture (HPCA), pages 130–134, January1999.
[GAG94] R. Govindarajan, Erik R. Altman, and Guang R. Gao. Minimizingregister requirements under resource-constrained rate-optimal softwarepipelining. In Proceedings of the 27th Annual International Symposiumon Microarchitecture, pages 85–94, San Jose, California, November 30–December2, 1994. ACM SIGMICRO and IEEE-CS TC-MICRO.
231
[GAG96] R. Govindarajan, Erik R. Altman, and Guang R. Gao. A framework forresource-constrained rate-optimal software-pipelining. IEEE Transac-tions on Parallel and Distributed Systems, 7(11):1133,1149, November1996.
[gcc03] The GNU compiler collection. http://gcc.gnu.org, November 2003.
[GCM+94] David M. Gallagher, William Y. Chen, Scott A. Mahlke, John C. Gyl-lenhaal, and Wen mei W. Hwu. Dynamic memory disambiguation usingthe memory conflict buffer. In Proceedings of the Sixth InternationalConference on Architectural Support for Programming Languages andOperating Systems, pages 183–193, San Jose, California, October 4–7,1994. ACM SIGARCH, SIGOPS, SIGPLAN, and the IEEE ComputerSociety. Computer Architecture News, 22, October 1994; Operating Sys-tems Review, 28(5), December 1994; SIGPLAN Notices, 29(11), Novem-ber 1994.
[GJ79] Michael R. Garey and David S. Johnson. Computers and Intractability:A Guide to the Theory of NP-Completeness. W. H. Freemann and Co.,New York, 1979.
[GSS+01] E. Granston, R. Scales, E. Stotzer, A. Ward, , and J. Zbiciak. Control-ling code size of software-pipelined loops on the tms320c6000 vliw dsparchitecture. In Proceedings of 3rd IEEE/ACM Workshop on Media andStream Processors, 2001.
[HGAM92] Laurie J. Hendren, Guang R. Gao, Erik R. Altman, and Chandrika Muk-erji. A register allocation framework based on hierarchical cyclic intervalgraphs. In Proc. of the 4th Int’l Conf. on Compiler Construction, pages176–191. Springer-Verlag, 1992.
[HMR+00] J. Huck, D. Morris, J. Ross, A. Knies, H. Mulder, and R. Zahir. Intro-ducing the IA-64 architecture. IEEE Micro, 20(5):12–23, 2000.
[HP03] John L. Hennessy and David A. Patterson. Computer Architecture: AQuantitative Approach. Morgan Kaufmann Publishers Inc., San Fran-cisco, CA, USA, 2003.
[Hu61] T. C. Hu. Parallel sequencing and assembly line problems. OperationsResearch, 9(6):841–848, November 1961.
[Huf93] Richard A. Huff. Lifetime-sensitive modulo scheduling. In Proceedingsof the ACM SIGPLAN ’93 Conference on Programming Language De-sign and Implementation, pages 258–267, Albuquerque, New Mexico,June 23–25, 1993. SIGPLAN Notices, 28(6), June 1993.
232
[IBM03] IBM. IBM research Blue Gene project.http://www.research.ibm.com/bluegene/, November 2003.
[Jai91] Suneel Jain. Circular scheduling: A new technique to perform softwarepipelining. In Proceedings of the ACM SIGPLAN ’91 Conference onProgramming Language Design and Implementation, pages 219–228,Toronto, Ontario, June 26–28, 1991. SIGPLAN Notices, 26(6), June1991.
[Lam78] Leslie Lamport. Time, clocks, and the ordering of events in a distributedsystem. Communications of the ACM, 21(7), July 1978.
[Lam88] Monica Lam. Software pipelining: An effective scheduling techniquefor VLIW machines. In Proceedings of the SIGPLAN ’88 Conference onProgramming Language Design and Implementation, pages 318–328,Atlanta, Georgia, June 22–24, 1988. SIGPLAN Notices, 23(7), July1988.
[LAV98] Josep Llosa, Eduard Ayguade, and Mateo Valero. Quantitative evalua-tion of register pressure on software pipelined loops. International Jour-nal of Parallel Programming, 26(2):121–142, 1998.
[LF02] J. Llosa and S.M. Freudenberger. Reduced code size modulo schedulingin the absence of hardware support. In Proceedings of the 35th An-nual International Symposium on Microarchitecture, Istanbul, Turkey,December 2002.
[LGAV96] J. Llosa, A. Gonzalez, E. Ayguade, and M. Valero. Swing moduloscheduling: A lifetime sensitive approach. In Proc. of the Interna-tional Conference on Parallel Architectures and Compilation Techniques(PACT), pages 80–86, october 1996.
[LM05] Jian Li and Jose Martınez. Power performance considerations of parallelcomputing on chip multiprocessors. ACM Trans. on Architecture andCode Optimization, 2(4):397–422, December 2005.
[LVA96] J. Llosa, M. Valero, and E. Ayguade. Heuristics for register-constrainedsoftware pipelining. In Proceedings of the 29th Annual InternationalSymposium on Microarchitecture, pages 250–261, 1996.
233
[MCmWH+92] Scott A. Mahlke, William Y. Chen, Wen mei W. Hwu, B. RamakrishnaRau, and Michael S. Schlansker. Sentinel scheduling for VLIW and su-perscalar processors. In Proceedings of the Fifth International Confer-ence on Architectural Support for Programming Languages and Oper-ating Systems, pages 238–247, Boston, Massachusetts, October 12–15,1992. ACM SIGARCH, SIGOPS, SIGPLAN, and the IEEE ComputerSociety. Computer Architecture News, 20, October 1992; OperatingSystems Review, 26, October 1992; SIGPLAN Notices, 27(9), Septem-ber 1992.
[MD01] Kalyan Muthukumar and Gautam Doshi. Software pipelining of nestedloops. In Proceedings of the 10th International Conference on CompilerConstruction, CC 2001, volume 2027 in Lecture Notes in Computer Sci-ence, pages 165–181, 2001.
[ME92] Soo-Mook Moon and Kemal Ebcioglu. An efficient resource-constrained global scheduling technique for superscalar and VLIW pro-cessors. In Proceedings of the 25th Annual International Symposiumon Microarchitecture, pages 55–71, Portland, Oregon, December 1–4, 1992. ACM SIGMICRO and IEEE-CS TC-MICRO. SIG MICRONewsletter 23(1–2), December 1992.
[ME97] Soo-Mook Moon and Kemal Ebcioglu. Parallelizing nonnumerical codewith selective scheduling and software pipelining. ACM Transactions onProgramming Languages and Systems (TOPLAS), 19(6):853–898, 1997.
[MLC+92] Scott A. Mahlke, David C. Lin, William Y. Chen, Richard E. Hank, andRoger A. Bringmann. Effective compiler support for predicated execu-tion using the hyperblock. In Proceedings of the 25th Annual Interna-tional Symposium on Microarchitecture, pages 45–54, Portland, Oregon,December 1–4, 1992. ACM SIGMICRO and IEEE-CS TC-MICRO. SIGMICRO Newsletter 23(1–2), December 1992.
[Muc97] Steven S. Muchnick. Advanced Compiler Design and Implementation.Morgan Kaufmann Publishers Inc., 1997.
[NE98] E. Nystrom and A. E. Eichenberger. Effective cluster assignment formodulo scheduling. In Procs. of 31st International Symposium on Mi-croarchitecture, pages 103–114, 1998.
[NG93] Q. Ning and Guang R. Gao. A novel framework of register allocation forsoftware-pipelining. In Conf. Rec. of the 20th Annual ACM SIGPLAN-SIGACT Symposium on Principles of Programming Languages, pages29–42, January 1993.
234
[Ope03] Open64 compiler and tools. http://open64.sourceforge.net/, November2003.
[ORSA05] Guilherme Ottoni, Ram Rangan, Adam Stoler, and David I. August. Au-tomatic thread extraction with decoupled software pipelining. In Pro-ceedings of the 38th annual IEEE/ACM International Symposium on Mi-croarchitecture (MICRO’05), 2005.
[PHA02] D. Petkov, R. Harr, and S. Amarasinghe. Efficient pipelining of nestedloops: Unroll-and-squash. In 16th International Parallel and DistributedProcessing Symposium (IPDPS ’02 (IPPS & SPDP)), pages 19–19,Washington - Brussels - Tokyo, April 2002. IEEE.
[RA93] M. Rajagopalan and V. H. Allan. Efficient scheduling of fine grain paral-lelism in loops. In Proceedings of the 26th Annual International Sympo-sium on Microarchitecture, pages 2–11, Austin, Texas, December 1–3,1993. IEEE-CS TC-MICRO and ACM SIGMICRO.
[Rau94] B. Ramakrishna Rau. Iterative modulo scheduling: An algorithm forsoftware pipelining loops. In Proceedings of the 27th Annual Interna-tional Symposium on Microarchitecture, pages 63–74, San Jose, Califor-nia, November 30–December2, 1994. ACM SIGMICRO and IEEE-CSTC-MICRO.
[RDG05] Hongbo Rong, Alban Douillet, and Guang R. Gao. Register allocationfor software pipelined multi-dimensional loops. In PLDI ’05: Proceed-ings of the 2005 ACM SIGPLAN conference on Programming languagedesign and implementation, pages 154–167, New York, NY, USA, 2005.ACM Press.
[RDGG04] Hongbo Rong, Alban Douillet, Ramaswamy Govindarajan, andGuang R. Gao. Code generation for single-dimension software-pipelining for multi-dimensional loops. In Proceedings of the 2004 In-ternational Symposium on Code Generation and Optimization (CGO),pages 175–184. IEEE Computer Society, March 2004.
[RG81] B. R. Rau and C. D. Glaeser. Some scheduling techniques and an easilyschedulable horizontal architecture for high performance scientific com-puting. In Proceedings of the 14th Annual Microprogramming Work-shop, pages 183–198, Chatham, Massachusetts, October 12–15, 1981.ACM SIGMICRO and IEEE-CS TC-MICRO.
235
[RGSL96] John Ruttenberg, G. R. Gao, A. Stoutchinin, and W. Lichtenstein. Soft-ware pipelining showdown: optimal vs. heuristic methods in a produc-tion compiler. In Proceedings of the ACM SIGPLAN 1996 conference onProgramming language design and implementation, pages 1–11. ACMPress, 1996.
[RLTS92] B. R. Rau, M. Lee, P. P. Tirumalai, and M. S. Schlansker. Register alloca-tion for software pipelined loops. In Proceedings of the ACM SIGPLAN1992 conference on Programming language design and implementation(PLDI), pages 283–299, 1992.
[RST92] B. Ramakrishna Rau, Michael S. Schlansker, and P. P. Tirumalai. Codegeneration schema for modulo scheduled loops. In Proceedings of the25th annual international symposium on Microarchitecture, pages 158–169, 1992.
[RTG+03] Hongbo Rong, Zhizhi Tang, Ramaswamy Govindarajan, Alban Douil-let, and Guang R. Gao. Single-dimension software pipelining of multi-dimensional loops. CAPSL Technical Memo 49, Department of Elec-trical and Computer Engineering, University of Delaware, Newark,Delaware, August 2003. In ftp://ftp.capsl.udel.edu/pub/doc/memos/.
[RTG+04] Hongbo Rong, Zhizhong Tang, Ramaswamy Govindarajan, AlbanDouillet, and Guang R. Gao. Single-dimension software pipelining formulti-dimensional loops. In Proceedings of the 2004 International Sym-posium on Code Generation and Optimization (CGO), pages 163–174.IEEE Computer Society, March 2004.
[RYYT89] B. Ramakrishna Rau, David W. L. Yen, Wei Yen, and Ross A. Towle.The Cydra 5 departmental supercomputer – design philosophies, deci-sions, and trade-offs. Computer, 22(1):12–35, January 1989.
[Sar00] Vivek Sarkar. Optimized unrolling of nested loops. In ConferenceProceedings of the 2000 International Conference on Supercomput-ing, pages 153–166, Santa Fe, New Mexico, May 8–11, 2000. ACMSIGARCH.
[SD05] Won So and Alexander G. Dean. Complementing software-pipeliningwith software thread integration. In Proceedings of LCTES’05, Chicago,Illinois, USA, June 2005.
236
[SG00a] J. Sanchez and A. Gonzalez. The effectiveness of loop unrolling formodulo scheduling in clustered VLIW architectures. In Procs. of the29th Int. Conf. on Parallel Processing, pages 555–562, August 2000.
[SG00b] J. Sanchez and A. Gonzalez. Modulo-scheduling for a fully-distributedclustered VLIW architecture. In Procs. of 33rd Int. Symp. on Microar-chitecture, December 2000.
[TEE+96] Dean M. Tullsen, Susan J. Eggers, Joel S. Emer, Henry M. Levy, Jack L.Lo, and Rebecca L. Stamm. Exploiting choice: Instruction fetch and is-sue on an implementable simultaneous multithreading processor. In Pro-ceedings of the 23rd Annual International Symposium on Computer Ar-chitecture, volume 24(2), pages 191–202. Computer Architecture News,May 1996.
[TEL95] Dean M. Tullsen, Susan J. Eggers, and Henry M. Levy. Simultaneousmulti-threading: Maximizing on-chip parallelism. In Proceedings of the22nd Annual International Symposium on Computer Architecture, vol-ume 23(2), pages 392–403. Computer Architecture News, May 1995.
[THA+99] J.Y. Tsai, J. Huang, C. Amlo, D.J. Lilja, and P.C. Yew. The superthreadedprocessor architecture. IEEE Transactions on Computers, Special Issueon Multithreaded Architectures, 48(9), September 1999.
[The99] Kevin Theobald. EARTH: An Efficient Architecture for RunningThreads. Ph.D. dissertation, McGill University, Quebec, Canada, May1999.
[TY96] J.Y. Tsai and P.C. Yew. The superthreaded architecture: Thread pipelin-ing with run-time data dependence checking and control speculation. InProceedings of the 1996 Conference on Parallel Architectures and Com-pilation Techniques (PACT’96), pages 35–46, October 1996.
[WBHS92] N. J. Warter, J. W. Bockhaus, G. E. Haab, and K. Subramanian. En-hanced modulo scheduling for loops with conditional branches. In Pro-ceedings of the 25th Annual International Symposium on Microarchitec-ture, Portland, Oregon,USA, 1992. ACM and IEEE.
[WG96] Jian Wang and Guang R. Gao. Pipelining-dovetailing: A transformationto enhance software pipelining for nested loops. In Proceedings of the6th International Conference on Compiler Construction, CC ’96, Lec-ture Notes in Computer Science, pages 1–17, Linkoping, Sweden, April22–26, 1996. Springer-Verlag.
237
[WKEE94] Jian Wang, Andreas Krall, M. Anton Ertl, and Christine Eisenbeis. Soft-ware pipelining with register allocation and spilling. In Proceedings ofthe 27th Annual International Symposium on Microarchitecture, pages95–99, San Jose, California, November 30–December2, 1994. ACMSIGMICRO and IEEE-CS TC-MICRO.
[WL91a] Michael E. Wolf and Monica S. Lam. A data locality optimizing al-gorithm. In Proceedings of the ACM SIGPLAN ’91 Conference on Pro-gramming Language Design and Implementation, pages 30–44, Toronto,Ontario, June 26–28, 1991. SIGPLAN Notices, 26(6), June 1991.
[WL91b] Michael E. Wolf and Monica S. Lam. A loop transformation theory andan algorithm to maximize parallelism. IEEE Transactions on Paralleland Distributed Systems, 2(4):452–471, October 1991.
[WMC+93] W.Hwu, S. A. Mahlke, W. Y. Chen, P. P. Chang, N. J. Warter, R. A.Bringmann, R. G. Ouellette, R. E. Hank, T. Kiyohara, G. E. Haab, J. G.Holm, and D. M. Lavery. The Superblock: An effective technique forVLIW and superscalar compilation. Journal of Supercomputing, 1993.
[WMC98] Michael E. Wolf, Dror E. Maydan, and Ding-Kai Chen. Combiningloop transformations considering caches and scheduling. Int. J. ParallelProgram., 26(4):479–503, 1998.
[WMHR93] N. J. Warter, S. A. Mahlke, W.-M. W. Hwu, and B. R. Rau. Reverse if-conversion. In Proceedings of the ACM SIGPLAN 1993 Conference onProgramming Language Design and Implementation (PLDI’93), pages290–299, New York, NY, USA, 1993. ACM Press.
[Wol86] Michael Wolfe. Loop skewing: The wavefront method revisited. In-ternational Journal of Parallel Programming, 15(4):279–293, August1986.
[Wol92] Michael E. Wolfe. Improving Locality and Parallelism in Nested Loops.Ph.D. dissertation, Stanford University, Stanford, CA, August 1992.
[Woo79] Graham Wood. Global optimization of microprograms through modularcontrol constructs. In Proc. of the 12th Annual Workshop in Micropro-gramming, pages 1–6, 1979.
[ZLAV00] Javier Zalamea, Josep Llosa, Eduard Ayguade, and Mateo Valero. Two-level hierarchical register file organization for vliw processors. In Proc.of the symp. on Microarch., pages 137–146, 2000.







































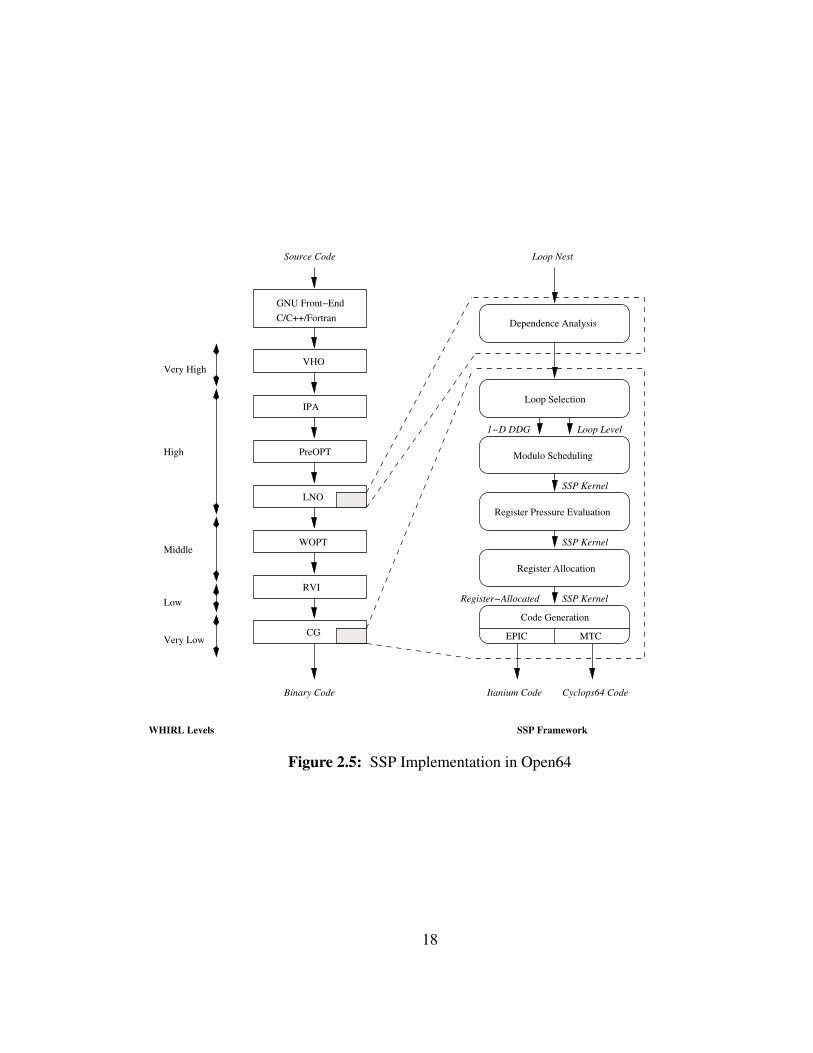










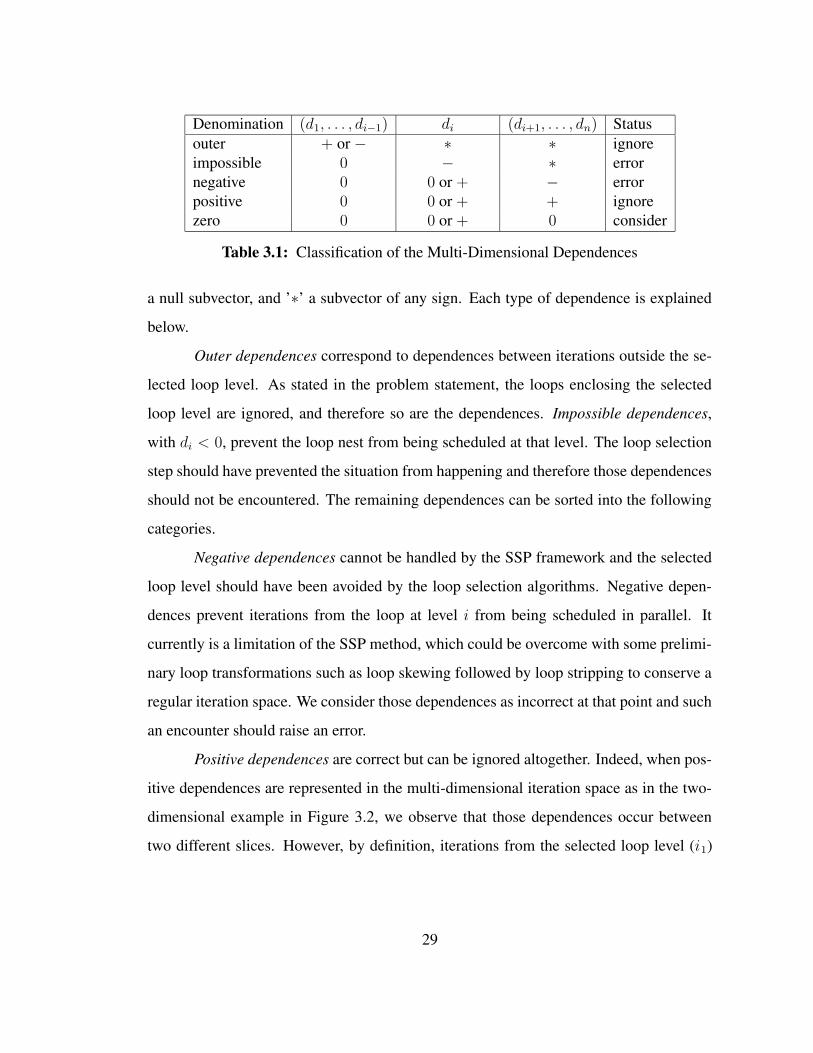









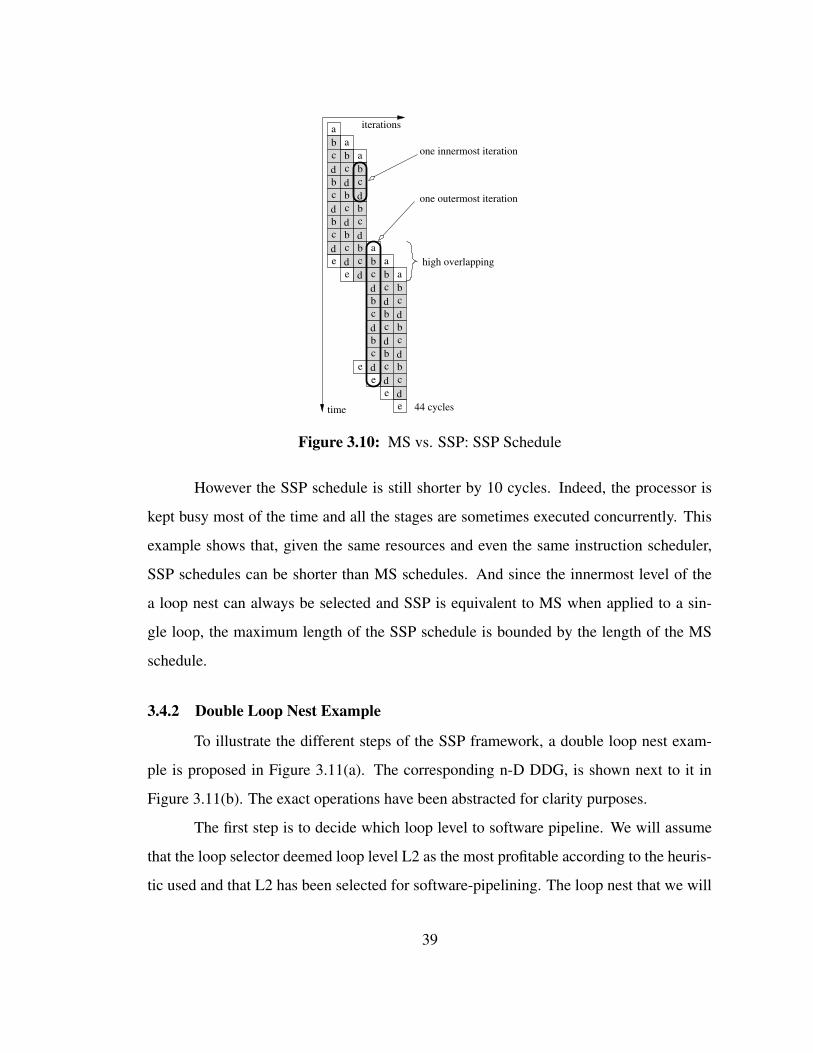





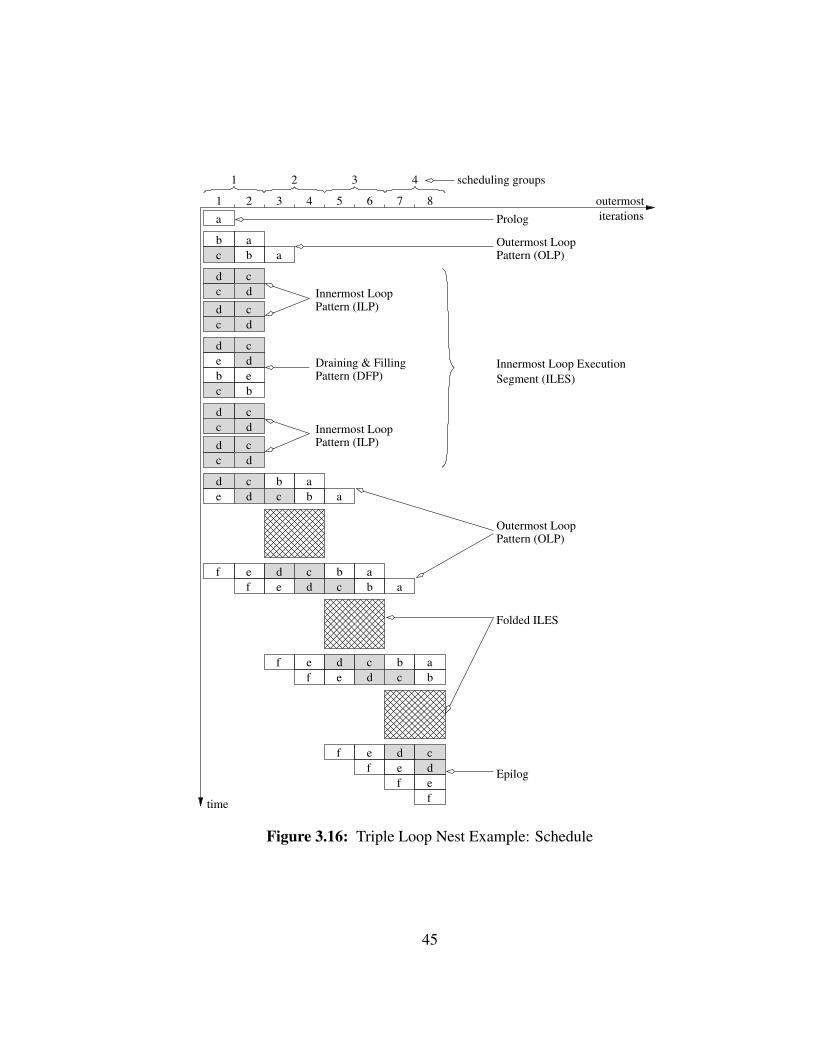



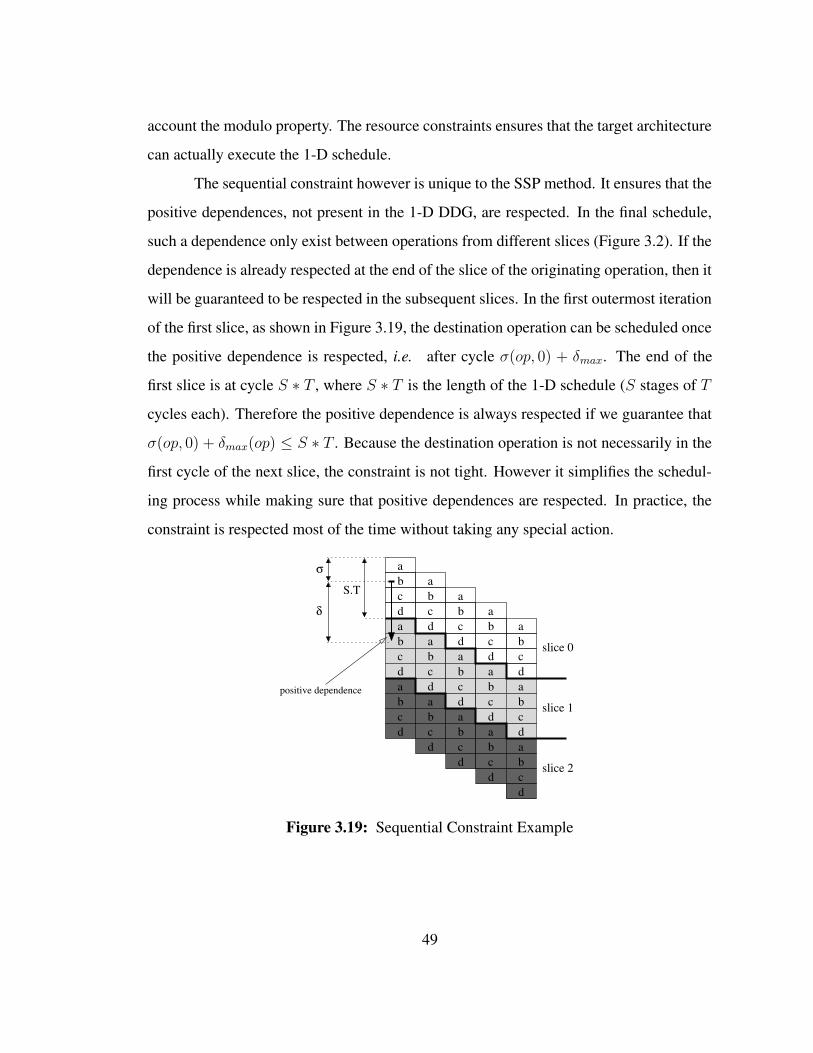
























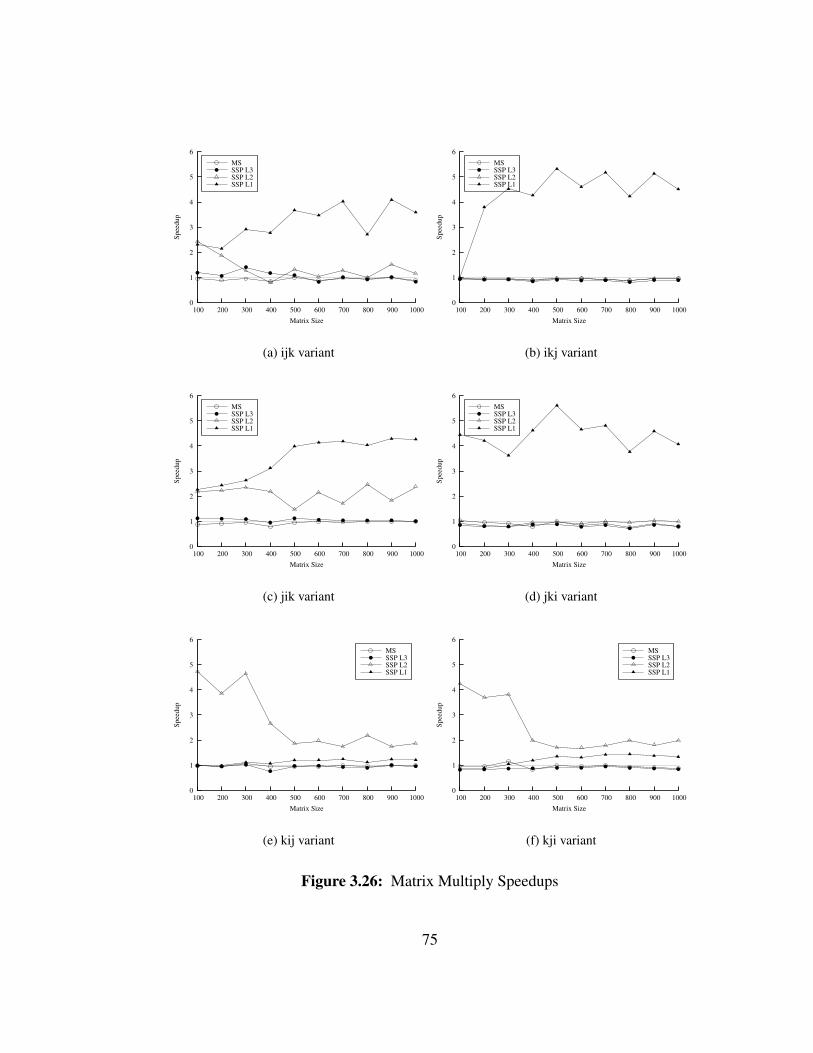
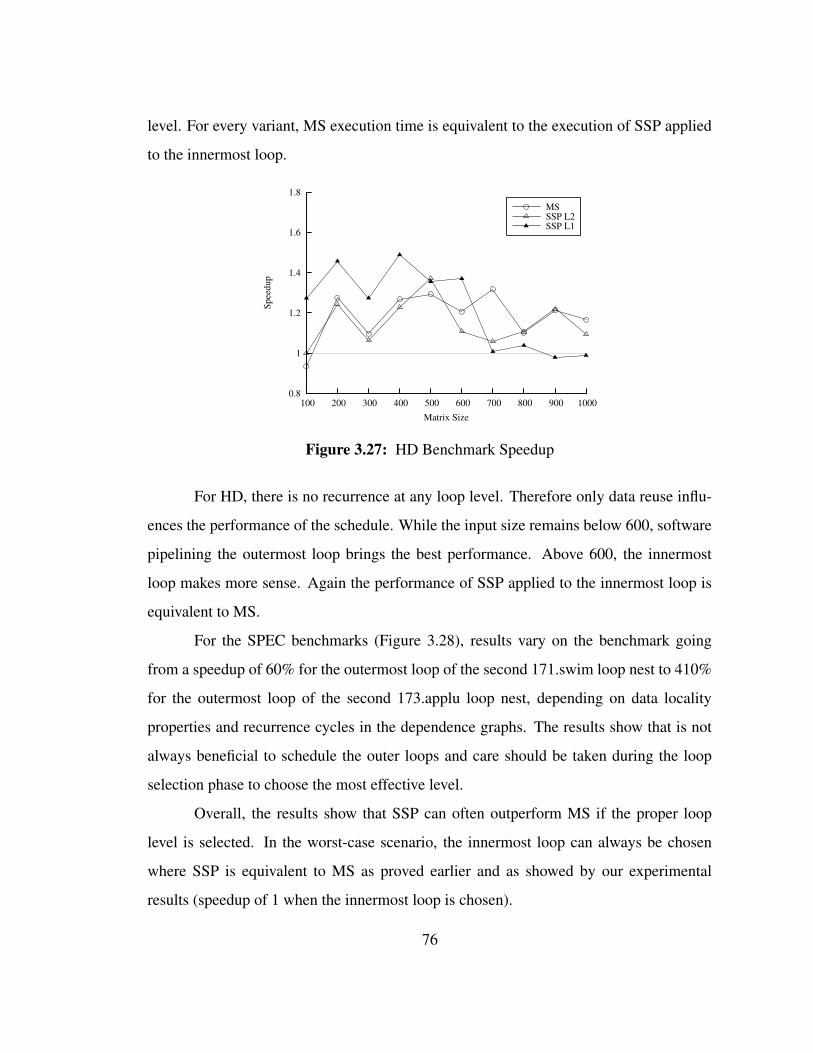
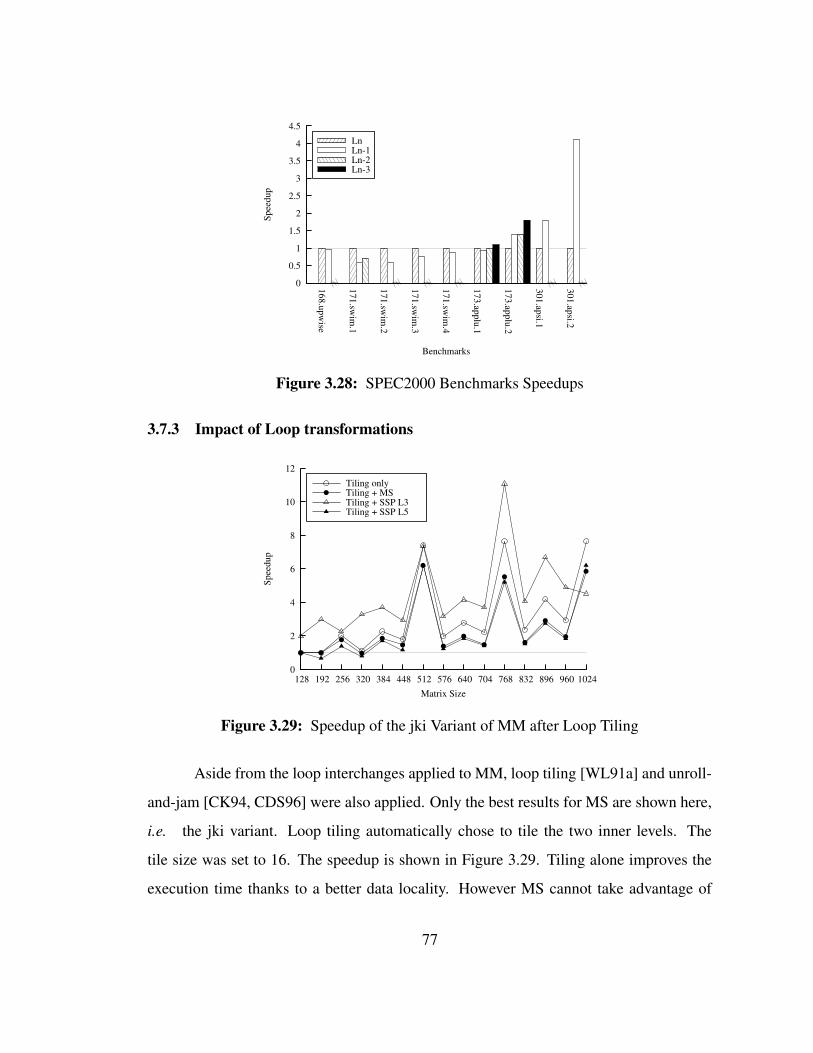

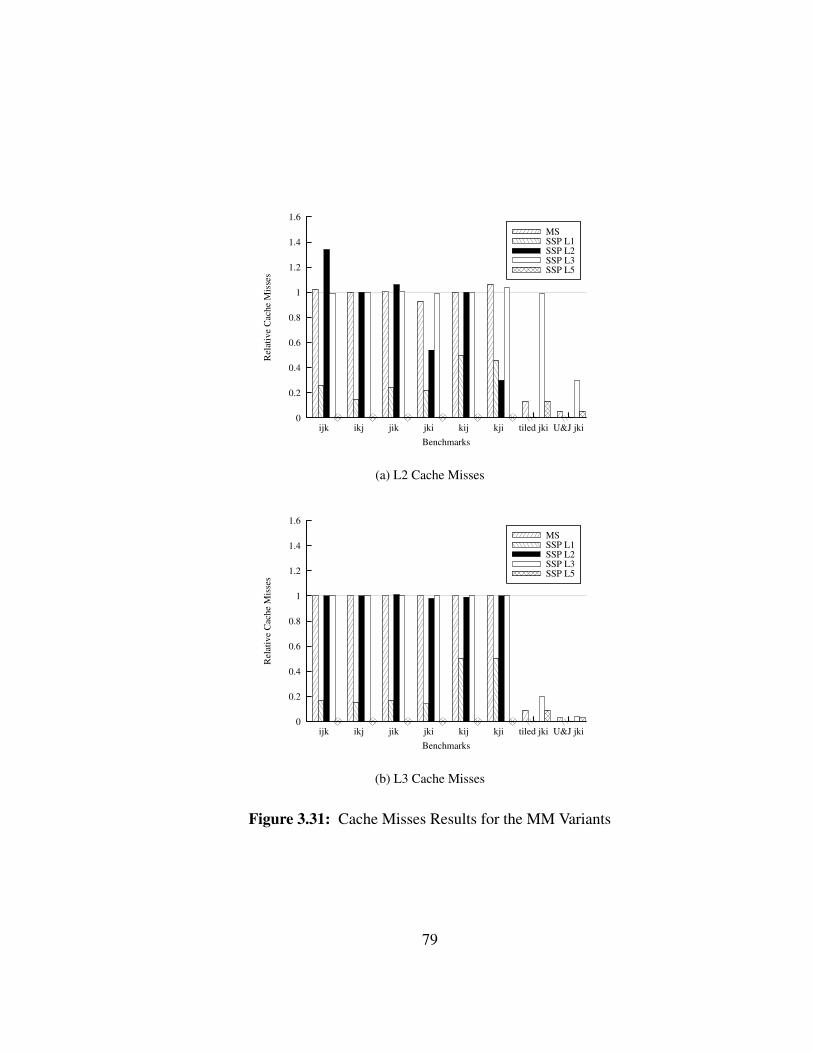
























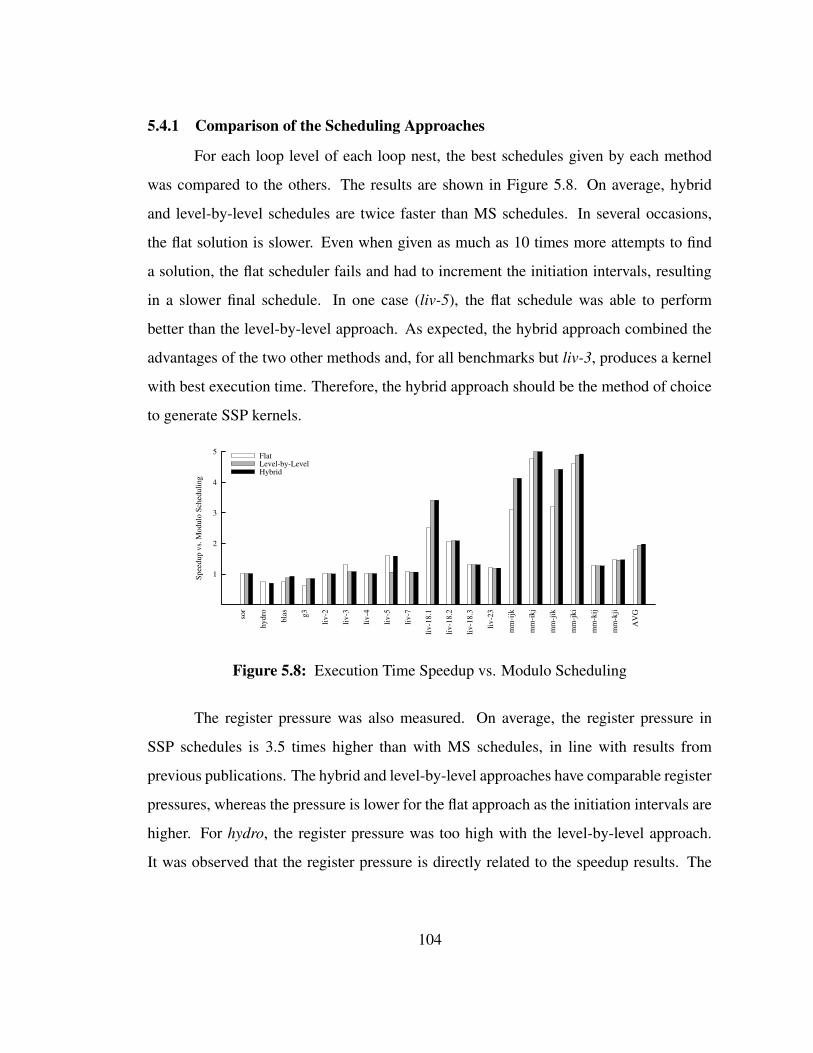
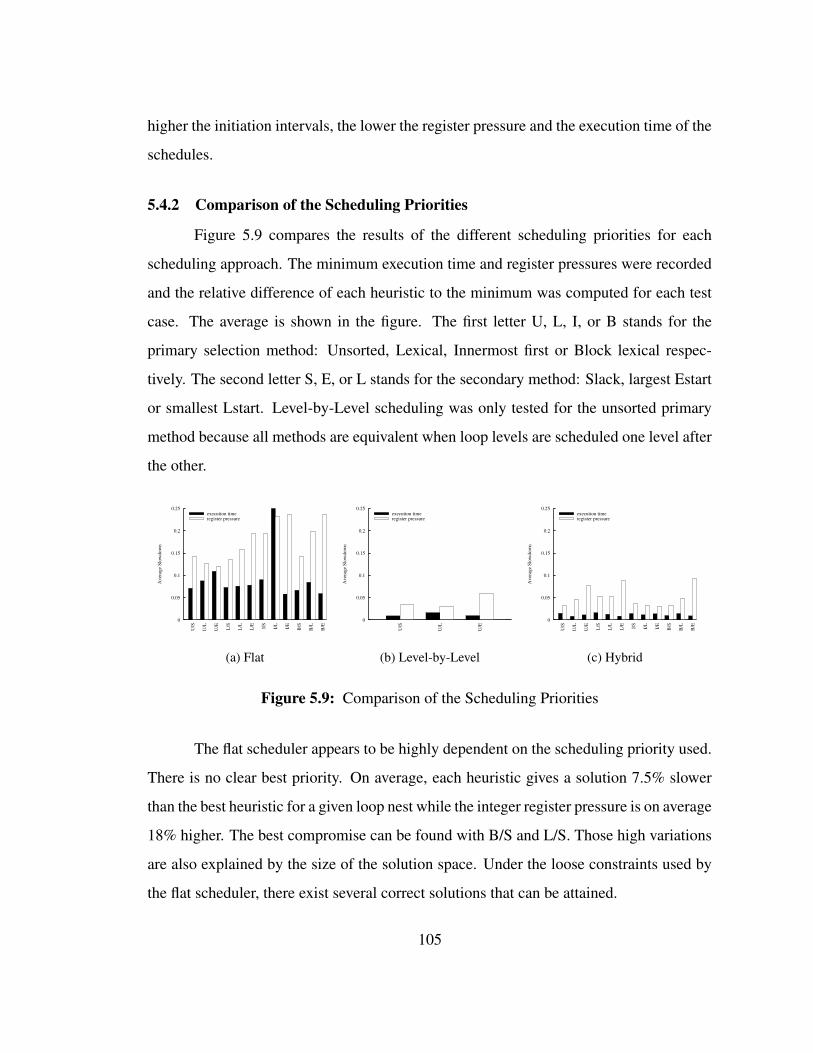















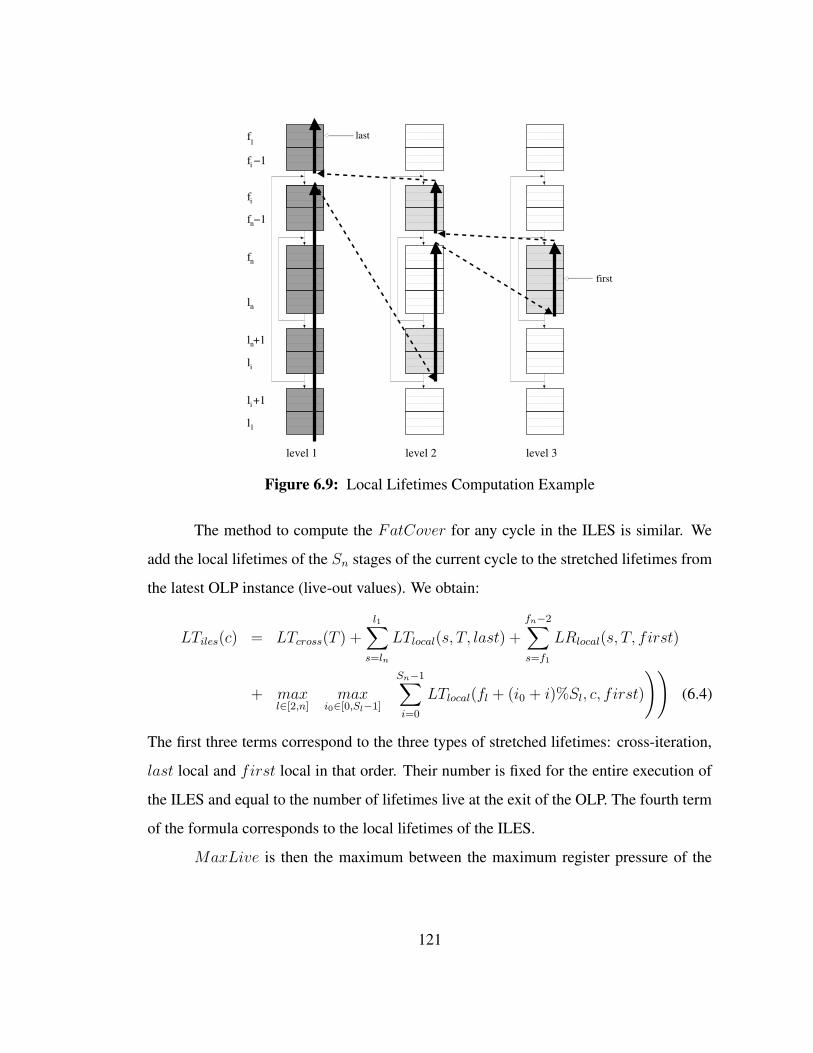

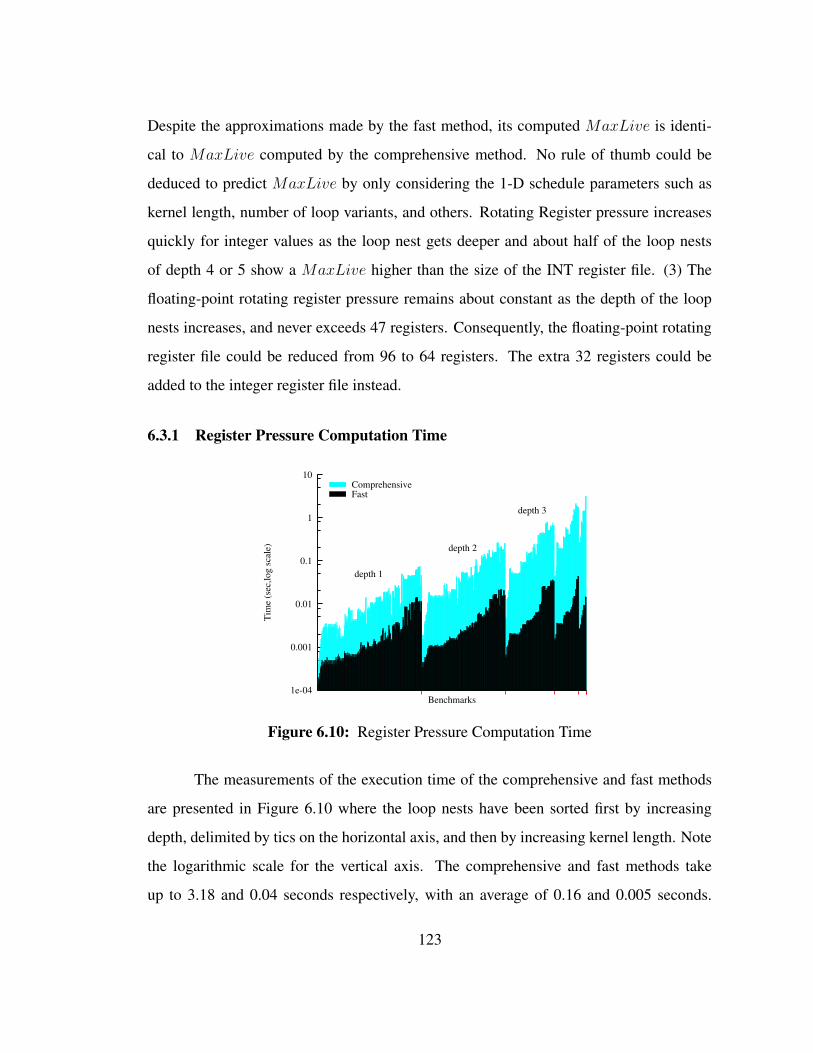
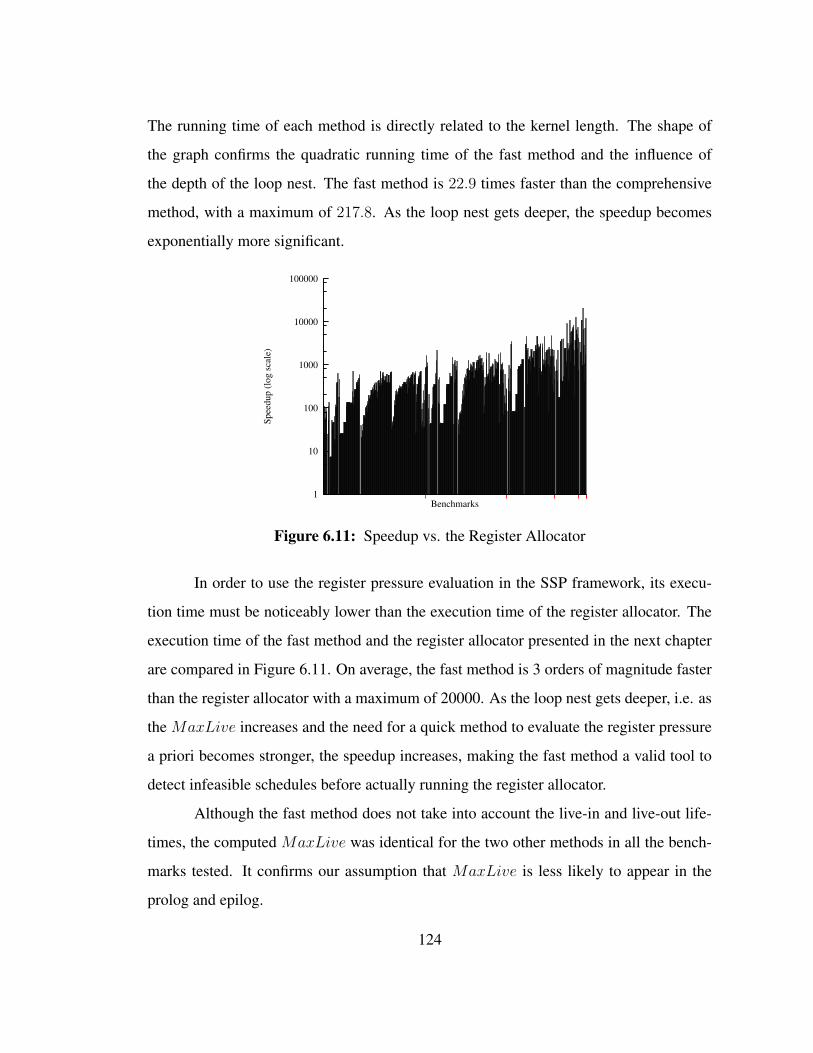
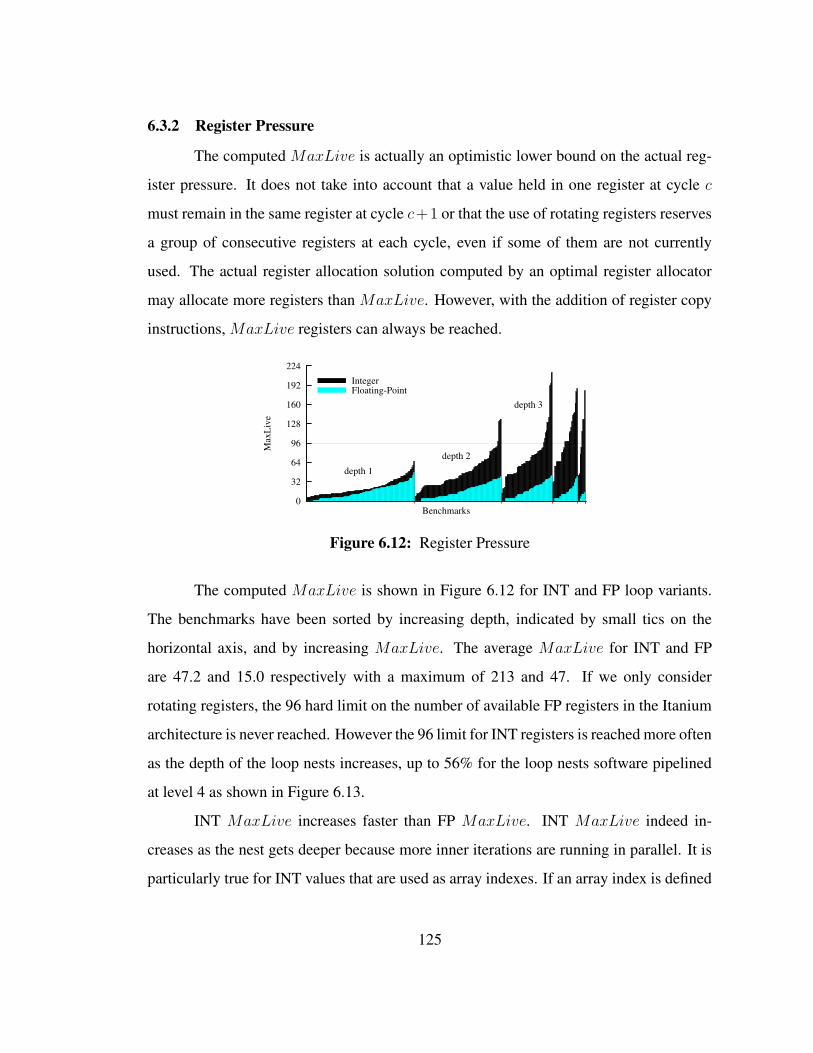

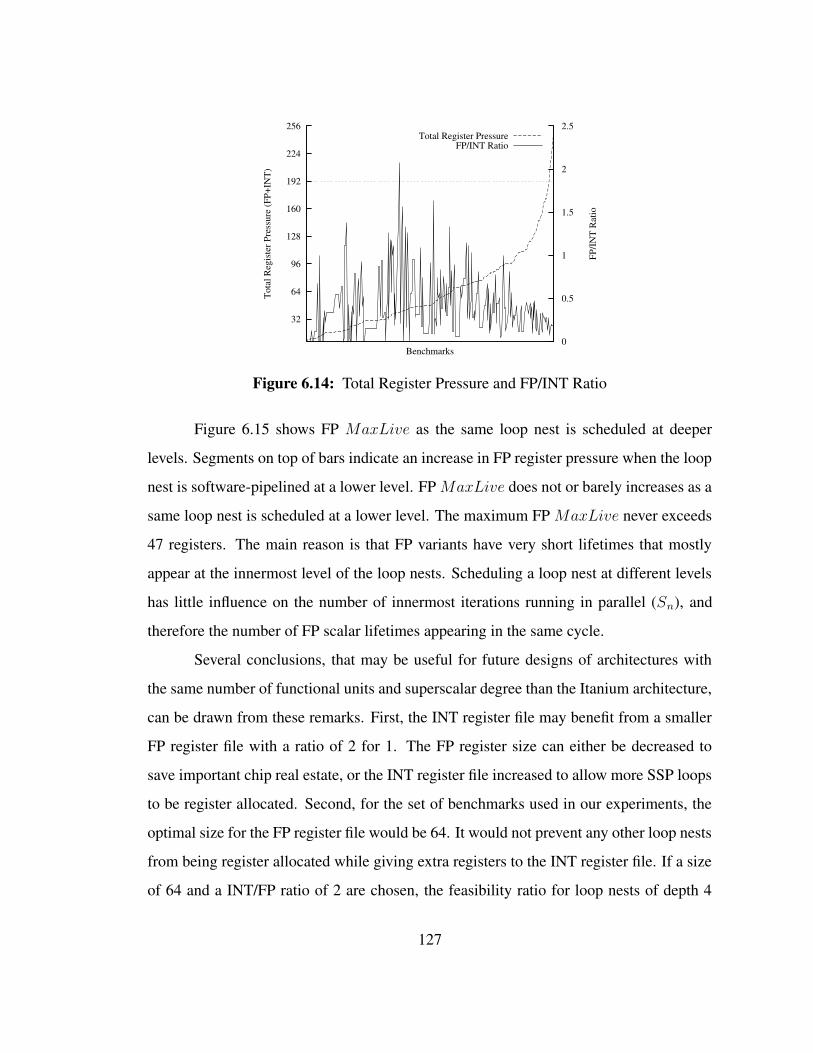
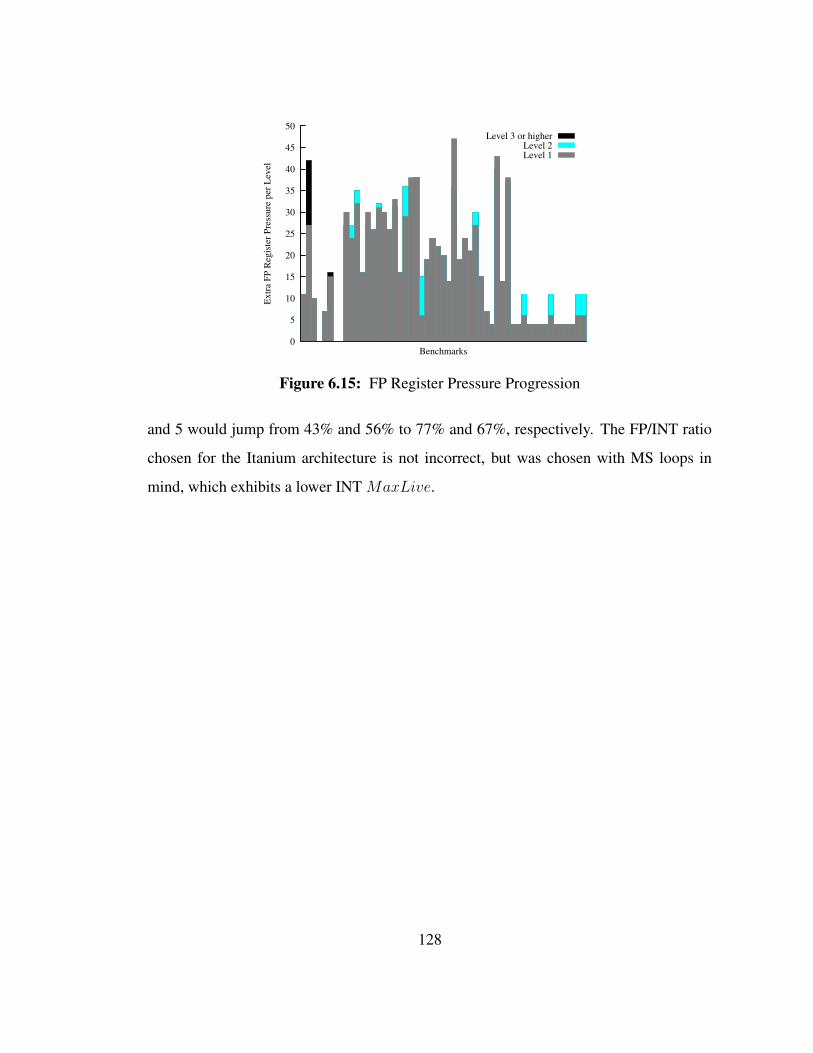


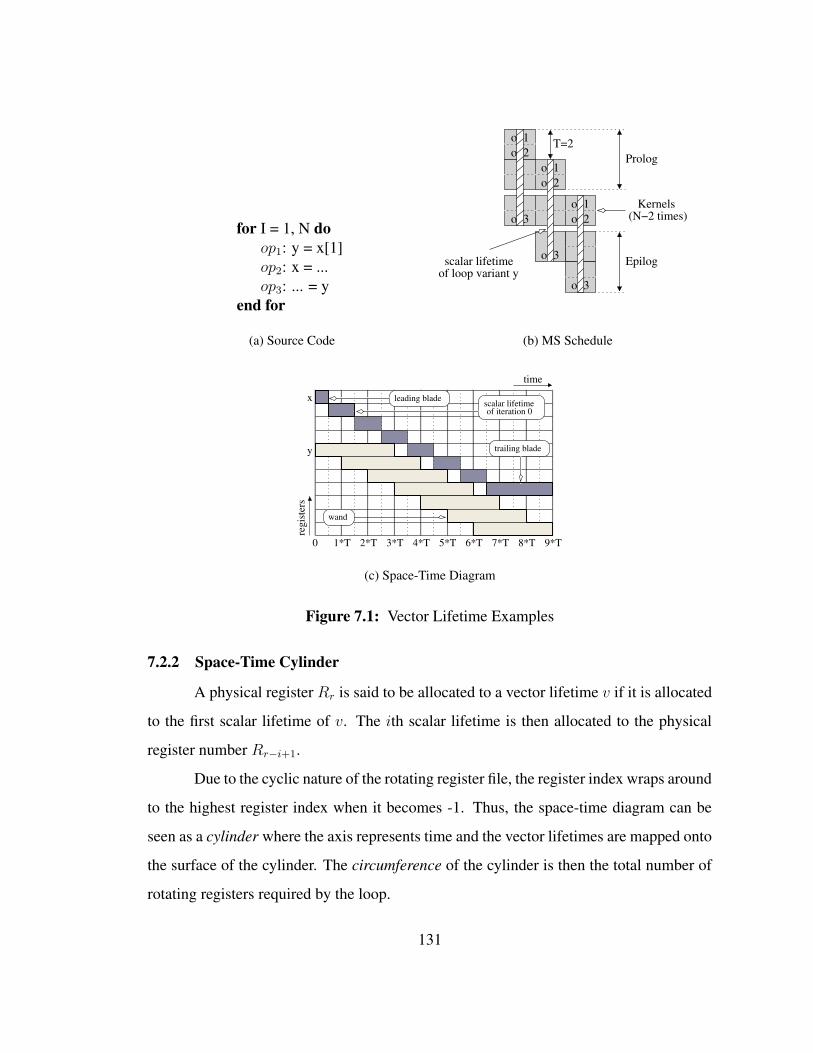


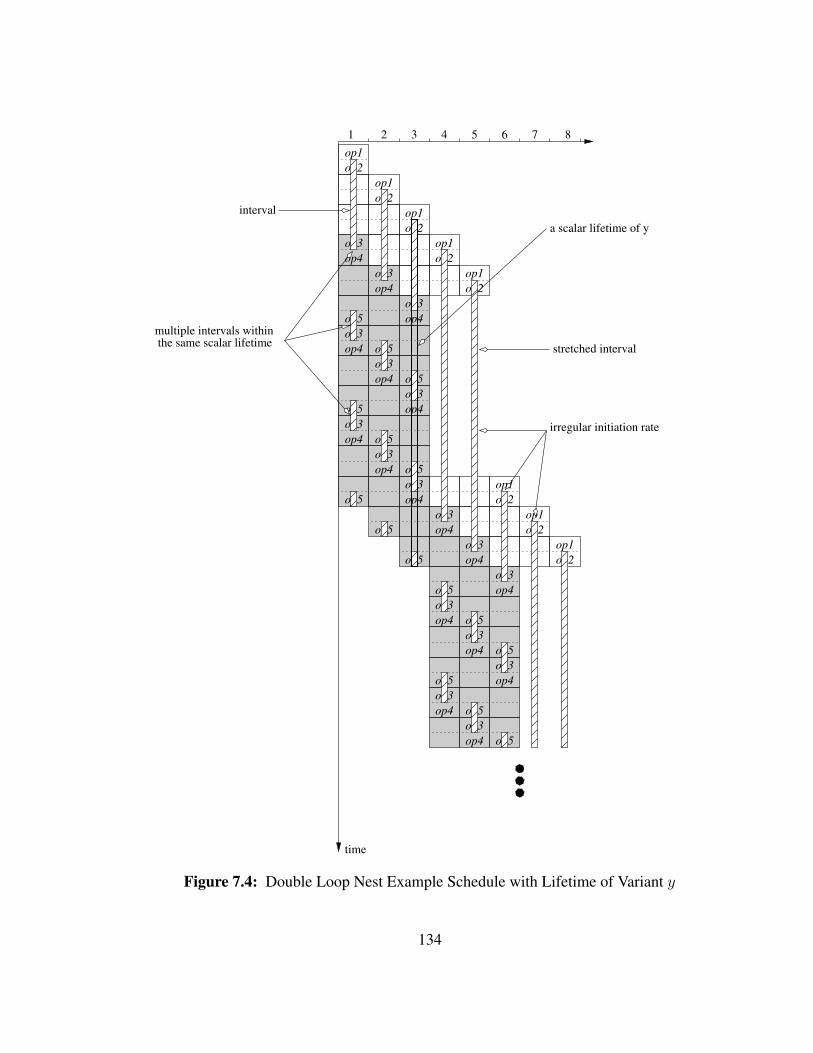

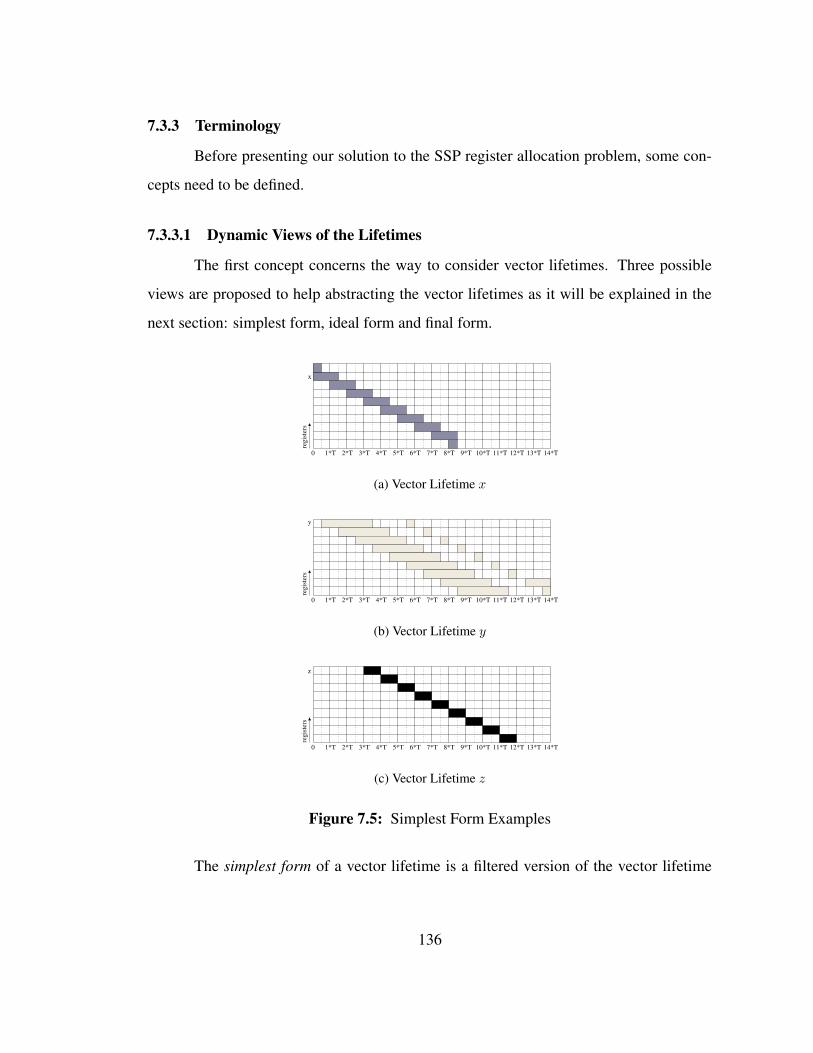

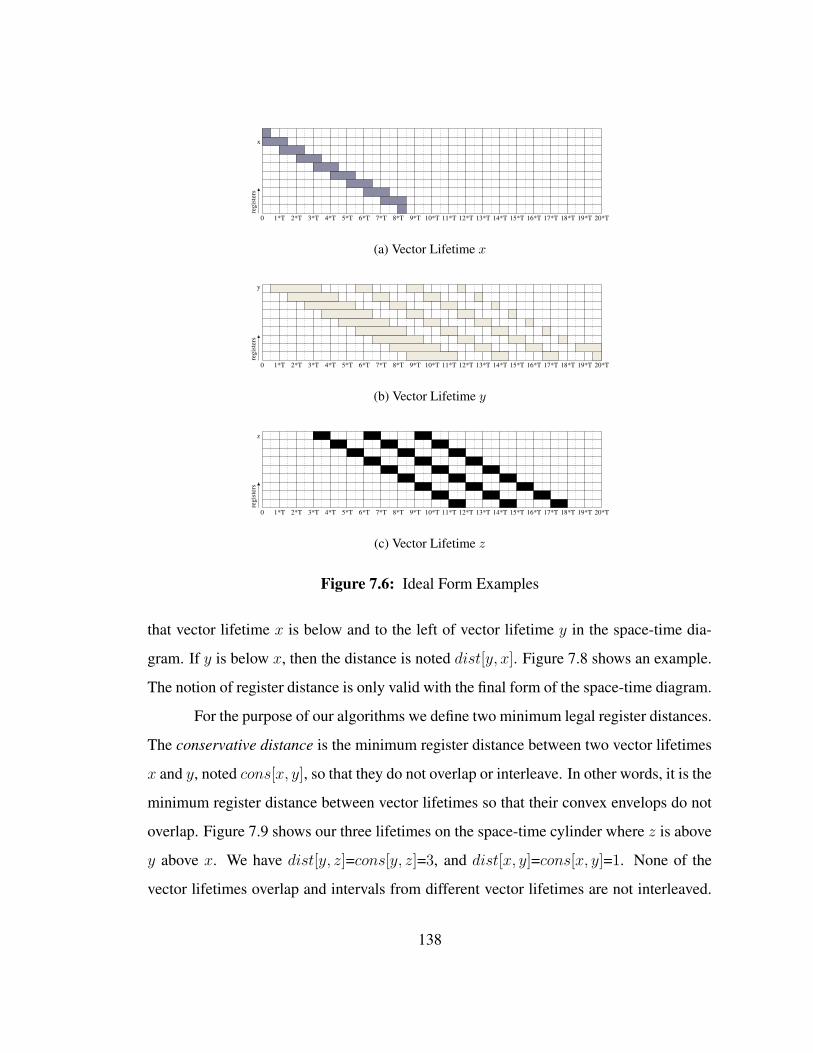
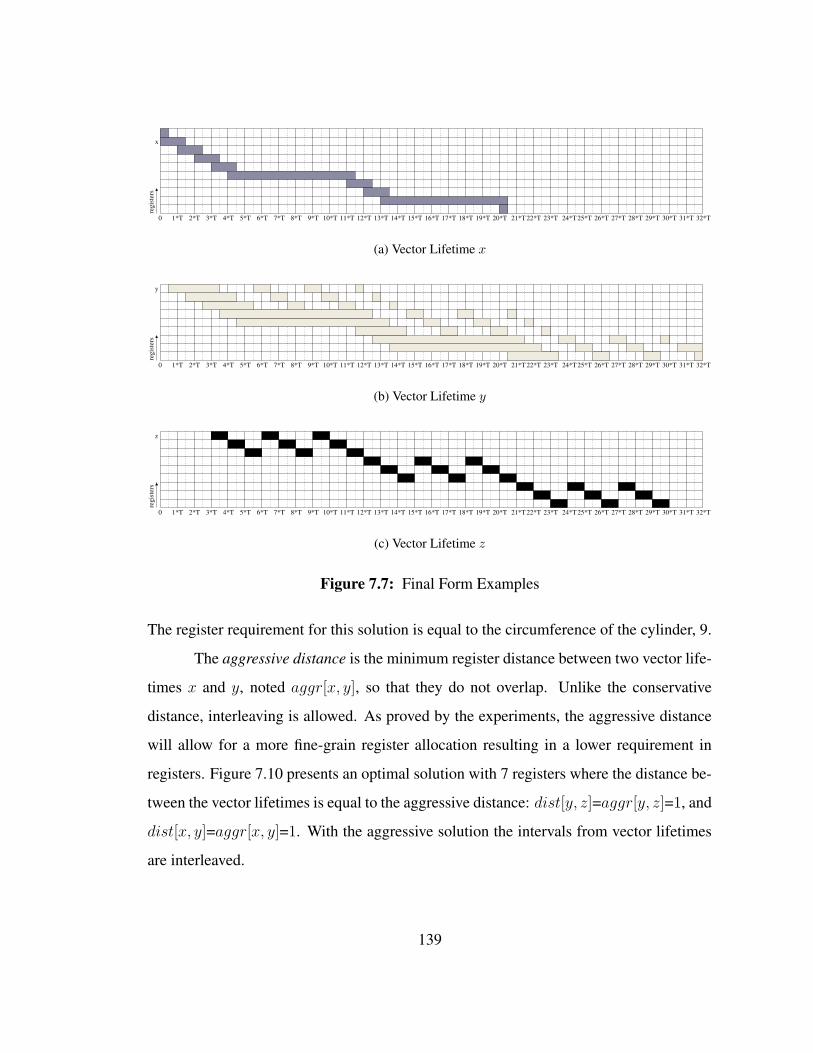
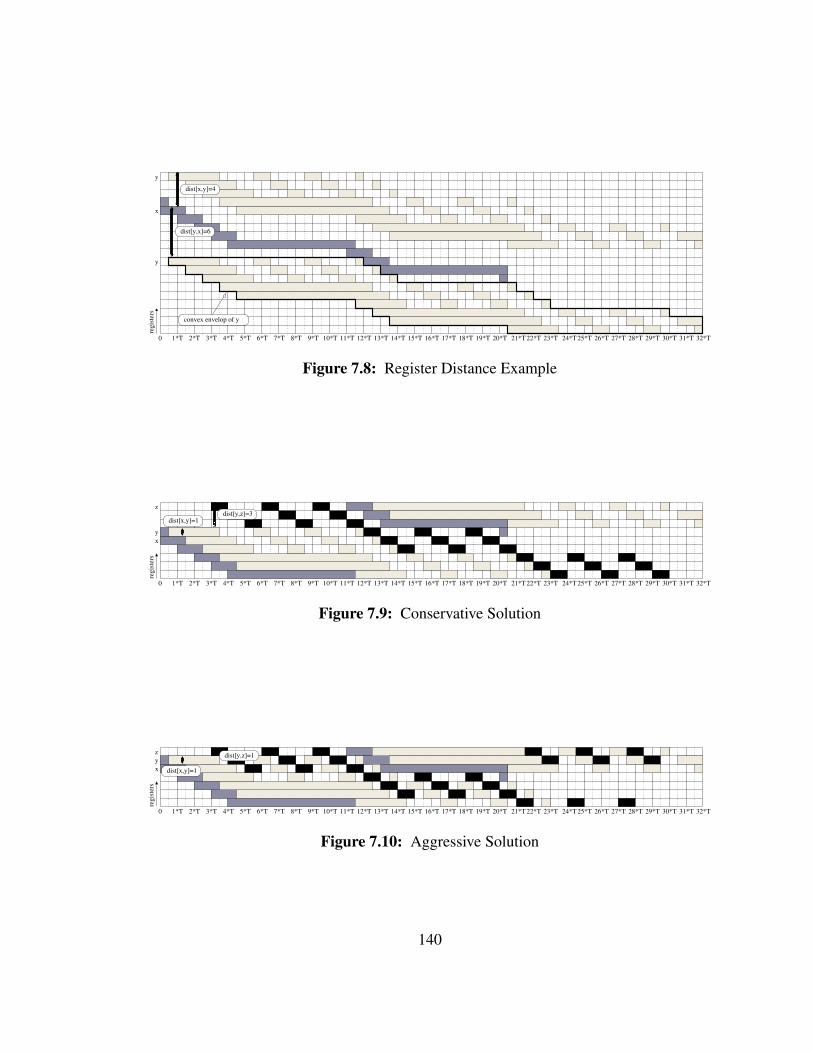







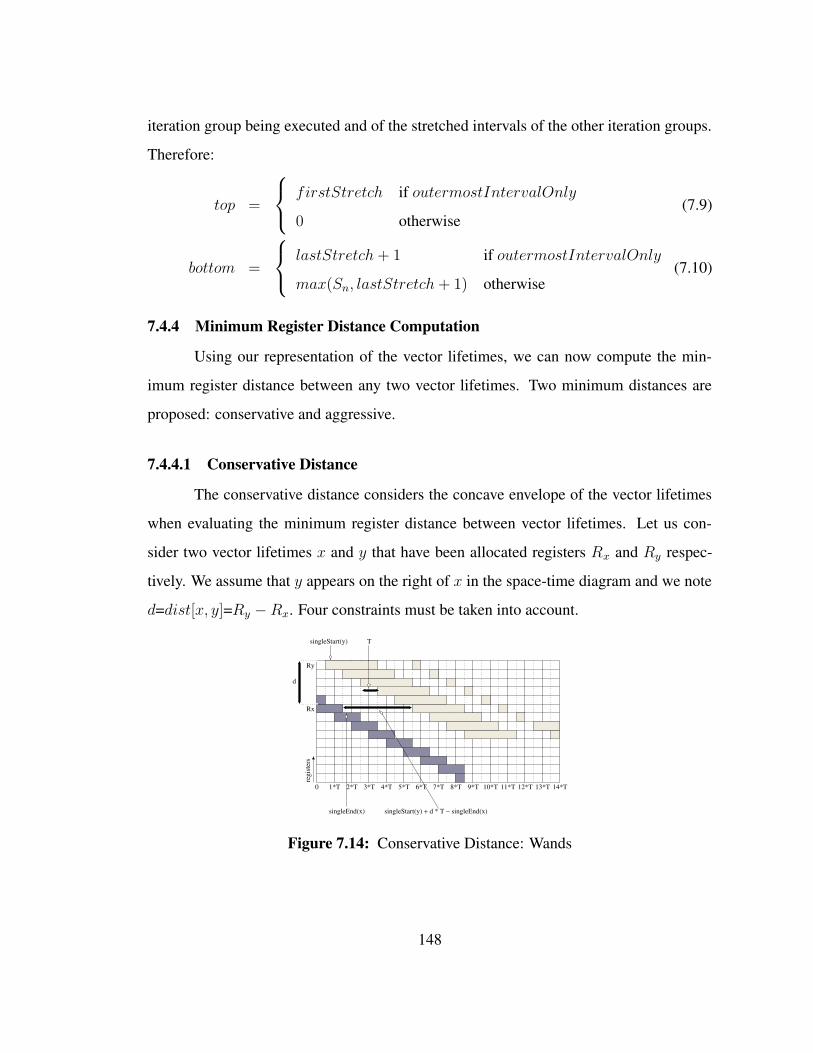

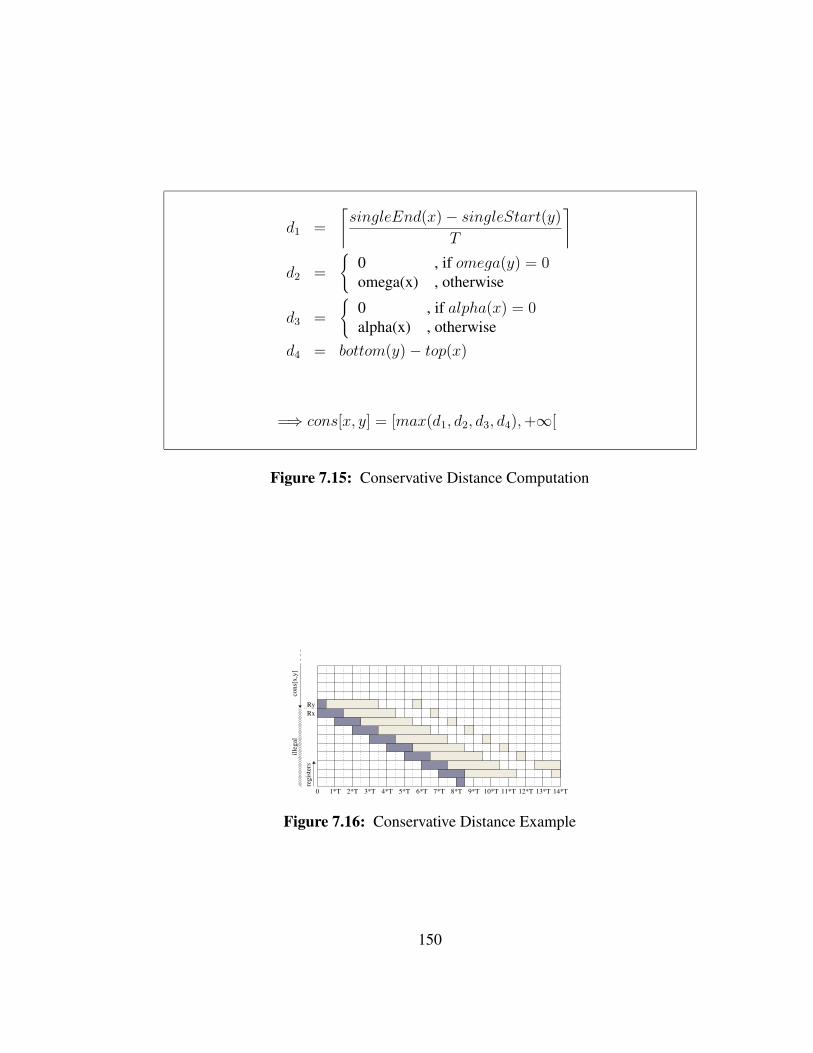


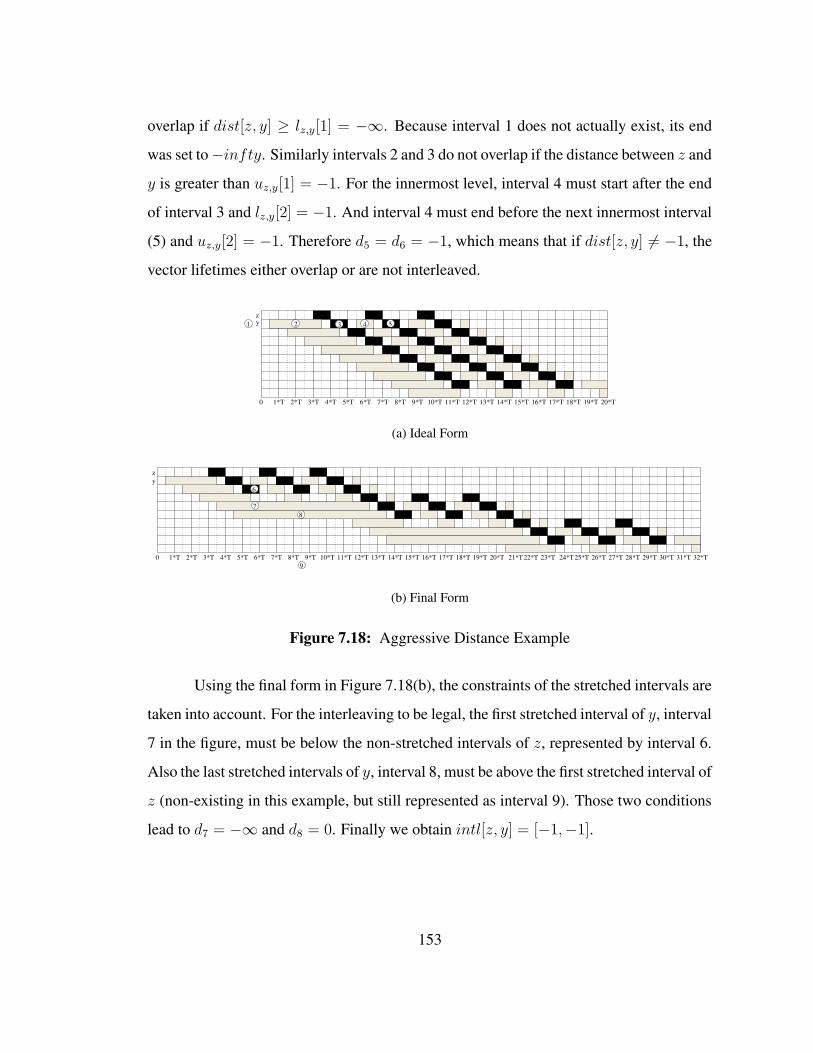







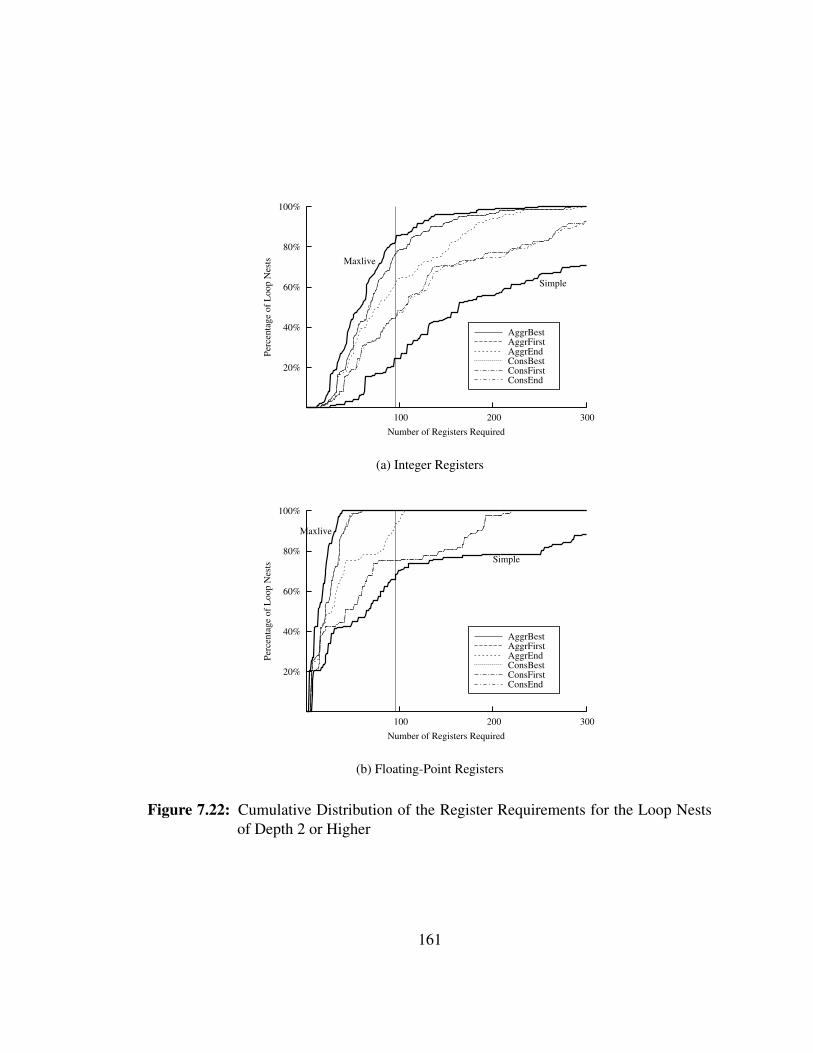





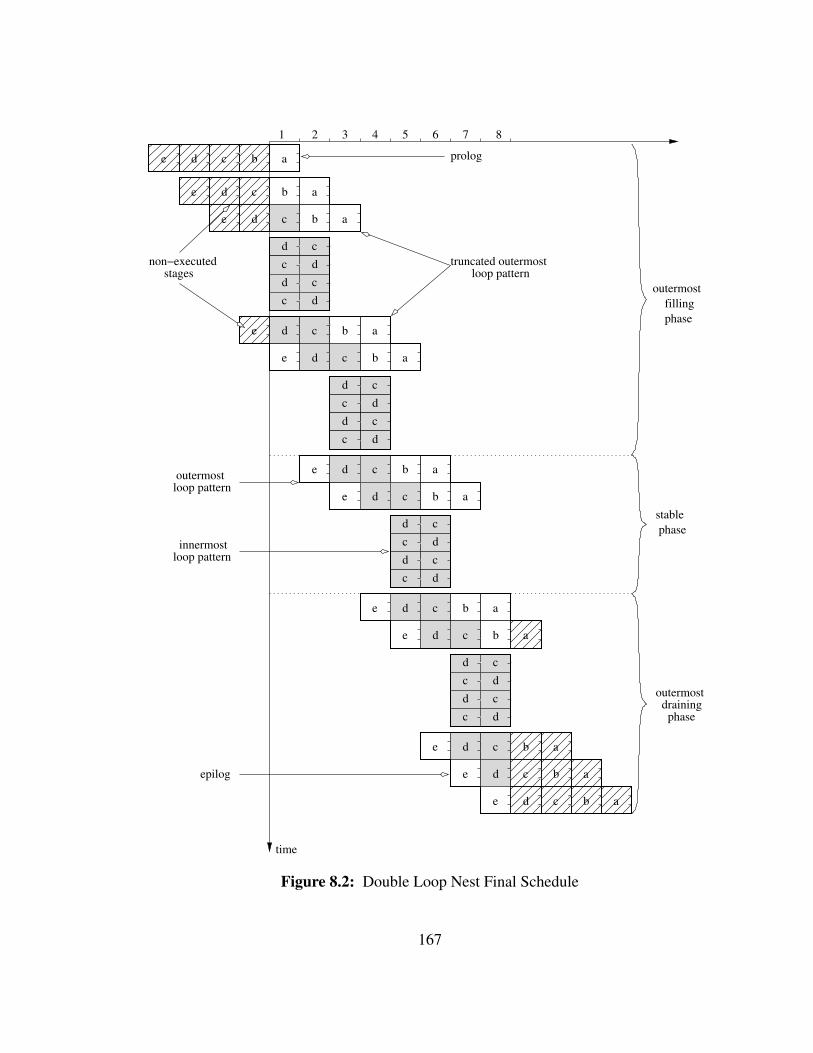


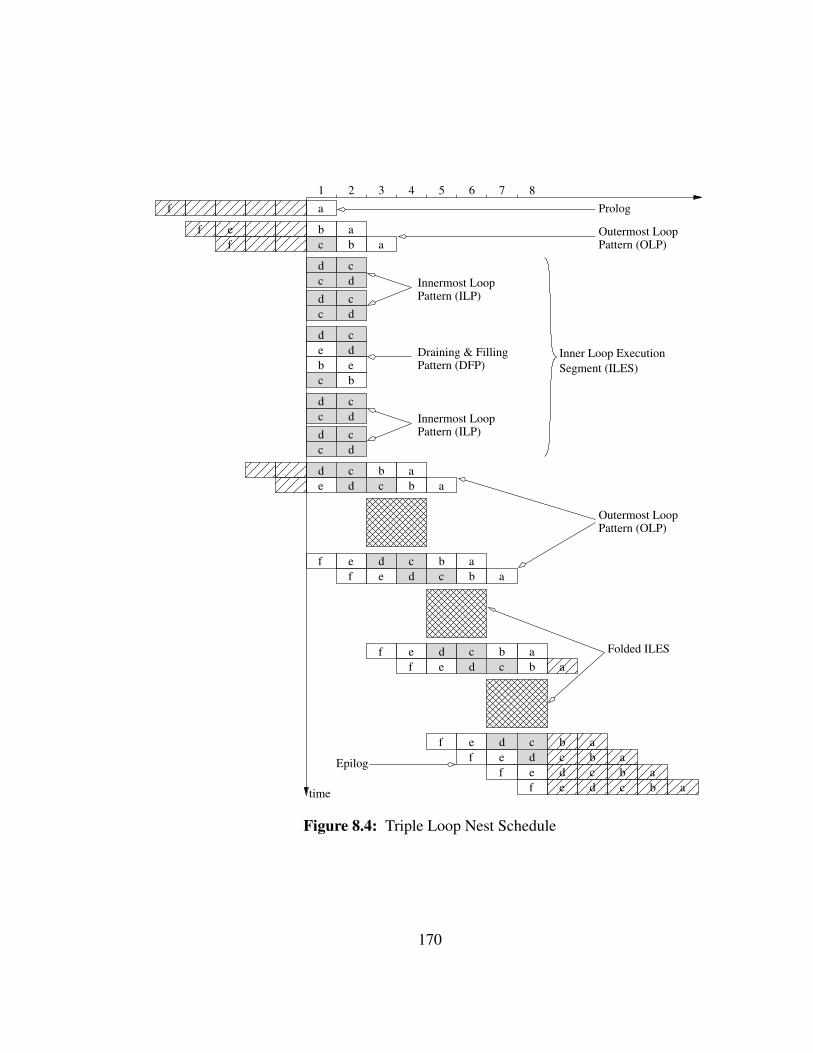











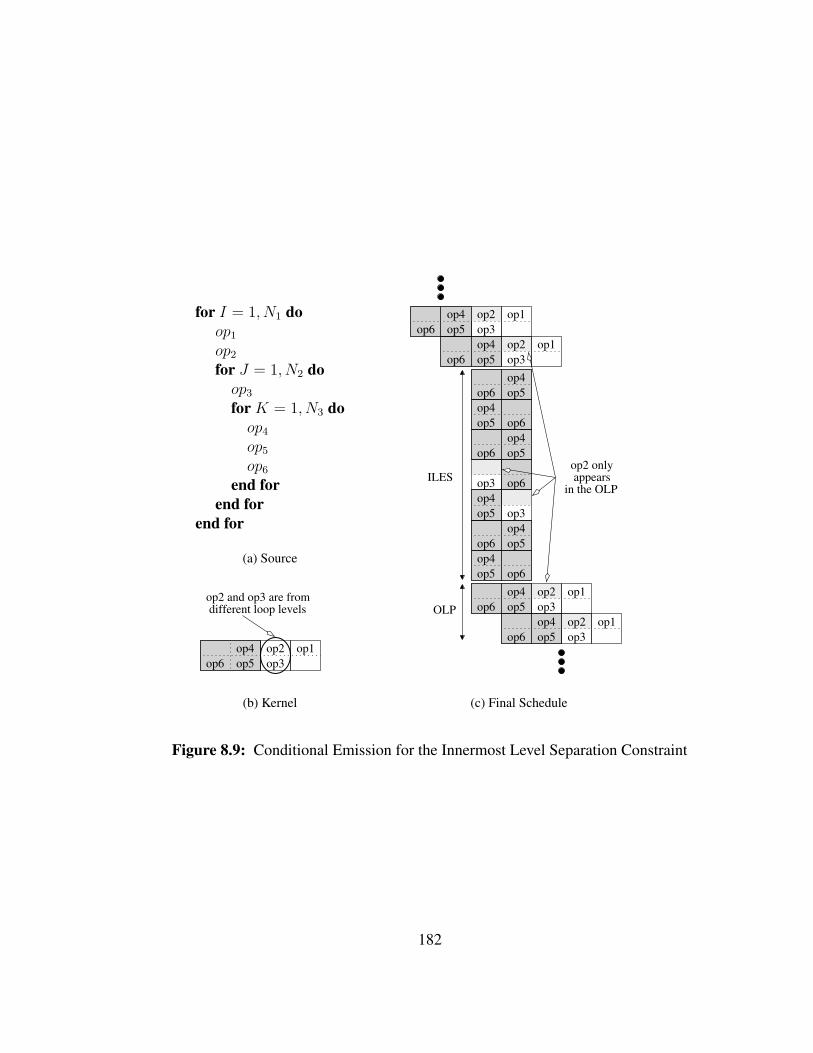



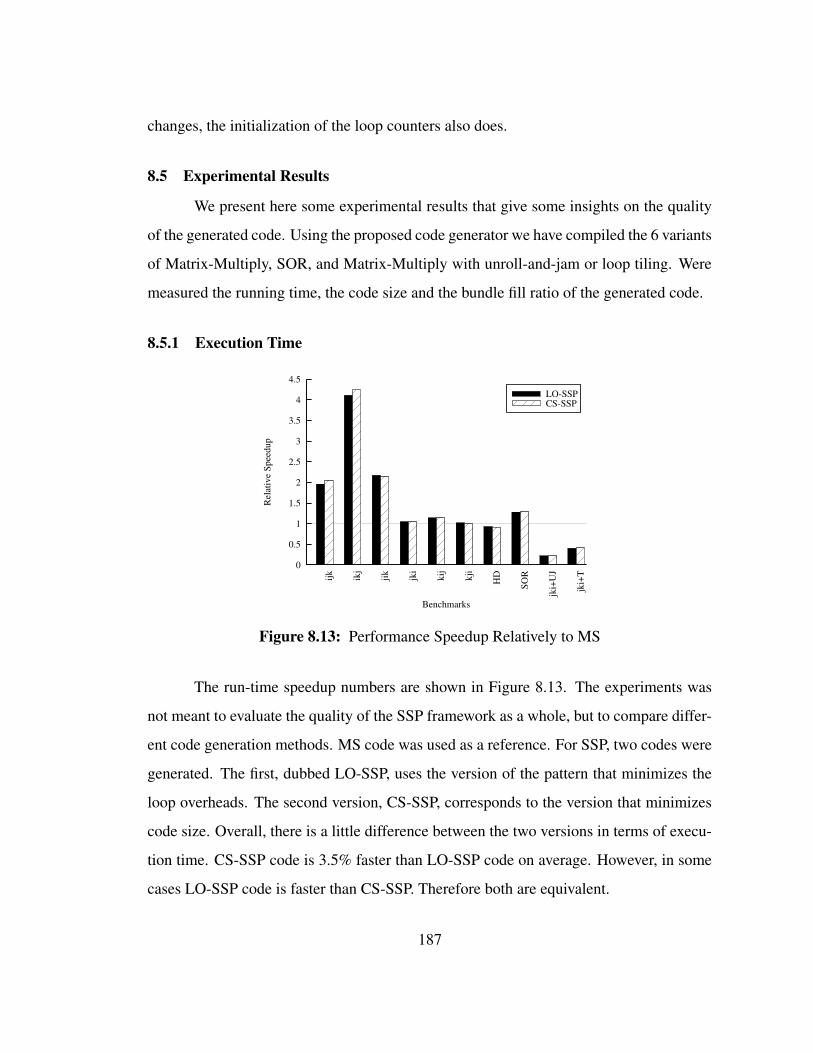




















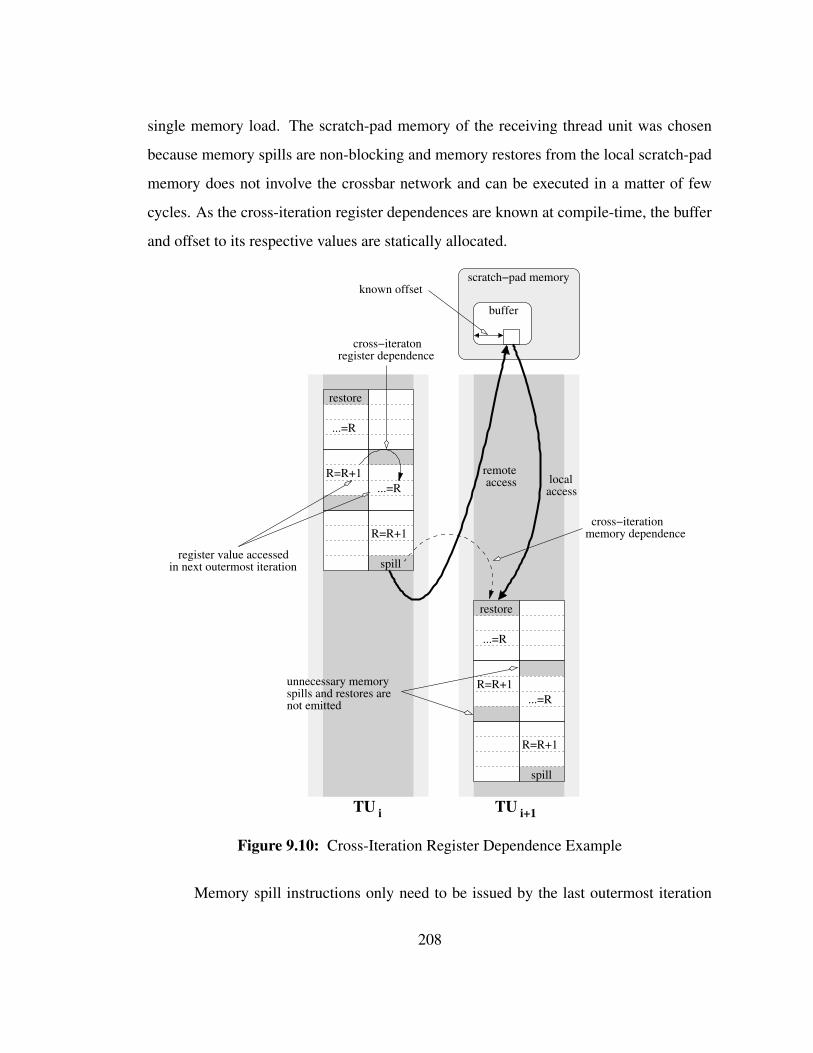







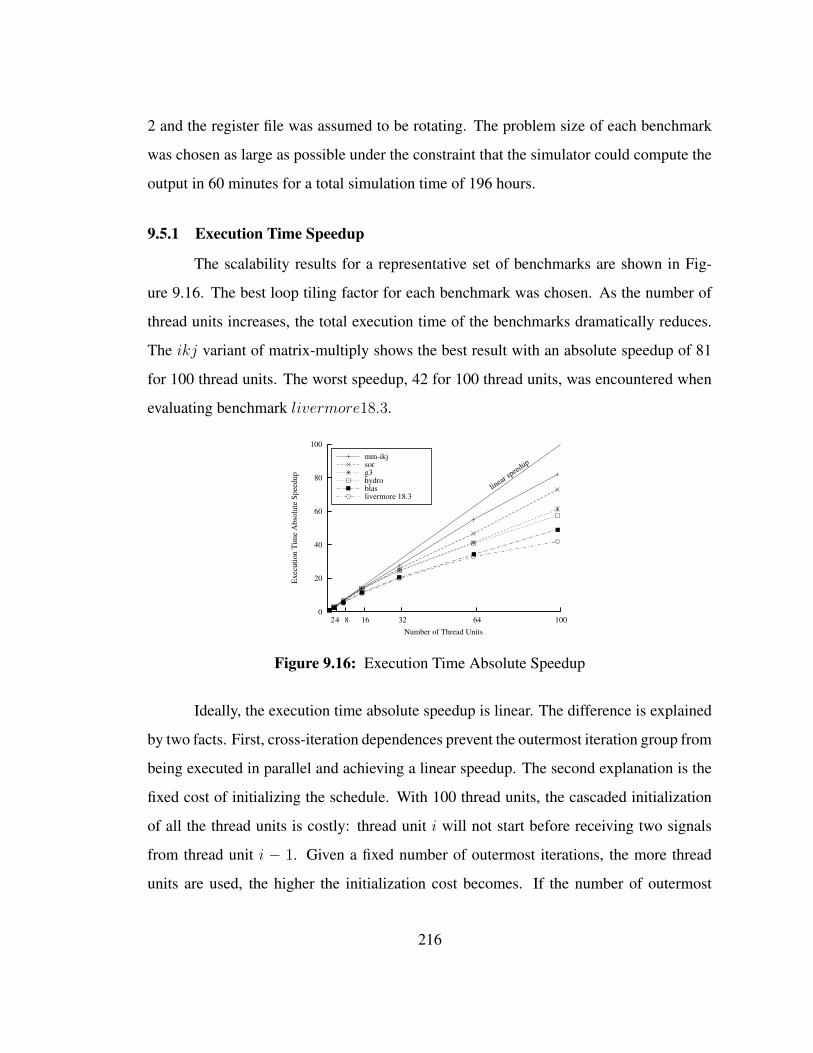




































![Pipelining & Parallel Processing - ics.kaist.ac.krics.kaist.ac.kr/ee878_2018f/[EE878]3 Pipelining and Parallel Processing.pdf · Pipelining processing By using pipelining latches](https://static.documents.pub/doc/80x56/5d40e26d88c99391748d47fb/pipelining-parallel-processing-icskaistackricskaistackree8782018fee8783.jpg)


