44
A diagnostic plot for assessing model fit in count data models Jochen Einbeck 1 Paul Wilson 2 1 Durham University 2 University of Wolverhampton Rennes, 5th July 2016

A diagnostic plot for assessing model fit in countdata models
Jochen Einbeck1 Paul Wilson2
1Durham University
2University of Wolverhampton
Rennes, 5th July 2016

Introduction
I Given: univariate count data y1, . . . , yn.
I Is it plausible to assume that y1, . . . , yn are generated from agiven (hypothesized) count distribution F?
I Specifically, denote F = F (µi , θi ), with both µi = E (Yi |xi )and θi (possibly) depending on covariates xi .
I Assume that a routine to obtain estimates µi = E (Yi |xi ) andθi is readily available.
I Denote N(k), for k = 0, 1, 2, . . ., the number of observedcounts k in y1, . . . , yn.
I Idea: check whether, for each count k = 0, 1, 2, . . ., thenumber N(k) is ‘plausible’ under the distribution F (µi , θi ).

Introduction
I Given: univariate count data y1, . . . , yn.
I Is it plausible to assume that y1, . . . , yn are generated from agiven (hypothesized) count distribution F?
I Specifically, denote F = F (µi , θi ), with both µi = E (Yi |xi )and θi (possibly) depending on covariates xi .
I Assume that a routine to obtain estimates µi = E (Yi |xi ) andθi is readily available.
I Denote N(k), for k = 0, 1, 2, . . ., the number of observedcounts k in y1, . . . , yn.
I Idea: check whether, for each count k = 0, 1, 2, . . ., thenumber N(k) is ‘plausible’ under the distribution F (µi , θi ).

Introduction
I Given: univariate count data y1, . . . , yn.
I Is it plausible to assume that y1, . . . , yn are generated from agiven (hypothesized) count distribution F?
I Specifically, denote F = F (µi , θi ), with both µi = E (Yi |xi )and θi (possibly) depending on covariates xi .
I Assume that a routine to obtain estimates µi = E (Yi |xi ) andθi is readily available.
I Denote N(k), for k = 0, 1, 2, . . ., the number of observedcounts k in y1, . . . , yn.
I Idea: check whether, for each count k = 0, 1, 2, . . ., thenumber N(k) is ‘plausible’ under the distribution F (µi , θi ).

Poisson-Binomial distribution
I The random variable N(k) follows a Poisson–Binomialdistribution with parameters p1(k), . . . , pn(k), where
pi (k) = P(k |µi , θi )
is the probability of observing the count k under covariate xiand model F (Chen and Liu, 1997).
I The pi (k) can be estimated by pi (k) = P(k |µi , θi ) from thefitted model.
I For instance, in the special case that F (µi , θi ) corresponds toPois(µi ), one has pi (k) = exp(−µi )µ
ki /k!.
I This scenario was discussed in the previous talk with focus onthe case k = 0.
I This talk generalizes those ideas to general k and F andproposes a generic diagrammatic tool.

Poisson-Binomial distribution
I The random variable N(k) follows a Poisson–Binomialdistribution with parameters p1(k), . . . , pn(k), where
pi (k) = P(k |µi , θi )
is the probability of observing the count k under covariate xiand model F (Chen and Liu, 1997).
I The pi (k) can be estimated by pi (k) = P(k |µi , θi ) from thefitted model.
I For instance, in the special case that F (µi , θi ) corresponds toPois(µi ), one has pi (k) = exp(−µi )µ
ki /k!.
I This scenario was discussed in the previous talk with focus onthe case k = 0.
I This talk generalizes those ideas to general k and F andproposes a generic diagrammatic tool.

Plausibility intervals for N(k)
I Knowing the distribution of N(k), one can derive intervals ofplausible values of N(k) by considering appropriate quantilesfrom this distribution.
I For fixed k , appropriate lower and upper quantiles, sayqα/2(k) and q1−α/2(k) of the Poisson–Binomial distributioncan be computed using the R package poibin (Hong, 2013).
I Do this for a range of values of k, and plot intervals(qα/2(k), q1−α/2(k)) alongside observed values N(k) as afunction of k .

Example: simulated data
I n = 100 observations y1, . . . , yn simulated from aZero–inflated Poisson (ZIP) distribution with Poissonparameter µ = 1.5 and zero–inflation parameter p = 0.2
k N(k)
0 381 282 153 74 85 16 27 1
0 1 2 3 4 5 6 7
010
2030
40
data value (k)
N(k
)

Example: simulated data
I n = 100 observations y1, . . . , yn simulated from aZero–inflated Poisson (ZIP) distribution with Poissonparameter µ = 1.5 and zero–inflation parameter p = 0.2
I Consider F (µ) ∼ Pois(µ) with µ = y .
k N(k) q0.05(k) q0.95(k)
0 38 19 331 28 27 432 15 17 313 7 6 164 8 1 75 1 0 36 2 0 17 1 0 0
0 1 2 3 4 5 6 7
010
2030
40
data value (k)
N(k
)

Median-adjustmentI The previous graph can be difficult to read if the sample size
is large, and so the bounds get very tight.I We therefore adjust it by subtracting the medians
M(k) = med(N(k)) from all values, where the median istaken wrt to the Poisson-Binomial distribution of N(k).
0 1 2 3 4 5 6 7
010
2030
40
data value (k)
N(k
)

Median-adjustment
I The previous graph can be difficult to read if the sample sizeis large, and so the bounds get very tight.
I We therefore adjust it by subtracting the mediansM(k) = med(N(k)) from all values, where the median istaken wrt to the Poisson-Binomial distribution of N(k).
k N(k) M(k) N(k)–M(k) q0.05(k)–M(k) q0.95(k)– M(k)
0 38 26 12 -7 71 28 35 -7 -8 82 15 24 -9 -7 73 7 10 -3 -4 64 8 3 5 -2 45 1 1 0 -1 26 2 0 2 0 17 1 0 1 0 0

Median–adjusted bounds
I Diagnostic plot for the accuracy of the Poisson assumption.
0 1 2 3 4 5 6 7
−5
05
10
data value (k)
N(k
)−M
(k)

Median–adjusted bounds: Variant
I Exchange horizontal and vertical axis:
−5 0 5 10
01
23
45
67
N(k)−M(k)
data
val
ue (
k)
I ‘Christmas tree diagram’.
I Adequate models have the ‘decoration’ inside the tree.

Median–adjusted bounds: Variant
I Exchange horizontal and vertical axis:
−5 0 5 10
01
23
45
67
N(k)−M(k)
data
val
ue (
k)
I ‘Christmas tree diagram’.
I Adequate models have the ‘decoration’ inside the tree.

Median–adjusted bounds: Variant
I Exchange horizontal and vertical axis:
−5 0 5 10
01
23
45
67
N(k)−M(k)
data
val
ue (
k)
I ‘Christmas tree diagram’.
I Adequate models have the ‘decoration’ inside the tree.

Example: Biodosimetry data
I Frequency of dicentric chromosomes in human lymphocytesafter in vitro exposure to doses between 1 and 5Gy of 200kVX–rays. The irradiated blood was mixed with non–irradiatedblood in a proportion 1:3 in order to mirror a partial bodyexposure scenario.
Frequency of countsdose 0 1 2 3 4 5 6 7 8
1 2713 78 8 0 1 0 0 0 02 1302 71 22 5 0 0 0 0 03 1116 46 28 7 2 1 0 0 04 929 18 14 22 13 2 0 1 15 726 17 18 12 9 13 1 4 0

Modelling of biodosimetry data
I These are n = 7200 observations of the type (dosei , yi ), withyi being a count in 0, . . . , 8.
I X–rays are sparsely ionizing — the literature suggests aquadratic dose model in this case.
I Link function:I Cytogenists prefer identity link.I Being among Statisticians, I will use the log link.
I Response (count) distribution:I It is widely accepted that the number of dicentrics in irradiated
blood samples is Poisson distributed.I However, under a partial body exposure scenario, we would
expect a deviation from the Poisson assumption, towardszero–inflation.
I Consider the initial model yi |dosei ≈ Pois(µi ) with
µi ≡ E (yi |dosei ) = exp(β0 + β1dosei + β2dose2i
)

Modelling of biodosimetry data
I These are n = 7200 observations of the type (dosei , yi ), withyi being a count in 0, . . . , 8.
I X–rays are sparsely ionizing — the literature suggests aquadratic dose model in this case.
I Link function:I Cytogenists prefer identity link.I Being among Statisticians, I will use the log link.
I Response (count) distribution:I It is widely accepted that the number of dicentrics in irradiated
blood samples is Poisson distributed.I However, under a partial body exposure scenario, we would
expect a deviation from the Poisson assumption, towardszero–inflation.
I Consider the initial model yi |dosei ≈ Pois(µi ) with
µi ≡ E (yi |dosei ) = exp(β0 + β1dosei + β2dose2i
)

Modelling of biodosimetry data
I These are n = 7200 observations of the type (dosei , yi ), withyi being a count in 0, . . . , 8.
I X–rays are sparsely ionizing — the literature suggests aquadratic dose model in this case.
I Link function:I Cytogenists prefer identity link.I Being among Statisticians, I will use the log link.
I Response (count) distribution:I It is widely accepted that the number of dicentrics in irradiated
blood samples is Poisson distributed.I However, under a partial body exposure scenario, we would
expect a deviation from the Poisson assumption, towardszero–inflation.
I Consider the initial model yi |dosei ≈ Pois(µi ) with
µi ≡ E (yi |dosei ) = exp(β0 + β1dosei + β2dose2i
)

Modelling of biodosimetry data
I These are n = 7200 observations of the type (dosei , yi ), withyi being a count in 0, . . . , 8.
I X–rays are sparsely ionizing — the literature suggests aquadratic dose model in this case.
I Link function:I Cytogenists prefer identity link.I Being among Statisticians, I will use the log link.
I Response (count) distribution:I It is widely accepted that the number of dicentrics in irradiated
blood samples is Poisson distributed.I However, under a partial body exposure scenario, we would
expect a deviation from the Poisson assumption, towardszero–inflation.
I Consider the initial model yi |dosei ≈ Pois(µi ) with
µi ≡ E (yi |dosei ) = exp(β0 + β1dosei + β2dose2i
)
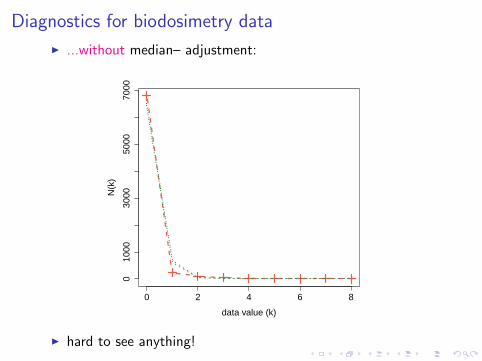
Diagnostics for biodosimetry data
I ...without median– adjustment:
0 2 4 6 8
010
0030
0050
0070
00
data value (k)
N(k
)
I hard to see anything!

Diagnostics for biodosimetry data
I ...with median– adjustment:
0 2 4 6 8
−40
0−
200
020
0
data value (k)
N(k
)−M
(k)
I much better!

Christmas tree diagram: Poisson hypothesis
−400 −200 0 200
02
46
8
N(k)−M(k)
data
val
ue (
k)
I We clearly observe zero–inflation (and associated 1–deflation);

Christmas tree diagram: Poisson hypothesis
−400 −200 0 200
02
46
8
N(k)−M(k)
data
val
ue (
k)
I We clearly observe zero–inflation (and associated 1–deflation);

Christmas tree diagram: Poisson hypothesis
−400 −200 0 200
02
46
8
N(k)−M(k)
data
val
ue (
k)
I We clearly observe zero–inflation (and associated 1–deflation);
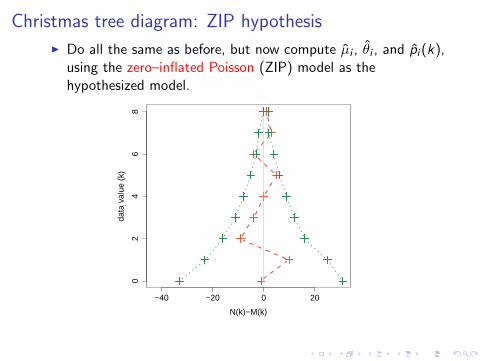
Christmas tree diagram: ZIP hypothesis
I Do all the same as before, but now compute µi , θi , and pi (k),using the zero–inflated Poisson (ZIP) model as thehypothesized model.
−40 −20 0 20
02
46
8
N(k)−M(k)
data
val
ue (
k)
I indicates a good fit.

Christmas tree diagram: ZIP hypothesis
I Do all the same as before, but now compute µi , θi , and pi (k),using the zero–inflated Poisson (ZIP) model as thehypothesized model.
−40 −20 0 20
02
46
8
N(k)−M(k)
data
val
ue (
k)
I indicates a good fit.

Christmas tree diagram: NB hypothesis
I Repeat the procedure using the negative Binomial model asthe hypothesized model.
−40 −20 0 20
02
46
8
N(k)−M(k)
data
val
ue (
k)
I indicates that the NB model does not capture the data well.

Christmas tree diagram: NB hypothesis
I Repeat the procedure using the negative Binomial model asthe hypothesized model.
−40 −20 0 20
02
46
8
N(k)−M(k)
data
val
ue (
k)
I indicates that the NB model does not capture the data well.

Christmas tree diagram: PIG hypothesis
I Repeat the procedure using the Poisson inverse Gaussian(PIG) model as the hypothesized model.
−80 −60 −40 −20 0 20
02
46
8
N(k)−M(k)
data
val
ue (
k)
I the PIG model does not capture the data well either.

Christmas tree diagram: PIG hypothesis
I Repeat the procedure using the Poisson inverse Gaussian(PIG) model as the hypothesized model.
−80 −60 −40 −20 0 20
02
46
8
N(k)−M(k)
data
val
ue (
k)
I the PIG model does not capture the data well either.

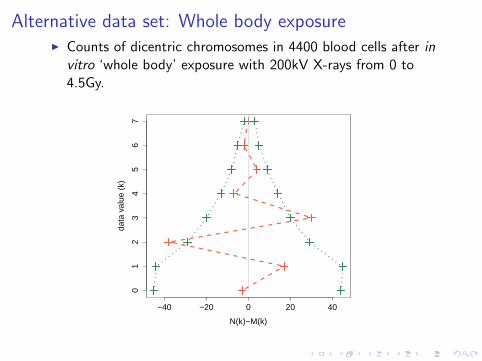
Alternative data set: Whole body exposureI Counts of dicentric chromosomes in 4400 blood cells after in
vitro ‘whole body’ exposure with 200kV X-rays from 0 to4.5Gy.
−40 −20 0 20 40
01
23
45
67
N(k)−M(k)
data
val
ue (
k)
I indicates that Poisson model is fairly reasonable.
Alternative data set: Whole body exposureI Counts of dicentric chromosomes in 4400 blood cells after in
vitro ‘whole body’ exposure with 200kV X-rays from 0 to4.5Gy.
−40 −20 0 20 40
01
23
45
67
N(k)−M(k)
data
val
ue (
k)
I indicates that Poisson model is fairly reasonable.

Alternative data set: Whole body exposureI Counts of dicentric chromosomes in 4400 blood cells after in
vitro ‘whole body’ exposure with 200kV X-rays from 0 to4.5Gy.
−40 −20 0 20 40
01
23
45
67
N(k)−M(k)
data
val
ue (
k)
I indicates that Poisson model is fairly reasonable.

Multiple testing ?
I If considered as a series of statistical tests over countsk = 0, 1, 2, ..., one can argue that multiple testing issues arise.
I For instance, if the tree covers ten possible counts, at asignificance level of 0.1 one would expect one piece ofdecoration to fall outside the tree purely by chance.
I One could adjust this through a Bonferroni correction etc.
I However, we do believe that the corresponding inflatedboundaries would be rather meaningless.
I Hence, we do not make such a correction, but explicitly donot advocate this procedure as a testing procedure.
I It should rather be seen as a diagnostic device, similar as aresidual plot or a QQ-plot.
I That is, exceeding the boundary limits once or twice shouldnot necessarily be interpreted as rejection of the hypothesizedcount distribution, as long as the ‘decoration’ is reasonablyconsistent with the tree.

Multiple testing ?
I If considered as a series of statistical tests over countsk = 0, 1, 2, ..., one can argue that multiple testing issues arise.
I For instance, if the tree covers ten possible counts, at asignificance level of 0.1 one would expect one piece ofdecoration to fall outside the tree purely by chance.
I One could adjust this through a Bonferroni correction etc.
I However, we do believe that the corresponding inflatedboundaries would be rather meaningless.
I Hence, we do not make such a correction, but explicitly donot advocate this procedure as a testing procedure.
I It should rather be seen as a diagnostic device, similar as aresidual plot or a QQ-plot.
I That is, exceeding the boundary limits once or twice shouldnot necessarily be interpreted as rejection of the hypothesizedcount distribution, as long as the ‘decoration’ is reasonablyconsistent with the tree.

Multiple testing ?
I If considered as a series of statistical tests over countsk = 0, 1, 2, ..., one can argue that multiple testing issues arise.
I For instance, if the tree covers ten possible counts, at asignificance level of 0.1 one would expect one piece ofdecoration to fall outside the tree purely by chance.
I One could adjust this through a Bonferroni correction etc.
I However, we do believe that the corresponding inflatedboundaries would be rather meaningless.
I Hence, we do not make such a correction, but explicitly donot advocate this procedure as a testing procedure.
I It should rather be seen as a diagnostic device, similar as aresidual plot or a QQ-plot.
I That is, exceeding the boundary limits once or twice shouldnot necessarily be interpreted as rejection of the hypothesizedcount distribution, as long as the ‘decoration’ is reasonablyconsistent with the tree.

Multiple testing ?
I If considered as a series of statistical tests over countsk = 0, 1, 2, ..., one can argue that multiple testing issues arise.
I For instance, if the tree covers ten possible counts, at asignificance level of 0.1 one would expect one piece ofdecoration to fall outside the tree purely by chance.
I One could adjust this through a Bonferroni correction etc.
I However, we do believe that the corresponding inflatedboundaries would be rather meaningless.
I Hence, we do not make such a correction, but explicitly donot advocate this procedure as a testing procedure.
I It should rather be seen as a diagnostic device, similar as aresidual plot or a QQ-plot.
I That is, exceeding the boundary limits once or twice shouldnot necessarily be interpreted as rejection of the hypothesizedcount distribution, as long as the ‘decoration’ is reasonablyconsistent with the tree.

Comparison with score testsI Alternatively, one can carry out traditional score tests.I For instance, consider H0: Poisson versus H1: ZIP or H1: NB.I Score test statistic T = ST J−1S , where S and J are the score
function and Fisher Information matrix (resp.) evaluatedunder the Poisson model. Asymptotically, T ∼ χ2(1).
I Resulting values of T , to be compared with χ21,0.95 = 3.84
(Oliveira et al, 2016):
Test Body exposure
Partial WholePois/ZIP 1996.30 1.00Pois/NB 6009.35 0.90
I Confirms that Poisson is adequate for whole body exposurebut inadequate for partial body exposure.
I ...but the score test does not tells us whether it’s at all thezero’s which cause the problem, nor whether the data arezero–inflated or –deflated!

Comparison with score testsI Alternatively, one can carry out traditional score tests.I For instance, consider H0: Poisson versus H1: ZIP or H1: NB.I Score test statistic T = ST J−1S , where S and J are the score
function and Fisher Information matrix (resp.) evaluatedunder the Poisson model. Asymptotically, T ∼ χ2(1).
I Resulting values of T , to be compared with χ21,0.95 = 3.84
(Oliveira et al, 2016):
Test Body exposure
Partial WholePois/ZIP 1996.30 1.00Pois/NB 6009.35 0.90
I Confirms that Poisson is adequate for whole body exposurebut inadequate for partial body exposure.
I ...but the score test does not tells us whether it’s at all thezero’s which cause the problem, nor whether the data arezero–inflated or –deflated!

Conclusion
I We have provided a simple diagrammatic tool to assess theadequacy of any given count data model.
I Essentially, it is verified whether the frequency, N(k), of eachcount, k, is plausible given the hyptothesized model.
I Can be used for with or without covariates.
I Only requires computation of fitted values, and the resultingplausibility intervals via the Poisson–Binomial distribution.
I Estimation of model parameters when the model is inadequatecan possibly be tricky!
I For the work carried out in this talk, all parameters have beenestimated under the hypothesized model.
I In the special case of checking whether the number of 0’s isconsistent with a Poisson distribution, an improved meanestimator µi has been proposed in the previous talk.
I More work required for the more general case of an arbitrarycount/distribution.
I Be aware of multiple testing: It is a diagram, not a test.

Conclusion
I We have provided a simple diagrammatic tool to assess theadequacy of any given count data model.
I Essentially, it is verified whether the frequency, N(k), of eachcount, k, is plausible given the hyptothesized model.
I Can be used for with or without covariates.
I Only requires computation of fitted values, and the resultingplausibility intervals via the Poisson–Binomial distribution.
I Estimation of model parameters when the model is inadequatecan possibly be tricky!
I For the work carried out in this talk, all parameters have beenestimated under the hypothesized model.
I In the special case of checking whether the number of 0’s isconsistent with a Poisson distribution, an improved meanestimator µi has been proposed in the previous talk.
I More work required for the more general case of an arbitrarycount/distribution.
I Be aware of multiple testing: It is a diagram, not a test.

Conclusion
I We have provided a simple diagrammatic tool to assess theadequacy of any given count data model.
I Essentially, it is verified whether the frequency, N(k), of eachcount, k, is plausible given the hyptothesized model.
I Can be used for with or without covariates.
I Only requires computation of fitted values, and the resultingplausibility intervals via the Poisson–Binomial distribution.
I Estimation of model parameters when the model is inadequatecan possibly be tricky!
I For the work carried out in this talk, all parameters have beenestimated under the hypothesized model.
I In the special case of checking whether the number of 0’s isconsistent with a Poisson distribution, an improved meanestimator µi has been proposed in the previous talk.
I More work required for the more general case of an arbitrarycount/distribution.
I Be aware of multiple testing: It is a diagram, not a test.

References
Chen, S.X. and Liu, J.S. (1997). Statistical applications of thePoisson-binomial and conditional Bernoullidistributions. Statistica Sinica 7, 875–892.
Hong, Y. (2013). poibin: The Poisson Binomial Distribution.R package version 1.2.https://CRAN.R-project.org/package=poibin
Oliveira, M. et al. (2016). Zero-inflated regression models forradiation–induced chromosome aberration data: Acomparative study. Biometrical Journal 58, 259–279.
Wilson, P. and Einbeck, J. (2015). A simple and intuitive test fornumber–inflation or number–deflation. In: Wagner,H. and Friedl, H. (Eds). Proc’s of the 30th IWSM,Linz, Austria, Vol 2, pages 299–302.

















