A Framework For Tuning Posterior Entropy. Rajhans Samdani Joint work with Ming-Wei Chang ( Microsoft Research ) and Dan Roth University of Illinois at Urbana-Champaign. Workshop on Inferning , ICML 2012, Edinburgh. Inference: Predicting Structures. - PowerPoint PPT Presentation
A Framework For Tuning Posterior Entropy Rajhans Samdani Joint work with Ming-Wei Chang (Microsoft Research) and Dan Roth University of Illinois at Urbana-Champaign Page 1 Workshop on Inferning, ICML 2012, Edinburgh
Transcript
A Framework For Tuning Posterior Entropy
Rajhans SamdaniJoint work with
Ming-Wei Chang (Microsoft Research) and Dan Roth
University of Illinois at Urbana-Champaign
Page 1
Workshop on Inferning,ICML 2012,Edinburgh
Inference: Predicting Structures
Predict the output variable y from the space of allowed outputs Y given input variable x using parameters or weight vector w
E.g. predict POS tags given a sentence, predict word alignments given sentences in two different languages, predict the entity-relation structure from a document
Prediction expressed as y* = argmaxy 2 Y P (y | x; w)
Page 2
Learning: Weakly Supervised Learning
Labeled data is scarce and difficult to obtain
A lot of work on learning with a small amount of labeled data
Expectation Maximization (EM) algorithm is the de facto standard
More recently: significant work on injecting weak supervision or domain knowledge via constraints into EM Constraint-driven Learning (CoDL; Chang et al, 07) Posterior regularization (PR; Ganchev et al, 10)
Page 3
Learning Using EM: a Quick Primer
Given unlabeled data: x, estimate w; hidden: y for t = 1 … T do
E-step: infer a posterior distribution, q, over y:
M:step: estimate the parameters w w.r.t. q:
wt+1 = argmaxw Eq log P (x, y; w)
Page 4
qt(y) = P (y|x;wt) qt(y) = argminq KL( q(y) , P
(y|
x;wt) ) (Neal and Hinton,
99)
Conditional distribution of
y given wPosterior distributionE-step is an inference step, and
M-step learns w.r.t. the distribution inferred
Different EM Variations
Hard EM changes the E-step of the EM algorithm
Which version to use: EM (PR) vs hard EM (CoDL) (Spitkovsky
et al, 10) (Pedro’s talk) ? Or is there something better out there?
OUR CONTRIBUTION: a unified framework for EM algorithms, Unified EM (UEM) (Samdani et al, 12) A framework which explicitly provides a handle on the entropy of
the inferred distribution during the E-step Includes existing EM algorithms Pick the most suitable EM algorithm in a simple, adaptive, and
principled way
Page 5
Outline
Background: Expectation Maximization (EM)
Unified Expectation Maximization (UEM) Motivation Formulation and mathematical intuition
Experiments
Page 6
EM/Posterior Regularization (Ganchev et al, 10)
E-step:argminq KL(qt(y),P
(y|
x;wt))
M-step: argmaxw Eq log P (x, y; w)
Hard EM/Constraint driven-learning (Chang et al, 07)
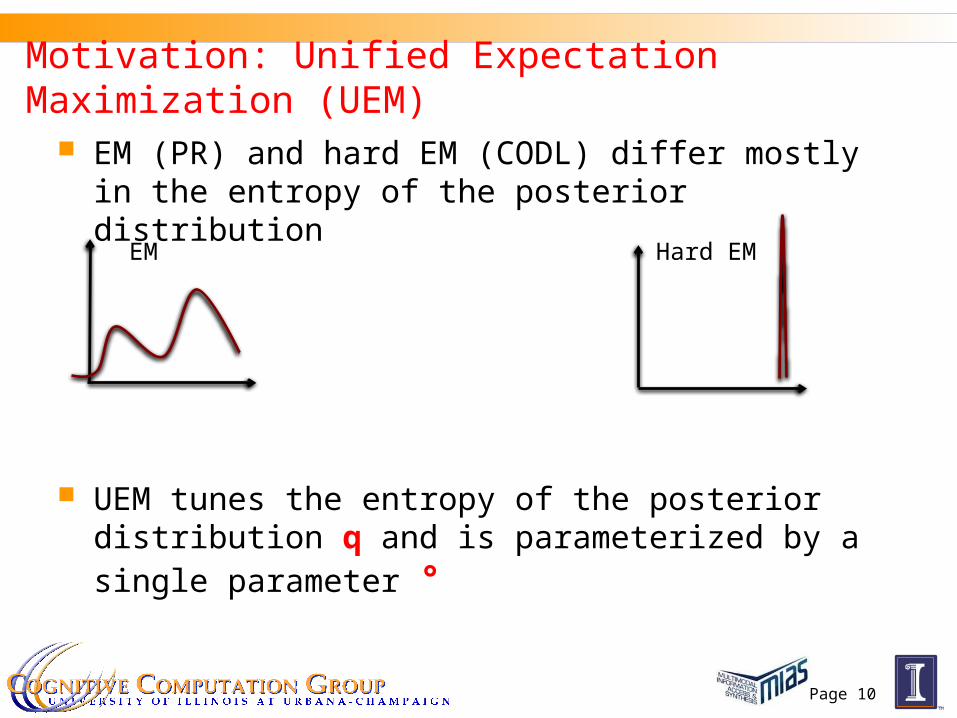
EM (PR) and hard EM (CODL) differ mostly in the entropy of the posterior distribution
UEM tunes the entropy of the posterior distribution q and is parameterized by a single parameter °
Page 10
EM Hard EM
EM (PR) minimizes the KL-Divergence KL(q , P (y|x;w)) KL(q , p) = y q(y) log q(y) – q(y) log p(y)
UEM changes the E-step of standard EM and minimizes a modified KL divergence KL(q , P (y|x;w); °) where
KL(q , p; °) = y ° q(y) log q(y) – q(y) log p(y)
Different ° values ! different EM algorithms
Changes the entropy of the posterior
Unified EM (UEM)
Page 11
Effect of Changing °
Original Distribution p
q with ° = 1
q with ° = 0
q with ° = 1
q with ° = -1
Page 12
KL(q , p; °) = y ° q(y) log q(y) – q(y) log p(y)
Unifying Existing EM Algorithms
Page 13
No Constraints
With Constraints
KL(q , p; °) = y ° q(y) log q(y) – q(y) log p(y)
° 1 0 -1 1
Hard EM
CODL
EM
PR
Deterministic Annealing (Smith and Eisner, 04; Hofmann, 99)
Changing ° essentially changes the “hardness of inference”
Outline
Setting up the problem
Introduction to Unified Expectation Maximization
Experiments POS tagging Entity-Relation Extraction Word Alignment
Page 15
Experiments: exploring the role of °
Test if changing the inference step by tuning ° helps improve the performance over baselines
Compare against: Posterior Regularization (PR) corresponds to ° = 1.0 Constraint-driven Learning (CODL) corresponds to ° = -1
Study the relation between the quality of initialization and ° (or “hardness” of inference)
Page 16
Unsupervised POS Tagging
Model as first order HMM
Try varying qualities of initialization: Uniform initialization: initialize with equal probability for all states Supervised initialization: initialize with parameters trained on varying
amounts of labeled data
Test the “conventional wisdom” that hard EM does well with good initialization and EM does better with a weak initialization
Page 17
Unsupervised POS tagging: Different EM instantiations
Uniform Initialization
Initialization with 5 examples
Initialization with 10 examples
Initialization with 20 examples
Initialization with 40-80 examples
°
Perf
orm
ance
rela
tive
to E
MHard EMEM
Page 18
Experiments: Entity-Relation Extraction
Extract entity types (e.g. Loc, Org, Per) and relation types (e.g. Lives-in, Org-based-in, Killed) between pairs of entities
Add constraints: Type constraints between entity and relations Expected count constraints to regularize the counts of ‘None’ relation
Semi-supervised learning with a small amount of labeled data
Page 19
Dole ’s wife, Elizabeth , is a resident of N.C.
E1 E2 E3 R12 R2
3
Result on Relations
5% 10% 20%0.3
0.32
0.34
0.36
0.38
0.4
0.42
0.44
0.46
0.48
No semi-sup
CODL
PR
UEM
Page 20
% of labeled data
Ma
cro
-f1
sco
res
UEM Statistically significantly better than PR
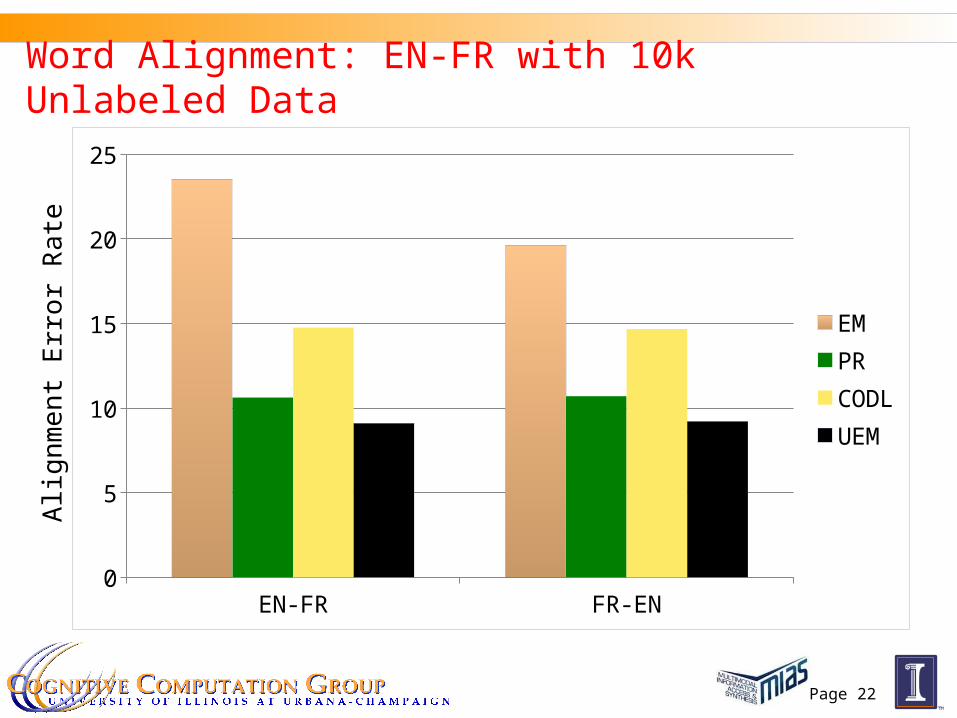
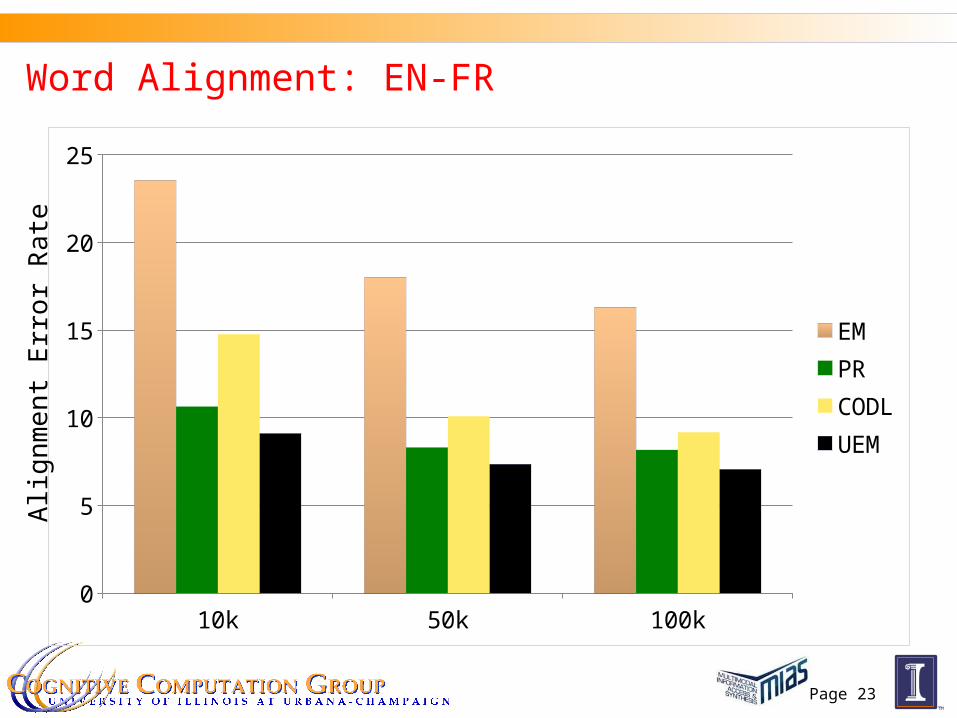
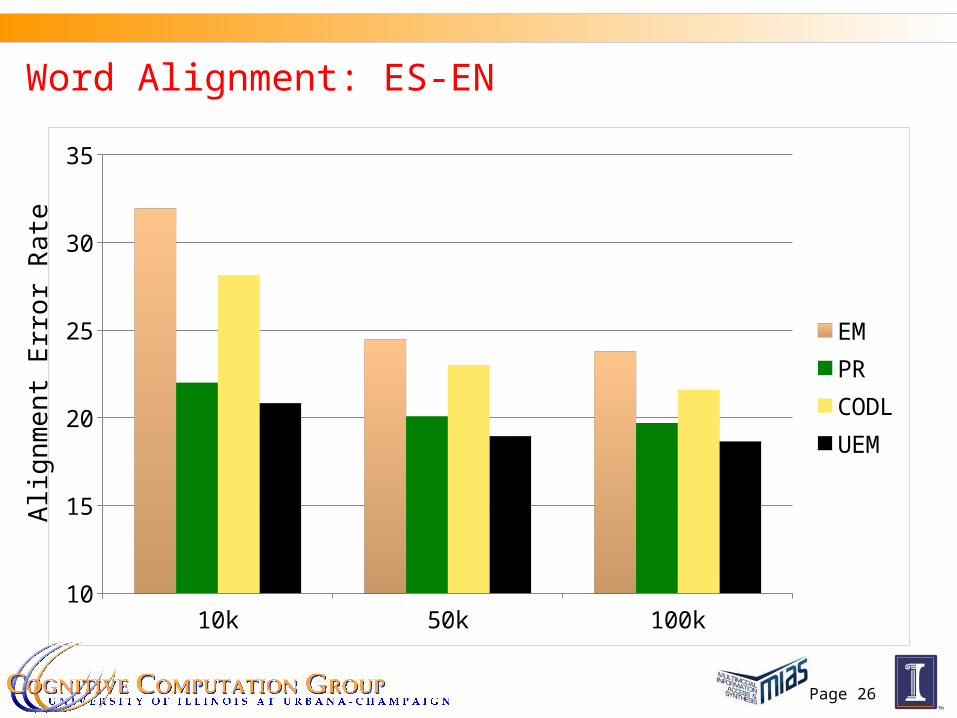
Experiments: Word Alignment
Word alignment from a language S to language T We try En-Fr and En-Es pairs We use an HMM-based model with agreement constraints for
word alignment PR with agreement constraints known to give HUGE
improvements over HMM (Ganchev et al’08; Graca et al’08) Use our efficient algorithm to decomposes the E-step into
individual HMMs
Page 21
Word Alignment: EN-FR with 10k Unlabeled Data
EN-FR FR-EN0
5
10
15
20
25
EMPRCODLUEM
Page 22
Alig
nm
ent
Err
or
Rat
e
Word Alignment: EN-FR
10k 50k 100k0
5
10
15
20
25
EMPRCODLUEM
Page 23
Alig
nm
ent
Err
or
Rat
e
Word Alignment: FR-EN
10k 50k 100k0
5
10
15
20
25
EMPRCODLUEM
Page 24
Alig
nm
ent
Err
or
Rat
e
Word Alignment: EN-ES
10k 50k 100k10
15
20
25
30
35
40
EMPRCODLUEM
Page 25
Alig
nm
ent
Err
or
Rat
e
Word Alignment: ES-EN
10k 50k 100k10
15
20
25
30
35
EMPRCODLUEM
Page 26
Alig
nm
ent
Err
or
Rat
e
Experiments Summary
In different settings, different baselines work better Entity-Relation extraction: CODL does better than PR Word Alignment: PR does better than CODL Unsupervised POS tagging: depends on the initialization
UEM allows us to choose the best algorithm in all of these cases Best version of EM: a new version with 0 < ° < 1
Page 27
Unified EM: Summary
UEM: a unified framework for EM algorithms which tunes the entropy of the posterior by a single parameter ° ° : adaptively changes the entropy of the posterior based on the data,
initialization, and constraints Experimentally: the best ° corresponds to neither EM (PR) nor
hard EM (CODL) and found through the UEM framework Shows the role of inference in learning: learned parameters
seem to be sensitive to entropy of the inferred posterior
Open question: What is actually going on? How is the entropy of the E-step actually changing the learnt model?