Journal of Econometrics 13 (1980) 67-82. 0 North-Holland Publishing Company A MONTE CARLO STUDY OF ESTIMATORS OF STOCHASTIC FRONTIER PRODUCTION FUNCTIONS Jerome A. OLSON Research Triangle Institute, NC, USA Peter SCHMIDT* Michigan State University, East Lansing, MI 48824, USA Donald M. WALDMAN University of North Carolina, Chapel Hill, NC 27514, USA 1. Introduction In recent papers which appeared almost simultaneously, Aigner, Love11 and Schmidt (ALS) (1977) and Meeusen and van den Broeck (1977) proposed a new error specification for frontier production function models. The specification is that the error term is the sum of two components ~ one normal with zero mean, and the other non-positive. ALS refer to a model with this error specification as a ‘stochastic frontier’, since the non-positive component of the disturbance represents the shortfall of actual output from the frontier, while the frontier contains the normal component of the disturbance, and is therefore stochastic. This specification avoids the serious statistical difficulties [discussed by Schmidt (1976) and Greene (1980)] which are encountered in the estimation of full frontiers - that is, in the presence of a purely non-positive error term. Any number of one-sided distributions exist which could plausibly be assumed to represent the distribution of the shortfall of output from the frontier. ALS consider (negative) half-normal and exponential distributions, while Meeusen and van den Broeck consider exponential only. Other possibilities include Gamma [Richmond (1974)] and lognormal [Greene (1980)]. ALS find very little difference in the fit of half-normal and exponential, in two empirical applications. In this paper we will restrict our attention to the half-normal case, which is the case considered in most detail by ALS. *The second author is grateful to the National Science Foundation for its support of this research under grant SOC 78-12447.
Transcript
Journal of Econometrics 13 (1980) 67-82. 0 North-Holland Publishing Company
A MONTE CARLO STUDY OF ESTIMATORS OF STOCHASTIC FRONTIER PRODUCTION FUNCTIONS
Jerome A. OLSON
Research Triangle Institute, NC, USA
Peter SCHMIDT*
Michigan State University, East Lansing, MI 48824, USA
Donald M. WALDMAN
University of North Carolina, Chapel Hill, NC 27514, USA
1. Introduction
In recent papers which appeared almost simultaneously, Aigner, Love11 and Schmidt (ALS) (1977) and Meeusen and van den Broeck (1977) proposed a new error specification for frontier production function models.
The specification is that the error term is the sum of two components ~ one normal with zero mean, and the other non-positive. ALS refer to a model with this error specification as a ‘stochastic frontier’, since the non-positive component of the disturbance represents the shortfall of actual output from the frontier, while the frontier contains the normal component of the disturbance, and is therefore stochastic. This specification avoids the serious statistical difficulties [discussed by Schmidt (1976) and Greene (1980)] which
are encountered in the estimation of full frontiers - that is, in the presence of a purely non-positive error term.
Any number of one-sided distributions exist which could plausibly be assumed to represent the distribution of the shortfall of output from the frontier. ALS consider (negative) half-normal and exponential distributions, while Meeusen and van den Broeck consider exponential only. Other
possibilities include Gamma [Richmond (1974)] and lognormal [Greene (1980)]. ALS find very little difference in the fit of half-normal and exponential, in two empirical applications. In this paper we will restrict our attention to the half-normal case, which is the case considered in most detail by ALS.
*The second author is grateful to the National Science Foundation for its support of this research under grant SOC 78-12447.
68 /.A. Olson et al., Estimators of stochastic frontier production functions
Stochastic frontier production function models can be estimated in several ways. Maximum likelihood is one possibility, and is discussed both by ALS
and by Meeusen and van den Broeck. ALS also discuss a method ipvolving least squares, with a correction to the constant term based on manipulation
of the moments of the least squares residuals. A third possibility is a two-step NewtonRaphson process, starting from initial consistent estimates. These three procedures produce consistent estimates with tractable asymptotic distributions. However, little is known about the small sample properties of these estimators. ALS report a very limited Monte Carlo study of the maximum likelihood estimator, with somewhat pessimistic conclusions, but do not compare maximum likelihood to the other possible estimators.
In this paper we report the results of a more ambitious Monte Carlo
experiment designed to compare the estimators mentioned above. Our results are more optimistic than those of ALS as to the applicability of these
techniques in moderately-sized samples. We also find that the corrected least squares estimator does quite well, in most cases, and is thus a reasonable alternative to maximum likelihood.
The plan of the paper is as follows: Section 2 presents the estimator to be
considered. Section 3 describes the experimental design. Section 4 gives details of the computational conduct of the experiment. Section 5 reports the results of the experiment. Finally, section 6 contains our conclusions.
2. The estimators and their known properties
We consider a linear production function model in the usual matrix form
where 4’ and E are N x 1 vectors of observations on output and the random disturbance, respectively; X is an N x K matrix of observations on a constant term and K - 1 inputs; and fi is a K x 1 vector of parameters. (Our model might be, for example, a CobbPDouglas function in its loglinear form.) The
error specification is
E=v-u, (2)
where the elements of v are iid as N(O,az), while the elements of u are absolute values of variables which are iid as N(O,ai). (That is, the elements of u are iid as half-normal.) All v’s and U’S are independent of each other, and are also independent of X - for example, by the Zellner, Kmenta and Dreze (1966) assumption of expected profit maximization. Finally, a convenient reparameterization of the disturbance specification is
a2=o,Z+u,2, A = UJU” . (3)
The first estimator we consider is maximum likelihood, which we
to as MLE. ALS (1977) show that the log likelihood function is
where si = yi -Xip, Xi is the ith row of X, and F is the standard normal cdf. The maximum likelihood ,estimator is obtained by the (numerical) maximization of (4) with respect to the parameters @,/2,a). MLE is consistent and asymptotically efficient. Its finite sample distribution is unknown.
The second estimator we consider is a two-step NewtonRaphson (so- called ‘method of scoring’) estimator, which we will refer to as 2STEP. Let 0 =(/Y, 2, rr2)’ be the vector of parameters to be estimated, and 8 be any initial consistent estimator of 8. (One will be discussed shortly.) Then the 2STEP estimator is
(5)
where L is the log likelihood function given in (4). The necessary derivatives are given in ALS (1977). The 2STEP estimator is consistent and asymptotically efficient - that is, its asymptotic distribution is identical to MLE. [See, e.g. Dhrymes (1970) or Schmidt (1976) for a proof.] Its finite sample distribution is unknown.
The third estimator we consider is a corrected least squares estimator, which we will refer to as COLS, which was discussed briefly in ALS. This estimator is similar in spirit to the estimator suggested by Richmond (1974) in the context of a pure frontier. We begin with the OLS estimator /s = (X’X)) ‘X’y. Except for the constant term, the OLS estimator is unbiased and consistent; its covariance matrix is equal to az(X’X)- ‘, where 0: = variance of E. The bias of the constant term is the mean of E, p=
-&G,. We can estimate the variances 0,’ and cr,Z consistently by
I?2 C;;=fi;---$ 71 “3 (6)
where 8; and ,& are the second and third moments of the OLS residuals.’ We can then ‘correct’ the constant term by adding to the OLS estimated
constant term the negative of the estimated bias, -6,.
‘For a proof, see Waldman (1977, app.).
IO J.A. Olson et al., Estimators of stochastic frontier production functions
To recapitulate, the COLS estimator of all elements of /I except the constant term is the same as the OLS estimator. Estimates of cr,” and gt are derived from the second and third moments of the OLS residuals. The estimate of rrU is used to convert the OLS estimate of the constant term into the COLS estimate. These estimates are consistent, but not asymptotically efficient. Their asymptotic covariance matrix is derived in the appendix. The estimates of all elements of /I except for the constant term are unbiased; we know nothing about the finite-sample properties of the estimates of o:, rrs or
the constant term.
Because they are consistent, and easy to calculate, the COLS estimates can be used as the first-step (initial consistent) estimates in arriving at the 2STEP
estimates. One problem with the COLS estimator is that it may not exist (in a
meaningful form) in some samples. This happens in two ways. A ‘Type I’ failure occurs if the third moment of the OLS residuals is positive. In this case the implied gU is negative [see (6)]. The probability of this occurrence depends on the value of &, the third central moment of the disturbance
(which is always negative); when & is near zero, the probability of a Type I failure may be substantial. This is a problem mainly when J. is small. In particular as 1+0(0:-+0) the probability of a Type I failure approaches (approximately) l/2. On the other hand, a Type II failure occurs when c?z < ((rr-2)/~)~?~; this implies 6: <O. Type II failures occur with non-negligible
probability when /z is large.
In the case of a Type I failure, it is natural to set 6,’ = A = 0. This causes no problem with 2STEP. It is also true that, in every case of Type I failure we
encountered, the MLE estimate of i also turned out to equal zero. (This makes some sense, though we cannot prove analytically that it should
happen.) As a result, Type I failures are not a serious problem. However, Type II failures are more troublesome. When 8: <O it is natural to set G% =O. However, this implies f= w. The non-zero probability of A= x implies that (i) the COLS estimate of ,? has no moments, and (ii) the 2STEP estimator fails to exist (since I= m is not an allowable starting value), with some non- zero probability. There appeared to be no comparable problem with MLE.
One maximizes with respect to /z (among other parameters), and a finite maximizing value always appeared to exist.
3. Design of the experiment
A sample point for the experiment consists of the specification of a sample size N, a regressor matrix X, a coefficient vector /I, and any two of the following five parameters: (r,2, o,Z, cr2, 0,2, 1.. [Since o2 =cr,2+cr,2, 0: =(rc - 2)0,2/?7 + 05, and ,? =GJG~., only two of the last five parameters are independent.]
J.A. Olson et al., Estimators of stochastic frontier production functions 71
The question of which two of these five parameters should be considered is
essentially just one of ease of interpretation. However, the choice is not a trivial one, for the following reason. Suppose we parameterize with respect to crz and A. Then it turns out that comparisons among the various estimators
are independent of g%. Let us be precise about the sense in which this is so. Suppose we start with a particular parameter point (T,X,p, A), with 0: = 1,
say. We then generate empirical means, variances and mean square errors for the various estimates. Now suppose, however, that we had picked the same parameter point except with a:= 10 instead of (T$= 1. This would have the
effect of multiplying each random error (drawn from our random number generator, as described below) by JlO. This in turn has the following effects:
(i) The empirical bias of /? increases by JlO.
(ii) The empirical bias of 6,, e,‘, and c*, and the empirical variance and
mean square error of fl, increase by 10.
(iii) The empirical variance and mean square error of &,, r?;, and (i* increase
by 100.
(iv) The empirical bias, variance and mean square error of i is unaffected.
This is easily shown to be true for all of the estimation techniques
considered, given the form of the likelihood function and the definition of the COLS estimator. As a result, we can, without loss of generality, take 0: = 1 in all of our experiments. This choice will not affect any comparisons of the
estimators. Similar statements hold for p. If the value of p is changed, no empirical
biases, variances or mean squared errors are affected; only the mean of /3 changes. This means that we can, without loss of generality, simply take fl to be a vector of ones.
As a result, a sample point need only consist of a set (N, X,2). We will consider in most detail cases in which X contains only a constant term ~ a case also considered by ALS. In such cases a sample point consists only of the pair (N,A). This is a real advantage, since we can investigate this sample space in considerable detail.
Specifically, (N,A) points were picked in the following manner:
(i) To investigate the effect of sample size (N), we held 1. fixed at one and picked N = 25, 50, 100, 200, 400 and 800.
(ii) To investigate the effect of I, we held N fixed at 50 and picked i= lo-‘, lo-$, lo-*, lo-*, 1, lOa, lo*, lO$, 10 (i.e., 0.1, 0.178, 0.316, 0.562, 1, 1.778, 3.162, 5.623, 10).
12 J.A. Olson et al., Estimators ofstochustic frontier production functions
We also conducted a few experiments with non-constant explanatory variables. The first set of such experiments used an X matrix consisting of a constant term plus a regressor whose observations were iid N(0, 1) deviates
(generated by the random number generator). For sample sizes 50, 100, 200, and 400 only the first 50, 100, 200, and 400 observations (respectively) were used. Except for sampling error, the X’X matrix for each sample size is of course equal to sample size times I,. We tested the effect of sample size by
considering N =50, 100, 200, 400, and 800, with A fixed at 1; we then tested the effect of A by considering A= lo- ‘, lo-*, 1, lo*, 10 with N fixed at 50.
Our experiment with non-constant explanatory variables used actual agricultural data from Farrell (1957). The X matrix consists of observations (by state) on a constant term plus the logarithm of land, labor, materials and capital. This X matrix is characterized by a moderate degree of
multicollinearity. Sample size is 48, and we considered only /I = 1.
4. Conduct of the experiment
For each experiment (sample point), we are given a specification of N, X, p, and A. We can easily generate the non-stochastic part of y, X0.
For each observation we then generated the error E =u-u from the random number generator. The values of u were drawn from a N(O,cz) population, while the values of u were the absolute values of drawings from a N(O,a,‘) population. (ai and G: are the values implied by of = 1 and the particular choice of A.) In this manner we formed the vector e of disturbances, and the vector y= Xg te of observations on the dependent variable. The parameters of the model were then estimated, from y and X, by COLS, 2STEP, and MLE.
By repeating the above procedure m times, a random sample of size m is
obtained from the distributions of the estimators. The purpose of this experiment is to make inferences regarding the distributions of the estimators
based on these samples. In making these inferences, the usual methods of statistical inference may be invoked. For example, for any estimator 0, we estimate E(d) by the sample mean of 0. [The variance of this estimate of E(o) can also be estimated as S2/m, where S2 is the sample variance of 8.1 In the results reported below, m was 100, except for two experiments. In the N = 50, i. = 1 experiment, m = 200, and in the N = 800, A.= 1 experiment, m = 50.
The random deviates used were generated by the Tausworthe generator described by Whittlesey (1968). Documentation of the program used, and the tests performed on it, can be found in Triangle Universities Computation Center (1976). Random ‘seeds’ for initiating the random number generator were picked separately for each experiment from a random number table.
The numerical maximization of the likelihood function required for MLE was done using the DavidonFletcher-Powell (DFP) algorithm described in
J.A. Olson et al., Estimutors of stochastic frontier production,finctions 73
Powell (1971), using a program (the so-called Goldfeld-Quandt package)
supplied by the Princeton Econometric Research Program. The fact that the apparent properties of MLE depend on the care taken in numerical maximization cannot be overemphasized. Results were originally generated using a very exacting convergence criterion, and using the true parameter
points as starting values. These results were apparently plausible, but in fact they spuriously overstated the virtues of MLE. The reason is that premature stopping of the algorithm left MLE too close to the true parameter values.
How serious a problem this was depended on cf and 2. When the convergence criterion was made even tighter, and the maximizing program’s error returns (indicating algorithm failure) were monitored for every maximization, some fairly substantial changes occurred. First, the invariance
of all substantive results with respect to 02 became clear. (This invariance
was then verified analytically.) Second, the results were now invariant with respect to choice of starting values.2 As a result we now feel reasonably
confident that our MLE results are free from spurious randomness caused by inaccurate numerical maximization.
5. Results of the experiment
As mentioned in section 4, the results of the experiment are basically the
empirical moments (bias, variance and mean square error) of the estimates of the various parameters. In the case of the parameters of the error distribution (u~,D~,o~, ~~,1) we can report results for some or all of these,
though these live parameters really represent only two independent parameters.
At this point we should briefly recall the discussion of section 2 on what we call Type II failures of COLS. These occur when the COLS estimate 8: ~0, and are ‘fixed’ by setting c?: = 0. Since this implies A= ~3, 2STEP (using
COLS starting values) ‘blows up’. It seems likely that 2STEP estimates have no moments, and, indeed, the instability of the empirical moments which we calculated supports this conjecture. Indeed, 2STEP turns out to perform not very well even at parameter points for which no Type II failures occurred, or, at parameter points for which they occurred, even when the iterations on which they occurred are dropped. Only for the largest sample sizes (N 2 400)
are the 2STEP estimates even nearly a? good (in terms of MSE) as their COLS starting values. As a result, we will drop 2STEP from further consideration, and look only at COLS and MLE.
We begin our comparison of COLS and MLE by looking first at the effect of sample size in the constant term only model. Our results are given in table
‘The sense in which COLS is a ‘safe’ choice is as follows: Should the algorithm stop prematurely, despite our best efforts, this will at least not create a spurious difference in efficiency between MLE and COLS if COLS starting values are used.
14 J.A. Olson et al., Estimators of stochasticfrontier production,functions
1 for our sample points with N =25, 50, 100, 200, 400 and 800; in each case A=l.
Looking at table 1, several expected patterns are evident. For all parameters, and for both MLE and COLS, bias, variance and MSE fall with increasing sample size. This is certainly to be expected since both estimates are consistent. (The decrease in bias does not always show up at the smallest sample sizes, presumably due to randomness of the results, but it is clear at the larger sample sizes.)
The COLS estimator is more (MSE) efficient for sample size 200 and below. At sample sizes 400 and 800, the MLE is (MSE) efficient for estimating oi, CJ~ and cr2 but COLS is still superior for /?. These results can be taken as encouraging evidence that the computationally simple COLS estimator is a viable alternative to the MLE. The unavoidable presence of sampling error in Monte Carlo results makes it impossible to say with certainty that either estimator is (MSE) efficient. However, statistical tests for the inequality of the variance of the two estimators can be performed with
the result that under the usual assumptions required to justify the use of an F statistic, we cannot reject the null hypothesis that there is no difference in
variance between MLE and COLS parameter estimates for any parameter for any sample size over 25. We may interpret this result as suggesting that the difference in efficiency between the two methods is so small that it cannot be detected without a more powerful test (more repetitions).
Table 2 shows the comparison of the finite sample variances of the estimates, as determined by the Monte Carlo experiment, and their corresponding asymptotic variances. The asymptotic variance of COLS is derived in the Appendix, while the asymptotic variance of MLE is calculated from the inverse of the information matrix. (The information matrix is itself
estimated in the Monte Carlo experiment.) Two things in table 2 are worthy of comment. First, the asymptotic
variances of MLE and COLS are almost equal. This is in agreement with the fact that the Monte Carlo variances of MLE and COLS are almost equal for our larger sample sizes (N 2 400). However, a second thing to note in table 2
is that the asymptotic variances are not really very close to the corresponding Monte Carlo variances, even for our largest sample sizes.
Thus, for our larger sample sizes, the asymptotic results give a good indication of the relative sizes, but not the absolute sizes, of the MLE and
COLS variances. We next consider the effect of the variance ratio I on the COLSMLE
comparison. Our results are given in table 3 for our sample points with N =50 and with all nine values of i which we considered.
One thing that is immediately noticeable is the effect of ,J on the probability of COLS failures. Type I failures occur primarily with small 2, and Type II failures primarily with large /1. Another obvious fact is that the
Tab
le
1
Eff
ects
of
sam
ple
size
.
Sam
ple
size
Per
cen
tage
of
CO
LS
fa
ilu
res
I II
Con
stan
t te
rm
ML
E
CO
LS
z 0”
2
0”
rJ*
ML
E
CO
LS
M
LE
C
OL
S
ML
E
CO
LS
Bia
s
25
41
2 50
33
.5
0 10
0 27
0
200
23
0 40
0 14
0
800b
4
0
Var
ian
ce
25
50”
100
200
400
SO
@
MSE
25
50”
100
200
400
800b
-0.1
143
- 0.
2177
0.
3127
-0
.021
5 -0
.142
3 -0
.053
3 -0
.170
4 -
0.07
49
-0.1
522
-0.1
122
0.14
52
0.06
23
- 0.
0666
-0
.041
6 0.
0785
0.
0206
-0
.103
1 -0
.117
3 0.
0665
0.
0211
-0
.051
8 -
0.03
78
0.01
47
-0.0
167
-0.1
473
-0.1
500
- 0.
0728
-
0.09
23
0.02
37
0.02
95
- 0.
0506
0.
0627
-0
.081
1 -
0.07
86
- 0.
0390
-0
.038
3 0.
0139
0.
0137
-
0.02
51
- 0.
0246
-0
.026
1 -0
.019
2 -
0.00
65
0.00
56
-0.0
017
-0.0
061
- 0.
0082
-
0.00
04
0.39
40
0.26
37
1.74
15
0.64
70
0.17
13
0.12
28
1.11
00
0.43
87
0.24
29
0.21
47
0.76
50
0.59
29
0.10
72
0.09
40
0.41
17
0.32
25
0.16
15
0.14
60
0.48
09
0.39
07
0.06
14
0.05
27
0.26
94
0.22
68
0.14
26
0.13
36
0.34
52
0.30
96
0.04
72
0.04
27
0.17
07
0.15
58
0.08
99
0.08
76
0.21
20
0.21
96
0.02
65
0.02
69
0.10
06
0.10
48
0.03
36
0.03
25
0.07
64
0.07
92
0.01
13
0.01
19
0.03
50
0.03
57
0.40
71
0.31
11
1.83
93
0.64
75
0.19
16
0.12
57
1.13
91
0.44
43
0.25
55
0.23
28
0.78
62
0.59
68
0.11
16
0.09
59
0.41
80
0.32
31
0.17
21
0.15
97
0.48
53
0.39
11
0.06
41
0.05
42
0.26
96
0.22
7 1
0.16
43
0.15
61
0.35
07
0.31
81
0.04
78
0.04
36
0.17
33
0.15
97
0.09
65
0.09
38
0.21
36
0.22
11
0.02
67
0.02
71
0.10
12
0.10
54
0.03
43
0.03
28
0.07
64
0.07
92
0.01
13
0.01
20
0.03
5 1
0.03
57
“Bas
ed o
n 2
00 i
tera
tion
s.
bBas
ed o
n 5
0 it
erat
ion
s.
16 J.A. Olson et ul., Estimutors of stochastic frontier production functions
Table 2
Comparison of asymptotic and Monte Carlo variances (A = 1).
Parameter N
Asymptotic variance MonteCarlo variance
COLS MLE COLS MLE
50 0.389 0.299
Bo 400 0.049 0.049 800 0.024 0.025
50 0.804 0.692 02 400 0.100 0.102
800 0.050 0.052
50 1.560 1.081 1. 400 0.195 0.182
800 0.098 0.092
0.215 0.243 0.088 0.090 0.032 0.034
0.325 0.412 0.105 0.101 0.036 0.035
6.039 0.275
_ 0.094
bias of the estimated constant term and of 6: (for both COLS and MLE) is positive for small and negative for large 2, with the opposite true for I?,“. Some of this bias can be explained in terms of the occurrences of COLS failures. For example, each occurrence of a Type I failure results in assigning a zero value to 6,‘. This truncates the distribution of c?,” at zero. However, this would not explain the downward bias of 6,’ for small A.
The pattern of mean square errors is also clear. At low values for A, COLS is the preferred estimator, in a minimum MSE sense. At AZ 3.162, MLE becomes the preferred estimator. This result is intuitively appealing because we would expect the estimator which specifically takes the exact nature of
the asymmetry of the distribution of the disturbance into account to perform better the more asymmetric the distribution becomes.
The question naturally arises as to the applicability of the results shown in tables 1 and 3 to (N,i) combinations not actually tried. The results shown in Olson (1977) generally showed that MSE as a function of N and ,4 is more or less separable between a J. effect and a N effect, so that generalization of the results contained here may be fairly safe.
This concludes our discussion of the constant term only case. We now
turn our attention to a set of experiments in our two-regressor model. As described in section 3, the two regressors are a constant term and a regressor whose observations were drawn as iid N(0, 1). Since an iid N (0,l) regressor is, at least in expected value, orthogonal to the constant term, X’X is approximately diagonal. Also we know that in the general model, the properties of the disturbance variance estimate (except for number of degrees of freedom) are independent of the nature of the regressor matrix. As a result, we would not expect the addition of this type of regressor to have much of an effect on the properties of the COLS estimates of the constant term or of the disturbance distribution parameters. Also, a glance at the information matrix (actually second derivative matrix) in Aigner, Lovell, and
Tab
le
3
Eff
ects
of
vari
ance
rat
io.a
F
Per
cen
tage
3 of
CO
LS
fa
ilu
res
Con
stan
t te
rm
2 6”
2
0”
02
Var
ian
ce
rati
os
I II
M
LE
C
OL
S
ML
E
CO
LS
M
LE
C
OL
S
ML
E
CO
LS
Bia
s
0.10
0 0.
178
0.31
6 0.
562
l.O
QO
1.
778
3.16
2 5.
623
10.0
00
Var
ian
ce
0.10
0 0.
178
0.31
6 0.
562
l.O
QO
1.
778
3.16
2 5.
623
10.0
00
MSE
0.10
0 0.
178
0.31
6 0.
562
1.00
0 1.
778
3.16
2 5.
623
10.0
00
48
0 0.
3452
0.
3198
0.
6600
0.
5689
-
0.27
38
- 0.
2472
0.
3862
0.
3218
46
1
0.32
87
0.29
57
0.63
44
0.53
77
- 0.
2454
-
0.22
05
0.38
90
0.31
72
44
0 0.
2046
0.
1866
0.
5441
0.
4653
-0
.218
4 -0
.193
7 0.
3257
0.
2716
51
2
-0.1
233
- 0.
0425
0.
2342
0.
2095
-0
.130
0 -0
.125
9 0.
1042
0.
0835
33
.5
0 -0
.112
2 -0
.152
2 0.
1452
0.
0623
-
0.06
66
-0.0
416
0.07
85
0.02
06
15
5 -0
.106
4 -
0.22
00
-0.1
501
- 0.
3689
0.
0041
-0
.059
5 -0
.146
0 -0
.309
4 1
10
-0.1
234
-0.3
162
- 0.
4704
-0
.809
1 0.
0298
0.
1204
-
0.44
07
- 0.
6887
0
29
- 0.
0893
-0
.383
7 -0
.690
1 -
1.12
64
0.01
03
0.09
65
- 0.
6798
-
1.02
99
0 29
-0
.100
5 -
0.37
67
- 0.
6670
-
1.13
35
0.02
23
0.12
71
- 0.
6447
-
1.00
64
0.25
63
0.21
41
0.78
30
0.49
34
0.10
39
0.08
62
0.43
60
0.27
46
0.26
20
0.21
22
0.71
67
0.44
50
0.11
43
0.08
78
0.36
15
0.23
33
0.25
31
0.20
56
0.61
53
0.42
78
0.10
26
0.08
56
0.32
12
0.22
99
0.25
42
0.19
39
0.48
60
0.44
82
0.10
93
0.10
58
0.24
41
0.23
98
0.24
29
0.21
47
0.76
50
0.59
29
0.10
72
0.09
40
0.41
17
0.32
25
0.23
35
0.16
64
1.01
03
0.61
98
0.10
16
0.08
99
0.69
32
0.46
18
0.18
82
0.12
34
1.16
88
0.72
87
0.06
66
0.06
63
0.99
44
0.70
35
0.11
98
0.11
71
1.06
88
0.86
36
0.02
60
0.03
71
1.00
70
0.89
96
0.09
45
O.l
CQ
8 0.
9854
0.
8987
0.
0141
0.
0273
0.
9572
0.
9547
0.37
55
0.31
63
1.21
86
0.81
71
0.17
88
0.14
73
0.58
71
0.37
82
0.37
01
0.29
97
1.11
91
0.73
41
0.17
46
0.13
64
0.51
29
0.33
38
0.29
50
0.24
04
0.91
14
0.64
44
0.15
03
0.12
31
0.42
73
0.30
37
0.25
43
0.19
56
0.54
08
0.49
21
0.12
62
0.12
16
0.25
49
0.24
67
0.25
55
0.23
28
0.78
62
0.59
68
0.11
16
0.09
59
0.41
82
0.32
31
0.24
48
0.21
48
1.03
28
0.75
59
0.10
16
0.09
34
0.71
45
0.55
75
0.20
34
0.22
34
1.39
01
1.38
34
0.06
75
0.08
08
1.18
85
1.17
78
0.12
78
0.26
44
1.54
51
2.13
20
0.02
62
0.04
64
1.46
91
1.96
03
0.10
46
0.24
27
1.43
03
2.18
36
0.01
46
0.04
34
1.37
30
1.96
75
“Bas
ed o
n 2
00 i
tera
tion
s.
78 J.A. Olson et al., Estimators of stochastic,frontier production functions
Schmidt (1977, app.) reveals that, in the row and column corresponding to the coefficient of the N(O,l) regressor, the off-diagonal elements will be approximately zero. As a result we would expect that the properties of the MLE estimates of the other parameters will also not be significantly affected by the addition of this regressor.
Indeed, this expectation is borne out by our results. In order to save space we will not present here the results for the constant term and the various disturbance variances (a:, G: and 0’). Basically, we find that, for any particular parameter point, the biases and variances of these parameters for the two cases (constant-term-only and two-regressor) are generally insignificantly different, at usual confidence levels. The comparisons of COLS versus MLE are also not affected in any substantial way.
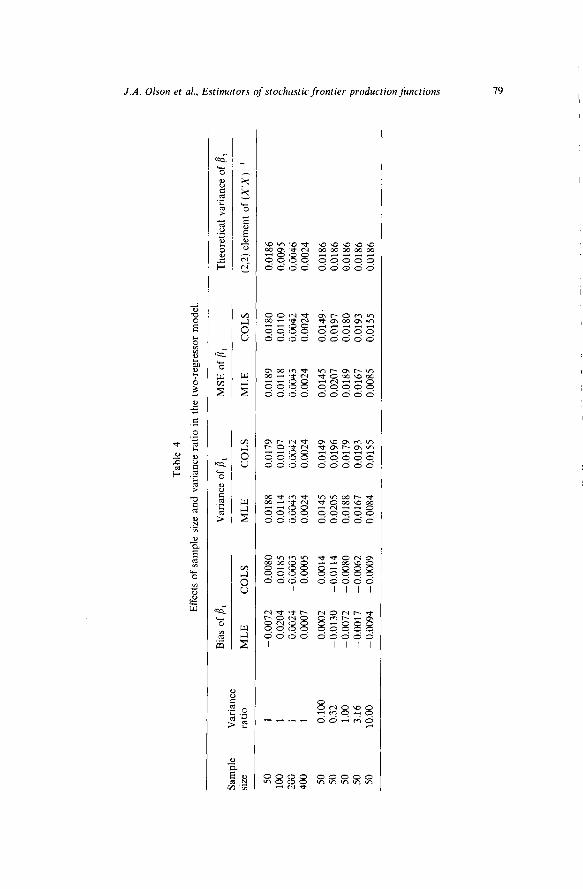
We therefore turn to the results for the coefficient of the non-constant regressor (which we will call /I1 to distinguish it from the constant term PO). These are given in table 4. The first four rows s’how the effect of sample size (N= 50, 100, 200, 400, with A= 1) while the last five rows show the effect of variance ratio (iz=O.l, 0.316, 1, 3.16, 10, with N=50). What we found was somewhat surprising to us; namely, there is no discernible difference between COLS and MLE.3 We know that the COLS estimate of B1 (which equals the
OLS estimate) is unbiased, and the MLE estimate of /I1 appears to be unbiased as well. Furthermore the variances of COLS and MLE are virtually identical, and are very close to the (known) exact variance of COLS (the 2,2 element of (X’X)- ‘, since f$ = 1).
This result, if general, is of obvious significance. It is therefore natural to wonder whether it is due to some peculiar feature of the model - e.g., the orthogonality of the regressors. To check this, we now turn to our last experiment, which. uses the Farrell data, as described in section 3. This X matrix contains 48 observations, four regressors in addition to the constant
term, and a reasonable degree of multicollinearity. We used only one value of the variance ratio, i = 1. To save space, we will not present our results, but will merely summarize them. The properties of the estimates of /I0 and of the
variances are not the same as in the constant term only case, due to the non- diagonality of X’X and the information matrix. However, the results are in accordance with what we would expect from the constant term only model with A= 1 and N =50 (which is the closest value to the present N =48). Specifically, COLS is a little better than MLE. The results for the estimates of p,, p2, /j3, and p4 are also approximately what we would expect from the two-regressor case. There is some difference between COLS and MLE, in the direction of larger MSE for MLE. This difference is not large, but it is bigger than in the two-regressor case.
‘It can be observed that, for /I,, COLS = OLS. Furthermore, OLS is MLE if there is a normal disturbance; we have only added a half-normal disturbance to the usual normal disturbance. From this point of view, this result perhaps should not have been surprising.
Tab
le
4
Eff
ects
of
sam
ple
size
an
d va
rian
ce r
atio
in
th
e tw
o-re
gres
sor
mod
el
Sam
ple
size
V
aria
nce
ra
tio
Bia
s of
j,
Var
ian
ce o
f/J,
M
SE
of
&
Th
eore
tica
l va
rian
ce o
f fl
,
ML
E
CO
LS
M
LE
C
OL
S
ML
E
CO
LS
(2
.2)
elem
ent
of (
X’X
)
’
50
1 -0
.007
2 -
0.00
80
0.01
88
0.01
79
0.01
89
0.01
80
0.01
86
100
1 0.
0204
0.
0185
0.
0114
0.
0107
0.
0118
0.
0110
0.
0095
20
0 1
0.00
24
- 0.
0003
0.
0043
0.
0042
0.
0043
0.
0042
0.
0046
40
0 1
0.00
07
0.00
05
0.00
24
0.00
24
0.00
24
0.00
24
0.00
24
50
0.10
0 -0
.000
2 0.
0014
0.
0145
0.
0149
0.
0145
0.
0149
. 0.
0186
50
0.
32
-0.0
130
-0.0
114
0.02
05
0.01
96
0.02
07
0.01
97
0.01
86
50
1.00
-0
.007
2 -
0.00
80
0.01
88
0.01
79
0.01
89
0.01
80
0.01
86
50
3.16
-0
.001
7 -
0.00
62
0.01
67
0.01
93
0.01
67
0.01
93
0.01
86
50
10.0
0 -
0.00
94
- 0.
0009
0.
0084
0.
0155
0.
0085
0.
0155
0.
0186
80 J.A. O/son et ul., Estimators ofstochasticfrontier productionfunctions
6. Conclusions
In this paper we have compared, by Monte Carlo methods, the small sample properties of various estimators of a stochastic frontier production function model of the type introduced by Aigner, Love11 and Schmidt (1977)
and Meeusen and van den Broeck (1977). The estimators considered were a corrected least squares estimator (COLS), a two-step Newton-Raphson method (2STEP), and maximum likelihood (MLE).
The performance of 2STEP was rather disappointing. Even in cases when it did not ‘explode’ (due to improper COLS starting values), it did not generally outperform the COLS estimates with which it started. We would
not recommend its use. The comparison of MLE and COLS varies, depending on which
parameters are of most interest. For the coefficients of all regressors except
the constant term, there was little difference between COLS and MLE. (For these coefficients, COLS =OLS, it should be recalled.) The computational simplicity of OLS would thus be a good reason to prefer it to MLE.
For the constant term and variance parameters, the choice of estimator
depends on the true value of A and sample size. For all sample sizes below 400 and for i less than 3.16, COLS is preferred. But, even for higher sample sizes and variance ratios, the additional efficiency of the MLE may not be worth the extra trouble required to compute it.
Appendix
In this appendix we give a sketch of the derivation of the asymptotic distribution of the COLS estimator. For simplicity we consider the case of a constant-term-only regression.
Our disturbance term is of the form O-U, where u-N(O,ot) and u is the
absolute value of a variable distributed as N(0, r~,“). Define p=E(u)
=J/ 2 7~0,. Then the first six central movements of the disturbance can be
shown to be
J.A. Olson et al., Estimators o~stochasticjrontier production functions 81
Now note that the constant term only model can be written as
y=p+v-u=(jl-p)+d,
where E’ = v - u +p is the difference minus its (population) mean. Let ml
represent the ith sample moment around zero of the a’, and let mi represent the ith central (i.e., around the sample mean) sample moment of the a’, for i = 1,2,3,. . . The m, are also, for the constant term only model, the ith sample
moments of the residuals (whose sample mean is zero).
The asymptotic distributions of central moments have been previously derived; see, e.g. Rao (1952, pp. 2155216). If we let I’( .) represent asymp- totic variance and C( ., . ) asymptotic covariance, then
We are now in a position to derive the asymptotic distribution of any
differentiable function of the sample moments of the disturbances. For example, it is easy to show that
82 J.A. Olson et ul., Estimcrtors ofstochastic~rontier production functions
Then we have
Similar results hold for other parameters such as E, and 02.
References
Aigner, D., C.A.K. Love11 and P. Schmidt, 1977, Formulation and estimation of stochastic frontier production function models, Journal of Econometrics 6, 21-37.
Dhrymes, P.J., 1970, Econometrics: Statistical foundations and applications (Harper and Row, New York).
Farrell, M.J., 1957, The measurement of productive efficiency, Journal of the Royal Statistical Society A 120, 253- 28 1.
Greene, W.H., 1980, Maximum likelihood estimation of econometric frontier functions, Journal of Econometrics, this issue.
Meeusen, W. and J. van den Broeck, 1977, Efficiency estimation from Cobb-Douglas production functions with composed error, International Economic Review 18, 435 -444.
Olson, J.A., 1977, Small sample properties of estimators for stochastic frontier production functions, Unpublished dissertation (University of North Carolina, Chapel Hill, NC).
Rao, C.R., 1952, Advanced statistical methods in biometric research (Wiley, New York). Richmond, J., 1974, Estimating the efficiency of production, International Economic Review 15,
515-521. Schmidt, P., 1976a, On the statistical estimation of parametric frontier production functions,
Review of Economics and Statistics 58, 238-239. Schmidt, P., 1976b, Econometrics (Marcel Dekker, New York). Triangle Universities Computer Center, 1976, VARGEN - Random variable distribution
generator, Library Services Document no. L551 l&l (Research Triangle Park, NC). Waldman, D.M., 1977, Estimation in economic frontier functions, Unpublished manuscript. Whittlesey, J., 1968, A comparison of the correlational behavior of random number generators
for the IBM 360, Communications of the Association of Computing Machines 11, 641-644. Zellner, A.. J. Kmenta and J. Dreze, 1966, Specification and estimation of Cobb-Douglas
production function models, Econometrica 34, 784795.