40
A probabilistic approach to building large scale federated systems Francisco Matias Cuenca-Acuna http://www.panic-lab.rutgers.edu/
| Date post: | 20-Dec-2015 |
| Category: |
Documents |
| View: | 213 times |
| Download: | 0 times |

A probabilisticapproach to building large scale
federated systemsFrancisco Matias Cuenca-Acuna
http://www.panic-lab.rutgers.edu/

Federated Computing• Rising Internet connectivity is driving a new model
of federated computing− Computing systems that span multiple organizations− Sharing of resources, including data and services
• Federated computing appearing at every level− Social group-based sharing
− P2P: Gnutella, KaZaA, DirectConnect− Web-based: Ebay, Google groups, Yahoo groups, DMOZ
− Scientific computing− Seti@home− Research grids: The European Data Grid
− E-commerce− Federated web ecommerce (Amazon WS)− Distributed supply chains (Travelocity, Sabre)

The Challenge• Federated computing is a natural model for
harnessing inherently distributed resources− Consider data generation and storage
− Users produce 740TB of information per year1
− The European Data Grid has 100’s of nodes hosting PB’s of data
• Challenge: how do we build systems that are− Inherently decentralized− Widely distributed− Widely heterogeneous− Resilient to uncontrolled node behavior
1Source http://www.sims.berkeley.edu/research/projects/how-much-info/

The PlanetP Project• Infrastructure support for federated systems
− Communication and distributed state maintenance− Loosely replicated state
− Global index over all data stores− Global membership
− One to many data propagation
− Information sharing− Content addressing & ranking of results− Provide predictable data availability
− Deployment, monitoring, and management of federated services
− Provide a common runtime environment− Self-managing and self-configuring given quality of service
goals

Approach & Status• PlanetP Principles
− Autonomous actions− Loosely synchronized global information− Randomized algorithms
• PlanetP today …− Multidimensional indexed data store
− Accommodates communities of 1000’s nodes− Content ranking comparable to centralized text-based
solution− ~4% loss of recall and precision when compared to
centralized TFxIDF implementation− Practical data availability
− Environment modeled after Gnutella, avg availability 24%, can achieve 99.9% data availability with 6x excess storage
− Successfully help a replicated service adapt to a volatile environment
− Maintains a UDDI service running on Planetlab across 100 nodes

The PlanetP Architecture
Node X
Hoarded Set
F1 F2 Fi
ExcessStorage
Fj Fk
Global Data Index
Membership Info. Gossiping
InformationSearch & Ranking

Communication and State Maintenance

• Nodes push and pull randomly from each others− Unstructured communication resilient to failures− Predictable convergence time
• Novel combination of previously known techniques− Rumoring, anti-entropy, and partial anti-entropy
− Introduce partial anti-entropy to reduce variance in propagation time for dynamic communities
− Batch updates into communication rounds for efficiency− Dynamic slow-down in absence of updates to save
bandwidth
Epidemic Communication
___
______

[K1,..,Kn]
LocalObjects
Bloom filter
LocalIndex
Global Directory
Gossiping[K1,..,Kn]
LocalObjects
Bloom filter
LocalIndex
Global DirectoryNickname Status IP Keys
Alice Online … [K1,..,Kn]
Bob Offline … [K1,..,Kn]
Charles Online … [K1,..,Kn]
Globally Indexed Data Store• Each node maintains a local index of its shared objects
− Objects can be accessed through handles or keys− Summarize the set of keys in its index using a Bloom filter
• The global index is the set of all summaries− Key-to-peer mappings (but don’t know the exact set of keys)− List of online peers
Nickname Status IP Keys
Alice Online … [K1,..,Kn]
Bob Offline … [K1,..,Kn]
Charles Online … [K1,..,Kn]

Data Propagation Performance
Arrival and departure experiment (LAN)
Propagation speed experiment (DSL)

Searching & Ranking

Content-based Searching• Parse & index all documents
− Extract keywords/terms to use them as references to the document
− Keep a per document term count
• Advertise terms using the indexed data stored− Effectively build a local inverted index
• Approximate a global inverted index− Split searching in two phases

Content-based Searching
QueryDiane
Global Directory
[K1,..,Kn]Gary
[K1,..,Kn]Fred
[K1,..,Kn]Edward
[K1,..,Kn]Diane
[K1,..,Kn]
[K1,..,Kn]
[K1,..,Kn]
Keys
Charles
Bob
Alice
Nickname
Bob
Fred
Local lookup
Fred
Bob
Diane
Ranknodes
Diane
Contactcandidates
FredFile3
File1
File2
Rankresults
STOP

Results Ranking• The Vector Space model
− Documents and queries are represented as k-dimensional vectors
− Each dimension represents the weight of a term to a document or query
− The angle between a query and a document indicates their similarity
• Weight assignment (TFxIDF)− Use Term Frequency (TF) to weight terms for documents− Use Inverse Document Frequency (IDF) to weight terms
for query− Intuition
− TF indicates how relevant a document is to a particular concept
− IDF gives more weight to terms that are good discriminators between documents

Approximating TFxIDF• TFxIDF is not well suited to decentralized environments
− Requires term to document mappings− Requires a frequency count for every term in the shared
collection
• Instead, use a two-phase approximation algorithm
• Replace IDF with IPF (Inverse Peer Frequency)− IPF(t) = f(No. Peers/No. Peers with documents containing term
t)− Individuals can compute a consistent global ranking of peers
and documents without knowing the global frequency count of terms
• Rank peers using
iBFtQt
ti IPFQRank )(

Pruning Searches• Centralized search engines have index for entire
collection− Can rank entire set of documents for each query
• In a distributed search, we do not want to contact peers that have only marginally relevant documents− Stop the search after contacting n peers that did not
contribute to current top k ranked documents− n needs to be a function of community size and k

Evaluation• Answer the following questions
− What is the efficacy of our distributed ranking algorithm?− What is the storage cost for the globally replicated index?
• Evaluation methodology− Use a running prototype to validate and collect micro
benchmarks (tested with up to 200 nodes)− Use simulation to predict performance on big
communities

Ranking Evaluation• Evaluated for 5 benchmark document collections
• AP89 collection from TREC− 84678 documents, 129603 words, 97 queries, 266MB− Each collection comes with a set of queries and binary
relevance judgments
• We measure recall (R) and precision (P)
user the topresented docs. no. total
user the topresented docs.relevant no.)(
collectionin docs.relevant no. total
user the topresented docs.relevant no.)(
QP
QR

AP89 Results
• Results intersection is 70% at low recall and gets to 100% as recall increases
• To get 10 documents, PlanetP contacted 20 peers out of 160 candidates

Size of Global Index• TREC collection (pure text)
− Simulate a community of 1000 nodes− Distribute documents uniformly
− 944,651 documents taking up 3GB− 16MB of RAM are needed to store the global index
− 36MB for 5000 peers
− This is 0.5% of the total collection size
• MP3 collection (audio + tags)− Based on Gnutella measurements − 3,000,000 MP3 files taking up 14TB− 36MB of RAM are needed to store the global index for
5000 peers− This is 0.0002% of the total collection size

Automatic replication for availability

Increasing Data Availability• GOAL: provide predictable data availability in P2P
systems− E.g., for file systems, we want to reason about minimum
file availability
• Wide range of node availability− Node MTTF no longer determined by hardware reliability
but by users’ on-line behavior− Fixed number of replicas too wasteful
− E.g., small number of replicas on highly available nodes equivalent to many replicas on low available nodes
− Gnutella span from 0.1% to 100%, with an average of 24%
− Also, we need to recreate replicas as nodes join and leave
• Long term dynamic membership− In fact, a fixed number doesn’t work at all because
availability profile will likely change over time

Our Approach
• Use replication but− Vary number of replicas based on estimated file
availability− Take advantage of nodes going offline as opposed to
failing− Loosely monitor availability− Use erasure codes to minimize space requirements and
spread file to more nodes

Internet
The StrategyAdvertise: - Availability 20% - Files F1, F2 - Fragments Fi, Fj, Fk
Node A
Global Data Index
Hoarded Set
F1 F2 Fi
ExcessStorage
Fj Fk
Membership
Info. Gossiping
Node B
Global Data Index
Hoarded Set
F3 F4 Fx
ExcessStorage
Fy Fz
Membership
Info. Gossiping

Internet
Node A
Global Data Index
Hoarded Set
F1 F2 Fi
ExcessStorage
Fj Fk
Membership
Info. Gossiping
The Strategy
PlanetP
Hoarded Set
F3 F4 Fx
ExcessStorage
Fy Fz
Membership
Info. Gossiping
Based on Node’s B view of F3: - Pick a random node - Create a new fragment for F3 - Push it
F3
Node B
Global Data Index
Hoarded Set
F3 F4 Fx
ExcessStorage
Fy Fz
Membership
Info. Gossiping

Dealing with Decentralization• Nodes replicate and evict autonomously
• All decisions are probabilistic− Weighted by availability estimates
• Target nodes control their own storage space− Protects system against greedy and faulty nodes
• Erasure codes plus− Use a modified version of Reed Solomon
− Provide a large fragment space
− Don’t re-create lost fragments− Prevents duplicates due to autonomous and misinformed
decisions

Availability-based Replacement• Estimating file availability
− Probability of finding an online copy or being able to reconstruct the file from the erasure coded fragments
• Evict fragments of files with “too much” availability− Note that “too much” is in comparison only to files in local
excess storage (don’t have to know about all files in system)
• Why does it work?− Randomized placement decisions local sample of file
availabilities reflect global distribution− This approximation drives space allocation and allows
files with insufficient availability to gain fragments

Evaluation• Evaluate three significantly different environments
• The file sharing environment− 1000 nodes hosting a total of 25000 files− Node availability avg:24%, min:0.1%, 90th perc:75%,
max:100%− Target 99.9% availability− 10 minute refresh rate
• Sources− Saroiu et al. (Gnutella, Napster), DirectConnect at Rutgers
• OMNI− Centralized knowledge with no limitation on replica
placement
• Base− What happens if you do not have availability estimates?

Availability Comparison
0%
10%
20%
30%
40%
50%
60%
70%
80%
90%
100%
0 1 2 3 4Availability (No. Nines)
Per
cen
tag
e o
f F
iles
P2P 1x
OMNI 1x

Availability Comparison
0%
10%
20%
30%
40%
50%
60%
70%
80%
90%
100%
0 1 2 3 4Availability (No. Nines)
Per
cen
tag
e o
f F
iles
P2P 1x
OMNI 1x
P2P 3x
OMNI 3x

Availability Comparison
0%
10%
20%
30%
40%
50%
60%
70%
80%
90%
100%
0 1 2 3 4Availability (No. Nines)
Per
cen
tag
e o
f F
iles
P2P 1xOMNI 1xP2P 3xOMNI 3xP2P 6x

Availability Comparison
0%
10%
20%
30%
40%
50%
60%
70%
80%
90%
100%
0 1 2 3 4Availability (No. Nines)
Per
cen
tag
e o
f F
iles
P2P 1xOMNI 1xP2P 3xOMNI 3xP2P 6x

Effect of Av. Based Replacement
0%
10%
20%
30%
40%
50%
60%
70%
80%
90%
100%
0 1 2 3 4Availability (No. Nines)
Per
cen
tag
e o
f F
iles
P2P 3X
Base 3X
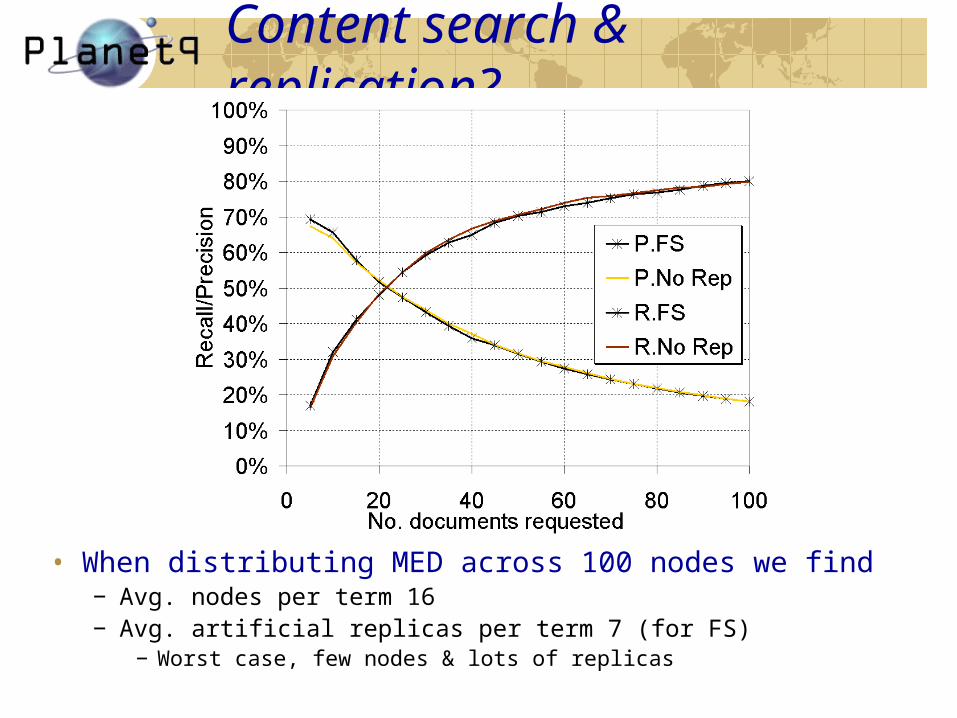
Content search & replication?
• When distributing MED across 100 nodes we find− Avg. nodes per term 16− Avg. artificial replicas per term 7 (for FS)
− Worst case, few nodes & lots of replicas

Self-managed Federated Services

Adaptive Federated Services• GOAL: Reduce administration burden
− Operator errors account for 19%-33% of total errors− 50% of them are due to configuration problems− Federated environments will amplify this trend
• GOAL: Improve availability & fault tolerance− Automatic reconfiguration, failure masking & av.
estimation
• Distributed runtime for Web Services − Administrators just dictate the policy− They reason about
− capacity− availability − privacy issues
− Provide self deployment and monitoring− Wrap service replicas with autonomous agents
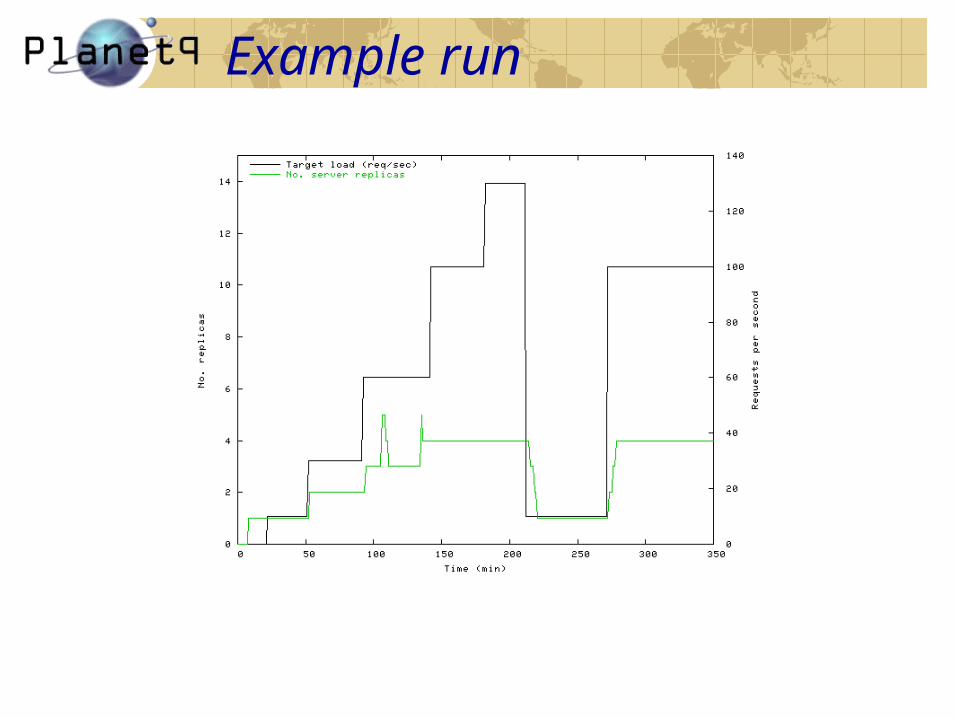
Example run

Conclusions• Explored infrastructural support for applications
running on federated systems− Membership, content addressing & ranking, service
management− Scale well to thousands of peers− Extremely tolerant to unpredictable dynamic peer
behaviors
• Gossiping with partial anti-entropy is reliable− Information always propagate everywhere− Propagation time has small variance
• Distributed approximation of TFxIDF− Within 11% of centralized implementation− Global index << size of data collection
− 0.5% for 1000 peers sharing TREC

Conclusions• Practical data availability
− We can achieve 3 in spite of low node availability and decentralized environment
− CO: 80% avg. av. 1X− FS: 24% avg. av. 6X− WG: 33% avg. av. 9X
− Having some global information is critical− But can do quite well with loosely synchronized data
• Effective service management & monitoring− No. service replicas adapts to
− Environmental changes− Workload changes− Application failures
− Monitoring agents can operate autonomously− Probabilistic serialization effectively reduces collisions− They advance toward stable solutions

The PlanetP Project http://www.panic-lab.rutgers.edu/
Thank youQuestions?

















