Hindawi Publishing CorporationEURASIP Journal on Advances in Signal ProcessingVolume 2008, Article ID 453580, 7 pagesdoi:10.1155/2008/453580
Research ArticleA Robust Zero-Watermarking Algorithm for Audio
Ning Chen and Jie Zhu
The Department of Electronic Engineering, Shanghai Jiao Tong University, DongChuan Road no. 800, Shanghai 200240, China
Correspondence should be addressed to Ning Chen, chenning [email protected].
Received 30 July 2007; Accepted 25 November 2007
Recommended by Mark Liao
In traditional watermarking algorithms, the insertion of watermark into the host signal inevitably introduces some percepti-ble quality degradation. Another problem is the inherent conflict between imperceptibility and robustness. Zero-watermarkingtechnique can solve these problems successfully. Instead of embedding watermark, the zero-watermarking technique extractssome essential characteristics from the host signal and uses them for watermark detection. However, most of the available zero-watermarking schemes are designed for still image and their robustness is not satisfactory. In this paper, an efficient and ro-bust zero-watermarking technique for audio signal is presented. The multiresolution characteristic of discrete wavelet transform(DWT), the energy compression characteristic of discrete cosine transform (DCT), and the Gaussian noise suppression propertyof higher-order cumulant are combined to extract essential features from the host audio signal and they are then used for water-mark recovery. Simulation results demonstrate the effectiveness of our scheme in terms of inaudibility, detection reliability, androbustness.
Unauthorized copying and distribution of digital data createsa severe problem in the protection of intellectual propertyrights. The embedding of digital watermark into multimediacontent has been proposed to tackle this problem. However,currently available digital watermarking schemes mainly fo-cus on image and video copyright protection and only afew audio watermarking techniques have been reported [1].Comparing with the development of digital video and imagewatermarking, digital audio watermarking provides a specialchallenge because the human auditory system (HAS) is ex-tremely more sensitive than human visual system (HVS) [2].
In traditional audio watermarking techniques, either inspatial domain, transform domain, or dual domain [3, 4],the embedding of watermark into the host audio inevitablyintroduces some audible quality degradation. Another prob-lem is the inherent conflict between the imperceptibility androbustness. Then, zero-watermarking technique was pro-posed by some researchers to solve these problems [5–14].Instead of embedding watermark into the host signal, thezero-watermarking approach just constructs a binary pat-tern based on the essential characteristics of the host signaland uses them for watermark recovery. An efficient zero-
watermarking technique was presented in [5]. At first, thehost image was rearranged randomly in the spatial domainand the result of which was divided into blocks according tothe size of the watermark. Next, the variance of each blockwas compared with the average of all variances to gener-ate a binary pattern. Finally, an exclusive or (XOR) opera-tion was performed between the binary pattern and the bi-nary watermark to obtain a secret key. For watermark re-covery, a binary pattern was extracted from the test imagefirst, and then the XOR operation was applied to the ex-tracted binary pattern and the secret key to recover the bi-nary watermark. In [6, 11], the property of the natural im-ages that the vector quantization (VQ) indices among neigh-boring blocks tend to be very similar was utilized to gen-erate the binary pattern. In [12], a scheme that combinedthe zero-watermarking with the spatial-domain-based neuralnetworks was proposed, in which the differences between theintensity values of the selected pixels and the correspondingoutput values of the neural network model were calculatedto generate the binary pattern. In [13], some low-frequencywavelet coefficients were randomly selected from the origi-nal image by chaotic modulation and used for character ex-traction. And in [14], two zero-watermarks were constructedfrom the host image. One was robust to signal process and
2 EURASIP Journal on Advances in Signal Processing
central cropping, which was constructed from low-frequencycoefficients in discrete wavelet transform domain and theother was robust to general geometric distortions as wellas signal process, which was constructed from DWT coeffi-cients of log-polar mapping of the host image. However, allthese zero-watermarking techniques are designed for still im-age and their robustness against some signal processing ma-nipulations or malicious attacks is not satisfactory. In thispaper, a novel robust zero-watermarking technique for au-dio signal is proposed. The multiresolution characteristic ofDWT, the energy compression characteristic of DCT, and theGaussian noise suppression property of higher-order cumu-lant are combined to extract essential features from the hostaudio signal and they are then used for watermark recovery.Simulation results demonstrate the effectiveness of our algo-rithm in terms of inaudibility, detection reliability, and ro-bustness against both common audio signal processing ma-nipulations and malicious attacks provided by the practi-cal audio watermarking evaluation tool, Stirmark for Audiov0.2 [15]. The remainder of this paper is organized as fol-lows. In Section 2, the definition and properties of higher-order cumulant are reviewed. In Section 3, the proposedzero-watermarking method is described in detail. The sim-ulation results and discussions are given in Section 4. Andthe conclusions are drawn in Section 5.
2. HIGHER-ORDER CUMULANT
The properties of higher-order statistics are becoming moreand more thoroughly studied in the field of signal processing.One property of great interest is the fact that the cumulantof Gaussian signal disappears entirely at higher orders. Sincemany noise and interference signals have Gaussian distribu-tion, this property offers the possibility that the higher-orderstatistics may be useful in signal recovery or interference mit-igation [16]. In this paper, the higher-order cumulant is com-bined in the proposed algorithm to improve its robustnessagainst Gaussian noise addition.
Let �ν = (ν1, ν2, . . . , νk) and x = (x1, x2, . . . , xk), where(x1, x2, . . . , xk) denotes a collection of random variables. Thekth-order cumulant of these random variables is defined asthe coefficient of (ν1, ν2, . . . , νk) in the Taylor series expansion(provided it exists) of the cumulant-generation function [17]
K(�ν ) = lnE{exp ( j�νx)}. (1)
Let {x(t)} be a zero-mean kth-order stationary randomprocess. The kth-order cumulant of this process, denotedCk,x(τ1, τ2, . . . , τk−1), is defined as the joint kth-order cumu-lant of the random variables x(t), x(t + τ1), . . . , x(t + τk−1),that is,
[CP5] If the random variables {xi} are independent of therandom variables {yi}, i = 1, 2, . . . , k, then
cum(x1 + y1, . . . , xk + yk)
= cum(x1, . . . , xk) + cum(y1, . . . , yk).(7)
[CP6] If a subset of the k random variables {xi} is indepen-dent of the rest, then
cum(x1, . . . , xk) = 0. (8)
The cumulants of an independent, identically dis-tributed random sequence are delta functions, that is tosay, if u(t) is such process, then Ck,u(τ1, τ2, . . . , τk−1) =γk,uδ(τ1)δ(τ2) · · · δ(τk−1), where γk,u is the kth-order cumu-lant of the stationary random sequence u(n).
Suppose z(n) = y(n) + v(n), where y(n) and v(n) areindependent, then from [CP5]
If v(n) is Gaussian (colored or white) and k ≥ 3, thenCk,z(τ1, τ2, . . . , τk−1) = Ck,y(τ1, τ2, . . . , τk−1). This makes thehigher-order cumulant quite robust to additive measurementnoise, even if that noise is colored. In essence, cumulants candraw non-Gaussian signals out of Gaussian noise, therebyboosting their signal-to-noise ratios.
3. PROPOSED ZERO-WATERMARKING SCHEME
3.1. Fundamental theory
The wavelet transform is a time-scale analysis. Its multires-olution decomposition offers high-temporal localization forhigh frequencies while offering high-frequency resolution forlow frequencies. So the wavelet transform is a very good toolto analyze the audio signal which is nonstationary. Cox et al.suggest that a watermark should be placed in perceptuallysignificant regions of the host signal if it is to be robust
N. Chen and J. Zhu 3
Host audioSegment
into framesSelectframes
Extractfeature
Key K1
Key K2
Key K3 Apply XORGenerate
binary pattern
Binary image watermark
Figure 1: Embedding process.
[18]. In the proposed scheme, three-level wavelet decom-position is applied to get the low-frequency subband of thehost audio, which is the perceptually significant region of it.The decorrelation, energy compaction, separability, symme-try, and orthogonality properties of discrete cosine transformlead to its widespread deployment in audio processing stan-dard, for example, MPEG-1. To make the proposed schemeresist lossy compression operation such as Mp3 compression,DCT is performed on the obtained low-frequency waveletcoefficients. And considering the Gaussian signal suppres-sion property of higher-order cumulant, the fourth-ordercumulants of the obtained DWT-DCT coefficients are calcu-lated to ensure the robustness of the proposed scheme againstvarious noise addition operations. Finally, the essential fea-tures extracted based on DWT, DCT, and higher-order cu-mulant are used for generating binary pattern. Thus, any ma-nipulations attempting to destroy the watermark will destroythe host audio signal first, so the high robustness of the pro-posed scheme is ensured. And since the essential features ofdifferent host audio signals are different, the detection relia-bility can also be achieved.
The block diagrams of embedding process and extrac-tion process of the proposed zero-watermarking scheme areshown in Figures 1 and 2, respectively. In the embeddingstage, the host audio signal is first segmented into equalframes according to the size of watermark and the frameswith larger energy values are selected for watermark embed-ding. Next, DWT is performed on each selected frame toget its coarse signal, on which DCT is performed. Then, thehigher-order cumulants of the obtained DWT-DCT coeffi-cients are calculated and those elements with large absolutevalue are selected to generate a binary pattern. Finally, thewatermark detection key is generated by applying XOR op-eration to the binary pattern and the binary-valued imagewatermark to be embedded. In the extraction stage, a binarypattern is calculated from the test audio signal first and thenan estimated watermark is obtained by performing XOR op-eration between the obtained binary pattern and the water-mark detection key.
3.2. Embedding process
Let A = {a(i) | i = 0, . . . ,LA − 1} be the host audio signaland let W = {w(i, j) | w(i, j) ∈ {0, 1}}, where i = 0, . . . ,M−1, j = 0, . . . ,N − 1, be the binary-valued image watermark to
Test audioSegment
into framesSelectframes
Extractfeature
Key K1 Key K2
Key K3
Apply XORGenerate
binary patternExtracted
watermark
Figure 2: Extraction process.
be embedded, then the watermark embedding procedure canbe described as follows.
Step 1. At first, A is segmented into L frames, denoted asF = {fi | i = 0, . . . ,L − 1,L > 2MN}, and each frame hasL f samples. Next, the energy value of each frame is calcu-lated and all the frames are rearranged in order of decreasingenergy value. Then, the first T frames are selected for water-mark embedding. And, the indices of the selected frames inF, denoted as I1,
Step 2. H-level wavelet decomposition is performed on eachselected frame fi(k) to get its coarse signal AH
i(k) and detail sig-nals DH
i(k), DH−1i(k) , . . . , D1
i(k). And, to take the advantage of low-frequency coefficient which has a high-energy value and isrobust against various signal processing manipulations theDCT is only performed on AH
i(k)as follows:
AHCi(k) = DCT
(AHi(k)
) = {aHCi(k)(n) | n = 0, . . . ,L f2H− 1
}.
(11)
Step 3. For each AHCi(k), calculate its fourth-order cumulant,
denoted as Ci(k),
Ci(k) ={ci(k)(n) | n = 0, . . . ,
L f2H−1
}. (12)
Then, the elements in Ci(k) are rearranged in order of de-creasing absolute value and the first P (P = (M ×N)/T) ele-ments are selected to generate a new sequence Di(k)as follows:
Di(k) ={di(k)(p) | p = 0, . . . ,P − 1
}. (13)
And the index of di(k)(p) in Ci(k) denoted as I2,
I2 ={ii(k)(p) | ii(k)(p) ∈
{0, . . . ,
L f2H−1
}, p = 0, . . . ,P − 1
},
(14)
is saved as the second secret key K2.
4 EURASIP Journal on Advances in Signal Processing
Step 4. A binary pattern, denoted as Bi(k),
Bi(k) ={bi(k)(p) | p = 0, . . . ,P − 1
}, (15)
is generated with (16) as follows:
bi(k)(p) ={
1, if di(k)(p) ≥ 0,
0, otherwise.(16)
And, the watermark detection key K3 = {Ki(k)(p) | k =0, . . . ,T − 1, p = 0, . . . ,P − 1} is obtained by performingXOR operation between Bi(k) and the binary watermark Was follows:
Ki(k)(p) = bi(k)(p)⊕w(i, j),
k = 0, . . . ,T − 1, p = 0, . . . ,P − 1,
i = floor
(k × P + p
N
), j = mod
(k × P + p
N
).
(17)
Finally, the host audio signal, the secret keys (K1, K2, K3),and the corresponding digital timestamp are registered or as-sociated with an authentication center for copyright demon-stration.
3.3. Extraction process
The watermark recovery procedure can be carried out with-out the host audio as follows.
At first, the test audio signal A = {a(i) | i = 0, . . . ,LA−1}is divided into L frames F = {fi | i = 0, . . . ,L−1}, from whichT frames, denoted as fi(k), k = 0, . . . ,T − 1, are selected withK1.
Next, H-level wavelet decomposition is performed oneach selected frame to get its coarse signal AH
i(k), on which
DCT is performed to get AHCi(k) .
Next, for each AHCi(k) , calculate its fourth-order cumulant
Ci(k), from which P elements are selected with secret key K2
Finally, XOR operation is performed between the esti-mated binary pattern and the watermark detection key K3
to obtain the estimated binary image watermark W.
4. SIMULATION RESULTS AND DISCUSSIONS
4.1. Simulation results
To demonstrate the feasibility of our scheme, the perfor-mance test, detection reliability test, and robustness test wereillustrated for the proposed watermarking algorithm, and theproposed watermark detection results were compared withthat of scheme [3] against various audio signal processingmanipulations and malicious attacks provided by Stirmarkfor Audio v0.2 [15]. All of the audio signals used in this testwere audio with 16 bits/sample, 44.1 KHz sample rate, and28.73s long. The watermark to be embedded was a visuallyrecognizable binary image of size 64× 64 . The Haar waveletbasis was used, and three-level wavelet decomposition wasperformed. The frame length was fixed at 512 samples and ineach selected frame 4 bits were embedded.
We used the signal-to-noise ratio (SNR) (21) to evaluatethe quality comparison between the attacked audio and orig-inal audio:
SNR(
A, A) = 10 log 10
{ ∑ LA−1i=0 a2(i)∑ LA−1
i=0 [a(i)− a(i)]2
}. (21)
The normalized cross-correlation (NC) (22) was adopted toappraise the similarity between the estimated watermark andthe original one:
NC(
W, W)
=∑M−1
i=0
∑ N−1j=0 w(i, j)w(i, j)√∑M−1
i=0
∑ N−1j=0 w2(i, j)
√∑M−1i=0
∑ N−1j=0 w2(i, j)
.
(22)
And, the bit error rate (BER) (23) was employed to measurethe robustness of our algorithm,
BER = B
M ×N × 100%, (23)
where B is the number of erroneously extracted bits.(1) Performance test: a plot of the host audio signal is
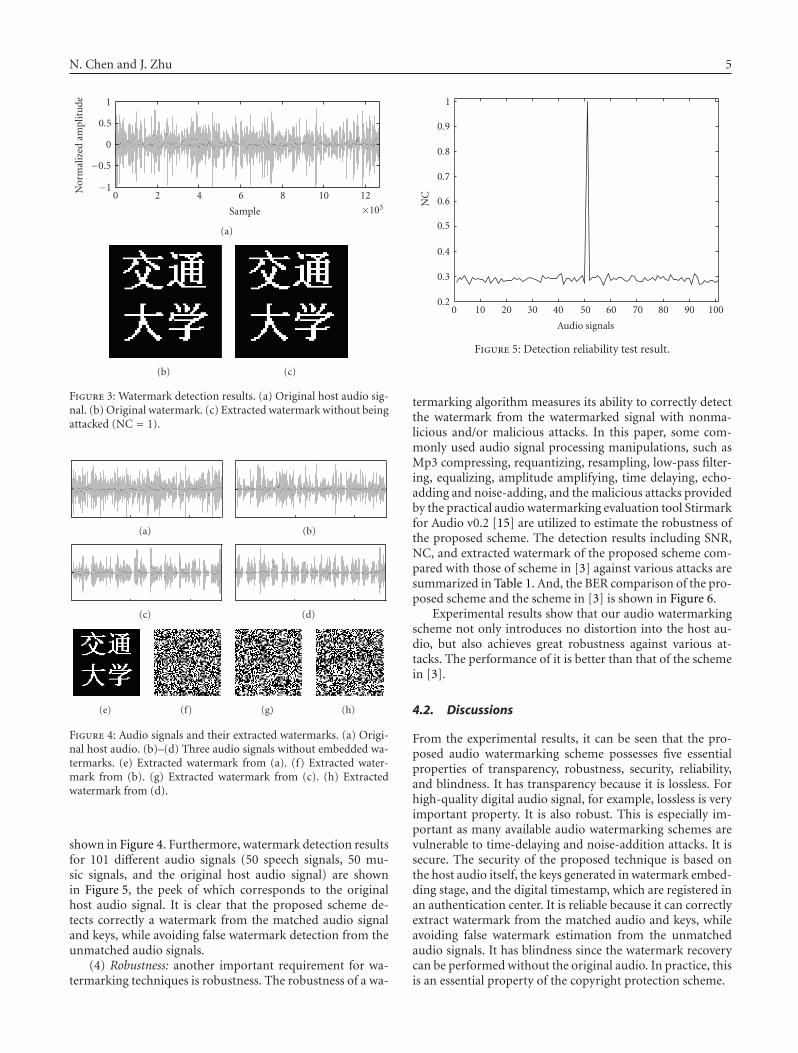
shown in Figure 3(a). The original watermark image and theextracted watermark image are displayed in Figures 3(b) and3(c) (NC = 1), respectively.
(2) Imperceptibility: one of the main requirements of au-dio watermarking techniques is inaudibility of the embed-ded watermark. For the proposed scheme, this requirement isnaturally achieved because the watermark is embedded intothe secret key but not the host audio signal itself. Actually,the watermarked audio is the identical to the original one.
(3) Detection reliability: to examine whether the proposedtechnique has the undesired property to extract the water-mark W from the audio signals with no embedded water-mark. More specifically, we attempt to extract W from thenonwatermarked audio signals using the same keys neededto extract W from the host audio signal. The waveformsof the original host audio signal (Figure 4(a)) and anotherthree pieces of audio signals (Figures 4(b)–4(d)), and theircorresponding extracted watermarks (Figures 4(e)–4(h)) are
N. Chen and J. Zhu 5
0 2 4 6 8 10 12
×105Sample
−1
−0.5
0
0.5
1
Nor
mal
ized
ampl
itu
de
(a)
(b) (c)
Figure 3: Watermark detection results. (a) Original host audio sig-nal. (b) Original watermark. (c) Extracted watermark without beingattacked (NC = 1).
(a) (b)
(c) (d)
(e) (f) (g) (h)
Figure 4: Audio signals and their extracted watermarks. (a) Origi-nal host audio. (b)–(d) Three audio signals without embedded wa-termarks. (e) Extracted watermark from (a). (f) Extracted water-mark from (b). (g) Extracted watermark from (c). (h) Extractedwatermark from (d).
shown in Figure 4. Furthermore, watermark detection resultsfor 101 different audio signals (50 speech signals, 50 mu-sic signals, and the original host audio signal) are shownin Figure 5, the peek of which corresponds to the originalhost audio signal. It is clear that the proposed scheme de-tects correctly a watermark from the matched audio signaland keys, while avoiding false watermark detection from theunmatched audio signals.
(4) Robustness: another important requirement for wa-termarking techniques is robustness. The robustness of a wa-
0 10 20 30 40 50 60 70 80 90 100
Audio signals
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
NC
Figure 5: Detection reliability test result.
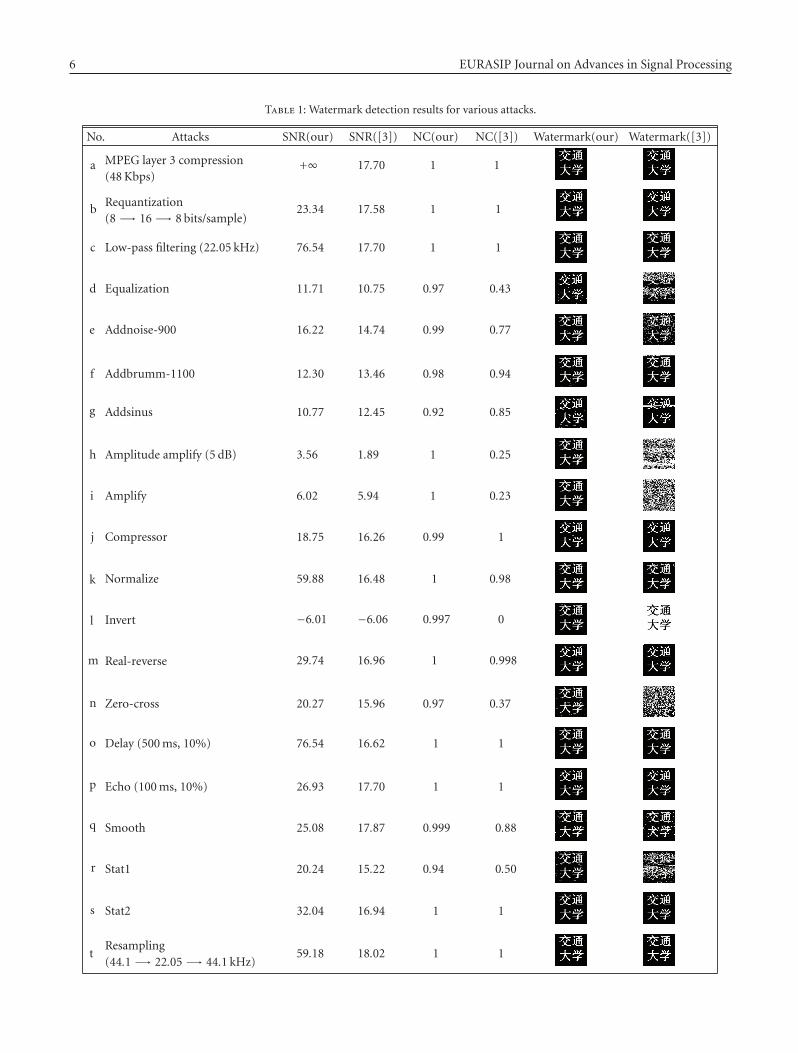
termarking algorithm measures its ability to correctly detectthe watermark from the watermarked signal with nonma-licious and/or malicious attacks. In this paper, some com-monly used audio signal processing manipulations, such asMp3 compressing, requantizing, resampling, low-pass filter-ing, equalizing, amplitude amplifying, time delaying, echo-adding and noise-adding, and the malicious attacks providedby the practical audio watermarking evaluation tool Stirmarkfor Audio v0.2 [15] are utilized to estimate the robustness ofthe proposed scheme. The detection results including SNR,NC, and extracted watermark of the proposed scheme com-pared with those of scheme in [3] against various attacks aresummarized in Table 1. And, the BER comparison of the pro-posed scheme and the scheme in [3] is shown in Figure 6.
Experimental results show that our audio watermarkingscheme not only introduces no distortion into the host au-dio, but also achieves great robustness against various at-tacks. The performance of it is better than that of the schemein [3].
4.2. Discussions
From the experimental results, it can be seen that the pro-posed audio watermarking scheme possesses five essentialproperties of transparency, robustness, security, reliability,and blindness. It has transparency because it is lossless. Forhigh-quality digital audio signal, for example, lossless is veryimportant property. It is also robust. This is especially im-portant as many available audio watermarking schemes arevulnerable to time-delaying and noise-addition attacks. It issecure. The security of the proposed technique is based onthe host audio itself, the keys generated in watermark embed-ding stage, and the digital timestamp, which are registered inan authentication center. It is reliable because it can correctlyextract watermark from the matched audio and keys, whileavoiding false watermark estimation from the unmatchedaudio signals. It has blindness since the watermark recoverycan be performed without the original audio. In practice, thisis an essential property of the copyright protection scheme.
6 EURASIP Journal on Advances in Signal Processing
Table 1: Watermark detection results for various attacks.
Figure 6: BER comparison between the proposed scheme and thescheme in [3] under various attacks.
5. CONCLUSIONS
Most of the currently available watermarking algorithms suf-fer in two points: one is the inevitable quality degradationintroduced by the embedded watermark and the other is theinherent conflict between the imperceptibility and the ro-bustness. To solve these problems, zero-watermarking tech-nique is proposed. In this paper, an efficient and robust zero-watermarking algorithm for audio signal has been proposed.It achieves great detection reliability and robustness sinceit combines the multiresolution characteristic of DWT, theenergy-compression characteristic of DCT, and the Gaussiannoise suppression property of higher-order cumulant to ex-tract essential characteristics from the host audio and usesthem for watermark recovery. In addition, it guarantees theinaudibility because it hides the watermark into the secretkey but not the host audio itself. Simulation results demon-strate the outstanding nature of our algorithm in terms ofinaudibility, detection reliability, and robustness. Our futurework will concentrate on introducing synchronization strat-egy into the proposed scheme to make it resist synchroniza-tion attacks such as random cropping and time-scale modi-fication; on combining the proposed scheme with the avail-able low-bit-rate audio coding standards to make it more fitfor practical applications; and on embedding multiple water-marks into the same host audio to provide dual protectionfor it.
REFERENCES
[1] L. Wei, Y. Yi-Qun, L. Xiao-Qiang, X. Xiang-Yang, and L. Pei-Zhong, “Overview of digital audio watermarking,” Journal ofCommunication, vol. 26, no. 2, pp. 100–111, 2005.
[2] X.-Y. Wang, Y.-R. Cui, H.-Y. Yang, and H. Zhao, “A newcontent-based digital audio watermarking algorithm for copy-right protection,” in Proceedings of the 3rd International Con-
ference on Information Security (SEC ’04), vol. 85, pp. 62–68,Palo Alto, Calif, USA, 2004.
[3] X.-Y. Wang and H. Zhao, “A novel synchronization invariantaudio watermarking scheme based on DWT and DCT,” IEEETransactions on Signal Processing, vol. 54, no. 12, pp. 4835–4840, 2006.
[4] X.-Y. Wang, W. Qi, and P. Niu, “A new adaptive digitalaudio watermarking based on support vector regression,”IEEE Transactions on Audio, Speech, and Language Processing,vol. 15, no. 8, pp. 2270–2277, 2007.
[5] C.-C. Chang, K.-F. Hwang, and M.-S. Hwang, “A block baseddigital watermarks for copy protection of images,” in Pro-ceedings of the 5th Asia-Pacific Conference on Communications(APCC ’99), vol. 2, pp. 977–980, Beijin, China, October 1999.
[6] H.-C. Huang, F.-H. Wang, and J.-S. Pan, “Efficient and robustwatermarking algorithm with vector quantisation,” ElectronicsLetters, vol. 37, no. 13, pp. 826–828, 2001.
[7] T. Sun, W. Quan, and S.-X. Wang, “Zero-watermark water-marking for image authentication,” in Proceedings of the Signaland Image Processing, pp. 503–508, Kauai, Hawaii, USA, Au-gust 2002.
[8] G. Horng, C. Chen, B. Ceng, and T. Chen, “Neural net-work based robust lossless copyright protection technique,”http://www.csie.cyut.edu.tw/TAAI2002/TAAI2002PDF/Parallel.
[9] Q. Wen, T.-F. Sun, and S.-X. Wang, “Concept and applica-tion of zero-watermark,” Tien Tzu Hsueh Pao/Acta ElectronicaSinica, vol. 31, no. 2, pp. 214–216, 2003.
[10] S. Yang, C. Li, F. Sun, and Y. Sun, “Study on the method of im-age non-watermark in DWT domain,” Chinese Journal ImageGraphics, vol. 8A, no. 6, pp. 664–669, 2003.
[11] D. Charalampidis, “Improved robust VQ-based watermark-ing,” Electronics Letters, vol. 41, no. 23, pp. 21–22, 2005.
[12] J. Sang, X. Liao, and M. S. Alam, “Neural-network-based zero-watermark scheme for digital images,” Optical Engineering,vol. 45, no. 9, 2006.
[13] C. Hanqiang, X. Hua, L. Xutao, L. Miao, Y. Sheng, andW. Fang, “A zero-watermarking algorithm based on DWTand chaotic modulation,” in Independent Component Analyses,vol. 6247 of Proceedings of SPIE, pp. 1–9, Orlando, Fla, USA,2006.
[14] L. Jing and F. Liu, “Double zero-watermarks scheme utilizingscale invariant feature transform and log-polar mapping,” inProceedings of the IEEE International Conference on Multimediaand Expo, pp. 2118–2121, Las Vegas, Nev, USA, February 2007.
[15] “StirMark benchmark for audio,” 2005, http://amsl-smb.cs.uni-magdeburg.de/.
[16] D. R. Green, “The utility of higher-order statistics in gaus-sian noise suppression,” US Government Authored or Col-lected Report, Naval Postgraduate School, Memory, Calif,USA, 2003.
[17] J. M. Mendel, “Tutorial on higher-order statistics (spectra) insignla processing and system theory: theoretical resutlts andsome applications,” Proceedings of IEEE, vol. 79, no. 3, 1991.
[18] I. J. Cox, J. Kilian, F. T. Leighton, and T. Shamoon, “Securespread spectrum watermarking for multimedia,” IEEE Trans-actions on Image Processing, vol. 6, no. 12, pp. 1673–1687, 1997.