A Rough Guide to A Rough Guide to Biological Databases Biological Databases Alastair Kerr, Ph.D. Alastair Kerr, Ph.D. Bioinformatician Bioinformatician Wellcome Trust Centre for Cell Biology Wellcome Trust Centre for Cell Biology
Transcript
A Rough Guide to A Rough Guide to Biological Databases Biological Databases
Follow links to Recent Follow links to Recent PresentationsPresentations
GoalsGoals
Understand differences between different Understand differences between different data sourcesdata sources
Know where to go if you have an sequence Know where to go if you have an sequence id (e.g. RefSeq, SwissProt Ensembl)id (e.g. RefSeq, SwissProt Ensembl)
Understand the best data source to use for Understand the best data source to use for your task (e.g. looking for orthologs or your task (e.g. looking for orthologs or splice variants, proteomics experiment)splice variants, proteomics experiment)
Understand how identifiers workUnderstand how identifiers work Understand how to get the best annotationUnderstand how to get the best annotation
Brief history Brief history Varieties of data sources (databases Varieties of data sources (databases
and datasets)and datasets)– Utility/drawbacks of each Utility/drawbacks of each
Use of identifiersUse of identifiers DNA /Protein Annotation DNA /Protein Annotation
– Distributed annotation system [DAS]Distributed annotation system [DAS] DAS clients - outline and demoDAS clients - outline and demo
Dawn of the Age of Dawn of the Age of SequencingSequencing
Mid 50’s : First protein sequence -by Mid 50’s : First protein sequence -by Fred SangerFred Sanger
Late 70’s : clone based sequencing Late 70’s : clone based sequencing arrived with Sanger dideoxy method also arrived with Sanger dideoxy method also the first bioinformatics tools (STADEN, the first bioinformatics tools (STADEN, alignments)alignments)
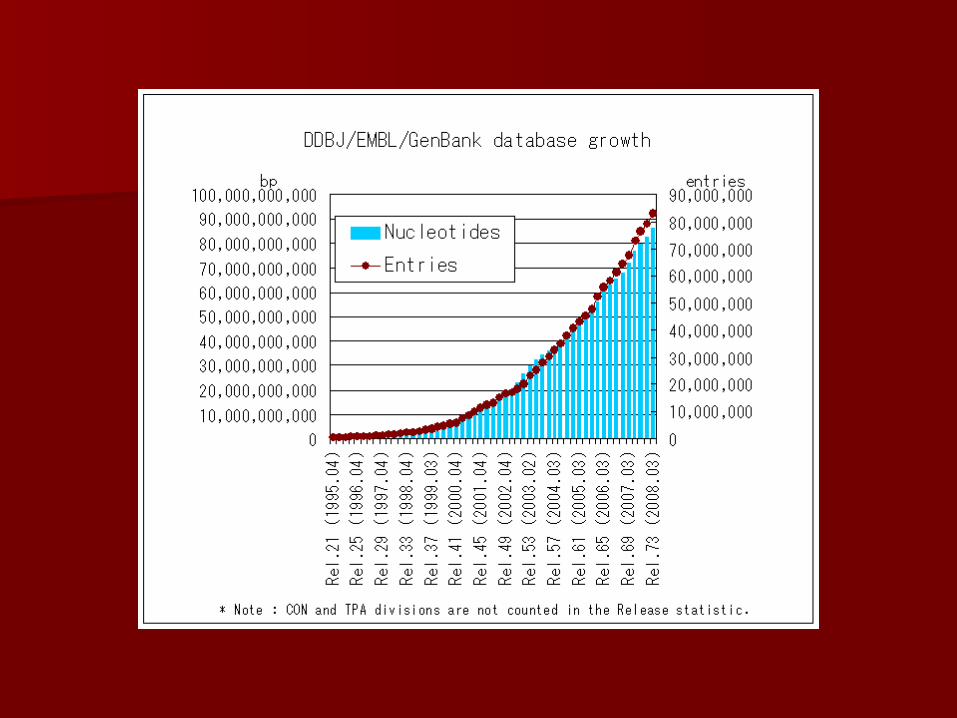
All sequences were published in papers, All sequences were published in papers, a central warehouse was clearly needed a central warehouse was clearly needed to keep them allto keep them all
Sharing PRIMARY sequence Sharing PRIMARY sequence data data
NCBIGenBank EMBL
DDBJ
Sequence WarehousesSequence Warehouses
NCBIGenBank EMBL
• Protein and DNA database
•GenBank NR [Non-redundant]
• Historically • DNA: EMBL• Protein: translated
EMBL (trEMBL)• Now called EBI
• UniProt
National Centre forBiotechnology Information
European MolecularBiology Laboratory
Sources of DNA ErrorSources of DNA Error
Vector contaminationVector contamination– Now mainly eliminated in the sequencing Now mainly eliminated in the sequencing
pipeline but still possible with rarer vectorspipeline but still possible with rarer vectors Sequencing artefactsSequencing artefacts
– Recombination, mutations, contaminationRecombination, mutations, contamination– insertions /deletions (More prone in Next-insertions /deletions (More prone in Next-
gen sequencing?) gen sequencing?) – Most removed from ‘finished’ sequence by Most removed from ‘finished’ sequence by
comparing multiple reads, but still prevalent comparing multiple reads, but still prevalent in ESTs and GSSin ESTs and GSS
Protein Sequence ErrorProtein Sequence Error
Most proteins are based on a Most proteins are based on a modelmodel of the of the gene gene
This gene model is often deduced: This gene model is often deduced: combination of:combination of:– EST dataEST data– ORF finding programs ORF finding programs – Splice site finding programsSplice site finding programs
Protein interpretations may changeProtein interpretations may change– Transcription/translation start sites Transcription/translation start sites – Splice Variants Splice Variants – DNA errorsDNA errors
Varieties of data sources Varieties of data sources
Sequence Warehouses Sequence Warehouses – ““everything under one roof”everything under one roof”
Genome Databases Genome Databases – Containing single genome dataset(s)Containing single genome dataset(s)
Single pass reads Single pass reads – [EST] Expressed sequence set (cDNA)[EST] Expressed sequence set (cDNA)– [GSS] Genome survey sequence[GSS] Genome survey sequence
Curated setsCurated sets
ProsPros– Retrieve a specific sequenceRetrieve a specific sequence
e.g. an identifier from a papere.g. an identifier from a paper
Single Genome Single Genome databases/datasetsdatabases/datasets
ProsPros– Truly non-redundantTruly non-redundant– If complete, you know the gene copy number If complete, you know the gene copy number
and gene familiesand gene families– Can search genomic DNA for know but un-Can search genomic DNA for know but un-
annotated genesannotated genes– Can ‘browse’ the genomeCan ‘browse’ the genome– Usually very good computer annotationUsually very good computer annotation
ConsCons– Not always assembled correctly Not always assembled correctly – May be incomplete (despite saying otherwise)May be incomplete (despite saying otherwise)– Often no human intervention with annotationOften no human intervention with annotation
ensEMBLensEMBL
From EBI / Sanger From EBI / Sanger Many vertebrate and model organism Many vertebrate and model organism
genomesgenomes– All cross-annotated (easy to find All cross-annotated (easy to find
orthologs)orthologs) Access via web with built in DAS client Access via web with built in DAS client
(see later)(see later)– BIOMART accessBIOMART access– Also / SQL / Perl-APIAlso / SQL / Perl-API
Low Quality SequencesLow Quality Sequences
Expressed sequence tag (EST) are reads coding Expressed sequence tag (EST) are reads coding DNA of variable quality but usually very DNA of variable quality but usually very numerous numerous – Ideal for determining which part of a genome is Ideal for determining which part of a genome is
transcribed…transcribed… but not necessarily coding! [ncRNAs]but not necessarily coding! [ncRNAs]
– Recent improvements in visualisation, ORF Recent improvements in visualisation, ORF identification and clusteringidentification and clustering
Genomic survey sequence [GSS] are single pass Genomic survey sequence [GSS] are single pass readsreads– Genomes in early stage of sequencingGenomes in early stage of sequencing– Environmental sampling (meta-genomics) Environmental sampling (meta-genomics)
Using EST databasesUsing EST databases
Gene model verification (e.g. checking Gene model verification (e.g. checking a splice variant)a splice variant)– Search EST databases with genomic Search EST databases with genomic
sequence or cDNAsequence or cDNA
Curated (Protein) Data SetsCurated (Protein) Data Sets
Several efforts to create high quality Several efforts to create high quality databasesdatabases
SwissProt (1986) the first gold standard in SwissProt (1986) the first gold standard in protein functional annotation protein functional annotation – Originally every entry entered by Amos Originally every entry entered by Amos
Bairoch!Bairoch!– Now integrated into UniProt (EBI / EMBL)Now integrated into UniProt (EBI / EMBL)
IMPORTANT: These are site specific. And IMPORTANT: These are site specific. And NOT shared between NCBI / EBI NOT shared between NCBI / EBI
IPI IPI International Protein IndexInternational Protein Index
From EBIFrom EBI Contains proteomes of higher Contains proteomes of higher
eukaryotic eukaryotic Effectively maintains a database of Effectively maintains a database of
cross references between the primary cross references between the primary data sources data sources
Minimally redundant yet maximally Minimally redundant yet maximally complete sets of proteins for featured complete sets of proteins for featured species (one sequence per transcript) species (one sequence per transcript)
Primary sequence crossover Primary sequence crossover between databasesbetween databases
Primary sequence is exchanged Primary sequence is exchanged between databasesbetween databases– But what is primary sequence?But what is primary sequence?– Sometimes only ‘finished’ sequence is Sometimes only ‘finished’ sequence is
sharedshared NOT SHAREDNOT SHARED
– Gene Models (and therefore proteins)Gene Models (and therefore proteins)– Some EST/GSSSome EST/GSS– From some genome projects not yet From some genome projects not yet
publishedpublished
IdentifiersIdentifiers
Consortia identifiersConsortia identifiers
Most key species have a consortia / Most key species have a consortia / group / community that provides the group / community that provides the key identifiers in the fieldkey identifiers in the field
Humans Humans – Was HUGO (HUman Genome Was HUGO (HUman Genome
Organisation)Organisation)– now the HGNC (Human Genome now the HGNC (Human Genome
Nomenclature Committee)Nomenclature Committee) Some of limited use as have Some of limited use as have
incomplete coverageincomplete coverage
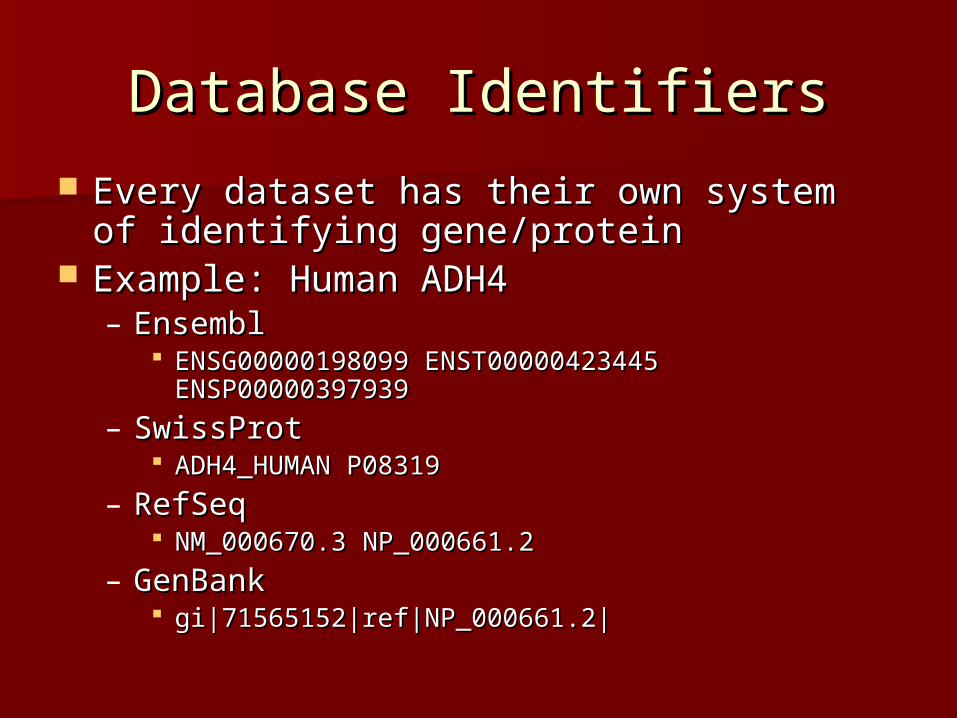
Database IdentifiersDatabase Identifiers
Every dataset has their own system of Every dataset has their own system of identifying gene/proteinidentifying gene/protein
Example: Human ADH4Example: Human ADH4– EnsemblEnsembl
Gene models can changeGene models can change– Will the id you used yesterday still get Will the id you used yesterday still get
the same sequence today?the same sequence today?– Or: How to you get the latest version of Or: How to you get the latest version of
a sequence?a sequence?
Keeping Track of ChangesKeeping Track of Changes GenbankGenbank
– Gi number changes each time, often removed Gi number changes each time, often removed when it gets supersededwhen it gets superseded
SwissProtSwissProt– Accession changes each time (P08319) but the Accession changes each time (P08319) but the
ID remains constant (ADH4_HUMAN)ID remains constant (ADH4_HUMAN) RefSeq and EnsemblRefSeq and Ensembl
– Revision based ids Revision based ids NM_000670.3 ENSG00000198099.1NM_000670.3 ENSG00000198099.1
– XXX.number XXX.number XXX always retrieve latestXXX always retrieve latest XXX.number retrieves the versionXXX.number retrieves the version
Converting between Converting between identifiersidentifiers
Most databases understand an Most databases understand an identifier from another database – identifier from another database – some are better than otherssome are better than others– Best to use UniprotBest to use Uniprot
NEVER rely on common names NEVER rely on common names
AnnotationAnnotation
Standard Keywords and Standard Keywords and annotation annotation
Problem: Many ways to name a geneProblem: Many ways to name a gene– Reductase = oxidase = dehydrogenaseReductase = oxidase = dehydrogenase
Gene Ontology Consortium [GO]Gene Ontology Consortium [GO]– GO terms standardise naming GO terms standardise naming – Note that errors may still occur in the Note that errors may still occur in the
assignment of terms assignment of terms – Found in RefSeq, SwissProt and most Found in RefSeq, SwissProt and most
genome databasesgenome databases GO browsers e.g. AmiGOGO browsers e.g. AmiGO
Annotation IssuesAnnotation Issues
Most annotation by inference from Most annotation by inference from homology/orthologyhomology/orthology
Domain specific function rather than Domain specific function rather than protein specific functionprotein specific function
Programs may give different answers Programs may give different answers – not possible for one source to store – not possible for one source to store all possibilitiesall possibilities
Distributed AnnotationDistributed Annotation
Information on a protein or gene can Information on a protein or gene can be stored on multiple (often be stored on multiple (often specialised) specialised) serversservers– Distributed Annotation System [DAS]Distributed Annotation System [DAS]
Data can be accessed using Data can be accessed using clientclient software that checks these sitessoftware that checks these sites– Built into the ensEMBL websiteBuilt into the ensEMBL website
DAS ClientDAS ClientDAS ClientDAS ClientDAS ClientDAS Servers
DAS Client
Reference Data
DISTRIBUTED ANNOTATION SYSTEM
Das ServersDas Servers
Free one in ensEMBLFree one in ensEMBL I have my own in-house I have my own in-house
– Currently storing CpG islands Currently storing CpG islands – Speak to me if you need to use itSpeak to me if you need to use it
Found on DAS registryFound on DAS registry– many DAS clients can look up this many DAS clients can look up this
registryregistry
Some DAS ClientsSome DAS Clients
Dedicated Web siteDedicated Web site– Dasty2 [Protein DAS]Dasty2 [Protein DAS]
Genome browsersGenome browsers– ensEMBL web site [Protein and Gene DAS]ensEMBL web site [Protein and Gene DAS]
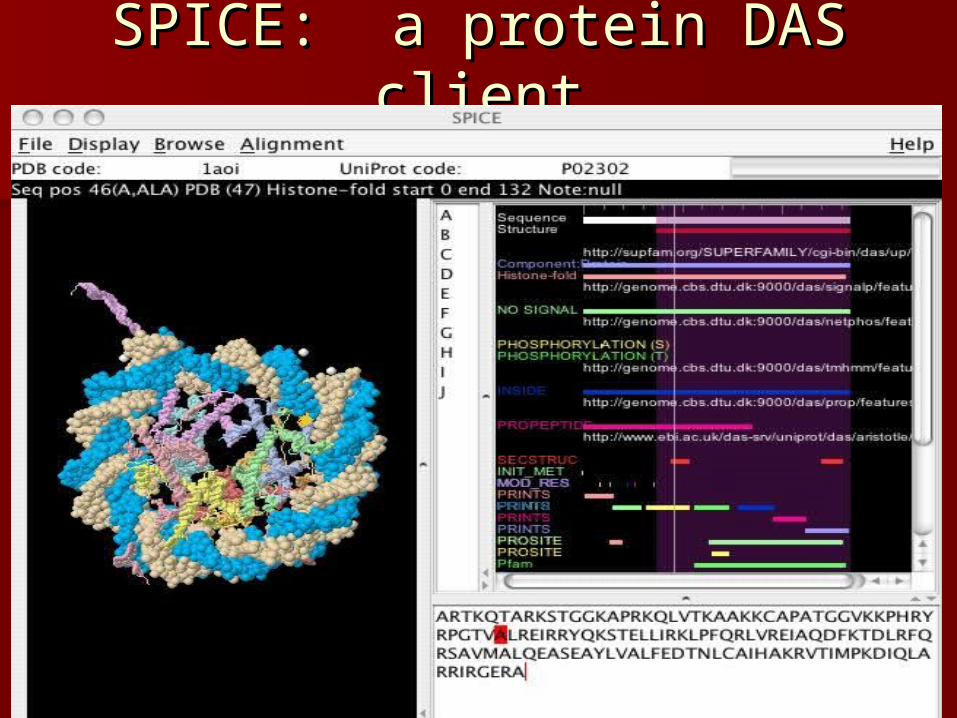
Protein structure viewersProtein structure viewers– Spice [3D Protein DAS]Spice [3D Protein DAS]
Alignment programs Alignment programs – Jalview [Protein and Gene DAS]Jalview [Protein and Gene DAS]
DAS DAS
CpG island tracksCpG island tracks
SPICE: a protein DAS clientSPICE: a protein DAS client
GotchasGotchas
Coordinate systems MUST matchCoordinate systems MUST match– Will change with each genome assemblyWill change with each genome assembly
Use a single source only Use a single source only – e.g. UniProt for proteinse.g. UniProt for proteins
Linked databasesLinked databases
More key databases1More key databases1
Conserved Domains (See later siminar)Conserved Domains (See later siminar)– Interpro: hosts and names from multiply Interpro: hosts and names from multiply
projectsprojects– Each domain often functionally annotatedEach domain often functionally annotated– More in following talkMore in following talk
Mendelian Inheritance in Man (at NCBI)Mendelian Inheritance in Man (at NCBI)– Phenotype centric, literature curatedPhenotype centric, literature curated
Population differencesPopulation differences– dbSNP: polymorphisms (also in Ensembl)dbSNP: polymorphisms (also in Ensembl)