49
Abdul Rahim Ahmad MITM 613 Intelligent System Chapter 8: Neural networks
| Date post: | 30-Dec-2015 |
| Category: |
Documents |
| Upload: | myron-wood |
| View: | 215 times |
| Download: | 1 times |

Abdul Rahim Ahmad
MITM 613Intelligent System
Chapter 8: Neural networks

Chapter Eight : Neural Networks
Abdul Rahim Ahmad
2
8.1 Introduction8.2 Neural network applications
Nonlinear estimationClassification
ClusteringContent-addressable memory
8.3 Nodes and interconnections8.4 Single and multilayer perceptrons
Network topologyPerceptrons as classifiersTraining a perceptronHierarchical perceptronsSome practical considerations
8.5 The Hopfield network8.6 MAXNET8.7 The Hamming network8.8 Adaptive Resonance Theory (ART) networks8.9 Kohonen self-organizing networks8.10 Radial basis function networks

Artificial neural networks
Abdul Rahim Ahmad
3

Artificial Neural Networks (ANN)
ANN - A family of techniques for numerical learning.
Consist of many nonlinear computational elements which form the network nodes or neurons, linked by weighted interconnections.
Analogous in structure to the biological neurological system but are much simpler and effective certain tasks, such as classification.
Generally neural network is taken to mean artificial neural network.
Abdul Rahim Ahmad
4

Artificial neural networks
Using neural networks is described as connectionism.
Each node in a neural network may have several inputs, each of which has an associated weighting.
The node performs a simple computation on its input values, which are single integers or real numbers, to produce a single numerical value as its output.
The output from a node can either form an input to other nodes or be part of the output from the network as a whole.
Abdul Rahim Ahmad
5

Artificial neural networks
Overall effect -> a pattern of numbers is generated at its outputs in response to a pattern of numbers at its inputs.
These patterns of numbers are one-dimensional arrays known as vectors, e.g., (0.1, 1.0, 0.2).
Each neuron performs its computation independently.
Outputs from some neurons may form the inputs to others.
Thus, neural networks have a highly parallel structure, allowing them to explore many competing hypotheses simultaneously.
Abdul Rahim Ahmad
6

Artificial neural networks
Parallelism allows to chance to take advantage of parallel processing computers.
ANN can run on conventional serial computers, except that it is longer.
ANN are tolerant of the failure of individual neurons or interconnections.
ANN performance degrade gracefully if the localized failures within the network occur.
The weights on the node interconnections, together with the overall topology, define the output vector that is derived by the network from a given input vector.
Abdul Rahim Ahmad
7

The Weights
In supervised learning: Examples are presented along with the corresponding
desired output vectors.
Weight is adjusted with each iteration until the actual output for each input is close to the desired vector.
In unsupervised learning: Examples are presented without any corresponding
desired output vectors.
Weight is adjusted in accordance with naturally occurring patterns in the data using a suitable training algorithm.
Output vector represents the position of the input vector within the discovered patterns of the data.Abdul
Rahim Ahmad
8

When presented with noisy/incomplete data, ANN produce approximate answer rather than incorrect.
When presented with unfamiliar data within the range of its previously seen examples, ANN will generally produce a reasonable output interpolated between the example outputs.
However, ANN is unable to extrapolate reliably beyond the range of the previously seen examples.
For Interpolation we can use fuzzy logic. Therefore, ANN and fuzzy logic are alternative solutions to engineering problem and may be combined in a hybrid system.
Abdul Rahim Ahmad
9

ANN applications
ANN can be applied to many tasks.
ANN associates input vector (x1, x2, … xn) with output vector (y1, y2, … ym)
The function linking the input and output may be unknown and can be highly nonlinear. A linear function is one that can be represented as f(x) = mx +
c, where m and c are constants;
a nonlinear one may include higher order terms for x, or trigonometric or logarithmic functions of x.)
Abdul Rahim Ahmad
10

Application 1: Nonlinear estimation ANN technique can determine values of variables that
cannot be measured easily, but known to depend on other more accessible variables.
The measurable variables form the network input vector and the unknown variables constitute the output vector.
In Nonlinear estimation, the network is initially trained using a set of examples known as the training data.
Supervised learning is used; i.e: each example in the training comprises two vectors: an
input vector and its corresponding desired output vector.
This assumes that some values for the less accessible variable have been obtained to form the desired outputs.
Abdul Rahim Ahmad
11

Application 1: Nonlinear estimation During training, the network learns to associate the
example input vectors with their desired output vectors.
When it is subsequently presented with a previously unseen input vector, the network is able to interpolate between similar examples in the training data to generate an output vector.
Abdul Rahim Ahmad
12

Classification Output vector classify input into one of a set of
known possible class.
Example: speech recognition system: Classify input into 3 different words: yes, no, and maybe.
Input: Preprocessed digitized sound of the words
Output: (0, 0, 1) for yes(0, 1, 0) for no(1, 0, 0) for maybe.
During training, the network learns to associate similar input vectors with a particular output vector.
When it is subsequently presented with a previously unseen input vector, the network selects the output vector that offers the closest match. Abdul
Rahim Ahmad
13

Clustering Unsupervised learning
Input vectors are clustered into N groups, (N is integer, may be prespecified or may be allowed to grow according to the diversity of the data).
Example: In speech recognition Input : only spoken words
Training: cluster together examples that is similar to each other. (eg: according to different words or voices).
Once the clusters have formed, a second neural network is trained to associate each cluster with a particular desired output.
The overall system then becomes a classifier, where the first network is unsupervised and the second one is supervised.
Clustering is useful for data compression and is an important aspect of data mining, i.e., finding patterns in complex data.
Abdul Rahim Ahmad
14

Content-addressable memory A form of unsupervised learning.
no desired output vectors associated with the training data. During training, each example input vector becomes stored in a dispersed form through the network.
When a previously unseen vector is subsequently presented to the network, it is treated as though it were an incomplete or error-ridden version of one of the stored examples.
So the network regenerates the stored example that most closely resembles the presented vector.
This can be thought of as a type of classification, where each of the examples in the training data belongs to a separate class, and each represents the ideal vector for that class.
Abdul Rahim Ahmad
15

Nodes and interconnections Node or neuron is a simple computing
element having an input side and an output side.
Each node may have directional connections to many other nodes at both its input and output sides.
Each input xi is multiplied by its associated weight wi.
Typically, the node’s role is to sum each of its weighted inputs and add a bias term w0 to form an intermediate quantity called the activation, a.
It then passes the activation through a nonlinear function ft known as the transfer function or activation function. Figure shows the function of a single neuron.
Abdul Rahim Ahmad
16

Nodes and interconnections The behavior of a neural network depends on
its topology, the weights, the bias terms, and the transfer function.
The weights and biases can be learned, and the learning behavior of a network depends on the chosen training algorithm.
Typically a sigmoid function is used as the transfer function
For each neuron, the activation function is given by:
where n is the number of inputs and the bias term w0 is defined separately for each node.
Abdul Rahim Ahmad
17

Typical Transfer Functions
Non-linear transfer function:
Abdul Rahim Ahmad
18
Sigmoid function
Ramp function Step function
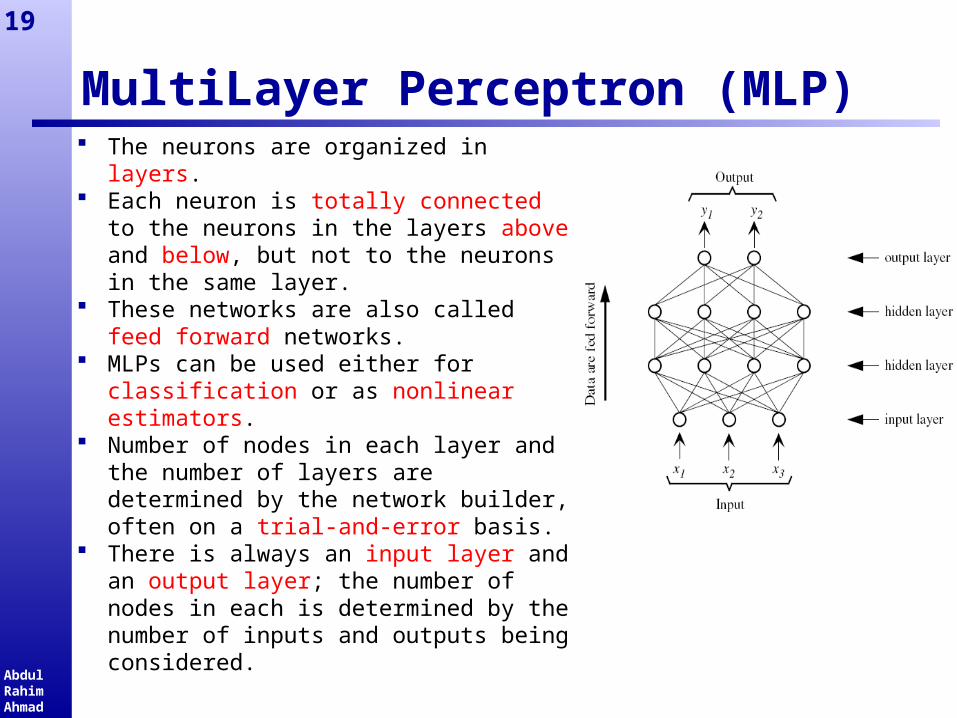
MultiLayer Perceptron (MLP) The neurons are organized in layers. Each neuron is totally connected to
the neurons in the layers above and below, but not to the neurons in the same layer.
These networks are also called feed forward networks.
MLPs can be used either for classification or as nonlinear estimators.
Number of nodes in each layer and the number of layers are determined by the network builder, often on a trial-and-error basis.
There is always an input layer and an output layer; the number of nodes in each is determined by the number of inputs and outputs being considered.
Abdul Rahim Ahmad
19
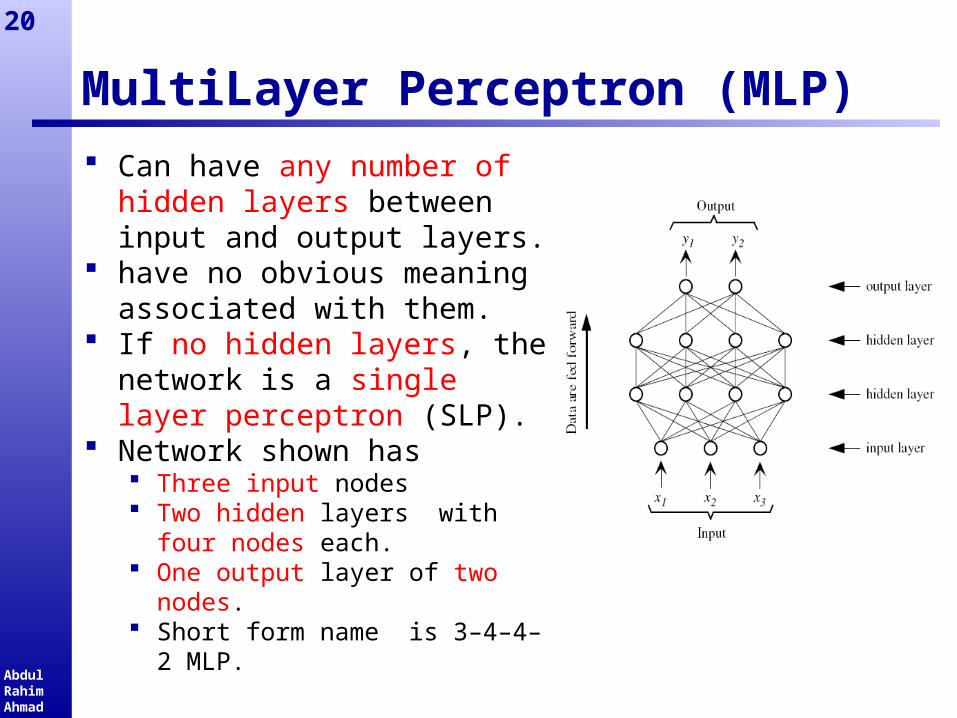
MultiLayer Perceptron (MLP) Can have any number of
hidden layers between input and output layers.
have no obvious meaning associated with them.
If no hidden layers, the network is a single layer perceptron (SLP).
Network shown has Three input nodes Two hidden layers with four
nodes each. One output layer of two
nodes. Short form name is 3–4–4–2
MLP.Abdul Rahim Ahmad
20

MultiLayer Perceptron (MLP) Feed data forwards along input
layer, hidden layers, to the output layer.
Inputs to a node are the outputs from each node in the previous layer except nodes in the input layer.
At each node except input layer, the data are weighted, summed, added to the bias, and then passed through the transfer function.
In the counting of layers, the input nodes is not included since it do not perform any processing
The network in the figure is a three layer MLP.
Abdul Rahim Ahmad
21

Perceptrons as classifiers
Abdul Rahim Ahmad
22
Normally there is one input node for each element of the input vector and one output node for each element of the output vector.
Each output node would usually represent a particular class
Typical representation for a class would be ~1 for one class and the rest ~0.
For the case it does not fall into any class, the winning node must exceed a predetermined threshold such as 0.5.
Other representations are such as two output nodes to represent four classes. Eg: (0,0), (0,1), (1,0), and (1,1).

Linear classifiers
Abdul Rahim Ahmad
23
Example: Single layer perceptron Input : 2 neuron
Output: 3 classes
Each class has 1 dividing line
Linearly separable
Output, prior to application of the transfer function, is given by
The dividing criterion is assumed to be a = 0 corresponding to output of 0.5 after the application of the sigmoid transfer function
Thus the hyperplane that separates the two regions is given by:
In the form of a straight line :

Nonlinear classifiers
Abdul Rahim Ahmad
24
Multilayer perceptron one hidden layer
a differentiable, i.e., smooth, transfer function such as the sigmoid function
First layer divides the state space with straight lines (or hyperplanes),
2nd layer forms multifaceted regions by Boolean combinations (AND, OR, and NOT) of the linearly separated regions.
To perform any nonlinear mapping or classification with an MLP:
With sigmoid transfer function, one hidden layer is needed.
With step transfer function, less than two hidden layers are required.
Learning cannot be guaranteed; final topology involves trial and error. start small then expand.

Training a perceptron Training separate the regions in state space by adjusting its
weights and bias.
Difference between the generated value and the desired value is the error
The overall error is expressed as the root mean squares (RMS) of the errors (both –ve and +ve)
Training minimized RMS by altering the weights and bias, through many passes of the training data.
This search for weights and biases that gives the minimum RMS error is an optimization problem with RMS error as the cost function.
When RMS error is within a small range, we say that the network converged.
Abdul Rahim Ahmad
25

Training Algorithm
Most common is : back-error propagation (BP) algorithm (or generalized delta rule)
A gradient-proportional descent technique with continuous and differentiable transfer function such as sigmoid.
For sigmoid function , the derivative is
Abdul Rahim Ahmad
26

Nomenclature for BP algorithm
Abdul Rahim Ahmad
27

BP Training Algorithm
In BP, biases is always 1.
Delta rule determines the modifications to the weights as follows:
for all nodes j in layer A and all nodes i in layer B after .(B = A + 1).
Neurons in the output and hidden layers have error term, δ. When the sigmoid transfer function is used, δAj is given by:
Abdul Rahim Ahmad
28

BP Training Algorithm (cont.)
learning rate, η, is applied to the calculated values for δAj and should be about 0.35.
Sometimes, momentum coefficient, α is included.
Momentum term forces changes in weight to be dependent on previous weight changes.
Momentum coefficient must be in the range 0–1.
Some suggest to set α to be 0.0 for the first few training passes and then increased to 0.9.
Abdul Rahim Ahmad
29
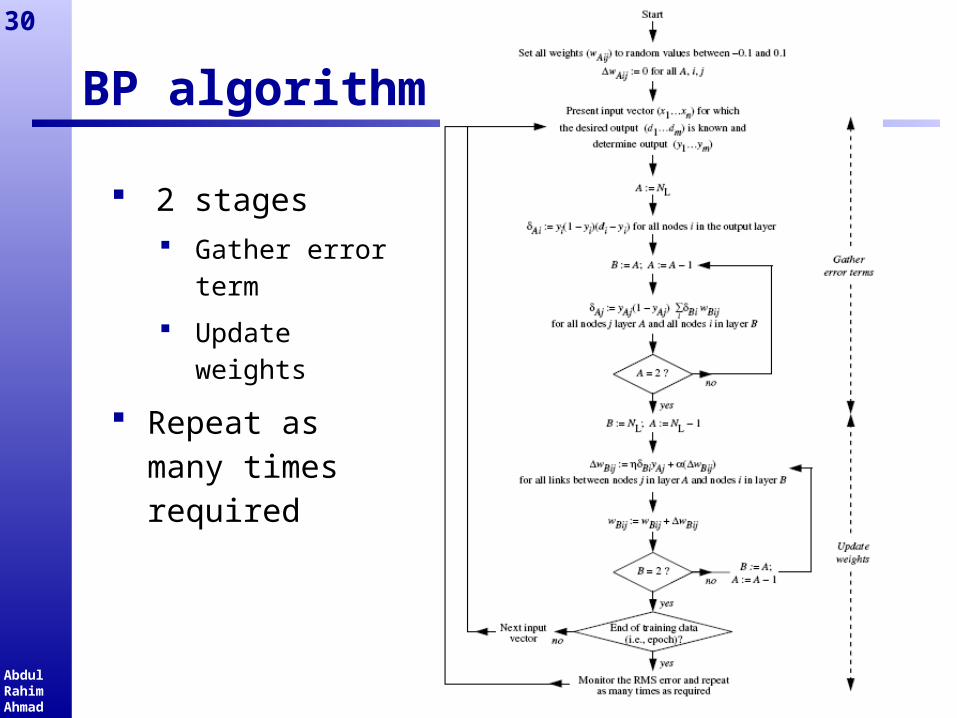
BP algorithm
Abdul Rahim Ahmad
30
2 stages Gather error
term
Update weights
Repeat as many times required

Hierarchical Perceptrons
In complex problems recommended to divide MLP into several smaller MLPs arranged in a hierarchy.
Each MLP independent from each other, can be trained separately or in parallel.
Abdul Rahim Ahmad
31

Some Practical Considerations
Stop training if RMS error remains constant so as not to over-train the network (expert at giving correct output for training data, but not with new data).
Some reasons : too many cycles of training
over-complex network (many hidden layers or numbers of neurons)
To avoid: divide the data into training, testing, and validation.
Use leave-one-out method
Use scaled data.Abdul Rahim Ahmad
32

Effects of Over training
Abdul Rahim Ahmad
33

Hopfield network
One layer: nodes are used for both input and output
Used as a content-addressable memory
Input: binary, (1 and -1)
Output: binary
Transfer function ft is step nonlinearity.
If network has Nn nodes, then the input and output would comprise Nn binary digits.
Weights and biases are set according to the following equations:
Abdul Rahim Ahmad
34
where wij is the weighting on the connection from node i to node j, wi0 is thebias on node i, and xik is the ith digit of example k. There are no circularconnections from a node to itself, hence wij = 0 where i = j.

Learning in Hopfield
Setting weights constitutes the learning phase, results in the examples being stored in a distributed fashion in the network
A new input, is initially the output, too, (as nodes are used for both input and output).
The node function is performed on each node in parallel. If this is repeated many times, the output will be progressively modified and will converge on the example that most closely resembles the initial input.
number of examples (Ne) should not exceed 0.15Nn
Abdul Rahim Ahmad
35

MAXNET
Topology : identical to the Hopfield network
Difference: weights on the circular interconnections, wii, are not always zero.
Used to recognize which of its inputs has the highest value.
Used in conjunction with MLP to select output node that generates the highest value.
interconnection weights are set as follows
Abdul Rahim Ahmad
36
Circular connections from a node to itself are allowed in the MAXNET, but are disallowed in the Hopfield network

Comparison
Abdul Rahim Ahmad
37
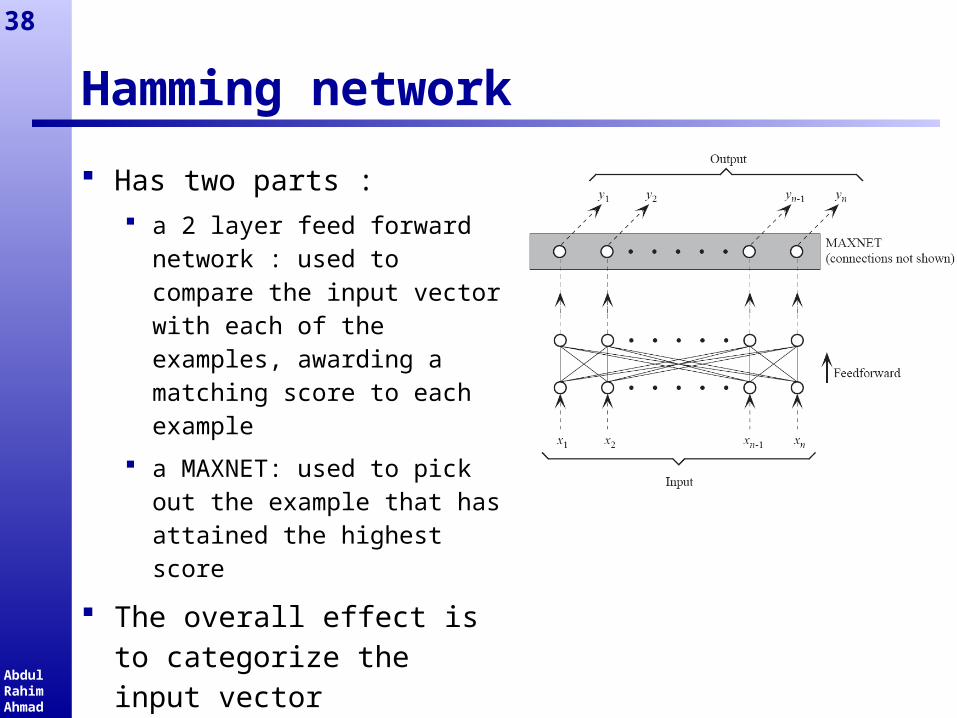
Hamming network
Has two parts : a 2 layer feed forward
network : used to compare the input vector with each of the examples, awarding a matching score to each example
a MAXNET: used to pick out the example that has attained the highest score
The overall effect is to categorize the input vector
Abdul Rahim Ahmad
38

Adaptive Resonance Theory (ART) Unsupervised, comprises of 2-
way interconnections between input nodes and a MAXNET.
Classifies the incoming data into clusters.
1st example stored as example or model pattern, 2nd example compared to 1st: either same cluster or new example.
How the differences are measured - the closeness measure.
New example is compared with all current example in parallel.Abdul
Rahim Ahmad
39
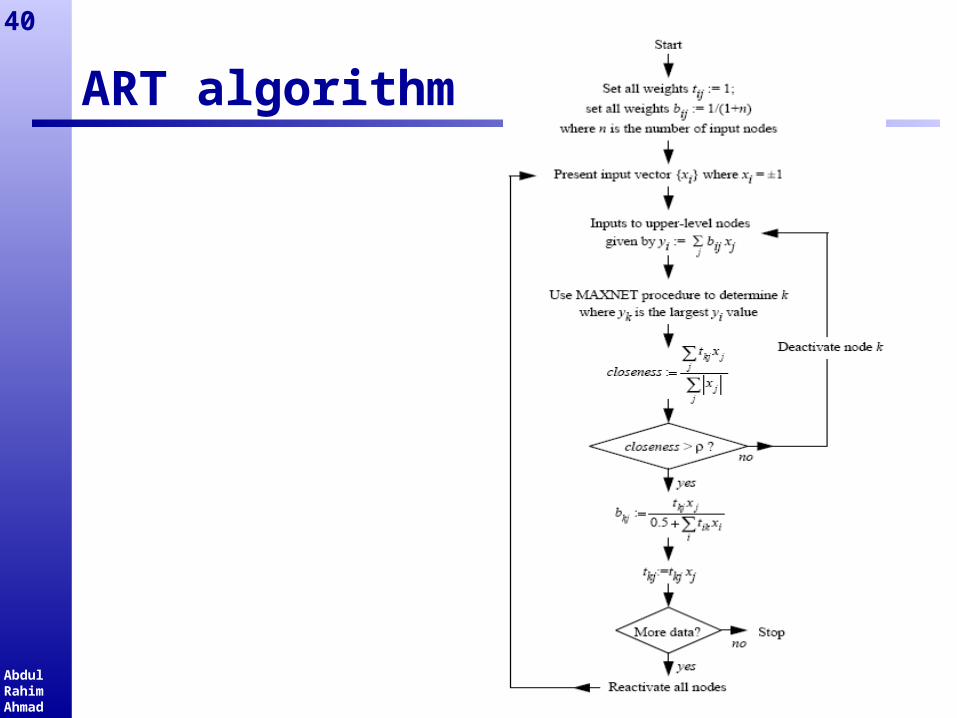
ART algorithm
Abdul Rahim Ahmad
40

Kohonen Self-organizing Networks Unsupervised - also called self-organizing maps
(SOMs).
Topology: Processing nodes arranged in a 2-D array (Kohonen layer)
1-D layer of input nodes, each input node connected to each node in the Kohonen layer.
Used to cluster together similar patterns.
Learning involves competition between the neurons to respond to a particular input vector. Weights of “winner” set to generate a high output (~1)
Weights on nearby neurons (neighborhood) adjusted to be high.
Weights on the “losers” are unchanged. Abdul Rahim Ahmad
41

Kohonen Self-organizing Networks
Abdul Rahim Ahmad
42
When the trained network is presented with an input pattern, one neuron in the Kohonen layer will produce an output larger than the others, and is said to have fired. When a second similar pattern is presented, the same neuron or one in its neighborhood will fire.
As similar patterns cause topologically close neurons to fire, clustering of similar patterns is achieved.

Kohonen Self-organizing Networks
Abdul Rahim Ahmad
43
Can demonstrate by training the network using pairs of Cartesian coordinates - Distribution of the firing neurons corresponds with the Cartesian coordinates represented by the input. Thus, if the input elements fall in the range between –1 and 1, then an
input vector of (–0.9, 0.9) will cause a neuron close to one corner of the Kohonen layer to fire, while an input vector of (0.9, –0.9) would cause a neuron close to the opposite corner to fire.
Can form part of a hybrid network for supervised learning. Can pass coordinates of the firing neuron in a SOM to an MLP
learning takes place in two distinct phases First, the Kohonen self-organizing network learns, without
supervision, to associate regions in the pattern space with clusters of neurons in the Kohonen layer.
Second, an MLP learns to associate the coordinates of the firing neuron in the Kohonen layer with the desired class.

Radial Basis Function (RBF) networks
Unsupervised and feedforward
overall architecture similar to a 3-layer perceptron (i.e:MLP with one hidden layer)
The input & output neurons - similar to perceptron
Neurons in the hidden layer is a symmetrical function - radial basis function (RBF).
Abdul Rahim Ahmad
44

RBF networks (cont.)
The input neurons simply feed the input data into the nodes above.
The neurons in the output layer produce the weighted sum of their inputs, passed through a linear transfer function.
For an input vector (x1, x2, … xn), a neuron i in the hidden layer produces an output, yi, given by:
where wij are the weights on the inputs to neuron i, and fr is a radial basis function (RBF).Abdul
Rahim Ahmad
45
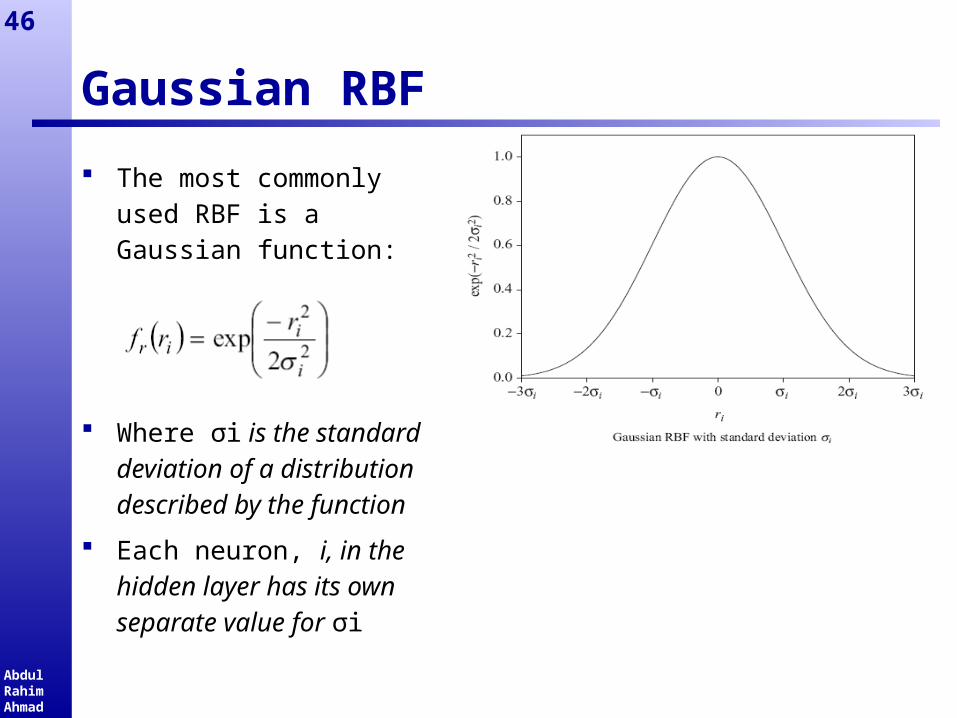
Gaussian RBF
Abdul Rahim Ahmad
46
The most commonly used RBF is a Gaussian function:
Where σi is the standard deviation of a distribution described by the function
Each neuron, i, in the hidden layer has its own separate value for σi

Training
If the set of weights (wi1, wi2, … win) on a given neuron i is treated as the coordinates of a point in pattern space, then ri is the Euclidean distance from there to the point represented by the input vector (x1, x2, … xn).
During unsupervised learning, the network adjusts the weights — (centers in an RBF network ) - so that each point (wi1, wi2, … win) represents the center of a cluster of data points in pattern space.
Abdul Rahim Ahmad
47

Training (cont.)
Sizes of the clusters is defined by adjusting the variables σi (or equivalent variables if an RBF other than the Gaussian is used). Data points within a certain range, e.g., 2σi from a cluster center might be deemed members of the cluster.
RBF network can be thought of as drawing circles around clusters in 2-D space, or hypersheres in n-D space.
One such cluster can be identified for each neuron in hidden layer.
Abdul Rahim Ahmad
48

Training (cont.)
Abdul Rahim Ahmad
49
Gaussian function in 2-D space it can be seen that a fixed
output value (e.g., 0.5) defines a circle in the pattern space.
Hidden layer : unsupervised learning – forming clusters.
Output layer : supervised learning - associate each cluster with a particular class.
Associate several circular clusters of varying center and size with a single class.

















