81
Ad-hoc Wireless Multi Point Relay Simulation CS 293 Project – Final Submission Vipul Singh 100050057 Ashwin Paranjape 100050056
| Date post: | 13-Dec-2015 |
| Category: |
Documents |
| Upload: | martin-norman |
| View: | 219 times |
| Download: | 1 times |

Ad-hoc Wireless Multi Point Relay Simulation
CS 293 Project – Final Submission
Vipul Singh 100050057
Ashwin Paranjape 100050056

Introduction to ‘name’
Ad-hoc – No previous knowledge of network design assumed
Wireless – All messages broadcasted and no overall control
Multi-point – Large network (not a clique) Relay – Information can be transferred to
non-neighbours Simulator !! (phew …such a long name)

Why to do it?
Ad-hoc-ness – Ability to transfer data efficiently without prior common infrastructure
Robustness – Control not concentrated at one place
Scalability – Can extend to any number of nodes
Its fun !!

What is it all about?
Its about designing protocols to maximize data transfer with out loss
Make a Simulator to verify the protocols and algorithms

What have we done ?
Designed 2 independent protocols systems Feasibilty protocols
RTS-CTS-DTS-DNR Assuming - Transfer pairs ( Neighbours) Maximize utiization of available bandwidth
Preprocessing protocols DBSN-IASN-PSN-FTL A random map of nodes to Simulator Nodes preprocess the map (in ~ linear time) Path from any-node to any other can be found

Inputs and outputs
Inputs Number of nodes Time and load factor (RTS-CTS)
Output All messages as they would be broadcast in
ASCII format Some special events

Hierarchy of Code
Simulator Class
Node Class Map ClassPacket Design
(not class)
GUI

Data Stuctures Used All STL structures Priority queues (for scheduling) Adjacency matrix in Simulator (over all coordination) Vector based adjacency lists (for each node) Stringstream (emulate string transfers over wireless
as streams and their associated processing) Lists (storing of trunk-line on SuperNodes – easy
reversal)

Packages Used
Graphwhiz – An excellent graphics package to show graphs
GNU libplot – X Window GUI, used for simulating in real time

High level program flow Feasibility protocols
Map - initialize positions, calculate bandwidths
Assign initial data transfer pairs Role of Simulator
reduceed to popping, pushing events Convaying messages as required by Nodes Printing statements
Then the Sim world takes care of itself! (How?)

Properties of Simulator world
There are many nodes which have different connectivity with some of the other nodes
Different files are scheduled to be transferred from one node to another
Nodes don’t know the map only Simulator does
Simulator doesn’t schedule events only Nodes do.

Map Class
Responsible for generating an initial random graph and modifying it over time
Also responsible for simulating addition and deletion of nodes

Improved Feasibilty Protocols
RTS – Request to send CTS – Clear to send DTS – Denial to send DNR – Do not Receive

Problems without any protocol
Extremely dense connectivty and large number of collisions exp in Ad-hoc networks

Problems with CTS/RTS Large number of unutilized nodes
Many nodes neighbours of 2 nodes Need to block all neighbours even if 1 RTS/CTS
without actual data transfer No Synchronisation (collisions)
CTS and RTS occur along with data transfer mismatch and collisions of RTS/CTS with data
thus reducing throughput

Solution (Part A) Time Windows
Request Interval – Demarcate a certain time interval Only requests and replies to these requests are made Ensures that any non-response is not due to data
transfer happening there but only because certain decisions are pending on the other side
Random send times for RTS(in request Window) ideally meaning no collisions
Thus in RI there has to be mechanism which ensures that schedules maximum throughput

Problems (Part B)
If CTS is not received in response to RTS then that then the RTS sender has no clue and can only timeout. Also, the neighbours of the RTS sender have no way of knowing whether the RTS sender is going to transfer data for sure, thus needing to block itself for the worst case(Pending 2)
Also if the node receives another RTS in this time interval it has no authority to send CTS back(Pending 1), leading to a chain of such dependancies

Problems (Part B)
SMS → All of these protocols taken together are short messages
Undirected → its nodeID is not there is the message. In other words the SMS was not meant for it.
Directed → SMS was meant for it

Solutions (Part B)
Designed 2 new protocols DTS (Denial to send) – This ensures that if
the node is sure to communicate it will atleast not block any other node
DNR(Do not recieve) – This ensures that if certain nodes get RTS, have a determisitic way of knowing their and there dependants fates

How it solves the problems If a node receives send and RTS then it is
bound to receive a CTS or DTS in the Request window
Thus any RTS sent to it can be replied back with a DTS/CTS
Undirected CTS means confirmed communication and the receiver of undirected CTS needs prevent any further RTS from being sent. Had it sent an RTS before then the CTS sender would not have confirmed in the first place and would have waited for DNR

Preprocessing Protocols
Finding Supernodes and routing algorithm DBSN – Don’t be a Super Node IASN – I am Super Node PSN – Path to Super Node FTL – Find Trunk Lines

Presentation of Ideas
All the algorithms are presented in chronological order as they would happenMany time windows are required

Finding Supernodes (Checking candidature of a node for a super)
Supernode coefficient calculated, depending on its bandwidths with neighbours
One with Maximum Supernode coeff. Tells upto a depth of 2 nodes not be a supernode(DBSN)
Done by timing DBSN’s so that max-sq Nodes send first with slight randomness to ward of neighbouring nodes with same coeffs

Avoiding supernode clusters
DBSN (Don't become super node)sent immediately to all nodes within a distance of 2 edges
Disables covered nodes from becoming supernodes in future

Partitioning map into groups
TellSuperNodes function All supernodes broadcast IASN (I am super
node) with messages delayed according to bandwidth (to ensure breadth 1st search)
Better knows as Djikstra’s algorithm Node records 1st such arrival and stores path
to supernode. Also propagates the same with modified path
All subsequent IASNs discarded and stopped

Database formation in supernode (PSN)
In a time window, all nodes at random times start sending their path to supernode (PSN)
At the end of this window, each supernode will have a complete database of all its children nodes and the shortest paths to reach them

Finding trunk lines and information exchange
Confirmed supernode sends FTL , this can keep propagating and when it reaches a pre-existing supernode, trunk line is formed
Also communicated back via same path Along with this, supernodes share list of
nodes under them with each other through trunk lines

Data Transfer and routing
In data transfer window, random pairs are generated
These become source-destination For already occurring data transfers, further
RTS-CTS occur and accordingly, data transfer continues

Starting with an initial path
Suppose A and B are chosen source and destination
Initial path is A → supernode of A (via path stored in A) → supernode of B (via trunk line) → B (via path stored in B's database)

Challenging aspects Thinking like a node (Node-centric)
Blindfold communication Understanding the response to evoke (330 LOC)
Depending upon pending states, whether they are possible Whether we are a Super Node Implementing proper scheduling for time windows Bottom up approach Correct BFT (using explicit time delays) Extracting proper information from String messages and
putting it in order again Not letting Simulator have any role in scheduling Debugging huge outputs

What took time Everything !! Analysing algorithms and Forecasting
responses Avoiding complete flooding, message
clashes Debugging > 6000 lines of output Designing Algorithms ( 2 week approx. )

Distribution
All algorithmic design after long (and heated) debated and discussions (taking up most of time)
Respond function (heart of it all) done together
Overall input ~ 80-90 hrs hrs each LOC - ~ 1700 of functional code

Distribution
Map IASN PSN FTL Event handler
DBSN RTS CTS GUI Simulator

Further Extenstionsand unimplemented ideas
Shortening of paths

Shortening the initial path (not implemented)
Trunk lines tend to remain busy, hence get heated up
So, we shorten paths wherever possible, mostly around trunk lines
Start from node previous to A's supernode, send out BFT (upto depth 3) and end up at a node whose neighbour is on trunk line
Next start from this node, go on till supernode of B is crossed

Assumptions for designing Algorithm (subject to review)
There are two modes of transmitting data from each node
Broadcasting – Data transfer without specifying recipient node, to be used mainly for communication between nodes( and not data transfer), finding shortest paths and checking connectivity.
Directed – Data transfer with a particular recipient mentioned in the header of frame

Assumptions for designing Algorithm (subject to review)
Each node may either receive or send signals.
When it receives signals from one node it should neglect signals send by another node (under review)
It takes finite amount of time to establish connection and data transfer speed is proportional to connectivity

Overview of algorithm
To send signals over a single file of nodes we need to alternate data transfer between nodes

Source Destination

Source Destination

Source Destination

Source Destination

Source Destination

Source Destination

Analysis of previous case
Recipient and sender remains idle for atleast half the amount of time
Initial wait before data starts reaching is directly proportional to no of nodes in between and inversely proportional to packet size (being large)
But the smaller the packet size time overhead increases to switch between nodes
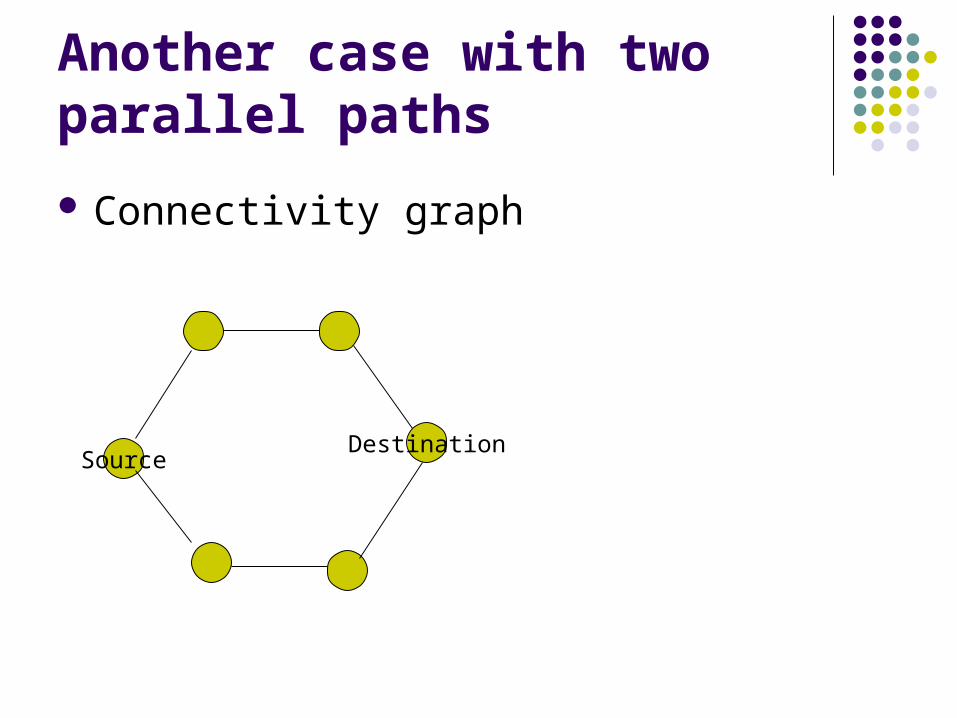
Another case with two parallel paths
Connectivity graph
SourceDestination

SourceDestination
SourceDestination

SourceDestination

SourceDestination

SourceDestination

SourceDestination

SourceDestination

SourceDestination

SourceDestination

SourceDestination

Analysis of previous algorithm
The sender and receiver remain busy except at end and beginning respectively
Data transfer speed approaches to that the speed of direct connection as packet size decreases irrespective of no of hops to be performed
But as switching has a constant cost associated with it so there exists an optimal packet size

Overview of Routing algorithm
Motivations Searching for a file inside a node will require
flooding the whole network, which would create a lot of congestion
Storing optimal paths to each node from one particular node is expensive
Due to the dynamism of the situation the optimal paths are likely to change
Frequent addition or deletion of nodes will cause unnecessary flooding of the graph

Overview of Routing algorithm
Solution Construct a hierarchy of nodes, the nodes choose
some representative nodes ( referred to as super nodes), inspired by hierarchical governance system
These super-nodes have the task of storing the indexes of all files around it, it does not participate in major data transfer activity except its personal file transfer requirements

Overview of Routing algorithm
Solution All super-nodes find and store trunk line connecting all
other super nodes Trunk lines are dedicated to super-node communication
and do not handle other file transfers Any search request by a node is directed to nearest super-
node which then communicates this to other super-nodes through trunk lines
When a data transfer request from one node to another is made then it is redirected to nearest super-node, which is turn asks all super-nodes whether they have the target in their vicinity. Thus a path is established albeit long one which passes through the trunk lines

Overview of Routing algorithm
Solution This path is then shortened by finding bridges
between two nodes.






Analysis of the previous algorithm
The Super- nodes and trunk line become free of file transfer and a small route is established
If super-nodes and trunk line are involved in large quantity of data transfer then their place is taken by other nodes and they are relieved to prevent battery consumption
All the metadata stored by super-nodes is archived in other nodes to prevent loss due to abrupt disconnection of super-nodes
This idea is to be extended to many levels of hierarchy thus making it scalable

Initial housekeeping (Ommited from simulation)
Background – There had been a previous data transfer going on due to which certain nodes were occupied. It is important to maintain continuity of path for them and exclude them from participation in further routing
If such a node (which has a data packet with itself) is seen to have lost connectivity then BFT is done and first node reached on the further path is connected to

Checking lost connectivity
Initial connectivity Red path is the data transfer path

Checking lost connectivity
Previous data transfers

Checking lost connectivity
One path broken Red path is the data transfer path

Checking lost connectivity
Finding the broken path
RTSRTS

Checking lost connectivity
Finding the broken pathCTS
NO CTS SENTBACK

Checking lost connectivity
Knows its path is broken so starts BFT to find another node on the path following after it
RTS

Checking lost connectivity
Knows its path is broken so starts BFT to find another node on the path following after it
RTS

Checking lost connectivity
This path becomes the new path

Checking lost connectivity
Sends an RTS to the first node expexting a CTS
Communication on the cutoff (black) node continues till all data is transferred
RTS

Checking lost connectivity
CTS

Rebuilding the heirarchy
Every change (mentioned in previuos slides) has a weight associated with it, cumulative value of all changes kept track of by supernodes
When exceeding a certain value, find super nodes run again on entire graph

Mending broken edges in a tree
Unoccupied node – disconnected from supernode due to random movements or deletion
Broadcasts BFT (inclusive of bandwidth) First in own group to receive replies becomes
new next node (GROUP – all nodes which are under the
jurisdiction of a single supernode)

Handling direct disconnection to Supernode
Node sends a HI to supernode Can be replied with 0 connectivity also If reply received, node sends BFT and finds
alternate path to supernode Else, node knows supernode got deleted Now, FSN (findsupernode) run on all nodes
with that group number only New supernode found for that group

















