Pattern Recognition 33 (2000) 225}236 Adaptive document image binarization J. Sauvola*, M. Pietika K inen Machine Vision and Media Processing Group, Infotech Oulu, University of Oulu, P.O. BOX 4500, FIN-90401 Oulu, Finland Received 29 April 1998; accepted 21 January 1999 Abstract A new method is presented for adaptive document image binarization, where the page is considered as a collection of subcomponents such as text, background and picture. The problems caused by noise, illumination and many source type-related degradations are addressed. Two new algorithms are applied to determine a local threshold for each pixel. The performance evaluation of the algorithm utilizes test images with ground-truth, evaluation metrics for binarization of textual and synthetic images, and a weight-based ranking procedure for the "nal result presentation. The proposed algorithms were tested with images including di!erent types of document components and degradations. The results were compared with a number of known techniques in the literature. The benchmarking results show that the method adapts and performs well in each case qualitatively and quantitatively. ( 1999 Pattern Recognition Society. Published by Elsevier Science Ltd. All rights reserved. Keywords: Adaptive binarization; Soft decision; Document segmentation; Document analysis; Document understanding 1. Introduction Most document analysis algorithms are built on taking advantage of the underlying binarized image data [1]. The use of a bi-level information decreases the computational load and enables the utilization of the simpli"ed analysis methods compared to 256 levels of grey-scale or colour image information. Document image understanding methods require logical and semantic content preserva- tion during thresholding. For example, a letter connect- ivity must be maintained for optical character recognition and textual compression [2]. This requirement narrows down the use of a global threshold in many cases. Binarization has been a subject of intense research interest during the last ten years. Most of the developed algorithms rely on statistical methods, not considering the special nature of document images. However, recent developments on document types, for example docu- ments with mixed text and graphics, call for more special- ized binarization techniques. In current techniques, the binarization (threshold se- lection) is usually performed either globally or locally. * Corresponding author. Tel.: #358-40-5890652. E-mail address: jjs@ee.oulu." (J. Sauvola) Some hybrid methods have also been proposed. The global methods use one calculated threshold value to divide image pixels into object or background classes, whereas the local schemes can use many di!erent adapted values selected according to the local area in- formation. Hybrid methods use both global and local information to decide the pixel label. The main situations in which single global thresholds are not su$cient are caused by changes in lumination (illumination), scanning errors and resolution, poor qual- ity of the source document and complexity in the docu- ment structure (e.g. graphics is mixed with text). When character recognition is performed, the melted sets of pixel clusters (characters) are easily misinterpreted if bi- narization labelling has not successfully separated the clusters. Other misinterpretations occur easily if meant to be clusters are wrongly divided. Fig. 1 depicts our taxon- omy (called MSLG) and general division into thre- sholding techniques according to level of semantics and locality of processing used. The MSLG can be applied in pairs, for example (ML), (SL), (MG) and (SG). The most conventional approach is a global threshold, where one threshold value (single threshold) is selected for the entire image according to global/local information. In local thresholding the threshold values 0031-3203/99/$20.00 ( 1999 Pattern Recognition Society. Published by Elsevier Science Ltd. All rights reserved. PII: S 0 0 3 1 - 3 2 0 3 ( 9 9 ) 0 0 0 5 5 - 2
Transcript
Pattern Recognition 33 (2000) 225}236
Adaptive document image binarization
J. Sauvola*, M. PietikaK inen
Machine Vision and Media Processing Group, Infotech Oulu, University of Oulu, P.O. BOX 4500, FIN-90401 Oulu, Finland
Received 29 April 1998; accepted 21 January 1999
Abstract
A new method is presented for adaptive document image binarization, where the page is considered as a collection ofsubcomponents such as text, background and picture. The problems caused by noise, illumination and many sourcetype-related degradations are addressed. Two new algorithms are applied to determine a local threshold for each pixel.The performance evaluation of the algorithm utilizes test images with ground-truth, evaluation metrics for binarizationof textual and synthetic images, and a weight-based ranking procedure for the "nal result presentation. The proposedalgorithms were tested with images including di!erent types of document components and degradations. The results werecompared with a number of known techniques in the literature. The benchmarking results show that the method adaptsand performs well in each case qualitatively and quantitatively. ( 1999 Pattern Recognition Society. Published byElsevier Science Ltd. All rights reserved.
Most document analysis algorithms are built on takingadvantage of the underlying binarized image data [1]. Theuse of a bi-level information decreases the computationalload and enables the utilization of the simpli"ed analysismethods compared to 256 levels of grey-scale or colourimage information. Document image understandingmethods require logical and semantic content preserva-tion during thresholding. For example, a letter connect-ivity must be maintained for optical character recognitionand textual compression [2]. This requirement narrowsdown the use of a global threshold in many cases.
Binarization has been a subject of intense researchinterest during the last ten years. Most of the developedalgorithms rely on statistical methods, not consideringthe special nature of document images. However, recentdevelopments on document types, for example docu-ments with mixed text and graphics, call for more special-ized binarization techniques.
In current techniques, the binarization (threshold se-lection) is usually performed either globally or locally.
Some hybrid methods have also been proposed. Theglobal methods use one calculated threshold value todivide image pixels into object or background classes,whereas the local schemes can use many di!erentadapted values selected according to the local area in-formation. Hybrid methods use both global and localinformation to decide the pixel label.
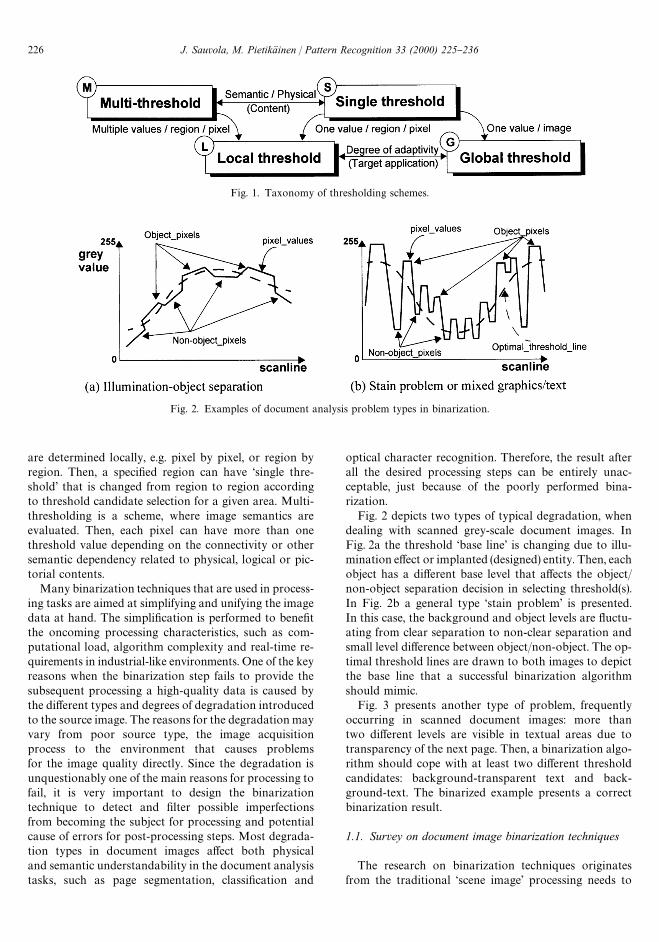
The main situations in which single global thresholdsare not su$cient are caused by changes in lumination(illumination), scanning errors and resolution, poor qual-ity of the source document and complexity in the docu-ment structure (e.g. graphics is mixed with text). Whencharacter recognition is performed, the melted sets ofpixel clusters (characters) are easily misinterpreted if bi-narization labelling has not successfully separated theclusters. Other misinterpretations occur easily if meant tobe clusters are wrongly divided. Fig. 1 depicts our taxon-omy (called MSLG) and general division into thre-sholding techniques according to level of semantics andlocality of processing used. The MSLG can be applied inpairs, for example (ML), (SL), (MG) and (SG).
The most conventional approach is a globalthreshold, where one threshold value (single threshold) isselected for the entire image according to global/localinformation. In local thresholding the threshold values
0031-3203/99/$20.00 ( 1999 Pattern Recognition Society. Published by Elsevier Science Ltd. All rights reserved.PII: S 0 0 3 1 - 3 2 0 3 ( 9 9 ) 0 0 0 5 5 - 2
Fig. 1. Taxonomy of thresholding schemes.
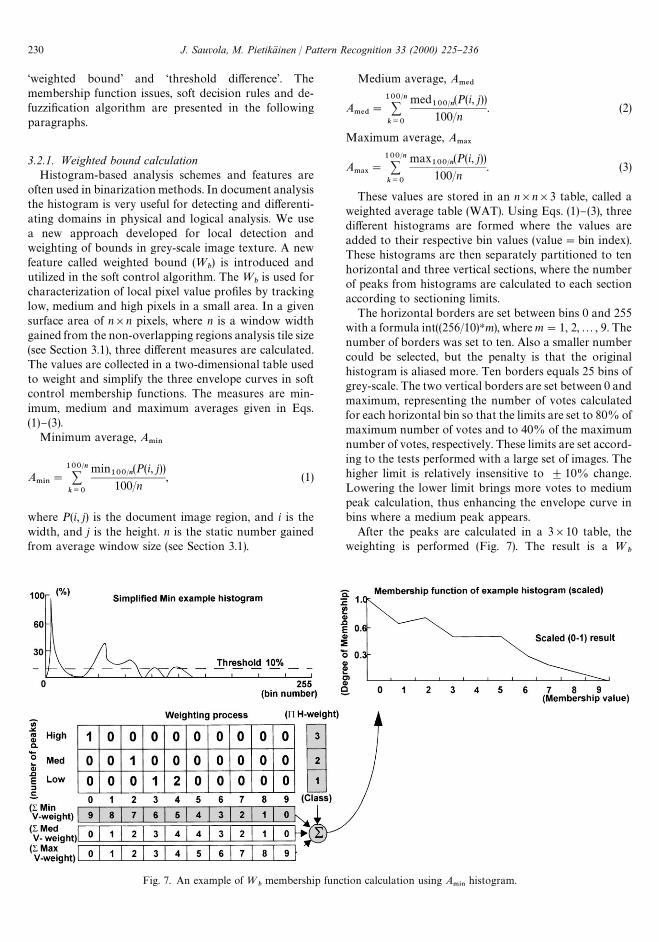
Fig. 2. Examples of document analysis problem types in binarization.
are determined locally, e.g. pixel by pixel, or region byregion. Then, a speci"ed region can have &single thre-shold' that is changed from region to region accordingto threshold candidate selection for a given area. Multi-thresholding is a scheme, where image semantics areevaluated. Then, each pixel can have more than onethreshold value depending on the connectivity or othersemantic dependency related to physical, logical or pic-torial contents.
Many binarization techniques that are used in process-ing tasks are aimed at simplifying and unifying the imagedata at hand. The simpli"cation is performed to bene"tthe oncoming processing characteristics, such as com-putational load, algorithm complexity and real-time re-quirements in industrial-like environments. One of the keyreasons when the binarization step fails to provide thesubsequent processing a high-quality data is caused bythe di!erent types and degrees of degradation introducedto the source image. The reasons for the degradation mayvary from poor source type, the image acquisitionprocess to the environment that causes problemsfor the image quality directly. Since the degradation isunquestionably one of the main reasons for processing tofail, it is very important to design the binarizationtechnique to detect and "lter possible imperfectionsfrom becoming the subject for processing and potentialcause of errors for post-processing steps. Most degrada-tion types in document images a!ect both physicaland semantic understandability in the document analysistasks, such as page segmentation, classi"cation and
optical character recognition. Therefore, the result afterall the desired processing steps can be entirely unac-ceptable, just because of the poorly performed bina-rization.
Fig. 2 depicts two types of typical degradation, whendealing with scanned grey-scale document images. InFig. 2a the threshold &base line' is changing due to illu-mination e!ect or implanted (designed) entity. Then, eachobject has a di!erent base level that a!ects the object/non-object separation decision in selecting threshold(s).In Fig. 2b a general type &stain problem' is presented.In this case, the background and object levels are #uctu-ating from clear separation to non-clear separation andsmall level di!erence between object/non-object. The op-timal threshold lines are drawn to both images to depictthe base line that a successful binarization algorithmshould mimic.
Fig. 3 presents another type of problem, frequentlyoccurring in scanned document images: more thantwo di!erent levels are visible in textual areas due totransparency of the next page. Then, a binarization algo-rithm should cope with at least two di!erent thresholdcandidates: background-transparent text and back-ground-text. The binarized example presents a correctbinarization result.
1.1. Survey on document image binarization techniques
The research on binarization techniques originatesfrom the traditional &scene image' processing needs to
226 J. Sauvola, M. Pietika( inen / Pattern Recognition 33 (2000) 225}236
Fig. 3. Example of good binarization on degraded sample image.
optimize the image processing tasks in terms of imagedata at hand. While the image types have become morecomplex the algorithms developed have gained widertheoretical grounds. Current trend seems to move for-ward image domain understanding based binarizationand the control of di!erent source image types and quali-ties. The state-of-the-art techniques are able to adapt tosome degree of errors in a de"ned category, and focus onfew image types. In images needing multi-thresholding,the problem seems to be ever harder to solve, since thecomplexity of image contents, including textual docu-ments has increased rapidly.
Some document directed binarization algorithms havebeen developed. O'Gorman [3] proposes a global ap-proach calculated from a measure of local connectivityinformation. The thresholds are found at the intensitylevels aiming to preserve the connectivity of regions. Liuet al. [4] propose a method for document image binariz-ation focused on noisy and complex background prob-lems. They use grey-scale and run-length histogramanalysis in a method called &object attribute thre-sholding'. It identi"es a set of global thresholds usingglobal techniques which is used for "nal threshold selec-tion utilizing local features.
Yang et al.'s [5] thresholding algorithm uses a statist-ical measurement, called &largest static state di!erence'.The method aims to track changes in the statistical signalpattern, dividing the level changes to static or transientaccording to a grey-level variation. The threshold value iscalculated according to static and transient propertiesseparately at each pixel. Stroke connectivity preservationissues in textual images are examined by Chang et al. inRef. [6]. They propose an algorithm that uses two di!er-ent components: the background noise elimination usinggrey-level histogram equalization and enhancement ofgrey-levels of characters in the neighbourhood using anedge image composition technique. The &binary par-titioning' is made according to a smoothed and equalizedhistogram information calculated in "ve di!erent steps.
Pavlidis [7] presents a technique based on the obser-vation that after blurring a bi-level image, the intensity oforiginal pixels is related with the sign of the curvature ofthe pixels of the blurred image. This property is used toconstruct the threshold selection of partial histograms inlocations where the curvature is signi"cant.
Rosenfeld and Smith [8] presented a global thresh-olding algorithm to deal with noise problem using an
iterative probabilistic model when separating back-ground and object pixels. A relaxation process was usedto reduce errors by "rst classifying pixels probabilisti-cally and adjusting their probabilities using the neigh-bouring pixels. This process is "nally iterated leading tothreshold selection, where the probabilities of the back-ground and the object pixels are increased and will beruled accordingly to non-object and object pixels.
The thresholding algorithm by Perez and Gonzalez[9] was designed to manage situations where imperfectillumination occurs in an image. The bimodal re#ectancedistribution is utilized to present grey-scale with twocomponents: re#ectance r and illumination i, used also inhomomorphic "ltering. The algorithm is based on themodel of Taylor series expansion and uses no a prioriknowledge of the image. The illumination is assumedto be relatively smooth, whereas the re#ectance compon-ent is used to track down changes. The threshold value ischosen from the probabilistic criterion of occurring two-dimensional threshold selection function. This can becalculated in raster-scan fashion.
The illumination problem is emphasized in the thre-sholding algorithm, called &edge level thresholding',presented by Parker et al. in Ref. [10]. Their approachuses the principles that objects provide high spatial fre-quency while illumination consist mainly of low spatialfrequencies. The algorithm "rst identi"es objects usingShen}Castan edge detector. The grey-levels are thenexamined in small windows for "nding highest andlowest values that indicate object and background. Theaverage of these values are used to determine the thre-shold. The selected value is then "tted to all pixels asa surface leading the values above to be judged as a partof an object and a value lower than threshold belongs tobackground.
Shapiro et al. [11] introduce a global thresholdingscheme, where the independency is stressed in the ob-ject/background areas ratio, intensity transition slope,object/background shape and noise-insensitivity. Thethreshold selection is done by choosing a value thatmaximizes the global non-homogeneity. This is obtainedas an integral of weighted local deviations, where theweight function assign higher standard weight deviationin case of background/object transitions than in homo-geneous areas.
Pikaz and Averbuch [12] propose an algorithm toperform thresholding for scenes containing distinct
J. Sauvola, M. Pietika( inen / Pattern Recognition 33 (2000) 225}236 227
Fig. 4. Overview of the binarization algorithm.
objects. The sequence of graphs is constructed using thesize of connected objects in pixels as a classi"er. Thethreshold selection is gained from calculating stablestates on the graph. The algorithm can be adapted toselect multi-level thresholds by selecting highest stablestate candidate in each level.
Henstock and Chelberg [13] propose a statisticalmodel-based threshold selection. The weighted sum oftwo gamma densities, used for decreasing the computa-tional load instead of normal distributions, are "tted tothe sum of edge and non-edge density functions usinga "ve-parameter model. The parameters are estimatedusing an expectation maximization-style two-step algo-rithm. The "tted weighted densities separate the edgepixels from non-edge pixels of intensity images.
The enhanced speed entropic threshold selection algo-rithm is proposed in Ref. [14] by Chen et al. They reducethe image grey-scale levels by quantization and produce aglobal threshold candidate vector from quantized image.The "nal threshold selection is estimated only from thereduced image using the candidate vector. The reductionin computational complexity is in the order of magnitudeof O(G8@3) of the number of grey-scale values, using O-notation. The quality of binarization is su$cient forpreliminary image segmentation purposes.
Yanowitz and Bruckstein [15] proposed an imagesegmentation algorithm based on adaptive binarization,where di!erent image quality problems were taken intoconsideration. Their algorithm aimed to separate objectsin illuminated or degraded conditions. The techniqueuses variating thresholds, whose values are judged byedge analysis processing combined with grey-level in-formation and construction of interpolated thresholdsurface. The image is then segmented using the gainedthreshold surface by identifying the objects by post-vali-dation. The authors indicated that validation can beperformed with most of the segmentation methods.
1.2. Our approach
For document image binarization, we propose a newmethod that "rst performs a rapid classi"cation of thelocal contents of a page to background, pictures and text.Two di!erent approaches are then applied to de"ne athreshold for each pixel: a soft decision method (SDM)for background and pictures, and a specialized text bi-
narization method (TBM) for textual and linedrawingareas. The SDM includes noise "ltering and signal track-ing capabilities, while the TBM is used to separate textcomponents from background in bad conditions, causedby uneven (il)lumination or noise. Finally, the outcome ofthese algorithms are combined.
Utilizing proper ways to benchmark the algorithmresults against ground-truth and other measures is im-portant for guiding the algorithm selection process anddirections that future research should take. A well-de-"ned performance evaluation shows which capabilitiesof the algorithm still need re"nement and which capabili-ties are su$cient for a given situation. The result ofbenchmarking o!ers information of the suitability of thetechnique to certain image domains and quality. How-ever, it is not easy to see the algorithm quality directlyfrom a set of performance values. In this paper we use agoal-directed evaluation process with specially developeddocument image binarization metrics and measures forcomparing the results against a number of well-knownand well-performed techniques in the literature [16].
2. Overview of the binarization technique
Our binarization technique is aimed to be used as a"rst stage in various document analysis, processing andretrieval tasks. Therefore, the special document charac-teristics, like textual properties, graphics, line-drawingsand complex mixtures of their layout-semantics shouldbe included in the requirements. On the other hand, thetechnique should be simple while taking all the documentanalysis demands into consideration. Fig. 4 presents thegeneral approach of the binarization processing #ow.Since typical document segmentation and labelling forcontent analysis is out of question in this phase, we usea rapid hybrid switch that dispatches the small, resolu-tion adapted windows to textual (1) and non-textual(2) threshold evaluation techniques. The switch was de-veloped to cover most generic appearances of typicaldocument layout types and can easily be modi"ed forothers as well. The threshold evaluation techniques areadapted to textual and non-textual area properties, withthe special tolerance and detection to di!erent basicdefect types that are usually introduced to images. Theoutcome of these techniques represent a threshold value
228 J. Sauvola, M. Pietika( inen / Pattern Recognition 33 (2000) 225}236
Fig. 5. Interpolation options for binarization computation.
proposed for each pixel, or every nth pixel, decided bythe user. These values are used to collect the "nal out-come of the binarization by a threshold control module.The technique also enables the utilization of multi-thre-sholds region by region of globally, if desired.
3. Adaptive binarization
The document image contains di!erent surface (tex-ture) types that can be divided into uniform, di!erenti-ating and transiently changing. The texture contained inpictures and background can usually be classi"ed touniform or di!erentiating categories, while the text, linedrawings, etc. have more transient properties by nature.
Our approach is to analyse the local document imagesurface in order to decide on the binarization methodneeded (Fig. 4). During this decision, a &hybrid switching'module selects one of two specialized binarization algo-rithms to be applied to the region. The goal of thebinarization algorithms is to produce an optimal thre-shold value for each pixel. A fast option is to compute"rst a threshold for every nth pixel and then use interpo-lation for the rest of the pixels (Fig. 5).
The binarization method can also be set to bypass thehybrid switch phase. Then the user can choose whichalgorithm is selected for thresholding. All other modulesfunction in the same way as in hybrid conditions.
The following subsection describes the region type andswitching algorithms. The two di!erent binarization al-gorithms are then discussed in detail. The "nal binariz-ation is performed using the proposed threshold values.This process is depicted in the last subsection.
3.1. Region analysis and switching
Threshold computation is preceded by the selection ofthe proper binarization method based on an analysis oflocal image properties. First, the document image is tiledto equal sized rectangular windows of 10}20 pixels wide,corresponding to the resolution that linearly varies be-tween '75 and (300 dpi. Two simple features are thencomputed for each window; these results are used toselect the method.
The "rst feature is simply the average grey value ofa window. The second feature, &transient di!erence',measures local changes in contrast (Eq. (4)). The dif-ference values are accumulated in each subwindow and
then scaled between 0 and 1. Using the limits of 10,15 and 30% of scaled values, the transient di!erenceproperty is de"ned as &uniform', &near-uniform', &di!ering'or &transient'. This coarse division is made according toaverage homogeneity on the surface. According to theselabels, a vote is given to corresponding binarizationmethod that is to be used in a window. The labels&uniform' and &near-uniform' correspond to backgroundand &scene' pictures, and give votes to the SDM. Thelabels &di!ering' and &transient' give their votes to theTBM method.
Selection of a binarization algorithm is then performedas following example rules (1, 2) show:
1. If the average is high and a global histogram peak is inthe same quarter of the histogram and transient di!er-ence is transient, then use SDM.
2. If the average is medium and a global histogram peakis not in the same quarter of the histogram and transi-ent di!erence is uniform, then use TBM.
An example result of image partitioning is shown inFig. 6. The white regions are guided to the SDM algo-rithm, while the grey regions are binarized with the TBMalgorithm.
3.2. Binarization of non-textual components
As in soft control applications, our algorithm "rstanalyses the window surface by calculating descriptivecharacteristics. Then, the soft control algorithm is ap-plied to every nth pixel (Fig. 5). The result is a localthreshold based on local region characteristics.
To ensure local adaptivity of threshold selection, weuse two di!erent types of locally calculated features:
Fig. 6. Example of region partitioning for algorithm(SDM/TBM) selection.
J. Sauvola, M. Pietika( inen / Pattern Recognition 33 (2000) 225}236 229
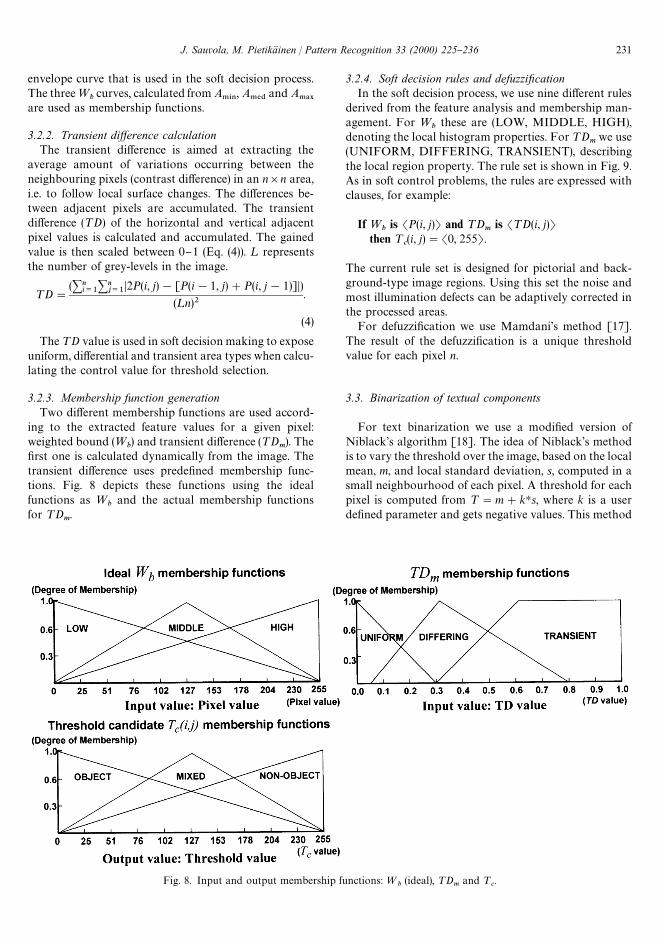
Fig. 7. An example of =bmembership function calculation using A
.*/histogram.
&weighted bound' and &threshold di!erence'. Themembership function issues, soft decision rules and de-fuzzi"cation algorithm are presented in the followingparagraphs.
3.2.1. Weighted bound calculationHistogram-based analysis schemes and features are
often used in binarization methods. In document analysisthe histogram is very useful for detecting and di!erenti-ating domains in physical and logical analysis. We usea new approach developed for local detection andweighting of bounds in grey-scale image texture. A newfeature called weighted bound (=
b) is introduced and
utilized in the soft control algorithm. The=bis used for
characterization of local pixel value pro"les by trackinglow, medium and high pixels in a small area. In a givensurface area of n]n pixels, where n is a window widthgained from the non-overlapping regions analysis tile size(see Section 3.1), three di!erent measures are calculated.The values are collected in a two-dimensional table usedto weight and simplify the three envelope curves in softcontrol membership functions. The measures are min-imum, medium and maximum averages given in Eqs.(1)} (3).
Minimum average, A.*/
A.*/
"
100@n+k/0
min100@n
(P(i, j))
100/n, (1)
where P(i, j) is the document image region, and i is thewidth, and j is the height. n is the static number gainedfrom average window size (see Section 3.1).
Medium average, A.%$
A.%$
"
100@n+k/0
med100@n
(P(i, j))
100/n. (2)
Maximum average, A.!9
A.!9
"
100@n+k/0
max100@n
(P(i, j))
100/n. (3)
These values are stored in an n]n]3 table, called aweighted average table (WAT). Using Eqs. (1)} (3), threedi!erent histograms are formed where the values areadded to their respective bin values (value"bin index).These histograms are then separately partitioned to tenhorizontal and three vertical sections, where the numberof peaks from histograms are calculated to each sectionaccording to sectioning limits.
The horizontal borders are set between bins 0 and 255with a formula int((256/10)Hm), where m"1, 2,2, 9. Thenumber of borders was set to ten. Also a smaller numbercould be selected, but the penalty is that the originalhistogram is aliased more. Ten borders equals 25 bins ofgrey-scale. The two vertical borders are set between 0 andmaximum, representing the number of votes calculatedfor each horizontal bin so that the limits are set to 80% ofmaximum number of votes and to 40% of the maximumnumber of votes, respectively. These limits are set accord-ing to the tests performed with a large set of images. Thehigher limit is relatively insensitive to $10% change.Lowering the lower limit brings more votes to mediumpeak calculation, thus enhancing the envelope curve inbins where a medium peak appears.
After the peaks are calculated in a 3]10 table, theweighting is performed (Fig. 7). The result is a =
b
230 J. Sauvola, M. Pietika( inen / Pattern Recognition 33 (2000) 225}236
Fig. 8. Input and output membership functions:=b(ideal), ¹D
mand ¹
c.
envelope curve that is used in the soft decision process.The three=
bcurves, calculated from A
.*/, A
.%$and A
.!9are used as membership functions.
3.2.2. Transient diwerence calculationThe transient di!erence is aimed at extracting the
average amount of variations occurring between theneighbouring pixels (contrast di!erence) in an n]n area,i.e. to follow local surface changes. The di!erences be-tween adjacent pixels are accumulated. The transientdi!erence (¹D) of the horizontal and vertical adjacentpixel values is calculated and accumulated. The gainedvalue is then scaled between 0}1 (Eq. (4)). ¸ representsthe number of grey-levels in the image.
¹D"
(+ni/1
+nj/1
D2P(i, j)![P(i!1, j)#P(i, j!1)]D)(¸n)2
.
(4)
The ¹D value is used in soft decision making to exposeuniform, di!erential and transient area types when calcu-lating the control value for threshold selection.
3.2.3. Membership function generationTwo di!erent membership functions are used accord-
ing to the extracted feature values for a given pixel:weighted bound (=
b) and transient di!erence (¹D
m). The
"rst one is calculated dynamically from the image. Thetransient di!erence uses prede"ned membership func-tions. Fig. 8 depicts these functions using the idealfunctions as =
band the actual membership functions
for ¹Dm.
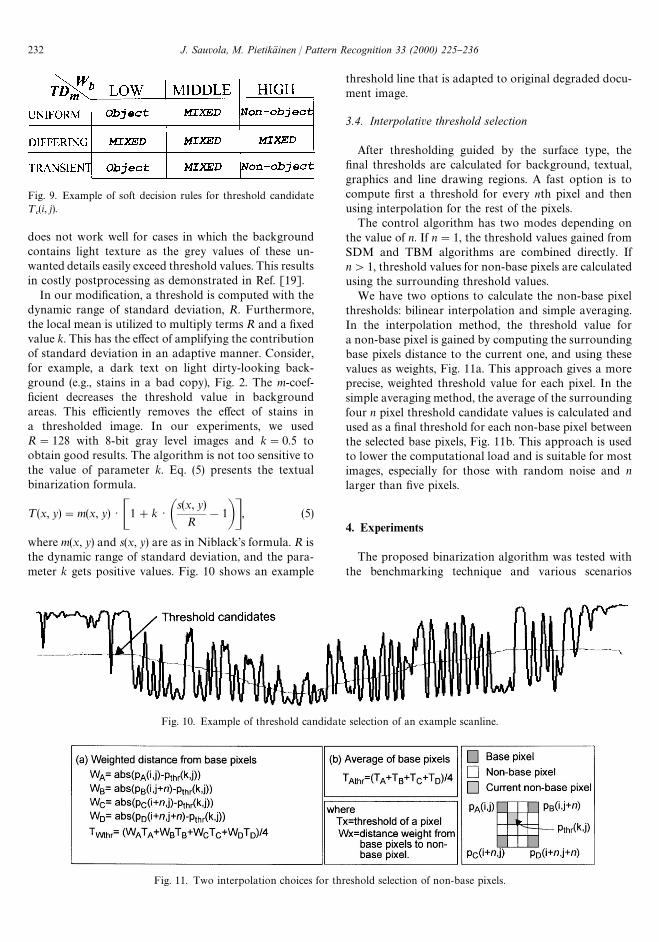
3.2.4. Soft decision rules and defuzzixcationIn the soft decision process, we use nine di!erent rules
derived from the feature analysis and membership man-agement. For =
bthese are (LOW, MIDDLE, HIGH),
denoting the local histogram properties. For ¹Dm
we use(UNIFORM, DIFFERING, TRANSIENT), describingthe local region property. The rule set is shown in Fig. 9.As in soft control problems, the rules are expressed withclauses, for example:
If=bis SP(i, j)T and ¹D
mis S¹D(i, j)T
then ¹c(i, j)"S0, 255T.
The current rule set is designed for pictorial and back-ground-type image regions. Using this set the noise andmost illumination defects can be adaptively corrected inthe processed areas.
For defuzzi"cation we use Mamdani's method [17].The result of the defuzzi"cation is a unique thresholdvalue for each pixel n.
3.3. Binarization of textual components
For text binarization we use a modi"ed version ofNiblack's algorithm [18]. The idea of Niblack's methodis to vary the threshold over the image, based on the localmean, m, and local standard deviation, s, computed in asmall neighbourhood of each pixel. A threshold for eachpixel is computed from ¹"m#kHs, where k is a userde"ned parameter and gets negative values. This method
J. Sauvola, M. Pietika( inen / Pattern Recognition 33 (2000) 225}236 231
Fig. 10. Example of threshold candidate selection of an example scanline.
Fig. 11. Two interpolation choices for threshold selection of non-base pixels.
Fig. 9. Example of soft decision rules for threshold candidate¹
c(i, j).
does not work well for cases in which the backgroundcontains light texture as the grey values of these un-wanted details easily exceed threshold values. This resultsin costly postprocessing as demonstrated in Ref. [19].
In our modi"cation, a threshold is computed with thedynamic range of standard deviation, R. Furthermore,the local mean is utilized to multiply terms R and a "xedvalue k. This has the e!ect of amplifying the contributionof standard deviation in an adaptive manner. Consider,for example, a dark text on light dirty-looking back-ground (e.g., stains in a bad copy), Fig. 2. The m-coef-"cient decreases the threshold value in backgroundareas. This e$ciently removes the e!ect of stains ina thresholded image. In our experiments, we usedR"128 with 8-bit gray level images and k"0.5 toobtain good results. The algorithm is not too sensitive tothe value of parameter k. Eq. (5) presents the textualbinarization formula.
¹(x, y)"m(x, y) ) C1#k ) As(x, y)
R!1BD, (5)
where m(x, y) and s(x, y) are as in Niblack's formula. R isthe dynamic range of standard deviation, and the para-meter k gets positive values. Fig. 10 shows an example
threshold line that is adapted to original degraded docu-ment image.
3.4. Interpolative threshold selection
After thresholding guided by the surface type, the"nal thresholds are calculated for background, textual,graphics and line drawing regions. A fast option is tocompute "rst a threshold for every nth pixel and thenusing interpolation for the rest of the pixels.
The control algorithm has two modes depending onthe value of n. If n"1, the threshold values gained fromSDM and TBM algorithms are combined directly. Ifn'1, threshold values for non-base pixels are calculatedusing the surrounding threshold values.
We have two options to calculate the non-base pixelthresholds: bilinear interpolation and simple averaging.In the interpolation method, the threshold value fora non-base pixel is gained by computing the surroundingbase pixels distance to the current one, and using thesevalues as weights, Fig. 11a. This approach gives a moreprecise, weighted threshold value for each pixel. In thesimple averaging method, the average of the surroundingfour n pixel threshold candidate values is calculated andused as a "nal threshold for each non-base pixel betweenthe selected base pixels, Fig. 11b. This approach is usedto lower the computational load and is suitable for mostimages, especially for those with random noise and nlarger than "ve pixels.
4. Experiments
The proposed binarization algorithm was tested withthe benchmarking technique and various scenarios
232 J. Sauvola, M. Pietika( inen / Pattern Recognition 33 (2000) 225}236
Fig. 12. Visual and numeric results on the comparison algorithms applied to illuminated, textual images.
against several known binarization techniques in theliterature [18,20}22]. Using the environment factors(such as di!erent degradations) and available documentand test image databases the algorithm results wereevaluated and benchmarked against each other, againstthe ground-truth knowledge by visual and benchmarkevent(s) evaluation processes. The focus was set on docu-ments with textual content and on multi-content docu-ments, i.e. documents having text, graphics, linedrawingsand halftone. The test images were selected from a specialdatabase of document image categories, comprisingover 1000 categorized document images (e.g. article, let-ter, memo, fax, journal, scienti"c, map, advertisement,etc.) [23].
The numerical test and results presented were gainedusing binarization metrics emphasizing the performancein textual image region binarization. Fig. 12 presents anexample benchmarking scene performed to a database of15 textual document images having illumination. Visualresults to a sample input image having 20% of centeredillumination defect, an example of a ground-truth imagemap and the results of the proposed and comparisonbinarization algorithms. The results show good behav-iour of Sauvola's, Niblack's and Eikvil's algorithms,when the limit is set to 80% performance, i.e. the limitwhere the OCR performance drop is less than 10% usingCaere Omnipage OCR package [24]. Bernsen su!ered ofnoise that was introduced to binarized result image,while the Eikvil's threshold ruled some of the darkestareas belong to object pixels. Parker's algorithm adaptedpoorly to even small changes in lumination, but hadsu$cient results with relatively &clean' grey-scale docu-ment images.
The visual tests performed for a synthetic test imagedatabase were based on ranking according to di!erent
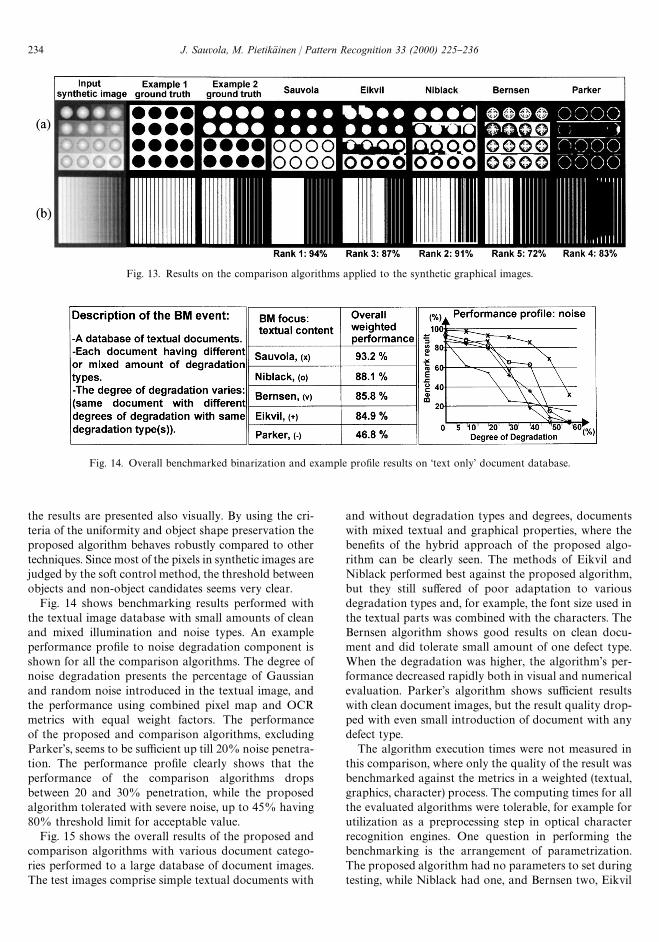
objectives set for these types of images. The purpose ofthe synthetic image database is to allow visual analysis ofthe nature and behaviour of the benchmarking techniquein a di!erent kind of situation, e.g. in edge preservation,the object uniformity preservation, in changing/varyingbackground, etc. This is aimed to aid the suitabilityselection of di!erent algorithm to di!ering environ-mental conditions in terms of adaptability to changes,shape management, object preservation, homogeneous-ness of region preservation, and so on. An example of thevisual results on synthetic images is shown in Fig. 13.
Fig. 13 shows visually the results of our, and compari-son, algorithms applied to synthetic grey-scale imageshaving di!erent/di!ering kind of background(s), ob-ject(s), line(s), directions and shapes complying with cer-tain simple test setting rules. As the input grey-scaleimages were synthetically generated, a set of ground-truth images were generated focusing in di!erent areas ofinterest in measuring the algorithm performance andbehaviour. Therefore, the benchmark results are depen-dent on the selection of the ground-truth set used, i.e. thetarget performance group the algorithm behaviour. Forexample, the ground-truth criteria of object uniformityand edge preservation were tested using ground-truthimage in Fig. 13a. The object edge and background/object uniformity was used as a weight criteria, where theEuclidean distance was used as a distance measurebetween the result and the ground-truth pixel maps.Fig. 13b shows a situation, where the synthetic image hasuniformly gliding background from white to black, andthin lines, whose grey-scale value glides on the oppositedirection from the background. The test evaluation cri-terium was set on di!erentiating lines from backgroundand uniformity of the background. Since the results arehighly dependent on the target aims of the binarization,
J. Sauvola, M. Pietika( inen / Pattern Recognition 33 (2000) 225}236 233
Fig. 13. Results on the comparison algorithms applied to the synthetic graphical images.
Fig. 14. Overall benchmarked binarization and example pro"le results on &text only' document database.
the results are presented also visually. By using the cri-teria of the uniformity and object shape preservation theproposed algorithm behaves robustly compared to othertechniques. Since most of the pixels in synthetic images arejudged by the soft control method, the threshold betweenobjects and non-object candidates seems very clear.
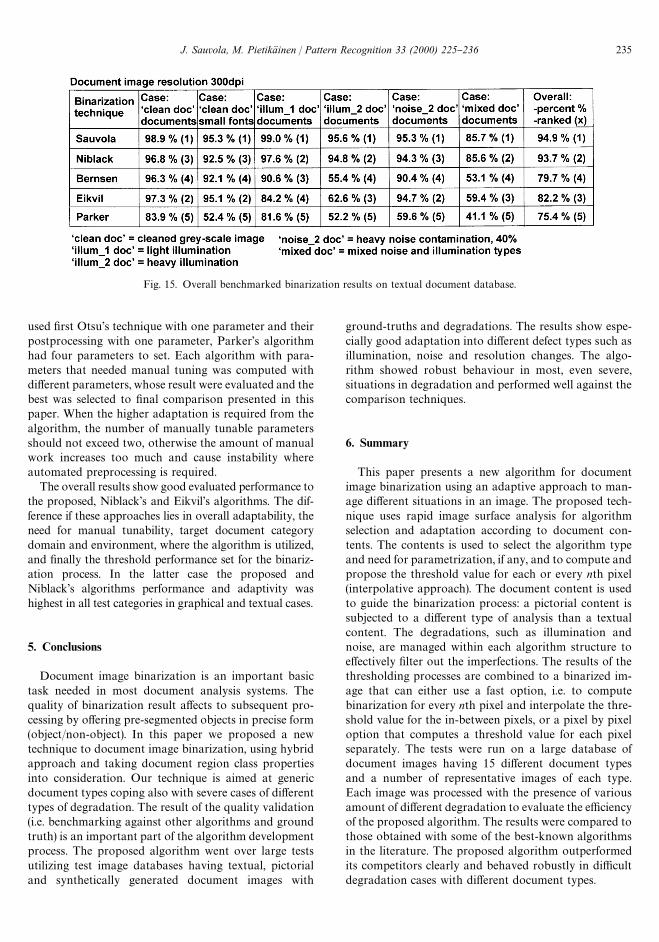
Fig. 14 shows benchmarking results performed withthe textual image database with small amounts of cleanand mixed illumination and noise types. An exampleperformance pro"le to noise degradation component isshown for all the comparison algorithms. The degree ofnoise degradation presents the percentage of Gaussianand random noise introduced in the textual image, andthe performance using combined pixel map and OCRmetrics with equal weight factors. The performanceof the proposed and comparison algorithms, excludingParker's, seems to be su$cient up till 20% noise penetra-tion. The performance pro"le clearly shows that theperformance of the comparison algorithms dropsbetween 20 and 30% penetration, while the proposedalgorithm tolerated with severe noise, up to 45% having80% threshold limit for acceptable value.
Fig. 15 shows the overall results of the proposed andcomparison algorithms with various document catego-ries performed to a large database of document images.The test images comprise simple textual documents with
and without degradation types and degrees, documentswith mixed textual and graphical properties, where thebene"ts of the hybrid approach of the proposed algo-rithm can be clearly seen. The methods of Eikvil andNiblack performed best against the proposed algorithm,but they still su!ered of poor adaptation to variousdegradation types and, for example, the font size used inthe textual parts was combined with the characters. TheBernsen algorithm shows good results on clean docu-ment and did tolerate small amount of one defect type.When the degradation was higher, the algorithm's per-formance decreased rapidly both in visual and numericalevaluation. Parker's algorithm shows su$cient resultswith clean document images, but the result quality drop-ped with even small introduction of document with anydefect type.
The algorithm execution times were not measured inthis comparison, where only the quality of the result wasbenchmarked against the metrics in a weighted (textual,graphics, character) process. The computing times for allthe evaluated algorithms were tolerable, for example forutilization as a preprocessing step in optical characterrecognition engines. One question in performing thebenchmarking is the arrangement of parametrization.The proposed algorithm had no parameters to set duringtesting, while Niblack had one, and Bernsen two, Eikvil
234 J. Sauvola, M. Pietika( inen / Pattern Recognition 33 (2000) 225}236
Fig. 15. Overall benchmarked binarization results on textual document database.
used "rst Otsu's technique with one parameter and theirpostprocessing with one parameter, Parker's algorithmhad four parameters to set. Each algorithm with para-meters that needed manual tuning was computed withdi!erent parameters, whose result were evaluated and thebest was selected to "nal comparison presented in thispaper. When the higher adaptation is required from thealgorithm, the number of manually tunable parametersshould not exceed two, otherwise the amount of manualwork increases too much and cause instability whereautomated preprocessing is required.
The overall results show good evaluated performance tothe proposed, Niblack's and Eikvil's algorithms. The dif-ference if these approaches lies in overall adaptability, theneed for manual tunability, target document categorydomain and environment, where the algorithm is utilized,and "nally the threshold performance set for the binariz-ation process. In the latter case the proposed andNiblack's algorithms performance and adaptivity washighest in all test categories in graphical and textual cases.
5. Conclusions
Document image binarization is an important basictask needed in most document analysis systems. Thequality of binarization result a!ects to subsequent pro-cessing by o!ering pre-segmented objects in precise form(object/non-object). In this paper we proposed a newtechnique to document image binarization, using hybridapproach and taking document region class propertiesinto consideration. Our technique is aimed at genericdocument types coping also with severe cases of di!erenttypes of degradation. The result of the quality validation(i.e. benchmarking against other algorithms and groundtruth) is an important part of the algorithm developmentprocess. The proposed algorithm went over large testsutilizing test image databases having textual, pictorialand synthetically generated document images with
ground-truths and degradations. The results show espe-cially good adaptation into di!erent defect types such asillumination, noise and resolution changes. The algo-rithm showed robust behaviour in most, even severe,situations in degradation and performed well against thecomparison techniques.
6. Summary
This paper presents a new algorithm for documentimage binarization using an adaptive approach to man-age di!erent situations in an image. The proposed tech-nique uses rapid image surface analysis for algorithmselection and adaptation according to document con-tents. The contents is used to select the algorithm typeand need for parametrization, if any, and to compute andpropose the threshold value for each or every nth pixel(interpolative approach). The document content is usedto guide the binarization process: a pictorial content issubjected to a di!erent type of analysis than a textualcontent. The degradations, such as illumination andnoise, are managed within each algorithm structure toe!ectively "lter out the imperfections. The results of thethresholding processes are combined to a binarized im-age that can either use a fast option, i.e. to computebinarization for every nth pixel and interpolate the thre-shold value for the in-between pixels, or a pixel by pixeloption that computes a threshold value for each pixelseparately. The tests were run on a large database ofdocument images having 15 di!erent document typesand a number of representative images of each type.Each image was processed with the presence of variousamount of di!erent degradation to evaluate the e$ciencyof the proposed algorithm. The results were compared tothose obtained with some of the best-known algorithmsin the literature. The proposed algorithm outperformedits competitors clearly and behaved robustly in di$cultdegradation cases with di!erent document types.
J. Sauvola, M. Pietika( inen / Pattern Recognition 33 (2000) 225}236 235
About the Author*JAAKKO SAUVOLA is a Professor and Director of the Media Team research group in the University of Oulu,Finland, and a member of the a$liated faculty at the LAMP Laboratory, Center for Automation Research, University of Maryland,USA. Dr. Sauvola is also a Research Manager in Nokia Telecommunications, where his responsibilities cover value adding telephonyservices. Dr. Sauvola is a member of several scienti"c committees and programs. His research interests include computer-telephonyintegration, media analysis, mobile multimedia, media telephony and content-based retrieval systems.
About the Author*MATTI PIETIKAG INEN received his Doctor of Technology degree in Electrical Engineering from the University ofOulu, Finland, in 1982. From 1980 to 1981 and from 1984 to 1985 he was a visiting researcher in the Computer Vision Laboratory of theUniversity of Maryland, USA. Currently, he is a Professor of Information Technology, Scienti"c Director of Infotech Oulu researchcenter, and Director of Machine Vision and Media Processing Group at the University of Oulu. His research interests cover variousaspects of image analysis and machine vision, including texture analysis, color machine vision and document analysis. His research hasbeen widely published in journals, books and conferences. He was the editor (with L.F. Pau) of the book `Machine Vision for AdvancedProductiona, published by World Scienti"c in 1996. Prof. PietikaK inen is one of the founding Fellows of the International Association forPattern Recognition (IAPR) and a Senior Member of IEEE, and serves as Member of the Governing Board of IAPR. He also serves onprogram committees of several international conferences.
Acknowledgements
The support from the Academy of Finland and Tech-nology Development Centre is gratefully acknowledged.We also thank Dr. Tapio Seppanen and Mr. SamiNieminen for their contributions.
References
[1] J. Sauvola, M. PietikaK inen, Page segmentation and classi-"cation using fast feature extraction and connectivity anal-ysis, International Conference on Document Analysisand Recognition, ICDAR '95, Montreal, Canada, 1995,pp. 1127}1131.
[2] H. Baird, Document image defect models, Proceedings ofthe IAPR Workshop on Syntactic and Structural PatternRecognition, 1990, pp. 38}46.
[3] L. O'Gorman, Binarization and multithresholding ofdocument images using connectivity, CVGIP: Graph.Models Image Processing 56 (6) (1994) 496}506.
[4] Y. Liu, R. Fenrich, S.N. Srihari, An object attribute thre-sholding algorithm for document image binarization, In-ternational Conference on Document Analysis and Recog-nition, ICDAR '93, Japan, 1993, pp. 278}281.
[5] J. Yang, Y. Chen, W. Hsu, Adaptive thresholding algo-rithm and its hardware implementation, Pattern Recogni-tion Lett. 15 (2) (1994) 141}150.
[6] M. Chang, S. Kang, W. Rho, H. Kim, D, Kim, Improvedbinarization algorithm for document image by histogramand edge detection, International Conference for Docu-ment Analysis and Recognition ICDAR '95, Montreal,Canada, 1995, pp. 636}643.
[7] T. Pavlidis, Threshold selection using second derivatives ofthe gray scale image, International Conference on Docu-ment Analysis and Recognition, ICDAR '93, Japan, 1993,pp. 274}277.
[8] A. Rosenfeld, R.C. Smith, Thresholding using relaxation,IEEE Trans. Pattern Anal. Mach. Intell. PAMI-3 (5) (1981)598}606.
[9] A. Perez, R.C. Gonzalez, An iterative thresholding algo-rithm for image segmentation, IEEE Trans. Pattern Anal.Mach. Intell. PAMI-9 (6) (1987) 742}751.
[10] J.R. Parker, C. Jennings, A.G. Salkauskas, Thresholdingusing an illumination model, ICDAR '93, Japan, 1993,pp. 270}273.
[11] V.A. Shapiro, P.K. Veleva, V.S. Sgurev, An adaptivemethod for image thresholding, Proceedings of the 11thKPR, 1992, pp. 696}699.
[12] A. Pikaz, A. Averbuch, Digital image thresholding, basedon topological stable-state, Pattern Recognition 29 (5)(1996) 829}843.
[14] W. Chen, C. Wen, C. Yang, A fast two-dimensional en-tropic thresholding algorithm, Pattern Recognition 27 (7)(1994) 885}893.
[15] S.D. Yanowitz, A.M. Bruckstein, A new method for imagesegmentation, CVGIP 46 (1989) 82}95.
[16] S. Nieminen, J. Sauvola, T. SeppaK nen, M. PietikaK inen,A benchmarking system for document analysis algorithms,Proc. SPIE 3305 Document Recognition V 3305 (1998)100}111.
[17] S.T. Welstead, Neural Network and Fuzzy LogicApplications in C/C##, Wiley, New York, 1994,p. 494.
[18] W. Niblack, An Introduction to Image Processing, Pren-tice-Hall, Englewood Cli!s, NJ, 1986, pp. 115}116.
[19] O.D. Trier, A.K. Jain, Goal-directed evaluation of binari-zation methods, IEEE Trans. Pattern Anal. Mach. Intell.17 (12) (1995) 1191}1201.
[20] L. Eikvil, T. Taxt, K. Moen, A fast adaptive method forbinarization of document images, International Confer-ence on Document Analysis and Recognition, ICDAR '91,France, 1991, pp. 435}443.
[21] J. Bernsen, Dynamic thresholding of grey-level images,Proceedings of the Eighth ICPR, 1986, pp. 1251}1255.
[22] J. Parker, Gray level thresholding on badly illuminatedimages, IEEE Trans. Pattern Anal. Mach. Intell. 13 (8)(1991) 813}819.
[23] J. Sauvola, S. Haapakoski, H. Kauniskangas, T. SeppaK nen,M. PietikaK inen, D. Doermann, A distributed managementsystem for testing document image analysis algorithms,4th ICDAR, Germany, 1997, pp. 989}995.











![Learningngerprintminutiaelocationandtype - … Image Orientation field Binarization Minutiae extraction Thinning Fig.3.Variousstagesinatypicalminutiaeextractionalgorithm[1]. Parallel](https://static.documents.pub/doc/80x56/5ad98d817f8b9a52528bb16e/learningngerprintminutiaelocationandtype-image-orientation-field-binarization.jpg)











