Page 1
Adaptive Virtual Machine Management in the Cloud: A
Performance-Counter-Driven Approach
Abstract. The success of cloud computing technologies heavily depends on
both the underlying hardware and system software support for virtualization. In
this study, we propose to elevate the capability of the hypervisor to monitor and
manage co-running virtual machines (VMs) by capturing their dynamic behav-
ior at runtime and adaptively schedule and migrate VMs across cores to mini-
mize contention on system resources hence maximize the system throughput.
Implemented at the hypervisor level, our proposed scheme does not require any
changes or adjustments to the VMs themselves or the applications running in-
side them, and minimal changes to the host OS. It also does not require any
changes to existing hardware structures. These facts reduce the complexity of
our approach and improve portability at the same time. The main intuition be-
hind our approach is that because the host OS schedules entire virtual machines,
it loses sight of the processes and threads that are running within the VMs; it
only sees the averaged resource demands from the past time slice. In our design,
we sought to recreate some of this low level information by using performance
counters and simple virtual machine introspection techniques. We implemented
an initial prototype on the Kernel Virtual Machine (KVM) and our experimental
results show the presented approach is of great potential to improve the overall
system throughput in the cloud environment.
Keywords: Cloud Computing, Virtual Machine Management, Hardware Per-
formance Counters, Virtualization.
Introduction
Nowadays cloud computing has become pervasive. Common services provided by
the cloud include infrastructure as a service (IaaS), platform as a service (PaaS), and
software as a service (SaaS), among others. Cloud computing has begun to transform
the way enterprises deploy and manage their infrastructures. It provides the founda-
tion for a truly agile enterprise, so that IT can deliver an infrastructure that is flexible,
scalable, and most importantly, economical through efficient resource utilization (Red
Hat, 2009).
One of the key enabling technologies for cloud computing is virtualization, which
offers users the illusion that their remote machine is running the operating system
(OS) of their interest on its own dedicated hardware. But underneath is actually a
completely different case, where different OS images (Virtual Machines) from differ-
ent users may be running on the same physical server simultaneously.
The success of cloud computing technologies heavily depends on both the underly-
ing hardware support for virtualization, such as Intel VT and AMD-V, and the in-
crease in the number of cores contained in modern multi-core multi-threading micro-
Page 2
processors (MMMP). Because a single Virtual Machine (VM) does not normally use
all the hardware resources available on MMMPs, multiple VMs can run simultane-
ously on processors such that the resource utilization on the cloud side can be im-
proved. Aggregately, this means increasing the system throughput in terms of the total
number of VMs supported by the cloud and even reducing the energy cost of the
cloud infrastructure by consolidating the VMs and turning off the resources (proces-
sors) not in usage.
Co-running VMs, however, introduces contention on shared resources in MMMP.
VMs may compete for the computation resources if they are sharing the same core; or
even if they are running on separate cores, they may be competing for the Last Level
Cache (LLC) and memory bandwidth if they are sharing the same die. If not managed
carefully, this contention might cause a significant performance degradation of the
VMs. This is against the original motivation for running them together, and may vio-
late the service level agreement (SLA) between the customer and the cloud service
provider.
Traditionally, load balancing of MMMPs have been under the purview of the OS
scheduler. This is still the case in cloud environments that use hosted virtualization
such as the Kernel Virtual Machine (KVM). In the case of bare-metal virtualization,
the scheduler is implemented as part of the Virtual Machine Monitor (VMM, a.k.a.
hypervisor). Regardless of where the scheduler resides, the scheduler tries to evenly
balance the workload among existing cores. Normally, these workloads are processes
and threads, but in a cloud environment they also include entire virtual machines.
(Note that this is the host scheduler. Each virtual machine will run its own guest OS,
with its own guest scheduler that manages the guest’s processes and threads.) The
hypervisor is unaware of potential contention on processor resources among the con-
current VMs it is managing. On top of that, the VMs (and the processes/threads with-
in them) exhibit different behaviors at different times during their lifetimes, some-
times being computation-intensive, sometimes being memory-intensive, sometimes
being I/O intensive, and other times following a mixed behavior. The fundamental
challenge is the semantic gap, i.e. the hypervisor is unaware of when and which guest
processes and threads are running. In facing this challenge, we propose to elevate the
capability of the hypervisor to monitor and manage the co-running VMs by capturing
their dynamic behavior at runtime using hardware performance counters. Once a per-
formance profile and model has been obtained and computational phases determined,
we then adaptively schedule and migrate VMs across cores according to the predicted
phases (as opposed to process and thread boundaries) to minimize the contention on
system resources hence maximize the system throughput.
The rest of this paper is organized as follows: a review of related published work is
presented in the Related Work section; In the Proposed Scheme section we include a
description of the default Virtual Machine Monitor architecture, we introduce the
hardware performance counters and some events of interest; within this section also
we also introduce our proposed architecture. Next, the Experiment Setup section in-
troduces the hardware and software setups, benchmarks, and workloads created to test
the proposed scheme. The experiments conducted and their respective results are
Page 3
3
presented in the Experimental Results section. Finally, conclusions and future work
are drawn in the Conclusion section.
Related Work
In this section we describe some previous work related to resource contention in
MMMPs, OS thread scheduling considering resource demands, and some works tar-
geting resource management in cloud environment.
Fedorova (2006) described the design and implementation of three scheduling al-
gorithms for chip multithreaded processors that target contention for the second-level
cache. Their experimental results were presented from a simulated dual-core proces-
sor based on the UltraSPARC T1 architecture. Their work also studied the effects of
L2 cache contention on performance for multi-core processors.
Knauerhase, Brett, Hohlt, Li, and Hahn (2008) showed how runtime observations
performed by the OS about threads’ behavior can be used to ameliorate performance
variability and more effectively exploit multi-core processor resources. This work
discusses the idea of distributing benchmarks with a high rate of off-chip requests
across different shared caches. The authors proposed to reduce cache interference by
spreading the intensive applications apart and co-scheduling them with non-intensive
applications. They used cache misses per cycle were as the metric for measuring in-
tensity.
Shelepov et al. (2009) described a scheduling technique for heterogeneous multi-
core systems that does the matching using per-thread architectural signatures. These
signatures are compact summaries of threads’ architectural properties collected of-
fline. Their technique is unable to adapt to thread phase changes. It appears to be ef-
fective for a reduced set of test cases, however it does not scale well since the com-
plexity of using off-line thread profiling becomes very high as the number of threads
increases.
Zhuravlev, Blagodurov, and Fedorova (2010) and Blagodurov, Zhuravlev, and
Fedorova (2010) conducted a study where they analyzed the factors defining the per-
formance in MMMPs and quantified how much performance degradation can be at-
tributed to contention for each shared resource in multi-core systems. They provided a
comprehensive analysis of contention-mitigating techniques that only use scheduling,
and developed scheduling algorithms that schedule threads such that the miss rate is
evenly distributed among the caches. The authors concluded that the highest impact of
contention-aware scheduling techniques is not in improving performance of a work-
load as a whole but in improving quality of service or performance isolation for indi-
vidual applications and in optimizing system energy consumption. They found that
the LLC miss rates turn out to be a very good heuristic for contention for resources
affecting performance in MMMP systems.
Blagodurov and Fedorova (2011) introduced the Clavis scheduler as a user-level
application designed to test efficiency of user-level scheduling algorithms for NUMA
multi-core systems available in Linux. It monitors workloads execution through
hardware performance counters and gather all the necessary information for making a
Page 4
scheduling decision, pass it to the scheduling algorithm and enforce the algorithm’s
decision.
Lugini, Petrucci, and Mosse (2012) proposed PATA (Performance-Asymmetric
Thread Assignment) algorithm, an online thread-to-core assignment policy for heter-
ogeneous multi-core systems. The PATA algorithm works without prior knowledge of
the target system and running workloads and makes thread-to-core assignments deci-
sions based on the threads’ IPS (Instructions committed Per Second). This solution is
proposed to be implemented on top of existing OS scheduling algorithms. Experiment
results showed improvements in workload execution over Linux’s scheduler and an-
other online IPS-driven scheduler.
Petrucci, Loques, Mosse, Melhem, Gazala, and Gobriel (2012) proposed an integer
linear programming model for heterogeneous multi-core systems using thread phase
classification based on combined IPS and LLC misses. Data collected offline was
then used to determine the best thread scheduling for power savings while meeting
thread performance and memory bandwidth guarantees with real-time requirements.
Although previous work discussed so far covers some of the fundamental aspects
of our work, it worth emphasizing that it entirely targets standard workloads managed
by the OS scheduler. None of such studies is oriented towards cloud environment.
Other works have been published in the area of VM resource management.
Nathuji, Kansal, and Ghaffarkhah (2010) developed Q-Clouds, a QoS-aware control
framework that tunes resource allocations to mitigate performance interference ef-
fects. Q-Clouds uses online feedback to build a multi-input multi-output (MIMO)
model that captures performance interference interactions, and uses it to perform
closed loop resource management. Wang, Xu, and Zhao (2012) also proposed to es-
tablish a multi-input-multi-output (MIMO) performance model for co-hosted VMs in
order to capture their coupling behavior using a fuzzy model. Based on their model,
the level of contention on the competing resources is quantified by the model parame-
ters, and later used to assist VM placement and resource allocation decisions. Alt-
hough these works (Nathuji et al., 2010; Wang et al., 2012) attempted to manage
resources in the cloud environment, their effects reside at the system level.
Arteaga, Zhao, Liu, Thanarungroj, and Weng (2010) proposed a cooperative VM
scheduling approach that allows software-level VM scheduler and hardware-level
thread scheduler to cooperate and optimize the allocation of MMMP resources to
VMs. They present an experiment-based feasibility study which confirms the effec-
tiveness of processor contention aware VM scheduling.
Weng and Liu (2010) and Weng, Liu, and Gaudiot (2013) introduced a scheme that
aimed to support a dynamic, adaptive and scalable operating system scheduling policy
for MMMP. They proposed architectural (hardware) strategies to construct linear
models to capture workload behaviors and then schedule threads according to their
resource demands. They employed regression models to ensure that the scheduling
policy is capable of responding to the changing behaviors of threads during execution.
Compared with the static scheduling approach, their phase-triggered scheduling poli-
cy achieved up to 29% speedup.
Our work integrates several aspects mentioned from previous researches and ap-
plies them to the cloud environment. We follow the approach to schedule VMs ac-
Page 5
5
cording their different resource demand in order to mitigate the contention on shared
processor resources between concurrent VMs (Weng et al., 2013; Arteaga et al.,
2010). One significant aspect of our approach is that it acts online at runtime, which
does not require a priori information about the VMs. The information pertaining to
each VM begins to be collected after it has been launched, and so is its behavioral
model. These features greatly improve over previous off-line profiling-based ap-
proaches. In addition, our approach is autonomous, which executes transparently to
the VMs because it does not require any changes or adjustments made to the VMs
themselves or the applications running inside them, nor to the host OS. It also does
not require any changes to existing hardware structures. These facts allow the com-
plexity of applying our scheme to be kept very low, in the meantime improve the
portability of our scheme.
Proposed Scheme
Default Virtual Machine Monitor Architecture
As mentioned earlier, in a virtualized environment, the hypervisor is responsible
for creating and running the virtual machines. We implemented our initial prototype
on the Kernel Virtual Machine (KVM) hypervisor.
KVM (http://www.linux-kvm.org/) is a full virtualization solution for Linux that
can run unmodified guest images. It has been included in the mainline Linux kernel
since 2.6.20 and is implemented as a loadable kernel module that converts the Linux
kernel into a bare metal hypervisor. KVM relies on hardware (CPUs) containing vir-
tualization extensions like Intel VT-X or AMD-V, leveraging those features to virtu-
alize the CPU.
In the KVM architecture, the VMs are mapped to regular Linux processes (i.e.
QEMU processes) and are scheduled by the standard Linux scheduler. This allows
KVM to benefit from all the features of the Linux kernel such as memory manage-
ment, hardware device drivers, etc. Device emulation is handled by QEMU. It pro-
vides emulated BIOS, PCI bus, USB bus and a standard set of devices such as IDE
and SCSI disk controllers, network cards, etc. (Red Hat, 2009). Figure 1(a) shows the
default system architecture with KVM sitting in between the VMs and the physical
hardware, at the host OS level.
Hardware Performance Counters
Hardware Performance Counters (HPC) are special hardware registers available on
most modern processors. These registers can be used to count the number of occur-
rence of certain types of hardware events such as: instructions executed, cache-misses
suffered, and branches mispredicted. These events are counted without slowing down
the kernel or applications because they use dedicated hardware that does not incur any
additional overhead. Although originally implemented for debugging hardware de-
signs during development, performance tuning purposes, or identifying bottlenecks in
program execution, nowadays they are widely used for gathering runtime information
Page 6
of programs and performance analysis (Weaver & McKee, 2008; Bandyopadhyay,
2010).
The types and number of available events to track and the methodologies for using
these performance counters vary widely, not only across architectures, but also across
systems sharing an ISA. Depending on the model of the microprocessor, they may
include 2, 4, 6, 8 or even more of these counters. Intel’s most modern processors offer
more than a hundred different events that can be monitored (Intel, 2013). Therefore, it
is up to the programmer to select which events to monitor and set the configuration
registers appropriately.
Several profiling tools are available to access HPCs on different microprocessor
families. They are relatively simple to use and usually allow monitoring a larger
number of unique events than the number of physical counters available in the proces-
sor. This is possible using round-robin scheduling of monitored events through multi-
plexing and estimation. However, the results are presented after completing the exe-
cution of the target application.
Since online profiling is required by our scheme, we did not use any of the availa-
ble profiling tools. We directly configure and access the HPCs via simple
RDMSR/WRMSR operations (Intel, 2013). This fact also contributes to the autonomy
of the proposed scheme.
Fig. 1. Overall System Architecture
Proposed Architecture
As shown in Figure 1, there is no difference between a regular process and a virtual
machine. We propose to assist the hypervisor to adaptively monitor and model each
VM’s behavior separate from that of processes. Then, given the models, we assist the
Host OS in managing the co-running VMs by providing hints to the scheduler as to
which VM should be scheduled on which core to minimize resource contention. The
proposed architecture is based on the following key aspects:
Page 7
7
- Utilize Hardware Performance Counters (HPCs) that exist in most modern
microprocessors to collect runtime information on each VM.
- The information collected from the HPCs is used to derive the resource de-
mand of each VM and construct a dynamic model to capture their runtime
behavior.
- With the VM’s behavioral information obtained from above, and after a
comprehensive evaluation of their resource demands, our scheme (modified
hypervisor) will generate a VM-to-core mapping that minimizes the conten-
tion for resources among the VMs.
- This mapping is then used by the Host OS scheduler to commit the map-
pings.
Figure 1(b) illustrates the overall layout of the proposed scheme. It shows the
runtime monitoring module added to KVM getting information from the HPCs. Fig-
ure 2 shows a block diagram containing the basic steps performed by our runtime and
monitoring module added to KVM.
Fig. 2. General Scheme
Page 8
Hardware Events and Runtime Model
Extensive work has been done in identifying which shared resources affect perfor-
mance the most in MMMPs (Weng & Liu, 2010; Weng et al., 2013; Zhuravlev et al.,
2010; Cazorla et al., 2006; Cheng, Lin, Li, & Yang, 2010). At this moment, complet-
ing an extensive study in this area is not part of the objectives of this work. This paper
follows the approach presented by Weng and Liu (2010) and Weng et al. (2013) and
adopts Last-Level-Cache (LLC) misses as an essential indicator to the demand on
shared resources in the MMMPs. The work that we present here is mainly performed
at the hypervisor level, which is at a different level from Weng and Liu (2010) and
Weng et al. (2013). Since the previous work was able to model the resource demands
of threads into phases, our current work simply treats entire VMs as “threads”.
The hardware events we monitor are: LLC misses, L1 misses, and committed in-
structions. We create a simple linear model for evaluating the feasibility of the pro-
posed approach. The model is based on the metrics known as Misses Per Kilo Instruc-
tions (MPKI) and Misses Per Million Instructions (MPMI) for both LLC and L1
cache (Cheng et al., 2010). Depending on the MPKI and MPMI values, we classify
the VMs into two categories: computation-intensive (for lower values) and memory-
intensive (for higher values).
The proposed scheme is continuously monitoring and profiling the running VMs. It
manipulates the HPCs to start counting right before giving control to a VM (VM-
entry) and records the counters’ values upon getting control back from the running
VM (VM-exit). The values collected from the hardware counters are recorded as
samples, which are later used to calculate the target metric (MPKI or MPMI). Such
implementation allows our scheme to collect detailed information from each VM
while still incurring in very low overhead.
Every certain number of samples (this value is a parameter of our scheme), the
MPKI/MPMI value for each VM is calculated and the VMs are classified as computa-
tion or memory-intensive. Next, our scheme determines the VM-to-core mapping
following the Mix-Scheduling criteria presented by Weng et al. (2013). Such a map-
ping pattern pairs the threads in such a way that the difference of LLC misses is max-
imized among VMs mapped to the same core. Our method groups together VMs with
different processor usage behaviors (categories) in order to reduce the contention on
shared processor resources among concurrent VMs, separating VMs of similar LLC
miss level.
Experiment Setup
This section introduces the hardware and software setups, the benchmarks used in
this work, and the distinct workloads created to test the proposed scheme.
Hardware Environment
The hardware platform we used for this work is a physical machine (laptop) with
an Intel Core 2 Duo CPU, Model T9400 running at 2.53GHz. This processor has two
Page 9
9
cores with private 64KB L1 (32KB Data + 32KB Instruction) caches each and 6MB
L2 shared cache (LLC). It does not support hyper-threading (HT) technology. There-
fore, only two threads can be executed simultaneously.
Even though this is not the ideal hardware platform, it is what was available to us
at the time this research was started and the experiments here presented were con-
ducted. An immediate extension of this research is to test our scheme using more
advanced MMMP processors housing a larger number of cores as well as equipped
with multi-threading technology.
Software Environment
Our software setup consists of the following:
─ Host OS: Ubuntu 13.04 (64-bit) (3.8.0-22-generic)
─ Hypervisor: Kernel-based Virtual Machine (KVM) version 3.8.0-22-generic
(same as host)
─ Guest OS: Xubuntu 12.04 (32-bit) (3.2.0-37-generic)
Benchmarks
In our study we used the SPEC CPU2006 benchmark suite (Henning, 2006) to con-
struct different types of workloads for the VMs. We performed offline profiling of
different benchmarks in order to get their LLC behavior for generating balanced and
unbalanced workloads. Based on the profiling information we obtained, we selected
benchmarks milc and sphinx3. Both of them are floating-point benchmarks represent-
ing high and low LLC MPKI respectively.
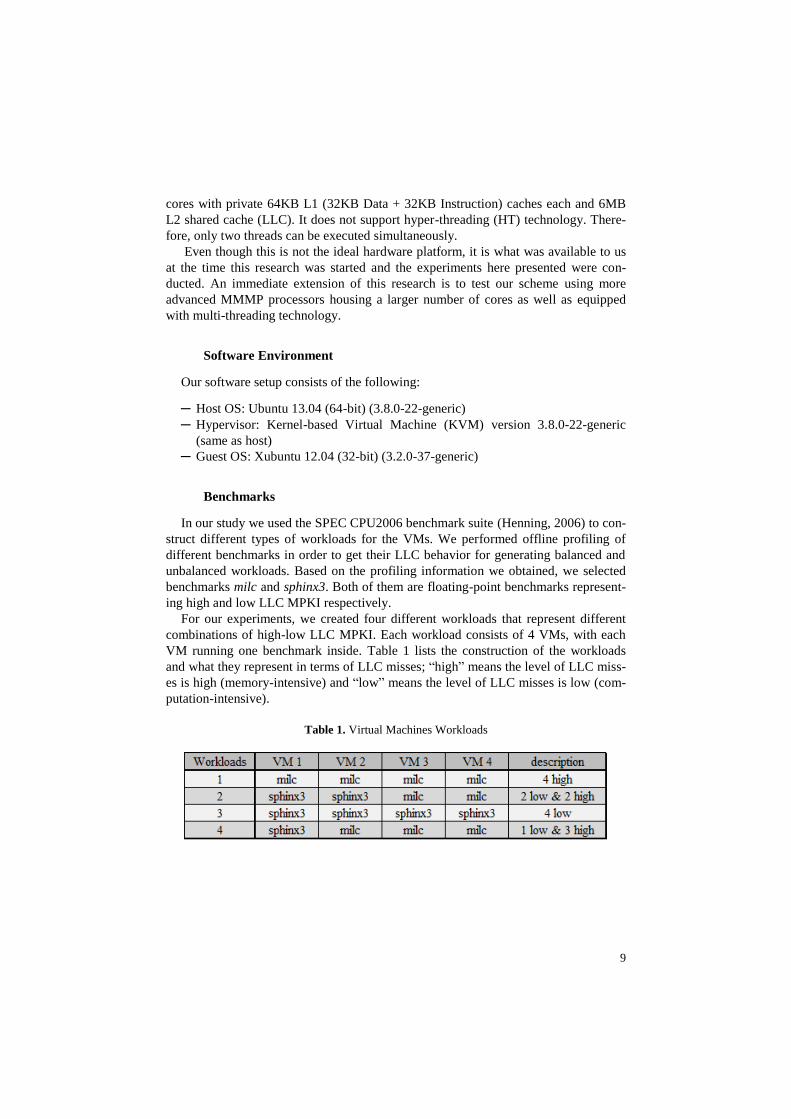
For our experiments, we created four different workloads that represent different
combinations of high-low LLC MPKI. Each workload consists of 4 VMs, with each
VM running one benchmark inside. Table 1 lists the construction of the workloads
and what they represent in terms of LLC misses; “high” means the level of LLC miss-
es is high (memory-intensive) and “low” means the level of LLC misses is low (com-
putation-intensive).
Table 1. Virtual Machines Workloads
Page 10
Experimental Results
In this section, we describe the experiments conducted and present the results ob-
tained. These experiments aim to provide an initial assessment of the feasibility of the
proposed scheme for adaptive VM management in the cloud.
A key objective for this work is to test and validate the fact that neither the OS
scheduler nor the hypervisor is aware of the potential contention on processor re-
sources among concurrent VMs. Therefore, we tested all four workloads with three
different schemes and measure their performance. Firstly we ran the experiment with
the default OS scheduler. Secondly, we tested our proposed approach (VM-mix-
scheduling) following the scheduling criteria explained previously, which is to sched-
ule the VMs of different resource demand onto the same core. Thirdly, we tested the
opposite of the proposed scheduling criteria (VM-mono-scheduling), which is to allo-
cate VMs of the same LLC miss category onto the same core.
Since each benchmark has different running times, in order to mitigate this dispari-
ty when creating the workloads and based on empirical trials, we ran each benchmark
several times (a loop that is different for each benchmark) in an effort to keep the total
running time the same across different VMs.
In our experiments, we identified each VM as memory-intensive or computation-
intensive based on the LLC misses. Then, after the hypervisor (KVM) generates the
VM-to-core mapping, it only manipulates the affinity of each VM in the host ma-
chine, which lets the OS scheduler to perform the migration for each VM that requires
it. It is worth mentioning that in our approach we “prioritize” the VMs over the rest of
the host processes because we assume that in a server hosting multiple VMs (as well
as in the cloud), such VMs might have the highest priority in terms of throughput.
Basically the affinity decisions made by the proposed scheme are based solely on the
VMs, while the host OS scheduler’s decisions are based on the VMs and all other
processes running on the host.
For this set of experiments the hypervisor makes VM-to-core mapping decisions
approximately every 30 seconds for simplicity sake (this time directly depends on the
number of samples collected between updates to each VM’s MPKI/MPMI value).
This is an important factor to keep in mind because it may affect the total overhead
incurred by the scheme. If the overhead is too big, it may have a counterproductive
effect on the system throughput. Furthermore, time intervals between mapping deci-
sions should be dynamic based on the resource demand models in practice, although
the overhead of updating the models does provide a minimum time. Finding the im-
pact of different time internals on the effectiveness of our proposed approach is the
subject of our next research step.
Page 11
11
Fig. 3. System Throughput (VMs)
Fig. 4. Throughput improvement of VM-mix-scheduling normalized to OS Default
Figure 3 shows the throughput results of the three evaluated schemes for all four
workloads. It can be noticed that the VM-mix-scheduling scheme performs slightly
better than the OS default for the first three workloads, and better that VM-mono-
scheduling for all cases. For the fourth workload, the OS default scheduler outper-
forms the other two schemes. Upon further analysis, we believe that this is expected
because with the proposed scheme the low LLC miss VM will be swapped with a
high LLC miss VM at every single decision point. For instance, assume that the cur-
rent mapping of VMs to cores is {L1,H2} and {H3,H4} where the subscripts are used
Page 12
to denote the VM number. At the next decision point VM 2 will have lower MPKIs
than VMs 3 and 4 since it was paired with VM 1. According to the model, VM 2 will
be swapped with either VM 3 or VM 4 in order to ensure that the average MPKI is
minimized. This in turn forces a complete cache flush of both cores, which will in-
crease the MPKIs for all VMs. Once again, better models and adaptive decision inter-
vals are left as future work.
Figure 4 shows the throughput improvement obtained from the VM-mix-
scheduling scheme normalized to that of the OS default. Figure 5 shows the average
speedup per VM of VM-mix-scheduling scheme over the OS default. The later metric
is calculated by averaging the performance benefits obtained on each VM for each
individual workload.
Fig. 5. Average VM speedup of VM-mix-scheduling over OS Default
The throughput improvement achieved by the VM-mix-scheduling scheme com-
pared to the OS Default is modest for all cases. As we can see, our scheme works best
under all memory-intensive VMs, with a throughput improvement of 3.6% and an
average VM speedup of 4.6%, over OS default scheme. The performance data from
Workload 4 is somewhat discouraging. However, making a model to be aware of this
type of scenarios may avoid the behavior described above. Overall, we believe that
these results serve as an indicator that indeed, a hypervisor that is aware of the re-
source contention existing among co-running VMs can improve the overall system
throughput in the cloud environment.
In the hardware platform used for this work, the VMs running on separate cores do
not content for the computational resources, since they have a complete physical core
for themselves. They mainly compete for off-core resources like LLC, memory con-
troller, etc. We think that this fact partially limits the real benefits that could be ob-
tained from applying our proposed scheme. As mentioned earlier, an immediate ex-
Page 13
13
tension of this research is to expand our experiment to more advanced MMMP pro-
cessors containing a larger number of cores that share both on-chip and off-chip re-
sources (like hyper-threaded processors).
Conclusion
Over the last few years there has been an exponential growth in the cloud compu-
ting market. The success of cloud computing technologies heavily depends on both
the underlying hardware and system software support for virtualization. For maintain-
ing such rates of growth, it is vital to efficiently utilize the available hardware re-
sources by understanding the contention on shared processor resources among co-
running VMs to mitigate performance degradation and system throughput penalties.
In this paper, we presented an adaptive scheduling scheme for virtual machine
management in the cloud following a performance-counter-driven approach. Our
proposed approach acts online at runtime, which does not require a priori information
about the VMs, improving over offline profiling-based approaches. The proposed
scheme is also transparent, which executes behind the scenes and does not require the
intervention from the VMs, the users of VMs or the core Operating System kernel. It
creates and maintains a dynamic model to capture a VM’s runtime behavior and man-
age VM-to-core mappings to minimize contention. Our experimental results showed
that the proposed scheme achieved modest improvement in terms of the overall sys-
tem (VMs) throughput as a result of mitigating resource contention among VMs.
Future stages of this work include improving the hardware platform to be used
with multi-threading technology, as well as conducting a more comprehensive hard-
ware event monitoring. At this point, our current implementation is at a coarse-grain
level in the way we categorize each VM. We plan to direct our efforts towards en-
hancing the current design with dynamic phase detection and prediction capability. At
a more advanced stage, we would like to extend the implementation of our scheme to
include non-uniform memory access (NUMA) and heterogeneous architectures as
well.
Acknowledgement
This work is supported under 2013 Visiting Faculty Research Program by Air
Force Research Laboratory. We would like to thank our mentor Steve for his guid-
ance and our team members Lok, Sergay and Matt for their constructive discussions
that made this work possible. We also want to thank the reviewers for their comments
and feedback. Any opinions, findings, and conclusions or recommendations expressed
in this material are those of the authors and do not necessarily reflect the views of the
Air Force Research Laboratory.
Page 14
References
Arteaga, D., Zhao, M., Liu, C., Thanarungroj, P. & Weng, L. (2010). Cooperative Virtual
Machine Scheduling on Multi-core Multi-threading Systems - A Feasibility Study. Work-
shop on Micro Architectural Support for Virtualization, Data Center Computing, and
Cloud.
Bandyopadhyay, S. (2010). A Study on Performance Monitoring Counters in x86-
Architecture. Indian Statistical Institute. Retrieved December 5, 2013, from
http://www.cise.ufl.edu/~sb3/files/pmc.pdf.
Blagodurov, S. & Fedorova, A. (2011). User-level scheduling on NUMA multicore sys-
tems under Linux. In Proc. of Linux Symposium.
Blagodurov, S., Zhuravlev, S. & Fedorova, A. (2010). Contention-Aware Scheduling on
Multicore Systems. ACM Trans. Comput. Syst. 28 (4), 8:1--8:45. (Doi:
10.1145/1880018.1880019.).
Cazorla, F., Knijnenburg, P. M. W., Sakellariou, R., Fernandez, E., Ramirez, A. & Valero,
M. (2006). Predictable performance in SMT processors: synergy between the OS and
SMTs. Computers, IEEE Transactions on 55 (7), 785-799. (Doi: 10.1109/TC.2006.108.).
Cheng, H.-Y., Lin, C.-H., Li, J. & Yang, C.-L. (2010). Memory Latency Reduction via
Thread Throttling. In Microarchitecture (MICRO), 2010 43rd Annual IEEE/ACM Interna-
tional Symposium on (pp. 53-64).
Fedorova, A. (2006). Operating System Scheduling for Chip Multithreaded Processors.
Unpublished doctoral dissertation, Harvard University. Retrieved December 5, 2013, from
http://www.cs.sfu.ca/~fedorova/thesis.pdf.
Henning, J. L. (2006). SPEC CPU2006 Benchmark Descriptions. SIGARCH Comput.
Archit. News 34 (4), 1--17. (Doi: 10.1145/1186736.1186737.).
Intel, I. (2013). Intel 64 and IA-32 Architectures Software Developer’s Manual. Retrieved
December 5, 2013, from
http://www.intel.com/content/dam/www/public/us/en/documents/manuals/64-ia-32-
architectures-software-developer-manual-325462.pdf.
Knauerhase, R., Brett, P., Hohlt, B., Li, T. & Hahn, S. (2008). Using OS Observations to
Improve Performance in Multicore Systems. Micro, IEEE 28 (3), 54-66. (Doi:
10.1109/MM.2008.48.).
Lugini, L., Petrucci, V. & Mosse, D. (2012). Online Thread Assignment for Heterogeneous
Multicore Systems. 2012 41st International Conference on Parallel Processing Workshops
0, 538-544. (Doi: http://doi.ieeecomputersociety.org/10.1109/ICPPW.2012.73.).
Nathuji, R., Kansal, A. & Ghaffarkhah, A. (2010). Q-clouds: Managing Performance In-
terference Effects for QoS-aware Clouds. In Proceedings of the 5th European Conference
on Computer Systems (pp. 237--250). ACM. (ISBN: 978-1-60558-577-2.).
Page 15
15
Petrucci, V., Loques, O., Mosse, D., Melhem, R., Gazala, N. & Gobriel, S. (2012). Thread
Assignment Optimization with Real-Time Performance and Memory Bandwidth Guaran-
tees for Energy-Efficient Heterogeneous Multi-core Systems. In Real-Time and Embedded
Technology and Applications Symposium (RTAS), 2012 IEEE 18th (pp. 263-272).
Red Hat, I. (2013). KERNEL BASED VIRTUAL MACHINE (KVM). http://www.linux-
kvm.org/.
Red Hat, I. (2009). KVM – KERNEL BASED VIRTUAL MACHINE. Red Hat, Inc.. Re-
trieved December 5, 2013, from http://www.redhat.com/rhecm/rest-
rhecm/jcr/repository/collaboration/jcr:system/jcr:versionStorage/5e7884ed7f00000102c31
7385572f1b1/1/jcr:frozenNode/rh:pdfFile.pdf.
Shelepov, D., Saez Alcaide, J. C., Jeffery, S., Fedorova, A., Perez, N., Huang, Z. F.,
Blagodurov, S. & Kumar, V. (2009). HASS: A Scheduler for Heterogeneous Multicore
Systems. SIGOPS Oper. Syst. Rev. 43 (2), 66--75. (Doi: 10.1145/1531793.1531804.).
Wang, L., Xu, J. & Zhao, M. (2012). Modeling VM Performance Interference with Fuzzy
MIMO Model. In Proceedings of the 7th International Workshop on Feedback Computing
(FeedbackComputing, co-held with ICAC2012).
Weaver, V. & McKee, S. (2008). Can hardware performance counters be trusted?. In
Workload Characterization, 2008. IISWC 2008. IEEE International Symposium on (pp.
141-150).
Weng, L. & Liu, C. (2010). On Better Performance from Scheduling Threads According
to Resource Demands in MMMP. In Parallel Processing Workshops (ICPPW), 2010 39th
International Conference on (pp. 339-345).
Weng, L., Liu, C. & Gaudiot, J.-L. (2013). Scheduling Optimization in Multicore Multi-
threaded Microprocessors Through Dynamic Modeling. In Proceedings of the ACM Inter-
national Conference on Computing Frontiers (pp. 5:1--5:10). ACM. (ISBN: 978-1-4503-
2053-5.) (Doi: 10.1145/2482767.2482774.).
Zhuravlev, S., Blagodurov, S. & Fedorova, A. (2010). Addressing Shared Resource Con-
tention in Multicore Processors via Scheduling. In Proceedings of the Fifteenth Edition of
ASPLOS on Architectural Support for Programming Languages and Operating Systems
(pp. 129--142). ACM. (ISBN: 978-1-60558-839-1.) (Doi: 10.1145/1736020.1736036.).