Shenzhen Research Institute of Big Data, the ChineseUniversity of Hong Kong (Shenzhen)
Shenzhen, Guangdong, China
ABSTRACTRecent research has demonstrated that adding some imperceptibleperturbations to original images can fool deep learning models.However, the current adversarial perturbations are usually shownin the form of noises, and thus have no practical meaning. Imagewatermark is a technique widely used for copyright protection. Wecan regard image watermark as a kind of meaningful noises andadding it to the original image will not affect people’s understand-ing of the image content, and will not arouse people’s suspicion.Therefore, it will be interesting to generate adversarial examplesusing watermarks. In this paper, we propose a novel watermarkperturbation for adversarial examples (Adv-watermark) which com-bines image watermarking techniques and adversarial example al-gorithms. Adding a meaningful watermark to the clean images canattack the DNN models. Specifically, we propose a novel optimiza-tion algorithm, which is called Basin Hopping Evolution (BHE),to generate adversarial watermarks in the black-box attack mode.Thanks to the BHE, Adv-watermark only requires a few queriesfrom the threat models to finish the attacks. A series of experimentsconducted on ImageNet and CASIA-WebFace datasets show that theproposed method can efficiently generate adversarial examples, andoutperforms the state-of-the-art attack methods. Moreover, Adv-watermark is more robust against image transformation defensemethods.
ACM Reference Format:Xiaojun Jia, Xingxing Wei, Xiaochun Cao, and Xiaoguang Han. 2020. Adv-watermark: A Novel Watermark Perturbation for Adversarial Examples. InProceedings of the 28th ACM International Conference on Multimedia (MM’20), October 12–16, 2020, Seattle, WA, USA.ACM, New York, NY, USA, 9 pages.https://doi.org/10.1145/3394171.3413976
1 INTRODUCTIONRecent literature has found that Deep Neural Networks (DNNs)are vulnerable to the adversarial examples which are generated byadding some imperceptible noises to the clean images [5]. Generallyspeaking, attack methods can be divided into two categories: white-box attack methods and black-box attack methods. The white-boxattack [2, 6, 15, 23] denotes that the attacker has complete accessto the target model such as model parameters, model structure, etc.And the black-box attack [1, 4, 17, 29, 33] denotes that the attackercan only access the output of the target model. The above methodsachieve attacks by generating imperceptible perturbations. They useL0,L2,L∞ to bound the noises. Recently, more andmore researcherspay attention to generating realistic adversarial examples withoutthe Lp norm limitation [4, 16, 26].
Watermarking methods [7] play an important role in protectingintellectual property rights. It embeds some specific information ofthe copyright holder (such as university logos, ownership descrip-tions, etc) into the multimedia data according to the requirementsof users. In [21], Mintzer et al. describe the characteristics of visiblewatermarks. The visible watermark should be visible but does notsignificantly obscure the details of the host image.
In this paper, we propose a novel adversarial attack which gener-ates adversarial examples using watermarks. We find that althoughwatermarks do not affect people’s understanding of the image con-tent, and adding specific watermarks to the clean images can foolthe DNN models. The specific watermarks refer to the specific po-sition and transparency of them. We mainly consider using visiblewatermarks to generate adversarial examples. In detail, we usealpha blending [31] to achieve watermark embedding. The host
Figure 1: Adversarial examples with watermark perturba-tions. The original class labels are in black text and the ad-versarial class labels are in red text.
image and the watermark are multiplied by a scaling factor. Thescaling factor is manipulated in the α channel of the image, whichdecides the image’s transparency.
As for a certain watermark, the DNN models can be success-fully attacked only by adding the watermark with the specifictransparency to a specific position of the host image. Consider-ing this, we propose a novel attack method to generate watermarkadversarial perturbations. Specifically, we propose a Basin HoppingEvolution (BHE) algorithm to find the appropriate transparencyof the watermark image and the appropriate position within thehost image to embed watermark. BHE is proposed based on theHopping Evolution (BH) [36], where we find it usually falls intoa local optimum and fails in attacking DNN models. In contrast,BHE has multiple initial starting points and crossover operationto keep the diversity of solutions. In this way, BHE makes it easierto find a global optimal solution and thus achieves a higher attacksuccess rate than BH. The proposed method achieves attacks byusing a little information (predicted probability of the classificationmodel). It does not need the inner information of DNNs such as net-work structures and weights. Therefore, it belongs to the black-boxattack.
Besides the ability to perform adversarial attacks, Adv-watermarkalso inherits the function of the visible watermark. That’s to say,Adv-watermark can also protect the copyright of the image becauseit carries the owner’s description. Therefore, Adv-watermark canaccomplish two functions at the same time. This is a major advan-tage compared with the previous research. Specifically, peoplestend to share their images on social media to record their lives.They usually add a visible watermark to protect their copyright.But their images can also be identified and embezzled by malicioussoftware. Adv-watermark can be used to avoid this situation. It notonly protects the copyright of the image but also performs adver-sarial attacks to avoid being embezzled by malicious software. Inthis paper, we explore two kinds of media as the watermarks: logos
Figure 2: In this paper, we explore two kinds of media asthe watermark: logos and texts. These six host images arerandomly selected from ImageNet.
and texts. Figure 2 lists the used watermarks, and some generatedAdv-watermark examples are shown in Figure 1.
In summary, this paper has the following contributions:1) We propose the Adv-watermark, a novel watermark perturba-
tion for adversarial examples, which combines image watermarkingtechniques and adversarial example algorithms. Compared with theprevious works, the proposed adversarial example is more realisticand effective.
2) We propose a novel optimization algorithm, which is calledBasin Hopping Evolution (BHE), to generate adversarial examplesefficiently. The proposed method adopts a population-based globalsearch strategy to generate adversarial examples, and can achievehigh performance in attacking DNN models.
3) Compared with the previous black-box attack methods, theproposedmethod can achieve a higher attack success rate.Moreover,the state-of-the-art image transformation defense methods cannot defend the proposed attack method. The code is released athttps://github.com/jiaxiaojunQAQ/Adv-watermark.git.
The remainder of this paper is organized as follows. Section 2briefly reviews the related work. Section 3 introduces the details ofthe proposed Adv-watermark. Section 4 shows a series of experi-mental results and analysis. Finally, Section 5 gives the conclusion.
2 RELATEDWORKIn this section, we investigate the attack methods and the visiblewatermarking methods.
2.1 Attack methodsIn [6], Goodfellow et al. devise an effective method to calculate theadversarial examples, and the adversarial perturbation is generatedaccording to the direction of the gradient change of the DNNs.This method is also called FGSM. Iterative FGSM (I-FGSM) [15] isan improved version of FGSM. I-FGSM constructs an adversarialexample by multi-step and smaller movements, which greatly im-proves the success rate of the attack. The most common adversarialattack methods are under the L∞ and L2 distance metric. But in[24], Papernot et al. propose to build adversarial saliency maps togenerate adversarial examples under L0 norm. Moosavi-Dezfooli
Spike Salt Shaker
Paperknife Water Jug
Figure 3: The top row is the original images (they are cor-rectly classified by Resnet101) and their corresponding heat-maps (generated by Grad-CAM algorithm).The bottom rowis the adversarial images with the visible watermark andtheir corresponding heat-maps. The image classification la-bels are in black color.
et al. propose a simple and accurate method (Deepfool) [23] to effi-ciently generate the adversarial examples. Moreover, they furtherpropose the universal perturbation based on Deepfool in [22]. Andin [2], Carlini and Wagner propose three attack methods to attackdefensive distillation Networks [25]. In [33], Su at el. propose togenerate one-pixel adversarial perturbations based on differentialevolution (DE).
2.2 Visible watermarking methodsIn [13], Kankanhalli et al. propose a visible watermarking techniquethat can find the strength of the watermark image and the locationof the host image. In [31], Shen et al. propose to use the alphablending technique to generate the visible watermark. A removablevisible watermark is proposed in [9]. They design a vision water-marking algorithm suitable for the different requirements of theapplications. In [19], Liu et at. propose a new approach to generatea generic lossless visible watermark. The proposed method makesuse of deterministic one-to-one mappings of image pixel valuesto achieve generating the visible watermark. In [10], Huang et al.design a visible watermarking algorithm for digital right manage-ment. A contrast-sensitive function and block classification are usedto achieve a better visual effect in the discrete wavelet transformdomain.
3 METHODOLOGYIn this section, we introduce the proposed method from three as-pects: visible watermarking, problem formulation and problemsolving.
3.1 Visible WatermarkingWe use alpha blending in [31] to generate a visible watermark. Al-pha channel(α channel) refers to the transparency of a foregroundregion w.r.t. the background image. In this paper, we use α to repre-sent the value of the alpha channel, H to represent the host image
whose size is N ×M ,W to represent the watermark image whosesize is n ×m and G to represent the generated image with a water-mark whose size is N ×M . When i ∈ (p,p + n), j ∈ (q,q +m), thegeneration for G is formulated as:
when i < (p,p + n), j < (q,q +m), G is formulated as:
v(G)i, j = v(H )i, j , (2)
where v(x) denotes the image x , the subscript i, j of v(x) representthe pixel position, and p,q represent the position where the wa-termark image is embedded. As for the image watermark, we useUC Berkeley, CMU, MIT, Cambridge and Stanford University logowatermarks. Simultaneously, we also use the official ACMMM logofrom 2016 to 2020. As for text watermark, we use red, green, blue,black and gray fonts to generate adversarial examples. We also syn-thesize watermark images in different sizes to explore scale-wareeffects. It is formulated as:
whereWh and Hh represent the width and height of the host image.Ww andHw represent the width and height of the watermark image.sl is the scaling factor. AndWsw and Hsw represent the width andheight of the scaled watermark image. Note that in this paper, wefocus on the position and transparency of the watermark, not therotation, etc.
3.2 Problem FormulationWe disguise adversarial noise as a visible watermark to achievestealthiness. And the generation of adversarial examples is only re-lated to the position and transparency of the watermark. Generatingadversarial watermark images can be formalized as an optimizationproblem with constraints. The host image is assumed as H , thewell-trained classification model is assumed as f and the correctclassification class of H is t . ft (H ) is the probability of H belong-ing to the class t . Simultaneously, letW be the watermark imageand д(H ,W ,p,q,α) be the visible watermark algorithm. It embedsthe watermark imageW in the position (p,q) of the host imageH . The p, q and α are dependent onW , H , f . And the limitationof maximum transparency of the watermark is L. In the case ofuntargeted attacks, the goal of generation of adversarial examplescan be transformed into finding the optimized solution e(p,q,α)∗.It is formulated as:
minimizee(p,q,α )∗
ft (д(H ,W ,p,q,α))
subject to α ≤ L(4)
This problem involves two values: 1) the position (p,q) of thewatermark in the host image and 2) the transparency α of the water-mark. Embedding the adversarial watermark which can be regardedas a practical perturbation into the host image modifies the local in-formation of the host image. In this way, the adversarial watermarkperturbation permits a clean image to be an adversarial example.Without affecting the visual effect of the image, the adversarial wa-termark disturbs the important local regions which determine theimage classification to attack the well-trained classification model.
Population
Initialization
Basin
HoppingCrossover Selection
Iteration
Figure 4: The process of Basin Hopping Evolution.
This is illustrated in Figure 3. From the heat-maps which are gener-ated by Gradient-weighted Class Activation Mapping (Grad-CAM)[30], it is clear why the Resnet101 predicts the input images as thecorresponding correct classes. And embedding the adversarial wa-termark into the image can modify the distribution of the maximumpoints on the generated heat-map.
3.3 Problem SolvingWe propose a novel optimization algorithm, which is called BasinHopping Evolution(BHE). The proposed method is a heuristic ran-dom search algorithm based on Basin Hopping, which can be usedfor finding the global minimumof amultivariate function. As shownin Figure 4, BHE includes Basin Hopping, crossover and selectionoperations. During each iteration, the current solutions (parents)use BH to produce a set of better solutions and conduct crossoveroperation to generate a new set of candidate solutions (children).And then in selection operation, compared with the correspondingparents to conduct, if the children are more suitable for the cur-rent population evolution (posses the smaller multivariate functionvalue), they survive and are passed to the next generation.
3.3.1 Population Initialization. BHE is an optimization algorithmbased on group evolution. We regard each solution as an individualof a population. And the elements (p,q and α ) are considered asits genes. Let Xi,д denote the i-th individual in the д-th generationpopulation. And Xi,д, j (j = 0, 1, 2) denotes the j-th gene of Xi,д .Therefore, we initialize a population as follows:
where Xi,0, j is the j-th gene of the i-th individual in the initialpopulation , Xmin, j is the minimum of the j-th gene and Xmax, j isthe maximum of the j-th gene.
3.3.2 Basin Hopping. Basin Hopping (BH) is a stochastic optimiza-tion algorithm. During each iteration, BH generates some newcoordinates with random perturbations, next finds the local mini-mization, and finally accepts or rejects the new coordinates accord-ing to the minimized function value. We use BH to evolve a betterindividual Vi,д from Xi,д .
In detail, ft (д(H ,W ,p,q,α)) is assumed as ft (·). Starting withXi,д , a local optimal solution Vi,д of the function ft (·) is found byusing a minimization method L(·). Next we start the global searchiterations and use µд(Xi,д) to represent the global neighborhoodof Xi,д . It is formulated as:
µд(Xi,д) = [Xi,д ,Xi,д + r ∗ ®d], (6)
Figure 5: The histogram of the top 5 category confidence ofgenerated images in the generation process of the adversar-ial examples using BHE.
where ®d is an n-dimensional Gaussian(0, 1) variable and r is a fixedstep size. A new starting point is selected from the global neighbor-hood of Vi,д . It is stored as Vi,д .It is formulated as:
Vi,д = G(µд(Vi,д)) (7)
And then starting with Vi,д , a local search is performed and theresult is stored as Si,д . Finally, we use a function Accept(Vi,д , Si,д)to choose Vi,д or Si,д . And it is formulated as:
Accept(Vi,д , Si,д) ={1 ft (Si,д) ≤ ft (Vi,д)0 ft (Si,д) > ft (Vi,д)
(8)
The detail description is given in Algorithm 1. To represent BHalgorithm simplify, it can be formulated as:
Vi,д = BH (Xi,д , I ), (9)
where Xi,д represents the i-th solution in the д-th generation popu-lation, Vi,д represents the corresponding better solution using BH,BH (·) represents the BH algorithm and I indicates the maximumnumber of Basin Hopping iterations which is a super parameterwhich we use a large number of experiments to certify.
Algorithm 1 BH algorithmRequire: The watermark imageW , the host image H , the well-
trained classifier f and Xi,дEnsure: Vi,д1: Vi,д = L(ft (·),Xi,д);2: repeat3: Vi,д = G(µд(Vi,д));4: Si,д = L(ft (·),Vi,д);5: if Accept(Vi,д , Si,д) then6: Vi,д = Si,д ;7: end if8: until global stopping rule is satisfied9: return Vi,д
3.3.3 Crossover. As for the current solution (parents) Xi,д and thecorresponding BH optimization solutionVi,д , we conduct crossoveroperation to get a candidate solution (child)Ui,д . It is formulatedas:
Ui,д, j =
{Vi,д, j , rand(0, 1) ≤ CRXi,д, j , others
(10)
whereUi,д, j is the j-th gene of Ui,д , Vi,д, j is the j-th gene of Vi,д ,Xi,д, j is the j-th gene of Xi,д and CR is the crossover probabilitywhich represents the degree of information exchange in the popula-tion evolution. It is a super parameter which we use a large numberof experiments to certify.
3.3.4 Selection. We adopt a greedy selection strategy to select abetter solution as the next generation solution. It is formulated as:
Xi,д+1 =
{Ui,д , ft
(Ui,д
)≤ ft
(Xi,д
)Xi,д others (11)
The detail description of BHE is given in Algorithm 2. And thegeneration process of the adversarial examples by using BHE isshown in Figure 5.
I ;Ensure: The best solution -△1: д← 0;2: for i = 1 toM do3: for j = 1 to 3 do4: Xi,0, j = Xmin, j + rand(0, 1) · (Xmax, j − Xmin, j )5: end for6: end for7: while ft (△) ≥ ε and д ≤ N do8: for i = 1 toM do9: ▶ Basin Hopping10: Vi,д = BH (Xi,д , I )11: ▶ Crossover12: for j = 1 to 3 do13: Ui,д, j = Crossover (Vi,д, j ,Xi,д, j )14: end for15: ▶ Selection16: if ft (Ui,д) ≤ ft (Xi,д) then17: Xi,д = Ui,д18: if ft (Xi,д) ≤ ft (△) then19: △ = Xi,д20: end if21: else22: Xi,д = Xi,д23: end if24: end for25: д← д + 126: end while
4 EXPERIMENTAL RESULTS AND ANALYSIS4.1 Experiment SettingsWe conduct experiments based on ImageNet [28]andCASIA-WebFace[37]. In detail, we randomly select 1,000 images from them to con-duct the related experiments. We choose six classification models
with different structures as threat models: Alexnet [14], VGG19[32], SqueezeNet[11], Resnet101 [8], InceptionV1 [34] and Incep-tionV3 [35]. We also compare with other black-box attack methodsto verify the proposed method: spatial attack [4], boundary attack[1], single-pixel attack [33] and pointwise attack[29]. As for theseattack methods, we adopt their benchmark approaches and defaultparameters as recommended in Foolbox [27].
4.2 Optimization method implementationThe initial value of the step size r is set as 0.5. And the initial p,qand α are set as 0, 0 and 100. The range of thep is [0,Wh−Wsw ]. Therange of the q is [0,Hh −Hsw ]. And the range of the α is [100, 200].
4.3 Selection of hyper-parametersWe conduct a large number of experiments to determine two hyperparameters in BHE. One is the number of basin hopping iterationsI , the other one is crossover probability CR. We adopt BHE to attackDNN models using ACMMM 2020 logo with scale=1/4. In detail, wecompute the attack success rates of the Resnet101 on 1000 randomimage of the ImageNet dataset. The result is shown in Table 1.From Table 1, it is clear that the attack success rate increases whenI increases. That is, as the number of Basin Hopping iterationsincreases, the solution generated by BH will be better, resulting inachieving a higher attack success rate. But more iterations meanmore time spent. Considering time complexity, we set CR to 0.9 andI to 3. In this way, Adv-watermark can achieve the highest attacksuccess rate(60%). And in the original BH algorithm, the iteration Iis set to 450.
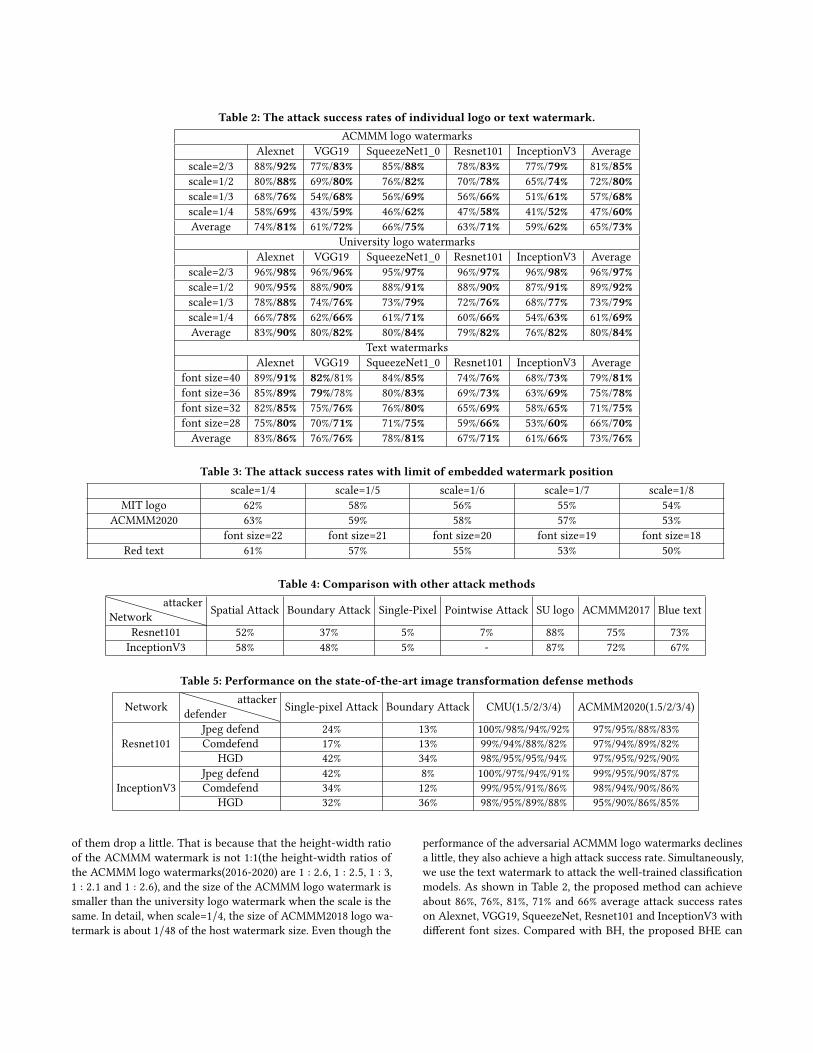
4.4 Attack performanceIn order to verify the proposed method comprehensively, we choosefive university logo watermarks and five official ACMMM water-marks as the image watermarks to generate corresponding adver-sarial examples. And we also choose five different color fonts as thetext watermarks to generate corresponding adversarial examples.The average attack success rates of individual logos or text water-marks are reported in Table 2. The first column of each row showsthe results of BH and the second column of each row shows theresults of BHE. It is clear that the proposed BHE can achieve a highattack success rate. As for the university logo watermarks, when thewatermark size is set as 4/9 of the host image size, the attack successrate can achieve about 97%. And when the watermark size is set as1/16 of the host image size, the attack rate also can achieve 69%. Asfor the ACMMM logo watermarks, the average attack success rates
Table 2: The attack success rates of individual logo or text watermark.ACMMM logo watermarks
of them drop a little. That is because that the height-width ratioof the ACMMM watermark is not 1:1(the height-width ratios ofthe ACMMM logo watermarks(2016-2020) are 1 : 2.6, 1 : 2.5, 1 : 3,1 : 2.1 and 1 : 2.6), and the size of the ACMMM logo watermark issmaller than the university logo watermark when the scale is thesame. In detail, when scale=1/4, the size of ACMMM2018 logo wa-termark is about 1/48 of the host watermark size. Even though the
performance of the adversarial ACMMM logo watermarks declinesa little, they also achieve a high attack success rate. Simultaneously,we use the text watermark to attack the well-trained classificationmodels. As shown in Table 2, the proposed method can achieveabout 86%, 76%, 81%, 71% and 66% average attack success rateson Alexnet, VGG19, SqueezeNet, Resnet101 and InceptionV3 withdifferent font sizes. Compared with BH, the proposed BHE can
Figure 6: (a) Limit of embedded watermark position. Theface is in the red rectangle and the embedded watermark isrestricted to the green rectangles. (b) Adversarial exampleson the CASIA-WebFace dataset.
achieve a higher attack success rate. Moreover, we conduct a seriesof experiments on the CASIA-WebFace dataset within restrictingadversarial watermark position. Specifically, as shown in Figure 6(a), we use MTCNN [38] to find face area which is marked as the redrectangle. We restrict the embedded watermark to the area on bothsides of the rectangle which is marked as the green rectangle. Andthen we use Adv-watermark to attack InceptionV1 which is trainedon CASIA-WebFace dataset. Generated adversarial examples areshown in Figure 6 (b). The attack result is shown in Table 3. Notethat since we limit the embedding area of the watermark, we shouldadopt a smaller scale and font size.
4.5 Comparisons with other attack methodsTo quantitatively evaluate the proposed method performance, wecompare the proposed method with other black-box attack methods:spatial attack [4], boundary attack [1], single-pixel attack [33] andpointwise attack[29]. In detail, we choose the SU and ACMMM2017image watermarks with different scales and blue font text water-mark with the different font sizes to complete the contrast experi-ments. Their average attack success rates are shown in Table 4. Asshown in Table 4, it is clear that compared with other black-boxattack methods, our attack method can achieve a higher attacksuccess rate. In particular, the average attack success rate of SUreaches up to 88%.
In order to evaluate the robustness of the proposed method, wecompare the Adv-watermark with other black-box attack methods:single-pixel attack and boundary attack, and choose three imagetransformation defense methods: Jpeg defend [3], Comdefend [12]
Wood Rabbit
Hare
Rhodesian Ridgeback
Great Dane
Minibus
Minivan
Standard Poodle
Miniature Poodle
Cougar
White Wolf
Spike
Nematode
Sorrel
Oxygen Mask
Pinwheel
Envelope
Figure 7: The adversarial examples with a variety of TV sta-tion logos. The original class labels are in black color andthe class labels of the adversarial examples are in red color.
Figure 8: Layer-wise perturbation levels of theVGG16model.Adversarial watermark and normal watermark added toclean images correspond to the El , respectively.
and HGD [18]. From Table 5, it is clear that the existing image trans-formation defense methods are useful for single-pixel attack andboundary attack, but not useful for our proposedmethod. Comparedwith other attack methods, the proposed method is more robust.We also conduct adversarial training [20] to defend the proposedattack method. In detail, we inject adversarial examples generatedby MIT, ACMMM2020 image watermark with scale = 1/4 and redtext watermark with font = 28 into the original image dataset andretrain three Resnet101 on them respectively. And then we usethese watermarks with different sizes to attack these models. Theresult is shown in Table 6. It is clear that the adversarial trainingcannot effectively defend Adv-watermark. Moreover, using anotherwatermark to attack the adversarial training model can achieve ahigher attack success rate. In other words, even though adversarialtraining increases the robustness to one watermark perturbation, itincreases the vulnerability to another watermark perturbation.
4.6 ExtensionThe proposed method is not limited to using a watermark to gener-ate an adversarial example. It can be extended to use the TV stationlogos to complete the attack. To make the generated adversarial
examples more realistic and imperceptible, we also choose morecommonly used TV station logos to complete the attack. In detail,we select a variety of TV station logos, next limit the embeddedposition of the logos to the upper right corner of the host image andthen use the proposed method to generate the adversarial examples.As shown in Figure 7, the generated adversarial examples are morerealistic and common in the physical world.
4.7 Analysis for Adv-watermarkCompared with the previous attack methods, Adv-watermark paysmore attention to generate realistic adversarial examples. We findDNN models are spatially vulnerable, which adding perturbationsat a specific position to clean images can attack them easily. Toinvestigate this characteristic, we conduct a comparative exper-iment to evaluate layer-wise perturbations of the VGG16 modelfed adversarial watermark images and normal watermark images,respectively. The difference between normal watermarks and ad-versarial watermarks is that they are positioned differently on cleanimages. The perturbation level in layer l can be formulated as:
where x represents a clean image, xw represents the clean imagewith adversarial or normal watermark and fl (·) represents the l-thlayer of the VGG16 model.
The result is shown in Figure 8. The red curve represents the Elfor adversarial watermark perturbations and the blue curve rep-resents the El for normal watermark perturbations. Specifically,the red curve is the average result on 30 randomly picked imageswith the adversarial watermarks and the blue curve is the averageresult on 30 same images with the normal watermarks. It is clearthat the watermark perturbation is progressively enlarged withthe layer hierarchy. But in the top layer, the adversarial watermarkperturbation is much higher than the normal watermark perturba-tion. Because the classification result is dependent on the top-levelfeatures, the adversarial watermark perturbation can fool DNNmodels but the normal watermark perturbation can not.
5 CONCLUSIONIn this paper, we discovered DNN models were spatially vulnerable,which adding perturbations at a specific position to clean imagescould attack models easily. And then we proposed a novel attackingmethod which used the real watermark to attack the well-trainedclassifier. Our adversarial perturbation was meaningful, which wasdifferent from the traditional ones. We formulated the watermarkattack problem as a global optimization problem, and proposeda novel optimization algorithm(BHE) to generate adversarial ex-amples. Compared with the previous BH, BHE achieved a higherattack success rate. Moreover, the Adv-watermark was more robust,because the image transformation defense methods could not de-fend the proposed attack method. And the proposed method couldbe more commonly used in the real world.
ACKNOWLEDGEMENTSupported by the National Key R&D Program of China underGrant 2018AAA0102503, National Natural Science Foundation ofChina (No. U1936210, U1736219, 61971016, 61806109), The Open
Research Fund from Shenzhen Research Institute of Big Data, un-der Grant No. 2019ORF01010, Beijing Natural Science Founda-tion (No.L182057), Peng Cheng Laboratory Project of GuangdongProvince PCL2018KP004.
REFERENCES[1] Wieland Brendel, Jonas Rauber, and Matthias Bethge. 2017. Decision-Based Ad-
versarial Attacks: Reliable Attacks Against Black-Box Machine Learning Models.arXiv:1712.04248 [stat.ML]
[2] Nicholas Carlini and David Wagner. 2017. Towards evaluating the robustnessof neural networks. In 2017 IEEE Symposium on Security and Privacy (SP). IEEE,39–57.
[3] Nilaksh Das, Madhuri Shanbhogue, Shang-Tse Chen, Fred Hohman, Li Chen,Michael E Kounavis, and Duen Horng Chau. 2017. Keeping the bad guys out:Protecting and vaccinating deep learning with jpeg compression. arXiv preprintarXiv:1705.02900 (2017).
[4] Logan Engstrom, Brandon Tran, Dimitris Tsipras, Ludwig Schmidt, and Alek-sander Madry. 2019. Exploring the Landscape of Spatial Robustness. In Interna-tional Conference on Machine Learning. 1802–1811.
[5] Ian Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley,Sherjil Ozair, Aaron Courville, and Yoshua Bengio. 2014. Generative adversarialnets. In Advances in neural information processing systems. 2672–2680.
[6] Ian J Goodfellow, Jonathon Shlens, and Christian Szegedy. 2014. Explaining andharnessing adversarial examples. arXiv preprint arXiv:1412.6572 (2014).
[7] Frank Hartung and Martin Kutter. 1999. Multimedia watermarking techniques.Proc. IEEE 87, 7 (1999), 1079–1107.
[8] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. 2016. Deep residuallearning for image recognition. In Proceedings of the IEEE conference on computervision and pattern recognition. 770–778.
[9] Yongjian Hu, Sam Kwong, and Jiwu Huang. 2005. An algorithm for removable vis-ible watermarking. IEEE Transactions on Circuits and Systems for Video Technology16, 1 (2005), 129–133.
[10] Biao-Bing Huang and Shao-Xian Tang. 2006. A contrast-sensitive visible water-marking scheme. IEEE MultiMedia 13, 2 (2006), 60–66.
[11] Forrest N Iandola, Song Han, Matthew W Moskewicz, Khalid Ashraf, William JDally, and Kurt Keutzer. 2016. SqueezeNet: AlexNet-level accuracy with 50xfewer parameters and< 0.5 MBmodel size. arXiv preprint arXiv:1602.07360 (2016).
[12] Xiaojun Jia, XingxingWei, Xiaochun Cao, and Hassan Foroosh. 2019. ComDefend:An Efficient Image Compression Model to Defend Adversarial Examples. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition.6084–6092.
[13] Mohan S Kankanhalli, KR Ramakrishnan, et al. 1999. Adaptive visible water-marking of images. In Proceedings IEEE International Conference on MultimediaComputing and Systems, Vol. 1. IEEE, 568–573.
[14] Alex Krizhevsky, Ilya Sutskever, and Geoffrey E Hinton. 2012. Imagenet classifica-tion with deep convolutional neural networks. In Advances in neural informationprocessing systems. 1097–1105.
[15] Alexey Kurakin, Ian Goodfellow, and Samy Bengio. 2016. Adversarial examplesin the physical world. arXiv preprint arXiv:1607.02533 (2016).
[16] Ares Lagae, Sylvain Lefebvre, Rob Cook, Tony DeRose, George Drettakis, David SEbert, John P Lewis, Ken Perlin, and Matthias Zwicker. 2010. A survey of proce-dural noise functions. In Computer Graphics Forum, Vol. 29. Wiley Online Library,2579–2600.
[17] Siyuan Liang, Xingxing Wei, Siyuan Yao, and Xiaochun Cao. 2020. EfficientAdversarial Attacks for Visual Object Tracking. arXiv preprint arXiv:2008.00217(2020).
[18] Fangzhou Liao, Ming Liang, Yinpeng Dong, Tianyu Pang, Xiaolin Hu, and JunZhu. 2018. Defense against adversarial attacks using high-level representationguided denoiser. In Proceedings of the IEEE Conference on Computer Vision andPattern Recognition. 1778–1787.
[19] Tsung-Yuan Liu and Wen-Hsiang Tsai. 2010. Generic lossless visible water-markingâĂŤa new approach. IEEE transactions on image processing 19, 5 (2010),1224–1235.
[20] Aleksander Madry, Aleksandar Makelov, Ludwig Schmidt, Dimitris Tsipras, andAdrian Vladu. 2018. Towards Deep Learning Models Resistant to AdversarialAttacks. In ICLR (Poster). OpenReview.net.
[21] Fred Mintzer, Gordon W Braudaway, and Minerva M Yeung. 1997. Effectiveand ineffective digital watermarks. In Proceedings of International Conference onImage Processing, Vol. 3. IEEE, 9–12.
[22] Seyed-Mohsen Moosavi-Dezfooli, Alhussein Fawzi, Omar Fawzi, and PascalFrossard. 2017. Universal adversarial perturbations. In Proceedings of the IEEEconference on computer vision and pattern recognition. 1765–1773.
[23] Seyed-Mohsen Moosavi-Dezfooli, Alhussein Fawzi, and Pascal Frossard. 2016.Deepfool: a simple and accurate method to fool deep neural networks. In Proceed-ings of the IEEE conference on computer vision and pattern recognition. 2574–2582.
[24] Nicolas Papernot, PatrickMcDaniel, Somesh Jha, Matt Fredrikson, Z Berkay Celik,and Ananthram Swami. 2016. The limitations of deep learning in adversarialsettings. In 2016 IEEE European Symposium on Security and Privacy (EuroS&P).IEEE, 372–387.
[25] Nicolas Papernot, Patrick McDaniel, Xi Wu, Somesh Jha, and Ananthram Swami.2016. Distillation as a defense to adversarial perturbations against deep neuralnetworks. In 2016 IEEE Symposium on Security and Privacy (SP). IEEE, 582–597.
[26] Haonan Qiu, Chaowei Xiao, Lei Yang, Xinchen Yan, Honglak Lee, and Bo Li. 2019.SemanticAdv: Generating Adversarial Examples via Attribute-conditional ImageEditing. arXiv preprint arXiv:1906.07927 (2019).
[27] Jonas Rauber, Wieland Brendel, and Matthias Bethge. 2017. Foolbox: A Pythontoolbox to benchmark the robustness of machine learning models. In ReliableMachine Learning in the Wild Workshop, 34th International Conference on MachineLearning. http://arxiv.org/abs/1707.04131
[28] Olga Russakovsky, Jia Deng, Hao Su, Jonathan Krause, Sanjeev Satheesh, SeanMa, Zhiheng Huang, Andrej Karpathy, Aditya Khosla, Michael Bernstein, et al.2015. Imagenet large scale visual recognition challenge. International journal ofcomputer vision 115, 3 (2015), 211–252.
[29] Lukas Schott, Jonas Rauber, Matthias Bethge, and Wieland Brendel. 2018.Towards the first adversarially robust neural network model on MNIST.arXiv:1805.09190 [cs.CV]
[30] Ramprasaath R. Selvaraju, Michael Cogswell, Abhishek Das, Ramakrishna Vedan-tam, Devi Parikh, and Dhruv Batra. 2017. Grad-CAM: Visual Explanations FromDeep Networks via Gradient-Based Localization. In The IEEE International Con-ference on Computer Vision (ICCV).
[31] Bo Shen, Ishwar K Sethi, and Vasudev Bhaskaran. 1998. DCT domain alphablending. In Proceedings 1998 International Conference on Image Processing. ICIP98(Cat. No. 98CB36269), Vol. 1. IEEE, 857–861.
[32] Karen Simonyan and Andrew Zisserman. 2014. Very deep convolutional networksfor large-scale image recognition. arXiv preprint arXiv:1409.1556 (2014).
[33] Jiawei Su, Danilo Vasconcellos Vargas, and Kouichi Sakurai. 2019. One pixelattack for fooling deep neural networks. IEEE Transactions on EvolutionaryComputation (2019).
[34] Christian Szegedy, Wei Liu, Yangqing Jia, Pierre Sermanet, Scott E. Reed,Dragomir Anguelov, Dumitru Erhan, Vincent Vanhoucke, and Andrew Rabi-novich. 2015. Going deeper with convolutions. In CVPR. IEEE Computer Society,1–9.
[35] Christian Szegedy, Vincent Vanhoucke, Sergey Ioffe, Jon Shlens, and ZbigniewWojna. 2016. Rethinking the inception architecture for computer vision. InProceedings of the IEEE conference on computer vision and pattern recognition.2818–2826.
[36] David J Wales and Jonathan P K Doye. 1997. Global Optimization by Basin-Hopping and the Lowest Energy Structures of Lennard-Jones Clusters Containingup to 110 Atoms. Journal of Physical Chemistry A 101, 28 (1997), 5111–5116.
[37] Dong Yi, Zhen Lei, Shengcai Liao, and Stan Z Li. 2014. Learning face representa-tion from scratch. arXiv preprint arXiv:1411.7923 (2014).
[38] Kaipeng Zhang, Zhanpeng Zhang, Zhifeng Li, and Yu Qiao. 2016. Joint FaceDetection and Alignment Using Multitask Cascaded Convolutional Networks.IEEE Signal Process. Lett. 23, 10 (2016), 1499–1503.