17
Reza Zadeh Matrix Completion with ALS @Reza_Zadeh | http://reza-zadeh.com
| Date post: | 08-Aug-2015 |
| Category: |
Data & Analytics |
| Upload: | spark-summit |
| View: | 1,674 times |
| Download: | 1 times |

Reza Zadeh
Matrix Completion with ALS
@Reza_Zadeh | http://reza-zadeh.com
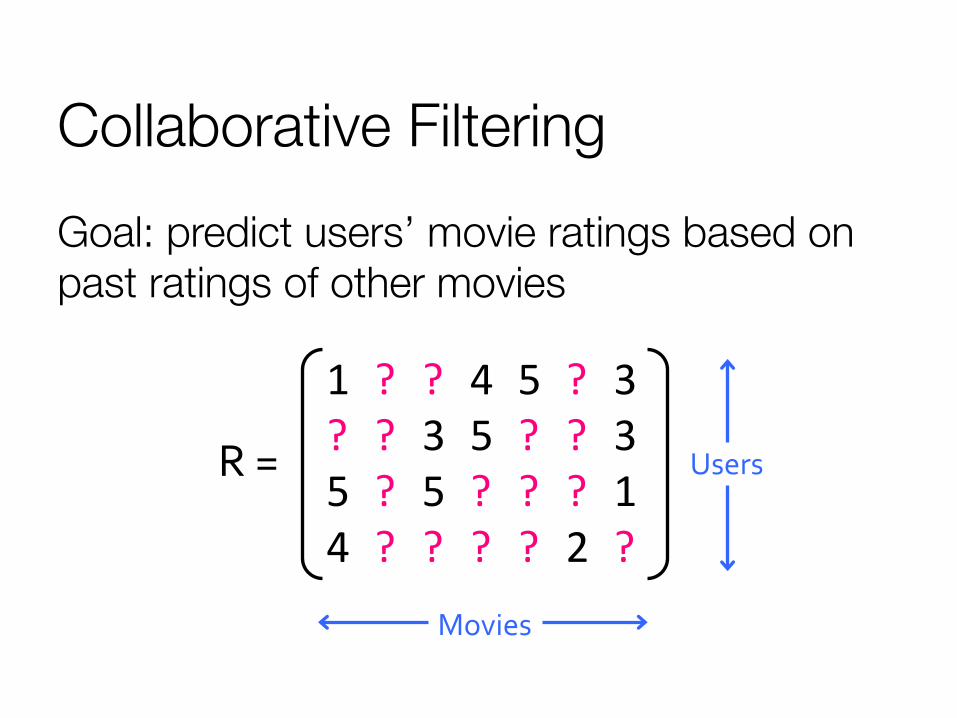
Collaborative Filtering Goal: predict users’ movie ratings based on past ratings of other movies
R =
1 ? ? 4 5 ? 3 ? ? 3 5 ? ? 3 5 ? 5 ? ? ? 1 4 ? ? ? ? 2 ?
Movies
Users

Don’t mistake this with SVD.
Both are matrix factorizations, however SVD cannot handle missing entries.

Optimization problem

Alternating Least Squares 1. Start with random A1, B1 2. Solve for A2 to minimize ||R – A2B1
T|| 3. Solve for B2 to minimize ||R – A2B2
T|| 4. Repeat until convergence
R A = BT

Attempt 1: Broadcast All

Attempt 2: Data Parallel

Attempt 3: Fully Parallel

ALS on Spark Cache 2 copies of R in memory, one partitioned by rows and one by columns Keep A & B partitioned in corresponding way Operate on blocks to lower communication
R A = BT
Matei Zaharia,"Joey Gonzales,"Virginia Smith
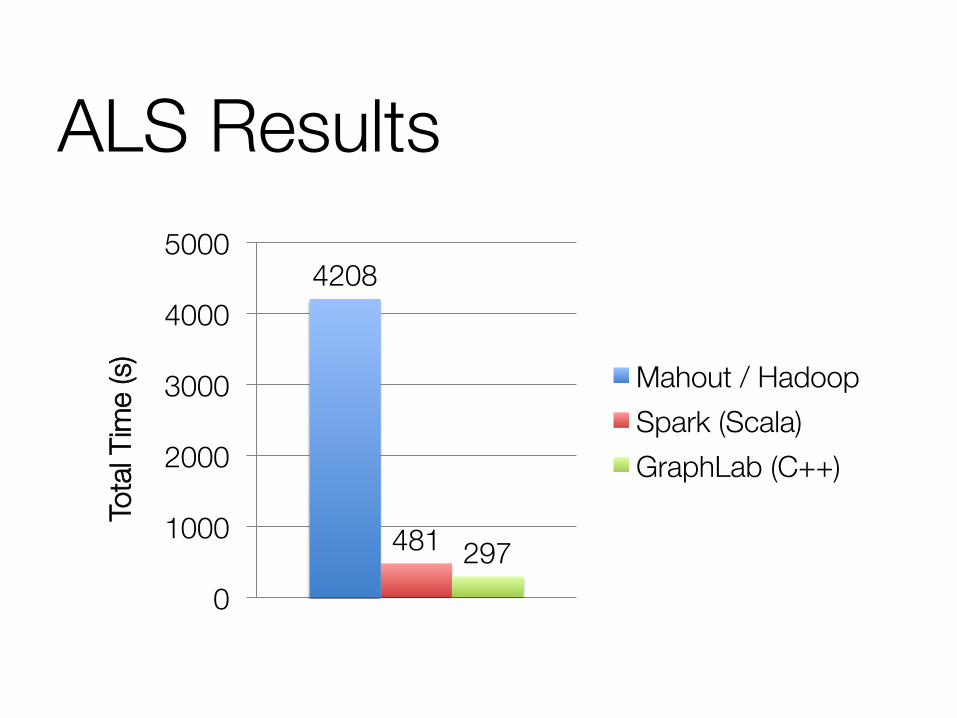
ALS Results
4208
481 297 0
1000
2000
3000
4000
5000
Tota
l Tim
e (s)
Mahout / Hadoop Spark (Scala) GraphLab (C++)

State of the Spark ecosystem

Most active open source community in big data
200+ developers, 50+ companies contributing
Spark Community
Giraph Storm
0
50
100
150
Contributors in past year

Project Activity M
apRe
duce
YA
RN HD
FS
Stor
m
Spar
k
0
200
400
600
800
1000
1200
1400
1600
Map
Redu
ce
YARN
HDFS
St
orm
Spar
k
0
50000
100000
150000
200000
250000
300000
350000
Commits Lines of Code Changed
Activity in past 6 months

Continuing Growth
source: ohloh.net
Contributors per month to Spark

Conclusions

Spark and Research Spark has all its roots in research, so we hope to keep incorporating new ideas!

Conclusion Data flow engines are becoming an important platform for numerical algorithms While early models like MapReduce were inefficient, new ones like Spark close this gap More info: spark.apache.org















