90
Advanced Speech Application Tuning Topics Yves Normandin, Nu Echo yves.normandin@nuech o.com SpeechTEK University August 2009
| Date post: | 31-Dec-2015 |
| Category: |
Documents |
| Upload: | nerea-french |
| View: | 33 times |
| Download: | 0 times |

Advanced Speech Application Tuning Topics
Yves Normandin, Nu [email protected]
SpeechTEK UniversityAugust 2009

Fundamental principles
Tuning is a data driven process– It should be done on representative samples of user
utterances You can only tune what you can measure
– And you must measure the right things Tuning can be quite time-consuming, so it’s important to
have efficient ways to:– Quickly identify where the significant problems are– Find and implement effective optimizations– Measure impact of changes

Activities in a tuning process
Produce application performance reports Call analysis Tuning corpus creation & transcription Benchmark setup + produce baseline results Grammar / dictionary / confidence feature tuning Confidence threshold determination Application changes (if required) Integration of tuning results in application Tests

Call analysis
Goal: Analyze complete calls in order to identify and quantify problems with the application– Focus is on detecting problems that won’t be obvious from
isolated utterances, e.g., usability, confusion, latency– This is the first thing that should be done after a deployment
For this, we need a call viewing tool that allows– Selecting calls that meet certain criteria (failures, etc.)– Stepping through a dialog
• Listening to a user utterance• Seeing the recognition result
– Annotating calls (to classify and quantify problems observed)

About call analysis
Only using utterances recorded by the engine doesn’t provide a complete picture– We don’t hear everything the caller said– Often difficult to interpret why the caller spoke in a certain
was (e.g., why was there a restart?) Having the ability to do full call recordings makes it
possible to get key missing information and better understand user behavior
An interesting trick is to ask questions to callers in order to understand their behavior

Tuning corpus creation
Build a tuning corpus for each relevant recognition context
For each utterance, the corpus should contain:– The waveform logged by the recognition engine– The active grammars when the utterance was collected– The recognition result obtained in the field
• Useful to provide an initial transcription• Allows comparing field results with lab results
– Utterance attributes, e.g.,• Interaction ID (“initial”, “reprompt-noinput”, “reprompt-nomatch”, etc.)• Date, language, etc.

Corpus transcription
Our tuning process assumes that accurate orthographic transcriptions are available for all utterances– Transcriptions are used to compute reference semantic
interpretations• The “reference semantic interpretation” is the semantic interpretation
corresponding to the transcription• It is produced automatically by parsing the transcription with the
grammar
– This needs to be done manually– Recognition result can be used as pre-transcription

Benchmark setup + Produce baseline performance results
There are several goals to this phase:– Obtain a stable ING/OOG classification for all utterances– Produce a reference semantic interpretation for all ING
utterances– Clean up grammars, if required– Produce a first baseline result
This can be a significant effort, but:– Effective tools make this fairly efficient– It doesn’t require highly skilled resources

High-level grammar tuning process

Scoring recognition results:Basic definitions
Symbol Name DescriptionA Accepted Confidence feature above
confidence thresholdR Rejected Not acceptedC Correct Recognition result is “correct” (see
comment)I Incorrect Recognition result is incorrecting In-grammar Utterance is in-grammaroog Out-of-grammar Utterance is out-of-grammar

Remarks
We use the term “confidence feature” to designate any score that can be used to evaluate confidence in a recognition result– We often compute confidence scores that provide much better results
than those provided by the recognition engine confidence score. The terms “accept” and “reject” mean that the confidence feature
is above or below the threshold being considered The definition of “correct” should be configurable, e.g.,
– Semantic scoring vs. word-based scoring– 1-best vs. N-best scoring

Scoring recognition results:Sufficient statistics
Symbol Name DescriptionAC Accepted
CorrectUtterances that are both accepted and correct
AI Accepted Incorrect
Utterances that are both accepted and incorrect
RC Rejected Correct Utterances that are both rejected and correct
RI Rejected Incorrect
Utterances that are both rejected and incorrect
Roog Rejected out-of-grammar
Rejected out-of-grammar utterances
Aoog Accepted out-of-grammar
Accepted out-of-grammar utterances

Equivalence with commonly used symbols
Common symbol Common name EquivalenceCA-in Correct accept in-
grammarAC
FA-in False accept in-grammar
AI
FR-in False reject in-grammar RC + RI
CR-out Correct reject Roog
FA-out False accept out-of-grammar
Aoog

All metrics can be calculated based on these sufficient statistics
All metrics clearly defined so that there is no ambiguity

Any metrics can be calculated based on the sufficient
statisticsKey metrics:
Metric Formula Description
Correct accept rate AC/ing
Percentage of in-grammar utterances that are accepted and correct
False accept rate (AI+Aoog)/all Percentage of utterances that are
accepted and incorrectFalse
accept rate (AI+Aoog)/A Percentage of accepted utterances that are incorrect
Includes both incorrect recognitions and OOG utterances

Fundamental performance plot:Correct Accept vs. False Accept
High Threshold
Low Threshold
False Accept rate
Correct Accept rate

The graphical view makes improvements immediately visible
That’s a very effective way of
measuring progress

Problems with the basic tuning process
Missing reference semantic
interpretations
• A big portion of transcriptions are not covered by the grammar
• Many should not be considered OOG
Definition of OOG (“out-of-grammar”)
• Based on the recognition grammar
• Impossible to get meaningful comparisons when the grammar is changed

Some reasons why transcriptions are not covered
Utterances with no possible interpretation
• Impossible to extract a meaning that’s relevant to the application• Therefore, no reference semantic interpretation
Unsupported formulations
• The utterance has a clear semantic interpretation, but…• has strange formulations, repeats, false starts, extraneous speech, etc.
Grammar-transcription mismatches
• Transcription errors• Spelling differences (e.g., for names)

Examples (birth date grammar)
Type Examples
No possible interpretation
the sixth ofni nineteen seventy one zero two the day fourteeni no understand that's my friend he gonna talk to
you please
Unsupported formulations
the fifth fifth month fourth day of forty sixmarch eleven six oneof ju thirty four nineteen thirty four six of juneja january twentieth nineteen forty six

What to do about such utterances?
We certainly can’t ignore them– They’re represent the reality of what users actually say– The application has to deal with that
We can’t just assume they should be rejected by the application– Many of these are actually perfectly well recognized, often
with a high score• The “False Accept” rate becomes meaningless
– Many of them should be recognized We can’t score them because we have no reference
interpretation

Our approach:“Human perceived ING/OOG”
Doesn’t depend on what the recognition grammar actually covers– Makes results comparisons meaningful since we always have
the same sets of ING and OOG utterances Provides accurate and realistic performance metrics
– CA measured on all valid user utterances– Reliable FA measurement for precise high threshold setting
A transcription is considered ING (valid) if a human can easily interpret it;
It is OOG otherwise

Challenge: Computing the reference semantic
interpretation
Use reference grammar distinct from recognition grammar
• Can have extensive coverage since this has no impact on recognition accuracy
• Recognition grammar can be developed by pruning the reference grammar
Transcription transformations• Transform
transcriptions so that can be parsed by the reference grammar
• Transformation framework :• pattern replacement• substitutions• paraphrases
Two techniques:

Sample regex transformations:Remove “as in” in postal codes

Sample regex transformations:Remove repetition of first letter
Repetition of first letter

Focus on high confidence OOG utterancesWe want to avoid utterances
incorrectly classified as false accepts
Transcription error (should be “one”)

Tool to add paraphrases
Aligns paraphrase
with transcription
Shows if the paraphrase is in-grammar
A paraphrase replaces a transcription by another one with
same meaning that parses

Postal code example
The advantage of supporting certain repeats, corrections, and the form “m as in mary” is clearly
demonstrated

Postal code exampleImpact of adding support for “p as in peter”

Comments on the transformations-based approach
Advantages– Not dependant on a specific semantic representation– The transformation framework makes this very efficient
• Single rules can deal with dozens of utterances
Problems– For really “natural language utterances”, transformed
transcriptions end up bearing little resemblance to the original one
– Better to use semantic tagging in this case

Note: The reference grammar is often a good starting point for the recognition grammar
High-level grammar tuning process (revisited)
Transcribe utterances
Grammars / dictionaries
Modify grammars / dictionaries
Generate semantic reference
Perform speech recognition
Field utterances
Score results
Identify improvements
Transcriptions
Semantic references
Recognition results
Reference grammars
Modify reference grammars
Transformations
Add transformations
(1) Benchmark setup
(2) Tuning

Key advantage: Meaningful performance comparisons
Scoring done only on address slots
Same set of ING and OOG utterances in both cases, despite significant grammar changes ensures that comparisons are meaningful
Address grammar that supports
apartment numbers
Address grammar that doesn’t

Key advantage: Better tuned applications
With transformationsThreshold = 0.63CA = 83.0%
WithoutThreshold = 0.85CA = 78.4%
0.5% FA

Other advantages
Lab results truly represent field performance– Better confidence in the results obtained– Little surprises when applications are deployed

Techniques to identify problems

Fundamental techniques
Listen to problem utterances– This includes incorrectly recognized utterances AND correctly recognized
utterances with a low score– This cannot be emphasized enough
Identify the largest sources of errors– Frequent substitutions– Words with high error rate– Slot values with high error rate
Look at frequency patterns in the data Analyze specific semantic slots
– Certain slots cause more problems than others Compare experiments

Substitutions / word errors
Are there words with unusually high error rates?

Then examine all sentences with a specific substitution(using a substitution filter)In this case:
a eight
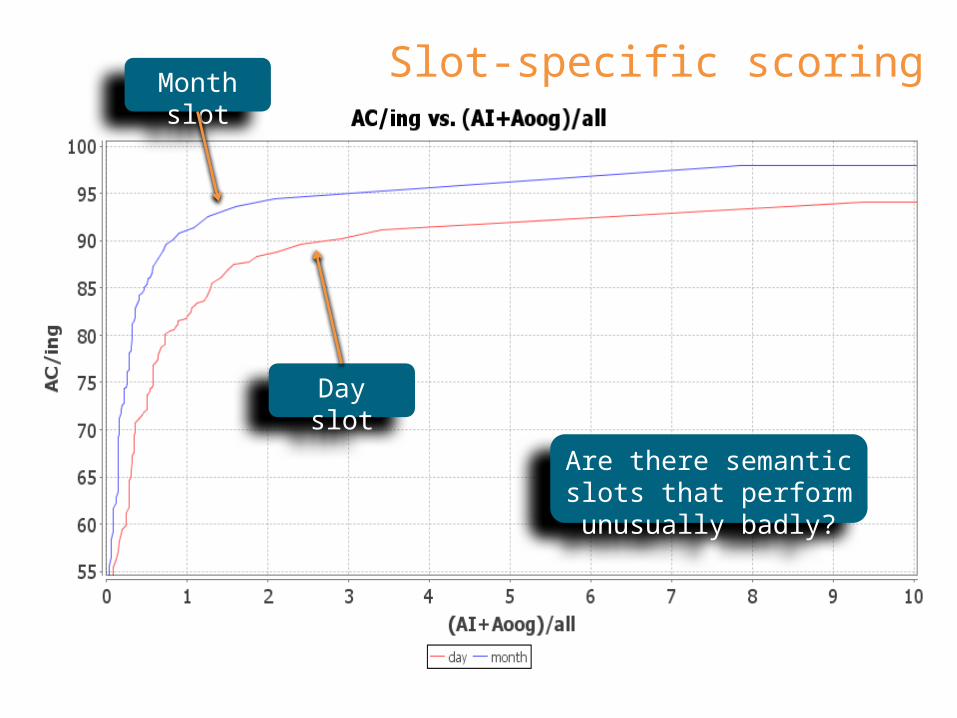
Slot-specific scoring
Day slot
Month slot
Are there semantic slots that perform unusually badly?

Tags and Tag Reports
In Atelier, we can use tags to create partitions based on any utterance attribute– Semantic interpretation patterns in the transcription or the recognition
result– ING / OOG– Index of correct result in the N-best list– Scoring category– Confidence score ranges
Tags can be used to filter the utterances in powerful ways Tag reports are used to compute selected metrics for any
partition of the utterances

Use tag reports to find out where the biggest problems
areSort based on correct accept
rate
Semantic tags

Filter utterances in order to focus on specific problem
casesThe “saint-leonard” borough has a high error rate. Let’s look at these utterances

Looking at semantic substitutions
What are the most frequent substitutions with “saint-leonard”?

Comparing experiments
This precisely shows the impact of a change on an utterance per utterance basis
Can choose which fields to consider for comparison purposes

Computing grammar weights for diagnostic purposes
public $date = ($intro | $NULL) ( $month {month=month.month} (the|$NULL) $dayOfMonth {day=dayOfMonth.day} |
$monthNumeric {month=monthNumeric.month} (the|$NULL) $dayOfMonth {day=dayOfMonth.day} |
(the|$NULL) $dayOfMonthThirteenAndOver {day=dayOfMonthThirteenAndOver.day} $monthNumeric {month=monthNumeric.month} |
(the|$NULL) $dayOfMonthThirteenAndOver {day=dayOfMonthThirteenAndOver.day} of the $monthNumeric {month=monthNumeric.month} |
(the|$NULL) $dayOfMonth {day=dayOfMonth.day} $month {month=month.month} | (the|$NULL) $dayOfMonth {day=dayOfMonth.day} of $month {month=month.month} ) $year {year=year.year};
There are many ways of saying a birth date. Which ones are worth covering?

Computing grammar weights for diagnostic purposes
public $date = ($intro | $NULL) ( $month {month=month.month} (the|$NULL) $dayOfMonth {day=dayOfMonth.day} |
$monthNumeric {month=monthNumeric.month} (the|$NULL) $dayOfMonth {day=dayOfMonth.day} |
(the|$NULL) $dayOfMonthThirteenAndOver {day=dayOfMonthThirteenAndOver.day} $monthNumeric {month=monthNumeric.month} |
(the|$NULL) $dayOfMonthThirteenAndOver {day=dayOfMonthThirteenAndOver.day} of the $monthNumeric {month=monthNumeric.month} |
(the|$NULL) $dayOfMonth {day=dayOfMonth.day} $month {month=month.month} |
(the|$NULL) $dayOfMonth {day=dayOfMonth.day} of $month {month=month.month} ) $year {year=year.year};
January the sixteenth eighty
zero one sixteen eighty
sixteen zero one eighty
sixteen of the zero one eighty
sixteen January eighty
the sixteenth of January eighty

Compute frequency weights based on transcriptions
public $date = (/0.00001/ $intro | /1/ $NULL) ( /0.9636/ $month {month=month.month} (/0.06352/ the | /0.9365/ $NULL) $dayOfMonth {day=dayOfMonth.day} |
/0.001654/ $monthNumeric {month=monthNumeric.month} (/0.00001/ the | /1/ $NULL) $dayOfMonth {day=dayOfMonth.day} |
/0.004962/ (/0.00001/ the | /1/ $NULL) $dayOfMonthThirteenAndOver {day=dayOfMonthThirteenAndOver.day} $monthNumeric {month=monthNumeric.month} |
/0.0008271/ (/1/ the | /0.00001/ $NULL) $dayOfMonthThirteenAndOver {day=dayOfMonthThirteenAndOver.day} of the $monthNumeric {month=monthNumeric.month} |
/0.012406/ (/0.00001/ the | /1/ $NULL) $dayOfMonth {day=dayOfMonth.day} $month {month=month.month} |
/0.01654/ (/0.25/ the | /0.75/ $NULL) $dayOfMonth {day=dayOfMonth.day} of $month {month=month.month} ) $year {year=year.year};
Weight means probability of using alternative

Discriminative grammar weights based on recognition
resultspublic $date = (/-110.743109/ $intro | /110.7751/ $NULL) ( /291.1/ $month {month=month.month} (/-104.318/ the | /395.418/ $NULL) $dayOfMonth {day=dayOfMonth.day} |
/-265.0/ $monthNumeric {month=monthNumeric.month} (/-75.4683/ the | /-189.53/ $NULL) $dayOfMonth {day=dayOfMonth.day} |
/-16.85/ (/-17.085/ the | /0.2347/ $NULL) $dayOfMonthThirteenAndOver {day=dayOfMonthThirteenAndOver.day} $monthNumeric {month=monthNumeric.month} |
/0.000035/ (/0.000035/ the | /0/ $NULL) $dayOfMonthThirteenAndOver {day=dayOfMonthThirteenAndOver.day} of the $monthNumeric {month=monthNumeric.month} |
/-21.16/ (/-10.058/ the | /-11.01/ $NULL) $dayOfMonth {day=dayOfMonth.day} $month {month=month.month} |
/11.94/ (/-2.211/ the | /14.15/ $NULL) $dayOfMonth {day=dayOfMonth.day} of $month {month=month.month} ) $year year=year.year};
Positive: Alternative should be favored
Negative: Alternative should be disfavored

Looking at utterance distribution statistics: Address
date grammar
Note that 20 (“vingt”) has
lowest recognition rate
People move more on the first
of the month

What are the substitutions for 20 (“vingt”, in French)?

Statistics for the month reflect when the data was collected

Result-specific post-processing

Results-specific post-processing
Many recognition contexts are a combination of very different things– A complex grammar in parallel with a command grammar– A date grammar containing actual dates (“july first 2009”) and
relative dates (“immediately”) These often behave very differently
– Recognition rates– Confidence scores– Tendency to match OOG

Example: Apartment number grammar + “no apartment”“no apartment”
Apartment number
Combined

Remarks on results-specific analysis
Results-specific analysis requires looking at the results from two perspectives:
– What was spoken (this is the user’s perspective)
– What was recognized (this is the application’s perspective)
Spoken Z
OOG utterances
Spoken X
Recognized X
Spoken Y

Setting threshold so thatFA < 0.5%
“no apartment”: Threshold = 0.0
(AC/ing = 98.5%)
Apartment number:
Threshold = 0.98 (AC/ing = 43%)
Combined: Threshold = 0.91 (AC/ing = 87%)

Basic post-processing algorithm

Basic post-processing algorithm
Tuning has to assume certain capabilities from the dialog
The current discussion will be based on the use of the “Basic post-processing algorithm”:– The recognition result is processed using an ordered set of
“post-processors”• Default is a single, “match-all” post-processor
– The first post-processor that “matches” the recognition result is the one that “handles” the recognition result • Normally, matching is done with the top recognition hypothesis
– If no post-processor matches the result, it is considered a “no-match”

Basic post-processing algorithm
A post-processor is defined by:– A semantic pattern matcher
• Matches semantic patterns in the recognition result• Normally the top hypothesis in N-best list
– A confidence feature– A set of N confidence thresholds (normally 1 or 2)
• These define N+1 confidence zones
– A set of N+1 dialog decisions• One for each confidence zone• Defines what to do next
Thresholds can vary based on interaction count

Apartment grammar with special post-processor for “no
apartment”
Semantic pattern matcher
Confidence feature
Confidence thresholds

Simple three-choice menu (single accept/reject threshold)

Techniques to improve performance

Fundamental techniques
Improve grammar coverage Improve phonetic pronunciations Add grammar weights Add grammar decoys Optimize confidence thresholds

Tuning phonetic pronunciations
Certainly one of the most effective ways to improve accuracy (as we all know)– Compound words, unusual names, under-articulated words,
etc. Enhancing large vocabulary phonetic dictionaries
– Our approach:• Rich baseform phonetic dictionary• Rules-based engine to transform pronunciations and add new ones
– Advantages:• Systematic and consistent application of rules• Easy to measure the impact of each rule• Rules used can be adapted to specific context (e.g., isolated names)

Tuning phonetic pronunciations
Baseform pronunciations
OSR system dictionary
Dictionary generated with
latest rules

Sample rules (French)
Release of /i/– In a closed syllable, /i/ can become /e/– Example: Gilles /Z i l/ → [Z i l] or [Z e l]
Semi-vowel treatment– When /i/ is followed by a vowel, insert a /j/ between /i/ and the
vowel OR do nothing OR insert a /j/ and then remove /i/.– Example: Dion /d i o~/ → [d i o~] or [d i j o~] or [d j o~]
End schwa insertion– When a word ends by a graphic "e", add /@/ if the word’s last
phonetic symbol is a consonant OR do nothing– Example: Houde /u d/ → [u d] or [u d @]

Using decoys to improve OOG robustness
Repeat + decoy (FA=0.5%)Threshold = 0.79
CA = 92.5%
Repeat (FA=0.5%)Threshold = 0.95
CA = 83.0%

Impact of decoys
Values Threshold AC/ing (AI+Aoog)/allcancel 0.96 89.65% 0.47%repeat 0.94 85.60% 0.60%validate 0.74 98.16% 0.78%
Values Threshold AC/ing (AI+Aoog)/allcancel 0.39 94.28% 0.28%repeat 0.57 94.64% 0.56%validate 0.30 98.76% 0.48%
Without decoys
With decoys
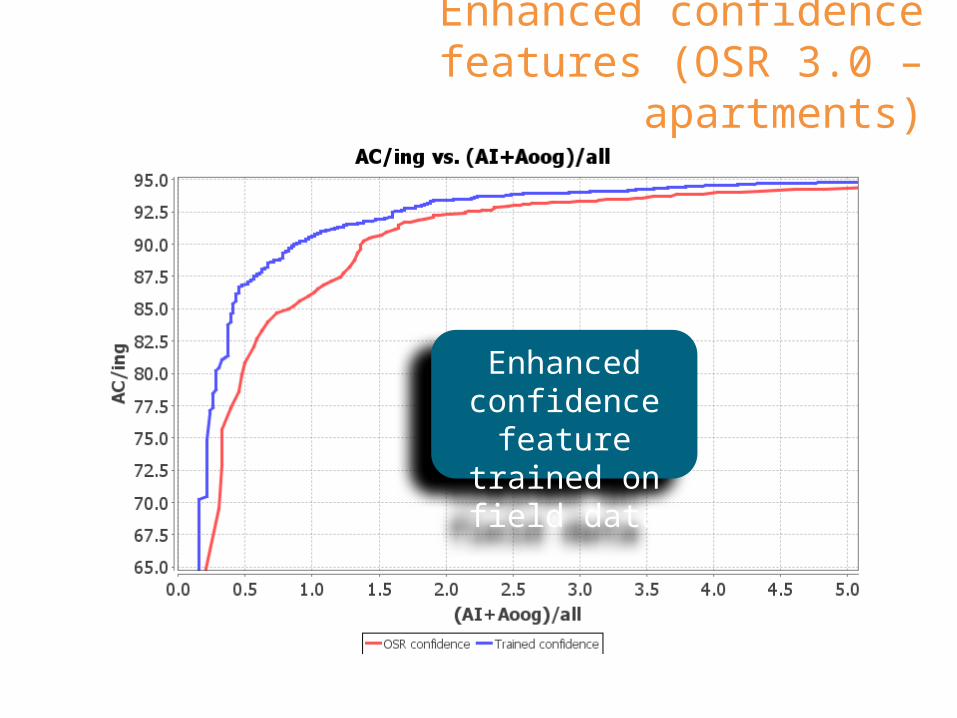
Enhanced confidence features (OSR 3.0 – apartments)
Enhanced confidence feature trained on field data

Impact of enhanced confidence features
6% improvement in correct accept rate at 0.5% FA
• Fewer confirmations• Improved success rate• Better user experience
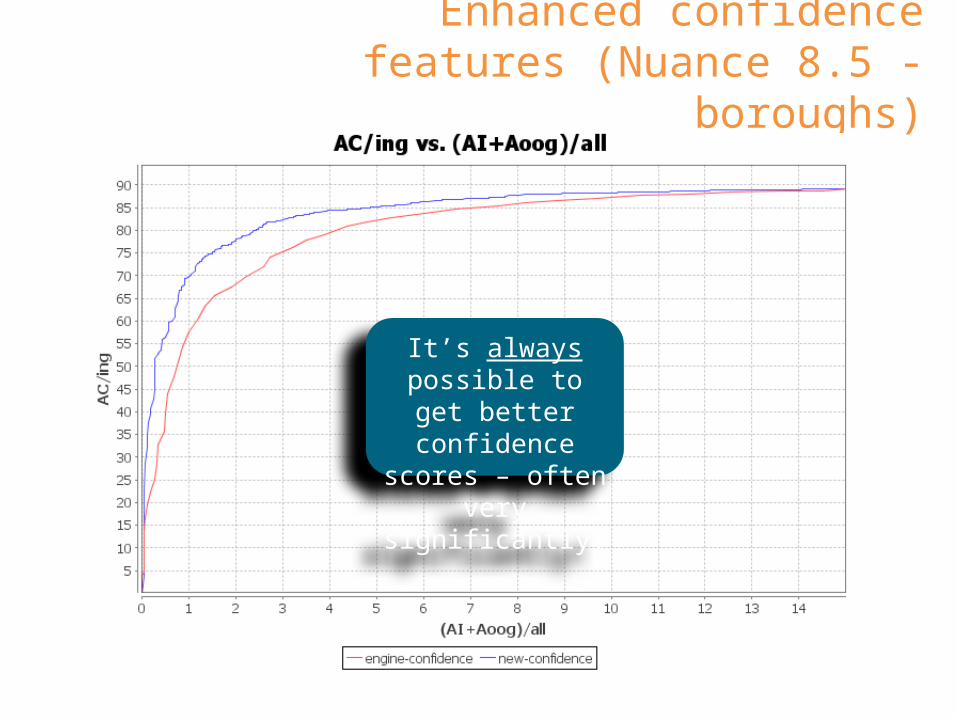
Enhanced confidence features (Nuance 8.5 - boroughs)
It’s always possible to get better confidence scores – often very
significantly!

Other reasons to use enhanced confidence scores
For certain tasks, the confidence scores produced by the engine are plain bad– On French postal codes with OSR 3, 20% of utterances have
a score of 0.01 (many of which are good) Need specialized confidence scores Need to re-compute confidence scores after post-
processing a recognition result

When to propose another choice from the N-best list?
In some situations, after a no-to-confirm, it may be a good idea to propose the second choice from the N-best list
That depends on many factors, including– The a priori probability that the utterance was OOG– Our ability to evaluate whether the second choice is correct– How correct results are distributed in the N-best list

When to propose another choice?
Initial utterance distribution
(date grammar)
Utterance distribution after excluding correct
top-1 results

The confidence feature is important
Here we compare using the confidence score of the first and second hypothesis
20% probability of proposing an incorrect result

Looking at utterances is also important
Second choice has better chance to be
correct when the first result is a date
(<day,month> or <day,month,year>)

Restricting to <day,month> or <day,month,year>
7.5% probability of proposing an incorrect result

Setting confidence thresholds: Confidence zones
0.0
1.0
High threshold
Low threshold
Low confidence zone
High confidence zone
Medium confidence zone

Setting confidence thresholds
Thresholds can have a large impact on success rate and user experience
So, how can we determine the “optimal” thresholds?– Optimal thresholds are those that optimize key dialog
performance metrics
Threshold Too high Too lowHigh Too many
confirmationsFA rate too high
Low Some people will never get recognized
Too many false confirmations

How can we measure the performance of a dialog?
One approach is to have a cost function based on a dialog outcome and what happened in the dialog
Dialog outcomes:– Success: The dialog has successfully completed with the
correct result– Failure: The dialog has successfully completed, but with an
incorrect result– Max-error: The dialog was aborted before being completed
(e.g., max errors)

Dialog performance
The total performance of a dialog can be calculated using:
Where:– path is a path in the dialog graph, with:– cost(path) the path’s cost
Sample costs:– Failure: 10– Max-error: 1– Each interaction: 0.4

Dialog simulations
Finding the impacts of thresholds even in simple dialogs can get quite complex
What we’re trying to do with dialog simulations is find the optimal dialog parameters based on performance statistics computed from field utterances

Dialog simulations
reject
accept
yesno confirm
reject
Can select different statistics based on interaction count
Probability of “yes”, “no”, “OOG” configurable based
on whether response is correct or not
Can model “user consistency”
Uses recognition statistics computed on confirmation utterances

How performance changes between interactions
Apartment utterances
First interaction
Other interactions

How performance changes between interactions
Boroughs routing application
Note that data distribution may also change significantly between interactions, sometimes even suggesting grammar changes

Simulation tool(date dialog)Dialog parameters
Every path through the dialog
Path probability
Path outcome
Dialog performance metrics
Dialog path details

Sample simulation results
Simulations make it easier to understand the impact of dialog parameters
Sometimes the results can be quite surprising
Success
rate
Failure
rate
Mean interaction
countScore
Untuned 95.30% 2.40% 1.16 -0.727Tuned 96.10% 0.40% 1.26 -0.577

Another example:Borough routing application
Constraint: 2 interactions maximum
Objective: Maximize success rate Simulation tool allowed us to find optimal threshold
reject
confirmaccept
acceptreject
reject
yesno

Other issues
Testing that the tuning results have been correctly integrated in the application
Comparing lab results with field results

Conclusion
For tuning to be effective, lab results must accurately predict field performance– Representative utterances– Meaningful metrics– Careful management of OOG utterances– System parameters
With lots of data to analyze, it’s critical to have tools to rapidly identify where the big problems are
Several small optimizations can add up to big gains– Enhanced confidence score, results-specific post-processing,
pronunciation tuning, grammar decoys, grammar weights, grammar coverage optimization, threshold tuning, etc.

















