30
Adversarial Search 1

Adversarial Search
1

Adversarial Search
• The ghosts trying to make pacman loose
• Can not come up with a giant program that plans to the end,
because of the ghosts and their actions
• Goal: Eat lots of dots and lots of ghosts (not most hideous ones)
and not die
• How to come up with an action based on reasoning ahead about
what both you and your adversary might do 2

Adversarial Search Problems: Games
• Many different kinds of games!
– Deterministic or stochastic?
Is there any dice? Does any action have multiple random
outcomes?
– One, two, or more players?
Multiple agents may cooperate, compete, or act in between.
– Zero sum?
One utility function: you want to make it big and the adversary
wants to make it small
– Perfect information (can you see the state)?
• Need algorithms for calculating a strategy (policy) which
recommends a move in each state3

Deterministic Games• Many possible formalizations, one is:
– States: S (start at s0)
– Players: P={1 ... N} (usually take turns)
– Actions: A (may depend on player/state)
– Transition Function (also called the model): S×A → S– Transition Function (also called the model): S×A → S
– Terminal Test: S → {t, f}
– (Terminal) Utility Function: S × P → R
• Solution for a player is a policy: S → A
4

Deterministic Single-Player?• Deterministic, single player, perfect information:
– Know the rules
– Know what actions do
– Know when you win
– E.g. 8-Puzzle, Rubik’s
cube
• … it’s just a search!• … it’s just a search!
5
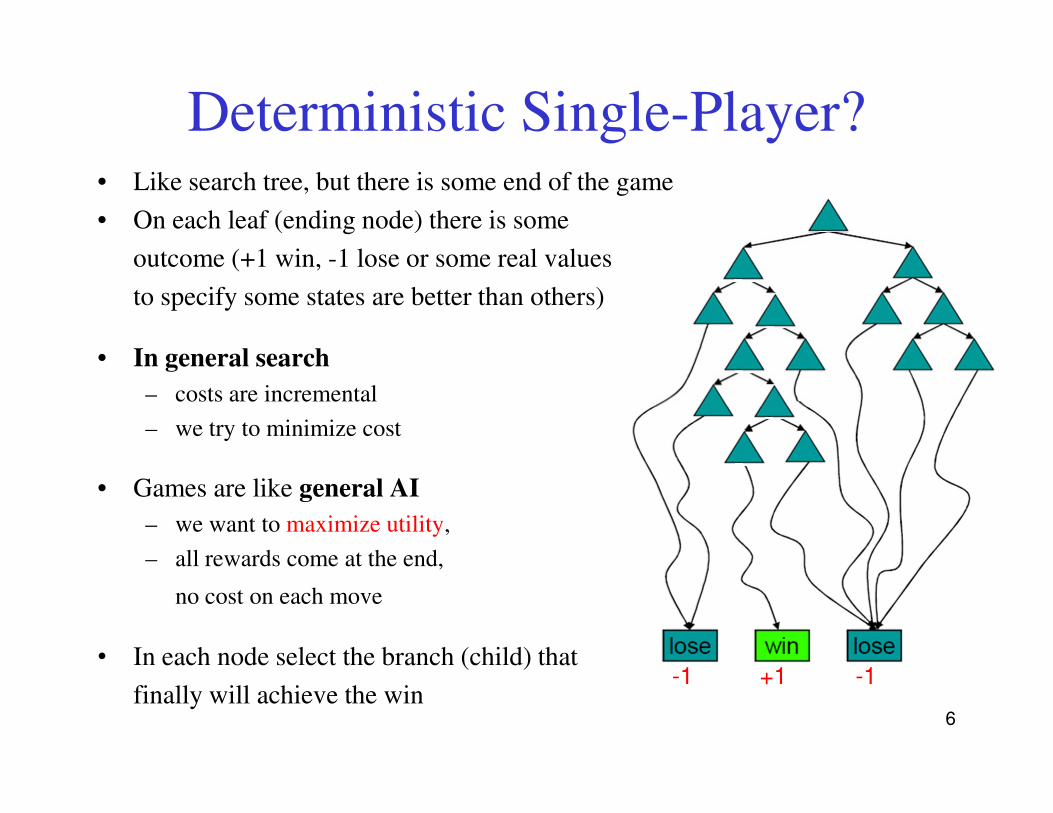
Deterministic Single-Player?• Like search tree, but there is some end of the game
• On each leaf (ending node) there is some
outcome (+1 win, -1 lose or some real values
to specify some states are better than others)
• In general search
– costs are incremental
– we try to minimize cost
• Games are like general AI
– we want to maximize utility,
– all rewards come at the end,
no cost on each move
• In each node select the branch (child) that
finally will achieve the win 6
+1 -1-1

Deterministic Single-Player?• … it’s just a search!
• Slight reinterpretation:
– Each node stores a value: the
best outcome it can reach under
optimal play
– This is the maximal value of
its children (the maxValue)
+1
its children (the maxValue)
– Note that we don’t have path sums
as before (utilities are at leaves)
– Here, value at the root is +1
since you can force the win
• After search,
can pick move that leads to best node 7+1 -1-1
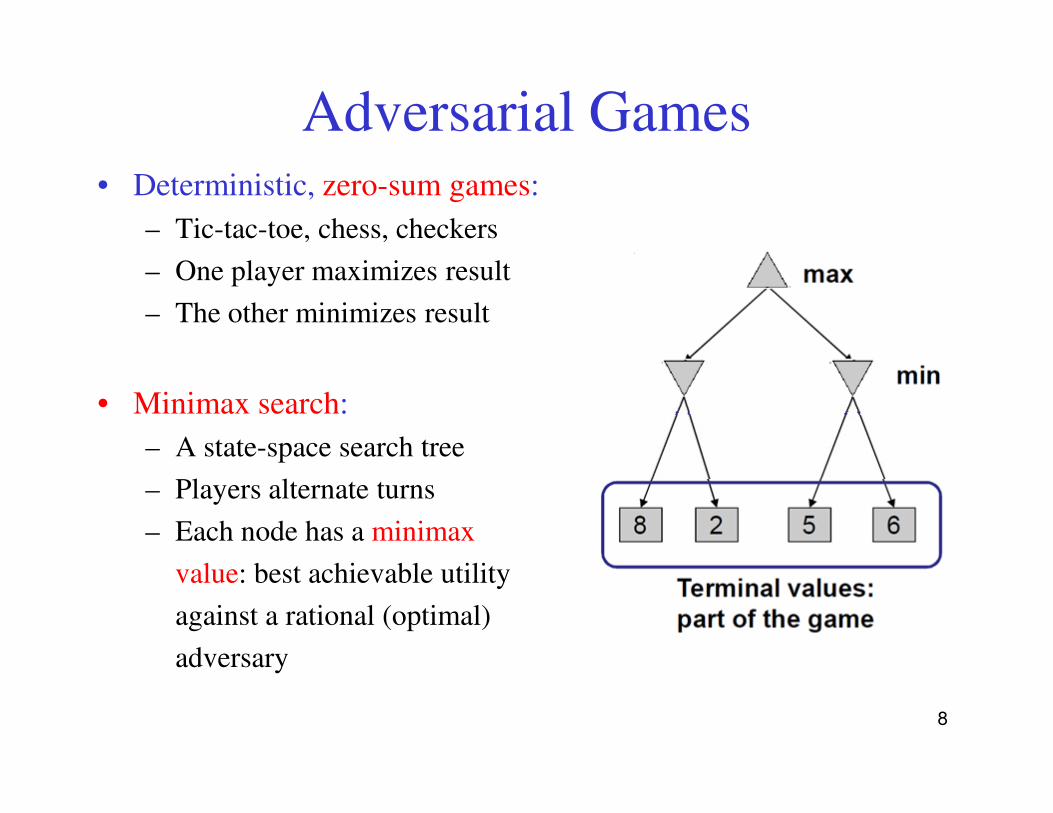
Adversarial Games• Deterministic, zero-sum games:
– Tic-tac-toe, chess, checkers
– One player maximizes result
– The other minimizes result
• Minimax search:• Minimax search:
– A state-space search tree
– Players alternate turns
– Each node has a minimax
value: best achievable utility
against a rational (optimal)
adversary
8
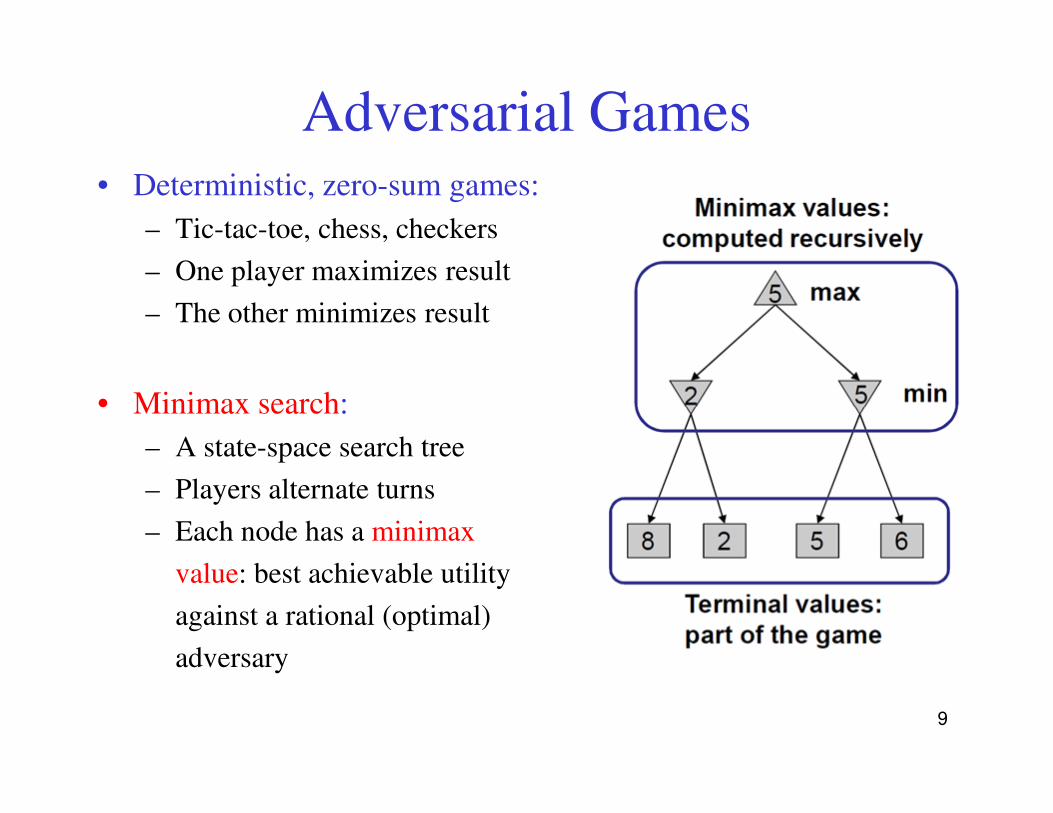
Adversarial Games• Deterministic, zero-sum games:
– Tic-tac-toe, chess, checkers
– One player maximizes result
– The other minimizes result
• Minimax search:• Minimax search:
– A state-space search tree
– Players alternate turns
– Each node has a minimax
value: best achievable utility
against a rational (optimal)
adversary
9

Computing Minimax Values• Two recursive functions:
– max-value maxes the values of successors
– min-value mins the values of successors
def value(state):
If the state is a terminal state: return the state’s utilityIf the state is a terminal state: return the state’s utility
If the agent is MAX: return max-value(state)
If the agent is MIN: return min-value(state)
def max-value(state):
Initialize max = -∞
For each successor of state:
Compute value(successor)
Update max accordingly
Return max10

11
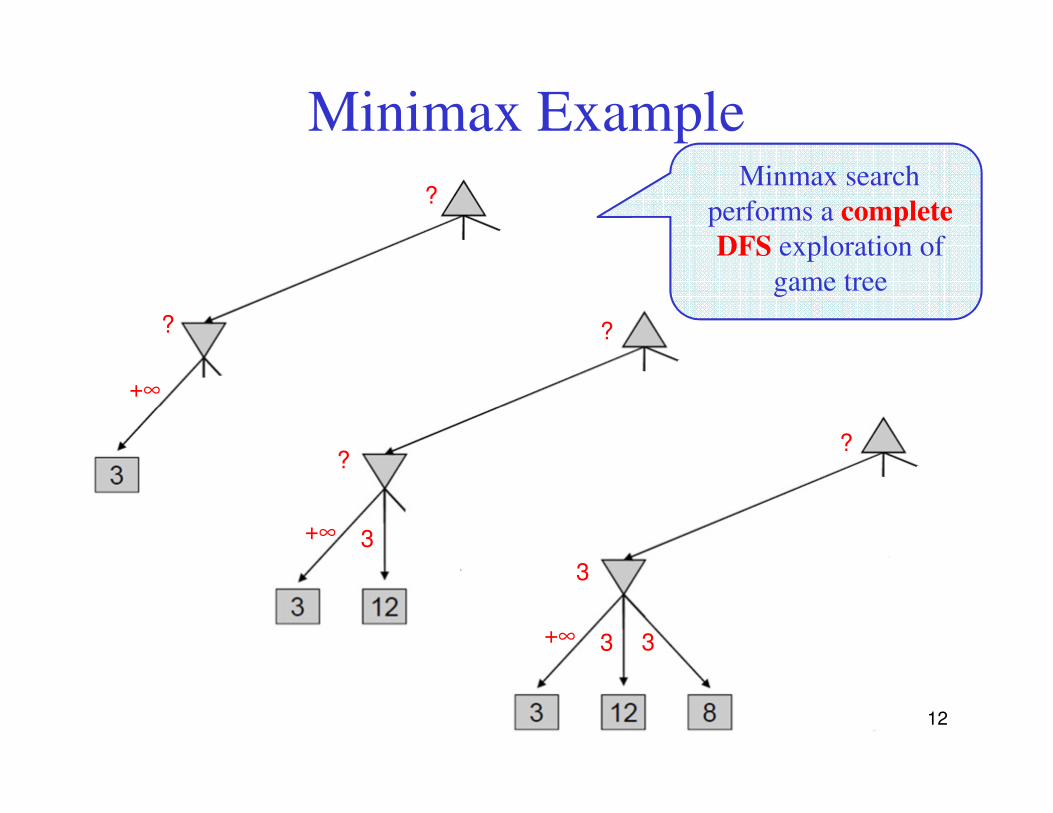
Minimax Example
+∞
?
? ?
Minmax search
performs a complete
DFS exploration of
game tree
12
+∞ 3
+∞ 3 3
??
3

Minimax Example
3
13
23 2

Tic-Tac-Toe Game Tree
14
Fewer than 9! Terminal nodes
Minmax value at the root is 0
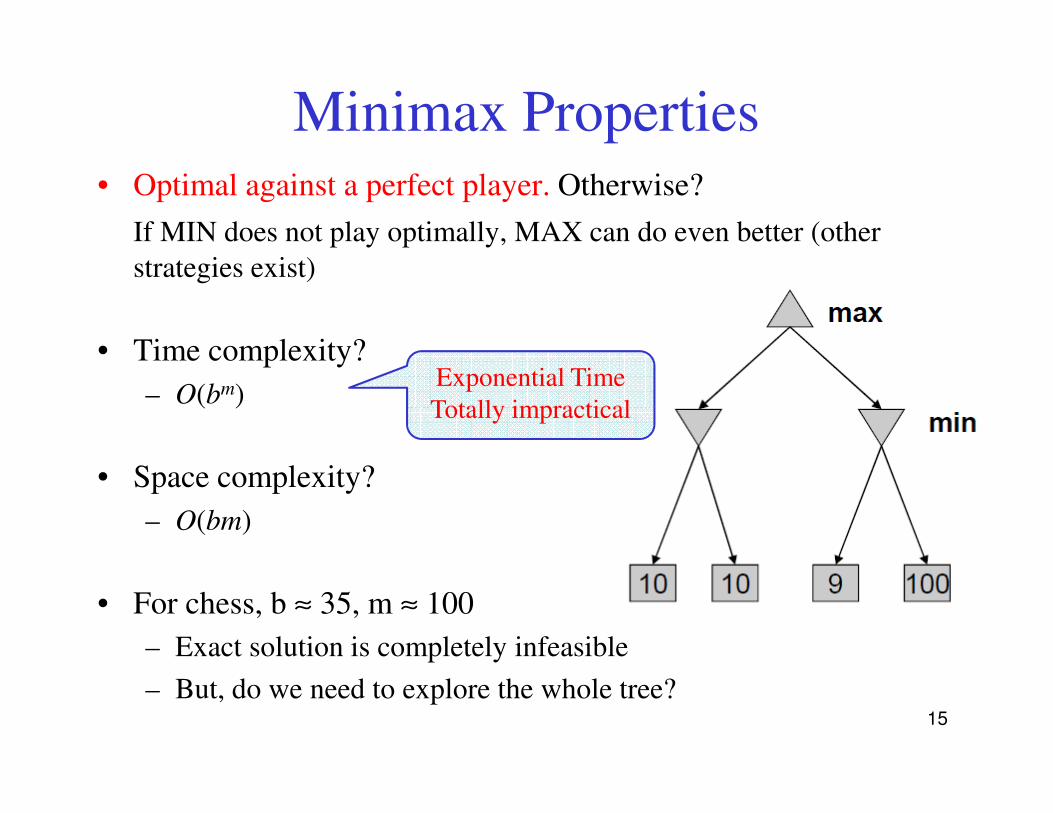
Minimax Properties• Optimal against a perfect player. Otherwise?
If MIN does not play optimally, MAX can do even better (other
strategies exist)
• Time complexity?
– O(bm)Exponential Time
Totally impractical– O(b )
• Space complexity?
– O(bm)
• For chess, b ≈ 35, m ≈ 100
– Exact solution is completely infeasible
– But, do we need to explore the whole tree?15
Totally impractical
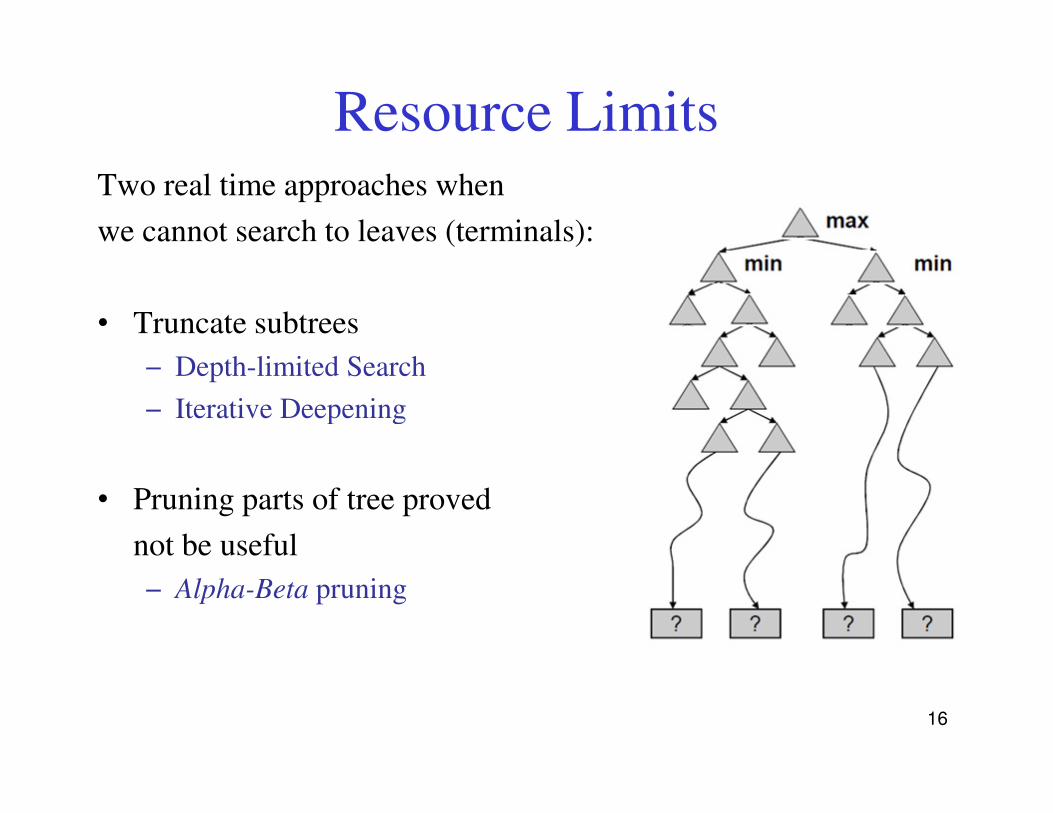
Resource LimitsTwo real time approaches when
we cannot search to leaves (terminals):
• Truncate subtrees
− Depth-limited Search
− Iterative Deepening− Iterative Deepening
• Pruning parts of tree proved
not be useful
− Alpha-Beta pruning
16
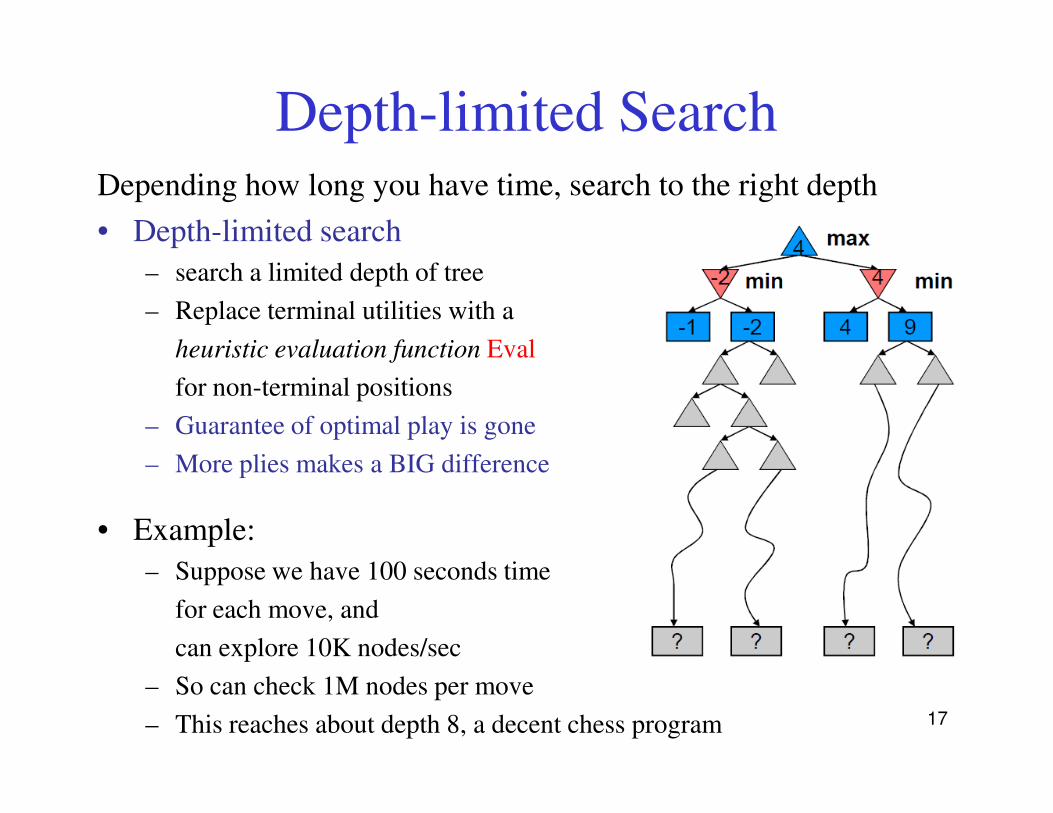
Depth-limited SearchDepending how long you have time, search to the right depth
• Depth-limited search
– search a limited depth of tree
– Replace terminal utilities with a
heuristic evaluation function Eval
for non-terminal positions
– Guarantee of optimal play is gone
– More plies makes a BIG difference
• Example:
– Suppose we have 100 seconds time
for each move, and
can explore 10K nodes/sec
– So can check 1M nodes per move
– This reaches about depth 8, a decent chess program 17

Iterative DeepeningIf not sure about time, search depth by depth
• Iterative deepening, use DFS to do BFS
− Do a DFS which only searches for paths of
length 1. (DFS gives up on any path of
more than 1)
− If still have time, do a DFS which only
searches paths of length 2 or less.
− If still have time, do a DFS which only
searches paths of length 3 or less.
….and so on.
Note: wrongness of Eval functions matters less and
less the deeper the search goes!
18

Evaluation Functions• Function which scores non-terminal states (estimated achievable
utility)
• Ideal function: returns the exact utility of the state
• In practice: typically weighted linear sum of features of states:
• e.g. f1(s) = (numWhiteQueens – numBlackQueens), etc. 19
)()()()( 2211 sfwsfwsfwsEval nn+++= K
Minimax Example
20
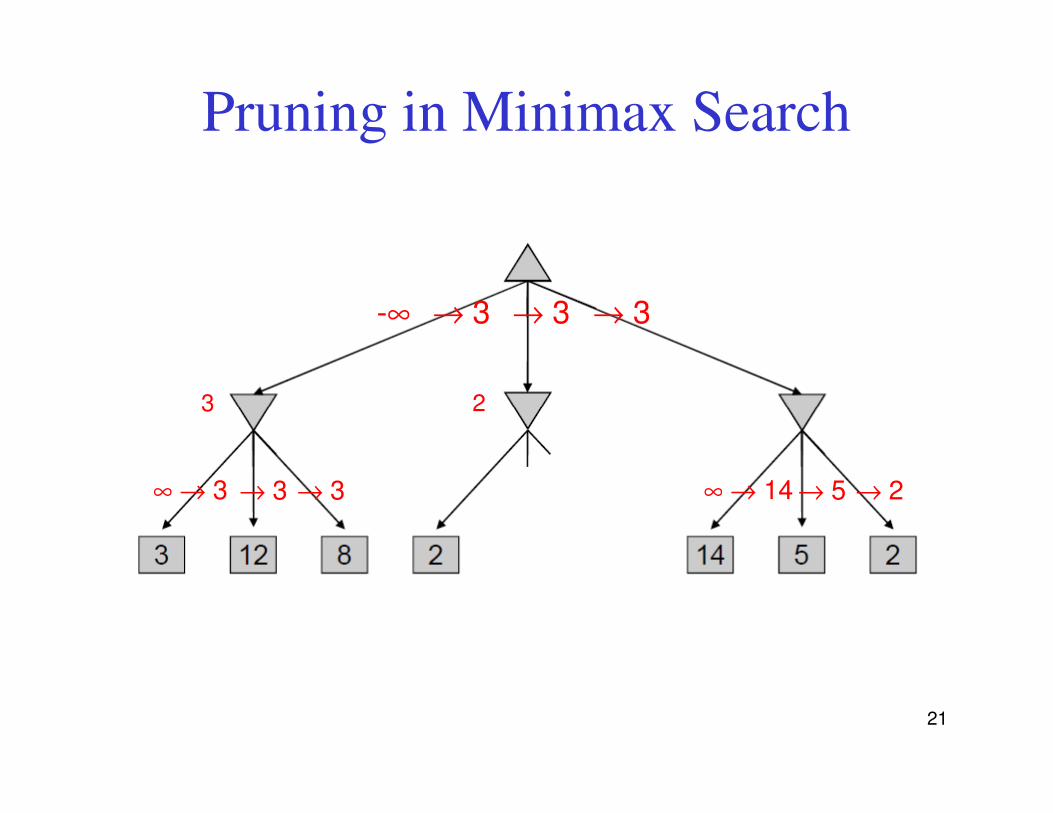
Pruning in Minimax Search
3 2
-∞ → 3 → 3→ 3
21
3 2
∞ → 3 → 3 → 3 ∞ → 14 → 5 → 2

Alpha-Beta Pruning• General configuration
– We’re computing the
MIN-VALUE at n
– We’re looping over n’s children
– n’s value estimate is dropping
– a is the best value that MAX– a is the best value that MAX
can get at any choice point
along the current path
– If n’s value estimate becomes
worse than a,
MAX will avoid it, so can stop
considering n’s other children
– Define b similarly for MIN22

Alpha-Beta Pruning Example
23
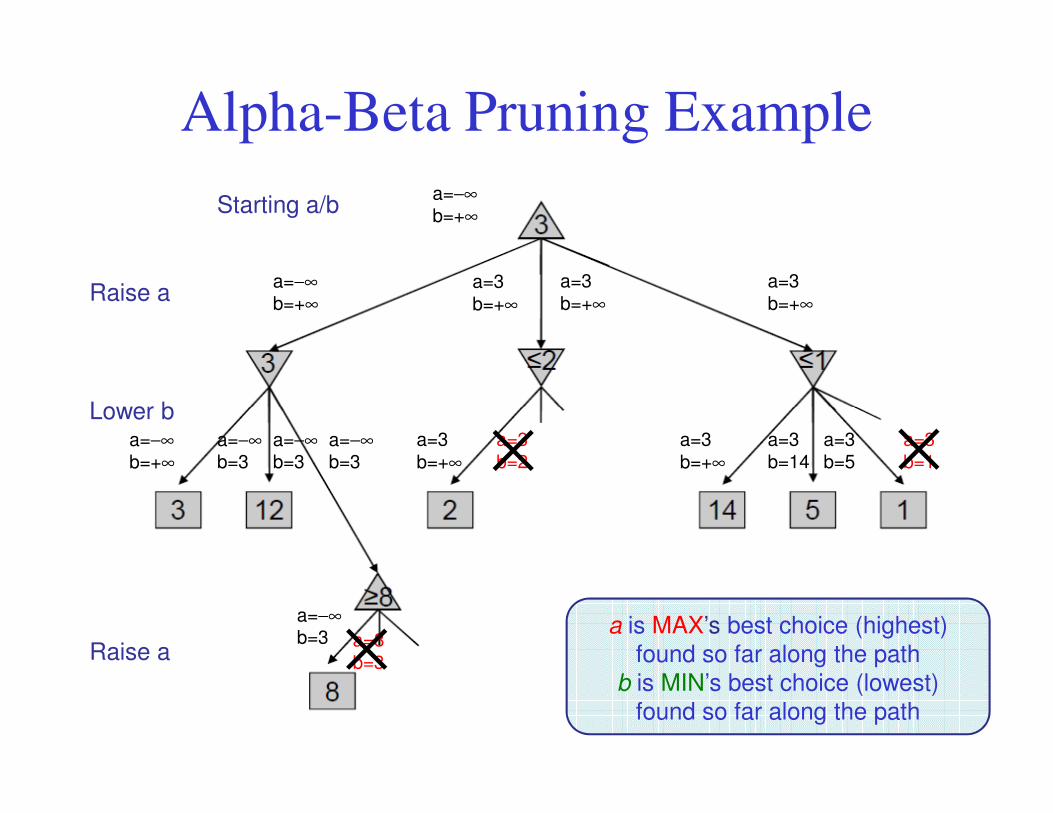
Alpha-Beta Pruning Example
Starting a/ba=−∞b=+∞
Raise a
Lower b
a=3
b=+∞
a=3
b=+∞a=3
b=+∞
a=−∞b=+∞
××
a is MAX’s best choice (highest)
found so far along the path
b is MIN’s best choice (lowest)
found so far along the path
Lower b
Raise a
a=3b=1
a=3b=5
a=3b=14
a=3
b=+∞
a=3b=2
a=3
b=+∞a=−∞b=3
a=−∞b=3
a=−∞b=3
a=−∞b=+∞
a=−∞b=3 a=8
b=3×
××
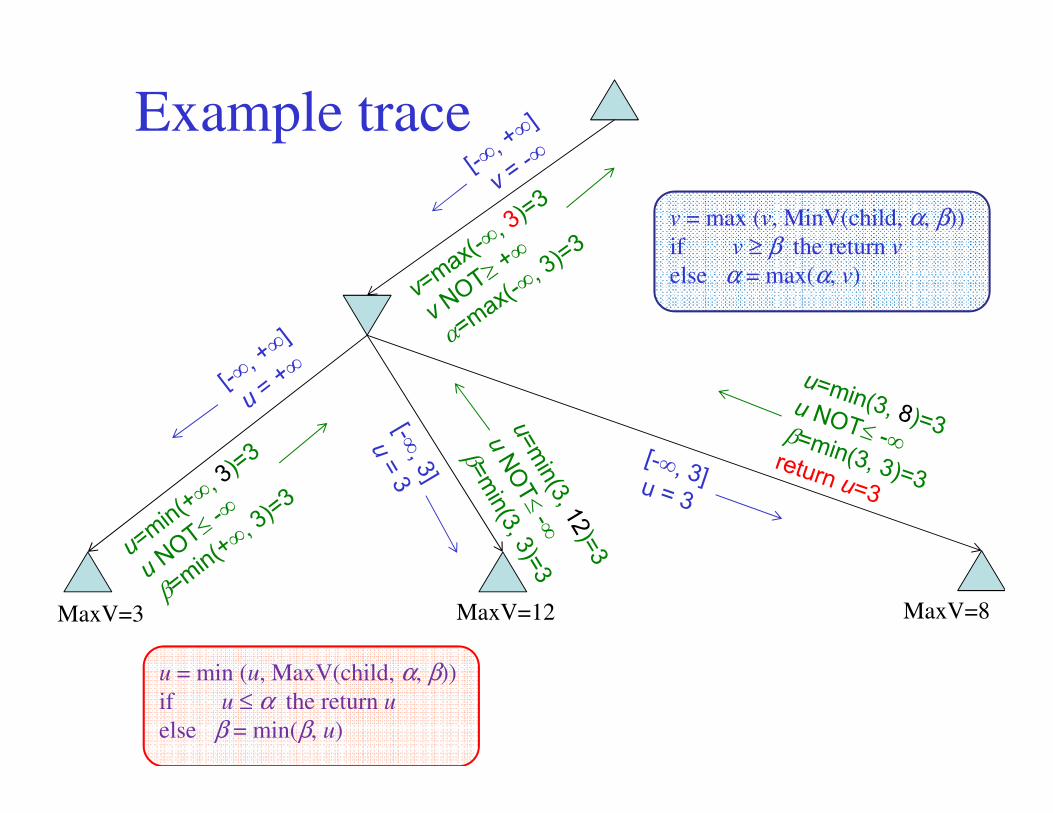
Example trace
v = max (v, MinV(child, α, β))
if v ≥ β the return v
else α = max(α, v)
MaxV=3 MaxV=12 MaxV=8
u = min (u, MaxV(child, α, β))
if u ≤ α the return u
else β = min(β, u)

Example trace
MaxV=2
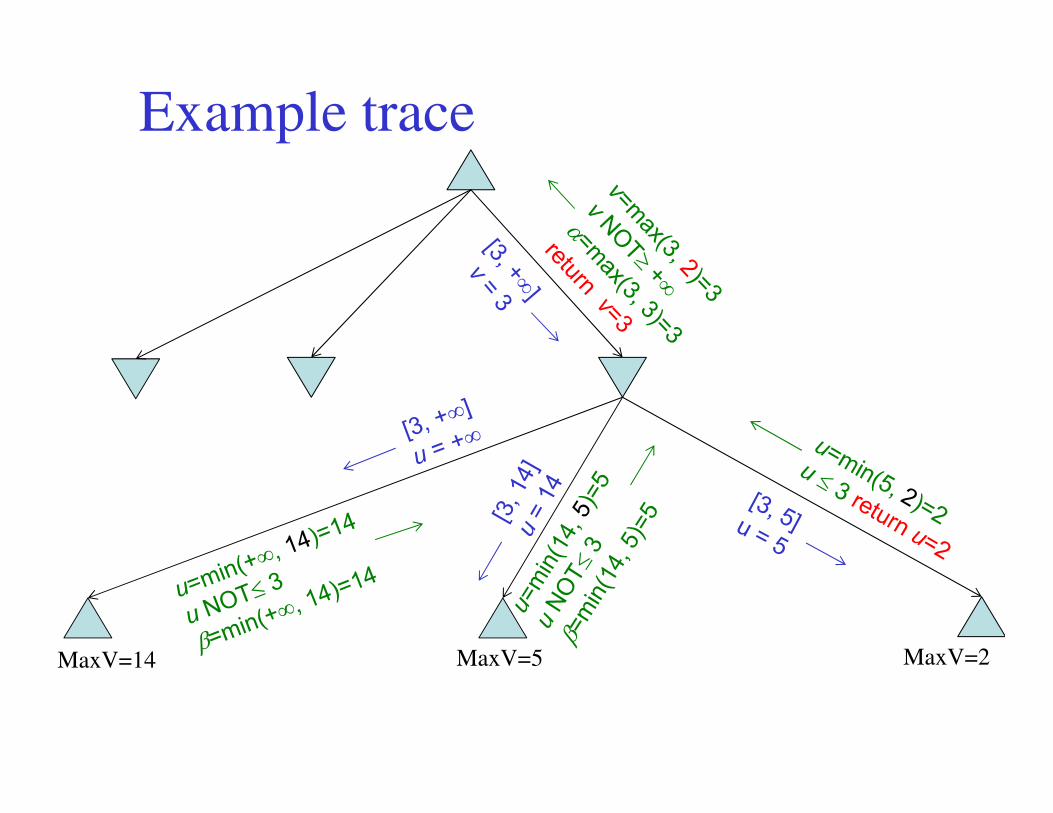
Example trace
MaxV=14 MaxV=5 MaxV=2

28

Alpha-Beta Pseudocode
29

Alpha-Beta Pruning Properties• This pruning has no effect on final result at the root
• Values of intermediate nodes might be wrong!
– Important: children of the root may have the wrong value
• Good child ordering improves effectiveness of pruning
• With “perfect ordering”:
– Time complexity drops to O(bm/2)
– Doubles solvable depth!
– Full search of, e.g. chess, is still hopeless…
• This is a simple example of metareasoning (computing
about what to compute) 30

















