19
AGA 0512- Análise de Dados em Astronomia II 4. Regressão Laerte Sodré Jr. 2o. semestre, 2019 1 / 19

AGA 0512- Análise de Dados em Astronomia II
4. Regressão
Laerte Sodré Jr.
2o. semestre, 2019
1 / 19

Introdução
aula de hoje:
1 regressão em aprendizado de máquina2 otimização3 regularização4 regressão com kernel5 processos gaussianos6 validação cruzada
We balance probabilities and choose the most likely.It is the scientific use of the imagination.
Sherlock Holmes em The Hound of the Baskervilles, Arthur Conan Doyle
2 / 19

Introdução
o que é regressão
regressão em aprendizado demáquina:estimativa de uma variável contínua, y,a partir de dados {xi, yi, σi} de umconjunto de treinamento
y: variável dependentex (pode ser um vetor): variávelindependente
cada dado i pode ser descrito por umacomponente xij - esses dados deentrada são frequentementedenominados features em ML
para a regressão precisamos de:modelo: y = f (x)função de custo (loss/cost function):para avaliar a qualidade do ajuste domodelootimizador: para encontrar osparâmetros do modelo queminimizam a função de custo
vamos representar o modelo como
y(x) = f (x|w) + ε
w: parâmetros do modeloε: “erro” ou ruído
3 / 19

Introdução
o que é regressão
modelo:y(x) = f (x|w) + ε
erro:os modelos não ajustam os dadosperfeitamenteε pode ser devido aos dados deentrada x (erros nas medidas)ε pode ser devido a erros nasmedidas de yε pode ser devido ao modelo sermuito simples ou inadequadoε deve ser uma combinação detudo isso!
exemplo: regressão linear por mínimosquadrados
modelo linear: y = w0 + w1xparâmetros: {w} = {w0,w1}função custo: soma dos quadradosdos resíduos
l(w) ∝ χ2 ∝N∑
i=1
[yi − (w0 + w1xi)
]2
estimativa dos parâmetros w:otimização/minimização da funçãocusto
4 / 19

otimização
otimização
otimização de l(w) com o algoritmogradiente descendente:
inicialize os parâmetros waleatoriamente
repita o aprendizado de w com baseno gradiente:
w = w− λ∂l(w)
∂w
0 < λ < 1: taxa de aprendizado
para um único dado:
w = w + 2λ
[yi − y(xi|w)
]xi
o termo em colchetes é o erro(resíduo) da medida i com osparâmetros atuais do modeloconforme o treinamento prossegue, oerro diminui e w tende a um valorestacionário
5 / 19
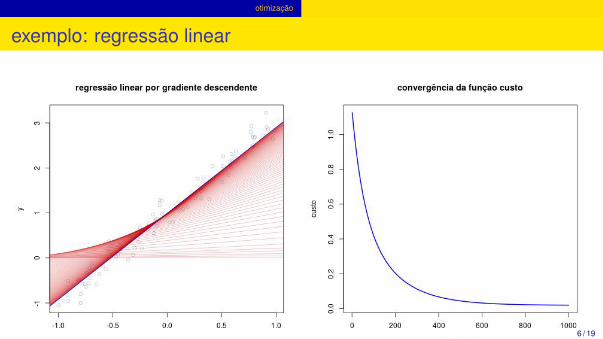
otimização
exemplo: regressão linear
6 / 19

otimização
estratégias de otimização
batch: calcula-se o custo sobre todo oconjunto de treinamento e faz-se asatualizações dos parâmetrosestocástica: calcula-se o custo sobre ndados ao acaso e faz-se asatualizações dos parâmetros
nesse caso supõe-se que as amostrasextraídas do conjunto de treinamentosão independentes e identicamentedistribuídas
o problema linear tem uma soluçãoanalítica: se y = x.w + ε, com
y = [y1, y2, ..., yN]T
x =
1 x11 x21 ...1 xN
então,
w = (xTx)−1xTy
7 / 19

regularização
modelos e generalização
modelos muito simples: underfit
modelos muito complexos: overfito modelo ajusta o ruído
ex: ajuste de um polinômio de grau Mpolinômio ajustado com o conjunto de treinamento e aplicado ao
conjunto de teste:
o que acontece? os w ficam enormes paraajustar o ruído
exemplo: coeficientes do polinômio degrau 9:30.87, -1122.61, 13019.71, -75589.66,256956.84, -544754.35, 730907.60,-603984.86, 280679.44, -56144.84
“remédio”: regularizaçãopara manter os pesos pequenos
8 / 19

regularização
regularização
objetivo: evitar que os pesos“explodam”função de custo:
l(w) =12χ2(w) + αwT.w
- o termo adicional penaliza valoresgrandes de |w|- α: parâmetro de regularização
modelo linear - tem solução analítica(ridge regression):
w = (xTx + αI)−1xTy
gradiente descendente para um dado:
w = w + 2λ[(yi − y(xi|w))xi − αw
]LASSO: least absolute shrinkage andselection
l(w) =12χ2(w) + α|w|
note que a regressão linear simples(α = 0) é um caso particular deLASSO e ridge regression
9 / 19

regularização
regressão robusta
regressão robusta: menos sensível aoutliers
particularmente importante quandonão se tem os erros das medidas
recomenda-se usar a norma L1 nafunção custoEx.: |y− f (x|w)|ao invés de L2, como em (y− f (x|w))2
pode-se introduzir regularização
muitos métodos!muitas funções de custo!
função de custo de Hubera = yi − xi.w: resíduo de uma medida
Lδ(a) ={ 1
2 a2 se |a| ≤ δδ(|a| − 1
2δ) se |a| > δ
10 / 19

regularização
regressão robusta
estimador M: função biquadrática deTukey
ρ(a) =
{12 a2 − a4
2c2 +a6
6c4 se |a| ≤ cc2
6 se |a| > 0
c = 4.685
estimador S:
ρ(a) =
{a[1− a2
c2 ]2 se |a| ≤ c
0 se |a| > 0
c = 1.54711 / 19

regressão com kernel
regressão com kernel
kernel- tipo de regressão “local”:
y = f (x|K) =∑N
i=1 K(|x− xi|/h)yi∑Ni=1 K(|x− xi|/h)
=
=
N∑i=1
wi(x)yi
K(u): kernelh: “largura de banda” - pode serdeterminada por validação cruzada
média ponderada local dos valores de ycom pesos
wi(x) =K(|x− xi|/h)∑Nj=1 K(|x− xj|/h)
variantes: regressão localmente linear,regressão polinomial local, kerneladaptativo (h estimado do número devizinhos), ...
12 / 19

processos gaussianos
processos gaussianos (PG)
modelagem de funções: visão paramétrica
y = f (x|w) + ε
a forma da função é conhecidaregressão: estimativa do posteriordos parâmetros w
modelagem de funções: visão do espaçode funções
não se assume uma forma para fregressão: estimativa do posteriordos valores da função nos pontos deinteressePG: define uma distribuição noespaço das funções
PG: se pegamos dois ou mais pontos x, ovalor de y nesses pontos segue umadistribuição gaussiana multivariada
supomos que f é uma variável aleatóriaque se distribui como um PG:
f (x) ∼ GP(µ(x), k(x, x′)),
µ(x) = E(f (x)): média do PGk(x, x′): covariância/kernel do PG
ex.: função de base radial:
k(x, x′) = σ2f exp
(− |x− x′|2
2λ2
)13 / 19

processos gaussianos
processos gaussianos (PG)
queremos estimar valores y∗ paravariáveis x∗ a partir dos dadosD = {x, y, σ}, amostrando f∗ dadistribuição P(f |D)supondo que a média do PG é µ = 0,mostra-se que a média e a variânciaesperada de y∗ em x∗ são
y∗ = K(x∗, x)[K(x, x) + σ2I]−1y
ecov(y∗) = K(x∗, x∗)−
−K(x∗, x)[K(x, x) + σ2I]−1K(x, x∗),
onde K(x∗, x) = [k(x∗, x1), ..., k(x∗, xn)]T e
Kij = k(xi, xj)
14 / 19

processos gaussianos
processos gaussianos (PG)
o método estima y sem assumir umaforma para a função
aplicável mesmo a dados não gaussianos
método muito flexível, excelente parainterpolação e suavização
provê uma estimativa confiável daincerteza
não paramétrico: encontra a distribuiçãosobre as possíveis funções que sãoconsistentes com os dados
15 / 19

outros métodos
árvores de regressão e redes de neurônios artificiais
árvores de regressão redes de neurônios artificiais
16 / 19

validação cruzada
validação cruzada
objetivo: estimar erros de modelose/ou determinar hiperparâmetrosVC simples: divide-se os dados emtreinamento, validação e teste
treinamento: usado para determinaros parâmetros do modelovalidação: usado para avaliar o errodo modeloteste: usado para avaliar aconfiabilidade do modeloos dados do conjunto de teste nãodevem ser vistos nas fases detreinamento e validação
VC por K-fold:
divide-se os dados em K+1subconjuntos
separa-se um subconjunto para teste,e treina-se K modelos diferentes,deixando-se um para se medir o erroda validação cruzada
o erro do método pode ser estimadopela mediana dos erros de cadasubconjunto
17 / 19
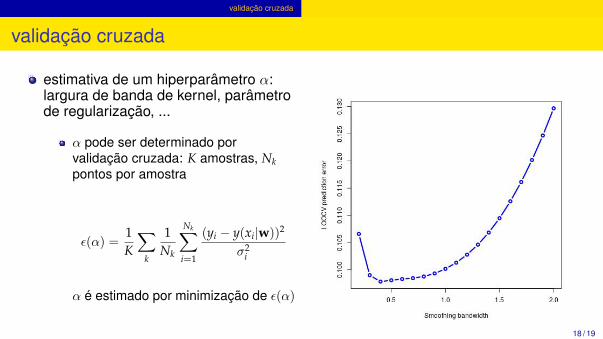
validação cruzada
validação cruzada
estimativa de um hiperparâmetro α:largura de banda de kernel, parâmetrode regularização, ...
α pode ser determinado porvalidação cruzada: K amostras, Nkpontos por amostra
ε(α) =1K
∑k
1Nk
Nk∑i=1
(yi − y(xi|w))2
σ2i
α é estimado por minimização de ε(α)
18 / 19

validação cruzada
exercícios
1 Verifique como a taxa de aprendizado afeta o resultado e a convergência no exemplode regressão linear por gradiente descendente. Considere α = 0.01, 0.1, 0.5.
2 a) Analise os dados abaixo com o modelo linear, ridge regression, LASSO e GP:x = {−0.4248, 0.5766,−0.1820, 0.7660, 0.8809,−0.9088,0.0562, 0.7848, 0.1028,−0.08678,−0.6166,−0.02602,−0.3024,−0.4648}
y = {0.2009, 2.1475, 0.6273, 2.8057, 2.7167,−0.5144,0.8026, 2.6865, 1.2305, 0.8696, 4.6570, 4.5188, 5.5980, 4.2708}
19 / 19

















