39
Druid Rostislav Pashuto November, 2015
| Date post: | 07-Jan-2017 |
| Category: |
Engineering |
| Upload: | rostislav-pashuto |
| View: | 3,138 times |
| Download: | 3 times |

Druid
Rostislav PashutoNovember, 2015

The pattern● we have to scale, current storage no longer able to support our growth
○ horizontal scaling for data which is doubling, quadrupling, …○ compression○ cost effective please
● we want near real-time reports○ sub-second queries○ multi-tenancy
● we have to do a real-time ingestion○ insights on events immediately after they occur
● we need something stable and maintained○ highly available○ open source solution with active community

Once upon a time“Over the last twelve months, we tried and failed to achieve scale and speed
with relational databases (Greenplum, InfoBright, MySQL) and NoSQL offerings (HBase). So instead we did something crazy: we rolled our own database. Druid is the distributed, in-memory OLAP data store that resulted.” © by Eric Tschetter · April, 2011
Started in 2011, open sourced in 2012, under Apache 2.0 licence since 20 Feb, 2015.
Druid is a fast column-oriented, distributed, not only in-memory data store designed for low latency ingestion, ad-hoc aggregations, keeping a history for years.

DruidPros
● aggregate operations in sub-second for most use cases● real-time streaming ingestion and batch Ingestion● denormalized data● horizontal scalability with linear performance● active community
Cons
● Lack of real joins● Limited query power compared to SQL/MDX

Druid: checklist
You need● fast aggregations and exploratory analytics
● sub-second queries for near real-time analysis
● no SPoF data store
● to store a lot of events (trillions, petabytes of data) which you can define as a
set of dimensions
● to process denormalized data, which is not completely unstructured data
● basic search is ok for you (regexp included)

Druid in production
Existing production cluster according druid.io whitepaper
● 3+ trillion events/month● 3M+ events/sec through Druid's real-time ingestion● 100+ PB of raw data● 50+ trillion events● Thousands of queries per second for applications used by
thousands of users● Tens of thousands of cores

Case: GumGumGumGum, a digital marketing platform reported about 3 billion events per day in real time => 5 TB of new data per day with:
● Brokers – 2 m4.xlarge (Round-robin DNS)
● Coordinators – 2 c4.large
● Historical (Cold) – 2 m4.2xlarge (1 x 1000GB EBS SSD)
● Historical (Hot) – 4 m4.2xlarge (1 x 250GB EBS SSD)
● Middle Managers – 15 c4.4xlarge (1 x 300GB EBS SSD)
● Overlords – 2 c4.large
● Zookeeper – 3 c4.large
● MySQL – RDS – db.m3.medium
More: http://goo.gl/tKKmw5
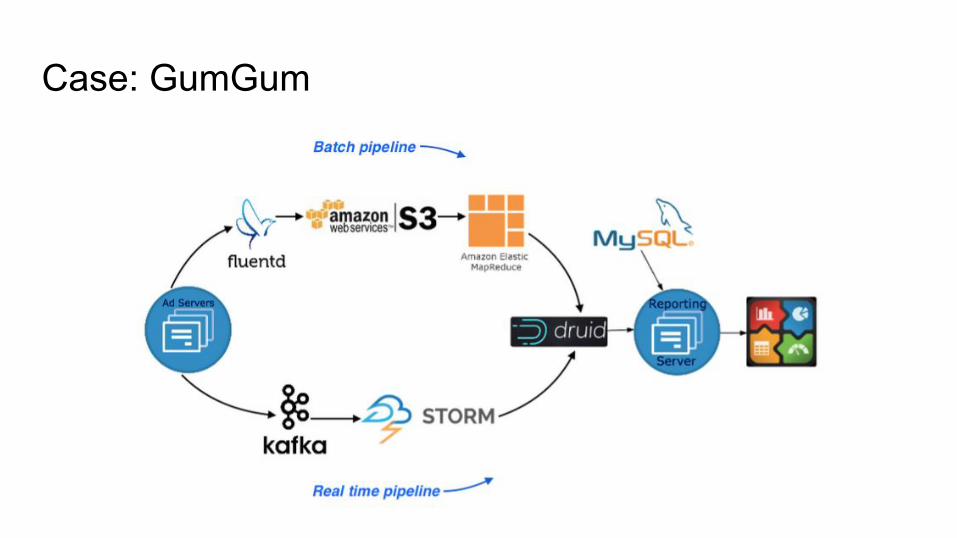
Case: GumGum

ProductionNetflix
Netflix engineers use Druid to aggregate multiple data streams, ingesting up to two terabytes per hour, with the ability to query data as it's being ingested. They use Druid to pinpoint anomalies within their infrastructure, endpoint activity and content flow.
PaypalThe Druid production deployment at PayPal processes a very large volume of data and
is used for internal exploratory analytics by business analytic teams
XiaomiXiaomi uses Druid as an analytics tool to analyze online advertising data.
More: http://druid.io/druid-powered.html
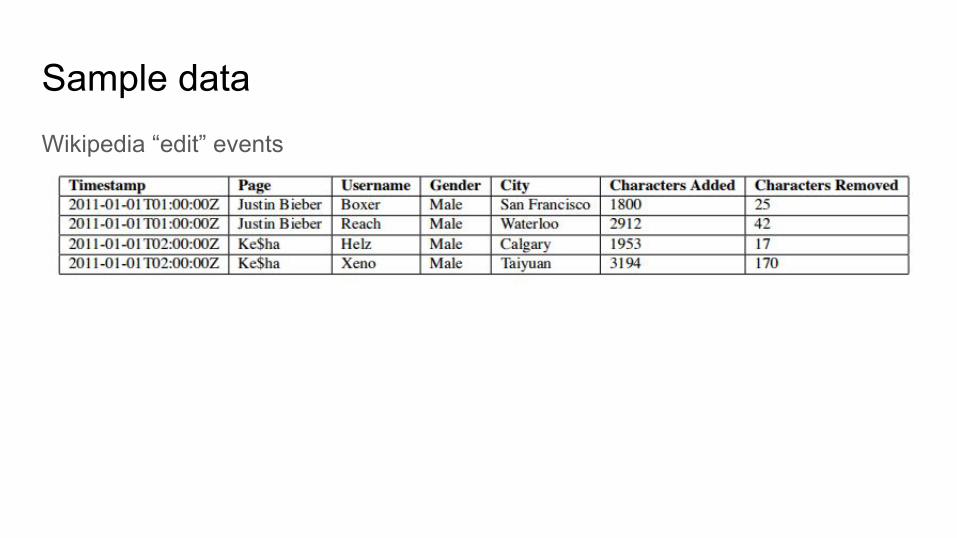
Sample dataWikipedia “edit” events

Druid cluster and the flow of data through the cluster

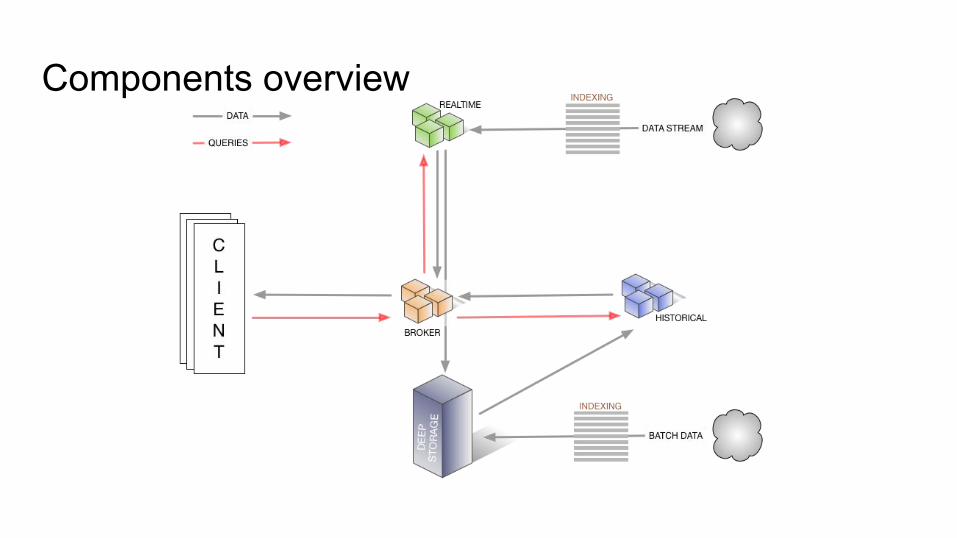
Components● Realtime Node● Historical Node● Broker Node● Coordinator Node● Indexing Service
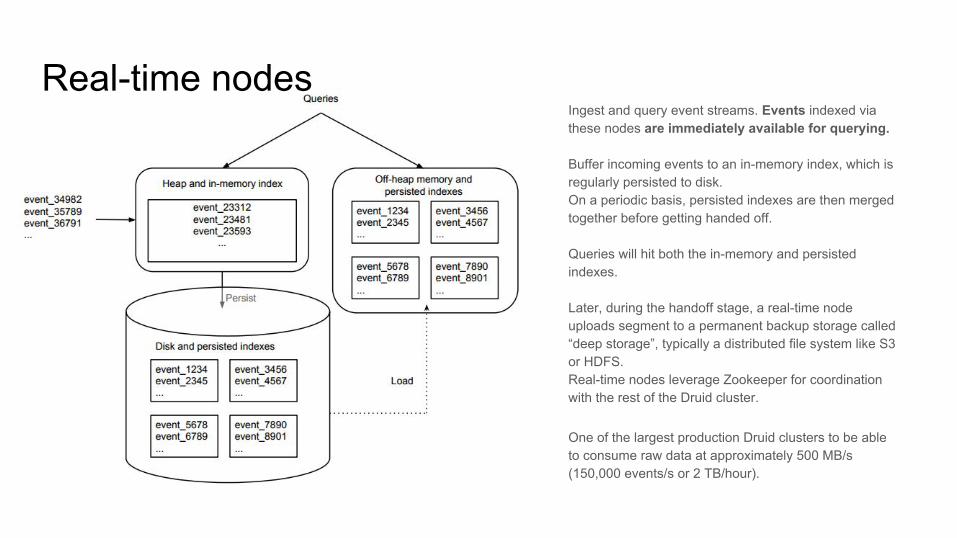
Real-time nodes Ingest and query event streams. Events indexed via these nodes are immediately available for querying.
Buffer incoming events to an in-memory index, which is regularly persisted to disk. On a periodic basis, persisted indexes are then merged together before getting handed off.
Queries will hit both the in-memory and persisted indexes.
Later, during the handoff stage, a real-time node uploads segment to a permanent backup storage called “deep storage”, typically a distributed file system like S3 or HDFS.Real-time nodes leverage Zookeeper for coordination with the rest of the Druid cluster.
One of the largest production Druid clusters to be able to consume raw data at approximately 500 MB/s (150,000 events/s or 2 TB/hour).
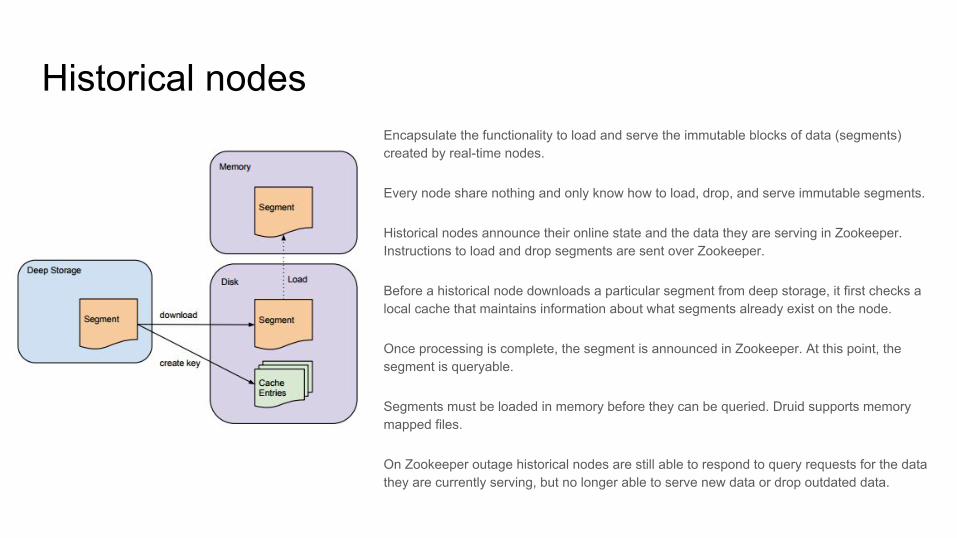
Historical nodesEncapsulate the functionality to load and serve the immutable blocks of data (segments) created by real-time nodes.
Every node share nothing and only know how to load, drop, and serve immutable segments.
Historical nodes announce their online state and the data they are serving in Zookeeper. Instructions to load and drop segments are sent over Zookeeper.
Before a historical node downloads a particular segment from deep storage, it first checks a local cache that maintains information about what segments already exist on the node.
Once processing is complete, the segment is announced in Zookeeper. At this point, the segment is queryable.
Segments must be loaded in memory before they can be queried. Druid supports memory mapped files.
On Zookeeper outage historical nodes are still able to respond to query requests for the data they are currently serving, but no longer able to serve new data or drop outdated data.

Broker nodes
Query router to historical and real-time nodes.
Merge partial results from historical and real-time nodes
Understand what segments are queryable and where those segments are located.
On ZK fail broker use last known view of the cluster

Coordinator nodesIn charge of data management and distribution on historical nodes.
Tell historical nodes to load new data, drop outdated data, replicate data, and move data to load balance.
Undergo a leader-election process that determines a single node that runs the coordinator functionality.Act as redundant backups.
On ZK downtime will no longer be able to send instructions

Indexing serviceConsists of
● Overlord (manages tasks distribution to middle manager)● Middle Manager (create peons for running tasks)● Peons (run a single task in a single JVM)
Creates and destroy segments
Components overview

IngestionStreaming data (does not guarantee exactly once processing)
● Stream processor ( like Apache Samza or Apache Storm ) ● Kafka support
You can use Tranquility library to send event streams to Druid.
Batch Data
● Hadoop-based indexing● Index task
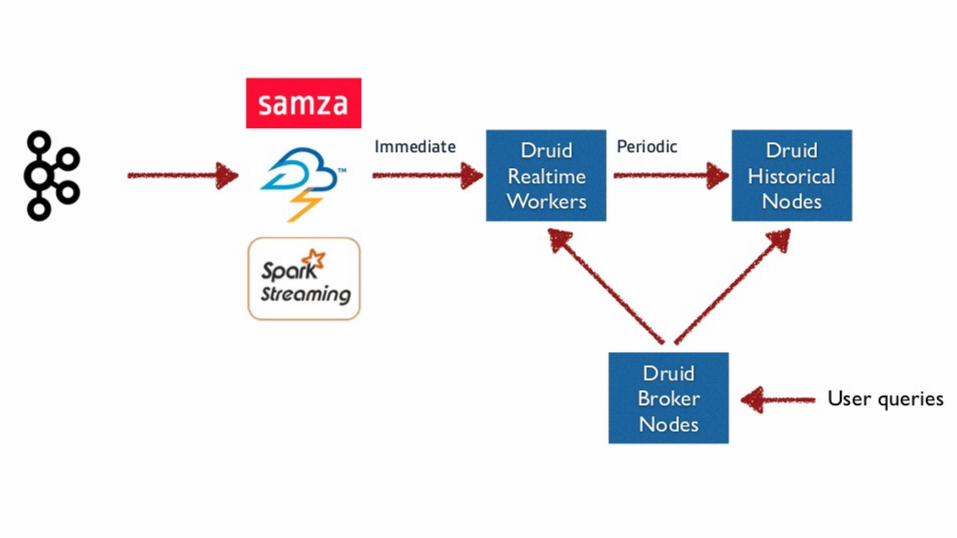
Lambda Architecture
Druid staff recommend running a streaming real-time pipeline to run queries over events as they are occurring and a
batch pipeline to perform periodic cleanups of data.

Data Formats● JSON● CSV● A custom delimited form such as TSV● Protobuf
Multi-value dimensions support

Storage format● data tables called data sources are collections of timestamped events and
partitioned into a set of segments● each segment is typically 5–10 million rows● storage format is highly optimized for linear scans

Replication● replication and distribution are done at a segment level● druid’s data distribution is segment-based and leverages a highly available
"deep" storage such as S3 or HDFS. Scaling up (or down) does not require massive copy actions or downtime; in fact, losing any number of historical nodes does not result in data loss because new historical nodes can always be brought up by reading data from "deep" storage.

QUERYING

Key differences Limited support for joins (through query-
time lookups)
Replace dimension value with another value.
No official SQL support 3rd party drivers
Immutable dimension data Re-index specific data segment
Specific “>” and “<” support in query filters AND, OR, NOT, REG_EXP, Java Script (Rhino), IN (as lookups), partial matchWorkaround for “more”/”less”:{ "type" : "javascript", "dimension" : "age", "function" : "function(x) { return(x >= '21' && x <= '35') }"}

Timeseries{ "queryType": "timeseries", "dataSource": "city", "granularity": "day", "dimensions": ["income"], "aggregations": [{ "type": "count", "name": "total", "fieldName": "userId" }], "intervals": [ "2012-01-01T00:00:00.000/2016-01-04T00:00:00.000" ], "filter": { "type" : "and", "fields" : [{"type": "javascript", "dimension": "income", "function": "function(x) {return x > 100 }"} ] }}
-----------------------------------------------------------------------------------------------------------------------------------------
[ {"timestamp": "2015-06-09T00:00:00.000Z", "result": {"total": 112}}, {"timestamp": "2015-06-10T00:00:00.000Z", "result": {"total": 117}}]

TopNTopNs are much faster and resource efficient than “GroupBy” for this use case.
{ "queryType": "topN", "dataSource": "city", "granularity": "day", "dimension": "income", “threshold”: 3, “metric”: “count”, "aggregations": [...],...}-----------------------------------------------------------------------------------------------------------------------------------------[ { "timestamp": "2015-06-09T00:00:00.000Z", "result": [ { “who”: “Bob”, "count": 100}, { “who”: “Alice”, "count": 40}, { “who”: “Jane”, "count": 15}, ] }]

GroupBy● Use “Timeseries” to do straight aggregates for some time range. ● Use “TopN for an ordered groupBy over a single dimension.
{
"queryType": "groupBy",
"dataSource": "twitterstream",
"granularity": "all",
"dimensions": ["lang", "utc_offset"],
"aggregations":[
{ "type": "count", "name": "rows"},
{ "type": "doubleSum", "fieldName": "tweets", "name": "tweets"}
],
"filter": { "type": "selector", "dimension": "lang", "value": "en" },
"intervals":["2012-10-01T00:00/2020-01-01T00"]
}
-----------------------------------------------------------------------------------------------------------------------------------------[{ "version": "v1",
"timestamp": "2012-10-01T00:00:00.000Z",
"event": {
"utc_offset": "-10800",
"tweets": 90,
"lang": "en",
"rows": 81
}
}...

OtherTime Boundary. Return the earliest and latest data points of a data set.
Segment Metadata. Return per segment information about: cardinality, byte size, type of columns, segment intervals and etc.
Data Source Metadata. Return timestamp of last ingested event.
Search. Returns dimension values that match the search specification.

Filters● exact match (“=”)● and● not● or● reg_exp (Java reg_exp)● JavaScript● extraction (similar to “in”)● search (capture partial search match)

Aggregations● count● min/max● JavaScript (All JavaScript functions must return numerical values)● cardinality (by value and by row)● HyperUnique aggregator (uses HyperLogLog to compute the estimated cardinality of a dimension
that has been aggregated as a "hyperUnique" metric at indexing time)● filtered agregator (wraps any given aggregator, but only aggregates the values for which the given
dimension filter matches)

Post Aggregations● arithmetic (applies the provided function to the given fields from left to right)● filed accessor (returns the value produced by the specified)● constant value (always returns the specified value)● JavaScript● HyperUnique Cardinality (is used to wrap a hyperUnique object such that it can be used in post aggregations)
...
"aggregations" : [
{ "type" : "count", "name" : "rows" },
{ "type" : "doubleSum", "name" : "tot", "fieldName" : "total" }],
"postAggregations" : [{
"type" : "arithmetic",
"name" : "average",
"fn" : "*",
"fields" : [
{ "type" : "arithmetic",
"name" : "div",
"fn" : "/",
"fields" : [
{ "type" : "fieldAccess", "name" : "tot", "fieldName" : "tot" },
{ "type" : "fieldAccess", "name" : "rows", "fieldName" : "rows" }]
},
...

Party

Druid in a party: SparkDruid is designed to power analytic applications and focuses on the latencies to ingest data and serve queries over that data. If you were to build an application where users could arbitrarily explore data, the latencies seen by using Spark will likely be too slow for an interactive experience.

Druid in a party: SQL on hadoop
Druid was designed to
1. be an always on service2. ingest data in real-time3. handle slice-n-dice style ad-hoc queries
SQL-on-Hadoop engines generally sidestep Map/Reduce, instead querying data directly from HDFS or, in some cases, other storage systems. Some of these engines (including Impala and Presto) can be collocated with HDFS data nodes and coordinate with them to achieve data locality for queries. What does this mean? We can talk about it in terms of three general areas
1. Queries2. Data Ingestion3. Query Flexibility

Resources● http://druid.io/● Druid in nutshell http://static.druid.io/docs/druid.pdf● Druid API https://github.com/druid-io/druid-api● Analytic UI http://imply.io/● 3rd party SQL interface https://github.com/srikalyc/Sql4D

THANK YOU

















