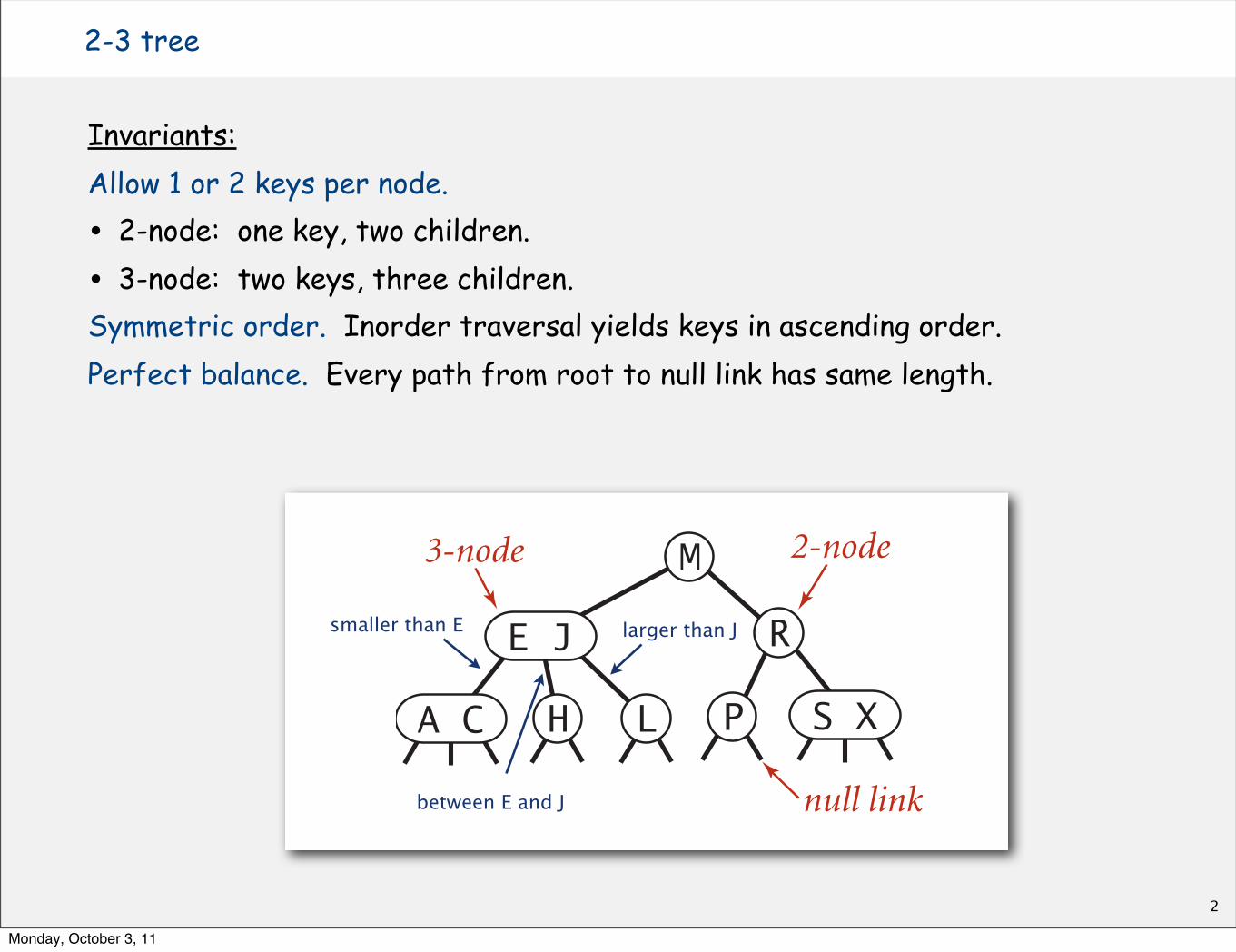
• 3-node: two keys, three children.Symmetric order. Inorder traversal yields keys in ascending order.Perfect balance. Every path from root to null link has same length.
E J
H L
2-node3-node
null link
M
R
P S XA C
Anatomy of a 2-3 search tree
2-3 tree
2
between E and J
larger than Jsmaller than E
Monday, October 3, 11
3
Search in a 2-3 tree
found H so return value (search hit)
H is less than M solook to the left
H is between E and L solook in the middle
B is between A and C so look in the middle
B is less than M solook to the left
B is less than Eso look to the left
link is null so B is not in the tree (search miss)
E J
H L
M
R
P S XA C
E J
H L
M
R
P S XA C
E J
H L
M
R
P S XA C
E J
H L
M
R
P S XA C
E J
H L
M
R
P S XA C
E J
H L
M
R
P S XA C
successful search for H unsuccessful search for B
Successful (left) and unsuccessful (right) search in a 2-3 tree
Monday, October 3, 11
4
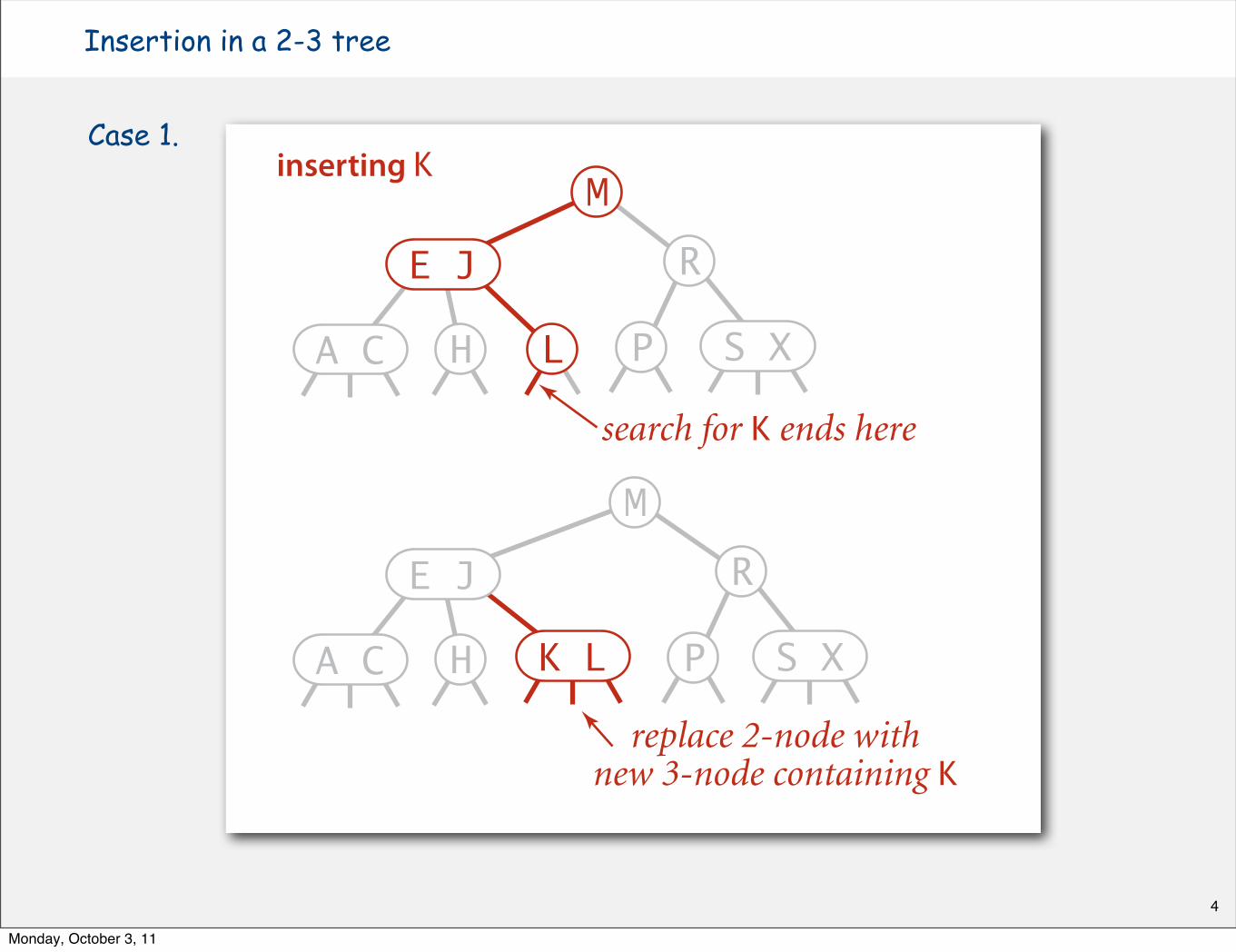
Insertion in a 2-3 tree
Case 1.
search for K ends here
replace 2-node withnew 3-node containing K
E J
H L
M
R
P S XA C
E J
H
M
R
P S XK LA C
inserting K
Insert into a 2-node
Monday, October 3, 11
5
Insertion in a 2-3 tree
Case 2.
split 4-node into two 2-nodespass middle key to parent
replace 3-node withtemporary 4-node
containing Z
replace 2-nodewith new 3-node
containingmiddle key
S X Z
S Z
E J
H L
L
M
R
PA C
search for Z endsat this 3-nodeE J
H L
M
R
P S XA C
E J
H
M
P
R X
A C
inserting Z
Insert into a 3-node whose parent is a 2-nodeMonday, October 3, 11
6
Insertion in a 2-3 tree
Case 3
split 4-node into two 2-nodespass middle key to parent
split 4-node into two 2-nodespass middle key to parent
add middle key E to 2-nodeto make new 3-node
add middle key C to 3-nodeto make temporary 4-node
add new key D to 3-nodeto make temporary 4-node
A C D
A D
search for D endsat this 3-node E J
H L
M
R
P S XA C
E J
H L
M
R
P S X
C E J
H L
M
R
P S X
A D H L
C J R
P S X
E M
inserting D
Insert into a 3-node whose parent is a 3-node
split 4-node into two 2-nodespass middle key to parent
split 4-node into two 2-nodespass middle key to parent
add middle key E to 2-nodeto make new 3-node
add middle key C to 3-nodeto make temporary 4-node
add new key D to 3-nodeto make temporary 4-node
A C D
A D
search for D endsat this 3-node E J
H L
M
R
P S XA C
E J
H L
M
R
P S X
C E J
H L
M
R
P S X
A D H L
C J R
P S X
E M
inserting D
Insert into a 3-node whose parent is a 3-node
Monday, October 3, 11
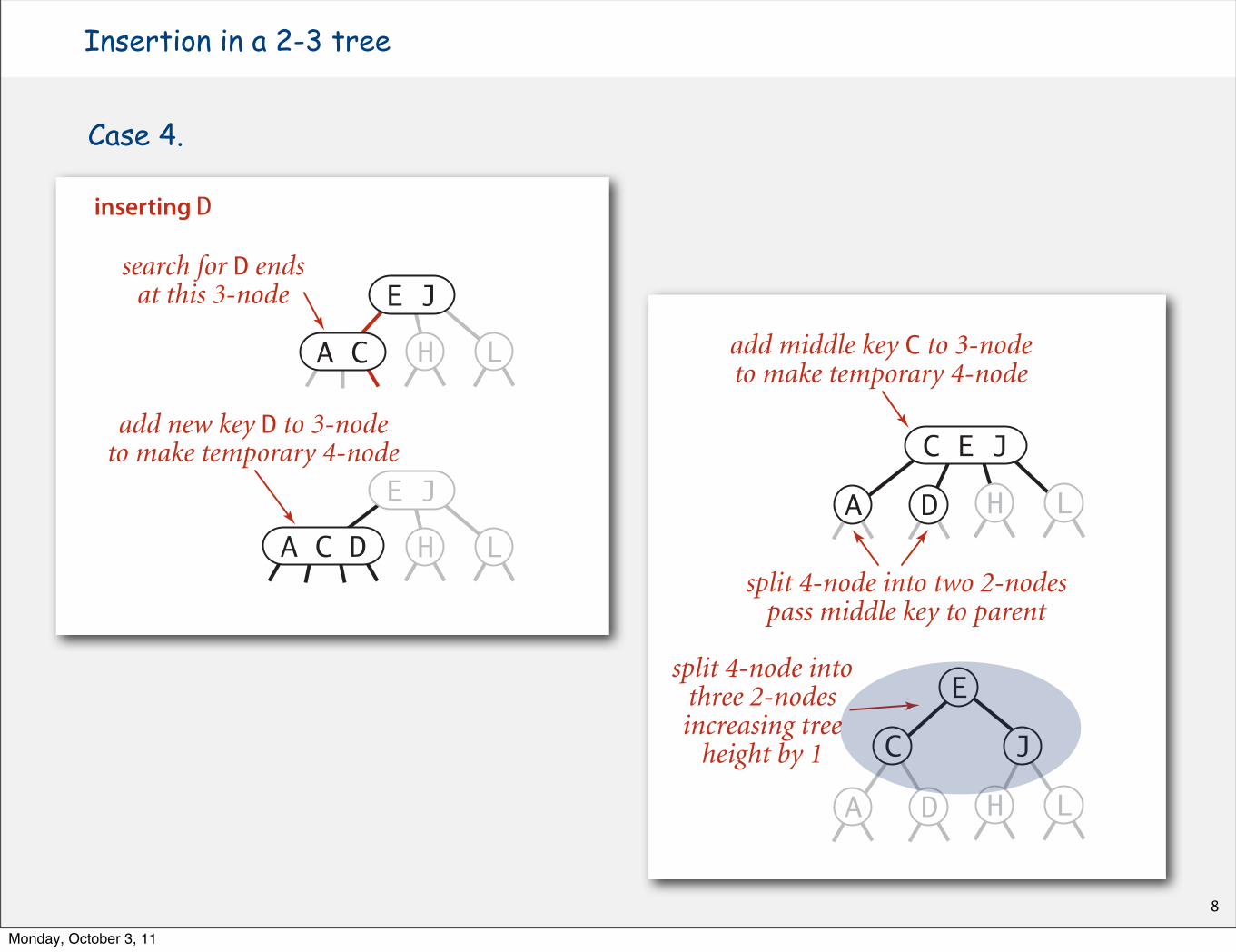
Case 4.
7
Insertion in a 2-3 tree
split 4-node into two 2-nodespass middle key to parent
split 4-node intothree 2-nodesincreasing tree
height by 1
add middle key C to 3-nodeto make temporary 4-node
A C D
A D
search for D endsat this 3-node E J
H LA C
E J
H L
C E J
H L
A D H L
C J
E
add new key D to 3-nodeto make temporary 4-node
inserting D
Splitting the root
Problem session:What should happen next?
Monday, October 3, 11
Case 4.
8
Insertion in a 2-3 tree
split 4-node into two 2-nodespass middle key to parent
split 4-node intothree 2-nodesincreasing tree
height by 1
add middle key C to 3-nodeto make temporary 4-node
A C D
A D
search for D endsat this 3-node E J
H LA C
E J
H L
C E J
H L
A D H L
C J
E
add new key D to 3-nodeto make temporary 4-node
inserting D
Splitting the root
split 4-node into two 2-nodespass middle key to parent
split 4-node intothree 2-nodesincreasing tree
height by 1
add middle key C to 3-nodeto make temporary 4-node
A C D
A D
search for D endsat this 3-node E J
H LA C
E J
H L
C E J
H L
A D H L
C J
E
add new key D to 3-nodeto make temporary 4-node
inserting D
Splitting the root
Monday, October 3, 11
Invariants. Maintains symmetric order and perfect balance.
Pf. Each transformation maintains symmetric order and perfect balance.
9
Global properties in a 2-3 tree
b
right
middle
left
right
left
b db c d
a ca
a b c
d
ca
b d
a b cca
root
parent is a 2-node
parent is a 3-node
Splitting a temporary 4-node in a 2-3 tree (summary)
c e
b d
c d e
a b
b c d
a e
a b d
a c e
a b c
d e
ca
b d e
Monday, October 3, 11
10
2-3 tree: performance
Perfect balance. Every path from root to null link has same length.
Tree height.
• Worst case:
• Best case:
Typical 2-3 tree built from random keys
Monday, October 3, 11
11
2-3 tree: performance
Perfect balance. Every path from root to null link has same length.
Tree height.
• Worst case: lg N. [all 2-nodes]
• Best case: log3 N ≈ .631 lg N. [all 3-nodes]
• Between 12 and 20 for a million nodes.
• Between 18 and 30 for a billion nodes.
Guaranteed logarithmic performance for search and insert.
Typical 2-3 tree built from random keys
Monday, October 3, 11
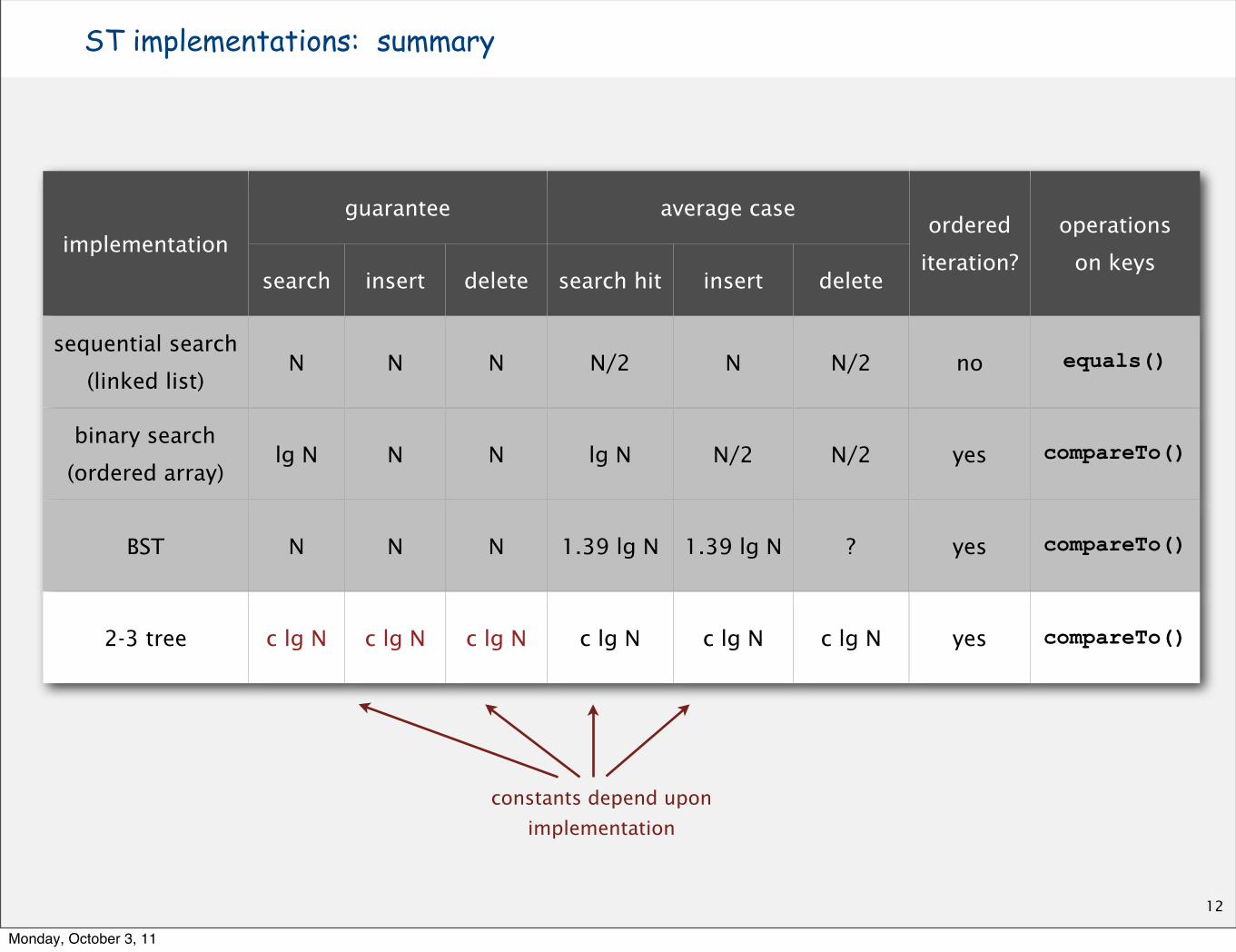
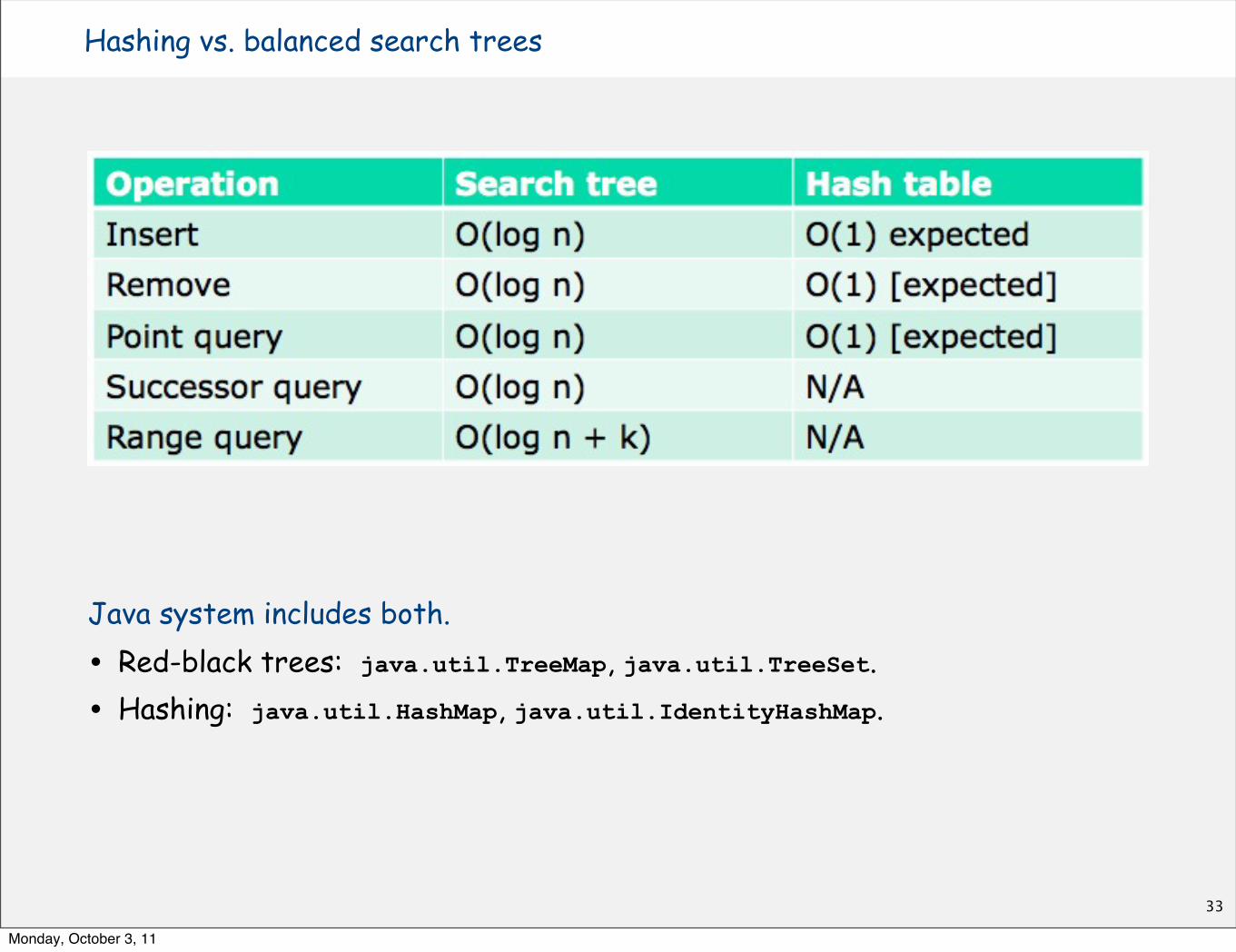
ST implementations: summary
12
constants depend upon
implementation
implementation
guaranteeguaranteeguarantee average caseaverage caseaverage caseordered operations
implementation
search insert delete search hit insert deleteiteration? on keys
sequential search
(linked list)N N N N/2 N N/2 no equals()
binary search
(ordered array)lg N N N lg N N/2 N/2 yes compareTo()
BST N N N 1.39 lg N 1.39 lg N ? yes compareTo()
2-3 tree c lg N c lg N c lg N c lg N c lg N c lg N yes compareTo()
Monday, October 3, 11
13
2-3 tree: implementation?
Direct implementation is complicated, because:
• Maintaining multiple node types is cumbersome.
• Need multiple compares to move down tree.
• Need to move back up the tree to split 4-nodes.
• Large number of cases for splitting.
Bottom line. Could do it, but there's a better way: Left-leaning read-black BSTs (self study).
Monday, October 3, 11
ST implementations: summary
14
implementation
guaranteeguaranteeguarantee average caseaverage caseordered operations
implementation
search insert delete search hit insert deleteiteration? on keys
sequential search
(linked list)N N N N/2 N N/2 no equals()
binary search
(ordered array)lg N N N lg N N/2 N/2 yes compareTo()
BST N N N 1.39 lg N 1.39 lg N ? yes compareTo()
2-3 tree c lg N c lg N c lg N c lg N c lg N c lg N yes compareTo()
red-black BST 2 lg N 2 lg N 2 lg N 1.00 lg N * 1.00 lg N * 1.00 lg N * yes compareTo()
* exact value of coefficient unknown but extremely close to 1
Monday, October 3, 11
Why left-leaning trees?
15
private Node put(Node x, Key key, Value val, boolean sw) { if (x == null) return new Node(key, value, RED); int cmp = key.compareTo(x.key);
if (isRed(x.left) && isRed(x.right)) { x.color = RED; x.left.color = BLACK; x.right.color = BLACK; } if (cmp < 0) { x.left = put(x.left, key, val, false); if (isRed(x) && isRed(x.left) && sw) x = rotateRight(x); if (isRed(x.left) && isRed(x.left.left)) { x = rotateRight(x); x.color = BLACK; x.right.color = RED; } } else if (cmp > 0) { x.right = put(x.right, key, val, true); if (isRed(h) && isRed(x.right) && !sw) x = rotateLeft(x); if (isRed(h.right) && isRed(h.right.right)) { x = rotateLeft(x); x.color = BLACK; x.left.color = RED; } } else x.val = val; return x; }
public Node put(Node h, Key key, Value val) { if (h == null) return new Node(key, val, RED); int cmp = kery.compareTo(h.key); if (cmp < 0) h.left = put(h.left, key, val); else if (cmp > 0) h.right = put(h.right, key, val); else h.val = val;
if (isRed(h.right) && !isRed(h.left)) h = rotateLeft(h); if (isRed(h.left) && isRed(h.left.left)) h = rotateRight(h); if (isRed(h.left) && isRed(h.right)) flipColors(h); return h; }
old code (that students had to understand in the past) new code (that you have to understand)
extremely tricky
straightforward
(based on high-level description)
Monday, October 3, 11
16
Balanced trees in the wild
Red-black trees are widely used as system symbol tables.
• Java: java.util.TreeMap, java.util.TreeSet.
• C++ STL: map, multimap, multiset.
• Linux kernel: completely fair scheduler, linux/rbtree.h.
The more general B-trees are widely used for file systems and databases.
Save items in a key-indexed table (index is a function of the key).
Hash function. Method for computing array index from key.
Issues.
• Computing the hash function.
• Equality test: Method for checking whether two keys are equal.
• Collision resolution: Algorithm and data structureto handle two keys that hash to the same array index.
hash("times") = 3
??
0
1
2
3 "it"
4
5
hash("it") = 3
Monday, October 3, 11
Let’s hash!
Post-its circulated.
Take one each, write your name and two random numbers in {1,…,r}.- E.g. use random.org
The two numbers will act as hash values for your post-it.
Later we will come back to how hash values can be computed – such that a key is consistently associated with the same value.
19
i=Rasmus h(i)=6 h’(i)=12
Monday, October 3, 11
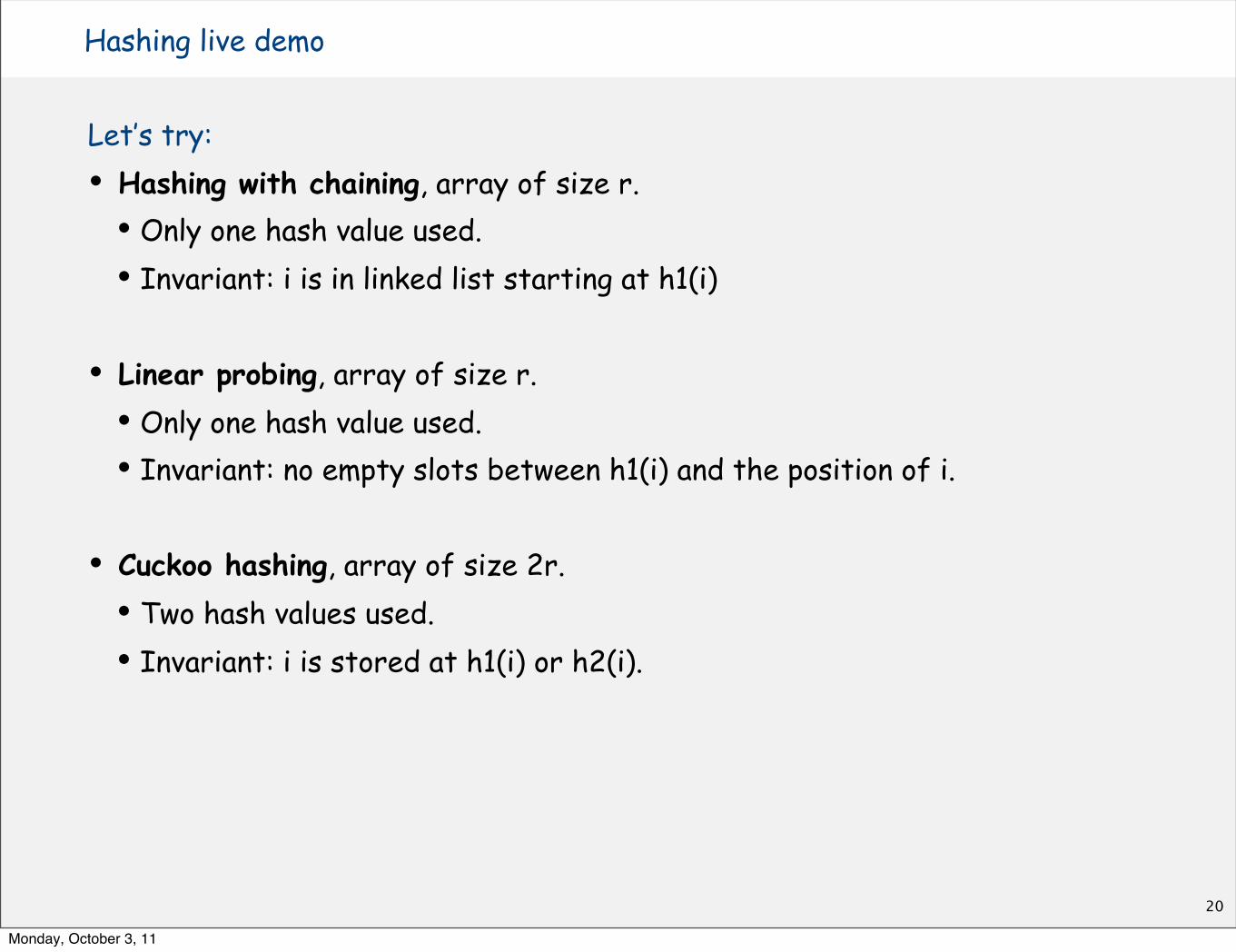
Hashing live demo
Let’s try:• Hashing with chaining, array of size r.• Only one hash value used.• Invariant: i is in linked list starting at h1(i)
• Linear probing, array of size r.• Only one hash value used.• Invariant: no empty slots between h1(i) and the position of i.
• Cuckoo hashing, array of size 2r.• Two hash values used.• Invariant: i is stored at h1(i) or h2(i).
20
Monday, October 3, 11
[H. P. Luhn, IBM 1953]Hashing with separate chaining;n keys, and r>n/2 lists.
Analysis sketch:
• Consider search for of a keyi placed at the end of its list:
• There are n other keys.
• Each of them has hash value h1(i) with probability 1/r.⇒ The expected number of other keys processed is 1/r.
⇒ The total expected number of keys processed is 1+n/r < 3, for r>n/2.
• Analysis of remove is similar.
21
Separate chaining ST
Hashing with separate chaining for standard indexing client
st
first
0
1
2
3
4
S 0X 7
E 12
first
first
first
first
A 8
P 10L 11
R 3C 4H 5M 9
independentSequentialSearchST
objects
S 2 0
E 0 1
A 0 2
R 4 3
C 4 4
H 4 5
E 0 6
X 2 7
A 0 8
M 4 9
P 3 10
L 3 11
E 0 12
null
key hash value
Monday, October 3, 11
Proposition. Under uniform hashing assumption, the average number of probes in a hash table of size M that contains N = α M keys is:
Pf. [Knuth 1962] A landmark in analysis of algorithms.
• Outside of scope of this course.
Recent advance in analysis of linear probing by Copenhagen researchers:- Linear probing with constant independence, by Anna Pagh, Rasmus Pagh, and Milan Ruzic, SIAM Journal of Computing, 2009.- The power of simple tabulation hashing, by Mihai Patrascu and Mikkel Thorup, STOC 2011.
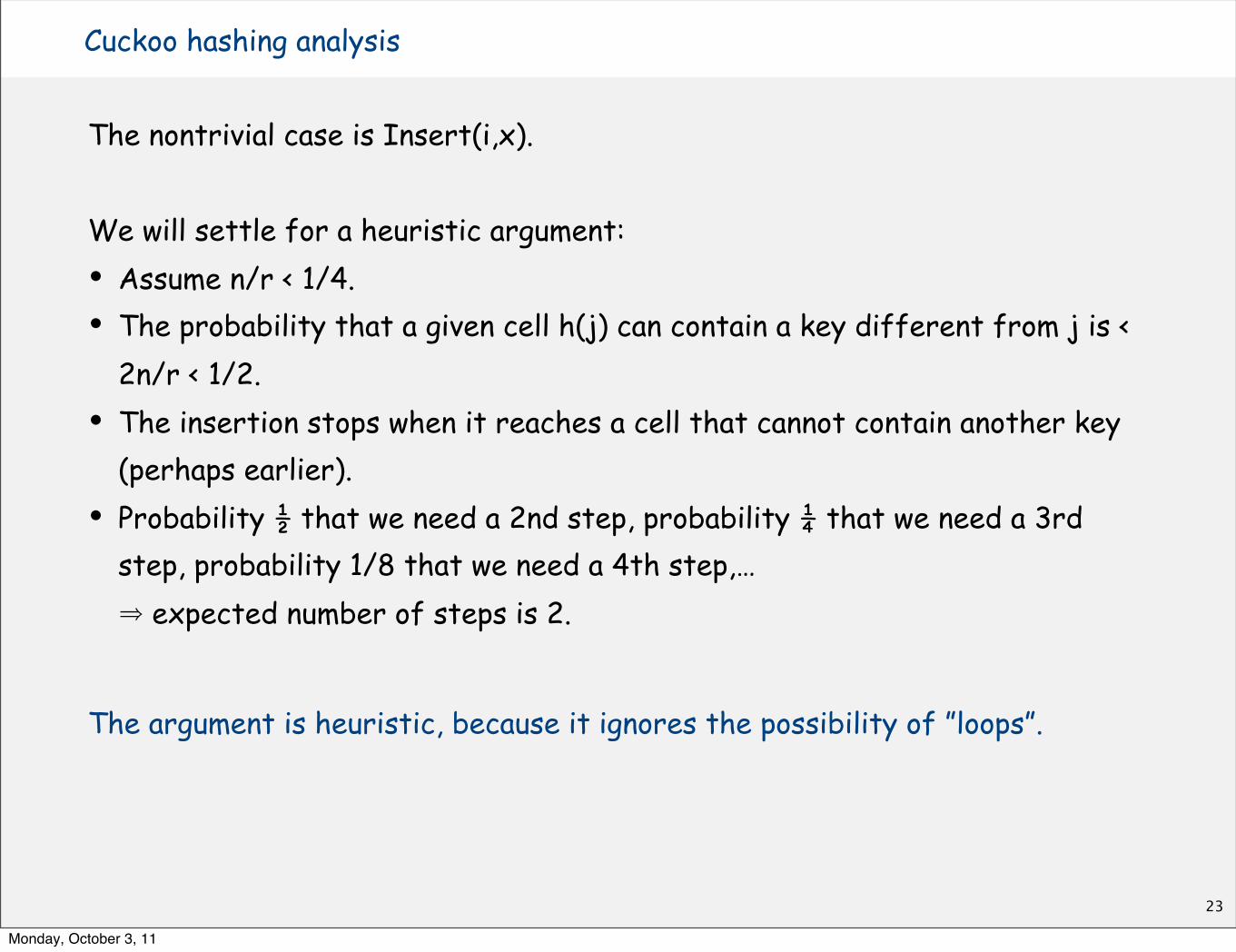
We will settle for a heuristic argument:• Assume n/r < 1/4.• The probability that a given cell h(j) can contain a key different from j is <
2n/r < 1/2.• The insertion stops when it reaches a cell that cannot contain another key
(perhaps earlier).• Probability ½ that we need a 2nd step, probability ¼ that we need a 3rd
step, probability 1/8 that we need a 4th step,…⇒ expected number of steps is 2.
The argument is heuristic, because it ignores the possibility of ”loops”.
23
Monday, October 3, 11
Issues
1. What do we do when there are too many collisions? Or even worse, when insertion in cuckoo hashing fails?
2. How do we compute random numbers? A paradox?
24
Monday, October 3, 11
Rehashing
If the performance of the hash table deteriorates, we may need to use a larger hash table:• Allocate new hash table of suitable size.• Move all keys to new hash table.• Analysis basically exactly the same as for unbounded arrays:
expected constant time per Insert, amortized.• If the present table has sufficient size, we may rehash all keys with new
hash function(s).
25
Monday, October 3, 11
26
Java’s hash code conventions
All Java classes inherit a method hashCode(), which returns a 32-bit int.For range [0;M] do a modulo operation (stay tuned).
Requirement. If x.equals(y), then (x.hashCode() == y.hashCode()).
Highly desirable. If !x.equals(y), then (x.hashCode() != y.hashCode()).
Default implementation. Memory address of x.Trivial (but poor) implementation. Always return 17.Customized implementations. Integer, Double, String, File, URL, Date, …User-defined types. Users are on their own.
x.hashCode()
x
y.hashCode()
y
Text
Monday, October 3, 11
27
Hash code heuristics: integers and doubles
public final class Integer{ private final int value; ... public int hashCode() { return value; }}
convert to IEEE 64-bit representation;
xor most significant 32-bits
with least significant 32-bits
public final class Double{ private final double value; ... public int hashCode() { long bits = doubleToLongBits(value); return (int) (bits ^ (bits >>> 32)); }}
Monday, October 3, 11
• Horner's method to hash string of length L: L multiplies/adds.
public final class String{ private final char[] s; ...
public int hashCode() { int hash = 0; for (int i = 0; i < length(); i++) hash = s[i] + (31 * hash); return hash; }}
28
Hash code heuristics: strings
3045982 = 99·313 + 97·312 + 108·311 + 108·310
= 108 + 31· (108 + 31 · (97 + 31 · (99)))
ith character of s
String s = "call";int code = s.hashCode();
char Unicode
… …
'a' 97
'b' 98
'c' 99
… ...
Monday, October 3, 11
String hashCode() in Java 1.1.
• For long strings: only examine 8-9 evenly spaced characters.
• Benefit: saves time in performing arithmetic.
• Downside: great potential for bad collision patterns.
29
War story: String hashing in Java
public int hashCode(){ int hash = 0; int skip = Math.max(1, length() / 8); for (int i = 0; i < length(); i += skip) hash = s[i] + (37 * hash); return hash;}
Monday, October 3, 11
String hashCode() in Java 1.1.
• For long strings: only examine 8-9 evenly spaced characters.
• Benefit: saves time in performing arithmetic.
• Downside: great potential for bad collision patterns.
29
War story: String hashing in Java
public int hashCode(){ int hash = 0; int skip = Math.max(1, length() / 8); for (int i = 0; i < length(); i += skip) hash = s[i] + (37 * hash); return hash;}
Class HashSet<E> - generic class implementing a set.Constructor: HashSet(int initialCapacity, float loadFactor)
HashMap<K,V> - generic class implementing a dictionary.Constructor: HashMap(int initialCapacity, float loadFactor)
34
offers constant time performance for the basic operations … assuming the hash function disperses the elements properly among the buckets. Iterating over this set requires time proportional to … the number of elements plus … the number of buckets
From
Jav
a A
PI
docu
men
tatio
n
offers constant time performance for the basic operations … assuming the hash function disperses the elements properly among the buckets. Iterating … requires time proportional to the ”capacity” of the HashMap instance.
From
Jav
a A
PI
docu
men
tatio
n
Monday, October 3, 11
Course goals
This lecture was particularly relevant for this course goal:
• Choose among and make use of the most important algorithms and data structures in libraries, based on knowledge of their complexity.




































![Algoritmi e Strutture Dati [24pt]Hashing - disi.unitn.itdisi.unitn.it/~montreso/asd/handouts/07-hashing.pdf · Algoritmi e Strutture Dati Hashing ... Tecniche di risoluzione delle](https://static.documents.pub/doc/80x56/5c66807b09d3f2d0218c6116/algoritmi-e-strutture-dati-24pthashing-disiunitn-montresoasdhandouts07-hashingpdf.jpg)





![Algorithms Lecture 12: Hash Tables [Sp’15] - Jeff Ericksonjeffe.cs.illinois.edu/teaching/datastructures/notes/12-hashing.pdf · Algorithms Lecture 12: Hash Tables [Sp’15] have2](https://static.documents.pub/doc/80x56/5edb07bb09ac2c67fa68b22b/algorithms-lecture-12-hash-tables-spa15-jeff-algorithms-lecture-12-hash.jpg)




