151
Formation Microsoft hyperconvergence Une formation Romain SERRE
| Date post: | 21-Jan-2018 |
| Category: |
Technology |
| Upload: | alphorm |
| View: | 3,841 times |
| Download: | 15 times |

Formation Microsoft hyperconvergence
Une formation
Romain SERRE

Une formation
Romain SERRE
Présentation du formateur
Cloud & Datacenter Management
Membre de la communauté CMDhttp://cmd.community
@RomSerre
http://www.linkedin.com/in/romainserre
http://www.tech-coffee.net

Une formation
Présentation du modèle hyperconvergé
Deep-Dive de Storage Spaces Direct
Troubleshooting et Monitoring
Plan de Reprise d’Activité
Plan de la formation

Une formation
Audience souhaitant découvrir le modèle hyperconvergé
Administrateur Windows
Avant vente / architecte
Public concerné

Une formation
Prérequis
Notion sur le stockage
Notion du système d’exploitation Windows Server
Notion sur les clusters à basculement (Failover Clustering)
PowerShell ☺

Une formation
Ressources
Windows Server 2016 évaluation 180 jours:https://www.microsoft.com/en-us/evalcenter/evaluate-windows-server-2016
Documentation de Microsoft:https://technet.microsoft.com/en-us/windows-server-docs/get-started/windows-server-2016
Documentation sur Storage Spaces Directhttps://technet.microsoft.com/en-us/windows-server-docs/storage/storage-spaces/storage-spaces-direct-overview

Merci

Présentation du lab
Une formation
Romain SERRE

Une formation
Présentation du lab
Machines virtuelles• Gen 2, 4 vCPU, 8GB de mémoire statique et 2x vNICs
• 8x disques virtuelles de 100GB (en dynamique)
Lab virtuel
• Tout le monde pourra déployer un lab
• Inutile d’investir dans du matériel de pointe
Hyperviseur• Hyper-V sous Windows Server 2016
• Nested Hyper-V pour les VMs

Une formation

Merci

Introduction au modèle hyperconvergé
Une formation
Romain SERRE

Une formation
Composants basiques d’une infrastructure
Le datacenter de l’antiquité
Le datacenter moyenâgeux
Le datacenter de la renaissance
Le datacenter du monde moderne
Plan

Une formation
Composants basiques
Compute
• Ressources processeurs et mémoire
• Exécute les applications
Networking
• Equipements réseaux
• Communication entre les applications
Storage
• Equipements de stockage
• Stocke les données des applications

Une formation
Le datacenter de l’antiquité
Compute
• Une application -> un serveur physique
• Faible consolidation
Networking
• Un flux -> une carte réseau
• Multiplication des équipements
Storage
• Applications non HA -> Interne aux serveurs
• Applications HA -> SAN ou NAS

Une formation
Le datacenter de l’antiquité
Faible densité et consolidation
Maintien opérationnel complexe
Coût élevé du matériel
Aucune flexibilité

Une formation
Le datacenter moyenâgeux
Compute
• Plusieurs applications -> quelques serveurs physiques
• Consolidation élevée grâce à la virtualisation
Networking
• Un flux -> une carte réseau
• Multiplication des équipements
Storage
• Plusieurs applications -> SAN ou NAS
• Complexité et évolutivité limitée

Une formation
Le datacenter moyenâgeux
Mutualisation des serveurs
Fort taux de consolidation
Evolutivité complexe
Coût élevé du matériel (SAN)
Management complexe

Une formation
Le datacenter de la renaissance
Compute
• Plusieurs applications -> quelques serveurs physiques
• Consolidation élevée grâce à la virtualisation
Networking
• Plusieurs flux -> quelques cartes réseaux
• Diminution des équipements
Storage
• Plusieurs applications -> Stockage logiciel
• Simplification, évolutivité limitée

Une formation
Le datacenter de la renaissance
Mutualisation des serveurs
Fort taux de consolidation
Automatisation
Mutualisation des ressources

Une formation
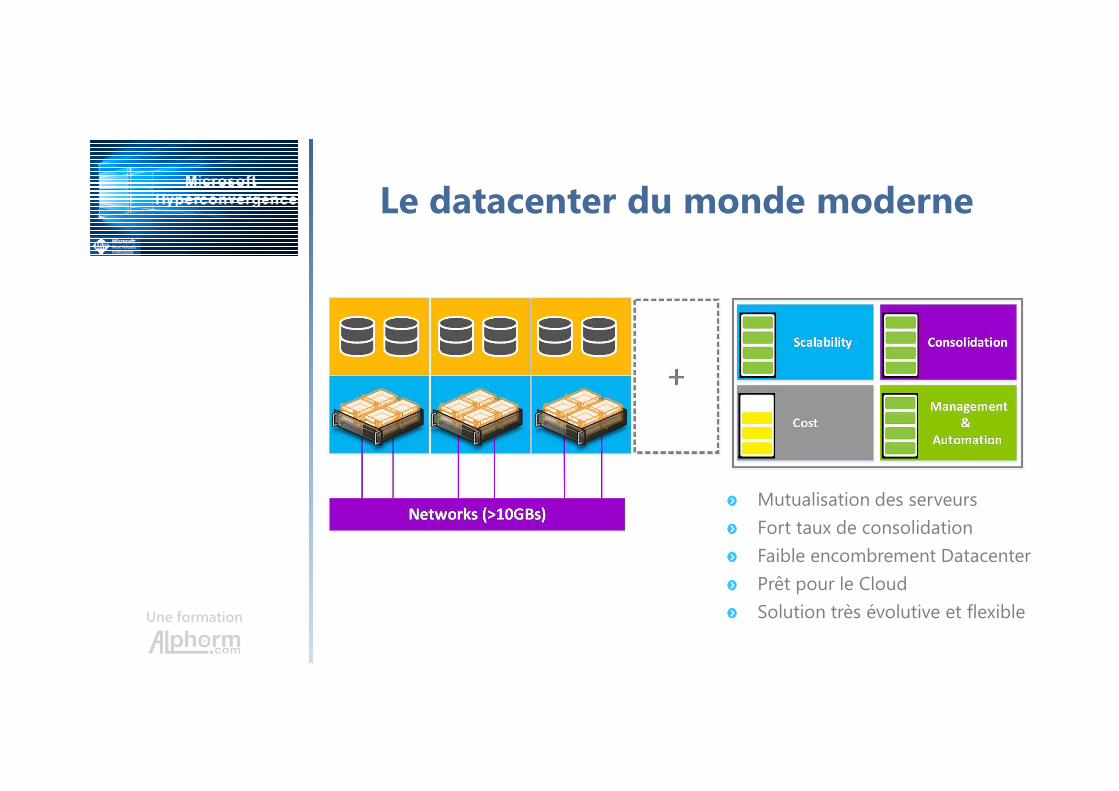
Le datacenter du monde moderne
Compute & Storage
• Le stockage et les noeuds de “compute” sont mutualisés
• Plusieurs applications -> quelques serveurs physiques
• Consolidation élevée grâce à la virtualisation
• Solution souple, flexible, hautement automatisable et Cloud Ready
Networking
• Plusieurs flux -> quelques cartes réseaux
• Diminution des équipements
• Convergence de tous les flux
Une formation
Le datacenter du monde moderne
Mutualisation des serveurs
Fort taux de consolidation
Faible encombrement Datacenter
Prêt pour le Cloud
Solution très évolutive et flexible

Merci

Avantages / inconvénients du modèle hyperconvergé
Une formation
Romain SERRE

Une formation
Les avantages
Les inconvénients
Plan

Une formation
Les avantages ☺
Infrastructure
• Réduction des équipements réseaux et de stockage nécessaires
• Faible empreinte dans le datacenter
• Moins de matériel = moins de panne
Flexibilité
• Ajout d’un nœud = ajout CPU, RAM, Stockage
• Monté en charge simplifiée
• Automatisation du déploiement (logiciel)
Simplification
• Simplification du réseau
• Simplification du stockage
• Solution basée sur du logiciel

Une formation
Les inconvénients �
Dépendance stockage / hyperviseur
• Ajout d’un nœud = ajout CPU, RAM, Stockage
• Perte d’un nœud = perte d’un hyperviseur et d’une partie du stockage
• Les ressources du nœud sont utilisés pour le calcul et le stockage
Contraintes matériels
• Le réseau c’est la vie !
• Attention aux cartes SAS / SATA (carte HBA)
• Augmentation des ressources minimum requises par nœud

Merci

Présentation des fonctionnalités requises de
Windows Server 2016
Une formation
Romain SERRE

Une formation
Hyperviseur
Fonctionnalités de stockage
Fonctionnalités réseaux
Edition de Windows Server 2016 requise
Plan

Une formation
Hyperviseur
Hyper-V
• Hyperviseur de Microsoft
• Permet d’exécuter des machines virtuelles
Failover Clustering
• Haute-disponibilité des VMs
• Utile pour la couche stockage
Dépendances
• Active Directory
• DNS

Une formation
Fonctionnalités de stockage
Failover Clustering
• Utile pour la couche hyperviseur
• Storage Spaces Direct
PRA (optionnel)
• Storage Replica
• Microsoft Azure
Dépendances
• Active Directory
• DNS

Une formation
Fonctionnalités réseaux
Windows
• Switch Embedded Teaming (recommandé)
Offload (optionnel)
• RDMA (RoCE ou iWARP) recommandé
• Datacenter Bridging si RoCE
Divers
• Réseaux 10/25/40/100 GbE
• Au moins deux NICs recommandés

Une formation
Edition de Windows Server requise

Merci

Présentation de la stack hyperconvergé de Microsoft
Une formation
Romain SERRE

Une formation
Couche du modèle hyperconvergé
Couche matérielle
Couche stockage
Storage Spaces Direct (S2D)
S2D intégré au cluster
Couche réseau
Couche Computer
(Hyper-V)

Une formation
Couche du modèle hyperconvergé
Couche réseau
• 10/25/40/100 GbE
• Basé sur SMB 3.11
• Option: RDMA
• Option: 2x vNICs

Une formation
Couche du modèle hyperconvergé
Couche matérielle
• Serveurs
• CPU
• RAM
• Disques
• Cartes réseaux
• Cartes HBA

Une formation
Couche du modèle hyperconvergé
Couche stokage
• Storage SpacesDirect
• Software Storage Bus
• Storage Pool
• Storage Spaces
• Failover Clustering
• CSV

Une formation
Couche du modèle hyperconvergé
Couche compute
• Hyper-V
• S’appuie sur Failover Clustering

Merci

Pré-requis réseaux
Une formation
Romain SERRE

Une formation
Bande passante requise
Remote Direct Memory Access
Exemple de matériel
Plan

Une formation
Bande passante requise
10 GbE minimum
• Pour les communications intra-cluster
• Supporte aussi le 25/40/100 GbE
• Nécessaire pour replication et accès aux données
• Les SSDs sont très consommateurs

Une formation
Remote Direct Memory Access
RDMA
• Réduit la consommation CPU
• Réduit la latence
• Augmente les débits
• Fonctionnalité recommandée mais pas obligatoire
Implémentation de RDMA supporté
• iWARP (internet Wide Area RDMA Protocol)
• Solution Plug & Play
• RoCE (RDMA over Converged Ethernet)
• Solution nécessitant une configuration de bout en bout
• DataCenter Bridging requis

Une formation
Exemple de matériel
Cartes réseaux
• Mellanox Connectx4 pro (RoCE)
• Chelsio T6225-CR (iWARP)
• Intel X710 series (Non RDMA)
Switches
• Mellanox SN2100
• Lenovo RackSwitch G8272
• Cisco Catalyst 3xxx series

Merci

Design réseau
Une formation
Romain SERRE

Une formation
Design réseau du cluster
Réseau 1GB + Réseau 10GB
Réseau 10GB + Réseau 10GB
Réseau > 10GB convergé
Plan

Une formation
Design réseau du cluster
Concernant les flux SMB
SMB Multichannel configuré automatiquement
SMB utilisera par défaut les pNIC ou vNIC où les metrics sont les plus faibles
Recommandations Microsoft pour les Clusters
1x carte physique (pNIC) ou 1x Carte virtuelle (vNIC) pour le management
2x pNIC ou 2x vNIC pour les flux clusters (Heartbeat, SMB, Live-Migration etc.)
Simplified SMB MultiChannel
Système activé automatiquement dans les clusters Windows Server 2016
Reconnaissance automatique des pNIC ou vNIC sur le même switch / sous-réseau
Une seule IP est configurée pour chaque point d’accès cluster

Une formation
Réseau 1GB + Réseau 10GB

Une formation
Réseau 10GB + Réseau 10GB

Une formation
Réseau > 10GB convergé

Merci

Prérequis serveurs et stockage
Une formation
Romain SERRE

Une formation
Prérequis serveurs
Prérequis carte HBA
Prérequis stockage
Minimum de disques requis
Plan

Une formation
Prérequis serveurs
Nombre de nœuds par cluster
• Minimum 2 serveurs
• Maximum 16 serveurs
CPU
• Processeur Intel Nehalem ou plus récent
• Recommandé 2x Intel Xeon par serveur
Mémoire
• 4GB de mémoire par TB de cache
• Ex: avec 2x 1TB de cache: 2 x 1 x 4096MB = 8192MB

Une formation
Prérequis cartes HBA
Cartes supportées
• Carte HBA simple en mode pass through JBOD (SAS ou SATA)
• SCSI Enclosure Service (SES) (SAS ou SATA)
• Les disques doivent être Direct-Attached et présenter un ID unique
• Non supportées : Carte RAID, Carte SCSI, disque SAN/NAS et MPIO
Exemple de cartes
• Lenovo N2215
• Dell HBA330

Une formation
Prérequis stockage
Type de disques
• NVMe, SAS ou SATA et physiquement attaché à un seul serveur
• Disque entreprise avec protection contre les coupures de courant
• Disque de cache : minimum 5 Disk Write Per Days (DWPD)
• Utiliser un disque et/ou carte HBA dédié pour l’OS
Configuration dans le cluster
• Recommandé : tous les serveurs ont la même configuration
• Tous les serveurs doivent avoir les mêmes types de disques
• Ajout de disques de capacité en suivant un multiple du nombre de disque de cache

Une formation
Minimum de disques requis
Minimum de disques
• S’il y a un système de cache : au moins deux disques de cache
• Au moins quatre disques de capacité
Disques présents Minimum requis
All NVMe (mêmes modèles) 4 NVMe
All SSD (mêmes modèles) 4 SSD
NVMe + SSD 2 NVMe + 4 SSD
NVMe + HDD 2 NVMe + 4 HDD
SSD + HDD 2 SSD + 4 HDD
NVMe + SSD + HDD 2 NVMe + 4 Others

Merci

Fonctionnement du Software Storage Bus
Une formation
Romain SERRE

Une formation
Qu’est ce que le Software Storage Bus ?
Fonctionnement
Plan

Une formation
Qu’est ce que le Software Storage Bus ?
Software Storage Bus
• Bus de stockage virtuel étendu aux nœuds du cluster
• Permet à tous les nœuds de voir tous les disques
Protocole
• Utilisation de SMB3
• Permet de s’appuyer sur SMB MultiChannel, SMB Direct
Gestion de la bande passante
• Algorithme d’accès équitable entre les nœuds
• Priorité des IO applicatives (VM) par rapport aux IO systèmes

Une formation
Fonctionnement
ClusPort
• Virtual HBA
• Initiator
Clusblft
• Virtualisation des disques
• Target

Merci

Fonctionnement du système de cache
Une formation
Romain SERRE

Une formation
Système de cache
Fonctionnement
Type de déploiement
Résilience du cache
Ratio disques cache / capacité
Plan

Une formation
Système de cache
Activé par défaut
• Surtout pour un serveur avec stockage mix
• Cache en lecture/écriture ou écriture
• Le disque le plus rapide est le disque de cache
Déploiement manuel
• Pour des déploiements personnalisés
• Cache réglable par PowerShell
• Possibilité de régler le type de cache manuellement

Une formation
Fonctionnement
Cache: Ecriture
(All Flash)
Cache: Lecture / Ecriture
(Hybrid)
Ecriture Lecture
cache Cache
Ecriture Lecture

Une formation
Type de déploiement
Déploiement All flash
• Full NVMe => pas de cache
• Full SSD => pas de cache
• NVMe + SSD / NVMe + NVMe / SSD + SSD = Cache en écriture
Déploiement hybride
• SSD + HDD => cache en lecture / écriture
• NVMe + HDD => Cache en lecture / écriture
• SSD + (SSD+HDD) => Cache en écriture pour SSD et Cache en lecture et écriture pour HDD
• NVMe + (SSD+HDD) => Cache en écriture pour SSD et Cache en lecture et écriture pour HDD

Une formation
Ratio disques de cache / capacité
Association disque cache / capacité
• Géré par le système
• Disques de capacité associés en Round Robin aux disques de cache
Ratio à respecter
• Chaque disque de cache doit avoir le même nombre de disque de capacité
• Ratio 1:1 à 1:12 et au delà

Une formation
Résilience du cache

Merci

Déploiement d’un cluster Storage Spaces Direct
Une formation
Romain SERRE

Une formation
Rappel du lab
Machines virtuelles• Gen 2, 4 vCPU, 8GB de mémoire statique et 2x vNICs
• 8x disques virtuelles de 100GB (en dynamique)
Hyperviseur• Hyper-V sous Windows Server 2016
• Nested Hyper-V pour les VMs

Une formation

Merci

Introduction aux storagepools et aux storage spaces
Une formation
Romain SERRE

Une formation
Storage Pool et Storage Spaces
Storage Spaces
Plan

Une formation
Storage Pool et Storage Spaces

Une formation
Storage Spaces
Résilience
• La résilience est géré par le Storage Spaces
• Mirroring, Parity ou les deux
Notion
• Colonne: nombre de disques participant au Storage Spaces
• Interleave: taille du block
Fonctionnement dans le cluster
• S’appuie sur Cluster Shared Volume (CSV) pour éviter les accès concurrents
• Les VMs seront hébergées dans le CSV

Merci

Introduction aux systèmes de résilience
Une formation
Romain SERRE

Une formation
Fault Domain Awareness
Mirroring
Parity
Multi-Resilient Virtual Disks
Résumé
Plan

Une formation
Fault Domain Awareness
Un Fault Domain (FD) est une collection de matériels qui partagent le même point de défaillance
Définition de votre infrastructure avec 4 types :
Site
Rack
Chassis
Nœuds
Chaque type correspond à un FD
Permet de la tolérance de panne comme dans Azure
Une formation
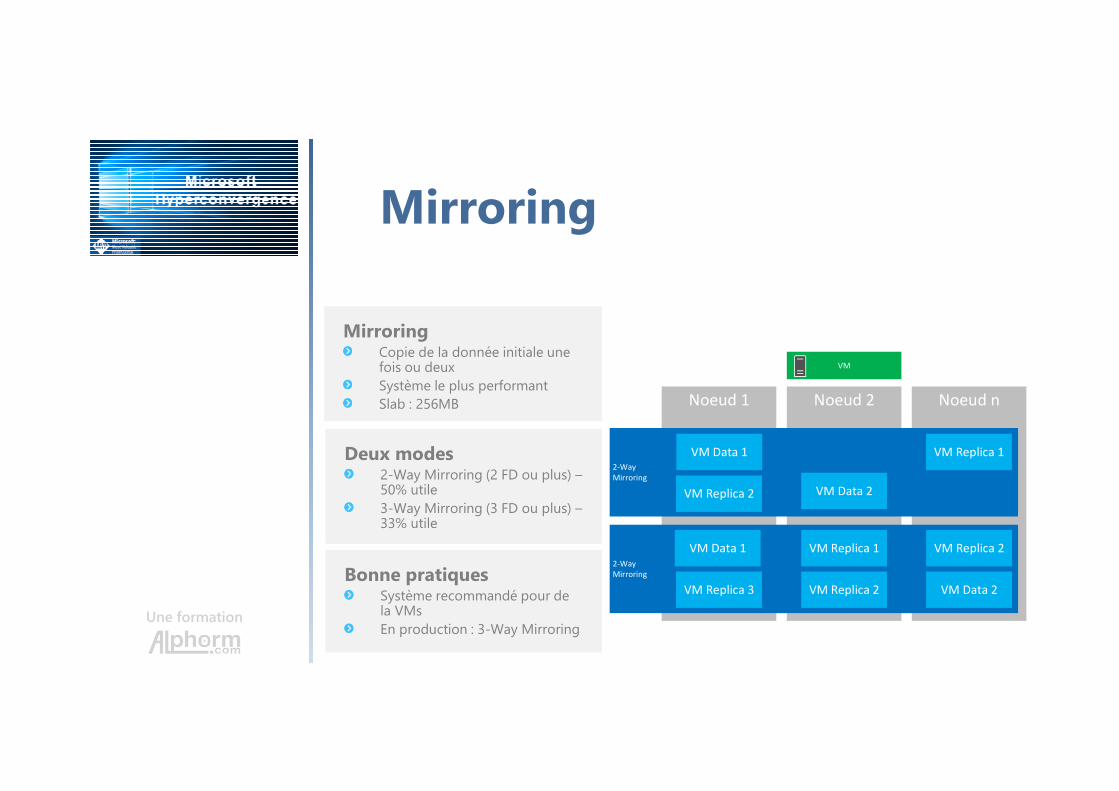
Mirroring
MirroringCopie de la donnée initiale unefois ou deux
Système le plus performant
Slab : 256MB
Deux modes2-Way Mirroring (2 FD ou plus) –50% utile
3-Way Mirroring (3 FD ou plus) –33% utile
Bonne pratiquesSystème recommandé pour de la VMs
En production : 3-Way Mirroring
Noeud 1 Noeud 2 Noeud n
2-Way
Mirroring
2-Way
Mirroring
VM Data 1 VM Replica 1
VM
VM Data 1 VM Replica 1 VM Replica 2
VM Data 2VM Replica 2
VM Data 2VM Replica 3 VM Replica 2

Une formation
Parity
Parity• Créer des symboles de parité
• Système le plus efficace
• Slab: 256MB
Deux modes (4 FD ou plus)• Simple Parity – jusqu’à 80%
• Dual Parity – jusqu’à 80%
Bonne pratiques• Système recommandé pour archivage ou
backup
• En production: Dual Parity

Une formation
Multi-Resilient Virtual Disk
Multi-Resilient Virtual Disk• Deux tiers dans un virtual disks
• ReFS obligatoire
• Non recommandé pour de la VMs
Efficacité• Deux tiers (mirroring et parité).
• Données chaudes -> Mirroring (33% utile)
• Données froides -> Parité (jusqu’à 80% utile)
Performant• Ecriture dans le tier chaud
• Tiering dans le tier froid

Une formation
Résumé
Résilience Tolérance de panne
Stockage utile Fault Domain requis
2-way mirroring
1 50% 2
3-way mirroring
2 33,3% 3
Dual parity 2 50% - 80% 4
Multi-Resilient virtual disk
2 33,3% - 80% 4

Merci

Système de fichiers recommandé pour Storage Spaces Direct
Une formation
Romain SERRE

Une formation
Système de fichier pour S2D
ReFS
• Système de fichiers amélioré avec WS 2016
• Apporte les opérations VHDX accélérées
Trafic redirigé sur le réseau
• Storage Spaces Direct va redirigé la majorité du trafic sur le réseau
• ReFS approprié uniquement avec cet usage uniquement
Alignement
• Il est recommandé de formater le volume en ReFS et en 4K

Merci

Déploiement d’un storagepool et d’un storage spaces
Une formation
Romain SERRE

Une formation

Merci

Ajouter / Supprimer un nœud
Une formation
Romain SERRE

Une formation

Merci

Gérer la QoS des disques de machines virtuelles
Une formation
Romain SERRE

Une formation
Plan
Distributed Storage QoS
Politiques de QoS
Types de politique
Monitoring

Une formation
Distributed Storage QoS
Gestion•
•
Solution native•
••
Politique simple•••

Une formation
Politiques de QoS

Une formation
Types de politique
Single instance••
Multi-instance•
•

Une formation
Monitoring
# Performance des VMs du cluster
# Performance de chaque volume du cluster

Une formation

Merci

Gérer les mises à jour du cluster
Une formation
Romain SERRE

Une formation

Merci

Monitoring de la solution avec Health Service
Une formation
Romain SERRE

Une formation
Health Service
Metrics
Incidents
Solution de monitoring
Plan

Une formation
Health Service
Health Service
• Nouveau service dans Failover Clustering dans WS2016
• Activé uniquement quand S2D est activé
• Rassemble les metrics et les alertes en temps réel des nœuds du cluster
API
• Informations accessibles depuis un seul point d’entrée
• PowerShell, .NET, C# etc.

Une formation
Health Service

Une formation
Metrics
Health service met à disposition des rollups monitors
Pour qu’un nœud soit sain, les moniteurs enfants doivent être sains
Dans la prochaine version de Health Service, le service sera intelligent:
• Un noeud qui perd un disque provoque une erreursur le moniteur noeud
• Cependant le cluster affiche qu’un “Warning” car il a assez de noeud pour encore faire marcher le service

Une formation
Incidents
Temps réel
• Les incidents sont traités en temps réel
• Affichage de la source de la panne
Exemple de panne
• Carte réseau déconnectée
• Serveur injoignable (maintenance ou panne sérieuse)
• Un disque est absent
• Il n’y a plus d’espace libre sur le Storage Pool

Une formation
Solution de monitoring
SCOM

Une formation
Solution de monitoring
DataOn Must

Une formation
Solution de monitoring
Log Analytics

Une formation

Merci

Remplacer un disque défectueux
Une formation
Romain SERRE

Une formation

Merci

Premiers gestes en cas d’incident
Une formation
Romain SERRE

Une formation

Merci

Introduction à Storage Replica
Une formation
Romain SERRE

Une formation
Plan
Storage Replica
Scénarios possibles
Modes de réplication
Prérequis

Une formation
Storage Replica
Réplication synchrone / asynchrone
Augmenter la résilience
Solution complète
Gestion simplifiée

Cluster-to-clusterStretch cluster
Server-to-selfServer-to-server
Scénarios possibles

Zero data loss RPO
Application critique
Petite distance
(<5 ms, soit <30 km)
Déploiement On-
premise
Lien dédié
Bande passante
importante
Near zero data loss (depends on multiple factors) RPO
Application non
critique
Réplication vers
d’autre sites région
ou pays
Distance illimitée
Utilisation du WAN
Mode de réplication

Une formation
Prérequis
Latence réseau
Bande passante
Performance et taille du volume
de log

Une formation

Merci

Introduction à Azure Site Recovery
Une formation
Romain SERRE

Une formation
Azure Site Recovery
Exemples de scénario
Scénarios disponibles
Plan

Une formation
Azure Site Recovery
Fonctionnalités
• Protection et réplication automatisées des machines virtuelles VMWare ou Hyper-V et de machine physiques
• Orchestration du PRA à l’aide de plans de récupération personnalisables
• Azure Site Recovery peut utiliser Azure Automation pour automatiser des tâches lors de l’exécution du PRA
• Possibilité de tester un plan de récupération sans impact sur la production
Pré-requis
• Nécessite un compte Microsoft Azure
• Nécessite au moins un compte de stockage dans la même région que l’instance ASR
• Un réseau virtuel configuré est nécessaire pour interconnecter les VMs qui ont basculées. Ce réseau virtuel doit être dans la même zone géographique que l’instance ASR

Azure Site Recovery
Exemple de scenario
Réplication ASR
SQL Availability Group
On-premises Microsoft Azure
Réplication AD
Site-to-Site VPN

Scénarios disponibles
Fonctionnalités clés:
Utiliser Azure comme site de récupération
Automatiser la protection et la replicationdes VMs
Monitoring de l’état de réplication
Personnaliser les plans de récupération
Tester les plans de récupération sans impact
Orchestrer la récupération d’applications tierces
Réplication dans Azure sans System Center
Orchestrationet réplication
Microsoft Azure Site Recovery
Site
On-premises
Hyper-V
Orchestrationet réplication
Microsoft Azure Site Recovery
Site
On-Premises VMware/Physical
Orchestrationet réplication
Microsoft Azure Site Recovery
Site
On-premises
Hyper-V

Une formation

Merci

Conclusion
Une formation
Romain SERRE

Une formation
Hyperconvergence : les atouts
Simplicité
• Facile à déployer
• Facile à administrer
Flexibilité
• Ajout / suppression d’un nœud rapide
• Ajout d’un nœud = ajout de CPU et de RAM
Orienté Cloud
• Suivi de la montée en charge plus facile
• Systèmes de gestion de QoS pour plusieurs SLA

Une formation
Hyperconvergence : attention
Evitez les économies sur :
• Les équipements réseaux (y compris les NICs)
• La qualité des équipements de stockage
Ne pas choisir cette solution lorsque:
• Le réseau n’est pas adapté
• Si les besoins stockage sont plus élevés que CPU
Le design
• Passer du temps sur le design avant d’acheter
• Bien calculer le stockage utile restant

Une formation
Merci !
Merci d’avoir suivi cette formation
En espérant qu’elle vous ait plu
N’hésitez pas à me joindre si vous avez des
questions :)

Une formation
Liens utiles
Merci d’avoir suivi cette formation
En espérant qu’elle vous ait plu
N’hésitez pas à me joindre si vous avez des
questions :)

Une formation
Romain SERRE
Présentation du formateur
Cloud & Datacenter Management
Membre de la communauté CMDhttp://cmd.community
@RomSerre
http://www.linkedin.com/in/romainserre
http://www.tech-coffee.net

Merci

















