Translation universals: do they exist? A corpus-based NLP study of convergence and simplification Gloria Corpas*, Ruslan Mitkov**, Naveed Afzal**, Viktor Pekar*** * University of Málaga ** University of Wolverhampton *** Oxford University Press
Transcript
Translation universals: do they exist?A corpus-based NLP study of convergence and simplification
Gloria Corpas*, Ruslan Mitkov**, Naveed Afzal**, Viktor Pekar***
* University of Málaga** University of Wolverhampton
Translated texts tend to be simpler than non-translated, original texts (simplification)Translated texts tend to be more explicit than non-translated texts (explicitation)Translated texts tend to be more similar than non-translated texts (convergence)
Previous research on translation universals
Formulation and initial explanation been based of intuition and introspection Follow-up corpus research limited to comparatively small-size corpora, literary or newswire texts and semi-manual analysisNo sufficient guidance as to which are the features which account for these universals to be regarded as valid
Objective of this study
To test the validity of convergence (translated texts tend to be more similar than non-translated texts)To test the validity of simplification (translated texts tend to be simpler than non-translated texts)To propose features which account for convergence y simplificationTest (target) language: Spanish
General methodology: convergence
Employment of NLP techniques on corpora of translated Spanish and on comparable corpora of non-translated (original) Spanish Similarity between every pair of corpora of translated texts and between every pair of corpora of original texts computedSimilarity is measured in terms of both style and syntax
General methodology: simplification
Employment of NLP techniques on corpora of translated Spanish and on comparable corpora of non-translated (original) Spanish For every corpus a set of lexical and stylistic features computed and compared with its comparable counterpart
Corpora usedCorpus of Medical Spanish Translations by Professionals (MSTP: 1,058,122) Corpus of Medical Spanish Translations by Students (MSTS: 1,058,122)Corpus of Technical Spanish Translations (TST: 1,736,027)Corpus of Original Medical Spanish Comparable to Translations by Professionals (MSTPC: 1,402,172) Corpus of Original Medical Spanish Comparable to Translations by Students (MSTSC: 1,164,435)Corpus of Original Technical Spanish Comparable to Technical Translations (TSTC: 1,986,651)
Comparability of corpora
Comparability in terms of
(i) Text types and forms (ii) Domains and sub domains (iii) Level of specialisation and formality (iv) Diatopic restrictions (Peninsular Spanish) (v) Time span (2005-2008) (vi) Similar size
CORPUS DESIGNCORPUS DESIGN
NONTRANSLATED
CORPUS
MSC
MSTSC MSTPC
TSTC
ES (TT) ES (NT)
Study 1: ConvergenceSpecific methodology (1)
Compared: all 3 pairs of translated texts (MSTP-MSTS; MSTS-TST; MSTP-TST) all 3 pairs of comparable non- translated texts (MSTPC-MSTSC; MSTSC-TSTC; MSTPC-TSTC)
Premise: If convergence universals holds, higher similarity for pairs of translated texts expected.
Study 1: ConvergenceSpecific methodology (2)
Texts compared on the basis of (i) style (stylistic features)(ii) syntax (syntactic features).
Our proposal for stylistic and syntactic features
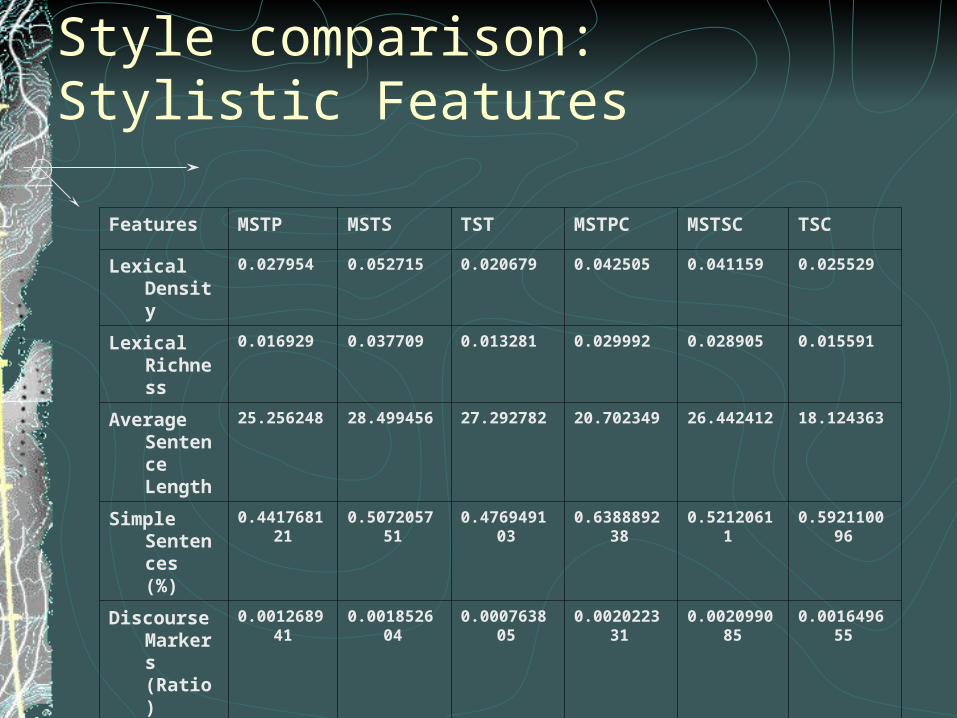
Style comparison: stylistic features
Lexical density: (number of types)/
(total number of tokens present in corpus)
Lexical richness: (number of lemmas)/
(number of tokens present in corpus)
Sentence length:(number of tokens in corpus)/
(number of sentences)
Style comparison: stylistic features (2)
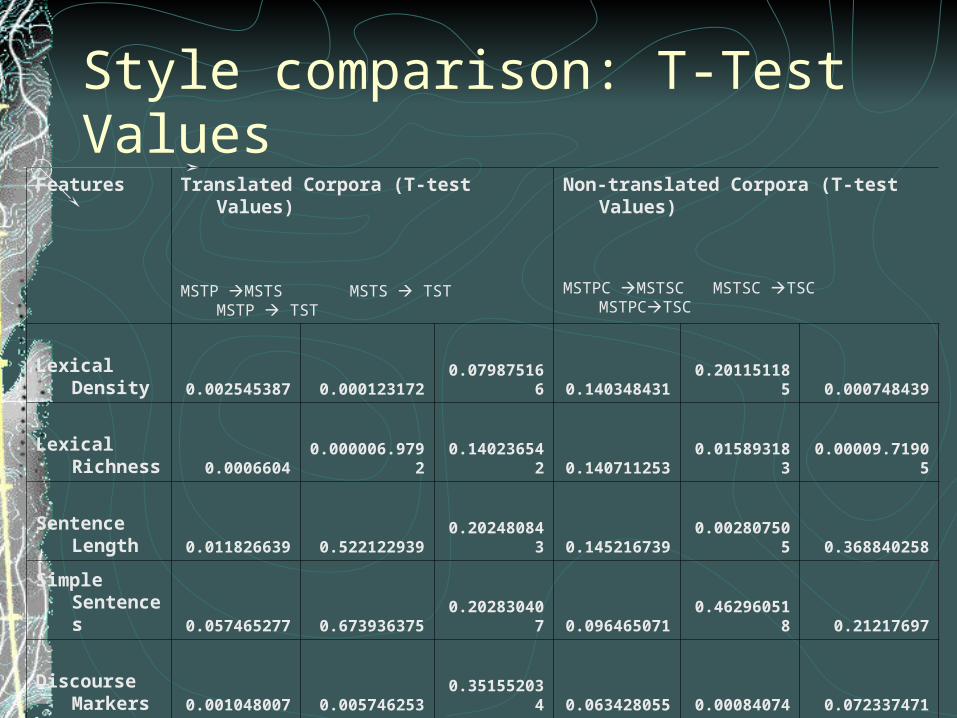
Simple/complex sentencesDiscourse markers (Spanish)Two statistical tests (Chi-Square test and T-test) employed
Syntax comparison
Sequences of POS tags for every pair of corpora comparedCorpora represented as frequency vectors of 3-grams (Nerbonne and Wiersma, 2006)Measures:
Cosine Recurrence metrics R and Rsq (Kessler, 2001)
Experimental results
Computation of stylistic featuresChi-square values for global comparisonT-test values for statistical significanceMeasuring vector differences for syntax comparison
Stylistic features: translated texts included in experiment are more similar than non-translated texts (Chi-square test)
Convergence: discussion (2)
T-test observationsThere are non-translated texts which are not statistically different in terms of stylistic features whereas corresponding translated texts different statisticallyThere are non-translated texts which are statistically different in terms of only one stylistic feature whereas corresponding translated texts different statistically with regard to two stylistic features Translated texts could often differ significantly with regard to certain style features (lexical density).
Convergence: discussion (3)
Translated texts differ more in terms of syntax for all compared pairs and from the point of view of all measures (1-C, R and Rsq)
Study 2: SimplificationSpecific methodology
Stylistic features accounting for ‘simple’ textsSentence lengthSimple vs. Complex sentences
ReadabilityAutomated Readability Index (ARI)Coleman-Liau Index (CLI)Flesch-Kincaid Grade Level Readibility Test (FK)
Results compared across pairs of corpora
Comparison of mean values of the lexical and stylistic features between corresponding comparable corpora
FK 19.53 18.21 0.5 21.32 21.51 0.5 20.03 15.46 0.001
Simplification: discussion
Mixed pictureSimplification confirmed on
Lexical richnessLexical densityReadability
Simplification not confirmed onSentence lengthProportion of simple sentences
Implications for translation universalsConvergence
Style: convergence appears to be broadly holding, but no definite conclusion can be made that convergence is a clear-cut universal Syntax: there is no evidence that convergence holds in terms of syntaxGeneral: results do not provide sufficient support to the convergence ‘universal’
SimplificationMixed picture: no sufficient support for simplification
Implication for Machine Translation
Given the mixed picture, not manyBut: translated text have to be more readable than non-translated textMore research is needed as to which features are ‘stable’Included into an MT model?
Conclusions
There is no sufficient evidence/support that translation universals (convergence, simplification) holdFeatures which appear to be ‘stable’ (e.g. readability) could be modelled into MT systems