12
WHITE PAPER MAY 2017 An Analytics System on a Hosted OpenStack™ Private Cloud for Manufacturing Author: Sanhita Sarkar, Western Digital Corporation

WHITE PAPER MAY 2017
An Analytics System on a Hosted OpenStack™ Private Cloud for ManufacturingAuthor: Sanhita Sarkar, Western Digital Corporation

1
AN ANALYTICS SYSTEM ON A HOSTED OPENSTACK PRIVATE CLOUDWHITE PAPER
Executive OverviewThe emergence of the software-defined economy is driving the architectural transformation of data centers. Organizations need a quick response to the demands of new services, with speed and agility. OpenStack™, a cloud-based computing platform and deployed as Infrastructure-as-a-Service (IaaS), provides organizations an increased level of flexibility to deploy storage, compute and network of resources within a data center, in a cost-effective manner. A few business benefits of OpenStack for Big Data workloads are the ability for rapid and dynamic provisioning of a cluster, ability to dynamically change the role of nodes providing elasticity, ability to scale resources as users grow, along with its open source benefits. Sahara in OpenStack has been developed to meet the need for agile access to Big Data and to provide unlimited scalability, elasticity and data availability.
This paper describes an analytics system using Sahara on a hosted OpenStack private cloud and how it can provide the flexibility of provisioning infrastructure resources to a real-world manufacturing workload with the growth of data and its users. The analytics system connects to an HGST Object Storage System, an external object data store, and can dynamically spin up a virtual compute cluster for a set of jobs, without moving the data. This paper demonstrates performance of the above-mentioned analytics system within the cloud environment to be 80-99% of native with a reduced TCO and an improved ROI.

2
AN ANALYTICS SYSTEM ON A HOSTED OPENSTACK PRIVATE CLOUDWHITE PAPER
1. IntroductionWhen we think of computer resources in the cloud, we usually think of public clouds, with infrastructure or applications shared by millions of clients worldwide, through the internet. However, organizations with security concerns cannot move directly to public clouds, but must invest in private clouds, instead. A few good qualities of private clouds are offering resources (infrastructure and applications) as services; flexibility and scale to meet client demands; resource sharing among a large number of corporate users and others. Physical hardware running on premise takes time and cost for organizations to host it across multiple functions. Instead, an IaaS model in a private cloud allows for availability of hardware within hours instead of days, saving time to market for organizations. Additionally, OpenStack IaaS provides an increased level of flexibility, allowing for growing and shrinking resources on demand within a private cloud, as well within hybrid clouds, if needed. Out of various deployment models, hosted OpenStack private cloud is where a vendor hosts an OpenStack-based private cloud including underlying hardware and the OpenStack software. Figure 1 shows the trends of different cloud models over the next couple of years, with hosted private cloud being one of the growth areas. The paper describes a hosted OpenStack private cloud implementation within a corporate data center for executing manufacturing business processes along with supporting various corporate users who access the data for deriving insights into quality control and operational efficiency (Figure 2). Here, the data is centralized and lives within the remote private cloud, and accessed by corporate users.
On the OpenStack-managed infrastructure, Sahara is then used to rapidly create and manage Apache™ Hadoop® clusters and run workloads on them, without the need of any cluster management. Sahara can install and manage several clusters at the same time, providing tools to add nodes to the existing cluster, remove nodes for maintenance or to dynamically provision clusters of different sizes to meet the needs of varied workloads. It provides predefined configurable templates to install a Hadoop cluster in a few minutes just by specifying several parameters. Because Big Data workloads are heavy in terms of required CPU and RAM, it is highly recommended to enable hardware virtualization on the OpenStack compute nodes. In this case, Red Hat® Kernel-based Virtual Machine (KVM) have been used to build Big Data /Hadoop instances on the analytics system (Figure 4).
Manufacturing data comprising of complex binary files generated from the shop floors of multiple sites is continuously archived into an HGST Object Storage System. As the data arrives, queries using Apache Hive™ user-defined functions (UDFs) which analyze device defect patterns are executed on the virtual machines provisioned by Sahara on the OpenStack cloud. Results are stored in a Hive table, and accessed by Impala query engine to display device defect quality metrics and sigma deviations from standard baseline, on a Tableau® visualizer. Predictive analytics is performed using K-means clustering machine learning algorithm enabled by an IBM® SPSS® engine to classify the defect patterns and detect any new patterns as a part of unsupervised learning (Figure 3).
Figure 5a shows the manufacturing workload executing in production in a public cloud where the corporate business users are challenged with a 24-48 hour lag in detecting device anomalies, thus impacting quality in time in production. The challenge surges with a bigger population of manufacturing event data (600 GB/day today). Figure 5b shows a bare metal (native) analytics system connected to an HGST Object Storage System installed on premise in a non-cloud environment. Process data persistence followed by optimizations have led up to a 17x performance improvement at ¼ of the TCO. Figure 5c shows the hosted OpenStack
Contents1. Introduction …………………………………………… 2
2. Implementation Details ………………………… 3
2.1. Specifications for Native System ……4
2.2. Specifications of the Analytics System on OpenStack Cloud …………………………4
2.2.1. Physical Configuration …………………… 4
2.2.2. OpenStack Logical Data Processing Cluster Configuration …………………… 4
2.2.2.1 Resource Pool (Max Quota) Configurations on OpenStack …… 4
2.2.2.2 Logical Hadoop Data Cluster Configuration ……………………………… 4
3. Performance Results …………………………… 5
3.1. Performance of Compute-intensive Analytical Query ………………………………… 5
3.2. Performance of I/O-intensive Analytical Query …………………………………6
3.3. Performance of Mixed Analytical Query …………………………………………………8
3.4. Summary of Performance Results …8
4. Total Cost of Ownership ………………… 10
5. Conclusions ………………………………………… 10
6. Appendix …………………………………………… 11

3
WHITE PAPER AN ANALYTICS SYSTEM ON A HOSTED OPENSTACK PRIVATE CLOUD
cloud implementation using Sahara provisioning of Big Data clusters.
The rest of the paper will focus on the implementation (5c) and will compare results time to time with (5b) and (5a). Details of implementation and optimizations for (5b) are not addressed in this paper, but discussed in a separate paper.
2. Implementation DetailsThis section describes the implementation details of the manufacturing workflow on premise on a native system as well as on OpenStack Cloud.
2.1. Specifications for Native SystemThe specifications of the native implementation are as follows (Figure 5b)
• 1 HGST Object Storage System with EasiScale™ 4.1.1 (the HGST Active Archive System was used for this implementation).
• Analytics System:
– 16 Data/Worker nodes each with 24 cores /48 vcpus (Intel® Xeon® E5-2680 V3), 24 drives, 512 GB memory
– 3 Master Nodes – 4 Edge Nodes – Dual 48-port 10GbE switches for data network – 48-port Management switch.
2.2. Specifications of the Analytics System on OpenStack CloudThe specifications of the analytics system on OpenStack cloud are as follows:
2.2.1. Physical Configuration• One Administration Node
º 48 vcpus, 512 GB memory, 4 4TB drives, 1 10GigE NIC with two ports;
SPSSModeler for Visualization
Impala QueryEngine
Predictive Analytics with SPSS
Hadoop MapReduce
On-Premise
APAC MFG Shop Floors4 Sites: Singapore, China, Thailand, Japan
Con
tinuo
usBi
nary
Dat
a
APAC Object Storage Site Gateways
Tran
sfor
med
Las Vegas Object StorageSite Gateway• 700 GB+ Object size/day• 10,000+ Objects/day• 30 TB+ Total Object Size for 4 months• 500K+ Total number of objects HGST Object
Storage System
Store,persist,archive
Batch Layer
Batch queries, machine learning/scoring, visual dashboards for patternrecognition of disk defect maps.
Serving Layer
Tableau for Visualization
Batch Analytics & Visualization
S3A
Con
nect
or
VenusQ SerDe
VenusQ_MasterHive Table
Hive Querywith UDF
Decode binary data
External table for decoded binary data
Manufacturingdefect analytics
Figure 3: Manufacturing workflow executing natively on an analytics system
Customer Supplied
Vendor-hostedSystem on
Private Cloud
ManufacturingApplications
TableauVisualization
Hive, User Defined Functions (UDFs), Impala, Hue, SAS,
R, JMP, SPSS
Big Data /Hadoop Virtual
Machines
SaharaEcosystem for
OpenStack
OpenStack Iaas
VM VMVM VM
VM VM
Figure 4: An analytics system hosted on OpenStack private cloud
9.0%6.0%8.9%
19.9%
51.0%
Todayn=108
5.2%
Software as a Service (SaaS)
Goal for thisparticular solution
Native, Non-Cloudsolution as our baseline
(completed earlier)
Infrastructure-as-a-Service (IaaS)/Public CloudHosted Private Cloud
On-premisesPrivate Cloud
O�-premisesNon-Cloud
On-premisesNon-Cloud
In Two Yearsn=99
16.5%
13.1%
16.1%
18.1%
33.5%
4.9%
Figure 1: On-premise deployments will decline dramatically, while hosted private cloud and public cloud deployments will increase (451 Research, September 2016)
Self-
Serv
ice
IT Admin Business User andDevelopers
Corporate Firewall
Example: A vendor hosts an OpenStack-based private cloud in Las Vegas including hosting the underlying hardware and the OpenStackTM software for various internal manufacturing business processes.
Vendor-hostedand managed
Vendor: An internal Cloud Service provider.
Data is centralized and lives withinthe private cloud.
OpenStack
Las Vegas
Administrator
Figure 2: Solution Objective: implement a vendor-hosted OpenStack private cloud for manufacturing analytics

4
WHITE PAPER AN ANALYTICS SYSTEM ON A HOSTED OPENSTACK PRIVATE CLOUD
• 16 worker nodes. Each worker node is configured with
º 48 vcpus, 512GB memory, 24 1TB drives, 1 10GigE NIC with two ports;
º A total pool of 768 vcpus, 8 TB RAM, 320 TB for GFS (20 1TB drives per node for Cinder block storage)
• 2 10GigE switches
• 1 GigE switch
2.2.2. OpenStack Logical Data Processing Cluster Configuration
2.2.2.1. Resource Pool (Max Quota) Configurations on OpenStack• 120 Instances
• 824 vcpus
• 8 TB memory
• 120 volumes
• 300 TB total disk volume
• Cloudera™ OpenStack Sahara Plugin: CDH-5.4.5-sahara-centos-S3A-v001 for Hadoop CDH plugin
• Guest OS: CentOS-6-x86_64-GenericCloud-1607 for Guest OS
• Three flavors are created for Hadoop VMs
- Flavor 1 - 24 vcpus, 192 GB, 80GB for Root Disk, 100GB Data disk volume
- Flavor 2 - 48 vcpus, 256 GB, 80GB for Root Disk, 100GB Data disk volume
- Flavor 3 – 8 vcpus, 128GB, 80GB for Root Disk, 100GB Data disk volume
2.2.2.2. Logical Hadoop Data Cluster ConfigurationConfiguration 1:16 Node CDH cluster (784 vcpus, 4352 GB, 1.6TB disk space for HDFS)
• 16 VMs using flavor 2, as Hadoop Data Nodes
• 2 VMs using flavor 3, as Hadoop Master Nodes
Configuration 2:32 Node CDH cluster (784 vcpus, 6400 GB, 3.2TB disk space for HDFS)
• 32 VMs using flavor 1, as Hadoop Data Nodes
• 2 VMs using flavor 3, as Hadoop Master Nodes
Figure 6 shows the software layout of an analytics system dynamically provisioned with OpenStack Sahara in the private cloud. The logical system within the cloud is connected to an externally located HGST Object Storage System (the HGST Active Archive System was used for
ManufacturingApplications
TableauVisualization
Hive, User Defined Functions (UDFs), Impala, Hue, SAS,
R, JMP, SPSS Big Data /
Hadoop VirtualMachines
SaharaEcosystem for
OpenStack
OpenStack IaaS
VM VMVM VM
VM VM
CustomerSupplied
Vendor-hostedSystem on
Private Cloud
Hosted OpenStack Private Cloud for Manufacturing Analytics
Native (On-premise Non-Cloud):An Analytics System Hosted on Premise
for Manufacturing
Production: Public Cloud forManufacturing Analytics
Corporate Manufacturing
Corporate BusinessUsers (Quality,Development,
Marketing, Sales...)
Corporate IT
Real-time data from manufacturingprocesses executing on shop floors
Public Cloud
Managing the public cloud infrastructure
Problems:• 24-hr lag in product defect detection, with delayed and missed decisions• Total Cost of Ownership (TCO)• Return on Investment (ROI)
OpenStack Cloud
SaharaController
DynamicAnalytics Cluster
S3A
Con
nect
or
Master 1
Node 1 Node 2 Node N
Stand byMaster 1
OpenStack Infrastructure
CustomerSupplied
Vendor-Physical/
NativeSystem
on premise(Non-Cloud)
ManufacturingApplications
TableauVisualization
Hive, User Defined Functions (UDFs), Impala, Hue, SAS,
R, JMP, SPSS
Big Data /Hadoop Physical
Ecosystem
• Process optimizations and on-premise deployment leading to ˜17x perfomance improvement at ¼th of TCO
• Product defect detection and analysis within 5 mins
Insight into product defects, Six Sigma compliance, time to market
• Flexibility to dynamically provision, grow and shrink application instances for end users, with an improved ROI
• Performance in OpenStack Cloud is within 80-90% of Native
Horizon +Sahara UI
SecurityNetwork
ComputeStorage
OpenStackController
Corporate IT ManufacturingApplications
Figure 5: Path to cloud enablement: a) manufacturing production environment in the public cloud; b) native on-premise non-cloud implementation for manufacturing analytics; c) the analytics system hosted on OpenStack private cloud for manufacturing

5
WHITE PAPER AN ANALYTICS SYSTEM ON A HOSTED OPENSTACK PRIVATE CLOUD
this implementation) through the S3A connector and reads and writes data from and to it.
The software specifications are shown in Table 1.
3. Performance ResultsThis section describes the performance characterization done for the manufacturing workload as follows:
• Uses three types of queries which are compute-intensive, I/O-intensive, and with a mixed compute and I/O operations;
• Uses three scenarios of query execution as follows:
• Scenario 1: Hadoop HDFS for Input and Output files;
• Scenario 2: HGST Object Storage System used for Input files and Hadoop HDFS for Output files;
• Scenario 3: HGST Object Storage System used as a default Hadoop HDFS, for both Input and Output files.
• Compares performance results of the queries in the above three scenarios running on native non-cloud system with those in OpenStack cloud;
• Compares performance results of the queries in the above three scenarios within OpenStack cloud for varying number of virtual machines.
Two configurations of OpenStack have been used for performance characterization:
1. OpenStack (16 VMs) with 1 VM per node;2. OpenStack (32 VMs) with 1 VM per NUMA node
(socket). NUMA stands for Non-uniform Memory Access.
Results from OpenStack (16 VMs) configuration are
compared to native non-cloud baseline configuration of 16 physical nodes.
The following sections provide a summary of the performance results.
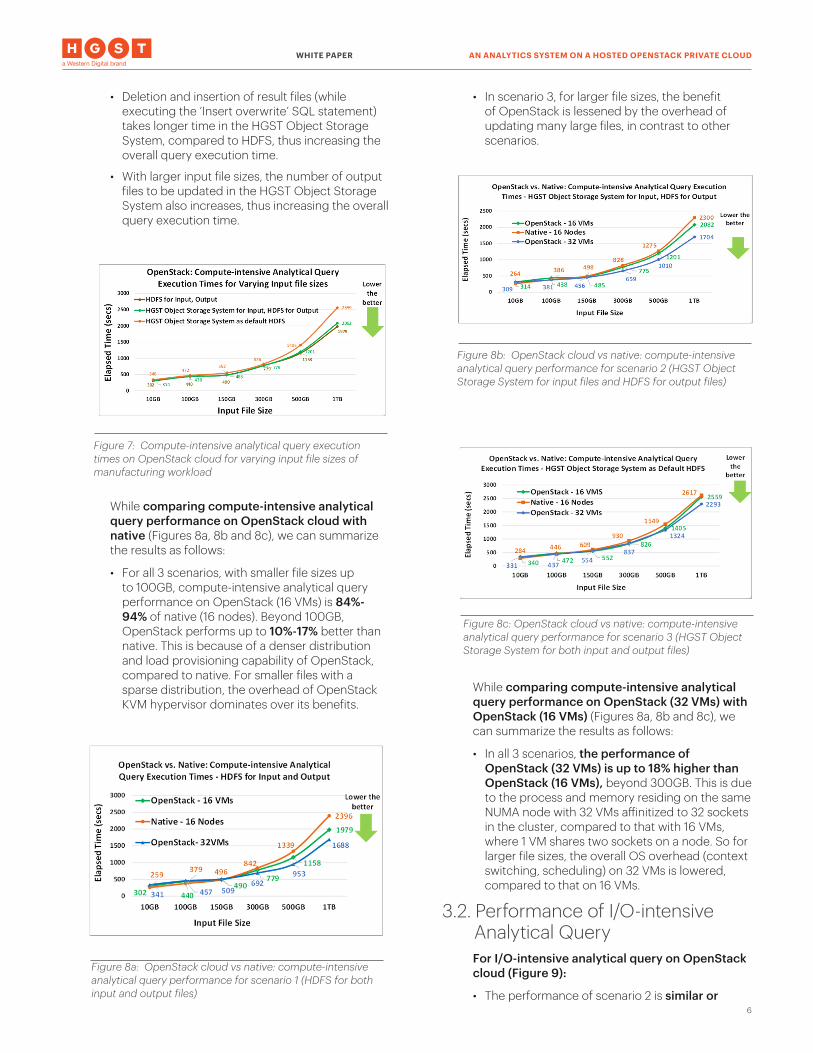
3.1. Performance of Compute-intensive Analytical QueryFor compute-intensive analytical query on OpenStack cloud (Figure 7):
• The performance of scenario 2 is similar to scenario 1, when writing the output to HDFS.
• The performance of scenario 3 is a bit lower compared to scenarios 1 and 2, with an increased slowdown with larger input file sizes. The reason for this slowdown is as follows:
Table 1: Software components used for the implementation
Big Data ComponentsManufacturing process data persistence within HGST Object Storage SystemConnectivity between HGST Object Storage and analytics clusterOpenStack® Library ReleaseSaharaOperating System (Host)Operating System (Guest)Java® for ClouderaTM functionalityHadoop®
ClouderaTM OpenStack® Sahara plugin
Analytical Query Engine
Advanced Manufacturing Analytics and Machine LearningDecodingStatistical data discovery**Predictive AnalyticsData Mining and Advanced Analytics**Open Source User Interface for R**Interactive Visualization
SoftwareCustom code
HGST S3A Connector
12.0.4-03.0.0 (comes with Liberty Release)Ubuntu® 14.04.5 LTSRHEL 6.6 (CentOS 6.6)Oracle® JDK 1.7CDH 5.4.5CDH-5.4.5-sahara-centos-S3A-v001(Custom support for S3A)Hive (comes with CDH 5.4.5)Impala (comes with CDH 5.4.5)Custom Code using Hive UDFs
Hive SerDeJMP from SASSPSS from IBM®
SAS, RRStudio®
Tableau®
** Not used for the implementation.
Figure 6: Software layout of the analytics system dynamically provisioned with OpenStack Sahara in the private cloud
Pool
of C
ompu
te a
nd S
tora
ge fo
r Ope
nSta
ck C
loud
Pro
visi
onin
g Analytics ClusterProvisioned in the Cloud
VMs(RHEL on Ubuntu®)
Con
trol
ler N
ode
S3A
Con
nect
or
NameNode
Tableau
ResourceManager
Hive, Impala, Hue
StandbyNameNode
NodeManagerApplicationMaster
NodeManagerApplicationMaster
VenusQ Decoder, R,RStudio®, SAS®,
JMP®, SPSS
OpenStack Nodes
Nova(Compute)
Nova(Networking)
Cinder(Block)
CephTM (provisioning block/object) -Not used for this implementation
Gluster FS backend
Swift(Object)
ClouderaTM OpenStackSahara Plugin
External Object Storage
(HGST ObjectStorage System)
OpenStack Cloud Controller Node
Dashboard(Horizon)
HAProxy
Identity(Keystone)
Saha
raC
ontr
olle
r
Orchestration(Heat)
Image(Glance)
Neutronagents
CustomerSupplied
Vendor-hostedSystem on
Private Cloud
ManufacturingApplications
TableauVisualization
Hive, User DefinedFunctions (UDFs),Impala, Hue, SAS,
R, JMP, SPSS Big Data /
Hadoop VirtualMachines
SaharaEcosystem for
OpenStack
OpenStack Iaas
VM VMVM VM
VM VM
6
WHITE PAPER AN ANALYTICS SYSTEM ON A HOSTED OPENSTACK PRIVATE CLOUD
• Deletion and insertion of result files (while executing the ‘Insert overwrite’ SQL statement) takes longer time in the HGST Object Storage System, compared to HDFS, thus increasing the overall query execution time.
• With larger input file sizes, the number of output files to be updated in the HGST Object Storage System also increases, thus increasing the overall query execution time.
While comparing compute-intensive analytical query performance on OpenStack cloud with native (Figures 8a, 8b and 8c), we can summarize the results as follows:
• For all 3 scenarios, with smaller file sizes up to 100GB, compute-intensive analytical query performance on OpenStack (16 VMs) is 84%-94% of native (16 nodes). Beyond 100GB, OpenStack performs up to 10%-17% better than native. This is because of a denser distribution and load provisioning capability of OpenStack, compared to native. For smaller files with a sparse distribution, the overhead of OpenStack KVM hypervisor dominates over its benefits.
• In scenario 3, for larger file sizes, the benefit of OpenStack is lessened by the overhead of updating many large files, in contrast to other scenarios.
While comparing compute-intensive analytical query performance on OpenStack (32 VMs) with OpenStack (16 VMs) (Figures 8a, 8b and 8c), we can summarize the results as follows:
• In all 3 scenarios, the performance of OpenStack (32 VMs) is up to 18% higher than OpenStack (16 VMs), beyond 300GB. This is due to the process and memory residing on the same NUMA node with 32 VMs affinitized to 32 sockets in the cluster, compared to that with 16 VMs, where 1 VM shares two sockets on a node. So for larger file sizes, the overall OS overhead (context switching, scheduling) on 32 VMs is lowered, compared to that on 16 VMs.
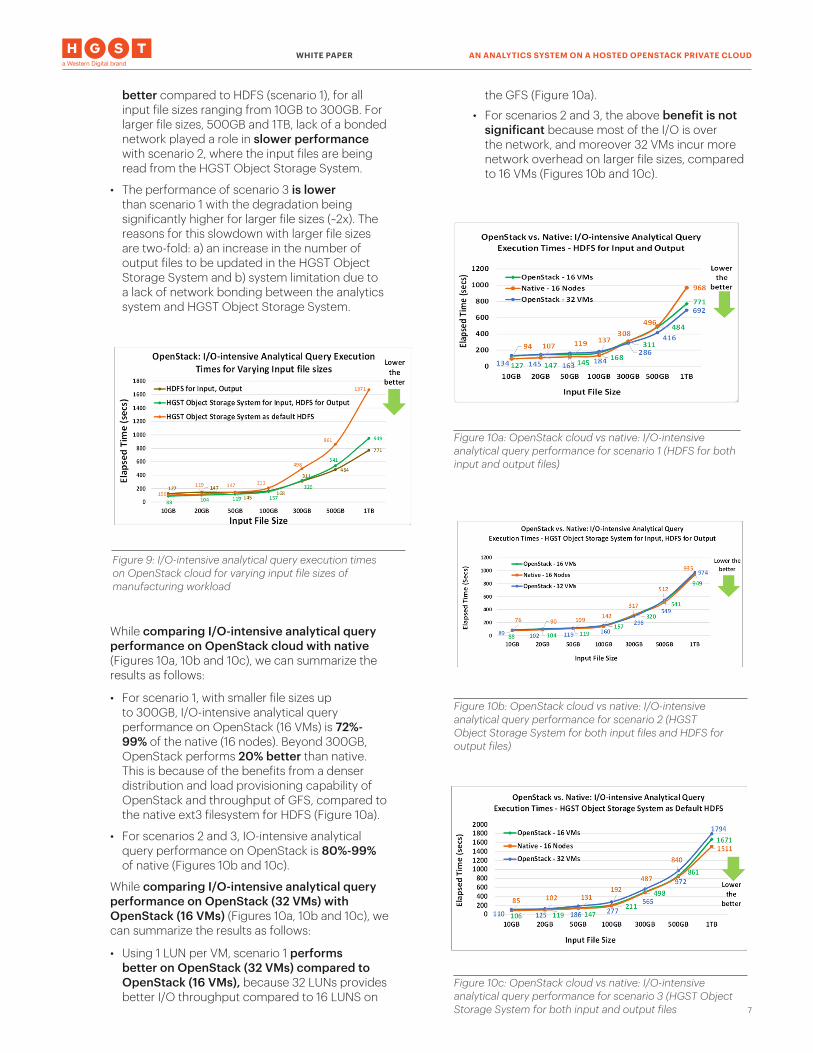
3.2. Performance of I/O-intensive Analytical QueryFor I/O-intensive analytical query on OpenStack cloud (Figure 9):
• The performance of scenario 2 is similar or
Figure 8a: OpenStack cloud vs native: compute-intensive analytical query performance for scenario 1 (HDFS for both input and output files)
Figure 7: Compute-intensive analytical query execution times on OpenStack cloud for varying input file sizes of manufacturing workload
Figure 8b: OpenStack cloud vs native: compute-intensive analytical query performance for scenario 2 (HGST Object Storage System for input files and HDFS for output files)
Figure 8c: OpenStack cloud vs native: compute-intensive analytical query performance for scenario 3 (HGST Object Storage System for both input and output files)
7
WHITE PAPER AN ANALYTICS SYSTEM ON A HOSTED OPENSTACK PRIVATE CLOUD
better compared to HDFS (scenario 1), for all input file sizes ranging from 10GB to 300GB. For larger file sizes, 500GB and 1TB, lack of a bonded network played a role in slower performance with scenario 2, where the input files are being read from the HGST Object Storage System.
• The performance of scenario 3 is lower than scenario 1 with the degradation being significantly higher for larger file sizes (~2x). The reasons for this slowdown with larger file sizes are two-fold: a) an increase in the number of output files to be updated in the HGST Object Storage System and b) system limitation due to a lack of network bonding between the analytics system and HGST Object Storage System.
While comparing I/O-intensive analytical query performance on OpenStack cloud with native (Figures 10a, 10b and 10c), we can summarize the results as follows:
• For scenario 1, with smaller file sizes up to 300GB, I/O-intensive analytical query performance on OpenStack (16 VMs) is 72%-99% of the native (16 nodes). Beyond 300GB, OpenStack performs 20% better than native. This is because of the benefits from a denser distribution and load provisioning capability of OpenStack and throughput of GFS, compared to the native ext3 filesystem for HDFS (Figure 10a).
• For scenarios 2 and 3, IO-intensive analytical query performance on OpenStack is 80%-99% of native (Figures 10b and 10c).
While comparing I/O-intensive analytical query performance on OpenStack (32 VMs) with OpenStack (16 VMs) (Figures 10a, 10b and 10c), we can summarize the results as follows:
• Using 1 LUN per VM, scenario 1 performs better on OpenStack (32 VMs) compared to OpenStack (16 VMs), because 32 LUNs provides better I/O throughput compared to 16 LUNS on
the GFS (Figure 10a).
• For scenarios 2 and 3, the above benefit is not significant because most of the I/O is over the network, and moreover 32 VMs incur more network overhead on larger file sizes, compared to 16 VMs (Figures 10b and 10c).
Figure 9: I/O-intensive analytical query execution times on OpenStack cloud for varying input file sizes of manufacturing workload
Figure 10a: OpenStack cloud vs native: I/O-intensive analytical query performance for scenario 1 (HDFS for both input and output files)
Figure 10b: OpenStack cloud vs native: I/O-intensive analytical query performance for scenario 2 (HGST Object Storage System for both input files and HDFS for output files)
Figure 10c: OpenStack cloud vs native: I/O-intensive analytical query performance for scenario 3 (HGST Object Storage System for both input and output files

AN ANALYTICS SYSTEM ON A HOSTED OPENSTACK PRIVATE CLOUD
8
WHITE PAPER
3.3. Performance of Mixed Analytical Query This section summarizes the performance results for an analytical query executing mixed compute and I/O operations (Figure 11) on OpenStack cloud, native and public cloud.
Considering the daily average binary data with an input file size of 50GB* for 13 products from 4 manufacturing sites:
• Analytical query on HGST analytics system on OpenStack is ~14-15x faster when getting daily defect patterns for scenario 1, compared to the public cloud (projected from reported data). The public cloud projection is calculated for a best case scenario. The worst case scenario is reported to be ~24-48 hrs.
• Analytical query to get daily defect patterns for scenarios 2 and 3 on OpenStack and native is pretty much similar in performance, compared to scenario 1.
• Analytical query performance on OpenStack is 84-90% of native.
• The price/performance benefits of scenarios 2 and 3 over scenario 1 is a driving factor for customers while making purchase decisions because they don’t need to maintain a large static Hadoop cluster, but can leverage HGST Object Storage System, instead.
* Out of 500GB-600GB data ingested per day to the Big Data platform on the public cloud, 50GB is the size of average daily binary data which is being used by the analytical query.
3.4. Summary of Performance ResultsA prototype of an analytics system within a hosted OpenStack private cloud has been implemented for manufacturing.
It has Amazon™ Elastic MapReduce-like (EMR-like)-capabilities of dynamic cluster provisioning, with all data stored within an externally located HGST Object Storage System. This yields efficient resource utilization for a desirable ROI. The solution provides a performance improvement of ~14-15x over a public cloud through process optimizations, for analyzing defect patterns of products from all MFG sites, at 1/4th of the TCO.
The query performance within OpenStack is 80-99% of native, depending on the scenario.
Table 2 summarizes a case study demonstrating the performance of compute-intensive and I/O-intensive workloads with varying input file sizes, within an OpenStack cloud.
The three scenarios used for the case study are as follows:
Scenario 1: HDFS for input and output filesScenario 2: HGST Object Storage System for Input files and HDFS for Output files
Scenario 3: HGST Object Storage System is used as the default HDFS
Please refer to the Appendix for a list of parameters within an OpenStack cloud that has been tuned for the manufacturing workload to get the best possible results.
4. Total Cost of Ownership This section compares the Total Cost of Ownership (TCO) for hosting a manufacturing production Big Data analytics platform on a public cloud with the TCO for the HGST analytics system hosted on an OpenStack private cloud.
Calculations include the operational costs to host the HGST analytics solution in a data center and the depreciation cost of the hardware over 5 years. The cost of the production environment in the public cloud is based on typical/reported pricing for a similar configuration described in Section 2, which has details about the HGST-Hosted
Figure 11: HGST analytics system on OpenStack cloud running a mixed compute and I/O workload from manufacturing, for a fixed input file size
Analytical Query Execution Times for Detecting WD Device Daily Defect Patterns
Elap
sed
Tim
e (s
ecs) 4500
262 306 260 311 316284
Lower thebetter
10000
1000
100
10
1Public Cloud
Solution(Reported)
HGST Analytics Solution:HDFS for both Input
and Output Files(Scenario 1)
HGST Analytics Solution:
HGST Object Storage System for
Input and HDFS for Output Files
(Scenario 2)
HGST Analytics Solution:
HGST Object Storage System as a default HDFS for both Input
and Output Files(Scenario 3)
Native - 16 Nodes OpenStack - 16 Nodes Public Cloud
Table 2: Performance of compute-intensive and I/O-intensive workloads for varied input file sizes within OpenStack cloud: scenario 2 vs. scenario 1 and scenario 3 vs. scenario 1
Input File size (considering 3.5GB/s as network bandwidth, 768 vcpus, 1 mapper/vcpu)
Similar Similar or 13% lower
OpenStack:Performance of HGST Object Storage System as an external storage for input files (Scenario 2) VS. HDFS (Scenario 1)
Performance of HGST Object Storage System as a default HDFS (Scenario 3) VS. HDFS (Scenario 1)
Workload Type
I/O-intensive analytical workloads
Similar or Better (30%) Similar (for 10-20 output file up
I/O-intensive analytical workloads
Similar or lower (10-20%)at 500 GB and 1 TB input file sizes
Lower at a 50% minimum (may not matter for public cloud customers, when considering price/performance benefit for not having to maintain a large static Hadoop cluster)
Compute-intensive analytical workloads
Compute-intensive analytical workloads
Similar or lower (5%) Similar (for 10-20 output file updates)
Lower (30%) (for a larger number of output file updates)
< 300GB
>= 300GB
9
WHITE PAPER
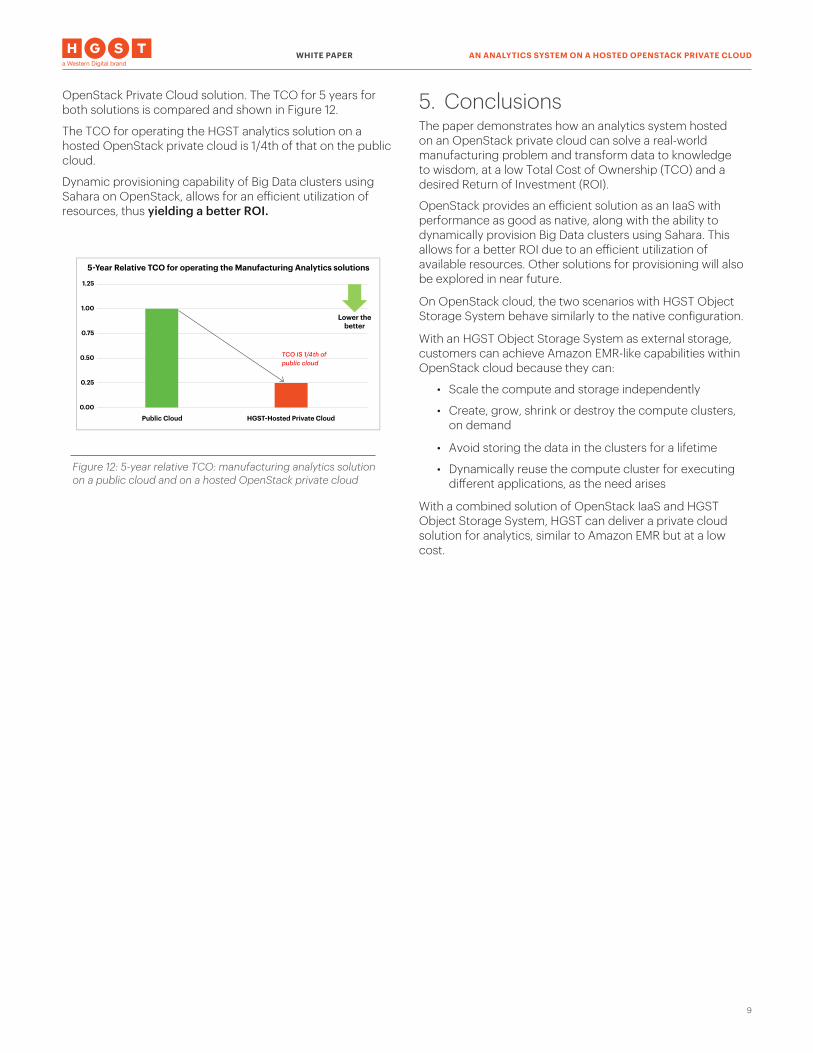
OpenStack Private Cloud solution. The TCO for 5 years for both solutions is compared and shown in Figure 12.
The TCO for operating the HGST analytics solution on a hosted OpenStack private cloud is 1/4th of that on the public cloud.
Dynamic provisioning capability of Big Data clusters using Sahara on OpenStack, allows for an efficient utilization of resources, thus yielding a better ROI.
5. ConclusionsThe paper demonstrates how an analytics system hosted on an OpenStack private cloud can solve a real-world manufacturing problem and transform data to knowledge to wisdom, at a low Total Cost of Ownership (TCO) and a desired Return of Investment (ROI).
OpenStack provides an efficient solution as an IaaS with performance as good as native, along with the ability to dynamically provision Big Data clusters using Sahara. This allows for a better ROI due to an efficient utilization of available resources. Other solutions for provisioning will also be explored in near future.
On OpenStack cloud, the two scenarios with HGST Object Storage System behave similarly to the native configuration.
With an HGST Object Storage System as external storage, customers can achieve Amazon EMR-like capabilities within OpenStack cloud because they can:
• Scale the compute and storage independently
• Create, grow, shrink or destroy the compute clusters, on demand
• Avoid storing the data in the clusters for a lifetime
• Dynamically reuse the compute cluster for executing different applications, as the need arises
With a combined solution of OpenStack IaaS and HGST Object Storage System, HGST can deliver a private cloud solution for analytics, similar to Amazon EMR but at a low cost.
AN ANALYTICS SYSTEM ON A HOSTED OPENSTACK PRIVATE CLOUD
Figure 12: 5-year relative TCO: manufacturing analytics solution on a public cloud and on a hosted OpenStack private cloud
5-Year Relative TCO for operating the Manufacturing Analytics solutions
1.25
1.00
0.75
0.50
0.25
0.00
TCO IS 1/4th ofpublic cloud
Public Cloud HGST-Hosted Private Cloud
Lower thebetter

10
WHITE PAPER AN ANALYTICS SYSTEM ON A HOSTED OPENSTACK PRIVATE CLOUD
Appendix1. Tunables for HGST Object Storage System Load
Balancer for OpenStack
1.1. HAProxy Load Balancer Tuning:
- Load balancer ‘haproxy’ is configured from single thread to multi-threaded, assigned threads to be equal to the number of vcpus.
- Dedicated server is assigned to the Load balancer.
- Each load balancer thread affinities to a physical core.
- Timeout for client and server is increased to 3minutes
- Max connections increased to 8000 for front end
1.2. Edited or Added the following parameters in haproxy.cfg file (for a server with 24 vcpus)
maxconn 8000nbproc 23cpu-map 1 1cpu-map 2 2cpu-map 3 3cpu-map 4 4cpu-map 5 5cpu-map 6 6cpu-map 7 7cpu-map 8 8cpu-map 9 9cpu-map 10 10cpu-map 11 11cpu-map 12 12cpu-map 13 13cpu-map 14 14cpu-map 15 15cpu-map 16 16cpu-map 17 17cpu-map 18 18cpu-map 19 19cpu-map 20 20cpu-map 21 21cpu-map 22 22
defaults timeout client 6m timeout server 3m
front-end maxconn 8000 timeout client 3m bind-process 1 2 3 4 5 6 7 8 9 10 11
2. S3A parameters in core-site.xml for OpenStack
2.1. The following parameters are added for S3A connector in core-site.xml:
property> <name>fs.s3a.impl</name>
<value>org.apache.hadoop.fs.s3a.S3AFileSystem</value>
</property><property> <name>fs.AbstractFileSystem.s3a.impl</name> <value>org.apache.hadoop.fs.s3a.S3A</value></property><property> <name>fs.s3a.connection.maximum</name> <value>100</value></property><property> <name>fs.s3a.connection.ssl.enabled</name> <value>false</value></property><property> <name>fs.s3a.endpoint</name> <value>s3.hgst.com</value></property><property> <name>fs.s3a.proxy.host</name> <value>192.168.1.72</value></property><property> <name>fs.s3a.proxy.port</name> <value>9007</value></property><property><name>fs.s3a.block.size</name> <value>67108864</value> <!-- 64MB --></property><property> <name>fs.s3a.attempts.maximum</name> <value>10</value> </property><property> <name>fs.s3a.connection.establish.timeout</name> <value>500000</value></property><property> <name>fs.s3a.connection.timeout</name> <value>500000</value></property><property> <name>fs.s3a.paging.maximum</name> <value>1000</value></property><property> <name>fs.s3a.threads.max</name> <value>4</value></property><property> <name>fs.s3a.threads.keepalivetime</name> <value>60</value></property><property>

AN ANALYTICS SYSTEM ON A HOSTED OPENSTACK PRIVATE CLOUD
11
<name>fs.s3a.max.total.tasks</name> <value>2</value></property><property> <name>fs.s3a.multipart.size</name> <value>67108864</value> <!-- 64MB --></property><property> <name>fs.s3a.multipart.threshold</name> <value>67108864</value> <!-- 64MB * 6 --></property><property> <name>fs.s3a.multipart.purge</name> <value>true</value></property><property> <name>fs.s3a.multipart.purge.age</name> <value>86400</value> <!-- 24h --></property><property> <name>fs.s3a.buffer.dir</name> <value>${hadoop.tmp.dir}/s3a</value></property><property> <name>fs.s3a.fast.upload</name> <value>true</value></property><property> <name>fs.s3a.fast.buffer.size</name><value>4194304</value> </property><property> <name>fs.s3a.signing-algorithm</name> <value>S3SignerType</value></property>
3. Operating System Kernel Parameters for OpenStack
3.1. The following entries are added to /etc/sysctl.conf
net.core.rmem_max = 33554432
net.core.wmem_max = 33554432 net.ipv4.tcp_rmem = 4096 87380 33554432net.ipv4.tcp_wmem = 4096 65536 33554432 net.ipv4.tcp_window_scaling=1net.ipv4.tcp_timestamps=1net.ipv4.tcp_sack=1 net.ipv4.tcp_tw_reuse=1net.ipv4.tcp_keepalive_intvl=30net.ipv4.tcp_fin_timeout=30net.ipv4.tcp_keepalive_probes=5net.ipv4.tcp_no_metrics_save=1net.core.netdev_max_backlog=30000net.ipv4.route.flush=1 fs.file-nr = 197600 0 3624009fs.file-max=10000000 net.ipv4.tcp_max_syn_backlog=16384net.ipv4.tcp_synack_retries=1net.ipv4.tcp_max_orphans=400000
3.2.The following entries are added to /etc/security/limits.conf file
* soft nofile 100000* hard nofile 100000
© 2017 Western Digital Corporation or its affiliates. All rights reserved. Western Digital and the HGST logo are registered trademarks or trademarks of Western Digital Corporation or its affiliates in the US and/or other countries. Amazon, AWS, and Amazon S3 are trademarks of Amazon.com, Inc. or its affiliates. Apache®, Apache Hadoop, Apache Hive, and Hadoop® are either registered trademarks or trademarks of the Apache Software Foundation in the United States and/or other countries. No endorsement by The Apache Software Foundation is implied by the use of these marks. The OpenStack™ Word Mark is either a registered trademarks/service marks or trademarks/service mark of the OpenStack Foundation, in the United States and other countries and is used with the OpenStack Foundation’s permission. All other marks are the property of their respective owners. This paper may contain forward-looking statements, including statements relating to expectations for cloud computing models, the market for our products, product development efforts, and the capacities, capabilities and applications of our products. These forward-looking statements are subject to risks and uncertainties that could cause actual results to differ materially from those expressed in the forward-looking statements, including development challenges or delays, supply chain and logistics issues, changes in markets, demand, global economic conditions and other risks and uncertainties listed in Western Digital Corporation’s most recent quarterly and annual reports filed with the Securities and Exchange Commission, to which your attention is directed. Readers are cautioned not to place undue reliance on these forward-looking statements and we undertake no obligation to update these forward-looking statements to reflect subsequent events or circumstances.
WHITE PAPER
11
WHITE PAPER
WP33-EN-US-0517-01

















