19
AN EFFICIENT APPROACH FOR ILLUSTRATING WEB DATA OF USER SEARCH RESULTS
| Date post: | 18-Jul-2015 |
| Category: |
Engineering |
| Upload: | neha-singh |
| View: | 52 times |
| Download: | 1 times |

AN EFFICIENT APPROACHFOR ILLUSTRATING
WEB DATA OF USER SEARCH RESULTS

INPUT URL
WRAPPER GENERATION
DATA EXTRACTION
SEARCH ENGINE
EXTRACTOR
SEARCH RESULT RECORD
CONTENT LINE
EXTRACTION
DATA ALIGNMENT
ANNOTATORS
LINE SEPARATOR
BLOCK EXTRACTION
ANNOTATION WRAPPER
ANNOTATED GROUPS
COMBINING ANNOTATORS
NEW RESULT PAGE

GOOGLE SEARCH CONTENT LINE
•LINK•TEXT•LINK-TEXT•LINK-HEAD•TEXT-HEAD•LINK-TEXT-HEAD•HR LINE• BLANK LINE

GOOGLE SEARCH BLOCKS
To identify similar blocks we check for block similarity onbasis of-
•TYPE distance•SHAPE distance•POSITION distance

Candidate Content Line Separators
•blank line (e.g., the <p> tag) •visual line (e.g. the <HR> tag).
(1) the line following an HR-LINE(2) if there is only one line starting with a number in a block,this line is a first line;(3) if only one line in a block has the smallest position code ,this line is a first line(4) if there is only one BLANK line in a block, the linefollowing the BLANK line is the first line.
Fist line of block
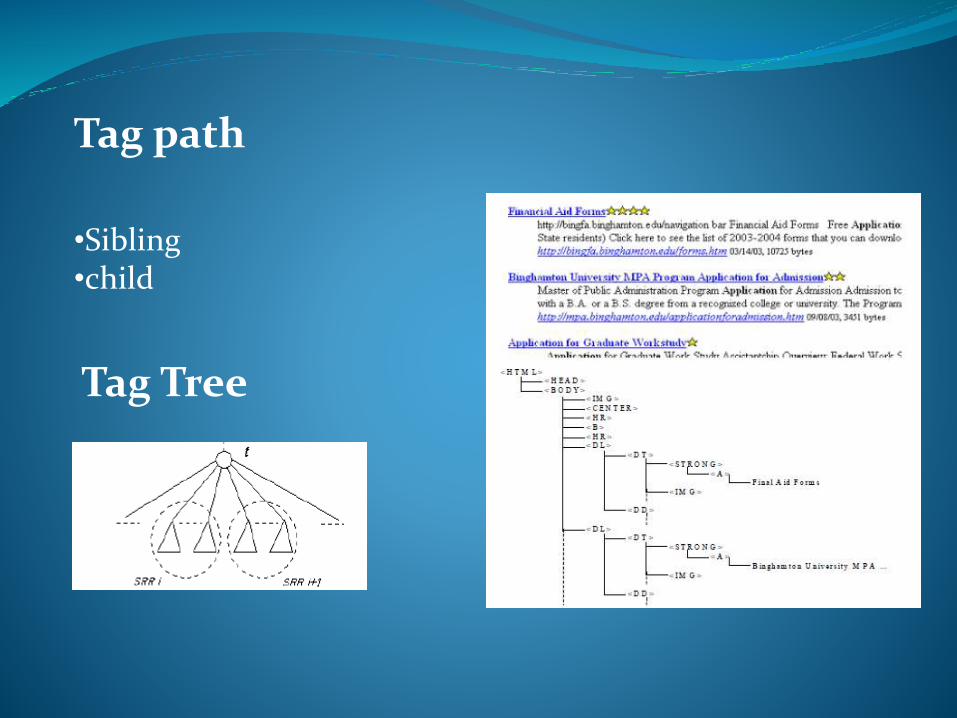
Tag path
•Sibling•child
Tag Tree

Wrapper Integration

Relationships between data unit (U) and text node (T):
•One-to-One RelationshipT=U
•One-to-Many RelationshipT )U
•Many-to-One RelationshipT (U
•One-To-Nothing RelationshipT!=U

Five common features shared by the data units
•Tag Path (TP)•Data Content (DC)•Data Type (DT)•Adjacency (AD)•Presentation Style (PS)

Alignment Algorithm
Here we will apply our data alignment algorithm to align the semantically same data in a group

After Alignment Algorithm
Same semantic data are aligned in a column as shown in fig.

Output

Annotators
• Table annotator• Query-based annotator• Schema value annotator• Frequency-based annotator• Same-prefix annotator• Common knowledge based annotator:

Let P(L) be the probability that L is correct in identifying a correctlabel for a group of data units when L isapplicable. P(L) is essentially the successrate of L. Specifically, suppose L is applicableto N cases and among these cases M areannotated correctly, then P(L)=M/N
Probability

Labelling
Suitable annotator is applied and then label the data

Annotation Wrapper
attribute= <label; prefix; suffix; separators; unit index>.
•comparing all the suffixes
•compare the prefixes of all the data units

New Result Page
This is a new result page with less no. of result record but all the result data will be annotated and efficient.

Tools
Jsoup is a Java library for working with real-world HTML. It provides a very convenient API for extracting and manipulating data, using the best of DOM, CSS, and jquery-like methods.
•Other Tools:•Webharvest•Htmlunit

[1] H. Zhao, W. Meng, Z. Wu, V. Raghavan, and C. Yu, “FullyAutomatic Wrapper Generation for Search Engines,” Proc. Int’l Conf. World Wide Web (WWW), 2005.
[2] Y. Zhai and B. Liu, “Web Data Extraction Based on Partial Tree Alignment,” Proc. 14th Int’l Conf. World Wide Web (WWW ’05),2005.
[3] Y. Lu, H. He, H. Zhao, W. Meng, and C. Yu, “Annotating Structured Data of the Deep Web,” Proc. IEEE 23rd Int’l Conf. Data Eng. (ICDE), 2007
[4] J. Wang and F.H. Lochovsky, “Data Extraction and Label Assignment for Web Databases,” Proc. 12th Int’l Conf. World Wide Web (WWW), 2003.
[5] Yiyao Lu, Hai He, Hongkun Zhao, Weiyi Meng, “Annotating Search Results from Web Database”, IEEE, 2014
References

















