20
AN IMPROVED INDEXING SCHEME FOR RANGE QUERIES Yvonne Yao Adviser: Professor Huiping Guo
| Date post: | 31-Dec-2015 |
| Category: |
Documents |
| Upload: | fletcher-oneill |
| View: | 35 times |
| Download: | 4 times |

AN IMPROVED INDEXING SCHEME FOR RANGE QUERIES
Yvonne Yao
Adviser: Professor Huiping Guo

DATABASE-AS-A-SERVICE
Business organizations handle a large amount of data (TB)
Cost of managing and maintaining these data onsite is high
DAS DBMSs outsourcing Clients rely on service providers for data
management and maintenance Cost is a lot lowered. But…

DATABASE-AS-A-SERVICE
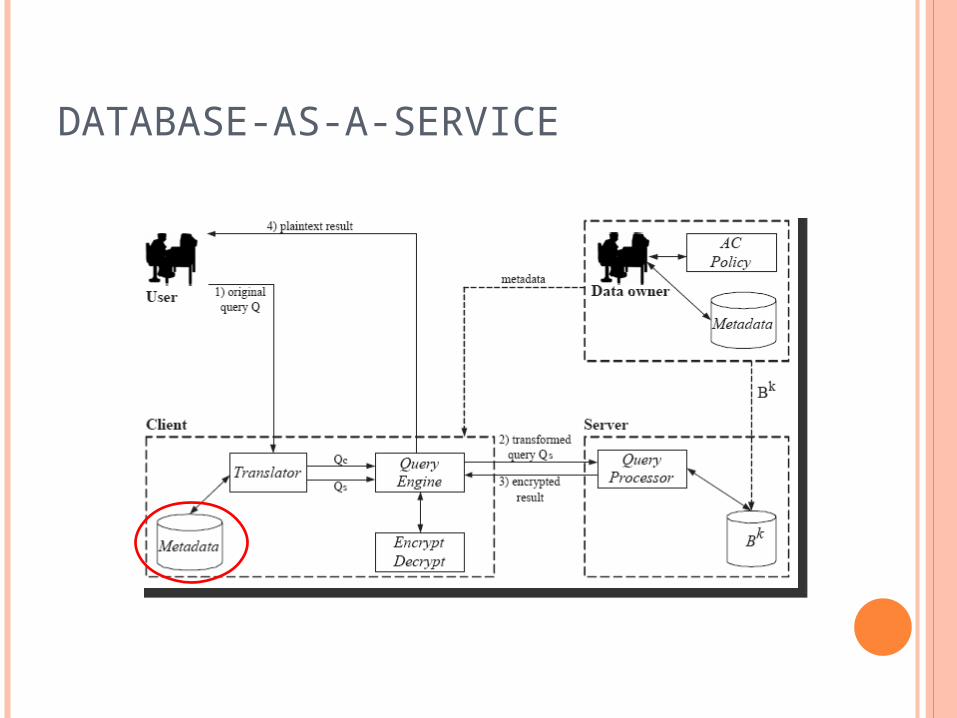
Security of data is not guaranteed Service providers are untrusted Store only an encrypted form of data onto the
remote server Only users with the correct key(s) can have
access How then can we query the encrypted data?
Retrieve and decrypt the entire table, and apply SQL statements on it. Too expensive!
A more realistic approach was discovered
DATABASE-AS-A-SERVICE

BUCKETIZATION
Various approaches to build meta-data: B+-tree based, hash-based, and bucket-based
What is bucketization? Partition of attribute data into several buckets Each bucket is identified by an ID Bucket IDs are stored, along with encrypted data,
on the remote server Client keeps partition information as meta-data
General bucketization approach Equi-width Equi-depth
EXAMPLE 1

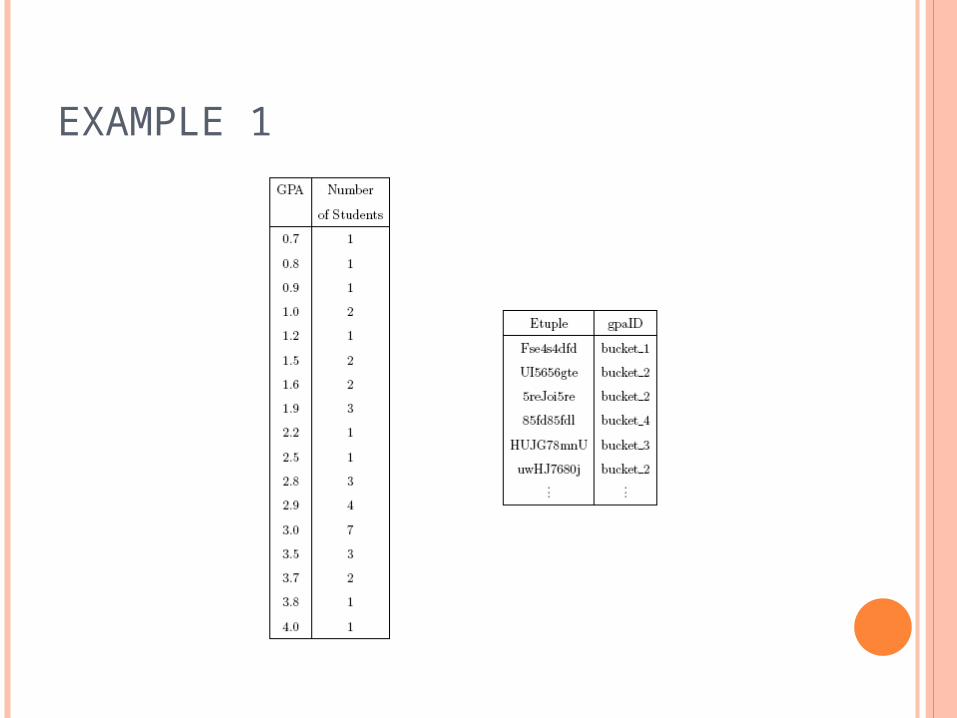
EXAMPLE 1
Partition ID
[0.0 ~ 1.0] Bucket_1
[1.1 ~ 2.0] Bucket_2
[2.1 ~ 3.0] Bucket_3
[3.1 ~ 4.0] Bucket_4

EXAMPLE 1 User query:
SELECT *
FROM grades
WHERE gpa < 3.0 Qserver:
SELECT *
FROM egrades
WHERE gpaID = ‘Bucket_1’ OR
gpaID = ‘Bucket_2’ OR
gpaID = ‘Bucket_3’
Size of superset is 29, of which 7 of them are false positives

QUERY OPTIMAL BUCKETIZATION
General idea: minimizing the bucket cost of each bucket
Input: <D = (V, F), M> V = {v1, v2, v3, …, vn} where v1 < v2 < v3 < … <vn
F = Frequency of each value M = Number of buckets to fill
Output: a matrix indicating the boundary of each bucket

QUERY OPTIMAL BUCKETIZATION
QOB Finds optimum solutions to two smaller sub-
problems one contains the leftmost M-1 buckets covering
the (n-i) smallest points Another contains the rightmost single bucket
covering the remaining i points
V = {v1, v2, v3, v4, v5, v6, …, vn-3, vn-2, vn-1, vn}
n-i points go to last i points go to
M-1 buckets last bucket

EXAMPLE 2
Partition ID
[0.7 ~ 1.2] Bucket_1
[1.5 ~ 2.5] Bucket_2
[2.8 ~ 3.0] Bucket_3
[3.5 ~ 4.0] Bucket_4

EXAMPLE 2
Qserver:
SELECT *
FROM egrades
WHERE gpaID = ‘Bucket_1’ OR
gpaID = ‘Bucket_2’ OR
gpaID = ‘Bucket_3’
Same as the general bucketization method In most cases, QOB can outperform the
conventional bucketization strategy, but not always

DEVIATION BUCKETIZATION
Built upon QOB, takes the same parameters Has two levels of buckets
First level: same as those produced by QOB Second level: bucketization of deviation values,
the difference between the value itself to the average of the bucket
Each first-level-bucket has at most M second level buckets
QOB has at most M buckets, while DB has at most M2 buckets

DEVIATION BUCKETIZATION
DB Run QOB (D, M) Construct First-Level-Buckets from boundary
matrix For each First-Level-Bucket
Initialize empty datasets vi’ and fi’
For each vi in the bucket vi’ = vi’ ∪ vi’ – avg()
fi’ = fi’ ∪ 1
Create a new dataset di = (vi’, fi’)Run QOB(di, M)
EXAMPLE 3
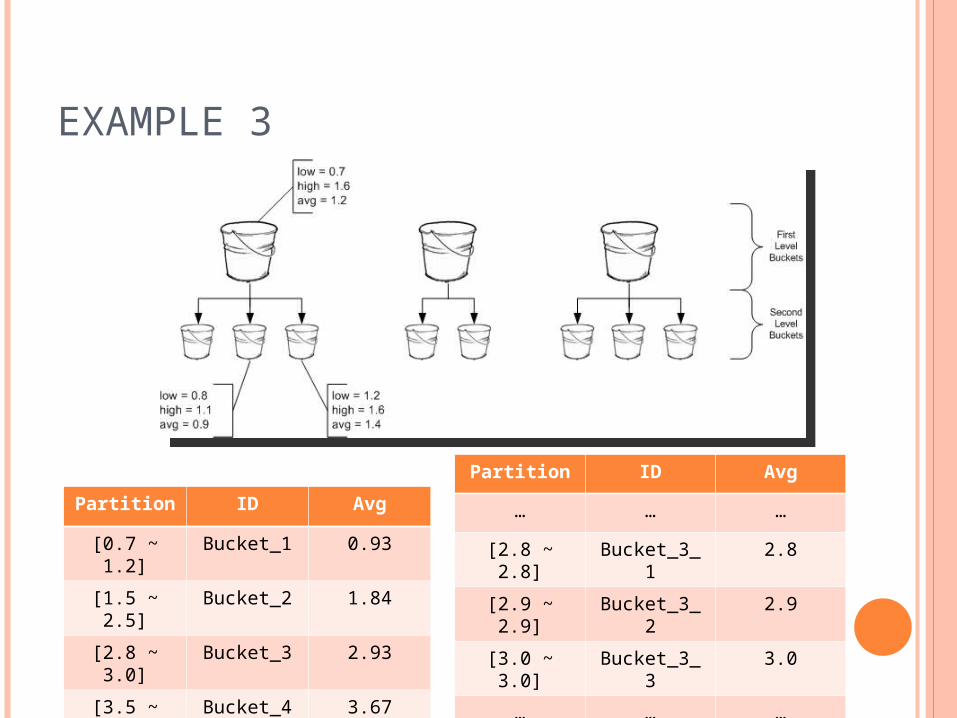
Partition ID Avg
[0.7 ~ 1.2] Bucket_1 0.93
[1.5 ~ 2.5] Bucket_2 1.84
[2.8 ~ 3.0] Bucket_3 2.93
[3.5 ~ 4.0] Bucket_4 3.67
Partition ID Avg
… … …
[2.8 ~ 2.8] Bucket_3_1 2.8
[2.9 ~ 2.9] Bucket_3_2 2.9
[3.0 ~ 3.0] Bucket_3_3 3.0
… … …

EXAMPLE 3
Qserver:
SELECT *
FROM egrades
WHERE gpaID = ‘Bucket_1’ OR
gpaID = ‘Bucket_2’ OR
gpaID = ‘Bucket_3_1’ OR
gpaID = ‘Bucket_3_2’
In this case, no false positives are returned Generally, false positives will still be returned,
just the number of them will be greatly reduced

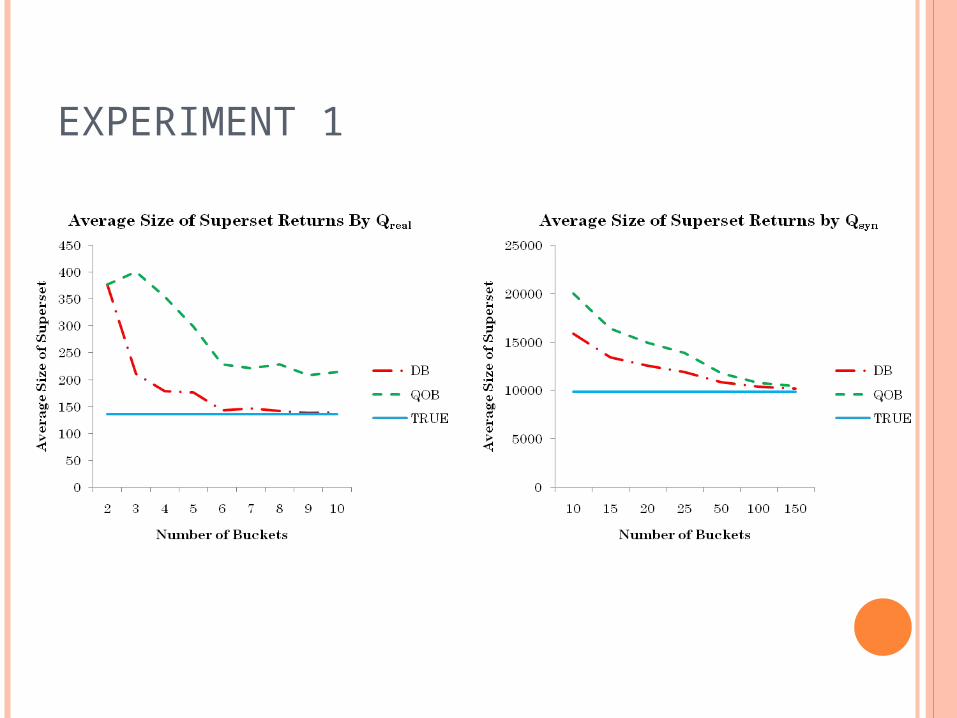
EXPERIMENTS
Two datasets Synthetic dataset: 105 integers from [0, 999] Real dataset: 103 data points from the Aspect
column of the Forest CoverType database in UCI’s KDD Archive
Two sets of queries Qsyn
Qreal
EXPERIMENT 1
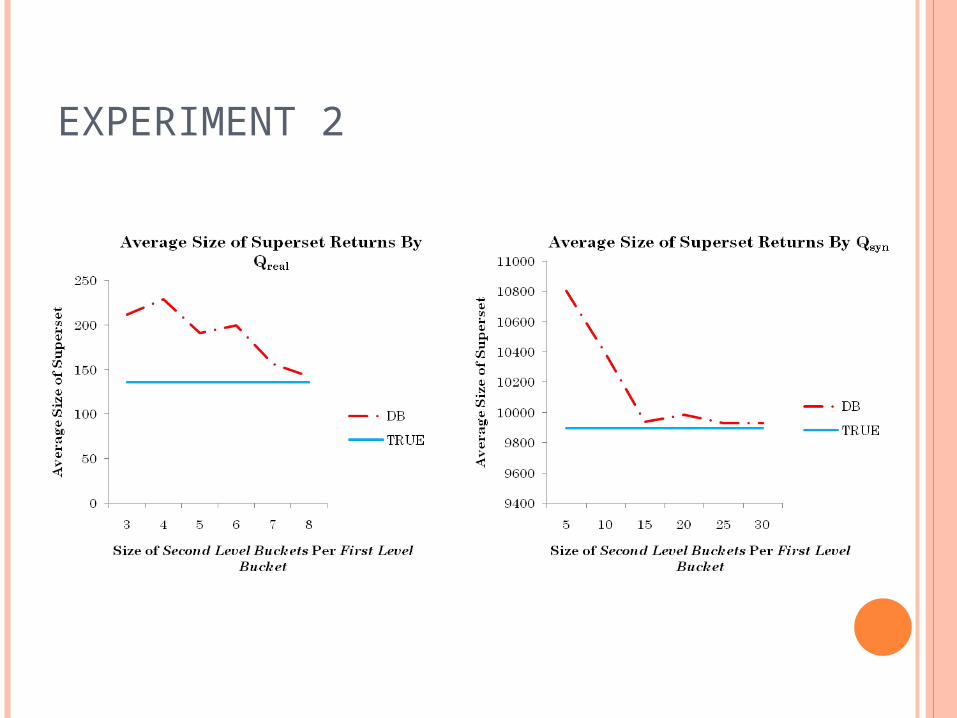
EXPERIMENT 2

Thank You

















