An XMT/MTGL Case Study: PageRank. Jonathan Berry Scalable Algorithms Department Sandia National Laboratories July 23, 2008. Informatics Datasets Are Different. Informatics : The analysis of datasets arising from “information” sources such as the WWW (not physical simulation) - PowerPoint PPT Presentation
Sandia is a multiprogram laboratory operated by Sandia Corporation, a Lockheed Martin Company, for the United States Department of Energy’s National Nuclear Security Administration under contract DE-AC04-94AL85000. An XMT/MTGL Case Study: PageRank Jonathan Berry Scalable Algorithms Department Sandia National Laboratories July 23, 2008
Transcript
Sandia is a multiprogram laboratory operated by Sandia Corporation, a Lockheed Martin Company,for the United States Department of Energy’s National Nuclear Security Administration
under contract DE-AC04-94AL85000.
An XMT/MTGL Case Study: PageRank
Jonathan Berry Scalable Algorithms Department
Sandia National Laboratories
July 23, 2008
Informatics Datasets Are Different
Informatics: The analysis of datasets arising from “information” sources such as the WWW (not physical simulation)Motivating Applications:
• Homeland security• Computer security (DOE emphasis)• Biological networks, etc.
Primary HPC Implication: Any partitioning is “bad”Primary HPC Implication: Any partitioning is “bad”
“One of the interesting ramifications of the fact that the PageRank calculation converges rapidly is that the web is an expander-like graph”
Page, Brin, Motwani,Winograd 1999
From UCSD ‘08
Broder, et al. ‘00
We Are Developing The MultiThreaded Graph Library
• Enables multithreaded graph algorithms• Based upon community standard (Boost Graph Library)
• Abstracts data structures and other application specifics• Hide some shared memory issues• Preserves good multithreaded performance
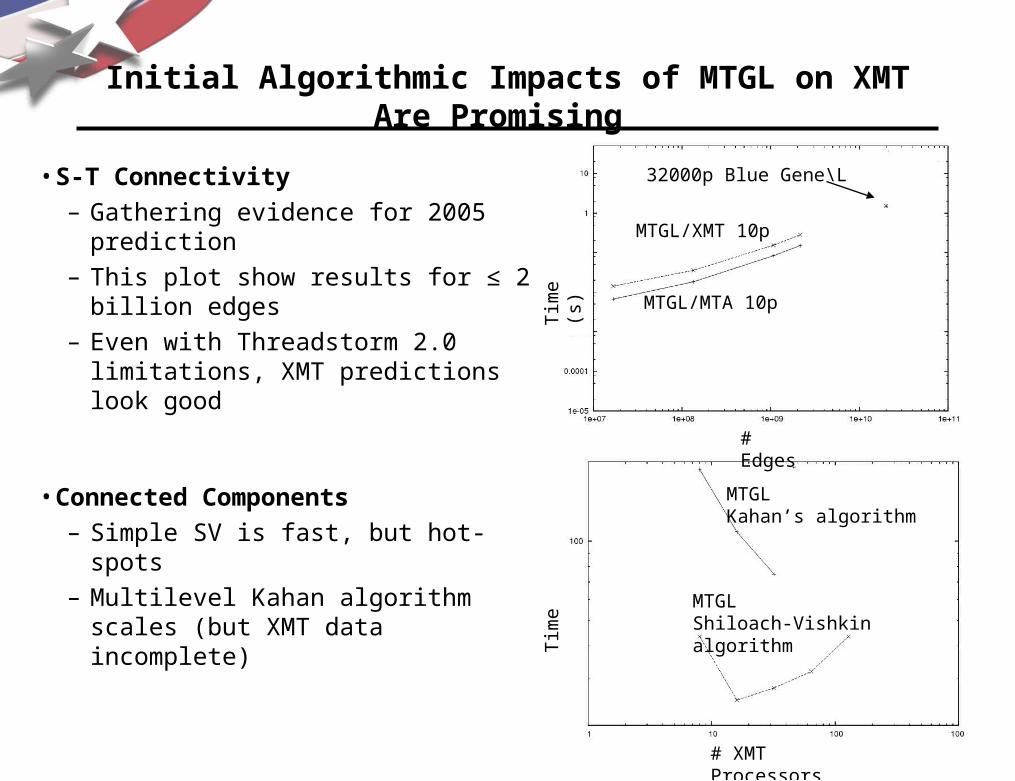
Initial Algorithmic Impacts of MTGL on XMT Are Promising
• S-T Connectivity
– Gathering evidence for 2005 prediction
– This plot show results for ≤ 2 billion edges
– Even with Threadstorm 2.0 limitations, XMT predictions look good
• Connected Components
– Simple SV is fast, but hot-spots
– Multilevel Kahan algorithm scales (but XMT data incomplete)
# XMT Processors
Tim
e (s
)
MTGLShiloach-Vishkin algorithm
32000p Blue Gene\L
MTGL/MTA 10p
Tim
e (s
)
# Edges
MTGLKahan’s algorithm
MTGL/XMT 10p
The “PageRank Derby”
• Ranking of data is a key operation– Which terabytes of some petabytes of data are the most interesting?– Which gigabytes of those terabytes? Etc..
• We have chosen PageRank as a candidate kernel ranking operation (though there are others)
• We wish to understand computational tradeoffs for various architectures and various datasets
– XMT, XT4, Niagara, Netezza, Hadoop, etc.
• We simulate real data with “R-MAT” graphs (Faloutsos, et al.)– No previous results for traditional HPC (distributed memory)– Two of Sandia’s top distributed memory people have gotten some.
“R-MAT” (Recursive MATrix Decomposition)
• Think of dropping a marble through a sequence of plastic trays with holes in them– Pick an initiator with k=pq holes– The i’th level has k^i holes– The marble goes through each hole with
some probability (normalized to 1.0 over all holes)
– The bottom level has N cells (1x1) and is the adjacency matrix
• The probabilities determine the nature of the graph– All equal generates Erdos-Renyi graphs– Unbalanced probabilities can lead to
inverse power-law graphs.
0.57 0.19
0.19 0.05
0.57 0.190.19 0.05
0.57 0.190.19 0.05
0.57 0.190.19 0.05
0.57 0.190.19 0.05
PageRank’s Kernel Operation
• Vertices “vote” by contributing their
current rank to their neighbors (in
proportion)
• For example, supposing that all
current ranks are 1.0:
– u contributes 0.5 to x
– v contributes 0.33.. To x
– w contributes 0.5 to x
• This operation, done over all edges,
dominates the running time of
PageRank
vu w
x
Attempt 1: Go Through The Adjacency Lists
= “bad”
Attempt 2: Go Over The Edges
Attempt 3: Load Balance Via Your Own Threads
= “kind of ok, but not very pleasing”
Attempt 4: Remove The Hot Spots, Auto-Parallelize
Load balanced and no hot spot! Extra memory for in-adjacencies
“CANAL” Output
Load balanced and no hot spot! Extra work to compute parallel prefix for merge


















![PageRank . PageRank . PageRank Googleceit.aut.ac.ir/~meybodi/paper/Forsati-IKT2007.pdf · PageRank PageRank. PageRank Google ([6,7] [8-10] [11] HITS [12] Site Rank 1 Content mining](https://static.documents.pub/doc/80x56/5ad6ca0c7f8b9af9068b6a17/pagerank-pagerank-pagerank-meybodipaperforsati-ikt2007pdfpagerank-pagerank.jpg)














