39
Apache Spark Internals Pietro Michiardi Eurecom Pietro Michiardi (Eurecom) Apache Spark Internals 1 / 80

Apache Spark Internals
Pietro Michiardi
Eurecom
Pietro Michiardi (Eurecom) Apache Spark Internals 1 / 80

Acknowledgments & Sources
SourcesI Research papers:
F https://spark.apache.org/research.htmlI Presentations:
F M. Zaharia, “Introduction to Spark Internals”,https://www.youtube.com/watch?v=49Hr5xZyTEA
F A. Davidson, “A Deeper Understanding of Spark Internals”,https://www.youtube.com/watch?v=dmL0N3qfSc8
I Blogs:F Quang-Nhat Hoang-Xuan, Eurecom, http://hxquangnhat.com/F Khoa Nguyen Trong, Eurecom,
https://trongkhoanguyenblog.wordpress.com/
Pietro Michiardi (Eurecom) Apache Spark Internals 2 / 80

Anatomy of a Spark Application
Anatomy of a SparkApplication
Pietro Michiardi (Eurecom) Apache Spark Internals 13 / 80

Anatomy of a Spark Application
A Very Simple Application Example
1 val sc = new SparkContext("spark://...", "MyJob", home,jars)
2
3 val file = sc.textFile("hdfs://...") // This is an RDD4
5 val errors = file.filter(_.contains("ERROR")) // This isan RDD
6
7 errors.cache()8
9 errors.count() // This is an action
Pietro Michiardi (Eurecom) Apache Spark Internals 14 / 80
Anatomy of a Spark Application
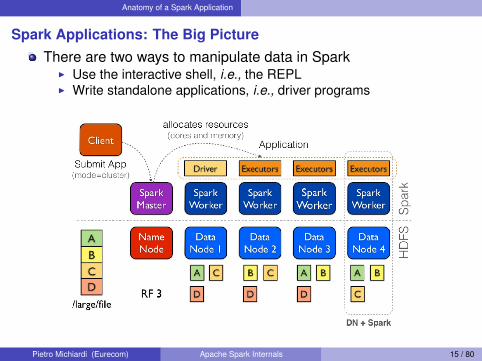
Spark Applications: The Big PictureThere are two ways to manipulate data in Spark
I Use the interactive shell, i.e., the REPLI Write standalone applications, i.e., driver programs
Pietro Michiardi (Eurecom) Apache Spark Internals 15 / 80
Anatomy of a Spark Application
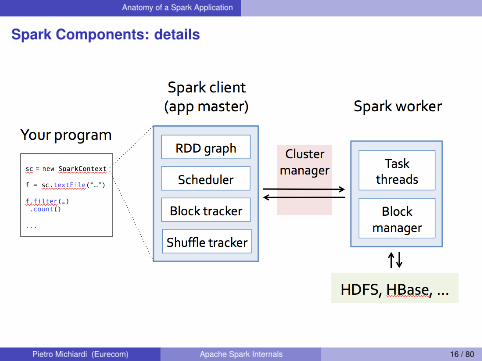
Spark Components: details
Pietro Michiardi (Eurecom) Apache Spark Internals 16 / 80
Anatomy of a Spark Application
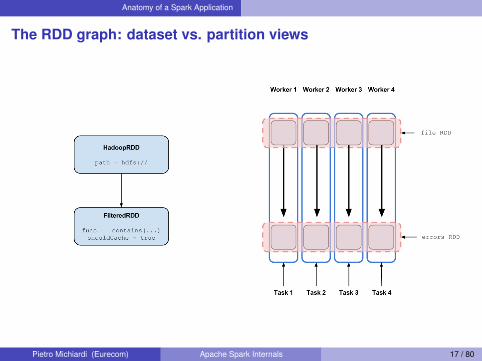
The RDD graph: dataset vs. partition views
Pietro Michiardi (Eurecom) Apache Spark Internals 17 / 80

Anatomy of a Spark Application
Data Locality
Data locality principleI Same as for Hadoop MapReduceI Avoid network I/O, workers should manage local data
Data locality and cachingI First run: data not in cache, so use HadoopRDD’s locality prefs
(from HDFS)I Second run: FilteredRDD is in cache, so use its locationsI If something falls out of cache, go back to HDFS
Pietro Michiardi (Eurecom) Apache Spark Internals 18 / 80
Anatomy of a Spark Application
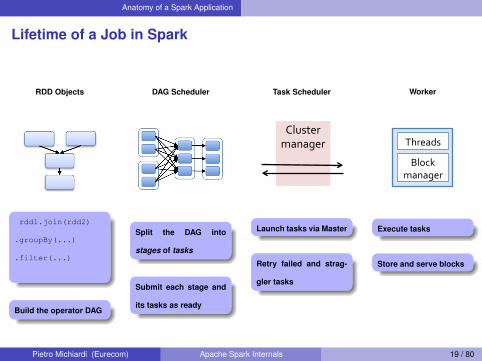
Lifetime of a Job in Spark
RDD Objects
rdd1.join(rdd2)
.groupBy(...)
.filter(...)
Build the operator DAG
DAG Scheduler
Split the DAG into
stages of tasks
Submit each stage and
its tasks as ready
Task Scheduler
Cluster(manager(
Launch tasks via Master
Retry failed and strag-
gler tasks
Worker
Block&manager&
Threads&
Execute tasks
Store and serve blocks
Pietro Michiardi (Eurecom) Apache Spark Internals 19 / 80

Application model for scheduling
Application: Driver code that represents the DAG
Job: Subset of application triggered for execution by an “action” in the DAG
Stage: Job sub-divided into stages that have dependencies with each other
Task: Unit of work in a stage that is scheduled on a worker
http://spark.apache.org/docs/latest/cluster-overview.html

Anatomy of a Spark Application
In Summary
Our example Application: a jar fileI Creates a SparkContext, which is the core component of the
driverI Creates an input RDD, from a file in HDFSI Manipulates the input RDD by applying a filter(f: T =>Boolean) transformation
I Invokes the action count() on the transformed RDDThe DAG Scheduler
I Gets: RDDs, functions to run on each partition and a listener forresults
I Builds Stages of Tasks objects (code + preferred location)I Submits Tasks to the Task Scheduler as readyI Resubmits failed Stages
The Task SchedulerI Launches Tasks on executorsI Relaunches failed TasksI Reports to the DAG Scheduler
Pietro Michiardi (Eurecom) Apache Spark Internals 20 / 80

Spark Deployments
Spark Deployments
Pietro Michiardi (Eurecom) Apache Spark Internals 21 / 80
Spark Deployments
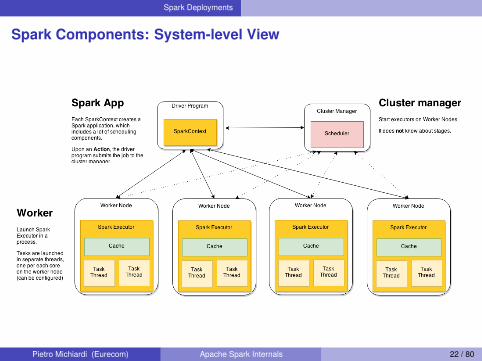
Spark Components: System-level View
Pietro Michiardi (Eurecom) Apache Spark Internals 22 / 80

Spark Deployments
Spark Deployment Modes
The Spark Framework can adopt several cluster managersI Local ModeI Standalone modeI Apache MesosI Hadoop YARN
General “workflow”I Spark application creates SparkContext, which initializes theDriverProgram
I Registers to the ClusterManagerI Ask resources to allocate ExecutorsI Schedule Task execution
Pietro Michiardi (Eurecom) Apache Spark Internals 23 / 80
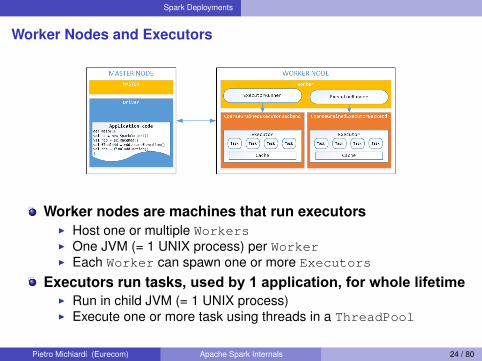
Spark Deployments
Worker Nodes and Executors
Worker nodes are machines that run executorsI Host one or multiple WorkersI One JVM (= 1 UNIX process) per WorkerI Each Worker can spawn one or more Executors
Executors run tasks, used by 1 application, for whole lifetimeI Run in child JVM (= 1 UNIX process)I Execute one or more task using threads in a ThreadPool
Pietro Michiardi (Eurecom) Apache Spark Internals 24 / 80

Spark Deployments
Comparison to Hadoop MapReduce
Hadoop MapReduceOne Task per UNIX process(JVM), more if JVM reuseMultiThreadedMapper,advanced feature to havethreads in Map Tasks
→ Short-lived Executor, with onelarge Task
SparkTasks run in one or moreThreads, within a single UNIXprocess (JVM)Executor process staticallyallocated to worker, even withno threads
→ Long-lived Executor, withmany small Tasks
Pietro Michiardi (Eurecom) Apache Spark Internals 25 / 80

Spark Deployments
Benefits of the Spark Architecture
IsolationI Applications are completely isolatedI Task scheduling per application
Low-overheadI Task setup cost is that of spawning a thread, not a processI 10-100 times fasterI Small tasks→ mitigate effects of data skew
Sharing dataI Applications cannot share data in memory nativelyI Use an external storage service like Tachyon
Resource allocationI Static process provisioning for executors, even without active tasksI Dynamic provisioning under development
Pietro Michiardi (Eurecom) Apache Spark Internals 26 / 80
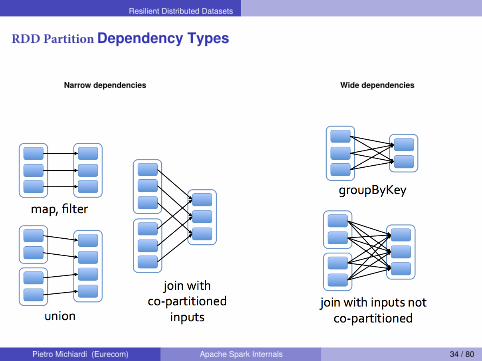
Resilient Distributed Datasets
RDD Partition Dependency Types
Narrow dependencies Wide dependencies
Pietro Michiardi (Eurecom) Apache Spark Internals 34 / 80

Resilient Distributed Datasets
Dependency Types (2)
Narrow dependenciesI Each partition of the parent RDD is used by at most one partition of
the child RDDI Task can be executed locally and we don’t have to shuffle. (Eg:map, flatMap, filter, sample)
Wide DependenciesI Multiple child partitions may depend on one partition of the parent
RDDI This means we have to shuffle data unless the parents are
hash-partitioned (Eg: sortByKey, reduceByKey, groupByKey,cogroupByKey, join, cartesian)
Pietro Michiardi (Eurecom) Apache Spark Internals 35 / 80
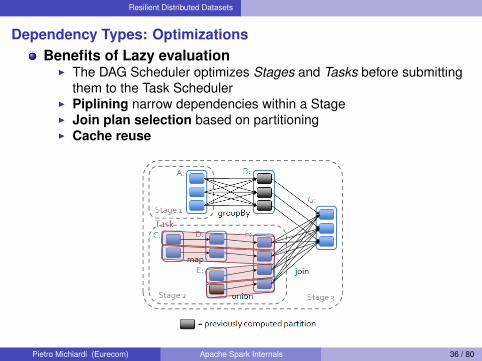
Resilient Distributed Datasets
Dependency Types: OptimizationsBenefits of Lazy evaluation
I The DAG Scheduler optimizes Stages and Tasks before submittingthem to the Task Scheduler
I Piplining narrow dependencies within a StageI Join plan selection based on partitioningI Cache reuse
Pietro Michiardi (Eurecom) Apache Spark Internals 36 / 80

Spark Word Count
Detailed Example:Word Count
Pietro Michiardi (Eurecom) Apache Spark Internals 48 / 80
Spark Word Count
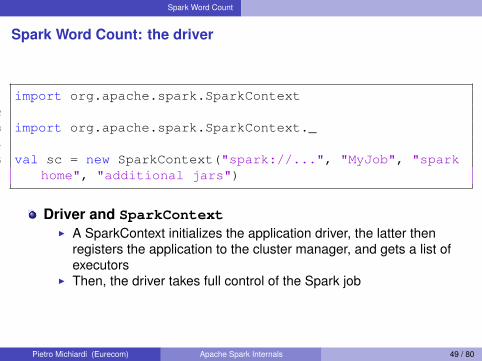
Spark Word Count: the driver
1 import org.apache.spark.SparkContext2
3 import org.apache.spark.SparkContext._4
5 val sc = new SparkContext("spark://...", "MyJob", "sparkhome", "additional jars")
Driver and SparkContextI A SparkContext initializes the application driver, the latter then
registers the application to the cluster manager, and gets a list ofexecutors
I Then, the driver takes full control of the Spark job
Pietro Michiardi (Eurecom) Apache Spark Internals 49 / 80
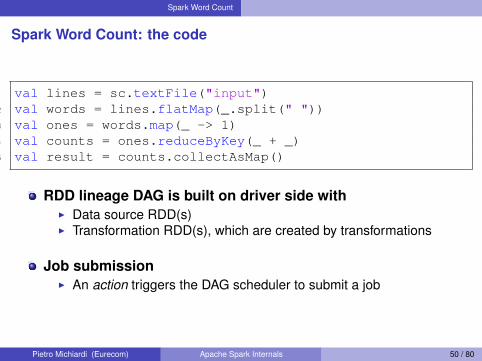
Spark Word Count
Spark Word Count: the code
1 val lines = sc.textFile("input")2 val words = lines.flatMap(_.split(" "))3 val ones = words.map(_ -> 1)4 val counts = ones.reduceByKey(_ + _)5 val result = counts.collectAsMap()
RDD lineage DAG is built on driver side withI Data source RDD(s)I Transformation RDD(s), which are created by transformations
Job submissionI An action triggers the DAG scheduler to submit a job
Pietro Michiardi (Eurecom) Apache Spark Internals 50 / 80
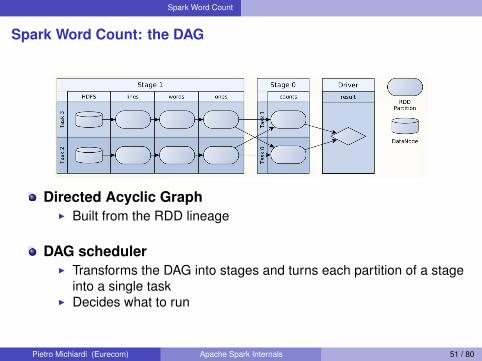
Spark Word Count
Spark Word Count: the DAG
Directed Acyclic GraphI Built from the RDD lineage
DAG schedulerI Transforms the DAG into stages and turns each partition of a stage
into a single taskI Decides what to run
Pietro Michiardi (Eurecom) Apache Spark Internals 51 / 80
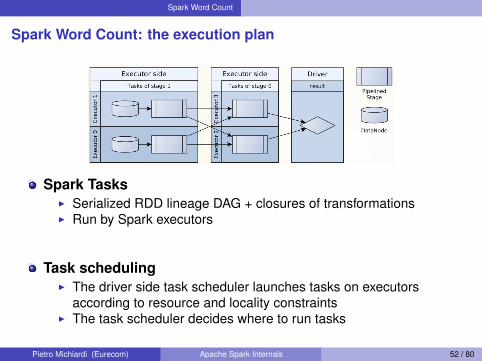
Spark Word Count
Spark Word Count: the execution plan
Spark TasksI Serialized RDD lineage DAG + closures of transformationsI Run by Spark executors
Task schedulingI The driver side task scheduler launches tasks on executors
according to resource and locality constraintsI The task scheduler decides where to run tasks
Pietro Michiardi (Eurecom) Apache Spark Internals 52 / 80

Spark Word Count
Spark Word Count: the Shuffle phase
1 val lines = sc.textFile("input")2 val words = lines.flatMap(_.split(" "))3 val ones = words.map(_ -> 1)4 val counts = ones.reduceByKey(_ + _)5 val result = counts.collectAsMap()
reduceByKey transformationI Induces the shuffle phaseI In particular, we have a wide dependencyI Like in Hadoop MapReduce, intermediate <key,value> pairs are
stored on the local file system
Automatic combiners!I The reduceByKey transformation implements map-side
combiners to pre-aggregate data
Pietro Michiardi (Eurecom) Apache Spark Internals 53 / 80

Resource Allocation
Spark Schedulers
Two main scheduler components, executed by the driverI The DAG schedulerI The Task scheduler
ObjectivesI Gain a broad understanding of how Spark submits ApplicationsI Understand how Stages and Tasks are built, and their optimizationI Understand interaction among various other Spark components
Pietro Michiardi (Eurecom) Apache Spark Internals 62 / 80
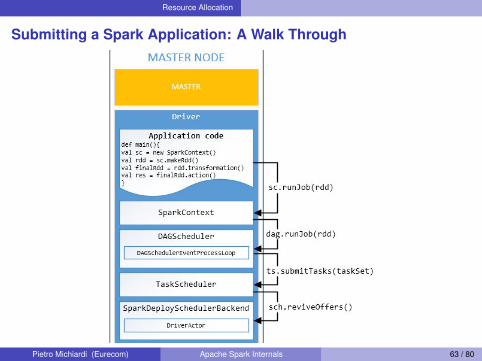
Resource Allocation
Submitting a Spark Application: A Walk Through
Pietro Michiardi (Eurecom) Apache Spark Internals 63 / 80

Resource Allocation
The DAG SchedulerStage-oriented scheduling
I Computes a DAG of stages for each job in the applicationI Keeps track of which RDD and stage output are materializedI Determines an optimal schedule, minimizing stagesI Submit stages as sets of Tasks (TaskSets) to the Task scheduler
Data locality principleI Uses “preferred location” information (optionally) attached to each
RDDI Package this information into Tasks and send it to the Task
schedulerManages Stage failures
I Failure type: (intermediate) data loss of shuffle output filesI Failed stages will be resubmittedI NOTE: Task failures are handled by the Task scheduler, which
simply resubmit them if they can be computed with no dependencyon previous output
Pietro Michiardi (Eurecom) Apache Spark Internals 65 / 80

Resource Allocation
More About Stages
What is a DAGI Directed acyclic graph of stagesI Stage boundaries determined by the shuffle phaseI Stages are run in topological order
Definition of a StageI Set of independent tasksI All tasks of a stage apply the same functionI All tasks of a stage have the same dependency typeI All tasks in a stage belong to a TaskSet
Stage typesI Shuffle Map Stage: stage tasks results are inputs for another stageI Result Stage: tasks compute the final action that initiated a job
(e.g., count(), save(), etc.)
Pietro Michiardi (Eurecom) Apache Spark Internals 68 / 80

Resource Allocation
The Task Scheduler
Task oriented schedulingI Schedules tasks for a single SparkContextI Submits tasks sets produced by the DAG SchedulerI Retries failed tasksI Takes care of stragglers with speculative executionI Produces events for the DAG Scheduler
Implementation detailsI
I
The Task scheduler creates a TaskSetManager to wrap the TaskSet from the DAG schedulerThe TaskSetManager class operates as follows:
F Keeps track of each task statusF Retries failed tasksF Imposes data locality using delayed scheduling
I Message passing implemented using Actors, and precisely usingthe Akka framework
Pietro Michiardi (Eurecom) Apache Spark Internals 69 / 80
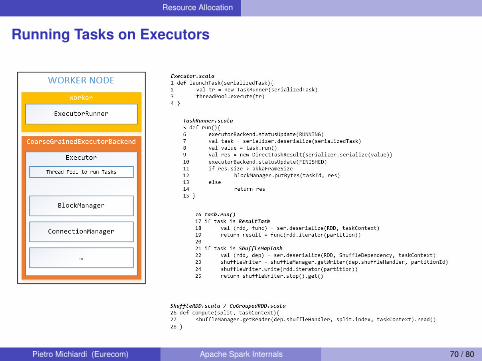
Resource Allocation
Running Tasks on Executors
Pietro Michiardi (Eurecom) Apache Spark Internals 70 / 80

Resource Allocation
Running Tasks on Executors
Executors run two kinds of tasksI ResultTask: apply the action on the RDD, once it has been
computed, alongside all its dependenciesLine 19
I ShuffleTask: use the Block Manager to store shuffle outputusing the ShuffleWriterLines 23,24
I The ShuffleRead component depends on the type of the RDD,which is determined by the compute function and thetransformation applied to it
Pietro Michiardi (Eurecom) Apache Spark Internals 71 / 80

Data Shuffling
Data Shuffling
Pietro Michiardi (Eurecom) Apache Spark Internals 72 / 80

Data Shuffling
The Spark Shuffle Mechanism
Same concept as for Hadoop MapReduce, involving:I Storage of “intermediate” results on the local file-systemI Partitioning of “intermediate” dataI Serialization / De-serializationI Pulling data over the network
Transformations requiring a shuffle phaseI groupByKey(), reduceByKey(), sortByKey(), distinct()
Various types of ShuffleI Hash ShuffleI Consolidate Hash ShuffleI Sort-based Shuffle
Pietro Michiardi (Eurecom) Apache Spark Internals 73 / 80
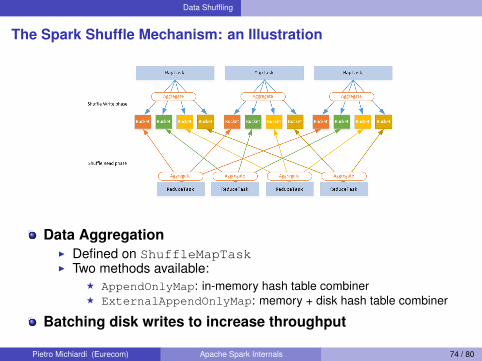
Data Shuffling
The Spark Shuffle Mechanism: an Illustration
Data AggregationI Defined on ShuffleMapTaskI Two methods available:
F AppendOnlyMap: in-memory hash table combinerF ExternalAppendOnlyMap: memory + disk hash table combiner
Batching disk writes to increase throughput
Pietro Michiardi (Eurecom) Apache Spark Internals 74 / 80

Data Shuffling
The Hash Shuffle Mechanism
Map Tasks write output to multiple filesI Assume: m map tasks and r reduce tasksI Then: m × r shuffle files as well as in-memory buffers (for batching
writes)Be careful on storage space requirements!
I Buffer size must not be too big with many tasksI Buffer size must not be too small, for otherwise throughput
decreases
Pietro Michiardi (Eurecom) Apache Spark Internals 76 / 80
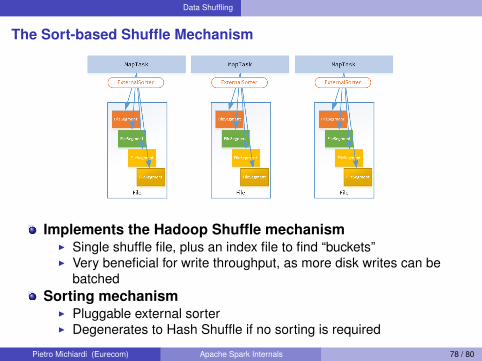
Data Shuffling
The Sort-based Shuffle Mechanism
Implements the Hadoop Shuffle mechanismI Single shuffle file, plus an index file to find “buckets”I Very beneficial for write throughput, as more disk writes can be
batchedSorting mechanism
I Pluggable external sorterI Degenerates to Hash Shuffle if no sorting is required
Pietro Michiardi (Eurecom) Apache Spark Internals 78 / 80
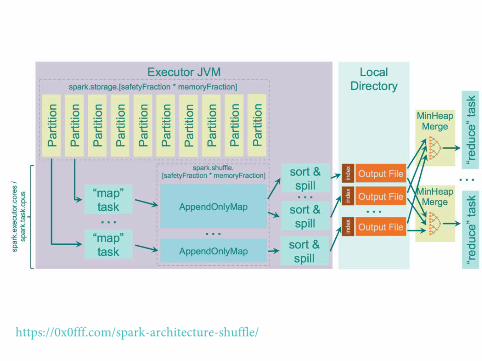
https://0x0fff.com/spark-architecture-shuffle/

















