BearWorks BearWorks MSU Graduate Theses Summer 2020 Applications of Artificial Intelligence and Graphy Theory to Applications of Artificial Intelligence and Graphy Theory to Cyberbullying Cyberbullying Jesse D. Simpson Missouri State University, [email protected]As with any intellectual project, the content and views expressed in this thesis may be considered objectionable by some readers. However, this student-scholar’s work has been judged to have academic value by the student’s thesis committee members trained in the discipline. The content and views expressed in this thesis are those of the student-scholar and are not endorsed by Missouri State University, its Graduate College, or its employees. Follow this and additional works at: https://bearworks.missouristate.edu/theses Part of the Artificial Intelligence and Robotics Commons , and the Data Science Commons Recommended Citation Recommended Citation Simpson, Jesse D., "Applications of Artificial Intelligence and Graphy Theory to Cyberbullying" (2020). MSU Graduate Theses. 3535. https://bearworks.missouristate.edu/theses/3535 This article or document was made available through BearWorks, the institutional repository of Missouri State University. The work contained in it may be protected by copyright and require permission of the copyright holder for reuse or redistribution. For more information, please contact [email protected].
Transcript
BearWorks BearWorks
MSU Graduate Theses
Summer 2020
Applications of Artificial Intelligence and Graphy Theory to Applications of Artificial Intelligence and Graphy Theory to
As with any intellectual project, the content and views expressed in this thesis may be
considered objectionable by some readers. However, this student-scholar’s work has been
judged to have academic value by the student’s thesis committee members trained in the
discipline. The content and views expressed in this thesis are those of the student-scholar and
are not endorsed by Missouri State University, its Graduate College, or its employees.
Follow this and additional works at: https://bearworks.missouristate.edu/theses
Part of the Artificial Intelligence and Robotics Commons, and the Data Science Commons
Recommended Citation Recommended Citation Simpson, Jesse D., "Applications of Artificial Intelligence and Graphy Theory to Cyberbullying" (2020). MSU Graduate Theses. 3535. https://bearworks.missouristate.edu/theses/3535
This article or document was made available through BearWorks, the institutional repository of Missouri State University. The work contained in it may be protected by copyright and require permission of the copyright holder for reuse or redistribution. For more information, please contact [email protected].
APPLICATIONS OF ARTIFICIAL INTELLIGENCE AND GRAPH THEORY TO
CYBERBULLYING
A Master’s Thesis
Presented to
The Graduate College of
Missouri State University
In Partial Fulfillment
Of the Requirements for the Degree
Master of Science, Computer Science
By
Jesse D Simpson
August 2020
Copyright 2020 by Jesse D Simpson
ii
APPLICATIONS OF ARTIFICIAL INTELLIGENCE AND GRAPH THEORY TO
CYBERBULLYING
Computer Science
Missouri State University, August 2020
Master of Science
Jesse D Simpson
ABSTRACT
Cyberbullying is an ongoing and devastating issue in today’s online social media. Abusive usersengage in cyber-harassment by utilizing social media to send posts, private messages, tweets, orpictures to innocent social media users. Detecting and preventing cases of cyberbullying is cru-cial. In this work, I analyze multiple machine learning, deep learning, and graph analysis algo-rithms and explore their applicability and performance in pursuit of a robust system for detectingcyberbullying. First, I evaluate the performance of the machine learning algorithms Support Vec-tor Machine, Naıve Bayes, Random Forest, Decision Tree, and Logistic Regression. This yieldedpositive results and obtained upwards of 86% accuracy. Further enhancements were achieved us-ing Evolutionary Algorithms, improving the overall results of the machine learning models. DeepLearning algorithms was the next experiment in which efficiency was monitored in terms of train-ing time and performance. Next, analysis of Recurrent Neural Networks and Hierarchical Atten-tion Networks was conducted, achieving 82% accuracy. The final research project used graphanalysis to explore the relation among different social media users, and analyze the connectivityand communities of users who were discovered to have posted offensive messages.
KEYWORDS: machine learning, deep learning, graph analysis, cyberbullying, social media
iii
APPLICATIONS OF ARTIFICIAL INTELLIGENCE AND GRAPH THEORY TO
CYBERBULLYING
By
Jesse D Simpson
A Master’s ThesisSubmitted to the Graduate College
Of Missouri State UniversityIn Partial Fulfillment of the Requirements
For the Degree of Master of Science, Computer Science
August 2020
Approved:
Jamil M. Saquer, Ph.D., Thesis Committee Chair
Anthony J. Clark, Ph.D., Committee Member
Lloyd A. Smith, Ph.D., Committee Member
Julie Masterson, Ph.D., Dean of the Graduate College
In the interest of academic freedom and the principle of free speech, approval of this thesis indicates the format isacceptable and meets the academic criteria for the discipline as determined by the faculty that constitute the thesiscommittee. The content and views expressed in this thesis are those of the student-scholar and are not endorsed byMissouri State University, its Graduate College, or its employees.
iv
ACKNOWLEDGEMENTS
I am extremely thankful for the support from the Department of Computer Science at Mis-
souri State University. I am thankful for all the help that Dr. Saquer has provided. He has been a
wonderful mentor, professor, and thesis committee chair through my time at Missouri State Uni-
versity. Dr. Saquer’s motivation to help keep me motivated and on track was very appreciated. I
am also thankful for my other thesis committee members Dr. Anthony J Clark and Dr. Lloyd A
Smith, working with them has been a privilege.
I would like to express my gratitude to my family. My mother Becky has been the number
one supporter of my academic career, despite the adversity faced in my youth. I am thankful to
my grandmother Janice, she has provided so much love and dedication to her grandchildren.
I would like to thank all the wonderful colleagues, students, and friends I have met at Mis-
souri State University, for it truly made it feel like a second home.
v
TABLE OF CONTENTS
1 INTRODUCTION 1
2 LITERATURE REVIEW 42.1 Psychological Impact 42.2 Machine Learning Across Multiple Languages 52.3 Deep Learning Applications 62.4 Offensive Social Media Message Dataset 72.5 Identified Research Gap 8
3 ANALYZING THE EFFECTIVENESS OF MACHINE LEARNING 93.1 Background 93.2 Methodology 103.3 Data Preprocessing 113.4 Experiment Setup and Results 123.5 Discussion 14
4 MACHINE LEARNING OPTIMIZATIONS WITH EVOLUTIONARY ALGORITHMS 154.1 Background 154.2 Methodology 154.3 Data Preprocessing 174.4 Machine Learning Results 174.5 Machine Learning with EA Results 194.6 Discussion 20
5 DEEP LEARNING APPLICATIONS ON TEXT CLASSIFICATION 215.1 Background 215.2 Deep Learning Methodology 225.3 Data Preprocessing 245.4 Algorithm Setup 255.5 Algorithm Performance 265.6 Discussion 28
6 GRAPH ANALYSIS OF TWITTER DATA 296.1 Background of Graph Theory 296.2 Graph Analysis Implementation 306.3 Data Preprocessing for Analysis 326.4 Graph Analysis on Waseem’s Dataset 336.5 Graph Analysis on Forum Posts 346.6 Discussion 40
7 CONCLUSION 42
vi
References 44
Appendices 46Appendix A. Datasets 46Appendix B. Codes 47
vii
LIST OF TABLES
Table 3.1. ML Algorithms Performance on Twitter - No Offensive Word List 13
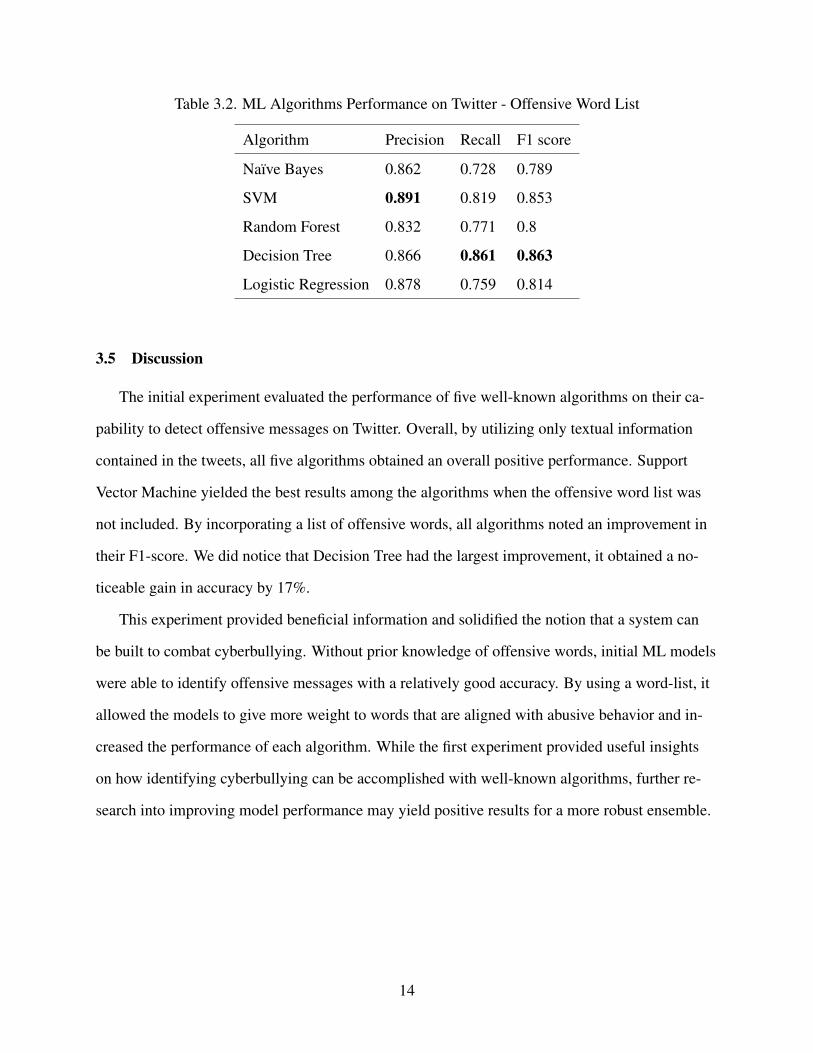
Table 3.2. ML Algorithms Performance on Twitter - Offensive Word List 14
Table 4.1. ML Algorithm Performance without EA - No Offensive List 18
Table 4.2. ML Algorithm Performance without EA - Offensive List 18
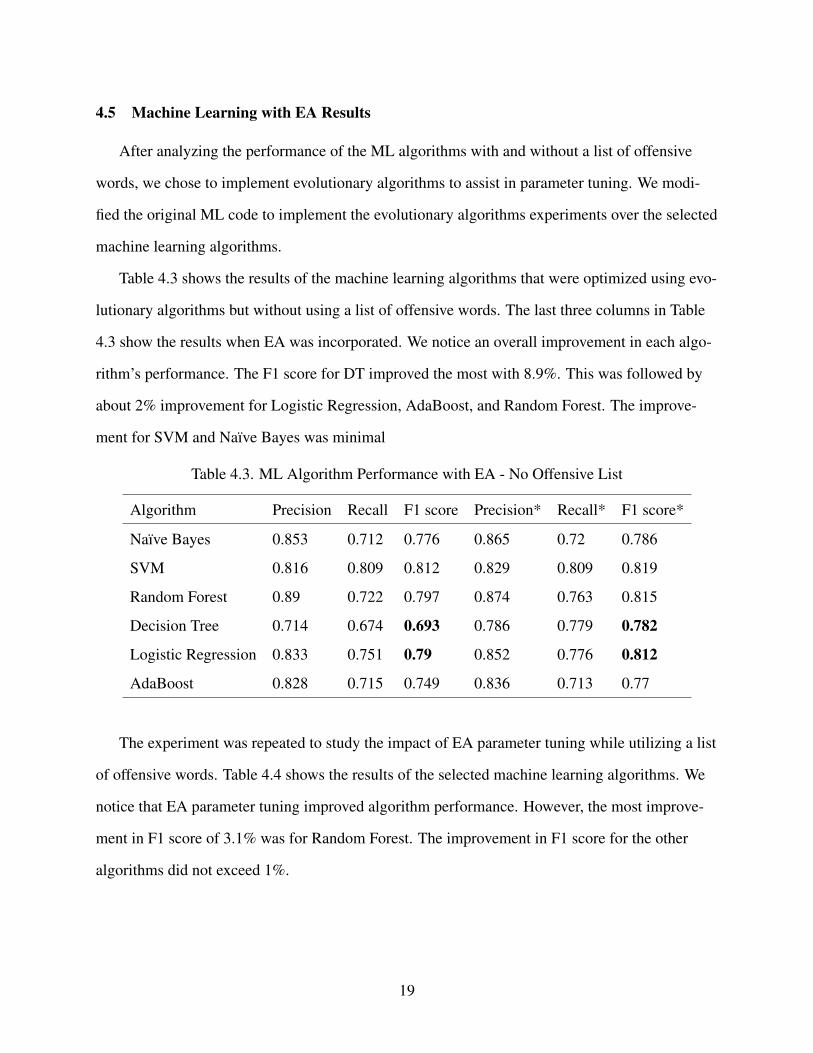
Table 4.3. ML Algorithm Performance with EA - No Offensive List 19
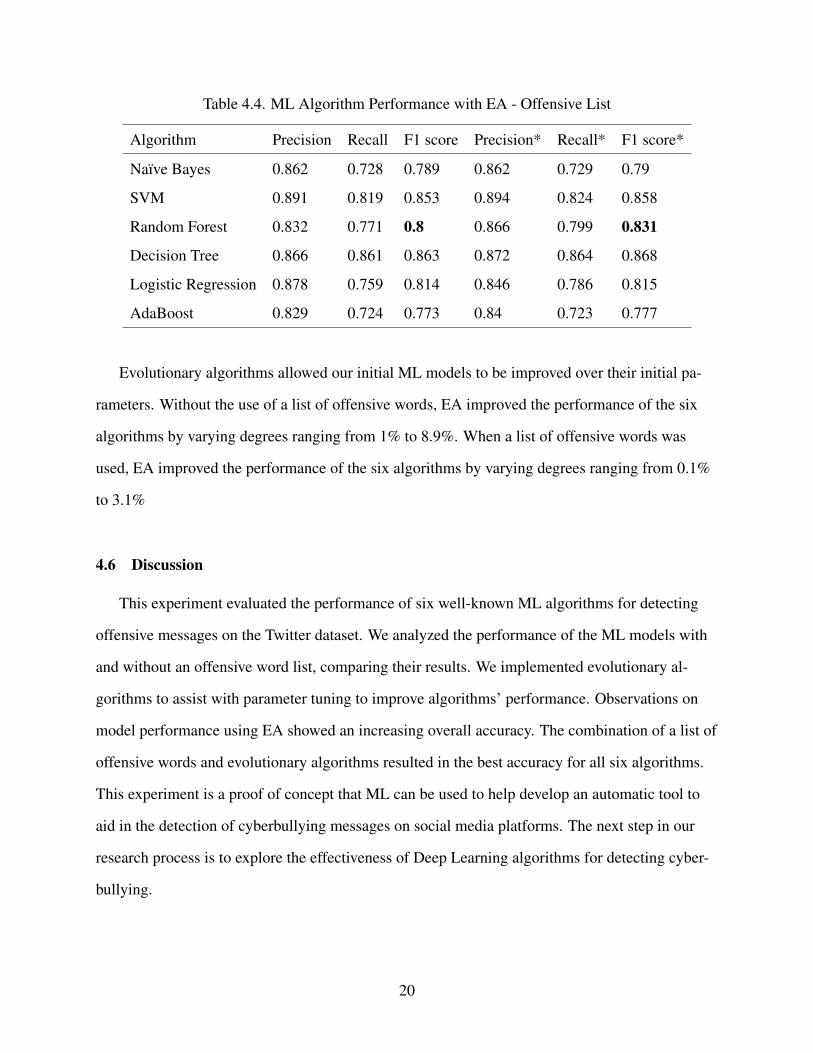
Table 4.4. ML Algorithm Performance with EA - Offensive List 20
Table 5.1. Deep Learning Algorithm Hyperparameters 26
Table 5.2. Recurrent Neural Network Top Results 27
Table 5.3. Hierarchical Attention Network Top Results 27
Table 5.4. Deep Learning Algorithms Average Run-Time 28
Table 6.1. Waseem’s Dataset Data Sample 34
Table 6.2. Imperium Forum Data Sample 36
Table 6.3. Imperium Forum Data Processed 37
viii
LIST OF FIGURES
Figure 3.1. Machine learning data preprocessing overview 12
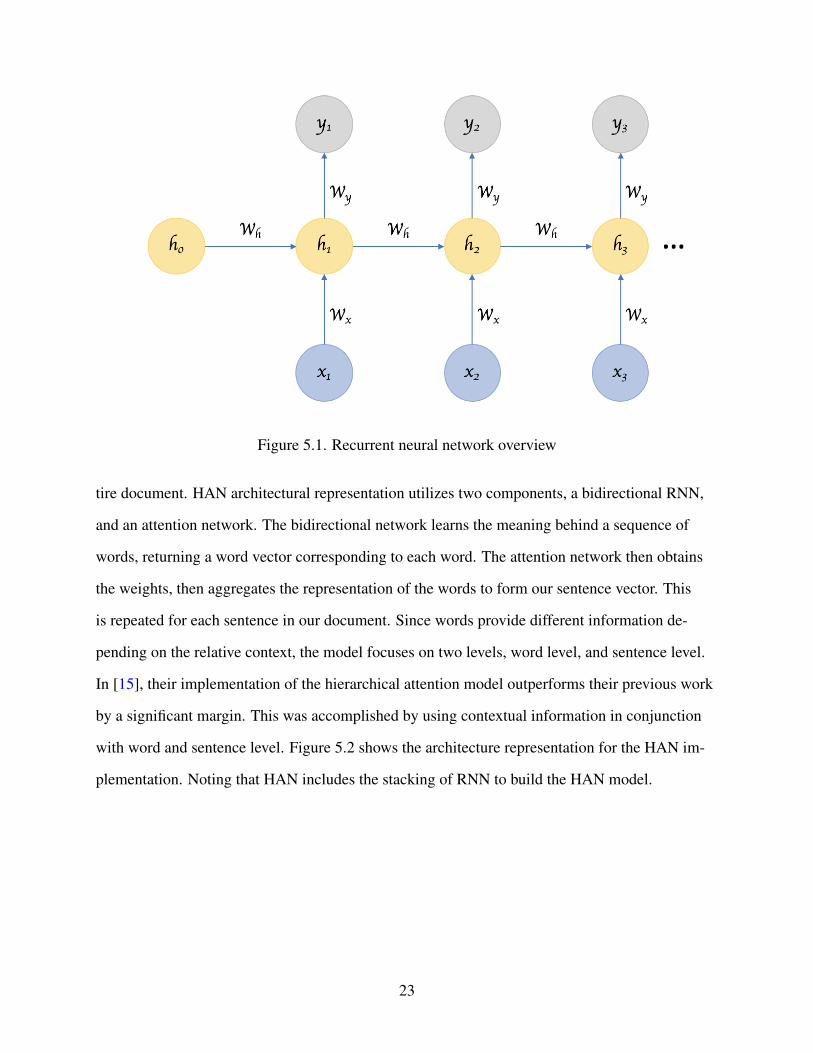
ture and save it as a .GEXF file type. Next, we will use Gephi, an open-source graph visualiza-
tion platform that works with our graph file type. After loading in the data, we can visualize the
results and attempt to infer some analysis based on the resulting graphs obtained from our multi-
step process on classifying offensive messages. Figure 6.3 demonstrates a basic graph generated
from Table 6.1 and how the information is portrayed. We can see our structure allows us to gener-
ate graphs centered that contain users who sent offensively labeled messages.
As we can see in Figure 6.3, we can set up the vertices structure between users who engage in
sending and being mentioned in tweets. To further expand on this system and its overall effective-
ness to identify users who are engaging in acts of cyberbullying, we decided to analyze another
dataset from [18] that contained multiple tweets sent by the same user, as well as recipients who
received offensive messages from multiple sources. The goal of the final analyzed dataset is to
show an initial system that can be used to identify and eventually prevent cyber-offensive mes-
sages from reaching users who wish to have a safe digital space.
6.5 Graph Analysis on Forum Posts
To test our cyberbullying identification system, we selected a secondary dataset that contained
multiple posts from users, as well as recipients who received messages from multiple sources.
The dataset is from Imperium, which contains personal-level insults while engaging in commu-
nication on forum posts [18]. The datasets are listed in Appendix A. for reference. The posts in
the Imperium dataset contain sentence level comments that can be processed through the defined
preprocessing pipeline used in prior chapters, as well as the machine learning and graph analysis.
34
Figure 6.3. Waseem’s example data graph
In order to process the finalized data for graph analysis, we need to declare how the vertex
and edge relationship work. Table 6.2 shows a selection of the tracking data between users and
their post locations. We can set up our vertex information using user id as a vertice, with the spe-
cific subforum id that another user created as the connected vertice. Finally, the edge will have
the label determined by the consensus results of the machine learning models.
Following the same approach in the previous section, we create a GraphX data structure from
loading in the processed data. Table 6.3 shows how the data is presented, including the tracking
of user messages to their forum posts. Due to the nature of the dataset not involving a retweet like
the Twitter dataset, a default value for recipient was not required.
Data visualization is done utilizing .GEXF file type and Gephi in order to infer results and
begin identifying key users. Furthermore, now that multiple messages are being analyzed by the
35
Table 6.2. Imperium Forum Data Sample
User ID Post ID Connected Components Consensus Label
581236 1345 2 Offensive
581236 1345 2 Offensive
579436 1345 0 Offensive
579436 1345 0 Offensive
579436 1345 0 Offensive
579436 1345 6 Non Offensive
581373 1347 0 Non Offensive
581373 1347 0 Offensive
572042 1347 0 Non Offensive
575709 1347 0 Non Offensive
same user, we can analyze the graph to check total sent messages (Out-Degree), total offensively
labeled messages, and total offensive messages sent to another user.
Due to computational and figure size restraints, we could not generate a graph illustrating
thousands of connections. To begin analyzing the data, we generate a basic graph to see how the
connections of users and forum posts look. Figure 6.4 shows a sample connection of 35 users,
with a total of 100 forum posts. We can see that depending on a forum topic, various amounts of
users engage in conversation.
Next, we want to see if certain users are sending overall more offensive messages to certain
users and their posts. To accomplish this, we need to generate a graph that establishes the edge
label as offensive or non-offensive. An edge connection will contain a label as offensive if at least
half of their sent messages to the user are labeled offensive by consensus of the machine learning
models. Similarly, if at least half the messages sent are labeled non-offensive, the edge connec-
tion will be labeled non-offensive. Using the same 35 users from Figure 6.4, we will generate a
new graph with establishing edge labels. Figure 6.5 shows the resulting graph with labels com-
pleted with 0 representing overall non-offensive and 1 representing overall offensive users.
36
Table 6.3. Imperium Forum Data Processed
User ID Post ID In-Degree Out-Degree Connected Components ConsensusLabel
581236 1345 1 2 2 Offensive
579436 1345 1 4 0 Offensive
581373 1347 1 1 0 Offensive
572042 1347 1 1 0 Non Offensive
575709 1347 1 2 0 Offensive
575675 1347 1 2 2 Non Offensive
Figure 6.4. Imperium forum user interactions
The final stage of the system is to identify primary users who engage in cyberbullying. We
want to analyze data to find certain users or posts that are repeatedly targeted by users engaging
in offensive, directed messages. To accomplish this feat, we want to analyze our data to generate
37
Figure 6.5. Imperium forum user interactions - labeled
graphs to not only discover individual users engaging in behavior, but groupings or communities
of users who repeatedly send offensive messages.
First, this is performed by analyzing users who share posts on the same user or forum, check-
ing the connected components and trying to isolate key individuals or groups who actively partic-
ipate in targeted, offensive messages. Next, we analyze the data on posts to check for subgraphs
of users who are labeled as offensive posters. If a subgraph of users are labeled as non-offensive
posters, no further checks are performed on the specific subgraph. If a subgraph of users are la-
beled as offensive posters, further analysis is required.
Should a subgraph be labeled as offensive, further analysis is done on other related forum
post topics to check if the subgraph appears in any other posts. If the subgraph appear or a subset
of vertices appear, we assess the consensus edge labels to determine if offensive behavior repli-
38
cated on another post. If the edges contain offensive user labels, we generate a graph that allows
us to identify which user or users is currently behaving with toxic online behavior. Figure 6.6
shows a resulting graph when finding isolated forum posts filled with repeated offensive mes-
sages from a group of users.
Figure 6.6. Imperium forum offensive behavior users
While Figure 6.7 demonstrates a grouping of individuals who have targeted multiple forum
posts with offensive posts, this suggests that have engaged in sending offensive messages to mul-
tiple users, as well as overlapping with other users. This provides us with a graph system that
can identify core users who are targeting individuals posts, and eventually prevent such scenar-
ios from occurring. The code implementation from the machine learning models to the compiled
graph models is available in Appendix B.
39
Figure 6.7. Grouping of imperium forum offensive behavior users
6.6 Discussion
Overall, this introductory graph system for identifying cyberbullying users and victims has
provided useful insights. We were able to process social media information that included users
involved in posts, recipients of posts, and apply machine learning models to classify textual data.
This allowed us to perform graph work, which aided in finding key users or groups of individuals
who on average, sent more offensive messages to other users. This is a potential application in
aiding average users or parents in keeping their digital social space secure from cyberbullying
threats.
To improve this proposed system, future work for improving overall machine learning method-
ology for classifying social media posts will be done. Further research into more specialized
graph analysis tools and algorithms can potentially aid in improving an overall system in discov-
40
ering subgraphs, identifying more key vertices, and discovering new social media patterns. All
with the intent to help prevent cases of cyberbullying while browsing social media.
41
7 CONCLUSION
In the conducted research, we applied a pipeline of methodologies for the identification of
cyberbullying incidents, as well as users involved. We initially explored the applicability of Ma-
chine Learning algorithms, furthermore extending the experiment with an exploration of Genetic
Programming enhancements, then we applied Deep Learning methods, and Graph Analysis.
First, we implemented five popular machine learning algorithms on Twitter data from [5]. We
implemented Support Vector Machine, Naıve Bayes, Random Forest, Decision Tree, and Logistic
Regression. Without the usage of an offensive word list, we discovered that Support Vector Ma-
chine recorded better results overall when compared to the other algorithms. We replicated the
experiment with the addition of an offensive word list [12]. Decision Tree saw the greatest im-
provement with an increase by 0.693 to 0.863. Support Vector Machine is the recommended ap-
proach for classifying the Tweets, due to the overall performance and stability during both exper-
iment scenarios of no provided offensive words, as well as weighting offensive words. Overall,
the initial machine learning experiment provided beneficial results in regards to the applications
of the algorithms on the targeted problem domain of cyberbullying detection.
Following the initial machine learning experiment, we researched the effectiveness of Genetic
Programming on the optimization of algorithm parameters. We define and implement popula-
tion, parent selection, fitness function, crossover, mutation, and survivor selection. We replicated
the prior experiment, fully analyzing the results of machine learning algorithms that have been
optimized using Genetic Programming. This includes the usage and withholding of an offensive
word list. Also, we included the AdaBoost algorithm in the original ensemble of models. We note
an overall increase in model performance among the six algorithms. Without utilizing the offen-
sive word list, we note algorithm improvements ranging from 1% to 8.9%. With the usage of the
offensive word list, we saw varying degrees of improvements from 0.1% to 3.1%. This experi-
ment yielded further improvement on the algorithms, further improving the ensemble of models.
42
The current stage of the experiments still reveal that Support Vector machine is the recommended
algorithm choice for classifying offensive tweets.
The next step in the research process analyzed the effectiveness of Deep Learning on clas-
sifying cyberbullying textual data. We implement Recurrent Neural Networks and Hierarchical
Attention Network using Keras library. Also, we analyze the performance of models using differ-
ent activation functions and loss metrics. We note that both algorithms achieved similar levels of
performance as the prior initial machine learning work when applied to the Twitter dataset. Re-
current Neural Network achieved results of 81.63% accuracy and Hierarchical Attention Network
achieved 78.88%. This experiment aided in concluding our ensemble of models for classifying
offensive social media messages and wrapping up final preparations for graph analysis.
Lastly, we implement and conclude our cyberbullying system using Graph Analysis. We im-
plement the ensemble of models previously discussed to classify social media messages and per-
form graph analysis to attempt an identification of key users or groups engaging in spreading hate
messages. We introduce a more diverse dataset that includes users who have sent multiple offen-
sive or non-offensive messages [18]. We analyze the incoming messages, outgoing messages,
connected users, and model labels to establish graphs for identifying users who prominently
engage in sending offensive messages or recipients who are receiving offensive messages. The
graph work laid the groundwork of a compiled system that can be utilized for combating the dire
issue of cyberbullying.
For future work, we can further improve and expand our algorithm selection for Machine
Learning and Deep Learning. This includes diverse algorithms, newer Deep Learning applica-
tions such as transfer learning, and exploring further optimization methods. We can also further
improve our graph analysis tools to analyze and generate subgraphs that represent user communi-
ties, then further analyzing the members, since social media revolves around friend circles, com-
munity groups, and other social gatherings.
43
REFERENCES
[1] J. Clement, “Global social media ranking 2019,” ”https://www.statista.com/statistics/272014/global-social-networks-ranked-by-number-of-users/”, Feb 2019.
[2] J. W. Patchin, Reney, J. W. Patchin, and J. W. Patchin, “2019 cyberbullying data,” ”https://cyberbullying.org/2019-cyberbullying-data.”, Feb 2020.
[3] L. Korte, “Youth suicide rates are rising. school and the internet may be toblame.” ”https://www.usatoday.com/story/news/nation-now/2017/05/30/youth-suicide-rates-rising-school-and-Internet-may-blame/356539001/”, October 2019.
[4] K. Rosenblatt, “Cyberbullying tragedy: New jersey family to sue after 12-year-old daughter’s suicide,” ”https://www.nbcnews.com/news/us-news/new-jersey-family-sue-school-district-after-12-year-old-n788506/”, Feb 2020.
[5] Z. Waseem and D. Hovy, “”Hateful symbols or hateful people? Predictive features for hatespeech detection on twitter”,” in Proc. NAACL Student Research Workshop, Jun. 2016, pp.88–93.
[6] S. Parime and V. Suri, “Cyberbullying detection and prevention: data mining and psycho-logical perspective,” in 2014 International Conference on Circuits, Power and ComputingTechnologies, 2014, pp. 1541–1547.
[7] C. L. Nixon, “Current perspectives: the impact of cyberbullying on adolescent health,” Ado-lescent health, medicine and therapeutics, vol. 5, p. 143, 2014.
[8] S. C. Eshan and M. S. Hasan, “An application of machine learning to detect abusive bengalitext,” in Proc. 2017 20th International Conference of Computer and Information Technol-ogy, 2017, pp. 1–6.
[9] M. Andriansyah, A. Akbar, A. Ahwan, N. A. Gilani, A. R. Nugraha, R. N. Sari, and R. Sen-jaya, “Cyberbullying comment classification on indonesian selebgram using support vectormachine method,” in Proc. 2017 Second International Conference on Informatics and Com-puting, 2017, pp. 1–5.
[10] P. Ruangkanokmas, T. Achalakul, and K. Akkarajitsakul, “Deep belief networks with fea-ture selection for sentiment classification,” in Proc. 2016 7th International Conference onIntelligent Systems, Modelling and Simulation, 2016, pp. 9–14.
[11] T. G. Dietterich, “Ensemble learning,” The handbook of brain theory and neural networks,vol. 2, pp. 110–125, 2002.
[12] “Google code archive - long-term storage for google code project hosting.” ”https://code.google.com/archive/p/badwordslist/”, Jan 2019.
[13] R. Poli, W. B. Langdon, N. F. McPhee, and J. R. Koza, A field guide to genetic program-ming. UK: Lulu.com, 2008.
[14] A. E. Eiben and J. E. Smith, Introduction to evolutionary computing. Heidelberg, Germany:Springer, 2003.
[15] Z. Yang, D. Yang, C. Dyer, X. He, A. Smola, and E. Hovy, “Hierarchical attention networksfor document classification,” in Proc. of the 2016 conference of the North American chapterof the association for computational linguistics: human language technologies, 2016, pp.1480–1489.
[16] T. Mikolov, M. Karafiat, L. Burget, J. Cernocky, and S. Khudanpur, “Recurrent neural net-work based language model,” in Eleventh annual conference of the international speechcommunication association, 2010, pp. 2877–2880.
[17] M. Grandjean, “A social network analysis of twitter: Mapping the digital humanities com-munity,” Cogent Arts & Humanities, vol. 3, no. 1, 2016.
[18] “Detecting insults in social commentary,” https://www.kaggle.com/c/detecting-insults-in-social-commentary/overview/, Mar 2020.