Page 1
Maîtrise Informatique
Option Micro-informatique Micro-électronique
Année 1995 - 1996
Université Paris 8
Département Micro-Informatique Micro-Electronique
2, rue de la Liberté 93526 SAINT DENIS CEDEX 02
Applied Neuro-cryptography
by
Sébastien Dourlens
To all beings thinking
That a secret can be kept longtime
Page 2
Summary
This memory is carried out in the context of the master MIME at the Paris 8 University.
Its purpose is to do research on the neuronal applications to Cryptography.
Searching for existing shows that no thesis, no Conference summary report, no work and no
internet (Web pages and news) user information and applied neural networks to
Cryptography.
We then thought it would be interesting to define a new field called neuro-Cryptography
whose aim is the use of neural networks to encrypt a message, decrypt a message or Exchange
messages in the network. The cryptogaphie contains another area to study in a probabilistic
manner the strength and weaknesses of an encryption algorithm, it comes to cryptanalysis.
Neural networks can play a decisive role in this area, this is why we have also defined the
neuro-cryptanalysis.
The areas of Artificial Intelligence with the networks of neurons, cryptography and
cryptanalysis have long been highly studied by universities around the world and, among
other things, by enterprises in electronic circuit design.
We begin by choosing the model and the most efficient learning of neural networks from its
qualities of synthesis of complex functions and statistical analyses. This model is the network
of perceptrons with back-propagation of the gradient. The hardware realization should not be
neglected since cryptography requires a great speed of learning, which is a function of the
number of keys and possible texts.
We have added elements allowing the creation of hardware architectures.
Then we choose the field of cryptographic applications, it is primarily the study of des (Data
Encryption Standard) and its cryptanalysis.
Then we test and measure the performance of neuro-Cryptography and neuro-cryptanalysis
which prove be quite interesting from all points of view. The calculation time can be
improved by design of machine architecture dedicated to the learning of cryptographic
algorithms through arsenide-based components or of massively parallel machines as it has
already been done for neural networks and the D.E.S. but separately.
In regards to neuro-Cryptanalysis of des, realize us a neuro-cryptanalyseurs differential and
linear studying the probabilities to get the entries of the S-tables based on outputs, allowing us
to obtain characteristics for an unknown subkey.
This line of research is open now, should continue to the coherence between the neural
network to learning of the globality of the cryptosystem and the neuro-cryptanalyseurs of the
internal structure of this cryptosystem which are very fast in learning. Another reason is the
ability of synthesis of the gradient back-propagation network.
Page 3
Thanks
I want to thank my research director Mr. Christian Riesner researcher in Artificial
Intelligence specializing in neural networks.
Thanks to teachers - researchers from the Department of Micro computer - Micro Electronics
of the University Paris 8.
Thanks again to students, researchers and professors of universities that have provided me
information valuable and useful for this memory.
Page 4
Table of contents
1 Introduction
1.1 Searching for existing
1.2 Neural networks
1.3 Contemporary Cryptography
1.4 The neuro-Cryptography applied
1.5 The memory map
2. Neural networks
2.1 Introduction
2.2 Basic concepts and terminology
2.3 The situation presents
2.4 Neural networks are used in Cryptography?
2.5 What types of neural networks use in Cryptography?
2.6 The model structure of perceptrons with back-propagation of the gradient
2.7 The gradient back-propagation algorithm
2.8 Analysis of linear multi-layer networks
2.8.1 Problem of the linear perceptron multilayer
2.8.2 Discriminant analysis of rank p
2.8.3 Incremental learning of the hidden layer
2.8.4 Relations with the principal component analysis
2.9 Material
2.10 Conclusion
3. The Cryptography
3.1 Introduction
Page 5
3.2 Definitions
3.3 Contemporary Cryptography
3.3.1 The cryptosystem and strength
3.3.2 Protocols
3.3.3. The types of attacks in cryptanalysis
3.4 Cryptographic algorithms
3.4.1 The coding of blocks and the stream encoding
3.4.2 The number of Vigenère
3.4.3 The strong figures
3.5 Reference: the Data Encryption Standard (des)
3.5.1 History
3.5.2 Architecture
3.5.3 Cryptanalysis
3.5.4 The physical aspect
3.6 The Cryptanalysis of des
3.6.1 Differential cryptanalysis
3.6.2 Linear cryptanalysis
3.7 Conclusion
4. The Neuro-Cryptography
4.1 Introduction
Can 4.2 I bind the Cryptography and neural networks?
4.3 The new definitions
4.3.1 The neuro-encryption or neuro-encryption
4.3.2 The neuro-decryption or neuro-decryption
4.3.3 The neuro-generator
Page 6
4.3.4 Neuro-cryptanalysis
4.4 The generation of bases of learning
4.4.1 Examples
4.4.2 Order of presentation
4.4.3 Automatic generation of texts
4.4.4 The coefficient of learning
4.5 Self-learning
4.6 The realization of applications
4.6.1 The learning of the exclusive or (XOR)
4.6.2 The learning of cryptographic algorithms
4.6.3 Key learning
4.7 The advantages and disadvantages
4.8 Conclusion
5. The Neuro-cryptanalysis
5.1 Introduction
5.2 Definition
5.3 General principle
5.4 Applied Neuro-cryptanalysis
5.4.1 The Neuro-Cryptanalysis of the Vigenère figure
5.4.2 The Neuro-differential cryptanalysis of des
5.4.3 The Neuro-linear Cryptanalysis of des
5.4.4 Overall Neuro-Cryptanalysis of the crypt (3) UNIX
5.5 Analysis of the results of cryptanalysis
5.6 Hardware implementations
5.6.1 Dedicated Machine
Page 7
5.6.2 Algorithm for the Connection Machine CM-5
5.7 Performance
5.8 Conclusion
6 Glossary and math basics
6.1 Introduction
6.2 The information theory
6.3 The complexity of algorithms
6.4 The number theory
7 Conclusion
Bibliography
Neural networks
Cryptography
Mathematics
HTML pages and newsgroup on the internet
Annexes
1 C sources
The gradient back-propagation neural network
The figure of Vigenère or XOR single
Cryptanalysis of the Vigenère figure
The code of the D.E.S.
Learning of the XOR in disorder
Automatic generation of basis for learning of the D.E.S.
The generation of tables of differences in des distributions
The generation of tables of linear approximations of des
Neuronal functions library
Page 8
The differential des neuro-generator
The linear neuro-generator of the D.E.S.
2. The neural circuits
3. The tables of differences in des distributions
4. The tables of linear approximations of des
5. Tables simplified distributions of differences
6. The tables of the neuro-cryptanalyseur differential
7. The tables in the linear neuro-cryptanalyseur
8. The measures of learning of the XOR tables
9. The massively parallel machines
Page 9
Chapter 1 - Introduction
1.1 Searching for existing
The purpose of the memorandum is to research on neuronal applications allowing for
Cryptography.
Searching for existing shows that no thesis, no Conference summary report, no work and no
internet (Web pages and news) user information and applied neural networks to
Cryptography.
Indeed, David Pointcheval de l'Ecole Normale Supérieure de Paris is served by the problem of
the perceptron to create an authentication protocol or it was an only mathematical and
theoretical study.
The areas of Artificial Intelligence with the networks of neurons, cryptography and
cryptanalysis have long been very studied by researchers at universities around the world and
among other electronic circuits design firms.
We then thought it would be interesting to define a new field called neuro-Cryptography
whose aim is the use of neural networks to encrypt a message, decrypt a message or Exchange
messages in the network. Cryptography contains another area to study in a probabilistic
manner the strength and weaknesses of an encryption algorithm, it comes to cryptanalysis.
Neural networks can play a decisive role in this area, this is why we have also defined the
neuro-cryptanalysis.
1.2 Neural networks
We present the neural networks, define and determine what model of neural networks the
most appropriate Cryptography on algorithmic learning plan and material terms in relation to
already completed architectures as well as the observed performance.
The most interesting Connectionist model turns out be the network of perceptrons with back-
propagation of the gradient through its various properties.
These properties were analyzed and demonstrated by different scientists.
their generalization property
their low sensitivity to noise (if an error sneaks into the basis of examples)
their low sensitivity to fault (lost connections, modified weight or bug in the program)
information are outsourced
Research of statistical calculations and heuristics capabilities
Page 10
We present the structure of the model chosen in the following figure:
This architecture can both be software (sequential single-processor computer program)
material (massively parallel machines).
These machines and neural networks are two little different Connectionist approaches. The
study of neural networks is equivalent to consider parallel machines interconnected except
that they contain a matrix of weight compact and some "intelligence". Furthermore, neural
networks have already been implemented on machines massively parallel.
An analysis of linear multilayer networks shows analogies with different statistical methods
of analysis of the data, in particular linear regression and discriminant analysis. It has been
shown that the backpropagation is a discriminant analysis of a population of N individuals (N
being the number of examples included in learning) described by n parameters (wheren is the
number of input neurons) and projected in a hyperplane of dimension p (wherep is the number
of hidden units). It is therefore possible to use non-linearly separable problem to build a
classifier where a probabilistic model. Which proves the interest of such an algorithm in
cryptography and especially cryptanalysis.
We need to go back to the hardware aspect if we want a faster learning of a large number of
keys and texts.
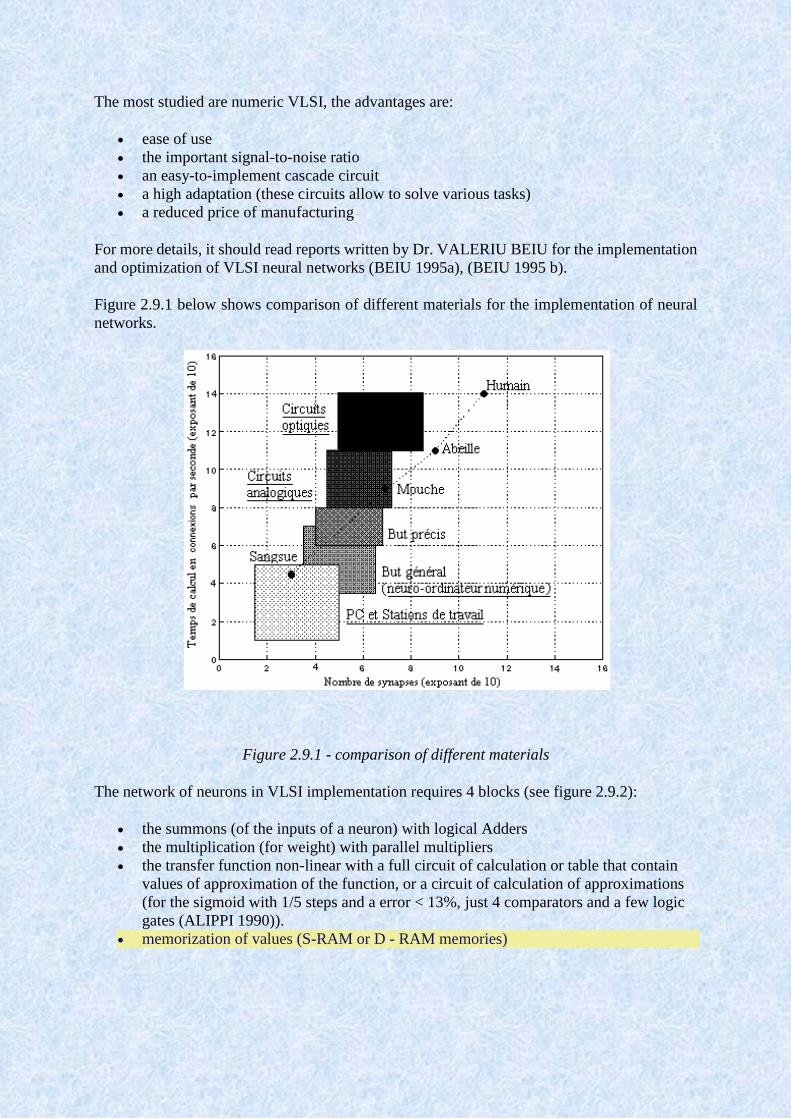
The most studied are numeric VLSI, the advantages are:
ease of use
the important signal-to-noise ratio
an easy-to-implement cascade circuit
a high adaptation (these circuits allow to solve various tasks)
a reduced price of manufacturing
The network of neurons in VLSI implementation requires 4 blocks:
the summons (of the inputs of a neuron) with logical Adders
the multiplication (for weight) with parallel multipliers
Page 11
the function of non-linear transfer with a full circuit of calculation or a table that
contains the values of the function approximations, or a circuit of calculation of
approximations (for the sigmoid with 1/5th of pas and a error of less than 13%.) Just 4
comparators and a few logic gates (ALIPPI 1990))
memorization of values (S-RAM or D - RAM memories)
We present then the three types of existing components on the market or research laboratory:
1. components dedicated to digital neural which speeds network go up to 1 GB of
connections processed per second
2. the digital coprocessors particular purpose (also called neuro-accelerators) are special
circuitry that can be connected to hosts (PCs or workstations), they work with a neuro-
simulator program. The mix of hardware and software aspects gives these benefits:
accelerated speed, flexibility and improved user interface
3. networks of neurons on massively parallel machines
An implementation of the above mentioned algorithm has been developed on the Connection
Machine CM-2 (created by THINKING MACHINES Corp.) with a topology hypercube 64 k
processors, which gave 180 million interconnections calculated per second (IPS) are 40
million weight updated per second.
Here is the performance measured by machine in interconnections calculated by seconds
(figure below).
CM-2 180 millions
CRAY X-MP 50 millions
WARP (10) 17 millions
ANZA PLUS 10 millions
The use of such configurations would get good results in learning of cryptographic ciphers.
1.3 Contemporary Cryptography
Cryptography is a very large and popular area of mathematicians and computer scientists.
However, nowadays, cryptography is the study of more or less strong encryption of messages
or files and study of protocols to Exchange private networks and other means of
communication. Found in the study of ciphers, the means to find keys or decrease the
exhaustive search of keys: it is cryptanalysis. We present the strength of a cryptosystem which
depends entirely on the used key that it is public (known to all for message sending) or private
(known to those who can read issued messages) and exchanges cryptographic protocols. We
prefer to focus on the realization of neural and neuro-Cryptanalysis of cryptosystems.
Here are the different types of possible attacks in cryptanalysis:
Page 12
to ciphertext only : the attacker must find the cleartext with the encrypted text. A
ciphertext attack is practically impossible, everything depends on the encryption.
to known-plaintext : the attacker has the plaintext and corresponding ciphertext. The
ciphertext was not chosen by the attacker but anyway the message is compromised. In
some cryptosystem, a pair of encrypted text - plaintext can compromise the security of
the system as well as the transmission medium.
to chosen plaintext : the attacker has the ability to find the ciphertext corresponding to
an arbitrary plaintext of his choice.
to chosen ciphertext : the attacker can arbitrarily choose and find the corresponding
unencrypted clear text. This attack may show weaknesses in the systems public key,
and even to find the private key.
to suitable chosen plaintext : the attacker can determine the ciphertexts of plaintexts
chosen in an iterative process or interactive based on the results previously found. An
example is the differential.
We quickly describe modes of encryption with Ci which is the i-th message Mi encrypted, E
the encryption function, D the function reverse for the key (or subkey) K and Vi an
intermediate encrypted message:
The ECB (Electronic Code Book) mode where Ci = EK(Mi) and Mi = DK(Ci)
CBC (Cipher Block Chaining) mode where Ci = EK(Mi XOR Ci-1) and Mi = DK(Ci)
XOR Ci-1
The OFB (Output FeedBack) mode where Vi = EK(Vi-1) and (c)i= Mi XOR Vi
The Cipher FeedBack (CFB) mode where Ci = Mi XOR EK(Ci-1) and Mi = Ci XOR
EK(C- i-1)
Any encryption algorithm can be implemented in these modes.
In what concerns our work, we will focus specifically on the ECB mode suited more to
learning of the networks of neurons with an input and output number of fixed bits and not
loop re-inbound, although it is possible to connect one or more networks of neurons in this
way but learning time would be quite longer.
There are simple as the figure of Vigenère (simple XOR of contiguous blocks with a same
key of the same size as a block) and algorithms more complex as the R.S.A. of the name of its
designers (RIVEST, SHAMIR, and ALDEMAN) and des.
One uses a public key and one private key, the other only a private key.
These are actually figures of Vigenère with a different key for each block. In the R.S.A. key
uses of large prime numbers while in the D.E.S. it depends on S-tables more or less linear and
more or less affine.
We have chosen to tackle the D.E.S. because it is the older standard of encryption and the
most studied algorithms.
The D.E.S. combines conversions and substitutions in a product code which the safety level is
much higher than that of the two codes used base (text and key). These substitutions are non-
linear which produces a cryptosystem resistant to any cryptanalysis. He has also designed to
Page 13
withstand differential cryptanalysis which was classified by the army and unknown to
researchers.
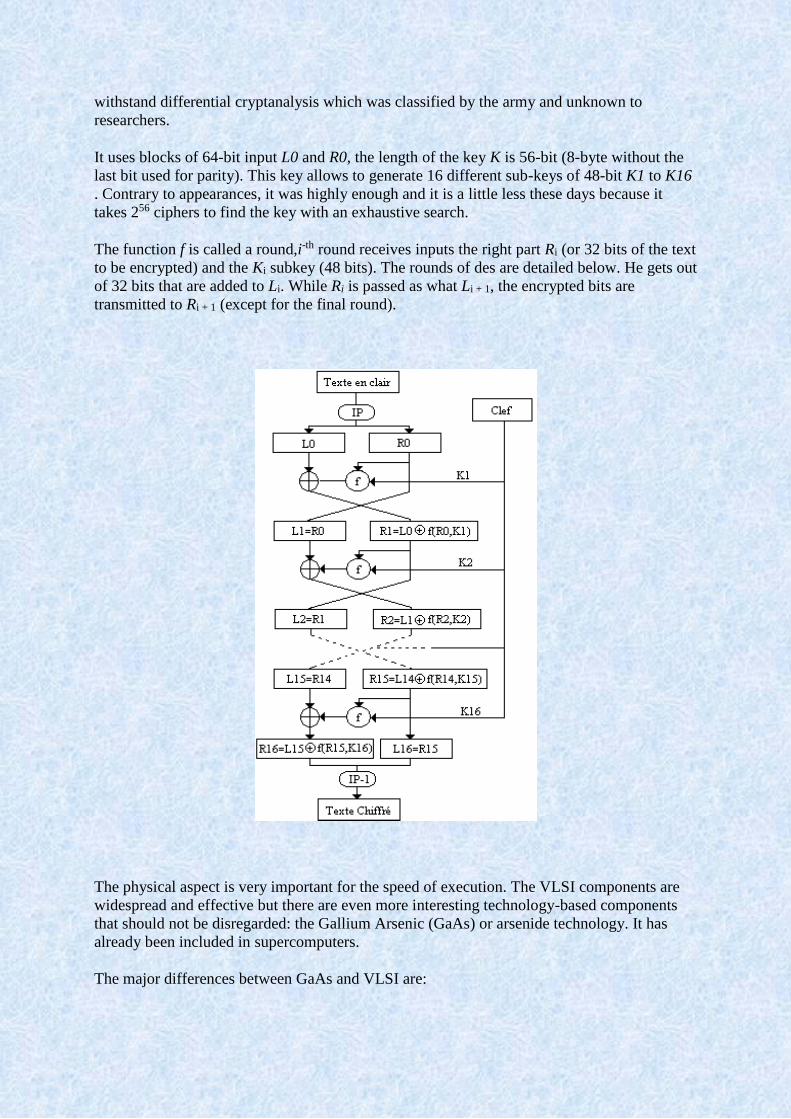
It uses blocks of 64-bit input L0 and R0, the length of the key K is 56-bit (8-byte without the
last bit used for parity). This key allows to generate 16 different sub-keys of 48-bit K1 to K16
. Contrary to appearances, it was highly enough and it is a little less these days because it
takes 256 ciphers to find the key with an exhaustive search.
The function f is called a round,i-th round receives inputs the right part Ri (or 32 bits of the text
to be encrypted) and the Ki subkey (48 bits). The rounds of des are detailed below. He gets out
of 32 bits that are added to Li. While Ri is passed as what Li + 1, the encrypted bits are
transmitted to Ri + 1 (except for the final round).
The physical aspect is very important for the speed of execution. The VLSI components are
widespread and effective but there are even more interesting technology-based components
that should not be disregarded: the Gallium Arsenic (GaAs) or arsenide technology. It has
already been included in supercomputers.
The major differences between GaAs and VLSI are:
Page 14
fast failover of the GaAs doors
the Exchange with components other than GaAs is a major difficulty
very small density of GaAs integrated circuits
With regard to the D.E.S., there is a circuit running at 50 MHz performing encryption in 20
ns, which allows to make 50 million of ciphers in a second.
Since late 1995, AMD sells a circuit encrypting at 250 MHz.
In August 1993, the Canadian Michael J. WIENER described how to build a machine for $ 1
million that performs a comprehensive search of des keys to find the right key in 3.5 hours.
Each of its basic circuits has power equivalent to 14 million stations SUN.
It seems so obvious that the exhaustive search is faster to perform types of cryptanalysis
because even if the number of attempts is less, the search time is much longer, cryptanalysis is
still very interesting to measure the performance of cryptographic algorithms.
We analyze then both as successful cryptanalysis against des.
Differential cryptanalysis is to look at the specifics of a pair of ciphertexts for a pair of
plaintexts with a particular difference.
It analyses the evolution of these differences when the plaintexts spread through rounds of
DES to be encrypted with the same key.
After randomly choosing a pair of plaintexts with a difference set, calculate the difference in
the resulting ciphertexts. Using these differences, it is possible to associate different
probabilities to various bits of the sub-keys. Plus a large number of ciphertexts is analyzed,
most most likely encryption key will emerge.
Force of residing in his rounds and all operations of a round being completely linear except S-
tables, Eli BIHAM and Adi SHAMIR analyzed 8 S-tables for text input differences and
differences in output texts, these information are synthesized in 8 tables called Tables of
distribution of differences of the (see 8 tables in annex 3). We realized the algorithm to
generate these tables.
Linear cryptanalysis is to study the statistical linear relationships between a plaintext bits, the
bits of the ciphertext and key which allowed to encrypt. These relationships allow for some
bits of the key values when we know the plaintexts and ciphertexts associated.
It deduced the linear relationships of each S-table by choosing a subset of bits of input and
output bits, calculating parity (Xor) of these bits with parity of the subset is zero. In general, a
subset will be entries with parity 0 (linear) and others with parity 1 (affine).
MATSUI has calculated the number of zero-parities of each subset of input bits and output for
each S-table amongst the 64 x 16 = 1024 possible subsets. It is possible to associate different
probabilities to various bits of the sub-keys. Probabilities for a parity-zero (linear relationship)
are synthesized in 8 tables called Tables of linear approximations of a (see 8 tables in annex
4). We realized the algorithm to generate these tables.
Page 15
1.4 Applied neuro-Cryptography
After showing the possible association between neural networks and cryptography, we define
the field of neuro-Cryptography. All terms used in Cryptography must be preceded by the
particle "neuro" where the cryptosystem contains one or more networks of neurons or one or
more elements of the network as for example the perceptron.
We then analyze some important points for the correct use of neural networks.
How the basis of learning will be generated is very important for the realization of neural
applications. Learning depends on random initialization of weights the network as well as the
number of examples, the order of presentation of these examples then the consistency in the
choice of a set of examples.
An example is composed of a value to be presented at the entrance to the network of neurons
and a value to present output of this network, the value of output based on the input value. If
the number of examples is too low, it is clear that the network will not seek a transfer function
of the studied cryptosystem but will instead store the examples given and cannot therefore in
any way find a result for an input value different from those given in the basis of examples. In
cryptography to present more than half of all possible to be certain of the results examples
even if it is true that in strong cryptography, the number of possible input values is very large.
Then we realized an algorithm to present the examples in a more or less complete mess. It's
cutting the base k sub-bases then in turn present the elements of each of the sub-bases (k can
be even or odd). The following figure shows the error rate final Tss for k different values (the
number of presentation being fixed at 500 and 256 examples).
We note that the order of presentation of the basis of learning is not useful.
k 1 2 3 4 5 6 7 8
Tss 0,05 0,06 0,06 0,05 0,08 0,07 0,05 0,08
At the level of the automatic generation of contiguous texts, we present an algorithm that can
generate clear examples regardless of the number of nested loops to a single body of loop
which will be executed on each iteration of the innermost loop.
The coefficient of learning, usually noted Epsilon and also called learning rate, allows a more
or less rapid learning with opportunities for convergence of the network to an inversely
proportional solution due to local minima of the curve of error measured by the basis for
learning and values output calculated by the neural network. Should empirically vary Epsilon
between 0.1 and 2.0. If the network doesn't want any similarly converge, this is certainly due
to the problem of the non-linearly separable, which is the case of learning of the XOR. You
should then use a Momentum Term whose real value is between 0.1 and 1.0 and which will
aim to avoid local minima by deriving the error function because it allows to take into account
in the current step of learning from previous steps.
Page 16
Self-study can be interesting for neuronal learning of cryptographic algorithms. The neuronal
system has two parts: the emulator and the controller whose learning are carried out
separately.
The task of the emulator is to simulate the complex function or the encryption algorithm.
There therefore its entry State at any given time and an input at this time and its output is the
output of the algorithm to the following time. The input of the controller is the State of the
system at time k, its output is the value to be input to the algorithm or the function complex.
The proper role of the controller is to learn the law of adaptive control. But for this learning,
the error signal is not calculated on the order but on its result, the gap between actual
condition and current state. It comes to the idea of a guided rather than supervised learning
because no Professor learns the System Control Act. In fact, the system learns itself in dealing
with the information he receives in return for shares. To make possible learning through
backpropagation and retropropager error on the position, the structure of the emulator must be
homogeneous at the controller.
Another quality of this device is its ability to e-learning. Learning of the controller is fast. In
addition, the law of synthesized control is sufficiently robust to small random perturbations. It
is therefore possible to perform neural networks for self-learning on a line of communication
for encryption as for authentication of messages in real time.
We present several different applications.
On learning of the XOR, i.e. to achieve C = A XOR B, need us a network 16-bit input (i.e. 2
bytes A and B) and 8-bit output (a byte C). The network must therefore be 16 neurons input,
16 minimum layer (s) (s) hidden neurons and 8 output neurons. The broadcast consists of
65536 causes - effects. After various tests, the success to the XOR learning rate is very close
to 100% depending on the random weight initialisation and the number of submissions. More
the number of entries and hidden layer neurons are great, plus the number of presentations of
the base can be reduced. If the random initialization of the weight is correct, a single
submission can be sufficient and better quality.
The learning of cryptographic algorithms to determine a function or an algorithm for
combining data entries (causes) for output data (effects). It is therefore to determine input and
output of the network structures and to find a basis of causes and associated effects sufficient
to learning of the network converges to a minimal amount of errors, or even almost.
The question that arises is to know how to make the neural network can memorize the
algorithm. The answer is to present virtually all possible encryption keys (e.g. 64 bits) and all
possible plaintexts (e.g. 64 bits) input and calculate all resulting ciphertexts with the
encryption algorithm. Thus, the neural network will be synthesized algorithm since when it
presents him an encryption key and a plain text input, it will give us output the ciphertext
whereas.
Page 17
If the encryption algorithm is bijectif (that is, if are presented as input encrypted text it gets
output the plaintext) then the encryption algorithm is the same as the decryption algorithm
and the neural network also decrypts.
With regard to key learning, an encryption key must be linked to an encryption or decryption
algorithm and a clear or encrypted text.
If key has a fixed size of N -bit, should be N -bit output of the neural network and M bits input
equal to two times the number of bits of text blocks clear and encrypted text.
In fact, the neural network realizes a function that finds the key directly from a plaintext and
encrypted text.
We present then the advantages and disadvantages of the neuronal methods used. Learning of
neural networks time remains long enough on the basis of the number of bits of the key and
encrypted and clear texts, this time can be optimized if the neural network is implemented on
a parallel machine.
Regards memorizing keys and encryption algorithms, neural networks are high achievers with
over 90% success in learning of weak ciphers. A strong encryption algorithm, to rapid
learning. Neural networks are widely used in image recognition, it is so simple to perform
authentication. At the level of the hardware architecture, it is easy to parallèliser the
algorithms. As well as at the level of networks of neurons and ciphers based on hardware
architectures. But this solution is quite expensive. The design of neuro-ciphers can be useful
in cases where a secret key and an encryption algorithm are taught how to network to hide
information to the user, in particular, at the level of the key generator that could be kept secret
by a distributor body. It would be messy to a cryptanalyst to discover the function of the
generator algorithm of encryption keys. Neuro-cryptanalysis seems to be a lot more
application to neural networks due to their emergent properties of massively parallel statistical
analysis and their ownership of concentration of information or approximations of statistical
matrices.
An application of the most important of neuro-Cryptography is neuro-cryptanalysis. Neuro-
cryptanalysis is to perform the Cryptanalysis of cryptographic algorithms with the use of
neural networks. I.e. to achieve one or more neural networks to find or help find the key of an
encryption algorithm. The important principle is the presentation to the network of neurons a
ciphertext and the encryption algorithm.
In neuro-cryptanalysis, the neural network to help find the encryption key used in the cipher
text.
As a neural network can learn a cryptographic algorithm or can 'remember' (by a function
approximation) a set of keys. This neural network structure is identical to that of the self-
Page 18
study. It is clear that neural networks can take an important place in cryptography in the
design, use, and verification of protocols.
We test and present possible forms of neuro-as cryptanalysis.
To neuro-cryptanalyser a Vigenère figure, it would take that our neural network either a
frequency analysis or one analysis of a subset of n characters of a given language, and then
measure the correlation between the plaintext and the ciphertext learned for all subsets of n
characters. This type of problem is resolvable by a neural network but would be very long in
supervised learning. However, it is possible to carry it out in self-learning mode but the
ciphertext should be large enough.
We measure the performance of neural networks at the statistical level by neuro-differential
cryptanalysis and linear neuro-Cryptanalysis of des according to the following scheme:
These performances proved to be particularly good.
We then implemented a neuro-cryptanalyseur of the command of Unix crypt (3) or ufc_crypt
(ultra fast crypt), which is an implementation of the des used in the encryption of passwords
stored in the/etc/passwd file. It is a little special in the sense where the key is unknown to the
user, no one has the ability to perform decryption of password. This key is specific to the
Unix system in use. We thought it would be interesting to learn a certain amount of passwords
clear and encrypted passwords corresponding to a neural network. The basis of learning
should be large enough so the D.E.S. learning does not become a memorization of the
examples of this basis, what makes that the network would be unable to find the solutions to
other nearby examples of the database.
We have therefore made two applications. A UNIX (or GNU Linux) synthesizing the crypt
function of Unix for password clear of 4 characters whose values are a miniscule letter or a
point, a division, or about 615000 passwords bar and 2 hours of calculations per presentation.
The other is MS-DOS, she realizes learning 1024 clear passwords of 7 characters and
passwords encrypted in 11 characters (we remove the first 2 characters of salt used to re-
encrypt the password encrypted for 65536 encrypted different passwords for the same clear
text).
Page 19
We have added a visualization program of the first graphical statistics. The second provides
information quickly.
We can deduce the following results.
The neuro-crypanalyses differential and linear methods are methods of probabilistic
calculations to quickly get information about a part of des. They allow to perform the opposite
function of a S-table for a difference of texts chosen for one and for a linear relationship with
a subkey selected for the other. Such neural networks learning is very fast.
It is possible to gather for a method given, differential or linear, 8 x 16 = 128 neural networks
(one for each S-tablesnew each round) and to operate in parallel to the information given by
the ciphertext output of des to the plaintext input. Thus these networks may be supervisors of
other neural networks learning unsupervised amending the key bits that different texts pass
through the D.E.S.. Would be a self-learning of the sub-keys. From the sub-keys, we find the
encryption key.
Statistical analysis of the program under MS-DOS version results are surprising with 90% of
the encryption function for the base found by the network of neurons and about 80% of bits to
a close this basic example but not submitted to the network. This proves that for a low basis of
learning, it is easy to a neural network to find a clear password from a password encrypted
without taking into account the salt included by the Unix system.
We present then two architectures.
The first is a dedicated parallel architecture as a neuro-cryptanalyseur of strong ciphers needs
a very fast supervised learning. It is necessary to present all plaintexts, ciphertexts and keys to
the neural network. The following figure shows the overview of learning dedicated to an
encryption algorithm.
A complete machine can be constructed on the same pattern with a large number of units of
binary counters and circuits with the encryption algorithm. This number is limited by the time
of learning of the single neural circuit of approximately 1 s. It is preferable for the D.E.S.,
treat a fixed data subset as we have done in past applications.
In the second, we present our algorithms written to the distributed architecture of the CM-5
using 3 layers of processors with a processor for a neuron. The first is used to initialize (clear
text) input and output (ciphertext) of neural network which is located on layers 2 and 3. It is
likely that examples learning time is longer than for the dedicated machine of the preceding
paragraph.
Page 20
The performances are as follows:
learning time is quite long (from several days to several years), but interesting results (error
rate is close to zero) are available in short presentations when the basis of examples is large
enough (which is the case of algorithms strong such as D.E.S. or R.S.A. then for simple
operations such as the XOR it takes between 200 and 500 presentations to get an error rate
zero. Once the learning is done, the deadline for passage of information through the network
of neurons is very short (in the order of tens of nanoseconds). What is prodigious when we
know that it must repeat an exhaustive search for each text encrypted with a different key.
1.5 The memory map
Chapters 2 and 3 are organized so as to present the neural networks, cryptography in a clear
manner and define our choices in the direction of our research.
In Chapter 4, we define the neuro-cryptography, settings for well use it in the creation of
applications.
Chapter 5 presents the neuro-cryptanalysis from ciphers based on XOR and more complex
ciphers. The study of neuro-Cryptanalysis of des shows the performance of the neuro-
cryptographic applications. Different applications support our conclusions on the performance
of neural networks.
In Chapter 6 supplementary, we give various definitions to clarify certain points on which is
based the current cryptography: callbacks in information theory, complexity of algorithms and
number theory.
You will then find the bibliography, HTML pages on the Internet and an annex with source
codes and various documents.
Page 21
Chapter 2 - Neural networks
2.1 Introduction
In this chapter, after some necessary definitions, we define current means to link neural
networks to Cryptography. We present the neural network model used as well as learning the
most suitable to perform Cryptography. We describe then the algorithm and the benefits of
such a model, specifically, at the level of the linear multilayer network analysis to evaluate
their performance at statistical level. Then, we list various material aspects knowing that
learning must be the fastest possible.
2.2 Basic concepts and terminology
Called self-organization network a network of elements of simultaneously active treatment
(nodes and connections) with time-varying local interactions are the overall conduct of the
system. Among such networks, Connectionist models use digital information and are dynamic
systems that perform calculations similar to those of a neuron.
A Connectionist model is characterized by: a network (all nodes) connected by directed links
or connections, an activation rule (local procedure at each node updating activation level
based on their input and their common activation, each node performs this procedure in
parallel) and a rule for learning or adaptation (local procedure that describes how connections
vary over timemeaning that the weight of the connection is updated to reflect its current value
and levels of activation of the nodes it connects each node will perform this procedure in
parallel).
The concept of intelligence is an emergent property of its self-organization, it is an underlying
principle of this type of network.
Early neural networks have appeared in 1943 with logical MC CULLOCH neurons, they exist
various forms of networks.
Multilayer networks to flow of information towards the front are the most interesting. they
have an input layer, a layer of output and one or more hidden so-called intermediate layers
(figure 2.2.1).
input hidden ouput
Figure 2.2.1 - multilayer network to flow to the front
Page 22
There are 3 modes of possible learning: supervised, Non-supportive and strengthened.
Supervised learning is more suitable to store a cryptographic algorithm or to remember a set
of private encryption keys because this learning uses a Professor giving desired system inputs
and outputs.
Supervised learning is to present to the inputs and outputs of the network a database causes
and effects (unlike non-supervised learning where effects are not presented). Then asked the
network we calculate the outputs corresponding to cases presented in its entries. Then
measure the sum of the errors for each of the neurons in the network. We must continue to
present the basis of causes and effects until the measured error is almost nil.
Neural networks behave well where the basis is not complete because they 'mainstreamed',
that is, the information acquired is delocalized over the entire surface of the network. It is
important that the number of neurons and the number of hidden layers are selected based on
the number of entries in the network, the number of elements of the base to present and the
number of submissions.
Figure 2.2.2 presents the response of a neural network during the learning phase, we can see
how the error decreases as the presentations of the basis of causes and effects.
Figure 2.2.2 - Learning Phase
The other two modes of learning are best in automatic control and correction of errors.
For more detailed information, see (BOURRET 1991).
2.3 The situation presents
Currently used neurons or perceptrons are elements made up of a number of input and output,
each entry is weighted by an amplification function and the output is activated by the
comparison of the sum of the weighted inputs and the activation threshold.
You will find all the models of neural networks in figure 2.3.1. The detail of each of these
models as well as a complete description are contained in (MAREN).
You can consult the documents of authors of previous models: (GROSSBERG 1986) (HEBB,
1975), (HOPFIELD 1982), (KOHONEN 1984), (ROSENBLATT 1959), (RUMELHART
1986), (LIPPMAN, 1987) (MCCULLOCH 1943) and (WEISHBUCH 1989).
Page 23
Neural networks
and learning
Authors and dates Advantages / disadvantages
Set of Perceptrons with back-
propagation of the gradient
WERBOS, PARKER,
RUMELHART. 1987
Learning fast, low memory
Bidirectional associative
memory
KOSKO. 1987 Low storage capacity, slow
search.
CAUCHY machine CAUCHY. 1986
Brain-state-in-a-box
Self-Association memory
ANDERSON. 1977 Unknown performance.
HOPFIELD
Self-Association memory
HOPFIELD. 1982 Low memory.
KOHONEN
The learning vector
quantization
KOHONEN. 1981 slow learning, unknown number
of presentations.
Self-organization
Auto-organisatrices cards
KOHONEN. 1981 slow learning, unknown number
of presentations.
Figure 2.3.1 - models of neural networks
Among these networks should take to cryptography that allows us a quick learning with little
memory capacity because the purpose of the use of such a network is a transfer function
approximation or synthesis of cryptographic algorithms.
Perceptrons neural network has the advantage of being currently well known and to meet our
needs, it is easy to implement, and his performances are very interesting.
2.4 Neural networks are they used in Cryptography?
There are a few applications that have been studied in the context of the compression of
images or files and the identification of messages (completed application no) (PATHMA
1995). We believe that apart from secret military projects, no neural network is used for
encryption, decryption and cryptanalysis. However some students specialized in cryptography
in France and Belgium appear to be interested. But no literature or media contains information
on this subject.
2.5 What types of neural networks are used in Cryptography?
As we have seen in paragraph 2.3, the model of perceptrons with back-propagation of the
gradient is the most studied and demonstrated reliability with respect to the learning of the
XOR, these networks are simple to implement and have a fast learning.
Page 24
The advantages of the use of neural networks are:
their generalization property
their low sensitivity to noise (if an error sneaks into the basis of examples)
their low sensitivity to fault (lost connections, modified weight or bug in the program)
information are outsourced
Research of statistical calculations and heuristics capabilities
This model is more suited to the synthesis and looking for associations or recognition. In
addition, all States and the outputs of the neurons of these networks can be updated
simultaneously. (See the code in annex 1 of the learning of the XOR). A critique of learning
algorithms lets say our choice for this model: (CAMARGO 1990). Paragraph 2.8 show these
benefits specifically.
2.6 The model structure of perceptrons with back-propagation of the gradient
Figure 2.6.1 on the next page shows the structure of the model of perceptrons in back-
propagation of the gradient. There are input bits, the hidden layer, and the output layer. The
deltas of the hidden layer, those of the output layer and activations for learning.
The choice of the number of hidden layer neurons necessary must obey a compromise
optimizing learning avoiding the overfitting which would be the consequence of a too large
number of hidden units. This choice is often the result of know-how and practical experience.
It can be guided by statistical considerations.
Figure 2.6.1 - Structure du modèle de perceptrons à rétropropagation du gradient
This architecture can both be software (sequential single-processor computer program)
material (massively parallel machines). On CM-1, CM - 2 and MASPAR implementations
were realized, their performances have been measured (at paragraph 2.9)
2.7 The gradient back-propagation algorithm
This model is a multilayer network traffic it forwards (see figure 2.2.1).
Page 25
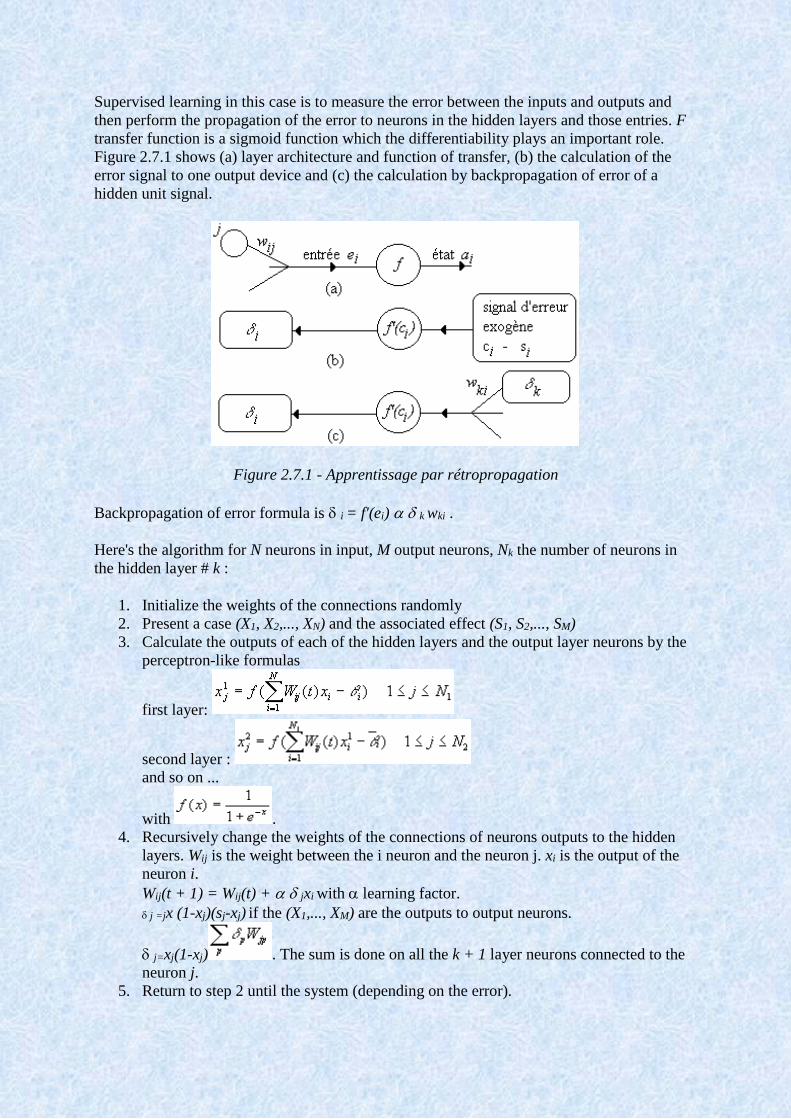
Supervised learning in this case is to measure the error between the inputs and outputs and
then perform the propagation of the error to neurons in the hidden layers and those entries. F
transfer function is a sigmoid function which the differentiability plays an important role.
Figure 2.7.1 shows (a) layer architecture and function of transfer, (b) the calculation of the
error signal to one output device and (c) the calculation by backpropagation of error of a
hidden unit signal.
Figure 2.7.1 - Apprentissage par rétropropagation
Backpropagation of error formula is i = f'(ei) k wki .
Here's the algorithm for N neurons in input, M output neurons, Nk the number of neurons in
the hidden layer # k :
1. Initialize the weights of the connections randomly
2. Present a case (X1, X2,..., XN) and the associated effect (S1, S2,..., SM)
3. Calculate the outputs of each of the hidden layers and the output layer neurons by the
perceptron-like formulas
first layer:
second layer :
and so on ...
with .
4. Recursively change the weights of the connections of neurons outputs to the hidden
layers. Wij is the weight between the i neuron and the neuron j. xi is the output of the
neuron i.
Wij(t + 1) = Wij(t) + jxi with learning factor.
j =jx (1-xj)(sj-xj) if the (X1,..., XM) are the outputs to output neurons.
j=xj(1-xj) . The sum is done on all the k + 1 layer neurons connected to the
neuron j.
5. Return to step 2 until the system (depending on the error).
Page 26
In the next parts of this memory, neural networks which is discussed will be networks of
perceptrons with back-propagation of the gradient.
Linear analysis of multilayer networks 2.8s
The success of the gradient back-propagation algorithm led researchers to analyze in detail the
process. They showed analogies with different statistical methods of analysis of data, in
particular linear regression and discriminant analysis. In this paragraph, we rely on
P.GALLINARI publications, F.FOGELMAN - SOULIÉ (GALLINARI 1988) that carry out a
comparison of the classical method of discriminant analysis and the linear multi-layer
perceptron (with a layer of hidden units). In the linear case, it is shown that the
backpropagation is a discriminant analysis of a population of N individuals (N being the
number of examples included in learning) described by n parameters (wheren is the number of
input neurons) and projected onto a hyperplane of dimension p (wherep is the number of
hidden units).
These results are then used to validate an incremental construction of the hidden layer. It is
thus shown that when we add a set of q hidden units, it is not necessary to repeat all the
learning, simply freeze the existing connections and make learning about connections relating
to units just to add. We can consider an incremental construction of the layer of hidden
neurons that saves a precious learning time but it means a variable structure.
The general interest of this approach is to show how comparison algorithms Connectionist
and classical methods suggests a permanent enrichment of the first allowing them to increase
their performance.
2.8.1 Problem of the linear perceptron multilayer
The perceptron is a supervised classification problem. The characteristics of the input number
is n (number of input devices). The number of classes is m (number of output neurons). The
number of examples of the basis of learning is N.
Assuming N > n > m which is the case of a reasonable classification problem.
Either X the matrix n x N of entries X = (x1,...,xN) and Y (m x N) matrix output imposed Y =
(y1,...,yN). The optimal linear classifier is the application of linear f space of entries in the
output space minimizing the quadratic distance there and fX. The problem is therefore to find
the matrix dimension M (m x n) minimizing are - MX 2 . The solution to this problem
is provided in the book (BOURRET, 1991, pages 189-212) by the Penrose pseudoinverse, it is
the matrix W = YX+. Although the quadratic error function is convex, the uniqueness of the
minimization problem is not ensured, there may be local minima.
The interest of the study is to analyse the linear multilayer case to approximate the behavior
of the back-propagation algorithm in the non-linear case (case of the XOR in Chapter 4). The
solution of the problem of minimization is the PW matrix where P is the projector onto the
subspace of Rm generated by the p vector own C=WXYt related to the p more large
eigenvalues.
Page 27
2.8.2 Discriminant analysis of rank p
Discriminant analysis of rank p is to find the best dimensional subspace p Rn such that the
classes of projections of vectors of input on these subspaces are best separated possible. It is
shown in (Bourret 1991) the following theorem: a problem of classification and M = HK optimal
achievement for the quadratic criterium of this classification by a linear perceptron with a layer
of p neurons hidden. Then K performs a discriminant analysis of rank p.
2.8.3 Incremental learning of the hidden layer
A serious gap in the gradient back-propagation algorithm is to apply that to a network already
structured and where the number of hidden neurons is fixed.
We can justify in (BOURRET 1991) the following procedure of incremental learning: the
learning algorithm is first applied to a network only with a minimum number of neurons in the
hidden layer. When we arrived at an optimal weighting of connections, the performance of the
network are not satisfactory, a hidden unit is added and the learning algorithm is applied only
to this neuron-related connections. The operation is repeated until a satisfactory performance.
Remember that beyond p = (W), it is pointless to increase the number of hidden neurons. The
role of hidden neurons is clear: each neuron detects a feature contributing to the classification.
These features are non-redundant (orthogonality of the eigenvectors) and their contribution to
the separation of the classes is decreasing (classification and module descending eigenvalues).
2.8.4 Relations with the principal component analysis
The back-propagation with p hidden neurons that projects data space dimension p
corresponding to that would be found by the principal component analysis. Moreover, in the
practice of the principal components analysis was built one by one these components in the
order of decreasing values of the modules of the eigenvalues of the covariance matrix of the
input data until the sum of these modules divided by the trace of the matrix reaches a fixed
threshold. The incremental construction of a back-propagation network to the same concern,
the corresponding threshold in this case meets the error observed on the outputs.
It can therefore be concluded that the results obtained by back-propagation could be through
more traditional methods of data analysis (discriminant analysis, principal components
analysis), this nearly the backpropagation occurs massively parallel. However, non-linearities
of the neural units make changes to the studied behavior. These observable changes by
numerical experimentation have been reported in (GALLINARI 1988). Notably, excess
neurons in the non-linear case instead of extract negligible surplus features in the classification
(orthogonality of the eigenvectors) behave like neurons from previous layers contribute to
robustness and improving the performance of the classifier.
2.9 Material
The physical aspect is very important for the cryptography because the implementation of
neural networks in VLSI (very large capacity for integration of transistors components) allows
faster and more suitable applications.
A large number of keys and text learning is faster.
Page 28
The most studied are numeric VLSI, the advantages are:
ease of use
the important signal-to-noise ratio
an easy-to-implement cascade circuit
a high adaptation (these circuits allow to solve various tasks)
a reduced price of manufacturing
For more details, it should read reports written by Dr. VALERIU BEIU for the implementation
and optimization of VLSI neural networks (BEIU 1995a), (BEIU 1995 b).
Figure 2.9.1 below shows comparison of different materials for the implementation of neural
networks.
Figure 2.9.1 - comparison of different materials
The network of neurons in VLSI implementation requires 4 blocks (see figure 2.9.2):
the summons (of the inputs of a neuron) with logical Adders
the multiplication (for weight) with parallel multipliers
the transfer function non-linear with a full circuit of calculation or table that contain
values of approximation of the function, or a circuit of calculation of approximations
(for the sigmoid with 1/5 steps and a error < 13%, just 4 comparators and a few logic
gates (ALIPPI 1990)).
memorization of values (S-RAM or D - RAM memories)
Page 29
Figure 2.9.2 - Circuit CMOS with 1024 synapses to distributed neurons
In regards to the backpropagation, NIGRI completed a circuit containing a table for all real
values of the sigmoid between-2 and 2 with 8-bit precision what is regarded as sufficiently
precise (NIGRI 1991).
Here are the three types of existing components on the market or research laboratory:
1. components dedicated to digital neural which speeds network go up to 1 GB of
connections processed per second
L-neuro Philips (Duranton 1988, 1989, 1990) *
X 1 and N64000 of Adaptive Solutions (Adaptive 1991, 1992; Hammerstrom 1990) *
Ni1000 Intel (Scofield, 1991; Holler 1992) *
p-RAM of King's College London (Clarkson 1989-1993) *
WSI's Hitachi (Yasunaga 1989, 1990, 1991) *
1.5-V chip (Watanabe1993) *
2. the digital coprocessors particular purpose (also called neuro-accelerators) are special
circuitry that can be connected to hosts (PCs or workstations), they work with a neuro-
simulator program. The mix of hardware and software aspects gives these benefits:
accelerated speed, flexibility and improved user interface.
Delta Floating Point Processor by SAIC (DARPA 1989) * connected to a PC
ANZA, Balboa Hecht - Nielsen Computers (Hecht-Nielsen 1991) * with a speed of the
order of 10 Mega-connections per second
implementations on RISC, DSP or Transputer processors
3. networks of neurons on massively parallel machines
WARP (Arnould 1985; Kung 1985, Annaratone 1987)*
CM (MeansE 1991) *
RAP (Morgan 1990; Beck 1990) *
SANDY (Kato 1990) *
Page 30
MUSIC (Gunzinger1992; Mueller 1995) *
MIND (Gamrat 1991) *
SNAP (Hecht-Nielsen 1991; Means R1991) *
GF-11 (Witbrock 1990; Jackson 1991) *
Toshiba (Hirai 1991) *
MANTRA(Lehmann 1991, 1993) *
SYNAPSE (Ramacher 1991a, 1991b, 1992, 1993;) Johnson1993a) *
HANNIBAL (Myers 1993) *
BACCHUS and PAN IV (Huch 1990; Pochmuller1991; Palm 1991) *
PE RISC (Hiraiwa 1990) *
RM-nc256 (Erdogan 1992) *
Hitachi WSI (Boyd 1990; Yasunaga 1989-1991) *
MasPar MP-1 (Grajski 1990; MasPar 1990 a - c;Nickolls 1990) *
CNS-1 (Asanovic 1993 b) *
For more information or the references of the machines above (with an asterisk), you can
consult (Beiu 1995 c).
You will find in annex 2 a set of electronics manufacturers who directed networks of neurons
in Silicon.
An implementation of the above mentioned algorithm has been developed on the Connection
Machine CM-2 (created by THINKING MACHINES Corp.) with a topology hypercube 64 k
processors, which gave 180 million interconnections calculated per second (IPS) or 40 million
weight updated per second.
Here is the performance measured by machine in interconnections calculated by seconds
(figure 2.9.3).
CM-2 180 millions
CRAY X-MP 50 millions
WARP (10) 17 millions
ANZA PLUS 10 millions
Figure 2.9.3 - performance of parallel machines
The use of such configurations would allow to obtain excellent results in learning of
cryptographic ciphers.
You will find in chapters 4 and 5 How to use the implementation of neural networks on the
Connection machine CM-2 or CM-5 in Cryptography.
We detail the functioning of the MASPAR machines CM-5 in annex 9.
Page 31
2.10 Conclusion
In this chapter, we see that the neural network model most interesting model is the perceptron
in back-propagation of the gradient and supervised learning is the most suitable. In addition,
the use of the networks of neurons in cryptography is very low and even very little known while
the study which has been made so far of neural networks allows to say that perceptrons networks
are able to learn to synthesize a transfer function fairly easily. They allow to give statistics, as
well as more traditional statistical methods, based on the values of entries making it very useful
in Cryptography. It also emerges that neural networks are currently at the level of hardware
implementing comprehensive enough and made at the industrial level. These networks can be
perfectly parallel and excessively fast.
Everything shows that should bind neural networks to cryptography, but what is Cryptography
appropriate? And what cryptographic tools use? The answers are the following chapters.
Page 32
Chapter 3 - Cryptography
3.1 Introduction
We give in this chapter of the important definitions to understand the continuation of our
work as well as clarification regarding the current situation of the world "known"
Cryptography then we describe the composition of cryptographic algorithms, weak and
strong. We specifically detail the D.E.S. because, after more than 20 years of existence, it
remains the most used and the most studied, especially at the level of its cryptanalysis which
is very difficult.
3.2 Definitions
Cryptography is the art of hiding (encrypt) messages.
A cryptosystem is a hardware or software system performing the cryptographic, it can
contain one or more encryption algorithms.
Cryptanalysis is the art of breaking codes or the cryptosystems, i.e. to find the key to
read all or part of the message.
Cryptology is the mathematical study of cryptography and cryptanalysis.
An original message is called plaintext or plaintext.
A resulting message is called cipher text.
An encryption key is a code to encrypt a plaintext.
A decryption key is a secret code to decrypt a ciphertext.
A private key allows the encryption and decryption, it must be secret.
A public key allows only encryption, it may be broadcast; only the person with the
associated private key can decrypt the message.
Is called exhaustive search the test of the set of all possible keys to find the
decryption key. Feel free to consult (FAQ 1996).
3.3 Contemporary Cryptography
Cryptography is a very large and popular area of mathematicians and computer scientists.
However, nowadays, cryptography is the study of more or less strong encryption of messages
or files and study of protocols to Exchange private networks and other means of
communication. Found in the study of ciphers, the means to find keys or decrease the
exhaustive search of keys: it is cryptanalysis.
3.3.1 The cryptosystem and strength
The strength of a cryptosystem lies in the used key and the algorithm of encryption (or digit)
if it is kept secret (which is reserved for the military).
The key size must be large (512, 1024 or 2048 bit is reasonable) so the distance of uniqueness
is great (see Chapter 6 supplementary) and the powerful key generator or secret.
The ciphertext should appear random to all standard statistical tests
The cryptosystem must withstand all known attacks.
Page 33
However, even if the cryptosystem meet the previous criteria, it cannot conclude that this
system is infallible!
The cryptosystems are of two types: public key or private key.
A cryptosystem private key K is defined by DK(= me CK(M)) = M where C is the function of
encryption and decryption function, M D a clear message and me the encrypted message.
3.3.2 Protocols
The protocols are a series of steps to human beings (at least two) to accomplish a task.
Cryptographic protocols allow participants to exchange secret information between them.
Applications using them are data communications, authentication, management of private and
public keys, cutting messages, mix of messages, access to databases, dating services,
subliminal messages, digital signatures, collective signatures, pledging, playing heads or tails,
playing poker blind evidence disclosure void, silver electronics and anonymous messages.
The best would be a protocol to intrinsic discipline because he himself would ensure the
integrity of the transaction (without intervenor or "arbitrator"), its construction would make
impossible challenges; There are no!
The study of the protocols is very documented in (SCHNEIER 95). We will attach in the
pages that follow to the neuronal development and neuro-Cryptanalysis of cryptosystems that
looking for protocols making it more secure exchange of information between participants.
3.3.3. The types of attacks in cryptanalysis
Cryptanalysis distinguishes between the following different types of possible attacks:
to ciphertext only : the attacker must find the plaintext having only the ciphertext. A
ciphertext attack is practically impossible, everything depends on the encryption.
to known-plaintext : the attacker has the plaintext and corresponding ciphertext. The
ciphertext was not chosen by the attacker but anyway the message is compromised. In
some cryptosystem, a pair of encrypted text - plaintext can compromise the security of
the system as well as the transmission medium.
to chosen plaintext : the attacker has the ability to find the ciphertext corresponding to
an arbitrary plaintext of his choice.
to chosen ciphertext : the attacker can arbitrarily choose and find the corresponding
unencrypted clear text. This attack may show weaknesses in the systems public key,
and even to find the private key.
to suitable chosen plaintext : the attacker can determine the ciphertexts of chosen
plaintexts in an iterative and interactive process based on the results previously found.
An example is the differential.
Some of these attacks can be interesting when they are used against ciphers strong. See (FAQ
96) and (SCHNEIER 95) for details of these attacks.
3.4 Cryptographic algorithms
3.4.1 The coding of blocks and the stream encoding
Page 34
In general, the plaintext M is divided into blocks of bits of fixed length: M =1M2M...MN.
Each Mi block is encrypted: Ci = Ek(Mi) and the result is added to the ciphertext C =12C C
...CN .
There are 2 main types of coding: coding blocks and the stream encoding.
In the coding of blocks, the size of a block must be high to prevent an attack: it is usual to use
64-bit to be 264 research opportunities. The transformation function T (M) = C is the same for
each block which can memory and goes relatively quickly to encode.
In the stream encoding, blocks are encoded sequentially and each block is encoded by a
separate transformation which depends on:
1. previous coded blocks, and/or
2. previous processing, and/or
3. the number of blocks
This information must be in memory between each coding of blocks. If the transformation
varies in each block, the block size can be short (usually between 1 and 8 bits).
The same clear text or message M won't give so necessarily the same ciphertext C.
Block coding is a coding of substitution in which the plaintext and ciphertext blocks are
binary vectors of length N. For each key, the encryption function EK(M) is a permutation of
the set {0,1}N to itself. DK (C) is the decryption function (inverse permutation) such as
DK(EK(M)) = EK(DK(C)) = identity.
There are 4 modes of encryption which are ECB, CBC, OFB, CFB
ECB mode (Electronic Code Book)
Ci = EK(Mi) and Mi = DK(Ci)
CBC mode (Cipher Block Chaining)
Ci = EK(Mi XOR Ci-1) and Mi = DK(Ci) XOR Ci-1
Page 35
OFB mode (Output FeedBack)
Vi = EK(Vi-1) and Ci=Mi XOR Vi
CFB mode (Cipher FeedBack)
Ci = Mi XOR EK(Ci-1) and Mi = Ci XOR EK(Ci-1)
Any encryption algorithm can be implemented in these modes.
In regard to our work, we will focus specifically on the ECB mode that most fits the learning
of neural networks with an input and an output of fixed-bit numbers and not loop re-inbound,
although it is possible to connect one or more networks of neurons in this way but learning
time would be quite longer.
3.4.2 The number of Vigenère
The only XOR based encryption algorithm is called Figure of Vigenère (the code is located
in the annex).
Encryption is performed between a clear M and a key of N characters:
1. M is divided into blocks of N characters
2. For each block, the XOR operation is performed between the block and the key.
Page 36
This algorithm is trivial has broken, if we accept that the characters are ASCII and the length
of the key is unknown:
1. You must first discover the key by a process called counting of coincidences
(FRIEDMAN 1920): compare the text encrypted to itself but shifted a given number
of bytes: count the number of identical bytes. If the two blocks of text put face to face
have been encoded with the same key, more than 6% of the bytes will be equal. If they
have been encoded with a different key so less than 0.4% of the bytes will be equal.
The smallest movement indicating a high coincidence is the length of the desired key.
2. Then he must offset the ciphertext of this length and apply the XOR between
ciphertext and thereby offset text. This operation removes the key and leave you with
the result of the XOR of the plaintext with itself shifted. The English language rate is
between 1 and 1.5 bit/letter, 1.2 for Shannon; the French is between 1 and 1.8 bit/letter
(see Chapter 6). There is enough redundancy to choose the correct decryption.
The code in C of this program is in the annex.
This figure is too low to be sure!
3.4.3 The strong figures
There are two kinds of strong encryption algorithms: only XOR operation between text and
code-based ciphers at base of very large prime numbers and others.
An example of the first case is the R.S.A. (RIVEST, SHAMIR and ALDEMAN) which is
PKI.
Here is the algorithm:
1. Decompose data into blocks of length equal to the length of the code word
2. Make a XOR between the block (modified by a given encryption) and code (key or
subkey encrypted)
3. Write the encrypted block
4. Repeat step 2 for each block
This algorithm is the same as almost all encryption algorithms, the differences come from the
generation of the keys to encrypt or decrypt.
In the R.S.A., it is necessary to generate codes (2 public codes and 3 secret codes) to encrypt
and decrypt, so the authors had to:
1. choose two large numbers p and q (512 bits),
2. make the product n = pq,
3. Choose randomly d first with (p-1)(q-1) between max(p,q) + 1 and n-1,
4. calculate e = d-1 modulo (p-1)(q-1).
This gives n and e public and p, q, d secret.
Page 37
The R.S.A. is based on the theory of numbers (see chapter V), in particular, the difficulty of
factorization of a number into its prime factors. Its effectiveness lies in the proliferation of
these factors. For more details on the R.S.A. should absolutely read (ALDEMAN 78).
PGP (Pretty Good Privacy) Zimmerman combines the RSA and the use of very long primes.
In the second case, it has the D.E.S. we describe in the next paragraph, it works with a private
key. (LUCIFER is the ancestor of REDOC II, SNEFRU, KHAFRE, IDEA, LOKI and
FEAL are of the same type and weaker algorithms that the of).
3.5 A reference: the Data Encryption Standard (des)
3.5.1 History
The algorithm of 1977, it was developed by the I.B.M. Corporation for the federal bureau of
standards of the United States, which has made the encryption standard for all exchanges of
confidential information (banking networks, smart cards, communications,...).
The D.E.S. combines conversions and substitutions in a product code which the safety level is
much higher than that of the two codes used base (text and key). These substitutions are non-
linear which produces a cryptosystem resistant to any cryptanalysis. He has also designed to
withstand differential cryptanalysis which was classified by the army and unknown to
researchers.
3.5.2 Architecture
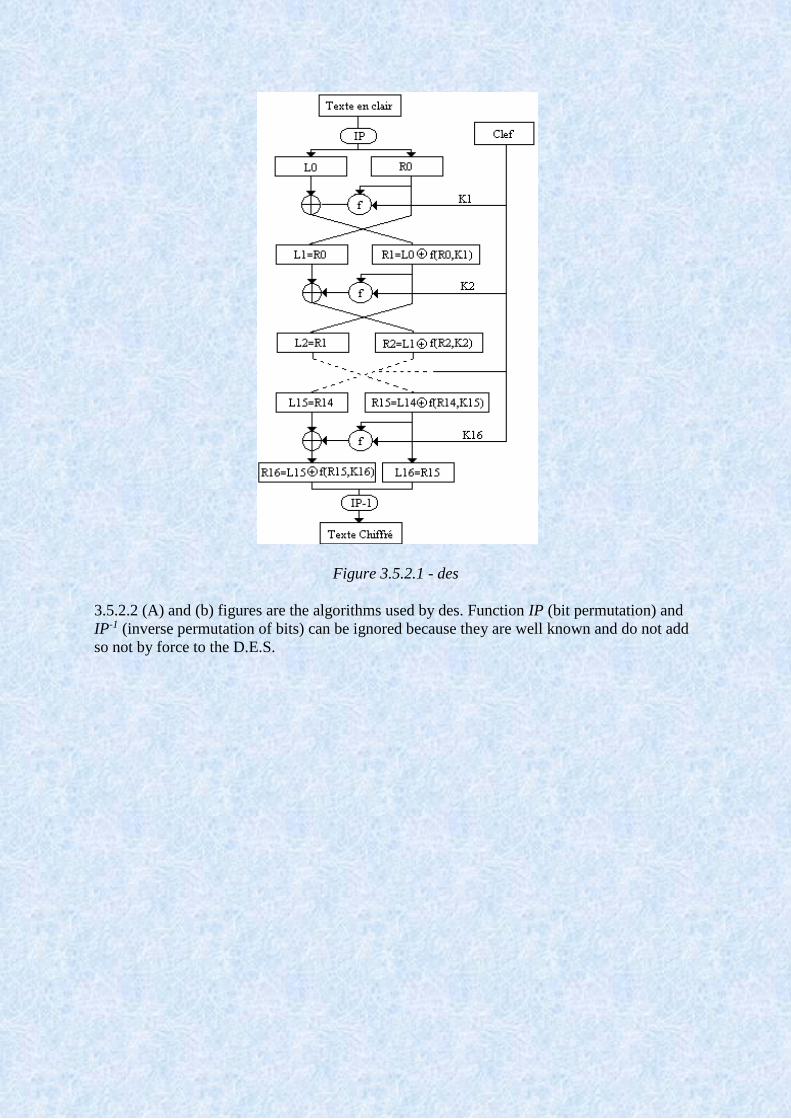
3.5.2.1 Below figure shows a graphical representation of the internal architecture of des. It
uses blocks of 64-bit input L0 and R0, the length of the key K is 56-bit (8-byte without the last
bit used for parity). This key will generate 16 48-bit different K1 to K16 sub-keys. Contrary to
appearances was very adequate and it is a little less these days because it takes 256 ciphers to
find the key with an exhaustive search.
The function f is called a round,i-th round receives inputs the right part Ri (or 32 bits of the text
to be encrypted) and the Ki subkey (48 bits). The rounds of des are detailed below. He gets out
of 32 bits that are added to Li. While Ri is passed as what Li + 1, the encrypted bits are
transmitted to Ri + 1 (except for the final round).
Page 38
Figure 3.5.2.1 - des
3.5.2.2 (A) and (b) figures are the algorithms used by des. Function IP (bit permutation) and
IP-1 (inverse permutation of bits) can be ignored because they are well known and do not add
so not by force to the D.E.S.
Page 39
We realize that all of the encryption is based on expansions, reductions and permutations of
bits. Apart from the round, these operations are linear.
Separation of the 16 sub-keys (48
bits per round) (56-bit) key
L, R: part low and high current text block
C (0), D (0) = PC1 (key) C, D: low and high compressed key
for(i = 0; i < 16;i++)) { PC1, PC2: permutation and key compression
C (i) = LS (i) (C (i-1)) LS: offset
D (i) = LS (i) (D (i-1)) IP: initial permutation (fig.II - 2 b)
K (i) = PC2 (i) (C (i), D (i)) IP-1 : inverse permutation (fig.II - 2 b)
} FP: Exchange (fig.II - 2 b)
3.5.2.2 Figure (a) - des algorithms
Coding of a block (64-bit) Decoding of a block (64-bit)
L (0), R (0) = IP (block plaintext) L (16), R (16) = IP-1(block ciphertext)
for(i = 0; i < = 16;i++)) { for(i = 0; i < = 16;i++)) {
L (i) = R (i-1) R (i-1) = L (i)
R (i) = R (i-1) ^ f (R (i-1), K (i)) L (i-1) = R (i) ^ f (L (i), K (i))
block cipher text = FP (R (16), L (16)) block plaintext = FP (L (0), R (0))
} }
3.5.2.2 Figure (b) - des algorithms
The D.E.S. combines 2 mathematical techniques: confusion and dissemination (see Chapter
6). The round f apply the text substitution (8 S - boxes or S-tables) followed by a permutation
(P-boxing or P-table) based on the text and the key.
3.5.2.3 Figure which follows presents the synopsis of a round (the function f).
Page 40
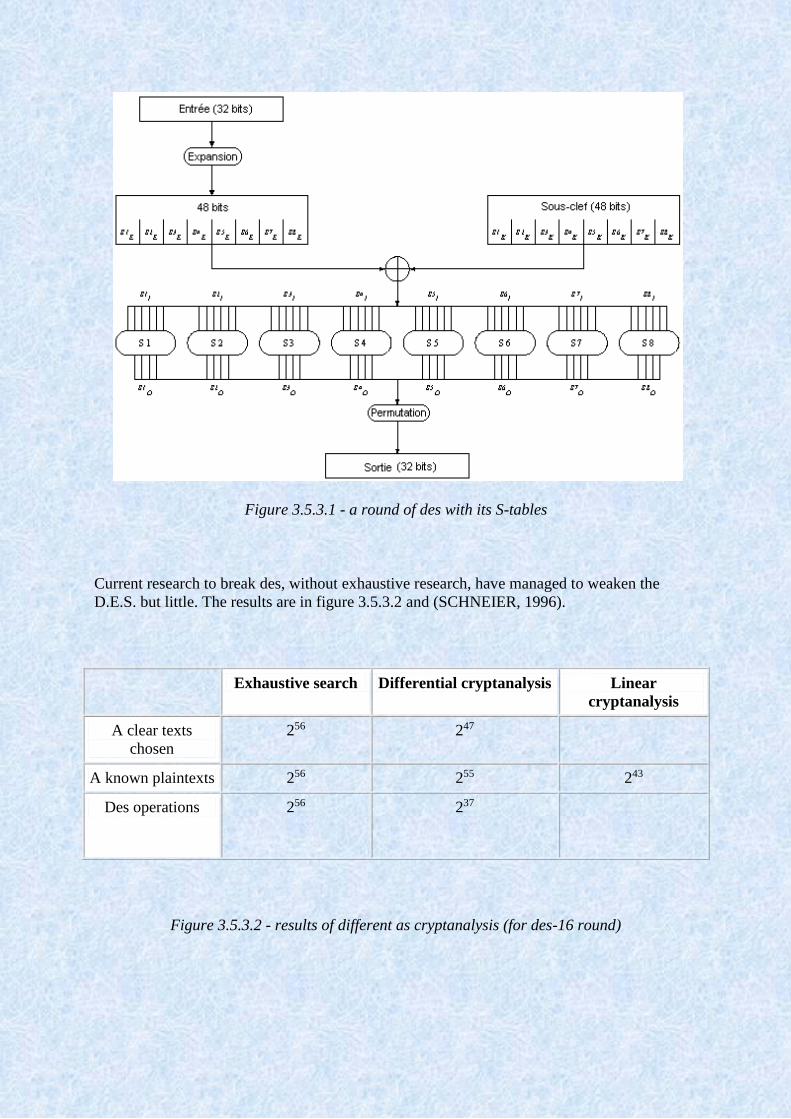
Figure 3.5.2.3 - a f round of the DES
The content of this round is otherwise presented in figure the following paragraph 3.5.3.1.
Various standards have emerged to standardize the exchange of encrypted information D.E.S.;
ANSI standards references are X3.92.digital: D.E.S., X3.106: modes of operation, X3.105:
network, X9.19: authentication, X9.24: distribution of keys; the references of standards of the
Federal standard are 1027 and 1028.
3.5.3 Cryptanalysis
3.5.3.1 Figure following shows the architecture of a round with its S-tables which, unlike
other operations, are more or less mi-lineaires/mi-affines. If they were completely ripened,
des would be very easy to break, but they have been selected to withstand attacks. The subkey
bits, and those of the once expanded text block are added, and substituted through S-tables
then swapped.
Page 41
Figure 3.5.3.1 - a round of des with its S-tables
Current research to break des, without exhaustive research, have managed to weaken the
D.E.S. but little. The results are in figure 3.5.3.2 and (SCHNEIER, 1996).
Exhaustive search Differential cryptanalysis Linear
cryptanalysis
A clear texts
chosen
256 247
A known plaintexts 256 255 243
Des operations 256 237
Figure 3.5.3.2 - results of different as cryptanalysis (for des-16 round)
Page 42
There are two types of cryptanalysis: differential cryptanalysis and linear cryptanalysis are
described in paragraph 3.6.
The complete and commented code in C to the D.E.S. is located in Appendix 1.
3.5.4 The physical aspect
The physical aspect is very important for the speed of execution. The VLSI components are
very widespread and effective but there are even more interesting technology-based
components that should not be disregarded: the Gallium Arsenic (GaAs) or arsenide
technology. It has already been included in supercomputers.
The major differences between GaAs and VLSI are:
Fast failover of the GaAs doors
The Exchange with components other than GaAs is a major difficulty
Very small density of GaAs integrated circuits
The GaAs (DCFL E/D-MESFET) Gates times are less than or equal to 50 picoseconds, while
it takes at least a nanosecond in Silicon (NMOS).
The access time to memory RAM GaAs takes approximately 500 picosecond and 10
nanoseconds in Silicon. This indicates that the performance of computers based on the GaAs
technology should be 20 times higher than the fastest silicon-based supercomputers. On the
other hand, the level of integration GaAs is of about 50,000 transistors per integrated circuit
while it is 1 million in Silicon due to the problem of heat dissipation. This problem is greater
the number of GaAs circuits required to design a computer and a high-performance computer
is to optimize the number of circuits integrated on the motherboard.
GaAs circuits with outside communication is another factor. The problem is the downturn
forced by other components. However, the signal propagation is not very different between
silicon and GaAs. The only solution to solve this exchange rate is to introduce a memory with
a multi-level hierarchy. However it does not exist for the moment which works with the GaAs
technology.
Although the GaAs technology cannot be fully exploited for the moment, it is certainly a very
interesting technology of the future for the Cryptography due to its excellent performance. If
the CM - 2 has its equivalent in arsenide, is the property of the military.
With regard to the D.E.S., there is a circuit running at 50 MHz performing encryption in 20
ns, which allows to make 50 million of ciphers in a second.
Since late 1995, AMD sells a circuit encrypting at 250 MHz.
In August 1993, the Canadian Michael J. WIENER described how to build a machine for $ 1
million that performs a comprehensive search of des keys to find the right key in 3.5 hours.
Each of its basic circuits has power equivalent to 14 million stations SUN.
See (WIENER 1993) for more details on this machine.
Page 43
It seems so obvious that the exhaustive search is faster to perform types of cryptanalysis
because even if the number of attempts is less, the search time is much longer, cryptanalysis is
still very interesting to measure the performance of cryptographic algorithms.
You will find in annex 9, the characteristics of the MASPAR machines CM-5.
3.6 The Cryptanalysis of des
3.6.1 Differential cryptanalysis
It is an attack to clear texts chosen on the rounds of des to find the key. (the presentation of
the various attacks was made in paragraph 3.3.3 In 1990 and 1991, Eli BIHAM and Adi
SHAMIR create differential cryptanalysis, this method is to look at the specifics of a pair of
ciphertexts for a pair of plaintexts with a particular difference.
Differential cryptanalysis analyzes the evolution of these differences when the plaintexts
spread through rounds of DES to be encrypted with the same key.
After randomly choosing a pair of plaintexts with a difference set, calculate the difference in
the resulting ciphertexts. Using these differences, it is possible to associate different
probabilities to various bits of the sub-keys. Plus a large number of ciphertexts is analyzed,
most most likely encryption key will emerge.
Force of the resident in his rounds and all operations of a round being completely linear
except S-tables (or S-boxes), Eli BIHAM and Adi SHAMIR analyzed 8 S-tables for text input
differences and differences in output texts, these information are synthesized in 8 tables called
Tables of distribution of differences of of (see the 8 tables in annex 3). We realized the
algorithm to generate these tables in figure 3.6.1.1. P is a plaintext, P* is another clear text, X
is the encrypted text of P, X* is the encrypted text of P*, P' is the difference of P and P*, X' X
and X*
Page 44
Initialize the Table boxes to 0
For t = 1 to 8 do / / number of S-table
For P = 0 to 63 To
For P*= 0 to 63 To
P'= P xor P*
X = S-tablet(P)
X*= S-tablet(P)*)
X'= X xor X*
Tablet[P'] [X'] = Tablet[P'] [X'] + 1
End for
End for
End for
Figure 3.6.1.1 - distribution tables generation algorithm
Once these tables is generated, pictured in figure 3.6.1.2 on next page it is possible to have
information about B ( B = B xor B *) according to C ( C = C xor C *). So for a has
known text ( A = A xor A *), the combination of A and C suggests bit a xor Ki values
and has ' xor Ki which allows to have information on a few bits of the Kt subkey.
With this information, it is possible to overlook a large number of chosen plaintexts.
Page 45
Figure 3.6.1.2 - a round of the analyzed
The likelihood of having a pair of inputs P' S-table on the basis of a pair of outputs X' is p=
Table [P'] [X'] / 64. I recall that E is the permutation of the round and P the toggle function
function.
You will find the program of generation of tables of distributions of the differences in annex
1.
This attack also works fine on FEAL, IDEA, LOKI, REDOC II, SNEFRU, KHAFRE and
LUCIFER. For more information, you can consult (BIHAM 1991), (BIHAM 1993a) and
(BIHAM 1993b).
3.6.2 Linear cryptanalysis
It is an attack to clear texts known on the rounds of des to find the key.
It was in 1993 that Mitsuru MATSUI created linear cryptanalysis, this method is to study the
statistical linear relationships between a plaintext bits, the bits of the ciphertext and key which
allowed to encrypt. These relationships allow for some bits of the key values when we know
the plaintexts and ciphertexts associated.
It deduced the linear relationships of each S-table by choosing a subset of bits of input and
output bits, calculating parity (Xor) of these bits with parity of the subset is zero. In general, a
subset will be entries with parity 0 (linear) and others with parity 1 (affine).
MATSUI has calculated the number of parity zero of each subset of bits of input and output
for each S-table amongst the 64 x 16 = 1024 possible subsets. is possible to associate different
probabilities to various bits of the sub-keys. Probabilities of obtaining parity zero (linear
relationship) are synthesized in 8 tables called Tables of linear approximations of a (see 8
tables in annex 4). We realized the algorithm to generate these tables in figure 3.6.2.1. P is a
plaintext, C is the text encrypted p, K is a subkey.
Page 46
For t = 1 to 8 do / / number of S-table
ForP = 0 to 63, do
For C = 0 to 15 do
Table [i] [j] = - 32 / / remove half
For K = 0 to 63, do
PA = (parity(S-tablet(K) & C) + parity(K & P)) & 1
If (AP == 0) ThenTable [i] [j] ++;
End for
End for
End for
End for
Figure 3.6.2.1 - linear approximations tables generation algorithm
Once these tables is generated, if a box of the table is set to 0 then the probability is (32/64 -
Tableij64) and this information cannot be exploited to attack des. on the other hand, if the
value of this checkbox is non-zero, we have a linear relationship of probability p = 1/2 -
Tableij64 on having the Kt subkey bits based on the bits of output of the S-table t.
You will find the program of generation of tables of linear approximations in annex 1.
You can consult (MATSUI 1994) and (harp, 1995). In (SCHNEIER, 1996), we learn that
searches are performed by combining differential cryptanalysis and linear cryptanalysis.
3.7 Conclusion
In this chapter, you have seen a terminology and a set of points on which it is interesting to
consider neuro-cryptography, especially in the study of their as cryptanalysis and encryption
algorithms, in means of hardware and software of the Cryptography implementation. The des
and its cryptanalysis, study with neural network architecture should prove their effectiveness
of memorization and probabilistic research for complex encryption algorithms. Found in the
following chapters of the theories and applications implemented to prove these theories.
Page 47
Chapter 4 - Neuro-Cryptography
4.1 Introduction
In this chapter, we define the possible association between neural networks and
Cryptography. We then present the neuro-Cryptography as well as the range of possible
applications to perform encryption, decryption and Cryptanalysis of a chosen algorithm. Also
found in this chapter the formation of a learning base and different parameters related to the
learning of ciphers and discuss self-study as part of a line of communications information
control applications.
4.2 Can we bind Cryptography and Neural networks?
The two preceding chapters show that although that this has not been done (or made by the
military confidentially), neural networks can be useful in Cryptography. Learning of neural
networks must still be optimized and fast. On the other hand, the use of the once-trained
network is excessively fast and efficient.
To achieve satisfactory applications for learning a strong figure, must be a great execution
speed. This implies that used neural networks must be implemented in parallel hardware
architecture as cryptographic algorithms. Nevertheless, it is possible to create software
applications on data smaller to get results more quickly.
Low numbers can be simulated on a PC. The problem arises when you want to associate a
cryptographic algorithm with a neural network in a unique parallel architecture without
wasting time in Exchange for information. You can make applications on strong ciphers but
not a general point of view, i.e. the entire algorithm, it is better in this case to simplify the task
by working on small parts of the algorithm whose complexity is reduced. In addition, can
ignore completely linear or completely affine functions and endeavour to weaken the other
functions through the neural network synthesis facility.
4.3 The new definitions
It comes to define the field of neuro-Cryptography. All terms used in Cryptography must be
preceded by the particle "neuro" where the cryptosystem contains one or more networks of
neurons or one or more elements of the network as for example the perceptron.
4.3.1 Neuro-encryptionor neuro-encryption
It is the action of encrypting it with a cryptosystem with a hardware or software architecture
based on the functioning of neural networks.
4.3.2 Neuro-decryptionor neuro-decryption
It is the action of decipher with a cryptosystem with a hardware or software architecture based
on the functioning of neural networks.
Page 48
4.3.3 The neuro-generator
A neuro-generator is a generator of all or part of a public or private encryption key with a
hardware or software architecture based on the functioning of neural networks.
4.3.4 Neuro-cryptanalysis
Neuro-cryptanalysis is the Cryptanalysis of a cryptosystem using a hardware or software
architecture based on the functioning of neural networks and neuro-cryptanalyseur the way to
the neuro-cryptanalysis. Chapter 5 is completely devoted to neuro-cryptanalysis and its
applications, in particular, at the level of a strong cipher like des.
4.4 The generation of bases of learning
How the basis of learning will be generated is very important for the realization of neural
applications. Learning depends on random initialization of weights the network as well as the
number of examples, the order of presentation of these examples then the consistency in the
choice of a set of examples.
4.4.1 Examples
An example is composed of a value to be presented at the entrance to the network of neurons
and a value to present output of this network, the value of output based on the input value.
If the number of examples is too low, it is clear that the network will not seek a transfer
function of the studied cryptosystem but will instead store the examples given and cannot
therefore in any way find a result for an input value different from those given in the basis of
examples.
In cryptography to present more than half of all possible to be certain of the results examples
even if it is true that in strong cryptography, the number of possible input values is very large.
4.4.2 Order of presentation
If all possible examples are in the basis of learning, i.e. If for N input neurons there are 2N- 1
examples presented, it is not necessary to present the examples in the order of generation (in
general, ascending).
We conducted an algorithm to present the examples in a more or less complete mess. It's
cutting the base k sub-bases then in turn present the elements of each of the sub-bases (k can
be even or odd).
The following algorithm uses n for the total number of examples of the basis for learning and
p for the current addressing element, it returns the index of the sample to the neural network:
Page 49
Begin
d =Integer(p * k/n);
return ((p- Integer(d*n/k)) * k) + d;
End
Figure 4.4.2.1 - choice of an example in one of the sub-bases k
This mathematical formula is trivially demonstrated by recurrence because it is a suite of
discrete values.
The C source code is located in Appendix 1 (learning of the XOR in the mess). 4.4.2.2 Figure
shows error rates end Tss for k different values (the number of presentation being fixed at 500
and 256 examples).
We note that the order of presentation of the basis of learning is not useful.
k 1 2 3 4 5 6 7 8
TSS 0.05 0.06 0.06 0.05 0.08 0.07 0.05 0.08
Figure 4.4.2.2 - error for a disordered presentation rate
4.4.3 Automatic generation of texts
To generate a regular automatic learning basis, i.e. following an alphabet given by generating
all possible examples in the order must be a N characters in input to the encryption algorithm
N nested loops to a single body of loop which will be executed on each iteration of the
innermost loop as shown in figure 4.4.3.1 for an alphabet of P characters.
The body of loop retrieves the values of the counters and generates a plain text (one character
of the text by meter), this text is encrypted by an encryption algorithm which gives an
example (plaintext - ciphertext) to present to the neural network.
Page 50
For compteur1 = 0 to P-1 do
For compteur2 = 0 to P-1 do
For counterN= 0 to P-1 do
Corps(compteur1,compteur2,...,compteurN ))
End
End
End
Figure 4.4.3.1 - loops nested for the generation of ordained texts
The algorithm we present in 4.4.3.2 figure to generate clear examples regardless of the
number of nested loops N :
/ * Initialize loop counters and values of end conditions */
For b = 0 to N do i_bcl [b] = 0;End
For b = 0 to N do f_bcl [b] =P-1. End
/ * Execute the nested loops *
Repeat to infinity
b=N -1;
If (Body (i_bcl) ==true) Then exit;
If (i_bcl [b] < f_bcl [b]) then i_bcl [b] ++;
Else
Label _precedent:
i_bcl [b] = 0; / * Reset the counter to 0 * /
If(b== 0) Then exit; Otherwise b-;
If (i_bcl [b] < f_bcl [b]) Then i_bcl [b] ++; else go to
_precedent;
End else
End repeat
Page 51
Figure 4.4.3.2 - variable nested loops for the generation of ordained texts
In this case, the body function has arguments the values of the counters of loops and return a
Boolean value to indicate whether or not exit loops. b is the value of the current loop. An
example of C source code is located in Appendix 1 (Automatic Generation of basis for
learning of des).
4.4.4 The coefficient of learning
This coefficient, generally noted Epsilon and also called learning rate, allows a more or less
rapid learning with opportunities for convergence of the network to an inversely proportional
solution due to local minima of the curve of error measured by the basis for learning and
values output calculated by the neural network.
Should empirically vary Epsilon between 0.1 and 2.0. If the network doesn't want any
similarly converge, it is certainly due to the problem of the non-linearly separable, which is
the case of learning of the XOR. Should then use a Momentum Term whose real value is
between 0.1 and 1.0 and which will aim to avoid local minima by deriving the error function,
meaning that it allows to take into account in the current step of learning from previous steps.
4.5 Self-learning
Self-study can be interesting for neuronal learning of cryptographic algorithms. The neuronal
system consists of two parts the emulator and the controller whose learning are carried out
separately.
The task of the emulator is to simulate the complex function or the encryption algorithm.
There therefore its entry State at any given time and an input at this time and its output is the
output of the algorithm to the following time. Learning is done by presenting every moment a
different input (figure 4.5.1).
Figure 4.5.1 - learning a complex function or an algorithm
Once completed the learning of the emulator, it is connected to the controller (figure 4.5.2).
Page 52
Figure 4.5.2 - learning of the controller through the emulator
The input of the controller is the State of the system at time k, its output is the value to be
input to the algorithm or the function complex. The proper role of the controller is to learn the
law of adaptive control. But for this learning, the error signal is not calculated on the order but
on its result, the gap between actual condition and current state. It comes to the idea of a
guided rather than supervised learning because no Professor learns the System Control Act. In
fact, the system learns itself in dealing with the information he receives in return for shares.
To make possible learning through backpropagation and retropropager error on the position,
the structure of the emulator must be homogeneous at the controller.
Another quality of this device is its ability to e-learning. Learning of the controller is fast. In
addition, the law of synthesized control is sufficiently robust to small random perturbations.
It is therefore possible to perform neural networks for self-learning on a line of
communication for encryption as for authentication of messages in real time.
4.6 The realization of applications
4.6.1 The learning of the exclusive or (XOR))
The XOR is a simple operation that is particularly used in Cryptography. 4.6.1.1 Figure below
represents its truth table with a, b and c binary, c being the sum without restraint of a and b.
The purpose of this paragraph is to show that the XOR is easily achievable and that all of the
XOR-based cryptographic applications are feasible with one or more networks of neurons.
You will find how cryptanalyser a single digit XOR-based on 64-bit in Chapter 3.
a b c
0 0 0
0 1 1
1 0 1
1 1 0
Figure 4.6.1.1 - Table of truth of the XOR
Page 53
To achieve C = A XOR B, need us a network 16-bit input (i.e. 2 bytes A and B) and 8-bit
output (a byte C). The network must therefore be 16 neurons input, 16 minimum layer (s) (s)
hidden neurons and 8 output neurons. The broadcast consists of 65536 causes - effects.
You can find the code in C of this network in annex 1. (The coefficient of learning is referred
by EPSILON). The rate of success at learning of the XOR is very close to 100% depending on
the random weight initialisation and the number of submissions.
More the number of entries and hidden layer neurons are great, plus the number of
presentations of the base can be reduced. If the random initialization of the weight is correct, a
single submission can be sufficient and better quality.
The table in annex 8 the measurement error rate for each presentation.
4.6.2 The learning of cryptographic algorithms
Just as the previous paragraph, to determine a function or an algorithm for combining data
entries (causes) for output data (effects).
It is therefore to determine input and output of the network structures and to find a basis of
causes and associated effects sufficient to learning of the network converges to a minimal
amount of errors, or even almost.
Any encryption algorithm consists as in figure 4.6.2.1.
Figure 4.6.2.1 - synoptic of an encryption algorithm
The question that arises is to know how to make the neural network can memorize the
algorithm. The only answer is to present virtually all possible encryption keys (e.g. 64 bits)
and all possible plaintexts (e.g. 64 bits) input and calculate all resulting ciphertexts with the
encryption algorithm.
Thus, the neural network will be synthesized algorithm since when it presents him an
encryption key and a plain text input, it will give us output the ciphertext whereas.
If the encryption algorithm is bijectif (that is, if are presented as input encrypted text it gets
output the plaintext) then the encryption algorithm is the same as the decryption algorithm
and the neural network also decrypts.
Page 54
Initialize the network weights randomly
Repeat
for each key make
for each text make clear
Encrypt the plaintext with key
Initialize the network with the clear text entries
Calculate the outputs of the network
Initialize the outputs of the network with the cipher text
Calculate the deltas of the network
Change the weight of the network
Measure the error of the network
end for
end for
until the error is almost nil
Figure 4.6.2.2 - learning algorithm
4.6.2.2 Figure presents the learning algorithm regardless of the "Encrypt" function which
computes the ciphertext from the provided clear text.
If the number of bits of the plaintext is 64 and the key is 56, gives us 2120 examples to present
to the network of neurons, which may be huge in calculation time if the encryption function is
long.
Hence the importance of the physical aspect and dedicated architectures.
Various applications can be carried out, including the Cryptanalysis of des, that you can see in
Chapter 5 of this memorandum.
4.6.3 Key learning
A single encryption or decryption key has no meaning, it must be linked to an encryption or
decryption algorithm and a clear or encrypted text.
If key has a fixed size of N bits, then N bits in the neural network outputs and M bits input
equal to two times the number of bits of the plaintext and ciphertext blocks.
Page 55
4.6.3.1 Figure shows text input and the output key:
Figure 4.6.3.1 - memorization of key
In fact, the neural network realizes a function that finds the key directly from a plaintext and
encrypted text.
4.7 The advantages and disadvantages
Learning of neural networks time remains long enough on the basis of the number of bits of
the key and encrypted and clear texts, this time can be optimized if the neural network is
implemented on a parallel machine.
In regards to memorizing keys and ciphers, neural networks are high achievers with over 90%
success in learning of weak ciphers. A strong encryption algorithm, to rapid learning.
Neural networks are used extensively in recognition of images, it is so simple to perform
authentication.
At the level of the hardware architecture, it is easy to parallèliser the algorithms. As well as at
the level of networks of neurons and ciphers based on hardware architectures. But this
solution is quite expensive financially.
The design of neuro-encryption can be useful in cases where a secret key and an encryption
algorithm are taught how to network to hide information to the user, in particular, at the level
of the key generator that could be kept secret by a distributor body. It would be messy to a
cryptanalyst to discover the function of the generator algorithm of encryption keys.
Neuro-cryptanalysis is an application much more adapted to neural networks due to their
emergent properties of massively parallel statistical analysis and their ownership of
concentration of information or approximations of statistical matrices. Chapter 5 on neuro-
cryptanalysis should enlighten you about the possibilities of neural networks.
In addition, over a problem cryptographic complexity class of P-SPACE requiring a very
large capacity memory, Neuron network is compact and its size is fixed.
4.8 Conclusion
We have defined in this chapter, the association of two broad areas of Artificial Intelligence
neural networks and contemporary Cryptography. We presented the neuro-Cryptography as
well as the range of applications possible to perform encryption, decryption and Cryptanalysis
of a chosen algorithm. Also found in this chapter the formation of a learning base and
different parameters related to the learning of ciphers and discuss self-study as part of a line
of communications information control applications. Learning of a strong encryption
Page 56
algorithm being quite long and requiring the use of parallel machines, to use neural networks
to synthesize an encryption algorithm with a given key, this algorithm and this key being kept
secret for example by a distributor body.
Page 57
Chapter 5 - Neuro-cryptanalysis
5.1 Introduction
In this chapter, we present the neuro-Cryptanalysis of strong encryption, the general principle
being the search for key by a neural networks-based study, whether learning the functions of
the texts clear and encrypted keys. Then we describe applications. We present differential
neuro-cryptanalysis and linear neuro-Cryptanalysis of des, allowing us to measure the
statistical performance of neural networks. A dedicated hardware application is described as a
last resort.
5.2 Definition
Neuro-cryptanalysis is to perform the Cryptanalysis of cryptographic algorithms with the use
of neural networks. I.e. to achieve one or more neural networks to find or help find the key of
an encryption algorithm.
The reader will find in Chapter 3 an introduction to applications in neuro-cryptanalysis.
Neuro-cryptanalyseur means then a system performing the Cryptanalysis of a cryptographic
algorithm, this system is a hardware or software program containing at least a neural network
useful in cryptanalysis in question.
5.3 General principle
The important principle is the presentation to the network of neurons a ciphertext and the
encryption algorithm.
In neuro-cryptanalysis, the neural network must help find the encryption key used in the
cipher text, figure 5.3.1 shows a possible architecture of neuro-cryptanalyseur.
Figure 5.3.1 - Overview of neuro-cryptanalyseur
According to Chapter 2, a neural network can learn a cryptographic algorithm or can
'remember' (by a function approximation) a set of keys, I therefore infer that the neuro-
cryptanalyseur can be broken down into 2 subnets of neurons as follows:
Figure 5.3.2 - a neuro-cryptanalyseur learning
Page 58
This neural network structure is identical to that of self-learning in paragraph 4.5.
Applications carried out in the following paragraph will allow to check learning described in
Chapter 2.
It is clear that neural networks can take an important place in cryptography in the design, use,
and verification of protocols presented in Chapter 3.
5.4 Applied Neuro-cryptanalysis
5.4.1 Neuro-Cryptanalysis of the Vigenère
This figure, as well as its cryptanalysis are explained in paragraph 3.4.2.
To neuro-cryptanalyser such a algorithm, should our neural network performs either a
frequency analysis or one analysis of a subset of n characters of a given language, and then
measure the correlation between the plaintext and the ciphertext learned for all subsets of n
characters.
This type of problem is resolvable by a neural network but would be very long in supervised
learning. However, it is possible to carry it out in self-learning mode but the ciphertext should
be large enough.
5.4.2 The Neuro-differential cryptanalysis of DES
Differential cryptanalysis is described in Chapter 3.6.1.
To better understand the information given by the tables of differences by BIHAM and
SHAMIR distributions, we have generated for each S-table, the tables with x-axis values of
outputs of the S-table and ordered the bits of S-table entries. These tables are in Appendix 5, it
can therefore be directly see the probabilities p= Table [P'] [bits of X'] / 64 to have any
particular bit depending on the value of output.
-What is presenting pairs of plaintexts input and pairs of ciphertexts in output of an S-to a
neural network, would be close probability or no previous tables for each of the input bits?
We have to create a network of neurons with 16 input bits (each of these bits is a value of
output among the 16 who are the category of preceding tables) and 6 output neurons giving
the probability of having a 1 on one of the 6 bits of S-table entries.
Figure 5.4.2.1 - use of the differential neuro-cryptanalyseur
Page 59
For examples using learning algorithm and realization of this neural network, you can read the
code C in annex 1. 5.4.2.1 Figure presents the neuro-cryptanalyseur after learning, it returns
information about the probability of having one bit to 1 of P' . One gets not directly of
probabilities on the bits of the subkey, just make a XOR between the bits of the input text pair
and those calculated for information on the bits of the subkey.
The neural network, at the end of 10 presentations of 4096 examples (pairs of texts among 64
S-table entry texts), gives the results contained in the table in annex 6. Just increase the
number of presentations to get more accurate probability values. Note that the obtained
probability exactly match the values given by the classical method of differential
cryptanalysis.
The advantage of the neural network is its concentration of the set of S-tables-specific
statistical matrices and massively parallel operation which allows to calculate the 8 S 8
cryptanalyseurs neuro - tables simultaneously.
5.4.3 Neuro-linear Cryptanalysis of DES
Linear cryptanalysis is described in section 3.6.2.
The neural network will generate all quadratic forms for obtaining information outputs on the
basis of its inputs, which amounts to generalized linear Cryptanalysis of of.S., generalized
linear cryptanalysis looks up information about the key from the study of the rounds of des
and more precisely of its S-tables which is different from the global study of the cryptosystem
by our neuro-cryptanalyzer.
Figure 5.4.3.1 - use of the linear neuro-cryptanalyseur
Unlike differential neuro-cryptanalysis, it shouldn't try to simplify the tables of linear
approximations because make the sum of the probabilities for each bit would be a loss of
information. Indeed, these sums are all almost equal. On the other hand, should create a
network of neurons with 16 input bits (each of these bits is a value of output among the 16
who are the category of preceding tables) and 6 output neurons giving the probability of
having a 1 on one of the 6 bits of S-table entries. The advantage of the neural network is that
it refers to excellent values of probabilities. You can check the correlation between the bits of
the neuro-single tables and tables of linear approximations input values for each output value.
The basis examples learning algorithm and realization of this neural network are in annex 1.
5.4.3.1 Figure presents the neuro-cryptanalyseur after learning, it returns information about
the probability of having one of the 6 bits of the S-1 table entries. One gets not directly of
Page 60
probabilities on the bits of the subkey, just make a XOR between plaintext bits, and those
calculated for information on the bits of the subkey.
The results are given in annex 7. Just increase the number of presentations to get more
accurate probability values.
5.4.4 Overall Neuro-Cryptanalysis of the crypt (3) UNIX
The command of Unix crypt (3) or ufc_crypt (ultra fast crypt) is an implementation of the des
used in the encryption of passwords stored in the/etc/passwd file, a little special in the
direction where the key is unknown to the user, no one has the ability to perform decryption
of password. This key is specific to the Unix system in use. The goal is not to find the clear
password. It is encrypted with the same key given clear password and compare it with the
password from the/etc/passwd file. If they are identical, the user is authenticated and access to
its own account.
Crack is an application seeking the passwords of users on a Unix server. Its role is to generate
a clear passwords set on the basis of a multitude of syntactic rules and/or from a dictionary. It
takes several hours to several days to penetrate a system and then retrieve the password file
and search out others.
We thought it would be interesting to learn a certain amount of passwords clear and encrypted
passwords corresponding to a neural network. The basis of learning should be large enough so
the D.E.S. learning does not become a memorization of the examples of this basis, what
makes that the network would be unable to find the solutions to other nearby examples of the
database.
We have therefore made two applications. A UNIX (or GNU Linux) synthesizing the crypt
function of unix for password clear of 4 characters whose values are a lowercase letter or a
point or a division, or about 615000 passwords bar and 2 hours of calculations per
presentation. The other is MS-DOS, she realizes learning 1024 clear passwords of 7
characters and passwords encrypted in 11 characters (we remove the first 2 characters of salt
used to re-encrypt the password encrypted for 65536 encrypted different passwords for the
same clear text).
We have added a visualization program of the first graphical statistics. The second provides
quick information.
The source and the results are available in the annex.
5.5 Analysis of the results of cryptanalysis
The neuro-crypanalyses differential and linear methods are methods of probabilistic
calculations to quickly get information about a part of des. They allow to perform the opposite
function of a S-table for a difference of texts chosen for one and for a linear relationship with
a subkey selected for the other. Such neural networks learning is very fast.
It is possible to gather for a method given, differential or linear, 8 x 16 = 128 neural networks
(one for each S-tablesnew each round) and to operate in parallel to the information given by
the ciphertext output of des to the plaintext input. Thus these networks may be supervisors of
Page 61
other non-supervised learning neural networks amending the bits of the key as and as different
texts passes through the D.E.S.. Would be a self-learning of the sub-keys. From the sub-keys,
we find the encryption key.
Statistical analysis of the program under MS-DOS version results are surprising with 90% of
the encryption function for the base found by the network of neurons and about 80% of bits to
a close this basic example but not submitted to the network. This proves that for a low basis of
learning, it is easy for a neural network to find a clear password from a password encrypted
without taking into account salt included by the Unix system.
5.6 Hardware implementations
There are 2 possible hardware implementations. One is based on existing architectures and
more precisely consists of an implementation on machine massively parallel type MASPAR
or Connection Machine (characteristics of these machines are given in annex 9).
The other is based on the design of architecture dedicated cryptanalyser encryption algorithm.
5.6.1 Dedicated Machine
The idea is to present a strong ciphers with a very fast supervised learning neuro-
cryptanalyseur. As we show in paragraph 4.6.2 it is necessary to present all plaintexts,
ciphertexts and keys to the neural network. 5.6.1.1 Figure shows the overview of learning
dedicated to an encryption algorithm.
A complete machine can be constructed on the same pattern with a large number N of units of
binary counters (120 bits: 64 bits of text and 56 bits of key) and circuits with the encryption
algorithm (for the D.E.S., AMD has built a circuit at a clock frequency of 250 MHz arsenide
approximately 5.109 encryptions per second). The number N is limited by the time of learning
of the single neural circuit of approximately 1 s. Each unit has less than 14 ns.
For des, the time interval between each unit is necessarily 1 s. What gives 106 learning per
second to learn the 256 possible keys. Either 1030 s for all possible values of text and key, or
422 years for a presentation. If the neural circuit took 14 ns, should be 318 years.
In the case of a single key, it would take 41 years and for a single text should be 2 months.
While the exhaustive search for a key takes 3.5 hours for a dedicated non-neuronal machine
which would cost 5 million francs.
Nevertheless, it is possible that the neural circuits of the future go much faster. It is preferable
for the D.E.S., treat a fixed data subset as we have done in paragraph 5.4.4.
Page 62
5.6.2 Algorithm for the Connection Machine CM-5
The following algorithms was written for the distributed architecture of the CM-5 using 3
layers of processors with a processor for a neuron. The first is used to initialize input
(plaintext) and output (ciphertext) network of neurons located on layers 2 and 3. We use
duplicated and used in layers 2 and 3 variables. NB_ENTREES, NB_CACHEES,
NB_SORTIES, EPSILON are constants that define the number of entries, hidden layer
neurons and output of the neural network and the coefficient of learning. So in a single
processor is:
NB_ENTREES poids_cachee for the weight of the hidden layer in a processor;
1 seuil_cachee; 1 activation_cachee; 1 delta_cachee;
NB_CACHEES poids_sortie; 1 seuil_sortie; 1 activation_sortie; 1 delta_sortie.
Before you start, we initialize the weights of the connections with random values.
Repeat to infinity do
generate key & texte_clair in M
For i = 0 to NB_CACHES-1 Do issue M to all layer 2 end processors
encrypt M with the encryption algorithm in C
For i = 0 to NB_SORTIES-1 Do issue C to all layer 3 end processors
Finrepeter
Figure 5.6.2.1 - algorithm of the first layer of processors
It defines a small macro: bit (i, m) {return (! ())}m & (1 < < i))); } for the following
algorithm.
Repeat to make infinity
Integer tempo [i];
Floating output, error;
receive the layer 1 M
Page 63
output = 0.0
For i = 0 to NB_ENTREES-1 If (bit (i,M)) then exit += poids_cachee [i];
tempo [i] =M end
Activation_cachee= sigmoid (output-seuil_cachee)
For i = 0 to NB_SORTIES-1 do activation_cachee transmitting to layer 3 end
error= 0.0
For i = 0 to NB_SORTIES-1 do
receive M layer 3 / * poids_sortie for this hidden below neuron *
error=error+ receive M layer 3 / * delta_sortie * /.
End
delta_cachee = error*activation_cachee*(1-activation_cachée ))
For i = 0 to NB_ENTREES do poids_cachee[i] =poids_cachee[i] +EPSILON
* delta_cachee * tempo[i]
seuil_cachee = seuil_cachee - EPSILON * delta_cachee
Finrepeter
Figure 5.6.2.2 - algorithm of the second layer of processors
Repeat to make infinity
Floating F, exit, tempo[NB_CACHEES];
output = 0;
For i = 0 to NB_CACHEES-1 do
receive F's Layer 2
Tempo[i] =F
output = output + poids_sortie[i] *F
End
issue poids_sortie to layer 2
Page 64
activation_sortie = sigmoid (exit - seuil_sortie ));
receive F's Layer 1 / * activation of the learning values *
delta_sortie = (F - activation_sortie) * activation_sortie *(1-activation_sortie)
For i = 0 to NB_CACHEES-1 do
issue delta_sortie to layer 2
poids_sortie[i] = poids_sortie[i] + (EPSILON*o_delta * tempo[i]);
End
seuil_sortie = seuil_sortie - EPSILON * delta_sortie
Finrepeter
Figure 5.6.2.3 - algorithm of the third layer of processors
Procedures making (non blocking) and receiving (blocking) a message through the lines of
communications to 40 MB/s allow a low of timeout.
It is likely that examples learning time is longer than for the dedicated machine of the
preceding paragraph.
5.7 Performance
Learning time is quite long (from several days to several years), but interesting results (error
rate is close to zero) are available in short presentations when the basis of examples is large
enough (which is the case of algorithm strong such as D.E.S. or R.S.A. then be simple as the
XOR operations for between 200 and 500 submissions for an error rate of zero.
However, once the learning is done, the deadline for passage of information through the
network of neurons is very short (in the order of tens of nanoseconds). What is prodigious
when we know that it must repeat an exhaustive search for each text encrypted with a
different key.
5.8 Conclusion
We have seen in this chapter, the neuro-Cryptanalysis of strong encryption, the general
principle and a study based on neural networks, whether learning the keys on the basis of
clear and encrypted texts. We describe applications. We present differential neuro-
cryptanalysis and linear neuro-Cryptanalysis of des, which allowed us to measure the
statistical performance of neural networks that are excellent. A dedicated hardware
application has been described. A set of very satisfactory performance on a basis of learning
of low size.
Page 65
Chapter 6 - Glossary and Mathematics
6.1 Introduction
This chapter is part of this memory mainly to complement the terminology used in the
previous chapters. Just bring the reader to the clarification in the fields of theory information,
the complexity of algorithms and number theory. All the above-mentioned points are widely
used in Cryptography.
6.2 The information theory
Quantification of information
This is the minimum number of bits to encode all possible meanings of information.
The entropy H (M)
It is a measure of the amount of information contained in a message M.
In general, H (M) = Log2(n) where n is the number of possible meanings.
The uncertainty
This is the number of bits of the plaintext which must be found to help locate the
plaintext in an integer from the ciphertext.
The rate of the r language
r = H (M) / n where N is the length of the message in characters of the language (in
bytes).
The absolute rate R
R = Log2(L) where L is the number of characters in the language. R is in
bits/character.
Redundancy D
D = R - r
The entropy of a cryptosystem H (K)
H (K) = Log2 (number of possible keys)
The number of different keys to decrypt a message
2H (K) - nD-1 where n is the length of the message, H (K) entropy and D redundancy.
Page 66
The Unicity distance (point of uniqueness)
u = H (K) /D
The confusion
Due to erase the relationship between plaintexts and ciphertexts (example: overriding)
The dissemination
Fact disperse the redundancy of the text (example: transposition or permutation of
blocks)
6.3 The complexity of algorithms
The complexity of algorithms corresponds to 2 parameters: T the time complexity and S
complexity in space (typically memory).
Denotation
O(n) : complexity of linear algorithms, n is the number of iterations
O(n2) : complexity of quadratic algorithms
O(n3) : cubic algorithms complexity
Previous algorithms are polynomial algorithms in time O(nt)
O(f (n)t) : complexity of exponential algorithms (t:constante, f (n): polynomial function of n)
O(f (n)t) : complexity of superpolynomiaux algorithms
(t:constante, f (n) > constant C and f (n) < O(n) ))
The classes of problems
The class least complex to most complex:
P : problems that can be solved in polynomial time.
NP : problems that can be solved in polynomial time on a non-deterministic TURING
machine (variant of the normal TURING machine who guess solutions).
NP-complete : problems that can be solved in polynomial time on a non-deterministic
TURING machine, including the class P (addition of a set of elements checking the P class).
Page 67
Also PSPACE : problems that can be solved in polynomial space and variable time.
Also PSPACE-complete : problems that can be solved in polynomial space and variable time.
EXP TIME : problems that can be solved in exponential time
6.4 The number theory
Congruences
(a + b) mod n = ((a mod n) + (b mod n)) mod n, same with (a-b) and (a * x)
(a *(b+c)) mod n = (((a*b) mod n) + ((a*c) mod n)) mod n
If (a mod n) then (ax mod n) with natural whole x
The primes
It is a number integer > 1 whose only factors are 1 and itself. For more details on primes and
their cryptographic applications, see (KRANAKIS 1986).
The inverses modulo n
The goal is to find x such as 1 =(a*x) mod n or a-1= x mod n
There is not solution, but in general, there is a single x if a and n are coprime between them.
The resolution of this problem is obtained by using the extended Euclidean algorithm and its
complexity is O(log2n). For more details see (SCHNEIER 1995, pages 209-210) and
(KNUTH 1981).
FERMAT's theorem
If m is Prime and a is not multiple of m, then m-1= 1 mod m.
Residues modulo n
These are the remains of the subtraction of one number by n
Residues restricted
These are the remains of the subtraction of a number n that are coprime to n.
N EULER function (indicator of EULER, n)
It is the cardinal of the restricted set of residues modulo n, this function is denoted (n).
(n) is the number of positive integers smaller than n and coprime to n.
Page 68
If first n, (n) = n-1 and if n = p * q where p and q are first then (n) =(p-1) *(q-1).
Or pgcd(a,n) = 1 and (a * x) mod n = b, calculate x:
-by the generalization of Euler: x = (b * exp(a (n)-1 mod n)) mod n
-by Euclid's algorithm: x = (b * reverse (a, n)) mod n.
see (SCHNEIER 1995, pages 212-213)
The Chinese remainder theorem
A few are has and (b) such as a < p and b < q (p and q first), there are unique x such as x < p *
q and as x = a mod p and x = b mod q.
By Euclid, calculating u as u * q = 1 mod p which gives us x = (((a-b) * u) mod p) * q + b
Details and code in C (SCHNEIER 1995, pages 213-214)
The residuals squared modulo p
If p Prime, has < p then a is residual squared modulo p If x2= a mod p for some x.
The LEGENDRE symbol
It is noted L (a, p) or (a/p) with a whole natural and p Prime > 2.
We then obtain: L (a, p) = 0 if a is divisible by p.
L (a, p) = 1 if a is a square modulo p
L(a,p) =-1 if a is not a residue quadratic modulo p
To calculate, it has the formula L(a, p) = a(p-1) / 2 mod p
There are also the following recursive expressions:
If a = 1, L (a, p) = 1
If a is even, L (a, p) = L (a/2, p) *(-1)(p * p - 1) / 8 else L (a, p) = L(p mod a,a) *(-1)(a-1) *(p-1)/4
The JACOBI symbol (Jacobian)
Noted J (a, n), it is a generalization of L (a, n). To compute,
If n is Prime, J (a, n) = 1 if a is residual squared modulo n
J(a,n) =-1 if a is not residual squared modulo n
If n = p1*... * pm (pm is a factor n Prime),.
Page 69
J (a, n) = J(a,p1) *... * J (a, pm)
If a = 0, J(0,n) = 0
It follows the following properties:
J(1,k) = 1; J (a * b, k) = (a, k) J * J (b, k);
J(2,k) = 1 if (k2-1) / 8 is peerJ(2,k) =-1 if (k2-1) / 8 is odd;
J (a, b) = J ((a mod b,b), useful if a > b; )
If pgcd(a,b) = 1 and a, b odd then
If (a-1) *(b-1)/4 pair is then J(a,b) = J(b,a) if J(a,b) =-J(b,a)
BLUM integers
If p and q are coprime and p = 3 mod 4 and q = 3 mod 4 then n = p * q is a BLUM integer.
Residues squared modulo n 4 square root which is also a square, it is the principal square root.
Generators
If p is Prime, g < p then g is a generator modulo p if whatever n (1, p-1), there is a as ga= n
mod p (g is primitive compared to's).
If you know the decomposition into factors first p - 1: q1, q2,..., qn so for all qn, computes g(p-1)
/q mod p, if the result is 1 for a first q-factor then g is not generator modulo p.
The body of GALOIS
Arithmetic modulo n, if n is Prime, is a finite field. Similarly if n is an integer power of a
prime number. If p is Prime, a body of GALOIS is Z/p. Addition, subtraction, multiplication,
division work with 0 neutral element of addition, 1 neutral element of multiplication.
Whatever p 0, there are p'= 1/p. On a commutativity, association and distributivity.
Z/2n (body Z/qn)
Let p(x) be a polynomial p (x) irreducible of degree n, the "generators" polynomials in a given
body are primitive polynomials. In Z/2n, in cryptography, we use much p (x) = xn+ x + 1
because multiplication and exponentiation are very effective and the physical implementation
is easy with shift registers.
The factorization
The best algorithms for factoring numbers are as follows:
Quadratic sieve: the number of operations is e(ln n) ½ * (ln (ln n)) ½., the fastest, see (POMERANCE
1985), (POMERANCE 1988) and (WUNDERLICH, 1983).
Page 70
Screened on digital bodies: the number of operations is e(ln n) 1/3 * (ln(ln n)) 2/3, see (LENSTRA
1993).
Methods of elliptic curves. See (MONTGOMERY 1987) and (MONTGOMERY 1990).
Algorithm Monte Carlo of POLLARD. See (POLLARD, 1975), (BRENT, 1980), (KNUTH,
1981, page 370).
Algorithm of continued fractions. See (KNUTH, 1981, pages 381-382)
Attempt of divisions: divisions of the number by all lower primes.
Page 71
Chapter 7 - Conclusion
We presented the neural networks, defined and determined which model of neural networks
the most appropriate Cryptography on algorithmic learning plan and material terms as regards
architectures already carried out and observed performance.
The most interesting Connectionist model turns out be the network of perceptrons with back-
propagation of the gradient through the various properties that were analyzed and
demonstrated by different scientists:
their generalization property
their low sensitivity to noise (if an error sneaks into the basis of examples)
their low sensitivity to fault (lost connections, modified weight or bug in the program)
information are outsourced
Research of statistical calculations and heuristics capabilities
We presented the structure of the model chosen in the following figure:
This architecture can also be software than hardware. Neural networks have already been
implemented on machines massively parallel.
An analysis of linear multilayer networks showed us the analogies with different statistical
methods of analysis of the data, in particular linear regression and discriminant analysis. It has
been shown that the backpropagation is a discriminant analysis of a population of N
individuals (N being the number of examples included in learning) described by n parameters
(wheren is the number of input neurons) and projected in a hyperplane of dimension p
(wherep is the number of hidden units). It is therefore possible to use non-linearly separable
problem to build a classifier where a probabilistic model. Which proves the interest of such an
algorithm in cryptography and especially cryptanalysis.
On the hardware side, the benefits of the VLSI components are:
ease of use
the important signal-to-noise ratio
an easy-to-implement cascade circuit
a high adaptation (these circuits allow to solve various tasks)
a reduced price of manufacturing
Page 72
We presented then the three types of existing components on the market or research
laboratory:
1. components dedicated to digital neural which speeds network go up to 1 GB of
connections processed per second.
2. the digital coprocessors particular purpose (also called neuro-accelerators) are special
circuitry that can be connected to hosts (PCs or workstations), they work with a neuro-
simulator program. The mix of hardware and software aspects gives these benefits:
accelerated speed, flexibility and improved user interface.
3. networks of neurons on massively parallel machines.
An implementation of the algorithm has been developed on the Connection Machine CM-2
(created by THINKING MACHINES Corp.) with a topology hypercube 64 k processors,
which gave 180 million interconnections calculated per second (IPS) or 40 million weight
updated per second.
Here is the performance measured by machine in interconnections calculated by seconds
(figure below).
CM-2 180 million
CRAY X -
MP
50 million
WARP (10) 17 million
ANZA
MORE
10 million
The use of such configurations would allow to obtain excellent results in learning of
cryptographic ciphers.
We have seen that Cryptography is a very large and popular area of mathematicians and
computer scientists. We had the force of a cryptosystem which depends entirely on the used
key whether it be public or private and exchanges cryptographic protocols. We have chosen to
focus on the realization of neural and neuro-Cryptanalysis of cryptosystems.
Our work specifically concerned the ECB mode which is more suitable for learning of the
networks of neurons with an entry and a number of bits output fixed and not loop re-inbound.
It is also possible to connect one or more networks of neurons in this way.
We have chosen to tackle the D.E.S. because it is the older standard of encryption and the
most studied algorithms.
The physical aspect is very important for the speed of execution. The VLSI components are
widespread and effective but there are even more interesting technology-based components
that should not be disregarded: the Gallium Arsenic (GaAs) or arsenide technology. It has
already been included in supercomputers.
Page 73
The major differences between GaAs and VLSI are:
Fast failover of the GaAs doors
The Exchange with components other than GaAs is a major difficulty
Very small density of GaAs integrated circuits
With regard to the D.E.S., there is a circuit running at 50 MHz performing encryption in 20
ns, which allows to make 50 million of ciphers in a second. Since late 1995, AMD sells a
circuit encrypting the of 250 MHz.
In August 1993, the Canadian Michael J. WIENER described how to build a machine for $ 1
million that performs a comprehensive search of des keys to find the right key in 3.5 hours.
Each of its basic circuits has power equivalent to 14 million stations SUN.
We analyzed both as successful cryptanalysis against des.
Differential cryptanalysis that is to look at the specifics of a pair of ciphertexts for a pair of
plaintexts with a particular difference.
Force of residing in his rounds and all operations of a round being completely linear except S-
tables, Eli BIHAM and Adi SHAMIR analyzed 8 S-tables for text input differences and
differences in output texts, these information are synthesized in 8 tables called Tables of
distribution of differences of the (see 8 tables in annex 3). We realized the algorithm to
generate these tables.
Linear cryptanalysis is to study the statistical linear relationships between a plaintext bits, the
bits of the ciphertext and key which allowed to encrypt. These relationships allow for some
bits of the key values when we know the plaintexts and ciphertexts associated. It deduced the
linear relationships of each S-table by choosing a subset of bits of input and output bits,
calculating parity (Xor) of these bits with parity of the subset is zero. In general, a subset will
be entries with parity 0 (linear) and others with parity 1 (affine). MATSUI has calculated the
number of parity zero of each subset of bits of input and output for each S-table amongst the
64 x 16 = 1024 possible subsets. It is possible to associate different probabilities to various
bits of the sub-keys. Probabilities of obtaining parity zero (linear relationship) are synthesized
in 8 tables called Tables of linear approximations of a (see 8 tables in annex 4). We realized
the algorithm to generate these tables.
After showing the possible association between neural networks and cryptography, we
defined the field of neuro-Cryptography.
We then identified some important points for the correct use of neural networks. How the
basis of learning will be generated is very important for the realization of neural applications.
Learning depends on random initialization of weights the network as well as the number of
examples, the order of presentation of these examples then the consistency in the choice of a
set of examples.
We have seen that a sample consists of a value to be presented at the entrance to the network
of neurons and a value to present output of this network, output based on the input value. If
the number of examples is too low, it is clear that the network will not seek a transfer function
of the studied cryptosystem but will instead store the examples given and cannot therefore in
Page 74
any way find a result for an input value different from those given in the basis of examples. In
cryptography to present more than half of all possible to be certain of the results examples
even if it is true that in strong cryptography, the number of possible input values is very large.
Then we realized an algorithm to present the examples in a more or less complete mess. It's
cutting the base k sub-bases then in turn present the elements of each of the sub-bases (k can
be even or odd). The following figure shows the error rate final Tss for k different values (the
number of presentation being fixed at 500 and 256 examples).
We note that the order of presentation of the basis of learning is not useful.
k 1 2 3 4 5 6 7 8
TSS 0.05 0.06 0.06 0.05 0.08 0.07 0.05 0.08
At the level of the automatic generation of contiguous texts, we presented an algorithm that
can generate clear examples regardless of the number of nested loops to a single body of loop
which will be executed on each iteration of the innermost loop.
We analyzed the coefficient of learning to enable a more or less rapid learning with
opportunities for convergence of the network to an inversely proportional solution due to local
minima of the curve of error measured by the basis for learning and values output calculated
by the neural network.
Should empirically vary Epsilon between 0.1 and 2.0. If the network doesn't want any
similarly converge, it is certainly due to the problem of the non-linearly separable, which is
the case of learning of the XOR. Should then use a Momentum Term whose real value is
between 0.1 and 1.0 and which will aim to avoid local minima by deriving the error function,
meaning that it allows to take into account in the current step of learning from previous steps.
We presented the self-study which is interesting for neuronal learning of cryptographic
algorithms. The neuronal system has two parts: the emulator and the controller whose
learning are carried out separately.
The task of the emulator is to simulate the complex function or the encryption algorithm.
There therefore its entry State at any given time and an input at this time and its output is the
output of the algorithm to the following time. The input of the controller is the State of the
system at time k, its output is the value to be input to the algorithm or the function complex.
The proper role of the controller is to learn the law of adaptive control. But for this learning,
the error signal is not calculated on the order but on its result, the gap between actual
condition and current state. It comes to the idea of a guided rather than supervised learning
because no Professor learns the System Control Act. In fact, the system learns itself in dealing
with the information he receives in return for shares. To make possible learning through
backpropagation and retropropager error on the position, the structure of the emulator must be
homogeneous at the controller.
Another quality of this device is its ability to e-learning. Learning of the controller is fast. In
addition, the law of synthesized control is sufficiently robust to small random perturbations. It
is therefore possible to perform neural networks for self-learning on a line of communication
for encryption as for authentication of messages in real time.
Page 75
We presented several different applications. On learning of the XOR, i.e. to achieve C = A
XOR B, need us a network 16-bit input (i.e. 2 bytes A and B) and 8-bit output (a byte C). The
network must therefore be 16 neurons input, 16 minimum layer (s) (s) hidden neurons and 8
output neurons. The broadcast consists of 65536 causes - effects. After various tests, the
success to the XOR learning rate is very close to 100% depending on the random weight
initialisation and the number of submissions. More the number of entries and hidden layer
neurons are great, plus the number of presentations of the base can be reduced. If the random
initialization of the weight is correct, a single submission can be sufficient and better quality.
For the learning of cryptographic algorithms, we have shown that whether a function or an
algorithm for combining data entries (causes) for output data (effects). It is therefore to
determine input and output of the network structures and to find a basis of causes and
associated effects sufficient to learning of the network converges to a minimal amount of
errors, or even almost.
We have shown how to make the neural network can memorize the algorithm. The answer is
to present virtually all possible encryption keys (e.g. 64 bits) and all possible plaintexts (e.g.
64 bits) input and calculate all resulting ciphertexts with the encryption algorithm. Thus, the
neural network will be synthesized algorithm since when it presents him an encryption key
and a plain text input, it will give us output the ciphertext whereas. If the encryption algorithm
is bijectif then the encryption algorithm is the same as the decryption algorithm and the neural
network also decrypts.
We have seen that with regard to key learning, an encryption key must be linked to an
encryption or decryption algorithm and a plaintext or encrypted. If key has a fixed size of N
bits, then N bits in the neural network outputs and M bits input equal to two times the number
of bits of the plaintext and ciphertext blocks.
In fact, the neural network realizes a function that finds the key directly from a plaintext and
encrypted text.
We presented then the advantages and disadvantages of the neuronal methods used. Learning
of neural networks time remains long enough on the basis of the number of bits of the key and
encrypted and clear texts, this time can be optimized if the neural network is implemented on
a parallel machine.
In regards to memorizing keys and ciphers, neural networks are high achievers with over 90%
success in learning of weak ciphers. A strong encryption algorithm, to rapid learning. Neural
networks are used extensively in recognition of images, they is so easy to perform
Page 76
authentication. At the level of the hardware architecture, it is easy to parallèliser the
algorithms. As well as at the level of networks of neurons and ciphers based on hardware
architectures. This solution is quite expensive. The design of neuro-encryption can be useful
in cases where a secret key and an encryption algorithm are taught how to network to hide
information to the user, in particular, at the level of the key generator that could be kept secret
by a distributor body. It would be messy to a cryptanalyst to discover the function of the
generator algorithm of encryption keys. Neuro-cryptanalysis seems to be a lot more
application to neural networks due to their emergent properties of massively parallel statistical
analysis and their ownership of concentration of information or approximations of statistical
matrices.
We have defined an application of the most important of neuro-Cryptography: neuro-
cryptanalysis. She is to perform the Cryptanalysis of cryptographic algorithms with the use of
neural networks. I.e. to achieve one or more neural networks to find or help find the key of an
encryption algorithm. The important principle is the presentation to the network of neurons a
ciphertext and the encryption algorithm.
In neuro-cryptanalysis, the neural network to help find the encryption key used in the cipher
text. As a neural network can learn a cryptographic algorithm or can 'remember' (by a
function approximation) a set of keys, we infer that the neuro-cryptanalyseur can be broken
down into 2 subnets of neurons as in the figure on the next page. This neural network
structure is identical to that of the self-study. It is clear that neural networks must take an
important place in cryptography in the design, use, and verification of protocols.
We tested and presented the possible forms of neuro-as cryptanalysis.
For neuro-cryptanalyser a Vigenère figure, it is necessary that the neural network is to do a
frequency analysis is an analysis of a subset of n characters from a given then language that it
measures the correlation between the plaintext and the ciphertext learned for all subsets of n
characters. This type of problem is resolvable by a network of neurons and very long in
supervised learning. However, it is possible to carry it out in auto-learning. In this case,
encrypted text must be large enough.
We measured the performance of neural networks at the statistical level by neuro-differential
cryptanalysis and linear neuro-Cryptanalysis of des according to the following scheme:
These performances proved to be particularly good.
We then implemented a neuro-cryptanalyseur of the command of Unix crypt (3) or ufc_crypt
(ultra fast crypt), which is an implementation of the des used in the encryption of passwords
Page 77
stored in the/etc/passwd file. It is a little special in the sense where the key is unknown to the
user, no one has the ability to perform decryption of password. This key is specific to the
Unix system in use. We thought it would be interesting to learn a certain amount of passwords
clear and encrypted passwords corresponding to a neural network. The basis of learning
should be large enough so the D.E.S. learning does not become a memorization of the
examples of this basis, what makes that the network would be unable to find the solutions to
other nearby examples of the database.
We have therefore made two applications. A UNIX (or GNU Linux) synthesizing the crypt
function of Unix for password clear of 4 characters whose values are a miniscule letter or a
point, a division, or about 615000 passwords bar and 2 hours of calculations per presentation.
The other is MS-DOS, she realizes learning 1024 clear passwords of 7 characters and
passwords encrypted in 11 characters (we remove the first 2 characters of salt used to re-
encrypt the password encrypted for 65536 encrypted different passwords for the same clear
text).
We have added a visualization program of the first graphical statistics. The second provides
quick information.
We deduce the following results.
The neuro-crypanalyses differential and linear methods are methods of probabilistic
calculations to quickly get information about a part of des. They allow to perform the opposite
function of a S-table for a difference of texts chosen for one and for a linear relationship with
a subkey selected for the other. Such neural networks learning is very fast.
It is possible to gather for a method given, differential or linear, 8 x 16 = 128 neural networks
(one for each S-tablesnew each round) and to operate in parallel to the information given by
the ciphertext output of des to the plaintext input. Thus these networks may be supervisors of
other neural networks learning unsupervised amending the key bits that different texts pass
through the D.E.S.. Would be a self-learning of the sub-keys. From the sub-keys, we find the
encryption key.
Statistical analysis of the program under MS-DOS version results are surprising with 90% of
the encryption function for the base found by the network of neurons and about 80% of bits to
a close this basic example but not submitted to the network. That proves that for a low basis
of learning, it is easy for a neural network to find a clear password from a password encrypted
without taking into account the salt included by the Unix system.
We then felt two implementations on two types of hardware architectures. The first is a
dedicated parallel architecture as a neuro-cryptanalyseur of strong ciphers needs a very fast
supervised learning. It is necessary to present all plaintexts, ciphertexts and keys to the neural
network.
Page 78
A complete machine has been studied with a large number of units of binary counters and
circuits with the encryption algorithm. This number is limited by the time of learning of the
single neural circuit of approximately 1 s. It is preferable for the D.E.S., treat a fixed data
subset as we have done in past applications.
In the second, we presented our algorithms written to the distributed architecture of the CM-5
using 3 layers of processors with a processor for a neuron. The first is used to initialize (clear
text) input and output (ciphertext) network of neurons located on layers 2 and 3. It is likely
that examples learning time is longer than for the dedicated machine of the preceding
paragraph.
General performance are as follows:
learning time is quite long (from several days to several years), but interesting results (error
rate is close to zero) are available in short presentations when the basis of examples is large
enough (which is the case of algorithm strong such as D.E.S. or R.S.A. then be simple as the
XOR operations for between 200 and 500 submissions for an error rate of zero. Once the
learning is done, the deadline for passage of information through the network of neurons is
very short (in the order of tens of nanoseconds). What is prodigious when we know that it
must repeat an exhaustive search for each text encrypted with a different key.
Neuro-Cryptography and neuro-cryptanalysis are two areas very interesting and helpful for
Cryptography. We hope that various studies and research will be done to refine the set of our
conclusions.
Software and hardware applications that we have studied or made can be implemented and
optimized.
The results obtained are very promising for the future of neural networks.
Page 79
Bibliographie
Neural networks
(Aleksander) I. Aleksander, H. Morton, An introduction to neural computing, Editions
CHAPMAN & HALL
(Alippi 1990a) C. Alippi, S. Bonfanti, G. Storti-Gajani, " Some simple bounds for
approximations of sigmoidal functions in layered neural nets ", Report n°90-022,
Dipartimento di elettronica politecnico di Milano, 1990, pages 1-25
(Alippi 1990b) C. Alippi, S. Bonfanti, G. Storti-Gajani, " Approximating sigmoidal functions
for VLSI implementations of neural nets ", Proceedings MicroNeuro’90, 1990, pages 165-170
(Beiu 1995a) V.Beiu et J.G. Taylor, " Optimal mapping of neural netwaorks onto FPGA ",
Lectures Notes in Computer Science : Proceedings. of the intl. Workshop on Artif. Neural
Networks (IWANN’95), Springer Verlag, Màlaga, Espagne, 1995, pages 822-829
(Beiu 1995b) V.Beiu, " Constant fan in neural networks are VLSI optimal ", First Intl. Conf.
on Mathematics of Neural Networks and applications (MANNA’95), Oxford,UK, 1995
(Bourret 1991) P. Bourret, J. Reggia, M. Samuelides , RESEAUX NEURONAUX - Une
approche connexionniste de l’intelligence artificielle, Editions TEKNEA, Toulouse, Octobre
1991, ISBN 2-87717-016-0
(Camargo 1990) F.A. Camargo, " Learning algorithms in neural networks ", DCC
Laboratory, Columbia University, NY, 1990.
(GALLINARI 1988) GALLINARI P., FOGELMAN-sOULIE F., " Progressive Design of
M.L.P Architecture ", Neuro-Nîmes, pages 171-182, 1988
(Grossberg 1986) Carpenter, Grossberg, " Neural dynamics of category learning and
recognition in brain structure, learning and memory ", AAAS Symposium Series, 1986
(Hebb 1975) Hebb, The organization of the behavior, JOHN WILEY & SONS, NY, 1975
(Hopfield 1982) Hopfield, " Neural networks ", Proc. Natinal Academy. Sciences USA, vol.
79, Avril 1982 , pages 2554-2558
(Kohonen 1984) Kohonen, Self organization and associative memory, SPRINGER
VERLAG, BERLIN, 1984
(Lippman 1987) Lippman, " Introduction to computing with neural nets ", IEEE ASSP
MAGAZINE, Avril 1987, Pages 4-22
(Maren) A.J. Maren, Handbook of neural computing applications, Editions ACADEMIC
PRESS INC.
Page 80
(McCulloch 1943) Mc Culloch et Pitts, " A logical calculus of the ideas imminent in nervous
activity ", BULLETIN OF MATHS BIOPHYSICS, vol.5, 1943, pages 115-133
(Nigri 1991) M.E. Nigri, " Harware emulation of backpropagation neural nets ", Research
Notes RN/91 /2 1, Departement of Computer Science, University of College London, Février
1991
(Rosenblatt 1959) Rosenblatt, Principles of neurodynamics, SPARTAN BOOKS, NY, 1959
(Rumelhart 1986) Rumelhart, McClelland, Parallel distributed processing exploration in
the micro-structure of cognition, 2 Volumes, MIT PRESS, 1986
(Weisbuch 1989) Weisbuch, Dynamique des systèmes complexes, INTEREDITIONS, 1989
Cryptography
(ALDEMAN 1978) RIVEST, SHAMIR, ALDEMAN, " A method for obtaining digital
signature and public key cryptosystems ", CACM, Vol. 21, N°2, pages 120-126, Février 1978
(Biham 1990) E. BIHAM et A. SHAMIR, " Differential cryptanalysis of DES-like
cryptosystems ", Advances in Cryptology CRYPTO’90 Proceedings, Editions Springer-
Verlag, Berlin, 1990 , pages 2-21
(BIHAM 1993a) E. BIHAM et A. SHAMIR, Differential cryptanalysis of Data Encryption
Standart, Editions Springer-Verlag, Berlin, 1993
(BIHAM 1993b) E. BIHAM et A. SHAMIR, " Differential cryptanalysis of the full 16 round
DES ", Advances in Cryptology CRYPTO’92 Proceedings, Editions Springer-Verlag, Berlin,
1993
(Diffie 1992) W.Diffie, The first ten years of public key cryptography - Contemporary
cryptology: The science of information integrity, IEEE Press, Piscatoway, NJ, 1992, pages 65-
134
(Friedman 1920) W.F. Friedman, " The index of coincidence and its applications in
cryptography ", RIVERBANK PUBLICATION, N°22, Riverbank Labs, 1920
(Harpes 1995) C. Harpes, G. Kramer et J.L. Massey, " A generalization of Linear
Cryptanalysis and the Applicability of Matsui's Piling-Up Lemma ", Advances in Cryptology -
EUROCRYPT '95, lecture notes in computer science, vol. 921, Springer-Verlag, New York,
1995, Pages 24-38
(MATSUI 1994) M. MATSUI, " Linear cryptanalysis method for DES cipher "Advances in
Cryptology EUROCRYPT’93 Proceedings, Editions Springer-Verlag, BERLIN, 1994
(Meier 1994) W.Meier, " On the security of the {IDEA} block cipher ", Advances in
Cryptology: EUROCRYPT '93, Lecture Notes in Computer Science, Vol. 765, Springer-
Verlag, Berlin, 1994, Pages 371-385
Page 81
(Pointcheval 1995) David Pointcheval, " Les réseaux de neurones et leurs applications
cryptographiques ", LIENS 95-2, Mémoire effectué au département Mathématiques et
Informatique, Ecole Normale Supérieure, PARIS, Février 1995
(SCHNEIER 1994) B. SCHNEIER, Applied cryptography, Editions JOHN WILEY &
SONS INC. , U.S., 1994
(SCHNEIER 1995) B. SCHNEIER, Cryptographie appliquée, Editions INTERNATIONAL
THOMSON PUBLISHING, Paris, 1995, ISBN 2-84180-000-8
(SCHNEIER 1996) B. SCHNEIER, " Differential and linear cryptanalysis : attacking the
Data Encryption Standart ", DOCTOR DOBBS JOURNAL, US, Janvier 1996, Page 42
(WIENER 1993) M.J. WIENER, " Efficient DES key search "
BELL-Nothern Research,P.O. Box 3511 Station C, Ottawa, Ontario,K1Y 4H7, CANADA
Mathematics
(Brent 1980) R.P.Brent, " An improved Monte Carlo factorization algorithm ", BIT, vol.20,
1980, pages 176-184
(Kranakis 1986) E. Kranakis, Primality and cryptography, Editions WILER-TUEBNER
Series in Computer Science, 1986
(KNUTH 1981) D. KNUTH, The art of computer programming, Volume 2 - Seminumerical
Algorithms, Editions Addison-Wesley, Reading, MA, 2e édition, 1981
(Lenstra 1993) A.K. Lenstra, H.W. Lenstra, M.S. Manasse, J.M. Pollard, " The factorization
of the ninth FERMAT number ", Mathematics of Computation, vol. 67, n°20, juillet 1993,
pages 319-350
(Montgomery 1987) P.Montgomery, " Speeding the pollard and elliptic curve methods of
factorization ", Mathematics of Computation, vol. 48, n°177, janvier 1987, pages 243-264
(Montgomery 1990) P.Montgomery, R.Silverman, " An FFT extension to the P-1 factoring
algorithm ", Mathematics of Computation, vol. 54, n°190, 1990, pages 839-854
(Pollard 1975) P.Montgomery, " A Monte Carlo method for factorization ", BIT, vol.15,
1975, pages 331-334
(Pomerance 1985) C. Pomerance, " The quadratic sieve factoring algorithm ", Advances in
Cryptology: Proceedings of EUROCRYPT 84, Editions Springer Verlag, berlin, 1985, pages
169-182
(Pomerance 1988) C. Pomerance, JW Smith, R.Tuler, " A pipe-line architecture for factoring
large integers with the quadratic sieve factoring algorithm ", SIAM Journal, vol.17, n°2, Avril
1988, pages 387-403
Page 82
(Wunderlich 1983) M.C. WUNDERLICH, " Recent advances in the design and
implementation of large integer factorization algorithms ", Proceedings of the 1983
Symposium on Security and Privacy, IEEE Press, Piscatoway, NJ, 1983, pages 67-71
HTML pages and newsgroup on the internet (FAQ 1996) FAQ of
CRYPTOLOGY (Frequently Asked Questions)
Sur Internet: NEWS:SCI.CRYPT
Janvier 1996 (mise à jour tous les 2 mois)
(FAQ 1996) FAQ ofNeural Networks (Frequently Asked Questions)
Sur Internet: NEWS:COMP.IA.NEURAL-NETS
Janvier 1996
(HTML-QUAD) Cryptography (magazine)
http://www.quadralay.com/www/Crypt/Crypt.html
(HTML-CRYPT) Cryptography
http://www.cryptography.com/index.html
(HTML-CS/1) Software
http://www.cs.hut.fi/crypto/software.html#cryptanalysis
(HTML-CS/2) Links to interesting sites
http://www.cs.hut.fi/crypto/sites.html
(HTML-CYP) Les anti-chiffrement
http://ibd.ar.com/lists/comp/cypherpunks/Threads.html
(HTML-DMI) Loi française sur le chiffrement
http://www.dmi.ens.fr/dmi/equipes_dmi/grecc/loi.html
(HTML-CNAM) Chiffrement en France
http://www.cnam.fr/Network/Crypto/
(HTML-ECST) Index of Cryptography
http://www2.ecst.csuchico.edu/~atman/Crypto/cryptoindex.html
Page 83
Annexes
1 C source code
gradient backpropagation of neural networks
(XOR learning on 8 bits)
/*
XOR.C : 8 bits (8:entrée1,8:entrée2,8:sortie) - Apprentissage avec Momentum Term
Sébastien DOURLENS - V1.00 - compilateur BORLAND C 3.1 pour DOS
*/
#include <stdio.h>
#include <math.h>
#include <stdlib.h>
#include <time.h>
#define NB_ENTREES 16 /* entrées du réseau */
#define NB_CACHEES 16 /* neurones en couche cachée */
#define NB_SORTIES 8 /* neurones de sortie */
#define NB_EXEMPLES 65536L /* nombre d’exemples de la base d’apprentissage */
#define NB_PRESENTATIONS 500 /* nombre de présentations de la base */
#define EPSILON 0.9 /* coefficient d’apprentissage */
#define MOMENTUM 0.3 /* momentum term :pour eviter les minima locaux */
#define MAX_ALEA 0.3 /* valeur maxi aléatoire */
#define MIN_ALEA -0.3 /* valeur mini aléatoire */
#define TYPE_REEL double /* type flottant pour la précision désirée */
TYPE_REEL exemples_entrees[NB_ENTREES], exemples_sorties[NB_SORTIES];
TYPE_REEL activations_entrees[NB_ENTREES], activations_cachees[NB_CACHEES];
Page 84
TYPE_REEL activations_sorties[NB_SORTIES], activations_apprentissage[NB_SORTIES];
TYPE_REEL delta_sorties[NB_SORTIES], delta_cachees[NB_CACHEES];
TYPE_REEL seuils_sorties[NB_SORTIES], seuils_cachees[NB_CACHEES];
TYPE_REEL delta_seuils_sorties[NB_SORTIES], delta_seuils_cachees[NB_CACHEES];
TYPE_REEL poids_sorties[NB_SORTIES][NB_CACHEES];
TYPE_REEL delta_poids_sorties[NB_SORTIES)[NB_CACHEES];
TYPE_REEL poids_cachees[NB_CACHEES][NB_ENTREES];
TYPE_REEL delta_poids_cachees[NB_CACHEES][NB_ENTREES];
/****************************************************************/
/* fonction de transfert du neurone */
TYPE_REEL sigmoid(TYPE_REEL x)
{
return( 1.0/(1.0+exp(-1.0*x)) );
}
/****************************************************************/
/* donne un nombre aléatoire compris entre min et max */
TYPE_REEL calculer_nb_aleatoire(TYPE_REEL min,TYPE_REEL max)
{
TYPE_REEL r=((rand()*(max-min))/32767.0)+min;
return r;
}
/****************************************************************/
/* initialise les poids de chaque connexion aléatoirement */
void initialiser_poids(void)
{
Page 85
register int i,j,k;
for(k=0;k<NB_SORTIES;k++) {
for(j=0;j<NB_CACHEES;j++) poids_sorties[k][j]=calculer_nb_aleatoire(MIN_ALEA,MAX_ALEA);
seuils_sorties[k]=calculer_nb_aleatoire(MIN_ALEA,MAX_ALEA);
}
for(j=0;j<NB_CACHEES;j++) {
for(i=0;i<NB_ENTREES;i++) poids_cachees[j][i]=calculer_nb_aleatoire(MIN_ALEA,MAX_ALEA);
seuils_cachees[j]=calculer_nb_aleatoire(MIN_ALEA,MAX_ALEA);
}
}
/****************************************************************/
/* calcule les activations des neurones de sorties */
void calculer_sorties(void)
{
register int i,j,k;
TYPE_REEL net;
for(j=0;j<NB_CACHEES;j++) {
net=0.0;
for(i=0;i<NB_ENTREES;i++) net+=activations_entrees[i]*poids_cachees[j][i];
activations_cachees[j]=sigmoid(net-seuils_cachees[j]);
}
for(k=0;k<NB_SORTIES;k++) {
net=0.0;
for(j=0;j<NB_CACHEES;j++) net+=activations_cachees[j]*poids_sorties[k][j];
activations_sorties[k]=sigmoid(net-seuils_cachees[k]);
Page 86
}
}
/****************************************************************/
/* calcule les variations entre valeurs d’apprentissage et valeur courante */
void calculer_deltas(void)
{
register int j,k;
TYPE_REEL erreur;
for(k=0;k<NB_SORTIES;k++) {
erreur=activations_apprentissage[k]-activations_sorties[k];
delta_sorties[k]=erreur*activations_sorties[k]*(1.0-activations_sorties[k]);
}
for(j=0;j<NB_CACHEES;j++) {
for(erreur=0.0,k=0;k<NB_SORTIES;k++) erreur+=delta_sorties[k]*poids_sorties[k][j];
delta_cachees[j]=erreur*activations_cachees[j]*(1.0-activations_cachees[j]);
}
}
/****************************************************************/
/* modifie les poids des connexions en fonction des variations mesurées */
void changer_poids(void)
{
register int i,j,k;
for(k=0;k<NB_SORTIES;k++) {
for(j=0;j<NB_CACHEES;j++) {
delta_poids_sorties[k][j]=EPSILON*delta_sorties[k]*activations_cachees[j]+
Page 87
MOMENTUM*delta_poids_sorties[k][j];
poids_sorties[k][j]+=delta_poids_sorties[k][j];
}
delta_seuils_sorties[k]=-1.0*EPSILON*delta_sorties[k]+MOMENTUM*delta_seuils_sorties[k];
seuils_sorties[k]+=delta_seuils_sorties[k];
}
for(j=0;j<NB_CACHEES;j++) {
for(i=0;i<NB_ENTREES;i++) {
delta_poids_cachees[j][i]=EPSILON*delta_cachees[j]*activations_entrees[i]+
MOMENTUM*delta_poids_cachees[j][i];
poids_cachees[j][i]+=delta_poids_cachees[j][i];
}
delta_seuils_cachees[j]=-1.0*EPSILON*delta_cachees[j]+MOMENTUM*delta_seuils_cachees[j];
seuils_cachees[j]+=delta_seuils_cachees[j];
}
}
/****************************************************************/
/* mesure l’erreur Pss (somme des carrés des différences) des valeurs d’activations des neurones de sorties*/
TYPE_REEL calculer_pss(void)
{
register int k;
TYPE_REEL res=0.0;
for(k=0;k<NB_SORTIES;k++)
res+=(activations_apprentissage[k]-activations_sorties[k])*
(activations_apprentissage[k]-activations_sorties[k]);
return res;
Page 88
}
/****************************************************************/
/* affichage des seuils des neurones et des poids des connexions */
void afficher_seuils_et_poids(void)
{
register int i,j,k;
for(k=0;k<NB_SORTIES;k++) {
printf("seuils_sorties(%2d)=%5.2f ",k,seuils_sorties(k]);
for(j=0;j<NB_CACHEES;j++) printf("%5.2f ",poids_sorties[k][j]); printf("\n");
}
printf("\n");
for(k=0;k<NB_CACHEES;k++) {
printf("seuils_cachees(%2d)=%5.2f ",k,seuils_cachees[k]);
for(j=0;j<NB_ENTREES;j++) printf("%5.2f ",poids_cachees[k][j]); printf("\n");
}
printf("\n");
}
/****************************************************************/
/* sauvegarde des seuils et des poids pour une réutilisation */
void sauver_seuils_et_poids(char *fichier)
{
register int i,j,k;
FILE *fp=fopen(fichier,"wt");
if (fp==NULL) { printf("Sauvegarde impossible\n"); return; }
Page 89
fprintf(fp,"seuils_sorties\n");
for(k=0;k<NB_SORTIES;k++) {
fprintf(fp,"%5.2f\n",seuils_sorties[k]);
for(j=0;j<NB_CACHEES;j++) fprintf(fp,"%5.2f\n",poids_sorties[k][j]);
}
fprintf(fp,"seuils_cachees\n");
for(k=0;k<NB_CACHEES;k++) {
fprintf(fp,"%5.2f\n",k,seuils_cachees[k]);
for(j=0;j<NB_ENTREES;j++) fprintf(fp,"%5.2f\n",poids_cachees[k][j]);
}
fclose(fp);
}
/****************************************************************/
void main(void)
{
register int nb_presentations;
long p;
unsigned char i,s[30],a,b;
TYPE_REEL tss,pss;
randomize();
initialiser_poids();
for(nb_presentations=0;nb_presentations<NB_PRESENTATIONS;nb_presentations++){
printf("Présentation: %3d ",nb_presentations+1);
tss=0.0;
Page 90
/* presentation des exemples */
for(p=0L;p<NB_EXEMPLES;p++) {
/* init s */
a=(p & 0xFF00)>>8; for(i=0;i<8;i++) s[i]=( (a & (1<<i)) != 0 );
b=p & 0xFF; for(i=0;i<8;i++) s[i+8]=( (b & (1<<i)) != 0 );
a^=b; for(i=0;i<8;i++) s[i+16]=( (a & (1<<i)) != 0 );
/* presentation entrees et sorties */
for(i=0;i<NB_ENTREES;i++) activations_entrees[i]=(TYPE_REEL)s[i];
for(i=0;i<NB_SORTIES;i++) activations_apprentissage[i]=(TYPE_REEL)s[i+NB_ENTREES];
/* calcul apprentissage */
calculer_sorties(); calculer_deltas(); changer_poids();
/* calcul d'erreur */
pss=calculer_pss(); tss+=pss;
}
printf("\ttss=%7.6f\n",tss); /*getch();*/
}
sauver_seuils_et_poids("XOR.PDS");
do {
printf("Valeur pour a (8 bits) et b (8 bits) ? "); gets(s);
for(i=0;i<NB_ENTREES;i++) activations_entrees[i]=(TYPE_REEL)(s[i]-'0');
calculer_sorties();
printf(" a XOR b=");
for(p=0;p<NB_SORTIES;p++) printf("%1.1f ",activations_sorties[p] );
printf("\tTouche ... (ECHAP pour quitter)\n");
}
while(getch()!=27);
Page 91
}
Vigenere ciffer or simple XOR
/* USE: CRYPTXOR clef fichier_source fichier_cible */
#include <stdio.h>
main(int argc,char **argv)
{
FILE *fi,*fo;
int *cp=argv[1],c;
if (argc==1) {
if ((fi=fopen(argv[2], rb ))==NULL) return 1;
if ((fo=fopen(argv[3], wb ))==NULL) return 2;
while ((c=getc(fi)) != EOF) {
if (!*cp) cp=argv(1);
c ^= *(cp++);
putc(c,fo);
}
fclose(fo);
fclose(fi);
}
return 0;
}
Cryptanalysis of Vigenere Ciffer
/*
Use: DEVIGENE <encrypted file(input)> <decrypted file (output)> (<most used char >)
Mot used char is an integer : 32 for textfile, 0 for binary file
Page 92
*/
#include <stdio.h>
#include <stdlib.h>
#include <math.h>
#include <alloc.h>
#define TRUE -1
#define FALSE 0
#define BLOCK 8
#define NB_BYTES 256
int main(int argc,char **argv)
{
register int byte, byte_num;
static int num_bytes;
static unsigned long file_size;
static unsigned int *freq[BLOCK], *freq_ptr, max_freq;
static unsigned char buffer[BLOCK],key[BLOCK], max_char, most_common;
FILE *infile, *outfile;
if ( !(argc == 3) || (argc == 4)) return 1; /* arguments incorrects */
for (byte_num=0; byte_num < BLOCK; byte_num++) {
freq_ptr=(unsigned int *) malloc(BLOCK/2);
freq[byte_num]=freq_ptr;
for (byte=0; byte < BLOCK/2; byte++) *(freq_ptr++)=(unsigned int) 0;
}
Page 93
if ((infile=fopen(argv[1],"rb")) == NULL) return 2; /* fichier introuvable */
file_size=(unsigned long) 0L;
while ((num_bytes=fread(&buffer[0],1,BLOCK,infile)) > 0) {
for (byte_num=0; byte_num < num_bytes; byte_num++)
(freq[byte_num][buffer[byte_num]])++;
file_size+=((unsigned int) num_bytes);
}
if (file_size < (unsigned long) BLOCK*20L) return 3; /* taille de fichier non suffisante pour decoder */
if (argc == 4) most_common=(unsigned char) atoi(argv[3]); else most_common=32;
for (byte_num=0; byte_num < BLOCK; byte_num++) {
max_char=(unsigned char) '\0'; max_freq=(unsigned int) 0;
for (byte=0; byte < BLOCK/2; byte++)
if (freq[byte_num][byte] > max_freq) {
max_freq=freq[byte_num][byte]; max_char=(unsigned char) byte;
}
key[byte_num]=max_char^most_common;
}
fseek(infile,0L,SEEK_SET);
if ((outfile=fopen(argv[2],"wb")) == NULL) return 4; /* ouverture de fichier impossible */
while ((num_bytes=fread(&buffer[0],1,BLOCK,infile)) > 0) {
for (byte_num=0; byte_num < num_bytes; byte_num++) buffer[byte_num]^=key[byte_num];
if (fwrite(&buffer[0],1,num_bytes,outfile) != num_bytes) return 5; /* erreur d’ecriture */
}
fclose(outfile);
Page 94
fclose(infile);
for (byte_num=(BLOCK/2)-1; byte_num >= 0; byte_num--) free(freq[byte_num]);
return 0;
}
D.E.S. Code
/*
CODEDES.C - D.E.S. Encryption of string
Dourlens Sébastien
V1.0
04.01.1996
*/
#define PERMUT_OK 0 /* accorder ou non le traitement des permutations initiales et finales */
/*///////////// VAR. GLOBALES //////////////*/
char bi[65]={7,6,5,4,3,2,1,0,7,6,5,4,3,2,1,0,7,6,5,4,3,2,1,0,7,6,5,4,3,2,1,0,
7,6,5,4,3,2,1,0,7,6,5,4,3,2,1,0,7,6,5,4,3,2,1,0,7,6,5,4,3,2,1,0 };
char bj[33]={3,2,1,0,3,2,1,0,3,2,1,0,3,2,1,0,3,2,1,0,3,2,1,0,3,2,1,0,3,2,1,0 };
/* Permutation de la clef */
char s_CleDess[57]={57,49,41,33,25,17,9,1,58,50,42,34,26,18,10,2,59,51,43,35,27,19,11,3,60,52,4,36,
63,55,47,39,31,23,15,7,62,54,46,38,30,22,14,6,61,53,45,37,29,21,13,5,28,20,12,4};
/* permutation compressive de la clef */
char perm2[49]={ 14,17,11,24,1,5,3,28,15,6,21,10, 23,19,12,4,26,8,16,7,27,20,13,2,
41,52,31,37,47,55,30,40,51,45,33,48, 44,49,39,56,34,53,46,42,50,36,29,32 };
/* Decalage de clef par ronde */
char decal[16]={1,1,2,2,2,2,2,2,1,2,2,2,2,2,2,1};
/* 8 S-tables */
char table[8][4][16]={{{
Page 95
14,4,13,1,2,15,11,8,3,10,6,12,5,9,0,7}, {0,15,7,4,14,2,13,1,10,6,12,11,9,5,3,8},
{4,1,14,8,13,6,2,11,15,12,9,7,3,10,5,0}, {15,12,8,2,4,9,1,7,5,11,3,14,10,0,6,13}},
{{15,1,8,14,6,11,3,4,9,7,2,13,12,0,5,10}, {3,13,4,7,15,2,8,14,12,0,1,10,6,9,11,5},
{0,14,7,11,10,4,13,1,5,8,12,6,9,3,2,15}, {13,8,10,1,3,15,4,2,11,6,7,12,0,5,14,9}},
{{10,0,9,14,6,3,15,5,1,13,12,7,11,4,2,8}, {13,7,0,9,3,4,6,10,2,8,5,14,12,11,15,1},
{13,6,4,9,8,15,3,0,11,1,2,12,5,10,14,7}, {1,10,13,0,6,9,8,7,4,15,14,3,11,5,2,12}},
{{7,13,14,3,0,6,9,10,1,2,8,5,11,12,4,15}, {13,8,11,5,6,15,0,3,4,7,2,12,1,10,14,9},
{10,6,9,0,12,11,7,13,15,1,3,14,5,2,8,4}, {3,15,0,6,10,1,13,8,9,4,5,11,12,7,2,14}},
{{2,12,4,1,7,10,11,6,8,5,3,15,13,0,14,9}, {14,11,2,12,4,7,13,1,5,0,15,10,3,9,8,6},
{4,2,1,11,10,13,7,8,15,9,12,5,6,3,0,14}, {11,8,12,7,1,14,2,13,6,15,0,9,10,4,5,3}},
{{12,1,10,15,9,2,6,8,0,13,3,4,14,7,5,11}, {10,15,4,2,7,12,9,5,6,1,13,14,0,11,3,8},
{9,14,15,5,2,8,12,3,7,0,4,10,1,13,11,6}, {4,3,2,12,9,5,15,10,11,14,1,7,6,0,8,13}},
{{4,11,2,14,15,0,8,13,3,12,9,7,5,10,6,1}, {13,0,11,7,4,9,1,10,14,3,5,12,2,15,8,6},
{1,4,11,13,12,3,7,14,10,15,6,8,0,5,9,2}, {6,11,13,8,1,4,10,7,9,5,0,15,14,2,3,12}},
{{13,2,8,4,6,15,11,1,10,9,3,14,5,0,12,7}, {1,15,13,8,10,3,7,4,12,5,6,11,0,14,9,2},
{7,11,4,1,9,12,14,2,0,6,10,13,15,3,5,8}, {2,1,14,7,4,10,8,13,15,12,9,0,3,5,6,11}}};
/* permutation initiale IPERM du texte donné */
char perm[65]={ 58,50,42,34,26,18,10,2,60,52,44,36,28,20,12,4,62,54,46,38,30,22,14,6,64,56,48,40,32,24,16,8,
57,49,41,33,25,17,9,1,59,51,43,35,27,19,11,3,61,53,45,37,29,21,13,5,63,55,47,39,31,23,15,7};
/* permutation finale I-1PERM du texte donné */
char invperm[65]={
40,8,48,16,56,24,64,32,39,7,47,15,55,23,63,31,38,6,46,14,54,22,62,30,37,5,45,13,53,21,61,29,
36,4,44,12,52,20,60,28,35,3,43,11,51,19,59,27,34,2,42,10,50,18,58,26,33,1,41,9,49,17,57,25 };
/* Permutation expansive */
char select[49]={ 32,1,2,3,4,5,4,5,6,7,8,9,8,9,10,11,12,13,12,13,14,15,16,17,
16,17,18,19,20,21,20,21,22,23,24,25,24,25,26,27,28,29,28,29,30,31,32,1 };
/* Permutation-P */
char perm3[33]={16,7,20,21,29,12,28,17,1,15, 23,26,5,18,31,10,2,8,24,14,32,27,3,9,19,13,30,6,22,11,4,25 };
char bloc[8][6]={ {1,2,3,4,5,6}, {7,8,9,10,11,12}, {13,14,15,16,17,18}, {19,20,21,22,23,24},
{25,26,27,28,29,30}, {31,32,33,34,35,36},{37,38,39,40,41,42}, {43,44,45,46,47,48} };
/* clef codée */
int Cl[17][49];
Page 96
/* codage de la clef // entree: chaine de la clef de 8 car.// sortie: aucune */
void traiter_clef(char *CleDess)
{
int i,p,iter;
int CleDessk[57];
int bk[65],l[29],r[29]; /* buf, left et right */
/* calcul de la clef K */
for(i=0;i<=64;i++) { p=bi[i-1]; bk[i]=(CleDess[(i-1)/8]&(1<<p))>>p; }
/* permutation initiale de la clef */
for(i=1;i<=56;i++) CleDessk[i]=bk[s_CleDess[i-1]];
/* calculer les 16 blocs de clef */
for(iter=1;iter<=16;iter++) {
for(i=1;i<=28-decal[iter-1];i++) {
l[i]=CleDessk[i+decal[iter-1]];
r[i]=CleDessk[i+28+decal[iter-1]]; }
for(i=28-decal[iter-1]+1;i<=28;i++) {
l[i]=CleDessk[i-28+decal[iter-1]];
r[i]=CleDessk[i+decal[iter-1]]; }
for(i=1;i<=28;i++){ CleDessk[i]=l[i]; CleDessk[i+28]=r[i]; }
/* permutation compressive d'un bloc de la clef */
for(i=1;i<=48;i++) Cl[iter][i]=CleDessk[perm2[i-1]];
}
}
/* entrees : a=99:coder,a=100:decoder, buffer, taille du buffer
notes: le buffer d'entree/sortie doit avoir une taille % 8, la taille est % 8 */
void codage_des(char a,char *buffer,long taille)
Page 97
{
int i,j,iter; /* compteurs */
long lgr; /* compteur */
int b[8],lig,col,e=0,f=1,k=0,p;
int res[8],g[33],temp[33],d[33],s[49];
int bk[65],bk1[65];
char *ptr;
unsigned char buf[2048]; /* buffer tampon */
/* buffer */
ptr=buf;
/* init codage ou decodage */
if (a==100) { e=1;f=-1;} k=0;
for(lgr=0L;lgr<taille;) {
b[k]=buffer[lgr++];
if (k<=6) k++;
else {
k=0;
for(i=1;i<=64;i++) {
p=bi[i-1];
#if (PERMUT_OK)
bk1[i]=(b[(i-1)/8]&(1<<p))>>p;
#else
bk[i]=(b[(i-1)/8]&(1<<p))>>p;
#endif
}
#if (PERMUT_OK)
Page 98
/* permutation initiale */
for(i=1;i<=64;i++) bk[i]=bk1[perm[i-1]];
#endif
/* les 16 rondes */
for(iter=1;iter<=16;iter++) {
for(i=1;i<=32;i++) { g[i]=bk[i]; d[i]=bk[i+32]; }
for(i=1;i<=48;i++) s[i]=d[select[i-1]];
j=e*17+f*iter;
for(i=1;i<=48;i++) s[i]=s[i]^Cl[j][i];
/* 8 S-tables */
for(j=0;j<8;j++){
lig=(s[bloc[j][0]]<<1)+s[bloc[j][5]];
col=(s[bloc[j][1]]<<3)+(s[bloc[j][2]]<<2)+(s[bloc[j][3]]<<1)+s[bloc[j][4]];
res[j]=table[j][lig][col];
}
for(i=1;i<=32;i++) { p=bj[i]; s[i]=(res[(i-1)/4]&(1<<p))>>p; }
if (iter!=16) for(i=1;i<=32;i++) { temp[i]=s[perm3[i-1]]^g[i];g[i]=d[i];d[i]=temp[i]; }
else for(i=1;i<=32;i++){ temp[i]=s[perm3[i-1]]^g[i];g[i]=temp[i]; }
for(i=1;i<=32;i++){ bk[i]=g[i];bk[i+32]=d[i]; }
#if (PERMUT_OK)
/* Permutation finale */
if (iter==16) {
for(i=1;i<=64;i++) bk1[i]=bk[invperm[i-1]];
for(i=1;i<=64;i++) bk[i]=bk1[i];
}
#endif
}
/* ecriture d'un bloc */
Page 99
for(i=0;i<=7;i++) {
for(p=0,j=1;j<=8;j++) p+=(1<<(8-j))*bk[8*i+j];
*ptr++=p;
} } }
/* copie */
ptr=buf;
for(lgr=0L;lgr<taille;lgr++) buffer[lgr]=*ptr++;
}
XOR learning in desorder
/* XOR4.C : 8 bits (4 :entree1, 4:entree2, 4 bits en:sortie)
*/
#include <stdio.h>
#include <conio.h>
#include <math.h>
#include <stdlib.h>
#include <time.h>
#define NB_ENTREES 8
#define NB_CACHEES 8
#define NB_SORTIES 4
#define NB_EXEMPLES 256
#define NB_PRESENTATIONS 500
#define EPSILON 2.0
#define MOMENTUM 0.1
#define MAX_ALEA 0.3
#define MIN_ALEA -0.3
Page 100
#define TYPE_REEL double
TYPE_REEL exemples_entrees[NB_ENTREES], exemples_sorties[NB_SORTIES];
TYPE_REEL activations_cachees[NB_CACHEES], activations_entrees[NB_ENTREES];
TYPE_REEL activations_sorties[NB_SORTIES], activations_apprentissage[NB_SORTIES];
TYPE_REEL delta_sorties[NB_SORTIES], delta_cachees[NB_CACHEES];
TYPE_REEL seuils_sorties[NB_SORTIES], delta_seuils_sorties[NB_SORTIES];
TYPE_REEL seuils_cachees[NB_CACHEES], delta_seuils_cachees[NB_CACHEES];
TYPE_REEL poids_sorties[NB_SORTIES][NB_CACHEES];
TYPE_REEL delta_poids_sorties[NB_SORTIES][NB_CACHEES];
TYPE_REEL poids_cachees[NB_CACHEES][NB_ENTREES];
TYPE_REEL delta_poids_cachees[NB_CACHEES][NB_ENTREES];
const char *ch[]={
"000000000000","100000001000","010000000100","110000001100","001000000010","101000001010","01100
0000110","111000001110","000100000001",
"100100001001","010100000101","110100001101","001100000011","101100001011","011100000111","11110
0001111","000010001000","100010000000",
"010010001100","110010000100","001010001010","101010000010","011010001110","111010000110","00011
0001001","100110000001","010110001101",
"110110000101","001110001011","101110000011","011110001111","111110000111","000001000100","10000
1001100","010001000000","110001001000",
"001001000110","101001001110","011001000010","111001001010","000101000101","100101001101","01010
1000001","110101001001","001101000111",
"101101001111","011101000011","111101001011","000011001100","100011000100","010011001000","11001
1000000","001011001110","101011000110",
"011011001010","111011000010","000111001101","100111000101","010111001001","110111000001","00111
1001111","101111000111","011111001011",
"111111000011","000000100010","100000101010","010000100110","110000101110","001000100000","10100
0101000","011000100100","111000101100",
"000100100011","100100101011","010100100111","110100101111","001100100001","101100101001","01110
0100101","111100101101","000010101010",
"100010100010","010010101110","110010100110","001010101000","101010100000","011010101100","11101
0100100","000110101011","100110100011",
Page 101
"010110101111","110110100111","001110101001","101110100001","011110101101","111110100101","00000
1100110","100001101110","010001100010",
"110001101010","001001100100","101001101100","011001100000","111001101000","000101100111","10010
1101111","010101100011","110101101011",
"001101100101","101101101101","011101100001","111101101001","000011101110","100011100110","01001
1101010","110011100010","001011101100",
"101011100100","011011101000","111011100000","000111101111","100111100111","010111101011","11011
1100011","001111101101","101111100101",
"011111101001","111111100001","000000010001","100000011001","010000010101","110000011101","00100
0010011","101000011011","011000010111",
"111000011111","000100010000","100100011000","010100010100","110100011100","001100010010","10110
0011010","011100010110","111100011110",
"000010011001","100010010001","010010011101","110010010101","001010011011","101010010011","01101
0011111","111010010111","000110011000",
"100110010000","010110011100","110110010100","001110011010","101110010010","011110011110","11111
0010110","000001010101","100001011101",
"010001010001","110001011001","001001010111","101001011111","011001010011","111001011011","00010
1010100","100101011100","010101010000",
"110101011000","001101010110","101101011110","011101010010","111101011010","000011011101","10001
1010101","010011011001","110011010001",
"001011011111","101011010111","011011011011","111011010011","000111011100","100111010100","01011
1011000","110111010000","001111011110",
"101111010110","011111011010","111111010010","000000110011","100000111011","010000110111","11000
0111111","001000110001","101000111001",
"011000110101","111000111101","000100110010","100100111010","010100110110","110100111110","00110
0110000","101100111000","011100110100",
"111100111100","000010111011","100010110011","010010111111","110010110111","001010111001","10101
0110001","011010111101","111010110101",
"000110111010","100110110010","010110111110","110110110110","001110111000","101110110000","01111
0111100","111110110100","000001110111",
"100001111111","010001110011","110001111011","001001110101","101001111101","011001110001","11100
1111001","000101110110","100101111110",
"010101110010","110101111010","001101110100","101101111100","011101110000","111101111000","00001
1111111","100011110111","010011111011",
"110011110011","001011111101","101011110101","011011111001","111011110001","000111111110","10011
1110110","010111111010","110111110010",
"001111111100","101111110100","011111111000","111111110000" };
Page 102
/****************************************************************/
TYPE_REEL sigmoid(TYPE_REEL x)
{
return( 1.0/(1.0+exp(-1.0*x)) );
}
/****************************************************************/
TYPE_REEL calculer_nb_aleatoire(TYPE_REEL min,TYPE_REEL max)
{
TYPE_REEL r=((rand()*(max-min))/32767.0)+min;
return r;
}
/****************************************************************/
void initialiser_poids(void)
{
int i,j,k;
for(k=0;k<NB_SORTIES;k++) {
for(j=0;j<NB_CACHEES;j++)
poids_sorties[k][j]=calculer_nb_aleatoire(MIN_ALEA,MAX_ALEA);
seuils_sorties[k]=calculer_nb_aleatoire(MIN_ALEA,MAX_ALEA);
}
for(j=0;j<NB_CACHEES;j++) {
for(i=0;i<NB_ENTREES;i++)
poids_cachees[j][i]=calculer_nb_aleatoire(MIN_ALEA,MAX_ALEA);
Page 103
seuils_cachees[j]=calculer_nb_aleatoire(MIN_ALEA,MAX_ALEA);
}
}
/****************************************************************/
void calculer_sorties(void)
{
int i,j,k;
TYPE_REEL net;
for(j=0;j<NB_CACHEES;j++) {
net=0.0;
for(i=0;i<NB_ENTREES;i++) net+=activations_entrees[i]*poids_cachees[j][i];
activations_cachees[j]=sigmoid(net-seuils_cachees[j]);
}
for(k=0;k<NB_SORTIES;k++) {
net=0.0;
for(j=0;j<NB_CACHEES;j++) net+=activations_cachees[j]*poids_sorties[k][j];
activations_sorties[k]=sigmoid(net-seuils_sorties[k]);
}
}
/****************************************************************/
void calculer_deltas(void)
{
int j,k;
Page 104
TYPE_REEL erreur;
for(k=0;k<NB_SORTIES;k++) {
erreur=activations_apprentissage[k]-activations_sorties[k];
delta_sorties[k]=erreur*activations_sorties[k]*(1.0-activations_sorties[k]);
}
for(j=0;j<NB_CACHEES;j++) {
erreur=0.0;
for(k=0;k<NB_SORTIES;k++) erreur+=delta_sorties[k]*poids_sorties[k][j];
delta_cachees[j]=erreur*activations_cachees[j]*(1.0-activations_cachees[j]);
}
}
/****************************************************************/
void changer_poids(void)
{
int i,j,k;
for(k=0;k<NB_SORTIES;k++) {
for(j=0;j<NB_CACHEES;j++) {
delta_poids_sorties[k][j]=EPSILON*delta_sorties[k]*activations_cachees[j]+
MOMENTUM*delta_poids_sorties[k][j];
poids_sorties[k][j]+=delta_poids_sorties[k][j];
}
delta_seuils_sorties[k]=-1.0*EPSILON*delta_sorties[k]+MOMENTUM*delta_seuils_sorties[k];
seuils_sorties[k]+=delta_seuils_sorties[k];
}
Page 105
for(j=0;j<NB_CACHEES;j++) {
for(i=0;i<NB_ENTREES;i++) {
delta_poids_cachees[j][i]=EPSILON*delta_cachees[j]*activations_entrees[i]+
MOMENTUM*delta_poids_cachees[j][i];
poids_cachees[j][i]+=delta_poids_cachees[j][i];
}
delta_seuils_cachees[j]=-1.0*EPSILON*delta_cachees[j]+MOMENTUM*delta_seuils_cachees[j];
seuils_cachees[j]+=delta_seuils_cachees[j];
}
}
/****************************************************************/
TYPE_REEL calculer_pss(void)
{
int k;
TYPE_REEL res=0.0;
for(k=0;k<NB_SORTIES;k++)
res+=(activations_apprentissage[k]-activations_sorties[k])*
(activations_apprentissage[k]-activations_sorties[k]);
return res;
}
/****************************************************************/
void afficher_seuils_et_poids(void)
{
Page 106
int i,j,k;
for(k=0;k<NB_SORTIES;k++) {
printf("seuils_sorties[%2d]=%5.2lf ",k,seuils_sorties[k]);
for(j=0;j<NB_CACHEES;j++) printf("%5.2lf ",poids_sorties[k][j]);
printf("\n");
}
printf("\n");
for(k=0;k<NB_CACHEES;k++) {
printf("seuils_cachees[%2d]=%5.2lf ",k,seuils_cachees[k]);
for(j=0;j<NB_ENTREES;j++) printf("%5.2lf ",poids_cachees[k][j]);
printf("\n");
}
printf("\n");
}
/****************************************************************/
choose_sample(int p)
{
int K=8; /* separer l'ensemble des exemples en K sous-ensembles */
int d,n=NB_EXEMPLES/K;
d=(int) (p/n);
return( ((p-(d*n))*K)+d );
}
Page 107
/****************************************************************/
void main(void)
{
int nb_presentations,p,n;
unsigned char i,s[10];
TYPE_REEL tss,pss[NB_EXEMPLES];
clrscr();
randomize();
initialiser_poids();
/* afficher_seuils_et_poids(); */
for(nb_presentations=0;nb_presentations<NB_PRESENTATIONS;nb_presentations++){
gotoxy(1,1); printf("Présentation: %3d ",nb_presentations);
tss=0.0;
for(p=0;p<NB_EXEMPLES;p++) {
n=choose_sample(p);
for(i=0;i<NB_ENTREES;i++) activations_entrees[i]=(TYPE_REEL)(ch[n][i]-'0');
for(i=0;i<NB_SORTIES;i++) activations_apprentissage[i]=(TYPE_REEL)(ch[n][i+NB_ENTREES]-'0');
calculer_sorties();
calculer_deltas();
changer_poids();
pss[p]=calculer_pss();
tss+=pss[p];
}
printf("\ttss(%d)=%7.6f\n",nb_presentations,tss); /*getch();*/
}
afficher_seuils_et_poids();
Page 108
}
Automatic Generation of training base for D.E.S.
#include <stdio.h>
#include <dos.h>
#include <time.h>
#include <conio.h>
#include <string.h>
#include <stdlib.h>
#include "codedes.c"
#define coder_des(s) codage_des(99,s,8L)
#define decoder_des(s) codage_des(100,s,8L)
char *alphabet=" ABCDEFGHIJKLMNOPQRSTUVWXYZ"\
"abcdefghijklmnopqrstuvwxyz0123456789";
#define NB_BCL 8
/*
entrees: valeurs des compteurs de boucles
retour : 0=continuer, 1=terminer
*/
corps(int i_bcl[NB_BCL])
{
int i,c;
static long n=0L;
unsigned char s[256];
Page 109
for(i=0;i<NB_BCL;i++) s[i]=alphabet[i_bcl[i]];
for(c=0;c<8;c++) printf("%c",s[c]);
coder_des(s);
printf(" ");
for(c=0;c<8;c++) printf("%02X",s[c]);
printf("\n");
n++;
if (n==64267L) { printf("%ld clefs testees\n",n); return 1; }
if (kbhit()) { if (!getch()) getch(); printf("%ld clefs testees\n",n); return 1;}
return 0;
}
/* NB_BCL boucles imbriquees i
du type for(boucle[i]=d;boucle[i]<f;boucle[i]++) { corps(); }
note: la derniere boucle seule contient le corps
*/
void compter(int d,int f)
{
int b,i_bcl[NB_BCL],f_bcl[NB_BCL];
unsigned char maclef[9]="*SECRET*";
struct time T,F;
clrscr();
traiter_clef(maclef);
gettime(&T);
Page 110
/* init. valeurs de depart */
for(b=0;b<NB_BCL;b++) i_bcl[b]=d;
/* init. valeurs de fin */
for(b=0;b<NB_BCL;b++) f_bcl[b]=f-1;
while(1) {
b=NB_BCL-1;
if (corps(i_bcl)) break;
if (i_bcl[b]<f_bcl[b]) i_bcl[b]++;
else {
precedent:
i_bcl[b]=d;
if (b==0) break; else b--;
if (i_bcl[b]<f_bcl[b]) i_bcl[b]++;
else goto precedent;
}
}
gettime(&F);
printf("\nHeure de debut: %2d:%02d:%02d.%02d\n",
T.ti_hour, T.ti_min, T.ti_sec, T.ti_hund);
printf("Heure de fin: %2d:%02d:%02d.%02d\n",
F.ti_hour, F.ti_min, F.ti_sec, F.ti_hund);
}
main()
{
Page 111
int l=strlen(alphabet);
compter(0,l);
}
Generation of differences distribution tables of D.E.S.
/*
CRYPTDIF.C - Calcul des tables de distributions des différences du DES
selon la méthode E.BIHAM/A.SHAMIR
Dourlens Sébastien
V1.00
*/
#include <stdio.h>
/* les 8 S-tables */
char Table[8][4][16]={
{{14,4,13,1,2,15,11,8,3,10,6,12,5,9,0,7},{0,15,7,4,14,2,13,1,10,6,12,11,9,5,3,8},
{4,1,14,8,13,6,2,11,15,12,9,7,3,10,5,0},{15,12,8,2,4,9,1,7,5,11,3,14,10,0,6,13}},
{{15,1,8,14,6,11,3,4,9,7,2,13,12,0,5,10},{3,13,4,7,15,2,8,14,12,0,1,10,6,9,11,5},
{0,14,7,11,10,4,13,1,5,8,12,6,9,3,2,15},{13,8,10,1,3,15,4,2,11,6,7,12,0,5,14,9}},
{{10,0,9,14,6,3,15,5,1,13,12,7,11,4,2,8},{13,7,0,9,3,4,6,10,2,8,5,14,12,11,15,1},
{13,6,4,9,8,15,3,0,11,1,2,12,5,10,14,7},{1,10,13,0,6,9,8,7,4,15,14,3,11,5,2,12}},
{{7,13,14,3,0,6,9,10,1,2,8,5,11,12,4,15},{13,8,11,5,6,15,0,3,4,7,2,12,1,10,14,9},
{10,6,9,0,12,11,7,13,15,1,3,14,5,2,8,4},{3,15,0,6,10,1,13,8,9,4,5,11,12,7,2,14}},
{{2,12,4,1,7,10,11,6,8,5,3,15,13,0,14,9},{14,11,2,12,4,7,13,1,5,0,15,10,3,9,8,6},
{4,2,1,11,10,13,7,8,15,9,12,5,6,3,0,14},{11,8,12,7,1,14,2,13,6,15,0,9,10,4,5,3}},
{{12,1,10,15,9,2,6,8,0,13,3,4,14,7,5,11},{10,15,4,2,7,12,9,5,6,1,13,14,0,11,3,8},
{9,14,15,5,2,8,12,3,7,0,4,10,1,13,11,6},{4,3,2,12,9,5,15,10,11,14,1,7,6,0,8,13}},
{{4,11,2,14,15,0,8,13,3,12,9,7,5,10,6,1},{13,0,11,7,4,9,1,10,14,3,5,12,2,15,8,6},
{1,4,11,13,12,3,7,14,10,15,6,8,0,5,9,2},{6,11,13,8,1,4,10,7,9,5,0,15,14,2,3,12}},
{{13,2,8,4,6,15,11,1,10,9,3,14,5,0,12,7},{1,15,13,8,10,3,7,4,12,5,6,11,0,14,9,2},
{7,11,4,1,9,12,14,2,0,6,10,13,15,3,5,8},{2,1,14,7,4,10,8,13,15,12,9,0,3,5,6,11}}};
Page 112
/****************************************************************/
/* Entrées : 0<=tb<=7, 0<=val<=63 */
/* note: la ligne correspond au bits 0 et 5 de val et la colonne aux bits de 1 a 4 */
char calculer_s_table(char tb,char val)
{
char j,t[6],lig,col;
for(j=0;j<6;j++) t[j]=((val & (1<<j))!=0)?1:0;
lig=(t[5]<<1)+t[0]; col=(t[4]<<3)+(t[3]<<2)+(t[2]<<1)+t[1];
return Table[tb][lig][col];
}
/****************************************************************/
void main(void)
{
char p,pe,pp,t,x,xe,xp;
char tab_dif[64][16],tb;
for(tb=0;tb<8;tb++) {
printf("\nS-Table %d\n\n",tb+1);
/* initialiser la table a 0 */
for(p=0;p<64;p++) for(t=0;t<16;t++) tab_dif[p][t]=0;
Page 113
/* remplir la table diff. */
for(p=0;p<64;p++) { /* on choisi une paire d'entrées */
for(pe=0;pe<64;pe++) {
pp=p^pe; /* on calcule le XOR des entrées, */
x=calculer_s_table(tb,p);
xe=calculer_s_table(tb,pe);
xp=x^xe; /* on calcule le XOR des sorties */
tab_dif[pp][xp]++;
}}
/* afficher les résultats */
printf(" 00x 01x 02x 03x 04x 05x 06x 07x 08x 09x 0Ax 0Bx 0Cx 0Dx 0Ex 0Fx\n");
for(p=0;p<64;p++) {
printf("%02Xx ",p);
for(t=0;t<16;t++) printf("%02d ",tab_dif[p][t]);
printf("\n");
}
}}
Linear approximation tables Generation for D.E.S.
/*
CRYPTLIN.C - Calcul des tables d'approximations linéaires du DES
selon la méthode M.MATSUI
Dourlens Sébastien
V1.00
*/
#include <stdio.h>
Page 114
/* les 8 S-tables */
char Table[8][4][16]={
{{14,4,13,1,2,15,11,8,3,10,6,12,5,9,0,7},{0,15,7,4,14,2,13,1,10,6,12,11,9,5,3,8},
{4,1,14,8,13,6,2,11,15,12,9,7,3,10,5,0},{15,12,8,2,4,9,1,7,5,11,3,14,10,0,6,13}},
{{15,1,8,14,6,11,3,4,9,7,2,13,12,0,5,10},{3,13,4,7,15,2,8,14,12,0,1,10,6,9,11,5},
{0,14,7,11,10,4,13,1,5,8,12,6,9,3,2,15},{13,8,10,1,3,15,4,2,11,6,7,12,0,5,14,9}},
{{10,0,9,14,6,3,15,5,1,13,12,7,11,4,2,8},{13,7,0,9,3,4,6,10,2,8,5,14,12,11,15,1},
{13,6,4,9,8,15,3,0,11,1,2,12,5,10,14,7},{1,10,13,0,6,9,8,7,4,15,14,3,11,5,2,12}},
{{7,13,14,3,0,6,9,10,1,2,8,5,11,12,4,15},{13,8,11,5,6,15,0,3,4,7,2,12,1,10,14,9},
{10,6,9,0,12,11,7,13,15,1,3,14,5,2,8,4},{3,15,0,6,10,1,13,8,9,4,5,11,12,7,2,14}},
{{2,12,4,1,7,10,11,6,8,5,3,15,13,0,14,9},{14,11,2,12,4,7,13,1,5,0,15,10,3,9,8,6},
{4,2,1,11,10,13,7,8,15,9,12,5,6,3,0,14},{11,8,12,7,1,14,2,13,6,15,0,9,10,4,5,3}},
{{12,1,10,15,9,2,6,8,0,13,3,4,14,7,5,11},{10,15,4,2,7,12,9,5,6,1,13,14,0,11,3,8},
{9,14,15,5,2,8,12,3,7,0,4,10,1,13,11,6},{4,3,2,12,9,5,15,10,11,14,1,7,6,0,8,13}},
{{4,11,2,14,15,0,8,13,3,12,9,7,5,10,6,1},{13,0,11,7,4,9,1,10,14,3,5,12,2,15,8,6},
{1,4,11,13,12,3,7,14,10,15,6,8,0,5,9,2},{6,11,13,8,1,4,10,7,9,5,0,15,14,2,3,12}},
{{13,2,8,4,6,15,11,1,10,9,3,14,5,0,12,7},{1,15,13,8,10,3,7,4,12,5,6,11,0,14,9,2},
{7,11,4,1,9,12,14,2,0,6,10,13,15,3,5,8},{2,1,14,7,4,10,8,13,15,12,9,0,3,5,6,11}}};
/****************************************************************/
/* 0<=tb<=7, 0<=val<=63 */
/* note: la ligne correspond au bits 0 et 5 de val
et la colonne aux bits de 1 a 4 */
int calculer_s_table(char tb,char val)
{
char j,t[6],lig,col;
for(j=0;j<6;j++) t[j]=((val & (1<<j))!=0)?1:0;
lig=(t[5]<<1)+t[0];
col=(t[4]<<3)+(t[3]<<2)+(t[2]<<1)+t[1];
Page 115
return Table[tb][lig][col];
}
/****************************************************************/
char calculer_parite(char val,char nbbits)
{
char j,n=0;
for(j=0;j<nbbits;j++) if (val & (1<<j)) n++;
return (n & 1);
}
/****************************************************************/
void main(void)
{
char parite;
unsigned tb,aa,k,i,j;
int tab_lin[64][16];
for(tb=0;tb<8;tb++) {
printf("\nS-Table %d\n\n",tb+1);
/* Remplir la table */
for(i=0;i<64;i++) {
for(j=0;j<16;j++) {
tab_lin[i][j]=-32;
for(k=0;k<64;k++) {
Page 116
aa = calculer_parite(calculer_s_table(tb,k) & j,4);
aa+= calculer_parite(k & i,6);
parite = aa & 1;
if (parite==0) tab_lin[i][j]++;
}}}
/* Afficher les resultats */
printf(" 00x 01x 02x 03x 04x 05x 06x 07x 08x 09x 0Ax 0Bx 0Cx 0Dx 0Ex 0Fx\n");
for(i=0;i<64;i++) {
printf("%02Xx ",i);
for(j=0;j<16;j++) printf("%3d ",tab_lin[i][j]);
printf("\n");
}
}
}
Neural functions Library
/* NEURONES.C - librairie de fonction pour l'apprentissage
supervise d'un réseau de neurones a perceptrons
a retropropagation du gradient
Dourlens Sebastien
V1.00
*/
#ifndef __NEURONES__
#define __NEURONES__
/****************************************************************/
Page 117
/* retourne le nombre de bits de sortie OK
*/
int calculer_suc(void)
{
int k,res = 0;
for(k=0;k<NB_SORTIES;k++) {
res += (activations_apprentissage[k] == 1.0 && activations_sorties[k] > 0.5) ||
(activations_apprentissage[k] == 0.0 && activations_sorties[k] < 0.5);
}
return res;
}
/****************************************************************/
/* retourne le nombre d'exemples realises
*/
int calculer_ok(void)
{
int k,res = 0;
for(k=0;k<NB_SORTIES;k++) {
res += (activations_apprentissage[k] == 1.0 && activations_sorties[k] > 0.5) ||
(activations_apprentissage[k] == 0.0 && activations_sorties[k] < 0.5);
}
return ((res==NB_SORTIES)?1:0);
}
Page 118
/****************************************************************/
/* Fonction de transfert du reseau de neurones
*/
TYPE_REEL sigmoid(TYPE_REEL x)
{
if (x>10.0) return 0.9999999998;
if (x<-10.0) return 0.0000000001;
return( 1.0/(1.0+exp(-1.0*x)) );
}
/****************************************************************/
TYPE_REEL calculer_nb_aleatoire(TYPE_REEL min,TYPE_REEL max)
{
TYPE_REEL r=((rand()*(max-min))/32767.0)+min;
return r;
}
/****************************************************************/
/* initialise les poids de chaque liaison et les seuils de chaque
neurone en couche de sortie et en couche cachee avec une valeur
aleatoire comprise entre MIN_ALEA et MAX_ALEA
*/
void initialiser_poids(void)
{
int i,j,k;
Page 119
for(k=0;k<NB_SORTIES;k++) {
for(j=0;j<NB_CACHEES;j++)
poids_sorties[k][j]=calculer_nb_aleatoire(MIN_ALEA,MAX_ALEA);
seuils_sorties[k]=calculer_nb_aleatoire(MIN_ALEA,MAX_ALEA);
delta_sorties[k]=calculer_nb_aleatoire(MIN_ALEA,MAX_ALEA);
}
for(j=0;j<NB_CACHEES;j++) {
for(i=0;i<NB_ENTREES;i++)
poids_cachees[j][i]=calculer_nb_aleatoire(MIN_ALEA,MAX_ALEA);
seuils_cachees[j]=calculer_nb_aleatoire(MIN_ALEA,MAX_ALEA);
delta_cachees[j]=calculer_nb_aleatoire(MIN_ALEA,MAX_ALEA);
}
}
/****************************************************************/
/* Calcule les sorties du reseau en fonction des entrees donnees
a travers les couches du reseau de neurones
*/
void calculer_sorties(void)
{
int i,j,k;
TYPE_REEL net;
for(j=0;j<NB_CACHEES;j++) {
net=0.0;
for(i=0;i<NB_ENTREES;i++) net+=activations_entrees[i]*poids_cachees[j][i];
activations_cachees[j]=sigmoid(net-seuils_cachees[j]);
}
Page 120
for(k=0;k<NB_SORTIES;k++) {
net=0.0;
for(j=0;j<NB_CACHEES;j++) net+=activations_cachees[j]*poids_sorties[k][j];
activations_sorties[k]=sigmoid(net-seuils_sorties[k]);
}
}
/****************************************************************/
/* Met à jour les variations des sorties en fonction des valeurs de
sortie desirees et des valeurs de sortie du reseau de neurones
pour chaque neurone de couche de sortie et de couche cachee
=> c'est la retropropagation de l'erreur
*/
void calculer_deltas(void)
{
int j,k;
TYPE_REEL erreur;
for(k=0;k<NB_SORTIES;k++) {
erreur=activations_apprentissage[k]-activations_sorties[k];
delta_sorties[k]=erreur*activations_sorties[k]*(1.0-activations_sorties[k]);
}
for(j=0;j<NB_CACHEES;j++) {
erreur=0.0;
for(k=0;k<NB_SORTIES;k++) erreur+=delta_sorties[k]*poids_sorties[k][j];
delta_cachees[j]=erreur*activations_cachees[j]*(1.0-activations_cachees[j]);
}
}
Page 121
#if AVEC_MOMENTUM
/****************************************************************/
/* Change les valeurs des poids de chaque liaison entre neurones
en fonction des variations "delta" sur les valeurs de sortie et
sur les valeurs des poids precedents avec un "momentum term".
=> le momentum permet d'eviter les minima locaux (blocage)
=> Epsilon est le learning rate (cad coeff. d'apprentissage)
*/
void changer_poids(void)
{
int i,j,k;
for(k=0;k<NB_SORTIES;k++) {
for(j=0;j<NB_CACHEES;j++) {
delta_poids_sorties[k][j]=EPSILON*delta_sorties[k]*activations_cachees[j]+
MOMENTUM*delta_poids_sorties[k][j];
poids_sorties[k][j]+=delta_poids_sorties[k][j];
}
delta_seuils_sorties[k]=-1.0*EPSILON*delta_sorties[k]+MOMENTUM*delta_seuils_sorties[k];
seuils_sorties[k]+=delta_seuils_sorties[k];
}
for(j=0;j<NB_CACHEES;j++) {
for(i=0;i<NB_ENTREES;i++) {
delta_poids_cachees[j][i]=EPSILON*delta_cachees[j]*activations_entrees[i]+
MOMENTUM*delta_poids_cachees[j][i];
poids_cachees[j][i]+=delta_poids_cachees[j][i];
}
Page 122
delta_seuils_cachees[j]=-1.0*EPSILON*delta_cachees[j]+MOMENTUM*delta_seuils_cachees[j];
seuils_cachees[j]+=delta_seuils_cachees[j];
}
}
#else
/****************************************************************/
/* Change les valeurs des poids de chaque liaison entre neurones
uniquement en fonction des variations "delta" sur les valeurs
de sortie (pas de momentum term ici)
=> Epsilon est le learning rate (cad coeff. d'apprentissage)
*/
void changer_poids(void)
{
int i,j,k;
for(k=0;k<NB_SORTIES;k++) {
for(j=0;j<NB_CACHEES;j++)
poids_sorties[k][j]+=EPSILON*delta_sorties[k]*activations_cachees[j];
seuils_sorties[k]-=EPSILON*delta_sorties[k];
}
for(j=0;j<NB_CACHEES;j++) {
for(i=0;i<NB_ENTREES;i++) {
poids_cachees[j][i]+=EPSILON*delta_cachees[j]*activations_entrees[i];
}
seuils_cachees[j]-=EPSILON*delta_cachees[j];
}
Page 123
}
#endif
/****************************************************************/
/* Calcule le taux d'erreur PSS entre la sortie desiree
et la sortie du reseau de neurones
*/
TYPE_REEL calculer_pss(void)
{
int k;
TYPE_REEL res=0.0;
for(k=0;k<NB_SORTIES;k++)
res+=(activations_apprentissage[k]-activations_sorties[k])*
(activations_apprentissage[k]-activations_sorties[k]);
return res;
}
/****************************************************************/
/* Affiche tous les seuils de chaque neurone et tous les poids
de chaque liaison entre neurones
*/
void afficher_seuils_et_poids(void)
{
int i,j,k;
Page 124
for(k=0;k<NB_SORTIES;k++) {
printf("seuils_sorties[%2d]=%5.2f ",k,seuils_sorties[k]);
for(j=0;j<NB_CACHEES;j++) printf("%5.2f ",poids_sorties[k][j]);
printf("\n");
}
printf("\n");
for(k=0;k<NB_CACHEES;k++) {
printf("seuils_cachees[%2d]=%5.2f ",k,seuils_cachees[k]);
for(j=0;j<NB_ENTREES;j++) printf("%5.2f ",poids_cachees[k][j]);
printf("\n");
}
printf("\n");
}
/**************************************************************/
void sauver_poids(t)
int t;
{
FILE *fp;
char s[256];
sprintf(s,"PDS%05d.RDN",t);
fp=fopen(s,"wb");
if (fp==NULL) { printf("ERREUR SAUVEGARDE %s\n",s); return; }
fwrite(seuils_sorties,sizeof(TYPE_REEL),NB_SORTIES,fp);
fwrite(seuils_cachees,sizeof(TYPE_REEL),NB_CACHEES,fp);
Page 125
fwrite(poids_cachees,sizeof(TYPE_REEL),NB_CACHEES*NB_ENTREES,fp);
fwrite(poids_sorties,sizeof(TYPE_REEL),NB_SORTIES*NB_CACHEES,fp);
fclose(fp);
}
/**************************************************************/
void relire_poids(t)
int t;
{
FILE *fp;
char s[256];
sprintf(s,"PDS%05d.RDN",t);
fp=fopen(s,"rb");
if (fp==NULL) { printf("FICHIER %s INTROUVABLE\n",s); return; }
fread(seuils_sorties,sizeof(TYPE_REEL),NB_SORTIES,fp);
fread(seuils_cachees,sizeof(TYPE_REEL),NB_CACHEES,fp);
fread(poids_cachees,sizeof(TYPE_REEL),NB_CACHEES*NB_ENTREES,fp);
fread(poids_sorties,sizeof(TYPE_REEL),NB_SORTIES*NB_CACHEES,fp);
fclose(fp);
}
#endif
Différential Neuro-generator for D.E.S.
// PROBDIF.C - Cryptanalyse differentielle des S-tables du D.E.S. par un réseau de neurones
// Dourlens Sebastien
// V1.0
#include <stdio.h>
Page 126
#include <conio.h>
#include <math.h>
#include <stdlib.h>
#include <time.h>
#include <mem.h>
#include <alloc.h>
#include <dos.h>
#define NB_ENTREES 16
#define NB_CACHEES 16
#define NB_SORTIES 6
#define EPSILON 0.5
#define AVEC_MOMENTUM 0
#define MOMENTUM 0.3
#define MAX_ALEA 0.3
#define MIN_ALEA -0.3
#define TYPE_REEL double
char *tabexemples[]={
"1000000000000000","0100000000000000","0010000000000000","0001000000000000",
"0000100000000000","0000010000000000","0000001000000000","0000000100000000",
"0000000010000000","0000000001000000","0000000000100000","0000000000010000",
"0000000000001000","0000000000000100","0000000000000010","0000000000000001" };
int NB_PRESENTATIONS = 10;
TYPE_REEL activations_entrees[NB_ENTREES]; // init.
TYPE_REEL activations_cachees[NB_CACHEES];
TYPE_REEL activations_sorties[NB_SORTIES]; // init.
TYPE_REEL activations_apprentissage[NB_SORTIES]; // init.
Page 127
TYPE_REEL delta_sorties[NB_SORTIES];
TYPE_REEL delta_cachees[NB_CACHEES];
TYPE_REEL seuils_sorties[NB_SORTIES];
TYPE_REEL seuils_cachees[NB_CACHEES];
TYPE_REEL poids_sorties[NB_SORTIES][NB_CACHEES];
TYPE_REEL poids_cachees[NB_CACHEES][NB_ENTREES];
#include "neurones.c"
/* 8 S-tables */
char Table[8][4][16]={{
{14,4,13,1,2,15,11,8,3,10,6,12,5,9,0,7},{0,15,7,4,14,2,13,1,10,6,12,11,9,5,3,8},{4,1,14,8,13,6,2,11,15,12,9,7,3,1
0,5,0},{15,12,8,2,4,9,1,7,5,11,3,14,10,0,6,13}},
{{15,1,8,14,6,11,3,4,9,7,2,13,12,0,5,10},{3,13,4,7,15,2,8,14,12,0,1,10,6,9,11,5},{0,14,7,11,10,4,13,1,5,8,12,6,9,
3,2,15},{13,8,10,1,3,15,4,2,11,6,7,12,0,5,14,9}},
{{10,0,9,14,6,3,15,5,1,13,12,7,11,4,2,8},{13,7,0,9,3,4,6,10,2,8,5,14,12,11,15,1},{13,6,4,9,8,15,3,0,11,1,2,12,5,1
0,14,7},{1,10,13,0,6,9,8,7,4,15,14,3,11,5,2,12}},
{{7,13,14,3,0,6,9,10,1,2,8,5,11,12,4,15},{13,8,11,5,6,15,0,3,4,7,2,12,1,10,14,9},{10,6,9,0,12,11,7,13,15,1,3,14,
5,2,8,4},{3,15,0,6,10,1,13,8,9,4,5,11,12,7,2,14}},
{{2,12,4,1,7,10,11,6,8,5,3,15,13,0,14,9},{14,11,2,12,4,7,13,1,5,0,15,10,3,9,8,6},{4,2,1,11,10,13,7,8,15,9,12,5,6,
3,0,14},{11,8,12,7,1,14,2,13,6,15,0,9,10,4,5,3}},
{{12,1,10,15,9,2,6,8,0,13,3,4,14,7,5,11},{10,15,4,2,7,12,9,5,6,1,13,14,0,11,3,8},{9,14,15,5,2,8,12,3,7,0,4,10,1,1
3,11,6},{4,3,2,12,9,5,15,10,11,14,1,7,6,0,8,13}},
{{4,11,2,14,15,0,8,13,3,12,9,7,5,10,6,1},{13,0,11,7,4,9,1,10,14,3,5,12,2,15,8,6},{1,4,11,13,12,3,7,14,10,15,6,8,
0,5,9,2},{6,11,13,8,1,4,10,7,9,5,0,15,14,2,3,12}},
{{13,2,8,4,6,15,11,1,10,9,3,14,5,0,12,7},{1,15,13,8,10,3,7,4,12,5,6,11,0,14,9,2},{7,11,4,1,9,12,14,2,0,6,10,13,1
5,3,5,8},{2,1,14,7,4,10,8,13,15,12,9,0,3,5,6,11}}};
/****************************************************************/
/* 0<=tb<=7, 0<=val<=63 */
/* note: la ligne correspond au bits 0 et 5 de val
et la colonne aux bits de 1 a 4 */
Page 128
char calculer_s_table(char tb,char val)
{
char j,t[6],lig,col;
for(j=0;j<6;j++) t[j]=((val & (1<<j))!=0)?1:0;
lig=(t[5]<<1)+t[0]; col=(t[4]<<3)+(t[3]<<2)+(t[2]<<1)+t[1];
return Table[tb][lig][col];
}
/****************************************************************/
void main(void)
{
int nb_presentations;
char p,pe,pp,x,xe,xp,j,tb=4,i;
TYPE_REEL tss;
/* init reseau */
clrscr();
randomize();
initialiser_poids();
/* apprentissage */
for(tb=0;tb<8;tb++){
printf("S-table %d",tb+1);
for(nb_presentations=0;nb_presentations<NB_PRESENTATIONS;nb_presentations++){
tss=0.0;
gotoxy(1,5); fprintf(stderr,"Presentation: %3ld ",nb_presentations+1L);
Page 129
for(p=0;p<64;p++) { /* on choisi une paire d'entrees */
for(pe=0;pe<64;pe++) {
pp=p^pe; /* on calcule le XOR des entrees */
x=calculer_s_table(tb,p);
xe=calculer_s_table(tb,pe);
xp=x^xe; /* on calcule le XOR des sorties */
/* saisir entree */
for(j=0;j<NB_ENTREES;j++)
activations_entrees[j]=(TYPE_REEL) (tabexemples[xp][j]-'0');
/* saisir sortie */
for(j=0;j<NB_SORTIES;j++)
activations_apprentissage[j]=(TYPE_REEL) ((pp & (1<<j))!=0)?1:0;
/* traiter */
calculer_sorties();
calculer_deltas();
changer_poids();
tss+=calculer_pss();
}
}
fprintf(stderr,"\nNø %d: Tss=%lf \n",nb_presentations+1,tss);
}
/* RESULTATS */
printf(" ");
for(p=0;p<16;p++) printf(" %Xx",p); printf("\n");
for(i=0;i<6;i++) {
printf("%Xx ",i);
for(p=0;p<16;p++) {
Page 130
for(j=0;j<NB_ENTREES;j++)
activations_entrees[j]=(TYPE_REEL) (tabexemples[p][j]-'0');
calculer_sorties();
printf("%1.3lf ",activations_sorties[i]);
}
printf("\n");
}
}
}
linear neuro-generator for D.E.S.
// PROBLIN.C - Cryptanalyse lineaire des S-tables du D.E.S. par
// un reseau de neurones
// Dourlens Sebastien
// V1.0
#include <stdio.h>
#include <conio.h>
#include <math.h>
#include <stdlib.h>
#include <time.h>
#include <mem.h>
#include <alloc.h>
#include <dos.h>
#define NB_ENTREES 16
#define NB_CACHEES 16
#define NB_SORTIES 6
#define EPSILON 0.5
Page 131
#define AVEC_MOMENTUM 0
#define MOMENTUM 0.3
#define MAX_ALEA 0.3
#define MIN_ALEA -0.3
#define TYPE_REEL double
char *tabexemples[]={ "1000000000000000","0100000000000000",
"0010000000000000","0001000000000000",
"0000100000000000","0000010000000000", "0000001000000000","0000000100000000",
"0000000010000000","0000000001000000", "0000000000100000","0000000000010000",
"0000000000001000","0000000000000100", "0000000000000010","0000000000000001" };
int NB_PRESENTATIONS = 10;
TYPE_REEL activations_entrees[NB_ENTREES];
TYPE_REEL activations_cachees[NB_CACHEES];
TYPE_REEL activations_sorties[NB_SORTIES];
TYPE_REEL activations_apprentissage[NB_SORTIES];
TYPE_REEL delta_sorties[NB_SORTIES];
TYPE_REEL delta_cachees[NB_CACHEES];
TYPE_REEL seuils_sorties[NB_SORTIES];
TYPE_REEL seuils_cachees[NB_CACHEES];
TYPE_REEL poids_sorties[NB_SORTIES][NB_CACHEES];
TYPE_REEL poids_cachees[NB_CACHEES][NB_ENTREES];
#if AVEC_MOMENTUM
TYPE_REEL delta_poids_sorties[NB_SORTIES][NB_CACHEES];
TYPE_REEL delta_seuils_sorties[NB_SORTIES];
TYPE_REEL delta_poids_cachees[NB_CACHEES][NB_ENTREES];
TYPE_REEL delta_seuils_cachees[NB_CACHEES];
Page 132
#endif
#include "neurones.c"
/* 8 S-tables */
char Table[8][4][16]={{
{14,4,13,1,2,15,11,8,3,10,6,12,5,9,0,7},{0,15,7,4,14,2,13,1,10,6,12,11,9,5,3,8},{4,1,14,8,13,6,2,11,15,12,9,7,3,1
0,5,0},{15,12,8,2,4,9,1,7,5,11,3,14,10,0,6,13}},
{{15,1,8,14,6,11,3,4,9,7,2,13,12,0,5,10},{3,13,4,7,15,2,8,14,12,0,1,10,6,9,11,5},{0,14,7,11,10,4,13,1,5,8,12,6,9,
3,2,15},{13,8,10,1,3,15,4,2,11,6,7,12,0,5,14,9}},
{{10,0,9,14,6,3,15,5,1,13,12,7,11,4,2,8},{13,7,0,9,3,4,6,10,2,8,5,14,12,11,15,1},{13,6,4,9,8,15,3,0,11,1,2,12,5,1
0,14,7},{1,10,13,0,6,9,8,7,4,15,14,3,11,5,2,12}},
{{7,13,14,3,0,6,9,10,1,2,8,5,11,12,4,15},{13,8,11,5,6,15,0,3,4,7,2,12,1,10,14,9},{10,6,9,0,12,11,7,13,15,1,3,14,
5,2,8,4},{3,15,0,6,10,1,13,8,9,4,5,11,12,7,2,14}},
{{2,12,4,1,7,10,11,6,8,5,3,15,13,0,14,9},{14,11,2,12,4,7,13,1,5,0,15,10,3,9,8,6},{4,2,1,11,10,13,7,8,15,9,12,5,6,
3,0,14},{11,8,12,7,1,14,2,13,6,15,0,9,10,4,5,3}},
{{12,1,10,15,9,2,6,8,0,13,3,4,14,7,5,11},{10,15,4,2,7,12,9,5,6,1,13,14,0,11,3,8},{9,14,15,5,2,8,12,3,7,0,4,10,1,1
3,11,6},{4,3,2,12,9,5,15,10,11,14,1,7,6,0,8,13}},
{{4,11,2,14,15,0,8,13,3,12,9,7,5,10,6,1},{13,0,11,7,4,9,1,10,14,3,5,12,2,15,8,6},{1,4,11,13,12,3,7,14,10,15,6,8,
0,5,9,2},{6,11,13,8,1,4,10,7,9,5,0,15,14,2,3,12}},
{{13,2,8,4,6,15,11,1,10,9,3,14,5,0,12,7},{1,15,13,8,10,3,7,4,12,5,6,11,0,14,9,2},{7,11,4,1,9,12,14,2,0,6,10,13,1
5,3,5,8},{2,1,14,7,4,10,8,13,15,12,9,0,3,5,6,11}}};
/****************************************************************/
/* 0<=tb<=7, 0<=val<=63 */
/* note: la ligne correspond au bits 0 et 5 de val
et la colonne aux bits de 1 a 4 */
char calculer_s_table(char tb,char val)
{
char j,t[6],lig,col;
for(j=0;j<6;j++) t[j]=((val & (1<<j))!=0)?1:0;
Page 133
lig=(t[5]<<1)+t[0]; col=(t[4]<<3)+(t[3]<<2)+(t[2]<<1)+t[1];
return Table[tb][lig][col];
}
/****************************************************************/
/* calcule la parité des nbbits bits d’une valeur val donnée */
char calculer_parite(char val,char nbbits)
{
char j,n=0;
for(j=0;j<nbbits;j++) if (val & (1<<j)) n++;
return (n & 1);
}
/****************************************************************/
void main(void)
{
int nb_presentations;
char p,aa,bb,i,j,k,tb;
TYPE_REEL tss;
/* init reseau */
clrscr();
/* pour chaque s-table */
Page 134
for(tb=0;tb<8;tb++) {
randomize();
initialiser_poids();
/* apprentissage */
printf("S-table %d",tb+1);
for(nb_presentations=0;nb_presentations<NB_PRESENTATIONS;nb_presentations++){
tss=0.0;
gotoxy(1,5); fprintf(stderr,"Presentation: %3ld ",nb_presentations+1L);
for(i=0;i<64;i++) {
for(j=0;j<16;j++) {
for(k=0;k<64;k++) {
aa = calculer_s_table(tb,k) & j; // 4 bits
bb = k & i; // 6 bits
/* saisir entree du reseau: 4 bits */
for(p=0;p<NB_ENTREES;p++)
activations_entrees[p]=(TYPE_REEL) (tabexemples[aa][p]-'0');
/* saisir sortie du reseau: 6 bits */
for(p=0;p<NB_SORTIES;p++)
activations_apprentissage[p]=(TYPE_REEL) ((bb & (1<<p))!=0)?1:0;
/* traiter */
calculer_sorties();
calculer_deltas();
changer_poids();
tss+=calculer_pss();
Page 135
}}}
fprintf(stderr,"\nNø %d: Tss=%lf \n",nb_presentations+1,tss);
}
/* RESULTATS */
printf(" "); for(p=0;p<16;p++) printf(" %Xx",p); printf("\n");
for(i=0;i<6;i++) {
printf("%Xx ",i);
for(p=0;p<16;p++) {
for(j=0;j<NB_ENTREES;j++)
activations_entrees[j]=(TYPE_REEL) (tabexemples[p][j]-'0');
calculer_sorties();
printf("%1.3lf ",activations_sorties[i]);
}
printf("\n");
}
printf("\n");
}
}
2 The neural circuits
HNC, INC.
5930 Cornerstone Court West
San Diego, CA 92121-3728
Téléphone : 619-546-8877
Fax : 619-452-6524
Page 136
The proposed package:
Database Mining (DMW) Workstation, a PC system that builds models of connections
and a database of reasons at present.
The Numerical Array Processor (SNAP) SIMD.It is a card to parallel processors in a
VME chassis which has between 16 and 64 parallel floating-point processors. It
provided between 640 MFLOPS and 2.56 GFLOPS for neural networks and other
applications of signal processing.
A SUN SPARC station as host.
The SNAP was awarded IEEE 1993 Gordon Bell for the best quality/price in its class of
supercomputers.
SAIC (Science Application International Corporation)
10260 Campus Point Drive
MS 71, San Diego
CA 92121
Tél. : (619) 546 6148
Fax : (619) 546 6736
Micro Devices
30 Skyline Drive
Lake Mary
FL 32746-6201
Tél. : (407) 333-4379
MicroDevices a fait le MD1220 - 'Neural Bit Slice'
Each of the completed circuits have very different uses.
They seem similar to those of Intel but architectures are not.
Intel Corp
2250 Mission College Blvd
Page 137
Santa Clara, Ca 95052-8125
Attn ETANN, Mail Stop SC9-40
Tél. : (408) 765-9235
Intel has manufactured an experimental circuit (which is no longer produced): 80170NW -
Electrically trainable Analog Neural Network (ETANN): electric drive analog neural network.
It has 64 "neurons" all fully connected and the circuit can be inserted dasn a hierarchical
architecture, it can perform 2 million interconnections per second.
Software support is provided by:
California Scientific Software
10141 Evening Star Dr #6
Grass Valley, CA 95945-9051
Tél. : (916) 477-7481
Their product is called " BrainMaker ".
NeuralWare, Inc
Penn Center West
Bldg IV Suite 227
Pittsburgh
PA 15276
They sell only a simulation software for various platforms.
Tubb Research Limited
7a Lavant Street
Peterfield
Hampshire
GU32 2EL
Page 138
United Kingdom
Tél.: +44 730 60256
Adaptive Solutions Inc
1400 NW Compton Drive
Suite 340
Beaverton, OR 97006
U. S. A.
Tel: 503-690-1236
FAX: 503-690-1249
NeuroDynamX, Inc.
4730 Walnut St., Suite 101B
Boulder, CO 80301
Tél.: (303) 442-3539
Fax: (303) 442-2854
Internet: [email protected]
NDX sells a lot of products to neural network:
Neural Accelerator NDX: a set of i860 to PC-based accelerator cards that give more
than 45 million connections per second.
The DynaMind neural network software.
The iNNTS: Intel's 80170NX (ETANN) Neural Network Training System.
The president of NDX was a co-director of the i80170.
IC Tech (Innovative Computing Technologies, Inc.)
4138 Luff Court
Okemos, MI 48864
Page 139
Tél. : (517) 349-4544
Internet : [email protected]
Integrated circuit IC:
DANN050L (dendro-dendritic artificial neural network)
-50 neurons connected to the input
-digital learning ability
-6 million connections per second
-Learn templates 7 x 7 in less than 50 ns
-reminders within 400 ns
-64-pin
NCA717D (matrix neuro-correlatrice)
-analog comparison of models in less than 500 ns
-PIN digital output/analog input real-time computation
-vision in stereo and image processing applications
-40-pin
Motherboard ICT1050
-IBM compatible PC
-map DANN050L
-digital interface
-demand configurations
3 Difference distribution tables of D.E.S.
Explanation of the achievement of these tables
Page 140
In the table, each row corresponds to a value of XOR of entries and each column to a value of
XOR output (in hexadecimal). The value of each cell in a table counts the number of pairs (in
decimal) among the 64 x 64 = 4096 possible pairs) whose input XORs and XORs outputs are
as specified by the row and column of the cell. As there are only 64 x 16 = 1024 casesdans the
table, the average value of the number of pairs of each box is 4.
The first line of the table is special. As in the first line, the Xor of entries is 0, the XOR output
must be 0 also. In addition, box with an XOR of output to 0 account all 64 pairs the XOR of
entries is 0 and the other boxes of this line doesn't count a pair at all. Different values are
represented in the other lines.
You can also consult the C code that allowed to generate tables of distributions on the
following pages.
How to read these tables?
You will find easting 16 possible differences of output of the S-table texts, it is an XOR of a
pair of outputs. Orderly, you will find 64 possible differences of texts in S-table entry, it is an
XOR of a pair of inputs.
For example, in the distribution of the S table - table 1, for the XOR of entries 01 x, there are
11 possible output XORs. For the XOR of entries 34 x and the XOR output 02 x, the number
of possible pairs is 16 or ¼ of the pairs with the XOR of entries goes to the XOR output 02 x.
Distributions for the S - table 1
00x 01x 02x 03x 04x 05x 06x 07x 08x 09x 0Ax 0Bx 0Cx 0Dx 0Ex 0Fx
00x 64 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
01x 00 00 00 06 00 02 04 04 00 10 12 04 10 06 02 04
02x 00 00 00 08 00 04 04 04 00 06 08 06 12 06 04 02
03x 14 04 02 02 10 06 04 02 06 04 04 00 02 02 02 00
04x 00 00 00 06 00 10 10 06 00 04 06 04 02 08 06 02
05x 04 08 06 02 02 04 04 02 00 04 04 00 12 02 04 06
06x 00 04 02 04 08 02 06 02 08 04 04 02 04 02 00 12
07x 02 04 10 04 00 04 08 04 02 04 08 02 02 02 04 04
08x 00 00 00 12 00 08 08 04 00 06 02 08 08 02 02 04
09x 10 02 04 00 02 04 06 00 02 02 08 00 10 00 02 12
0Ax 00 08 06 02 02 08 06 00 06 04 06 00 04 00 02 10
Page 141
0Bx 02 04 00 10 02 02 04 00 02 06 02 06 06 04 02 12
0Cx 00 00 00 08 00 06 06 00 00 06 06 04 06 06 14 02
0Dx 06 06 04 08 04 08 02 06 00 06 04 06 00 02 00 02
0Ex 00 04 08 08 06 06 04 00 06 06 04 00 00 04 00 08
0Fx 02 00 02 04 04 06 04 02 04 08 02 02 02 06 08 08
10x 00 00 00 00 00 00 02 14 00 06 06 12 04 06 08 06
11x 06 08 02 04 06 04 08 06 04 00 06 06 00 04 00 00
12x 00 08 04 02 06 06 04 06 06 04 02 06 06 00 04 00
13x 02 04 04 06 02 00 04 06 02 00 06 08 04 06 04 06
14x 00 08 08 00 10 00 04 02 08 02 02 04 04 08 04 00
15x 00 04 06 04 02 02 04 10 06 02 00 10 00 04 06 04
16x 00 08 10 08 00 02 02 06 10 02 00 02 00 06 02 06
17x 04 04 06 00 10 06 00 02 04 04 04 06 06 06 02 00
18x 00 06 06 00 08 04 02 02 02 04 06 08 06 06 02 02
19x 02 06 02 04 00 08 04 06 10 04 00 04 02 08 04 00
1Ax 00 06 04 00 04 06 06 06 06 02 02 00 04 04 06 08
1Bx 04 04 02 04 10 06 06 04 06 02 02 04 02 02 04 02
1Cx 00 10 10 06 06 00 00 12 06 04 00 00 02 04 04 00
1Dx 04 02 04 00 08 00 00 02 10 00 02 06 06 06 14 00
1Ex 00 02 06 00 14 02 00 00 06 04 10 08 02 02 06 02
1Fx 02 04 10 06 02 02 02 08 06 08 00 00 00 04 06 04
20x 00 00 00 10 00 12 08 02 00 06 04 04 04 02 00 12
21x 00 04 02 04 04 08 10 00 04 04 10 00 04 00 02 08
22x 10 04 06 02 02 08 02 02 02 02 06 00 04 00 04 10
23x 00 04 04 08 00 02 06 00 06 06 02 10 02 04 00 10
24x 12 00 00 02 02 02 02 00 14 14 02 00 02 06 02 04
25x 06 04 04 12 04 04 04 10 02 02 02 00 04 02 02 02
26x 00 00 04 10 10 10 02 04 00 04 06 04 04 04 02 00
Page 142
27x 10 04 02 00 02 04 02 00 04 08 00 04 08 08 04 04
28x 12 02 02 08 02 06 12 00 00 02 06 00 04 00 06 02
29x 04 02 02 10 00 02 04 00 00 14 10 02 04 06 00 04
2Ax 04 02 04 06 00 02 08 02 02 14 02 06 02 06 02 02
2Bx 12 02 02 02 04 06 06 02 00 02 06 02 06 00 08 04
2Cx 04 02 02 04 00 02 10 04 02 02 04 08 08 04 02 06
2Dx 06 02 06 02 08 04 04 04 02 04 06 00 08 02 00 06
2Ex 06 06 02 02 00 02 04 06 04 00 06 02 12 02 06 04
2Fx 02 02 02 02 02 06 08 08 02 04 04 06 08 02 04 02
30x 00 04 06 00 12 06 02 02 08 02 04 04 06 02 02 04
31x 04 08 02 10 02 02 02 02 06 00 00 02 02 04 10 08
32x 04 02 06 04 04 02 02 04 06 06 04 08 02 02 08 00
33x 04 04 06 02 10 08 04 02 04 00 02 02 04 06 02 04
34x 00 08 16 06 02 00 00 12 06 00 00 00 00 08 00 06
35x 02 02 04 00 08 00 00 00 14 04 06 08 00 02 14 00
36x 02 06 02 02 08 00 02 02 04 02 06 08 06 04 10 00
37x 02 02 12 04 02 04 04 10 04 04 02 06 00 02 02 04
38x 00 06 02 02 02 00 02 02 04 06 04 04 04 06 10 10
39x 06 02 02 04 12 06 04 08 04 00 02 04 02 04 04 00
3Ax 06 04 06 04 06 08 00 06 02 02 06 02 02 06 04 00
3Bx 02 06 04 00 00 02 04 06 04 06 08 06 04 04 06 02
3Cx 00 10 04 00 12 00 04 02 06 00 04 12 04 04 02 00
3Dx 00 08 06 02 02 06 00 08 04 04 00 04 00 12 04 04
3Ex 04 08 02 02 02 04 04 14 04 02 00 02 00 08 04 04
3Fx 04 08 04 02 04 00 02 04 04 02 04 08 08 06 02 02
Distributions Table for S-table 2
00x 01x 02x 03x 04x 05x 06x 07x 08x 09x 0Ax 0Bx 0Cx 0Dx 0Ex 0Fx
Page 143
00x 64 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
01x 00 00 00 04 00 02 06 04 00 14 08 06 08 04 06 02
02x 00 00 00 02 00 04 06 04 00 00 04 06 10 10 12 06
03x 04 08 04 08 04 06 04 02 04 02 02 04 06 02 00 04
04x 00 00 00 00 00 06 00 14 00 06 10 04 10 06 04 04
05x 02 00 04 08 02 04 06 06 02 00 08 04 02 04 10 02
06x 00 12 06 04 06 04 06 02 02 10 02 08 02 00 00 00
07x 04 06 06 04 02 04 04 02 06 04 02 04 04 06 00 06
08x 00 00 00 04 00 04 00 08 00 10 16 06 06 00 06 04
09x 14 02 04 10 02 08 02 06 02 04 00 00 02 02 02 04
0Ax 00 06 06 02 10 04 10 02 06 02 02 04 02 02 04 02
0Bx 06 02 02 00 02 04 06 02 10 02 00 06 06 04 04 08
0Cx 00 00 00 04 00 14 00 10 00 06 02 04 04 08 06 06
0Dx 06 02 06 02 10 02 00 04 00 10 04 02 08 02 02 04
0Ex 00 06 12 08 00 04 02 00 08 02 04 04 06 02 00 06
0Fx 00 08 02 00 06 06 08 02 04 04 04 06 08 00 04 02
10x 00 00 00 08 00 04 10 02 00 02 08 10 00 10 06 04
11x 06 06 04 06 04 00 06 04 08 02 10 02 02 04 00 00
12x 00 06 02 06 02 04 12 04 06 04 00 04 04 06 02 02
13x 04 00 04 00 08 06 06 00 00 02 00 06 04 08 02 14
14x 00 06 06 04 10 00 02 12 06 02 02 02 04 04 02 02
15x 06 08 02 00 08 02 00 02 02 02 02 02 02 14 10 02
16x 00 08 06 04 02 02 04 02 06 04 06 02 06 00 06 06
17x 06 04 08 06 04 04 00 04 06 02 04 04 04 02 04 02
18x 00 06 04 06 10 04 00 02 04 08 00 00 04 08 02 06
19x 02 04 06 04 04 02 04 02 06 04 06 08 00 06 04 02
1Ax 00 06 08 04 02 04 02 02 08 02 02 06 02 04 04 08
1Bx 00 06 04 04 00 12 06 04 02 02 02 04 04 02 10 02
Page 144
1Cx 00 04 06 06 12 00 04 00 10 02 06 02 00 00 10 02
1Dx 00 06 02 02 06 00 04 16 04 04 02 00 00 04 06 08
1Ex 00 04 08 02 10 06 06 00 08 04 00 02 04 04 00 06
1Fx 04 02 06 06 02 02 02 04 08 06 10 06 04 00 00 02
20x 00 00 00 02 00 12 10 04 00 00 00 02 14 02 08 10
21x 00 04 06 08 02 10 04 02 02 06 04 02 06 02 00 06
22x 04 12 08 04 02 02 00 00 02 08 08 06 00 06 00 02
23x 08 02 00 02 08 04 02 06 04 08 02 02 06 04 02 04
24x 10 04 00 00 00 04 00 02 06 08 06 10 08 00 02 04
25x 06 00 12 02 08 06 10 00 00 08 02 06 00 00 02 02
26x 02 02 04 04 02 02 10 14 02 00 04 02 02 04 06 04
27x 06 00 00 02 06 04 02 04 04 04 08 04 08 00 06 06
28x 08 00 08 02 04 12 02 00 02 06 02 00 06 02 00 10
29x 00 02 04 10 02 08 06 04 00 10 00 02 10 00 02 04
2Ax 04 00 04 08 06 02 04 04 06 06 02 06 02 02 04 04
2Bx 02 02 06 04 00 02 02 06 02 08 08 04 04 04 08 02
2Cx 10 06 08 06 00 06 04 04 04 02 04 04 00 00 02 04
2Dx 02 02 02 04 00 00 00 02 08 04 04 06 10 02 14 04
2Ex 02 04 00 02 10 04 02 00 02 02 06 02 08 08 10 02
2Fx 12 04 06 08 02 06 02 08 00 04 00 02 00 08 02 00
30x 00 04 00 02 04 04 08 06 10 06 02 12 00 00 00 06
31x 00 10 02 00 06 02 10 02 06 00 02 00 06 06 04 08
32x 08 04 06 00 06 04 04 08 04 06 08 00 02 02 02 00
33x 02 02 06 10 02 00 00 06 04 04 12 08 04 02 02 00
34x 00 12 06 04 06 00 04 04 04 00 04 06 04 02 04 04
35x 00 12 04 06 02 04 04 00 10 00 00 08 00 08 00 06
36x 08 02 04 00 04 00 04 02 00 08 04 02 06 16 02 02
37x 06 02 02 02 06 06 04 08 02 02 06 02 02 02 04 08
Page 145
38x 00 08 08 10 06 02 02 00 04 00 04 02 04 00 04 10
39x 00 02 00 00 08 00 10 04 10 00 08 04 04 04 04 06
3Ax 04 00 02 08 04 02 02 02 04 08 02 00 04 10 10 02
3Bx 16 04 04 02 08 02 02 06 04 04 04 02 00 02 02 02
3Cx 00 02 06 02 08 04 06 00 10 02 02 04 04 10 04 00
3Dx 00 16 10 02 04 02 04 02 08 00 00 08 00 06 02 00
3Ex 04 04 00 10 02 04 02 14 04 02 06 06 00 00 06 00
3Fx 04 00 00 02 00 08 02 04 00 02 04 04 04 14 10 06
Distributions Table for S-table 3
00x 01x 02x 03x 04x 05x 06x 07x 08x 09x 0Ax 0Bx 0Cx 0Dx 0Ex 0Fx
00x 64 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
01x 00 00 00 02 00 04 02 12 00 14 00 04 08 02 06 10
02x 00 00 00 02 00 02 00 08 00 04 12 10 04 06 08 08
03x 08 06 10 04 08 06 00 06 04 04 00 00 00 04 02 02
04x 00 00 00 04 00 02 04 02 00 12 08 04 06 08 10 04
05x 06 02 04 08 06 10 06 02 02 08 02 00 02 00 04 02
06x 00 10 06 06 10 00 04 12 02 04 00 00 06 04 00 00
07x 02 00 00 04 04 04 04 02 10 04 04 08 04 04 04 06
08x 00 00 00 10 00 04 04 06 00 06 06 06 06 00 08 08
09x 10 02 00 02 10 04 06 02 00 06 00 04 06 02 04 06
0Ax 00 10 06 00 14 06 04 00 04 06 06 00 04 00 02 02
0Bx 02 06 02 10 02 02 04 00 04 02 06 00 02 08 14 00
0Cx 00 00 00 08 00 12 12 04 00 08 00 04 02 10 02 02
0Dx 08 02 08 00 00 04 02 00 02 08 14 02 06 02 04 02
0Ex 00 04 04 02 04 02 04 04 10 04 04 04 04 04 02 08
0Fx 04 06 04 06 02 02 04 08 06 02 06 02 00 06 02 04
10x 00 00 00 04 00 12 04 08 00 04 02 06 02 14 00 08
Page 146
11x 08 02 02 06 04 00 02 00 08 04 12 02 10 00 02 02
12x 00 02 08 02 04 08 00 08 08 00 02 02 04 02 14 00
13x 04 04 12 00 02 02 02 10 02 02 02 02 04 04 04 08
14x 00 06 04 04 06 04 06 02 08 06 06 02 02 00 00 08
15x 04 08 02 08 02 04 08 00 04 02 02 02 02 06 08 02
16x 00 06 10 02 08 04 02 00 02 02 02 08 04 06 04 04
17x 00 06 06 00 06 02 04 04 06 02 02 10 06 08 02 00
18x 00 08 04 06 06 00 06 02 04 00 04 02 10 00 06 06
19x 04 02 04 08 04 02 10 02 02 02 06 08 02 06 00 02
1Ax 00 08 06 04 04 00 06 04 04 08 00 10 02 02 02 04
1Bx 04 10 02 00 02 04 02 04 08 02 02 08 04 02 08 02
1Cx 00 06 08 08 04 02 08 00 12 00 10 00 04 00 02 00
1Dx 00 02 00 06 02 08 04 06 02 00 04 02 04 10 00 14
1Ex 00 04 08 02 04 06 00 04 10 00 02 06 04 08 04 02
1Fx 00 06 08 00 10 06 04 06 04 02 02 10 04 00 00 02
20x 00 00 00 00 00 04 04 08 00 02 02 04 10 16 12 02
21x 10 08 08 00 08 04 02 04 00 06 06 06 00 00 02 00
22x 12 06 04 04 02 04 10 02 00 04 04 02 04 04 00 02
23x 02 02 00 06 00 02 04 00 04 12 04 02 06 04 08 08
24x 04 08 02 12 06 04 02 10 02 02 02 04 02 00 04 00
25x 06 00 02 00 08 02 00 02 08 08 02 02 04 04 10 06
26x 06 02 00 04 04 00 04 00 04 02 14 00 08 10 00 06
27x 00 02 04 16 08 06 06 06 00 02 04 04 00 02 02 02
28x 06 02 10 00 06 04 00 04 04 02 04 08 02 02 08 02
29x 00 02 08 04 00 04 00 06 04 10 04 08 04 04 04 02
2Ax 02 06 00 04 02 04 04 06 04 08 04 04 04 02 04 06
2Bx 10 02 06 06 04 04 08 00 04 02 02 00 02 04 04 06
2Cx 10 04 06 02 04 02 02 02 04 10 04 04 00 02 06 02
Page 147
2Dx 04 02 04 04 04 02 04 16 02 00 00 04 04 02 06 06
2Ex 04 00 02 10 00 06 10 04 02 06 06 02 02 00 02 08
2Fx 08 02 00 00 04 04 04 02 06 04 06 02 04 08 04 06
30x 00 10 08 06 02 00 04 02 10 04 04 06 02 00 06 00
31x 02 06 02 00 04 02 08 08 02 02 02 00 02 12 06 06
32x 02 00 04 08 02 08 04 04 08 04 02 08 06 02 00 02
33x 04 04 06 08 06 06 00 02 02 02 06 04 12 00 00 02
34x 00 06 02 02 16 02 02 02 12 02 04 00 04 02 00 08
35x 04 06 00 10 08 00 02 02 06 00 00 06 02 10 02 06
36x 04 04 04 04 00 06 06 04 04 04 04 04 00 06 02 08
37x 04 08 02 04 02 02 06 00 02 04 08 04 10 00 06 02
38x 00 08 12 00 02 02 06 06 02 10 02 02 00 08 00 04
39x 02 06 04 00 06 04 06 04 08 00 04 04 02 04 08 02
3Ax 06 00 02 02 04 06 04 04 04 02 02 06 12 02 06 02
3Bx 02 02 06 00 00 10 04 08 04 02 04 08 04 04 00 06
3Cx 00 02 04 02 12 02 00 06 02 00 02 08 04 06 04 10
3Dx 04 06 08 06 02 02 02 02 10 02 06 06 02 04 02 00
3Ex 08 06 04 04 02 10 02 00 02 02 04 02 04 02 10 02
3Fx 02 06 04 00 00 10 08 02 02 08 06 04 06 02 00 04
Distributions Table for S-table 4
00x 01x 02x 03x 04x 05x 06x 07x 08x 09x 0Ax 0Bx 0Cx 0Dx 0Ex 0Fx
00x 64 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
01x 00 00 00 00 00 16 16 00 00 16 16 00 00 00 00 00
02x 00 00 00 08 00 04 04 08 00 04 04 08 08 08 08 00
03x 08 06 02 00 02 04 08 02 06 00 04 06 00 06 02 08
04x 00 00 00 08 00 00 12 04 00 12 00 04 08 04 04 08
05x 04 02 02 08 02 12 00 02 02 00 12 02 08 02 02 04
Page 148
06x 00 08 08 04 08 08 00 00 08 00 08 00 04 00 00 08
07x 04 02 06 04 06 00 16 06 02 00 00 02 04 02 06 04
08x 00 00 00 04 00 08 04 08 00 04 08 08 04 08 08 00
09x 08 04 04 04 04 00 08 04 04 00 00 04 04 04 04 08
0Ax 00 06 06 00 06 04 04 06 06 04 04 06 00 06 06 00
0Bx 00 12 00 08 00 00 00 00 12 00 00 12 08 12 00 00
0Cx 00 00 00 04 00 08 04 08 00 04 08 08 04 08 08 00
0Dx 08 04 04 04 04 00 00 04 04 08 00 04 04 04 04 08
0Ex 00 06 06 04 06 00 04 06 06 04 00 06 04 06 06 00
0Fx 00 06 06 04 06 04 00 06 06 00 04 06 04 06 06 00
10x 00 00 00 00 00 08 12 04 00 12 08 04 00 04 04 08
11x 04 02 02 16 02 04 00 02 02 00 04 02 16 02 02 04
12x 00 00 00 08 00 04 04 08 00 04 04 08 08 08 08 00
13x 08 02 06 00 06 04 00 06 02 08 04 02 00 02 06 08
14x 00 08 08 00 08 00 08 00 08 08 00 00 00 00 00 16
15x 08 04 04 00 04 08 00 04 04 00 08 04 00 04 04 08
16x 00 08 08 04 08 08 00 00 08 00 08 00 04 00 00 08
17x 04 06 02 04 02 00 00 02 06 16 00 06 04 06 02 04
18x 00 08 08 08 08 04 00 00 08 00 04 00 08 00 00 08
19x 04 04 04 00 04 04 16 04 04 00 04 04 00 04 04 04
1Ax 00 06 06 04 06 00 04 06 06 04 00 06 04 06 06 00
1Bx 00 06 06 04 06 04 00 06 06 00 04 06 04 06 06 00
1Cx 00 08 08 08 08 04 00 00 08 00 04 00 08 00 00 08
1Dx 04 04 04 00 04 04 00 04 04 16 04 04 00 04 04 04
1Ex 00 06 06 00 06 04 04 06 06 04 04 06 00 06 06 00
1Fx 00 00 12 08 12 00 00 12 00 00 00 00 08 00 12 00
20x 00 00 00 08 00 00 00 12 00 00 00 12 08 12 12 00
21x 00 04 08 00 08 04 08 08 04 00 04 04 00 04 08 00
Page 149
22x 08 02 02 00 02 04 08 06 02 08 04 06 00 06 06 00
23x 04 06 02 08 02 04 00 02 06 00 04 06 08 06 02 04
24x 00 06 06 04 06 04 00 06 06 00 04 06 04 06 06 00
25x 00 08 04 04 04 00 00 04 08 08 00 08 04 08 04 00
26x 00 06 06 00 06 04 08 02 06 08 04 02 00 02 02 08
27x 04 06 02 08 02 04 00 02 06 00 04 06 08 06 02 04
28x 16 04 04 00 04 04 04 04 04 04 04 04 00 04 04 00
29x 00 06 02 08 02 04 00 02 06 08 04 06 08 06 02 00
2Ax 00 02 02 16 02 04 04 02 02 04 04 02 16 02 02 00
2Bx 08 00 04 00 04 08 16 04 00 00 08 00 00 00 04 08
2Cx 08 04 04 04 04 00 08 04 04 08 00 04 04 04 04 00
2Dx 04 02 06 04 06 08 00 06 02 00 08 02 04 02 06 04
2Ex 16 00 00 00 00 16 00 00 00 00 16 00 00 00 00 16
2Fx 16 00 00 00 00 00 16 00 00 16 00 00 00 00 00 16
30x 00 06 06 04 06 04 00 06 06 00 04 06 04 06 06 00
31x 00 08 04 04 04 00 00 04 08 08 00 08 04 08 04 00
32x 16 06 06 04 06 00 04 02 06 04 00 02 04 02 02 00
33x 00 02 06 04 06 08 08 06 02 00 08 02 04 02 06 00
34x 00 12 12 08 12 00 00 00 12 00 00 00 08 00 00 00
35x 00 04 08 00 08 04 08 08 04 00 04 04 00 04 08 00
36x 00 02 02 04 02 00 04 06 02 04 00 06 04 06 06 16
37x 00 02 06 04 06 08 08 06 02 00 08 02 04 02 06 00
38x 00 04 04 00 04 04 04 04 04 04 04 04 00 04 04 16
39x 00 06 02 08 02 04 00 02 06 08 04 06 08 06 02 00
3Ax 00 04 04 00 04 08 08 04 04 08 08 04 00 04 04 00
3Bx 16 04 04 00 04 00 00 04 04 00 00 04 00 04 04 16
3Cx 00 04 04 04 04 00 08 04 04 08 00 04 04 04 04 08
3Dx 04 02 06 04 06 08 00 06 02 00 08 02 04 02 06 04
Page 150
3Ex 00 02 02 08 02 12 04 02 02 04 12 02 08 02 02 00
3Fx 08 04 00 08 00 00 00 00 04 16 00 04 08 04 00 08
Distributions Table for S-table 4
00x 01x 02x 03x 04x 05x 06x 07x 08x 09x 0Ax 0Bx 0Cx 0Dx 0Ex 0Fx
00x 64 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
01x 00 00 00 04 00 10 08 06 00 04 02 02 12 10 02 04
02x 00 00 00 04 00 10 06 04 00 06 04 02 04 08 10 06
03x 08 02 04 06 04 04 02 02 06 08 06 04 04 00 02 02
04x 00 00 00 08 00 04 10 06 00 06 06 04 08 06 00 06
05x 12 02 00 04 00 04 08 02 04 00 16 02 00 02 00 08
06x 00 08 04 06 04 06 02 02 04 04 06 00 06 00 02 10
07x 02 00 04 08 04 02 06 06 02 08 06 02 02 00 06 06
08x 00 00 00 02 00 08 10 04 00 04 10 04 08 04 04 06
09x 08 06 00 04 00 06 06 02 02 10 02 08 06 02 00 02
0Ax 00 06 08 06 00 08 00 00 08 10 04 02 08 00 00 04
0Bx 04 02 02 04 08 10 06 04 02 06 02 02 06 02 02 02
0Cx 00 00 00 10 00 02 10 02 00 06 10 06 06 06 02 04
0Dx 10 04 02 02 00 06 16 00 00 02 10 02 02 04 00 04
0Ex 00 06 04 08 04 06 10 02 04 04 04 02 04 00 02 04
0Fx 04 04 00 08 00 02 00 02 08 02 04 02 08 04 04 12
10x 00 00 00 00 00 04 04 12 00 02 08 10 04 06 12 02
11x 06 06 10 10 04 00 02 06 02 04 00 06 02 04 02 00
12x 00 02 04 02 10 04 00 10 08 06 00 06 00 06 06 00
13x 00 00 06 02 08 00 00 04 04 06 02 08 02 08 10 04
14x 00 12 02 06 04 00 04 04 08 04 04 04 06 02 04 00
15x 04 08 00 02 08 00 02 04 02 02 04 02 04 08 08 06
16x 00 06 10 02 14 00 02 02 04 04 00 06 00 04 06 04
Page 151
17x 00 06 08 04 08 04 00 02 08 04 00 02 02 08 06 02
18x 00 10 08 00 06 04 00 04 04 04 06 04 04 04 00 06
19x 00 04 06 02 04 04 02 06 04 02 02 04 12 02 10 00
1Ax 00 02 16 02 12 02 00 06 04 00 00 04 00 04 04 08
1Bx 02 08 12 00 00 02 02 06 08 04 00 06 00 00 08 06
1Cx 00 10 02 06 06 06 06 04 08 02 00 04 04 04 02 00
1Dx 04 06 02 00 08 02 04 06 06 00 08 06 02 04 02 04
1Ex 00 02 06 02 04 00 00 02 12 02 02 06 02 10 10 04
1Fx 00 06 08 04 08 08 00 06 06 02 00 06 00 06 02 02
20x 00 00 00 08 00 08 02 06 00 04 04 04 06 06 08 08
21x 00 00 00 06 06 02 06 04 06 10 14 04 00 00 04 02
22x 14 04 00 10 00 02 12 02 02 02 10 02 00 00 02 02
23x 02 00 00 04 02 02 10 04 00 08 08 02 06 08 00 08
24x 06 02 08 04 04 04 06 02 02 06 06 02 06 02 02 02
25x 06 00 00 08 02 08 02 06 06 04 02 02 04 02 06 06
26x 12 00 00 04 00 04 04 04 00 08 04 00 12 08 00 04
27x 12 02 00 02 00 12 02 02 04 04 08 04 08 02 02 00
28x 02 08 04 06 02 04 06 00 06 06 04 00 02 02 02 10
29x 06 04 06 08 08 04 06 02 00 00 02 02 10 00 02 04
2Ax 04 04 00 02 02 04 06 02 00 00 06 04 10 04 04 12
2Bx 04 06 02 06 00 00 12 02 00 04 12 02 06 04 00 04
2Cx 08 06 02 06 04 08 06 00 04 04 00 02 06 00 06 02
2Dx 04 04 00 04 00 06 04 02 04 12 00 04 04 06 04 06
2Ex 06 00 02 04 00 06 06 04 02 10 06 10 06 02 00 00
2Fx 10 04 00 02 02 06 10 02 00 02 02 04 06 02 02 10
30x 00 04 08 04 06 04 00 06 10 04 02 04 02 06 04 00
31x 00 06 06 04 10 02 00 00 04 04 00 00 04 06 12 06
32x 04 06 00 02 06 04 06 00 06 00 04 06 04 10 06 00
Page 152
33x 08 10 00 14 08 00 00 08 02 00 02 04 00 04 04 00
34x 00 04 04 02 14 04 00 08 06 08 02 02 00 04 06 00
35x 00 04 16 00 08 04 00 04 04 04 00 08 00 04 04 04
36x 04 04 04 06 02 02 02 12 02 04 04 08 02 04 04 00
37x 04 02 02 02 04 02 00 08 02 02 02 12 06 02 08 06
38x 00 04 08 04 12 00 00 08 10 02 00 00 00 04 02 10
39x 00 08 12 00 02 02 02 02 12 04 00 08 00 04 04 04
3Ax 00 14 04 00 04 06 00 00 06 02 10 08 00 00 04 06
3Bx 00 02 02 02 04 04 08 06 08 02 02 02 06 14 02 00
3Cx 00 00 10 02 06 00 00 02 06 02 02 10 02 04 10 08
3Dx 00 06 12 02 04 08 00 08 08 02 02 00 02 02 04 04
3Ex 04 04 10 00 02 04 08 08 02 02 00 02 06 08 04 00
3Fx 08 06 06 00 04 02 02 04 04 02 08 06 02 04 06 00
Distributions Table for S-table 6
00x 01x 02x 03x 04x 05x 06x 07x 08x 09x 0Ax 0Bx 0Cx 0Dx 0Ex 0Fx
00x 64 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
01x 00 00 00 06 00 02 06 02 00 04 02 04 06 16 14 02
02x 00 00 00 02 00 10 06 10 00 02 04 08 06 06 08 02
03x 00 08 00 08 00 06 04 06 04 04 04 12 02 04 02 00
04x 00 00 00 08 00 00 08 00 00 06 08 10 02 04 10 08
05x 10 02 04 04 04 08 08 04 02 02 00 04 00 08 00 04
06x 00 08 04 04 08 04 02 02 12 00 02 06 06 02 02 02
07x 06 06 04 00 02 10 02 02 02 02 06 06 08 00 06 02
08x 00 00 00 06 00 02 16 04 00 02 06 02 04 12 06 04
09x 10 04 02 06 00 02 06 02 04 00 08 06 04 04 02 04
0Ax 00 14 04 04 00 02 02 02 10 04 04 04 06 04 02 02
0Bx 04 06 02 00 02 02 12 08 02 02 02 06 08 02 00 06
Page 153
0Cx 00 00 00 12 00 10 04 06 00 08 04 04 02 12 02 00
0Dx 12 00 02 10 06 04 04 02 04 02 06 00 02 06 00 04
0Ex 00 06 04 00 04 04 10 08 06 02 04 06 02 00 06 02
0Fx 02 02 02 02 06 02 06 02 10 04 08 02 06 04 04 02
10x 00 00 00 08 00 08 00 12 00 04 02 06 08 04 06 06
11x 06 02 06 04 06 02 06 04 06 06 04 02 04 00 06 00
12x 00 08 04 02 00 04 02 00 04 10 06 02 08 06 04 04
13x 06 06 12 00 12 02 00 06 06 02 00 04 00 02 04 02
14x 00 04 06 02 08 06 00 02 06 10 04 00 02 04 06 04
15x 02 02 06 06 04 04 02 06 02 06 08 04 04 00 04 04
16x 00 04 14 06 08 04 02 06 02 00 02 00 04 02 00 10
17x 02 06 08 00 00 02 00 02 02 06 00 08 08 02 12 06
18x 00 04 06 06 08 04 02 02 06 04 06 04 02 04 02 04
19x 02 06 00 02 04 04 04 06 04 08 06 04 02 02 06 04
1Ax 00 06 06 00 08 02 04 06 04 02 04 06 02 00 04 10
1Bx 00 04 10 02 04 04 02 06 06 06 02 02 06 06 02 02
1Cx 00 00 08 02 12 02 06 02 08 06 06 02 04 00 04 02
1Dx 02 04 00 06 08 06 00 02 06 08 06 00 02 04 00 10
1Ex 00 10 08 02 08 02 00 02 06 04 02 04 06 04 02 04
1Fx 00 06 06 08 06 04 02 04 04 02 02 00 02 04 02 12
20x 00 00 00 00 00 06 06 04 00 04 08 08 04 06 10 08
21x 02 08 06 08 04 04 06 06 08 04 00 04 00 02 02 00
22x 16 02 04 06 02 04 02 00 06 04 08 02 00 02 02 04
23x 00 04 00 04 04 06 10 04 02 02 06 02 04 06 06 04
24x 10 08 00 06 12 06 10 04 08 00 00 00 00 00 00 00
25x 00 02 04 02 00 04 04 00 04 00 10 10 04 10 06 04
26x 02 02 00 12 02 02 06 02 04 04 08 00 06 06 08 00
27x 08 04 00 08 02 04 02 04 00 06 02 04 04 08 02 06
Page 154
28x 06 08 04 06 00 04 02 02 04 08 02 06 04 02 02 04
29x 02 04 04 00 08 08 06 08 06 04 00 04 04 04 02 00
2Ax 06 00 00 06 06 04 06 08 02 04 00 02 02 04 06 08
2Bx 12 00 04 00 00 04 02 02 02 06 10 06 10 02 04 00
2Cx 04 02 06 00 00 06 08 06 04 02 02 08 04 06 04 02
2Dx 06 02 02 06 06 04 04 02 06 02 04 08 04 02 04 02
2Ex 04 06 02 04 02 04 04 02 04 02 04 06 04 10 04 02
2Fx 10 00 04 08 00 06 06 02 00 04 04 02 06 02 02 08
30x 00 12 08 02 00 06 00 00 06 06 00 02 08 02 06 06
31x 02 06 10 04 02 02 02 04 06 00 02 06 00 02 04 12
32x 04 02 02 08 10 08 08 06 00 02 02 04 04 02 02 00
33x 04 02 02 02 06 00 04 00 10 06 06 04 00 04 08 06
34x 00 04 04 02 06 04 00 04 06 02 06 04 02 08 00 12
35x 06 12 04 02 04 02 02 04 08 02 02 00 06 04 04 02
36x 00 02 02 04 04 04 04 00 02 10 12 04 00 10 04 02
37x 10 02 02 06 14 02 02 06 02 00 04 06 02 00 04 02
38x 00 04 14 00 08 02 00 04 04 04 02 00 08 02 04 08
39x 02 04 08 00 06 02 00 06 02 06 04 02 08 06 02 06
3Ax 08 04 00 04 06 02 00 04 06 08 06 00 06 00 04 06
3Bx 00 04 06 06 02 02 02 14 00 12 00 04 02 02 08 00
3Cx 00 06 16 00 02 02 02 08 04 02 00 12 06 02 02 00
3Dx 00 06 02 02 02 06 08 02 04 02 06 02 06 02 04 10
3Ex 04 02 02 04 04 00 06 10 04 02 04 06 06 02 06 02
3Fx 00 04 06 06 04 08 04 00 04 08 04 00 04 08 02 02
Distributions Table for S-table 7
00x 01x 02x 03x 04x 05x 06x 07x 08x 09x 0Ax 0Bx 0Cx 0Dx 0Ex 0Fx
00x 64 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
Page 155
01x 00 00 00 02 00 04 04 14 00 12 04 06 02 06 06 04
02x 00 00 00 00 00 12 02 02 00 04 00 04 08 12 06 14
03x 08 02 12 02 06 08 06 00 06 04 04 02 02 00 00 02
04x 00 00 00 08 00 04 04 08 00 08 08 12 02 06 02 02
05x 06 00 00 02 08 00 08 04 00 02 06 00 10 06 06 06
06x 00 02 12 00 08 04 08 02 04 04 04 02 06 00 06 02
07x 04 06 04 12 00 04 02 00 00 14 02 06 04 00 00 06
08x 00 00 00 08 00 00 06 10 00 04 12 04 06 06 00 08
09x 10 08 04 08 06 02 02 00 02 06 08 02 00 06 00 00
0Ax 00 10 06 02 12 02 04 00 04 04 06 04 04 00 00 06
0Bx 00 02 02 02 04 08 06 04 04 00 04 02 06 04 02 14
0Cx 00 00 00 04 00 04 08 04 00 02 06 00 14 12 08 02
0Dx 06 06 02 04 02 06 04 06 06 04 08 08 00 02 00 00
0Ex 00 12 10 10 00 02 04 02 08 06 04 02 00 00 02 02
0Fx 02 00 00 00 06 08 08 00 06 02 04 06 08 00 06 08
10x 00 00 00 04 00 02 08 06 00 06 04 10 08 04 08 04
11x 06 10 10 04 04 02 00 04 04 00 02 08 04 02 02 02
12x 00 00 08 08 02 08 02 08 06 04 02 08 00 00 08 00
13x 04 04 02 02 08 06 00 02 02 02 00 04 06 08 14 00
14x 00 08 06 02 08 08 02 06 04 02 00 02 08 06 00 02
15x 04 04 08 02 04 00 04 10 08 02 04 04 04 02 00 04
16x 00 06 10 02 02 02 02 04 10 08 02 02 00 04 10 00
17x 08 02 04 02 06 04 00 06 04 04 02 02 00 04 08 08
18x 00 16 02 02 06 00 06 00 06 02 08 00 06 00 02 08
19x 00 08 00 02 04 04 10 04 08 00 06 04 02 06 02 04
1Ax 00 02 04 08 12 04 00 06 04 04 00 02 00 06 04 08
1Bx 00 06 02 06 04 02 04 04 06 04 08 04 02 00 10 02
1Cx 00 08 04 04 02 06 06 06 06 04 06 08 00 02 00 02
Page 156
1Dx 04 04 04 00 00 02 04 02 04 02 02 04 10 10 08 04
1Ex 00 00 02 02 12 06 02 00 12 02 02 04 02 06 08 04
1Fx 02 02 10 14 02 04 02 04 04 06 00 02 04 08 00 00
20x 00 00 00 14 00 08 04 02 00 04 02 08 02 06 00 14
21x 04 02 06 02 12 02 04 00 06 04 10 02 04 02 02 02
22x 10 06 00 02 04 04 10 00 04 00 12 02 08 00 00 02
23x 00 06 02 02 02 04 06 10 00 04 08 02 02 06 00 10
24x 04 02 00 06 08 02 06 00 08 02 02 00 08 02 12 02
25x 02 00 02 16 02 04 06 04 06 08 02 04 00 06 00 02
26x 06 10 00 10 00 06 04 04 02 02 04 06 02 04 02 02
27x 04 00 02 00 02 02 14 00 04 06 06 02 12 02 04 04
28x 14 04 06 04 04 06 02 00 06 06 02 02 04 00 02 02
29x 02 02 00 02 00 08 04 02 04 06 04 04 06 04 12 04
2Ax 02 04 00 00 00 02 08 12 00 08 02 04 08 04 04 06
2Bx 16 06 02 04 06 10 02 02 02 02 02 02 04 02 02 00
2Cx 02 06 06 08 02 02 00 06 00 08 04 02 02 06 08 02
2Dx 06 02 04 02 08 08 02 08 02 04 04 00 02 00 08 04
2Ex 02 04 08 00 02 02 02 04 00 02 08 04 14 06 00 06
2Fx 02 02 02 08 00 02 02 06 04 06 08 08 06 02 00 06
30x 00 06 08 02 08 04 04 00 10 04 04 06 00 00 02 06
31x 00 08 04 00 06 02 02 06 06 00 00 02 06 04 08 10
32x 02 04 00 00 06 04 10 06 06 04 06 02 04 06 02 02
33x 00 16 06 08 02 00 02 02 04 02 08 04 00 04 06 00
34x 00 04 14 08 02 02 02 04 16 02 02 02 00 02 00 04
35x 00 06 00 00 10 08 02 02 06 00 00 08 06 04 04 08
36x 02 00 02 02 04 06 04 04 02 02 04 02 04 16 10 00
37x 06 06 06 08 04 02 04 04 04 00 06 08 02 04 00 00
38x 00 02 02 02 08 08 00 02 02 02 00 06 06 04 10 10
Page 157
39x 04 04 16 08 00 06 04 02 04 04 02 06 00 02 02 00
3Ax 16 06 04 00 02 00 02 06 00 04 08 10 00 00 04 02
3Bx 02 00 00 02 00 04 04 04 02 06 02 06 06 12 12 02
3Cx 00 00 08 00 12 08 02 06 06 04 00 02 02 04 06 04
3Dx 02 04 12 02 02 02 00 04 06 10 02 06 04 02 00 06
3Ex 04 06 06 06 02 00 04 08 02 10 04 06 00 04 02 00
3Fx 14 00 00 00 08 00 06 08 04 02 00 00 04 08 04 06
Distributions Table for S-table 8
00x 01x 02x 03x 04x 05x 06x 07x 08x 09x 0Ax 0Bx 0Cx 0Dx 0Ex 0Fx
00x 64 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
01x 00 00 00 06 00 16 10 00 00 00 06 00 14 06 02 04
02x 00 00 00 08 00 10 04 02 00 10 02 04 08 08 06 02
03x 06 00 02 08 02 06 04 00 06 06 06 02 02 00 08 06
04x 00 00 00 02 00 04 06 12 00 06 08 04 10 04 08 00
05x 04 10 06 00 00 02 06 00 04 10 04 06 08 02 00 02
06x 00 00 10 04 06 04 04 08 02 06 04 02 04 02 02 06
07x 06 02 08 02 08 10 06 06 04 02 00 04 00 00 00 06
08x 00 00 00 04 00 06 04 02 00 08 06 10 08 02 02 12
09x 08 04 00 06 00 04 04 06 02 04 06 02 12 02 00 04
0Ax 00 00 16 04 06 06 04 00 04 06 04 02 02 00 00 10
0Bx 02 08 00 06 02 06 00 04 04 10 00 02 10 02 06 02
0Cx 00 00 00 02 00 10 10 06 00 06 06 06 02 06 10 00
0Dx 06 00 04 10 02 00 08 06 02 02 06 10 02 02 02 02
0Ex 00 00 06 08 04 08 00 02 10 06 02 04 06 02 04 02
0Fx 08 00 04 02 02 04 02 02 02 06 04 06 00 02 14 06
10x 00 00 00 04 00 00 08 12 00 00 08 08 02 10 06 06
11x 00 06 04 06 02 02 06 06 04 06 04 06 00 04 04 04
Page 158
12x 00 04 00 08 06 02 08 04 02 04 04 06 02 04 10 00
13x 04 02 02 06 08 06 02 02 14 02 02 04 02 02 02 04
14x 00 16 04 02 06 00 02 06 04 00 04 06 04 06 04 00
15x 00 10 06 00 06 00 02 08 02 02 00 08 02 06 06 06
16x 00 12 06 04 06 00 00 00 08 06 06 02 02 06 04 02
17x 00 06 08 00 06 02 04 06 06 00 02 06 04 04 02 08
18x 00 12 02 02 08 00 08 00 10 04 04 02 04 02 00 06
19x 06 04 08 00 08 00 04 02 00 00 12 02 04 06 02 06
1Ax 00 04 06 02 08 08 00 04 08 00 00 00 06 02 00 16
1Bx 02 04 08 10 02 04 02 08 02 04 08 02 00 02 04 02
1Cx 00 12 06 04 06 04 02 02 06 00 04 04 02 10 02 00
1Dx 08 06 00 00 10 00 00 08 10 04 02 02 02 08 04 00
1Ex 00 04 08 06 08 02 04 04 10 02 02 04 02 00 06 02
1Fx 04 02 04 02 06 02 04 00 02 06 02 02 02 16 08 02
20x 00 00 00 16 00 04 00 00 00 14 06 04 02 00 04 14
21x 00 00 02 10 02 08 10 00 00 06 06 00 10 02 02 06
22x 08 00 06 00 06 04 10 02 00 06 08 00 04 04 02 04
23x 04 08 00 06 00 04 08 06 02 02 10 04 08 00 00 02
24x 04 00 04 08 04 06 02 04 08 06 02 00 00 04 04 08
25x 00 04 06 08 02 08 08 00 04 02 04 04 02 02 06 04
26x 02 06 00 06 04 04 04 06 06 00 04 04 10 04 02 02
27x 06 06 00 00 02 02 06 02 04 04 06 10 02 06 02 06
28x 10 02 06 02 04 12 12 00 02 02 04 00 00 00 02 06
29x 04 00 00 14 02 10 04 02 08 06 04 00 04 02 02 02
2Ax 08 08 00 02 00 02 04 00 02 06 08 14 02 08 00 00
2Bx 02 02 00 00 04 02 10 04 06 02 04 00 06 04 08 10
2Cx 02 06 06 02 04 06 02 00 02 06 04 00 06 04 10 04
2Dx 08 00 04 04 06 02 00 00 06 08 02 04 06 04 04 06
Page 159
2Ex 06 02 02 04 02 02 06 12 04 00 04 02 08 08 00 02
2Fx 08 12 04 06 06 04 02 02 02 02 04 02 02 04 00 04
30x 00 04 06 02 10 02 02 02 04 08 00 00 08 04 06 06
31x 04 06 08 00 04 06 00 04 04 06 10 02 02 04 04 00
32x 06 06 06 02 04 06 00 02 00 06 08 02 02 06 06 02
33x 06 06 04 02 04 00 00 10 02 02 00 06 08 04 00 10
34x 00 02 12 04 10 04 00 04 12 00 02 04 02 02 02 04
35x 06 04 04 00 10 00 00 04 10 00 00 04 02 08 08 04
36x 04 06 02 02 02 02 06 08 06 04 02 06 00 04 10 00
37x 02 02 08 02 04 04 04 02 06 02 00 10 06 10 02 00
38x 00 04 08 04 02 06 06 02 04 02 02 04 06 04 04 06
39x 04 04 04 08 00 06 00 06 04 08 02 02 02 04 08 02
3Ax 08 08 00 04 02 00 10 04 00 00 00 04 08 06 08 02
3Bx 08 02 06 04 04 04 04 00 06 04 04 06 04 04 04 00
3Cx 00 06 06 06 06 00 00 08 08 02 04 08 04 02 04 00
3Dx 02 02 08 00 10 00 02 12 00 04 00 08 00 02 06 08
3Ex 06 04 00 00 04 04 00 10 06 02 06 12 02 04 00 04
3Fx 00 06 06 00 04 04 06 10 00 06 08 02 00 04 08 00
4 Linear approximation tables of D.E.S.
Explanation of the achievement of these tables
In the table, each row corresponds to a value of entries and each column to a value of output (in hexadecimal) of
the S-table.
The algorithm is described in paragraph 3.6.2.
You can also consult the C code that allowed to generate tables of distributions on the following pages.
Page 160
How to read these tables?
You will find on the abscissa 16 S output-texts. Orderly, you will find the 64 possible texts in S-table entry.
By example, in the distribution of the S table - table 5, for an input of 10 x and 0Fx output value, reads - 20
which corresponds to a probability p=(32-20)/6 p= 3/16 to 10 x in entrance of the S-table if the output is 0Fx.
Table of linear approximations for the S - 1
00x 01x 02x 03x 04x 05x 06x 07x 08x 09x 0Ax 0Bx 0Cx 0Dx 0Ex 0Fx
00x 32 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
01x 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
02x 0 -2 -2 -4 -2 0 -4 6 2 0 0 6 4 -2 -6 4
03x 0 -2 -2 -4 -2 0 -4 6 2 8 0 -2 4 6 -6 -4
04x 0 2 -2 -4 -2 0 -4 -6 -2 4 8 2 0 -2 -6 12
05x 0 -2 -2 0 -2 -4 -4 -2 2 -4 -4 2 4 -10 -2 -4
06x 0 0 0 4 0 4 0 0 0 -4 4 4 0 0 -4 -8
07x 0 -4 0 8 0 0 0 4 4 -4 -8 -4 4 0 0 0
08x 0 4 -2 6 -6 -6 0 -4 -4 -4 2 -2 2 -2 0 0
09x 0 0 6 -6 -2 -6 4 -4 0 -4 -2 6 2 -6 0 -4
0Ax 0 -2 0 2 0 6 8 2 -2 0 -2 4 -2 0 -2 4
0Bx 0 2 -8 -2 -4 -10 4 2 -6 8 2 4 -2 -4 -2 0
0Cx 0 -2 0 6 0 2 0 2 2 0 6 -4 2 -4 6 0
0Dx 0 6 0 6 4 -2 -4 -2 2 0 6 4 -2 8 -6 -4
0Ex 0 0 -2 -2 2 2 0 0 4 4 6 -2 2 2 -4 4
0Fx 0 0 -2 6 -2 -2 4 -4 -4 -4 -2 -2 -2 -2 0 0
10x 0 2 2 0 -2 0 4 -6 0 6 2 -4 6 -4 -4 -18
11x 0 2 -2 -4 2 -4 -4 10 -4 2 2 -4 -2 -4 0 -6
12x 0 4 0 0 -4 4 0 4 -6 2 2 6 2 6 6 -10
13x 0 4 -4 -4 0 0 -8 -12 -2 -2 -6 6 2 6 2 2
14x 0 4 0 4 -8 -4 4 0 2 6 -2 2 6 2 -2 2
Page 161
15x 0 0 4 -4 -4 4 4 -4 10 2 2 2 -6 2 6 -2
16x 0 6 2 0 2 -4 0 2 4 2 2 0 -2 0 0 2
17x 0 2 6 -8 6 4 0 -2 -12 -2 -2 0 -6 0 0 -2
18x 0 2 8 2 0 6 4 2 4 -2 4 6 0 -2 -4 2
19x 0 -2 4 -6 0 -6 0 2 4 -6 8 6 0 2 0 -6
1Ax 0 0 -6 2 -2 -2 4 4 -2 -2 0 0 -4 4 2 2
1Bx 0 4 6 2 -10 2 -8 4 -2 -6 4 0 4 0 -2 2
1Cx 0 -4 2 2 2 -6 0 -4 -2 -2 4 0 0 4 2 2
1Dx 0 4 -2 -2 2 -6 -4 0 2 2 -4 0 -12 0 -6 -6
1Ex 0 2 0 -2 4 -2 0 -2 0 6 -4 -2 0 -2 0 2
1Fx 0 2 -4 2 -4 -2 4 2 4 -6 4 -2 -4 2 0 2
20x 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
21x 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
22x 0 2 -2 0 2 0 0 6 -2 0 -4 6 4 10 10 0
23x 0 2 -2 0 2 0 0 6 6 0 4 -10 -4 -6 2 0
24x 0 2 -6 -8 2 4 4 2 2 0 0 2 0 6 -10 0
25x 0 -2 2 4 2 0 -4 -2 -2 0 4 2 -4 6 -6 0
26x 0 4 4 -4 8 -8 4 0 0 -8 0 -4 0 4 0 0
27x 0 0 -4 -8 -8 4 -4 -4 4 -8 -4 -4 4 4 -4 0
28x 0 4 -2 -2 -2 -2 -4 0 4 4 2 6 -2 -6 12 4
29x 0 0 -2 -6 2 -2 -8 8 0 -4 -2 -2 6 -2 -4 0
2Ax 0 2 0 -2 0 2 0 -2 2 -8 -6 -4 2 0 2 -4
2Bx 0 -10 0 2 -4 2 4 6 -2 0 -10 4 2 -4 -6 0
2Cx 0 6 -4 2 8 2 4 6 -2 -4 -2 12 -2 -8 -2 0
2Dx 0 -2 -4 2 -4 -2 0 2 -2 -4 -2 4 -6 4 2 -4
2Ex 0 -4 2 6 6 -6 -8 4 -4 0 2 6 6 2 4 0
2Fx 0 -4 2 -2 2 -10 12 0 -4 0 2 -2 10 6 0 4
30x 0 -2 -2 0 -2 4 0 2 0 2 6 4 6 0 0 -2
Page 162
31x 0 -2 2 4 2 0 0 -6 -4 -2 -2 -4 -2 0 -4 2
32x 0 -4 -4 -4 0 0 0 4 -2 -2 -6 -2 -6 6 2 2
33x 0 -4 0 0 4 -4 0 -4 -6 2 2 -2 2 -2 -2 -2
34x 0 8 -8 8 4 4 0 0 -2 -2 2 -6 6 6 -2 -2
35x 0 4 -4 0 -8 -4 0 -4 -2 2 -2 2 2 -2 -2 2
36x 0 6 2 -8 2 -4 8 2 4 -6 2 0 6 0 0 2
37x 0 2 -10 0 6 4 8 -2 4 6 -2 0 2 0 0 -2
38x 0 -10 4 2 -4 -2 4 -2 4 2 0 6 -4 6 -4 -2
39x 0 2 0 -6 -4 2 0 -2 -4 6 -4 -2 4 2 8 -2
3Ax 0 0 6 -2 6 6 0 0 2 2 0 0 8 0 2 2
3Bx 0 4 2 -2 -2 10 4 0 -14 -2 4 0 0 -4 -2 2
3Cx 0 0 10 -2 -6 -2 0 8 -6 6 0 -8 -4 4 -2 2
3Dx 0 8 -2 2 -6 -2 4 4 -2 -6 0 0 0 0 -2 2
3Ex 0 2 0 -2 -8 2 4 2 0 -2 4 -2 -4 2 4 -2
3Fx 0 -14 -12 -6 0 2 0 -2 -4 -6 12 -2 0 -2 4 -2
Table of linear approximations for the S 2
00x 01x 02x 03x 04x 05x 06x 07x 08x 09x 0Ax 0Bx 0Cx 0Dx 0Ex 0Fx
00x 32 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
01x 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
02x 0 0 0 4 0 0 -4 0 0 0 -4 0 0 0 0 4
03x 0 0 4 -8 0 8 0 -4 0 0 -8 -4 0 8 -4 8
04x 0 -2 2 4 2 0 4 6 0 6 -2 0 2 0 0 10
05x 0 2 2 0 2 -4 4 -6 0 -6 6 4 -6 4 0 -2
06x 0 -2 -2 -4 -2 -4 0 -2 -4 2 2 0 2 0 4 10
07x 0 2 2 -4 -2 0 4 -2 -4 6 6 0 -6 -4 0 2
08x 0 0 2 2 -2 2 4 0 -2 -6 -4 0 0 0 10 -6
Page 163
09x 0 0 -2 -2 -2 2 8 4 -2 2 0 -4 0 8 -10 -2
0Ax 0 -4 2 2 2 2 -4 -8 2 2 4 0 0 4 -6 2
0Bx 0 4 2 10 2 2 4 0 2 2 4 0 0 -4 2 2
0Cx 0 -2 4 -2 0 2 0 6 -2 0 2 0 2 0 -6 -4
0Dx 0 -6 0 -2 0 6 4 -10 6 -4 6 0 2 -4 -2 4
0Ex 0 -6 0 2 0 -2 -8 6 -2 4 2 0 2 4 -2 0
0Fx 0 -2 0 -2 0 2 0 10 6 8 2 4 2 0 -2 4
10x 0 0 -4 4 0 0 0 0 0 0 4 4 4 -12 -4 -12
11x 0 0 0 0 0 -8 4 4 0 0 8 0 -4 4 8 0
12x 0 0 0 4 0 8 0 4 0 0 -4 8 -4 -12 0 12
13x 0 0 -8 4 0 8 8 4 0 0 -4 0 4 -4 8 -4
14x 0 -2 -6 -4 -2 4 -4 -2 -4 2 2 -4 6 -4 0 2
15x 0 10 -2 -4 -2 0 0 -2 4 6 6 -4 -2 0 4 2
16x 0 -2 -6 0 2 0 4 2 8 -2 2 0 6 4 0 -2
17x 0 10 2 4 2 4 -4 -2 0 2 2 -4 -2 0 0 2
18x 0 -4 2 -2 2 2 4 4 -2 -2 4 4 0 4 -2 2
19x 0 4 -6 6 2 2 4 -4 -2 -2 4 -4 8 4 -2 2
1Ax 0 8 -2 2 -2 2 0 0 2 6 0 0 0 0 2 -2
1Bx 0 -8 10 6 -2 2 4 -4 2 -2 -4 -4 -8 0 -2 -6
1Cx 0 2 8 -2 0 -2 0 2 2 0 -6 4 10 -4 2 0
1Dx 0 -2 0 2 0 -6 0 -2 2 4 2 0 10 0 2 4
1Ex 0 -2 0 6 0 2 4 -2 2 4 -2 0 2 0 2 0
1Fx 0 2 -4 6 0 -2 -8 -2 -14 0 2 0 2 4 -2 0
20x 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
21x 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
22x 0 0 0 4 0 -8 4 0 0 0 -4 -16 0 -8 -8 4
23x 0 0 -4 0 0 0 0 4 0 0 0 4 0 0 -4 0
24x 0 -2 -2 0 -2 -4 4 -10 0 6 -6 -4 6 4 8 2
Page 164
25x 0 -6 -2 4 -2 0 4 2 0 2 2 -8 -2 0 8 -2
26x 0 6 -6 0 -14 0 0 -2 -4 -6 -2 4 -2 -4 -4 2
27x 0 2 6 0 2 -4 -4 -2 -4 6 -6 4 6 0 0 -6
28x 0 -4 2 -2 2 2 0 -8 2 2 0 8 8 -4 -6 -2
29x 0 -4 -2 -6 2 2 4 -4 -6 2 -4 -4 0 -4 -2 -6
2Ax 0 8 2 -2 6 -6 0 0 -2 2 0 0 0 0 -6 -2
2Bx 0 0 -6 -2 6 10 0 0 -10 10 0 0 -8 0 2 -2
2Cx 0 -6 0 6 0 -2 -4 -2 2 -8 2 4 -2 0 2 8
2Dx 0 -2 -4 -2 0 -6 0 -10 2 4 -2 4 -10 -4 -2 0
2Ex 0 -2 -4 2 8 2 4 -2 -6 -4 -6 4 -2 4 -2 4
2Fx 0 -6 4 -2 -8 -2 4 2 -6 0 10 0 6 0 -2 0
30x 0 0 -4 4 -4 -4 4 4 0 0 -4 -4 0 0 -8 0
31x 0 0 0 0 4 -4 0 0 0 0 0 -8 0 -8 -4 4
32x 0 0 0 4 4 4 4 0 0 0 4 0 0 0 -4 0
33x 0 0 0 -4 -4 -4 -4 0 0 0 -4 0 0 0 4 0
34x 0 -10 -2 -8 6 4 -8 2 4 2 6 -8 -2 -4 4 -2
35x 0 -6 2 0 -2 0 4 2 -4 -2 -6 0 -2 0 0 -2
36x 0 -2 -2 4 -6 0 8 -2 0 6 6 4 -2 4 -4 2
37x 0 2 -2 -8 -14 4 0 2 8 2 -2 0 -2 0 -4 -2
38x 0 0 2 2 -6 -2 -4 0 2 -2 0 -4 -4 -4 2 2
39x 0 8 10 -6 2 6 4 0 -6 -10 8 -4 4 -4 2 2
3Ax 0 -4 -2 6 -2 -2 -8 4 -2 -2 4 0 -4 0 -2 -2
3Bx 0 -4 2 2 -10 6 -4 0 -10 -2 0 -4 4 0 2 2
3Cx 0 -2 -4 -2 4 -2 0 -2 -2 0 2 0 2 -8 -2 0
3Dx 0 2 4 10 -4 10 -8 -6 6 4 2 -4 2 4 -2 -4
3Ex 0 2 -12 -2 4 2 -4 2 6 -12 -2 -4 2 4 -2 0
3Fx 0 -2 -8 -2 -4 -2 0 -6 -2 0 2 4 2 0 2 0
Page 165
Table of linear approximations for the S - 3
00x 01x 02x 03x 04x 05x 06x 07x 08x 09x 0Ax 0Bx 0Cx 0Dx 0Ex 0Fx
00x 32 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
01x 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
02x 0 2 -2 -4 0 -2 -6 4 0 6 -2 -8 4 -2 -2 -4
03x 0 -2 -2 0 4 -2 -2 -4 -4 -2 2 0 -4 2 -2 0
04x 0 -4 0 0 2 -2 -6 2 0 4 4 -4 -6 -10 6 -2
05x 0 0 0 -4 2 2 2 6 0 0 4 0 2 -6 6 2
06x 0 -2 2 0 2 -4 0 2 0 -6 -2 0 -2 4 8 -2
07x 0 -2 2 0 -2 8 4 6 -4 -2 2 -4 -10 4 0 -2
08x 0 0 6 -6 0 0 2 -2 -2 2 0 8 6 2 4 -4
09x 0 0 2 -2 0 -8 -2 -6 -2 2 -4 -4 -2 2 8 0
0Ax 0 -2 8 -2 0 2 -8 -6 2 0 6 4 -2 0 2 -4
0Bx 0 2 -4 6 4 2 0 -2 -2 0 -2 0 -2 -4 -2 4
0Cx 0 0 -2 -2 2 10 4 -4 2 -2 0 -4 4 -8 6 -6
0Dx 0 -4 2 -2 2 -2 0 12 2 2 4 4 4 4 2 2
0Ex 0 -2 -4 -2 2 -4 -2 -4 -2 4 2 4 4 -2 -8 -2
0Fx 0 -2 -8 2 -2 0 -2 -4 -6 -8 2 4 4 -2 4 2
10x 0 0 2 -2 2 2 8 4 2 6 -4 12 -4 -8 2 10
11x 0 0 -2 2 -2 -2 0 4 -2 2 4 -4 4 0 -10 6
12x 0 -2 4 2 -2 0 2 4 -2 -4 -6 0 0 -14 4 -2
13x 0 2 0 2 -2 4 -2 -12 -2 0 -2 8 -8 -2 0 -2
14x 0 4 -6 -2 -4 0 2 -2 2 -6 -8 0 6 -2 0 0
15x 0 8 -2 6 0 8 2 2 -2 2 -8 -4 -2 2 4 0
16x 0 2 0 -10 0 6 0 2 -2 0 2 0 2 0 -2 0
17x 0 10 4 -6 0 -2 -4 -2 -2 0 -2 4 2 0 2 -4
18x 0 0 4 -4 2 2 -2 -2 -4 4 4 4 -2 6 6 -2
Page 166
19x 0 8 -4 -4 -2 -2 2 2 0 0 0 8 -10 -2 -10 -2
1Ax 0 -6 2 0 -2 4 -4 -2 -4 2 2 4 6 0 0 -2
1Bx 0 -2 2 -4 -2 0 -4 2 4 -2 2 0 -2 4 0 2
1Cx 0 0 -4 0 -4 4 -8 4 0 -8 4 0 -4 4 8 4
1Dx 0 4 4 4 0 4 -4 -4 4 8 0 0 4 0 0 8
1Ex 0 -6 6 0 0 -2 2 0 -8 -2 -2 -4 4 -2 -2 0
1Fx 0 -6 -10 0 0 6 -6 0 0 -2 -2 4 4 -2 -2 0
20x 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
21x 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
22x 0 -2 -2 0 0 2 2 -8 0 2 -2 -4 4 2 6 16
23x 0 2 -2 -4 4 -6 6 -8 -4 2 2 -4 -4 -2 6 -4
24x 0 4 0 8 2 -2 -6 2 4 0 -8 8 6 2 2 -6
25x 0 0 0 -4 2 -6 2 -2 4 4 8 4 -2 -2 2 6
26x 0 2 -6 -12 2 0 0 -2 -4 -6 2 0 2 -4 -4 -2
27x 0 2 -6 4 -2 -4 4 2 8 -2 6 -4 -6 -4 4 -2
28x 0 0 2 -2 0 8 6 2 -2 -6 -4 4 -2 10 0 0
29x 0 0 -2 2 0 0 2 -2 -2 -6 8 8 6 -6 4 4
2Ax 0 2 4 -2 8 -2 -4 2 2 -4 2 -4 -2 -4 -2 4
2Bx 0 -2 8 -2 -4 -10 4 -2 -2 -12 -6 0 -2 0 -6 4
2Cx 0 0 2 -6 2 10 0 0 -2 2 0 -4 0 -4 -2 2
2Dx 0 4 6 2 2 6 -4 -8 -2 -2 4 -4 0 0 -6 2
2Ex 0 2 -8 -2 -6 0 2 -4 2 4 2 0 0 -2 0 -6
2Fx 0 2 4 2 6 4 2 -4 14 -8 2 0 0 -2 -4 -2
30x 0 0 -6 -2 -2 -2 -4 0 2 -2 4 4 0 4 -2 6
31x 0 0 -2 -6 2 2 4 0 -2 -6 4 -4 0 4 2 2
32x 0 2 -4 -2 2 0 6 4 -2 8 2 4 -4 2 0 -2
33x 0 -2 0 -2 -6 4 2 -4 -2 4 -2 -4 -4 -2 -4 6
34x 0 -4 2 6 0 4 -2 2 6 -2 4 4 -2 -2 0 0
Page 167
35x 0 8 -2 -2 12 -4 -2 -2 2 -2 -4 0 -2 2 4 8
36x 0 -2 0 2 -4 -2 -12 2 -6 0 -2 0 -6 -4 -2 4
37x 0 6 -4 -2 -12 -2 0 -2 10 0 2 -4 2 4 2 0
38x 0 0 0 8 6 -2 6 -2 -4 4 0 0 2 2 -2 -2
39x 0 8 0 0 10 2 -6 2 0 0 4 -4 2 2 -2 -2
3Ax 0 6 -2 0 2 4 -4 2 -4 -2 -2 4 -6 0 0 2
3Bx 0 -14 -10 -4 10 0 -4 -2 4 2 -10 0 -6 4 0 -2
3Cx 0 0 0 4 -8 0 0 -4 -4 4 4 0 -4 4 4 0
3Dx 0 -4 0 8 4 0 4 -4 0 -4 8 0 -4 0 -4 -4
3Ex 0 6 2 0 -4 -2 -6 4 -4 -2 -2 0 -4 -6 2 0
3Fx 0 6 -6 8 4 -2 2 4 -12 -2 6 0 4 2 2 0
Table of linear approximations for the S - 4
00x 01x 02x 03x 04x 05x 06x 07x 08x 09x 0Ax 0Bx 0Cx 0Dx 0Ex 0Fx
00x 32 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
01x 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
02x 0 0 4 0 4 0 0 0 0 0 0 4 0 4 0 0
03x 0 -4 0 8 0 0 8 -4 -4 -8 0 0 -8 0 -4 0
04x 0 -2 -2 0 -2 0 0 -10 2 0 0 -6 0 -6 10 0
05x 0 2 -2 -4 2 0 -4 6 2 4 0 -10 4 10 6 0
06x 0 -2 2 0 -2 -4 -4 2 -2 -4 4 2 0 -2 2 8
07x 0 -2 -2 4 -2 12 0 -2 2 0 12 2 4 2 2 0
08x 0 -4 0 0 0 0 0 4 4 0 0 0 0 0 -4 0
09x 0 0 -4 -8 4 0 8 0 0 -8 0 4 8 -4 0 0
0Ax 0 -4 -4 0 4 0 0 -4 -4 0 0 4 0 -4 -4 0
0Bx 0 4 -4 0 -4 0 0 -4 -4 0 0 -4 0 -4 4 0
0Cx 0 -2 2 0 -2 4 4 -6 -2 4 -4 10 0 -10 -6 -8
Page 168
0Dx 0 -2 -2 -4 -2 4 0 -10 2 0 4 -6 -4 -6 10 0
0Ex 0 -2 -2 0 -2 0 0 -2 2 0 0 2 0 2 2 0
0Fx 0 2 -2 4 2 0 4 -2 2 -4 0 -2 -4 2 -2 0
10x 0 -2 -2 0 2 4 4 10 -2 4 -4 6 0 -6 10 8
11x 0 2 -2 -4 -2 -4 0 -6 -2 0 -4 10 -4 10 6 0
12x 0 2 -2 0 -2 0 0 -6 -2 0 0 10 0 10 6 0
13x 0 2 2 -4 -2 0 4 -10 2 -4 0 -6 4 6 -10 0
14x 0 4 -4 0 -4 0 0 4 -4 0 0 -4 0 -4 -4 0
15x 0 4 4 8 -4 0 0 4 4 0 0 4 -8 -4 4 0
16x 0 8 -4 0 4 8 -8 0 8 -8 -8 4 0 -4 0 0
17x 0 4 8 8 8 0 0 -4 -4 0 0 0 8 0 4 0
18x 0 2 -2 0 -2 0 0 2 -2 0 0 2 0 2 -2 0
19x 0 2 2 4 -2 0 -4 -2 2 4 0 2 -4 -2 -2 0
1Ax 0 -2 -2 0 2 -4 -4 2 -2 -4 4 -2 0 2 2 -8
1Bx 0 2 -2 -12 -2 4 0 2 -2 0 4 2 -12 2 -2 0
1Cx 0 -4 0 0 0 8 -8 4 -4 -8 -8 0 0 0 4 0
1Dx 0 0 -4 -8 -4 0 0 0 0 0 0 4 -8 4 0 0
1Ex 0 -8 0 0 0 0 0 0 8 0 0 0 0 0 0 0
1Fx 0 0 -8 8 8 0 0 0 0 0 0 0 -8 0 0 0
20x 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
21x 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
22x 0 4 0 0 0 -8 8 4 4 8 8 0 0 0 4 -16
23x 0 0 4 0 4 0 0 0 0 0 0 4 0 4 0 0
24x 0 2 2 0 -2 4 4 6 2 4 -4 2 0 -2 6 -8
25x 0 -2 2 4 2 -4 0 -2 2 0 -4 6 4 6 2 0
26x 0 -10 2 0 2 0 0 -2 10 0 0 -2 0 -2 2 0
27x 0 -2 -10 4 10 0 4 2 -2 -4 0 -2 -4 2 2 0
28x 0 0 4 0 -4 8 -8 0 0 -8 -8 -4 0 4 0 -16
Page 169
29x 0 -4 0 0 0 0 0 4 4 0 0 0 0 0 -4 0
2Ax 0 4 -4 0 -4 0 0 -4 -4 0 0 -4 0 -4 4 0
2Bx 0 4 4 0 -4 0 16 4 4 -16 0 -4 0 4 4 0
2Cx 0 -2 2 0 2 0 0 -2 2 0 0 6 0 6 2 0
2Dx 0 -2 -2 -4 2 0 -4 -6 -2 4 0 -2 4 2 -6 0
2Ex 0 2 10 0 -10 -4 -4 -2 2 -4 4 2 0 -2 -2 8
2Fx 0 -10 2 -4 2 -12 0 -2 10 0 -12 -2 -4 -2 2 0
30x 0 -2 -2 0 -2 0 0 6 2 0 0 2 0 2 -6 0
31x 0 2 -2 -4 2 0 4 -2 2 -4 0 6 4 -6 -2 0
32x 0 -2 2 0 -2 4 4 2 -2 4 -4 -6 0 6 2 8
33x 0 -2 -2 4 -2 4 0 6 2 0 4 2 4 2 -6 0
34x 0 0 8 0 -8 8 8 0 0 8 -8 0 0 0 0 0
35x 0 -8 0 0 0 8 0 0 8 0 8 0 0 0 0 0
36x 0 0 -4 0 -4 0 0 0 0 0 0 4 0 4 0 0
37x 0 4 0 8 0 0 0 -4 4 0 0 0 -8 0 -4 0
38x 0 -10 2 0 -2 -4 -4 2 -10 -4 4 2 0 -2 2 -8
39x 0 -2 -10 12 -10 -4 0 -2 2 0 -4 2 12 2 2 0
3Ax 0 -2 -10 0 -10 0 0 -2 2 0 0 2 0 2 2 0
3Bx 0 10 -2 4 2 0 -4 -2 10 4 0 -2 -4 2 -2 0
3Cx 0 4 8 0 8 0 0 -4 -4 0 0 0 0 0 4 0
3Dx 0 -8 4 8 -4 0 0 0 -8 0 0 -4 -8 4 0 0
3Ex 0 -4 -4 0 4 8 8 -4 -4 8 -8 -4 0 4 -4 0
3Fx 0 4 -4 0 -4 -8 0 4 -4 0 -8 -4 0 -4 -4 0
Table of linear approximations for the S - 5
00x 01x 02x 03x 04x 05x 06x 07x 08x 09x 0Ax 0Bx 0Cx 0Dx 0Ex 0Fx
00x 32 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
Page 170
01x 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
02x 0 4 -2 2 -2 2 -4 0 4 0 2 -2 2 -2 0 -4
03x 0 0 -2 6 -2 -2 4 -4 0 0 -2 6 -2 -2 4 -4
04x 0 2 -2 0 0 2 -2 0 0 2 2 4 -4 -2 -2 0
05x 0 2 2 -4 0 10 -6 -4 0 2 -10 0 4 -2 2 4
06x 0 -2 -4 -6 -2 -4 2 0 0 -2 0 -2 -6 -8 2 0
07x 0 2 0 2 -2 8 6 0 -4 6 0 -6 -2 0 -6 -4
08x 0 0 2 6 0 0 -2 -6 -2 2 4 -12 2 6 -4 4
09x 0 -4 6 -2 0 -4 -6 -6 6 -2 0 -4 2 -6 -8 -4
0Ax 0 4 0 0 -2 -6 2 2 2 2 -2 2 4 -4 -4 0
0Bx 0 4 4 4 6 2 -2 -2 -2 -2 -2 2 0 -8 -4 0
0Cx 0 2 0 -2 0 2 4 10 -2 4 -2 -8 -2 4 -6 -4
0Dx 0 6 0 2 0 -2 4 -10 -2 0 -2 4 -2 8 -6 0
0Ex 0 -2 -2 0 -2 4 0 2 -2 0 4 2 -4 6 -2 -4
0Fx 0 -2 -2 8 6 4 0 2 2 4 8 -2 8 -6 2 0
10x 0 2 -2 0 0 -2 -6 -8 0 -2 -2 -4 0 2 10 -20
11x 0 2 -2 0 4 2 -2 -4 4 2 2 0 -8 -6 2 4
12x 0 -2 0 -2 2 -4 -2 -8 4 6 4 6 -2 4 -6 0
13x 0 -6 0 2 -2 4 2 0 4 -6 4 2 -6 4 -2 0
14x 0 4 -4 0 0 0 0 0 -4 -4 4 4 0 4 -4 0
15x 0 4 0 -4 -4 4 -8 -8 0 0 -4 4 8 4 0 4
16x 0 0 6 6 2 -2 4 0 4 0 6 2 2 2 0 0
17x 0 4 -6 -2 6 -2 -4 4 4 -4 -6 2 -2 2 0 4
18x 0 6 0 2 4 -10 -4 2 2 0 -2 0 2 4 -2 -4
19x 0 2 4 -6 0 -2 4 -2 6 8 6 4 10 0 2 -4
1Ax 0 2 2 -8 -2 4 0 2 -2 0 4 2 0 -2 -2 0
1Bx 0 2 6 -4 -6 0 0 2 6 8 0 -2 -4 -6 -2 0
1Cx 0 0 -2 2 4 0 -6 2 -2 6 -4 0 2 -2 0 0
Page 171
1Dx 0 4 -2 6 -8 0 -2 2 10 -2 -8 -8 2 2 0 4
1Ex 0 -4 -8 0 -2 -2 -2 2 -2 2 -2 6 4 4 4 0
1Fx 0 -4 8 -8 2 -6 -6 -2 -2 2 -2 -2 -8 0 0 -4
20x 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
21x 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
22x 0 -4 -2 2 -2 2 -4 8 -4 0 -6 6 2 -2 -16 -12
23x 0 0 -2 -2 6 -2 -4 4 0 0 -2 -2 -2 6 4 -4
24x 0 -2 6 4 0 6 -2 4 4 -6 -2 4 0 14 2 0
25x 0 6 2 0 0 6 2 0 -4 -6 2 -8 0 -2 6 -4
26x 0 2 4 -2 -2 0 2 -4 4 -2 -4 -2 6 0 -2 0
27x 0 -10 0 -2 6 4 6 -4 0 6 -12 2 2 0 6 -4
28x 0 4 -2 -2 0 4 -6 2 2 -6 4 0 6 -2 -4 0
29x 0 0 2 6 0 0 6 2 2 -2 -8 0 -2 -6 0 0
2Ax 0 0 -4 -8 6 6 6 -6 6 2 -2 -2 -8 4 -4 4
2Bx 0 8 0 4 6 -2 -6 6 2 6 -2 6 -4 0 4 4
2Cx 0 2 4 -6 0 -6 0 6 -2 -4 2 -4 -2 4 6 0
2Dx 0 -2 -4 -2 0 -2 -8 2 -2 0 -6 -8 -2 0 -2 4
2Ex 0 6 2 -4 6 4 4 -2 -10 -8 0 -2 4 -2 2 0
2Fx 0 6 -6 -4 6 -4 4 -2 2 4 4 -6 0 2 -2 -4
30x 0 2 -2 0 -4 -6 -2 -4 4 2 2 0 0 2 2 4
31x 0 2 -2 0 0 -2 2 0 0 -2 -2 -4 0 2 2 4
32x 0 6 0 -2 -2 8 2 4 0 10 0 2 -2 4 2 0
33x 0 -6 0 10 2 0 -2 -4 0 6 0 -10 2 4 -2 0
34x 0 0 -12 4 -4 0 4 -8 -4 0 -4 0 -4 -4 0 0
35x 0 -8 0 0 8 -4 4 0 0 -4 -4 0 4 4 -4 4
36x 0 4 -2 -6 -2 -2 8 0 4 -4 -2 -2 6 2 -4 0
37x 0 -8 -6 -6 -6 6 0 4 12 0 2 -2 2 2 4 -4
38x 0 2 4 -6 0 -2 4 -2 -6 4 -6 0 6 4 -2 0
Page 172
39x 0 -2 8 2 -4 6 -4 -6 -2 -4 2 4 -2 0 2 0
3Ax 0 6 -10 0 2 4 0 -2 6 -4 0 2 4 -2 -2 -4
3Bx 0 -2 -6 -4 -10 0 -8 -2 -10 4 4 -2 0 2 -2 4
3Cx 0 -8 -6 -2 0 -4 2 2 -6 2 4 0 10 -2 4 4
3Dx 0 4 2 2 4 4 -2 2 -2 10 0 0 2 2 4 0
3Ex 0 -4 4 -4 2 2 -2 2 2 -2 -2 -2 4 -4 0 4
3Fx 0 -4 -4 -4 14 6 -6 -2 2 -2 6 -2 0 0 -4 0
Table of linear approximations for the S - 6
00x 01x 02x 03x 04x 05x 06x 07x 08x 09x 0Ax 0Bx 0Cx 0Dx 0Ex 0Fx
00x 32 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
01x 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
02x 0 0 0 0 2 -6 2 -6 2 6 -2 2 -4 0 0 4
03x 0 0 0 0 -2 -2 -2 -2 -2 -6 2 -2 4 8 0 4
04x 0 0 2 -2 2 -2 8 0 2 2 0 4 4 8 6 -2
05x 0 0 6 -6 2 6 4 -4 -2 -2 -8 4 8 4 -2 -10
06x 0 4 -2 -2 0 0 2 -2 0 0 -2 2 -8 4 2 2
07x 0 -4 2 2 4 -4 2 -2 0 0 2 -2 4 0 -6 2
08x 0 2 -2 0 -4 -2 -2 -8 2 0 8 6 6 -4 0 -2
09x 0 -2 6 4 0 6 2 0 -2 0 4 6 -2 0 0 10
0Ax 0 2 2 4 2 4 -8 2 0 2 -2 0 -6 -4 4 -2
0Bx 0 -2 -6 8 2 0 8 -2 0 -2 -10 4 2 0 -4 2
0Cx 0 -2 0 2 2 -4 2 8 -4 -2 0 -2 -2 -4 2 4
0Dx 0 2 4 2 -2 -4 2 4 4 2 -4 -2 2 12 10 0
0Ex 0 2 0 6 -4 2 -4 -2 -2 0 -2 -4 -6 8 2 4
0Fx 0 -2 4 -2 -4 6 0 -2 2 0 -2 0 -2 0 2 0
10x 0 2 0 -2 0 2 -4 -14 -4 -2 -4 -6 0 2 -12 10
Page 173
11x 0 2 0 -2 4 -2 8 6 -4 -2 -4 -6 4 -2 0 -2
12x 0 2 0 -2 -2 0 2 -8 -6 8 -2 8 -4 2 4 -2
13x 0 2 0 -2 -2 0 -6 0 -2 4 -6 -4 0 -2 8 10
14x 0 -2 2 0 2 -4 -4 -2 -2 -4 -4 2 -4 -2 -6 -4
15x 0 6 -2 -4 6 -8 -4 -2 2 8 4 -6 -4 6 -2 0
16x 0 -6 6 0 4 2 -6 0 0 -2 -2 4 0 2 -2 0
17x 0 -6 2 4 -4 2 -2 4 0 6 -6 0 0 2 -6 4
18x 0 0 -2 2 0 0 -2 2 -2 2 4 -4 2 -2 0 0
19x 0 -12 -2 -10 -8 -4 6 -2 -6 -6 8 -4 -2 6 4 0
1Ax 0 8 2 -2 2 2 -4 0 0 -8 6 2 -2 -2 -4 0
1Bx 0 -4 2 2 6 2 0 0 -8 4 -2 -2 2 -2 0 0
1Cx 0 0 0 0 -2 -6 2 -2 0 -4 4 8 2 -6 2 2
1Dx 0 4 4 0 -2 -10 -2 -2 0 -8 -8 0 2 -2 -2 -6
1Ex 0 4 8 -4 -4 -4 0 0 -2 2 -2 -6 6 -2 2 2
1Fx 0 0 -4 4 0 -4 0 4 2 2 -2 -2 -2 2 -2 2
20x 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
21x 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
22x 0 4 0 -4 -2 2 -2 10 2 -6 -2 14 0 0 4 12
23x 0 4 0 -4 2 -2 2 6 -2 -2 2 -6 0 0 -4 4
24x 0 0 -2 2 -2 2 0 -8 -2 -2 0 -4 4 0 10 2
25x 0 0 2 -2 -2 -6 -4 4 2 2 0 4 0 4 -6 2
26x 0 8 2 6 0 4 6 6 -4 0 6 -2 4 4 -6 -2
27x 0 0 6 10 -4 -8 -2 -2 -12 8 2 2 0 0 2 -2
28x 0 2 2 -4 0 2 -2 0 -2 4 0 -2 6 -12 4 2
29x 0 -2 2 8 4 -6 -6 0 2 -4 -4 -2 6 0 4 -2
2Ax 0 6 -2 4 2 0 -4 2 -4 -6 -2 -4 -2 4 4 2
2Bx 0 2 -2 0 10 4 -4 -2 4 -2 6 0 6 8 4 -2
2Cx 0 -2 8 -6 2 4 2 0 4 -2 0 -10 -2 -4 2 4
Page 174
2Dx 0 2 4 2 -2 4 -6 4 -4 2 4 -2 2 -4 2 -8
2Ex 0 6 -8 -6 0 -6 0 -2 6 4 -2 0 6 0 -2 4
2Fx 0 2 4 10 -8 6 4 -2 10 4 6 -4 2 0 -2 0
30x 0 2 0 -2 0 2 4 -6 0 2 0 -2 -4 -2 8 -2
31x 0 2 0 -2 4 -2 0 -2 0 2 0 -2 0 -6 4 2
32x 0 -2 0 2 2 -8 -2 0 -2 -8 2 0 -12 -2 4 -6
33x 0 -2 0 2 -6 0 -2 0 2 4 -2 4 0 2 0 -2
34x 0 -2 -2 4 -2 0 -4 -2 -2 -4 0 -2 8 2 2 4
35x 0 -10 10 0 2 -4 -4 -2 10 0 0 -2 0 2 -2 0
36x 0 -10 -6 0 -4 6 -2 0 0 -6 -6 -4 0 -2 2 0
37x 0 6 6 4 -4 -2 10 -4 -8 -6 -2 0 0 -2 -2 4
38x 0 0 -6 6 4 4 -2 -6 -2 -6 8 0 -2 2 0 0
39x 0 4 2 2 -4 0 -2 -2 2 -6 -4 0 2 2 4 0
3Ax 0 4 6 -2 -6 -2 -8 0 0 -4 2 2 6 2 0 0
3Bx 0 8 -2 -6 -10 6 -4 0 0 0 -6 -2 -6 2 -4 -8
3Cx 0 0 0 0 -2 2 2 6 -4 0 0 -4 -2 6 -2 -2
3Dx 0 4 -4 8 -2 -2 6 -2 12 -4 -4 -4 -2 -6 2 -2
3Ex 0 0 -8 0 8 4 -4 0 -6 2 -6 2 6 2 2 -2
3Fx 0 -4 -12 0 -12 -4 -4 4 -2 2 2 -2 6 -2 -2 -2
Table of linear approximations for the S - 7
00x 01x 02x 03x 04x 05x 06x 07x 08x 09x 0Ax 0Bx 0Cx 0Dx 0Ex 0Fx
00x 32 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
01x 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
02x 0 0 2 -6 4 -4 2 2 2 2 0 0 -2 -2 0 0
03x 0 0 -2 6 0 0 2 -6 2 2 -4 -4 -6 2 0 8
04x 0 0 2 2 0 -4 -6 -2 4 4 10 2 4 0 -6 6
Page 175
05x 0 0 2 10 0 4 -6 -2 0 -8 6 -2 0 -4 6 10
06x 0 4 0 -4 -8 0 4 -4 -2 -6 -2 2 6 -2 2 -6
07x 0 -4 4 0 4 4 -4 4 2 -2 6 2 6 -2 -2 -2
08x 0 -4 0 4 -2 -2 -2 6 -4 4 0 0 -2 2 2 -2
09x 0 4 -4 0 2 -6 -2 -10 0 0 0 0 -2 -6 -2 -6
0Ax 0 0 -2 -10 2 -2 -4 0 2 6 0 4 0 0 2 2
0Bx 0 0 -2 -2 10 -2 -4 0 6 -6 4 0 4 -4 -2 -2
0Cx 0 0 -2 -2 2 -6 0 0 0 -4 -2 2 -2 -6 4 0
0Dx 0 0 2 2 -2 -2 0 -8 0 4 2 -2 2 -2 -4 -8
0Ex 0 0 0 0 2 2 6 -2 -2 -6 -6 6 -4 -8 -4 0
0Fx 0 0 0 0 2 2 -2 6 6 -6 2 6 -4 0 4 0
10x 0 -2 2 4 0 -2 -2 0 -2 4 4 6 -2 -4 8 -14
11x 0 2 -2 4 -4 -2 -2 4 -2 0 0 -2 10 4 -8 -2
12x 0 -2 0 2 -4 2 -4 -10 0 -2 0 -14 4 -6 4 -2
13x 0 2 0 6 4 6 4 -6 0 -6 0 -2 -4 6 -4 -6
14x 0 2 8 6 0 -10 4 -2 6 8 -2 -4 -2 -4 2 4
15x 0 -2 -4 -2 4 -2 4 -6 2 0 -2 0 -2 0 -2 -4
16x 0 -2 2 -4 -8 2 2 0 0 -2 -2 0 0 -6 -2 4
17x 0 2 2 -8 -8 -10 2 -4 -12 6 2 0 4 2 2 4
18x 0 2 -2 -4 2 0 -4 6 2 8 0 -6 0 2 2 -8
19x 0 -2 6 -8 2 -4 -4 -6 6 0 12 2 -4 2 -2 0
1Ax 0 -2 0 2 -2 0 -2 4 0 2 -4 2 2 0 -2 0
1Bx 0 2 4 2 2 0 6 0 4 2 4 -2 2 4 2 0
1Cx 0 2 0 -2 -2 8 2 0 2 0 6 0 -4 2 4 -2
1Dx 0 -2 8 2 -2 -4 2 4 2 -4 -2 4 -12 -2 -4 -6
1Ex 0 2 6 -4 -2 0 4 2 8 -2 -2 0 2 0 0 2
1Fx 0 -2 2 4 2 0 4 -2 0 2 2 0 6 0 0 -2
20x 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
Page 176
21x 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
22x 0 0 2 2 -4 4 -6 2 2 2 0 -8 -2 -2 -16 -8
23x 0 0 -2 -2 0 0 2 2 2 2 -4 4 2 -6 -8 8
24x 0 0 -2 6 0 4 -2 2 -4 4 -2 6 4 0 -2 2
25x 0 0 -2 -2 0 -4 -2 2 0 0 2 -6 -8 4 2 -2
26x 0 -4 -4 0 -8 0 -8 0 6 2 2 6 -2 -2 -2 -2
27x 0 -12 0 4 -4 -4 8 0 2 -2 2 -2 -2 -2 -6 2
28x 0 0 -4 4 -2 -6 -6 -2 4 -8 -4 8 6 14 -2 -2
29x 0 0 0 0 2 -2 2 -2 0 4 -4 0 -2 6 -6 2
2Ax 0 -4 2 -2 2 2 0 0 -6 2 4 4 0 -4 -2 2
2Bx 0 4 10 6 2 2 0 -8 6 6 -8 8 4 0 2 -2
2Cx 0 4 6 2 2 -2 0 12 0 0 -2 -2 6 -10 4 -4
2Dx 0 -4 2 6 -2 -6 -8 4 0 0 -6 -6 -6 2 4 4
2Ex 0 4 0 4 -6 -2 6 2 -2 -2 2 2 4 4 4 -4
2Fx 0 12 -8 4 2 -2 -2 2 6 6 2 2 -4 -4 -4 4
30x 0 2 2 0 4 6 2 0 -2 8 4 2 2 4 -4 2
31x 0 6 -2 0 0 6 2 4 -2 4 0 -6 -2 -4 -4 -2
32x 0 2 0 6 0 -6 0 -2 0 2 0 6 0 -6 0 -2
33x 0 6 0 -6 0 6 0 -6 0 -2 0 2 0 -2 0 2
34x 0 -2 4 -2 -4 6 4 2 -2 4 2 4 -6 4 2 0
35x 0 -6 -8 6 0 -2 4 -2 2 4 10 0 2 0 6 0
36x 0 2 -2 4 -4 2 -6 -4 -8 2 2 8 -4 -6 -2 0
37x 0 6 -2 0 4 -2 2 0 4 2 -2 0 0 2 2 0
38x 0 2 -6 0 -2 4 4 -2 2 0 4 -2 -4 -2 2 0
39x 0 6 -6 -4 -2 -8 -4 2 -2 -8 0 -2 0 -2 -2 0
3Ax 0 6 4 -2 2 4 -10 -4 0 2 -8 -2 -2 4 6 0
3Bx 0 2 0 -2 -18 4 -2 0 12 2 0 2 -2 0 2 0
3Cx 0 -6 8 -2 2 4 -10 -4 -6 0 -2 0 0 -2 0 2
Page 177
3Dx 0 -2 -8 2 2 0 -2 0 -6 4 -2 4 -8 2 0 -2
3Ex 0 -6 6 -4 2 -4 0 -2 0 -2 -2 0 -2 4 -4 -2
3Fx 0 14 10 4 -2 -4 0 2 -8 -6 10 0 -6 4 -4 2
Table of linear approximations for the S - 8
00x 01x 02x 03x 04x 05x 06x 07x 08x 09x 0Ax 0Bx 0Cx 0Dx 0Ex 0Fx
00x 32 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
01x 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
02x 0 2 0 -2 -2 0 2 0 -2 0 -2 4 -4 -2 0 6
03x 0 -2 0 2 -2 4 -6 4 -2 -4 6 0 -4 2 0 2
04x 0 -2 -2 0 0 2 -2 -4 2 0 4 -2 6 0 0 14
05x 0 -2 -2 0 0 2 6 4 -2 12 -8 2 -6 4 4 2
06x 0 0 2 2 2 6 0 -4 4 4 2 2 2 -2 4 -8
07x 0 -4 2 -10 -6 2 8 0 0 -4 -2 2 -2 -2 0 0
08x 0 0 2 -2 0 0 2 -2 -2 2 0 0 2 -2 4 -4
09x 0 4 -2 -2 4 0 -6 2 2 2 0 12 -6 -6 0 -4
0Ax 0 2 -2 0 2 4 -4 -2 0 -2 -2 4 6 -4 0 -2
0Bx 0 2 2 12 6 8 4 -2 4 -6 -2 4 -2 -4 4 2
0Cx 0 -2 0 -2 0 2 0 -6 0 2 -4 -10 0 6 4 -6
0Dx 0 2 -4 -2 4 2 0 6 0 -2 0 6 -4 6 4 -2
0Ex 0 0 0 4 -2 2 2 2 -2 -6 2 2 4 4 4 0
0Fx 0 0 4 0 -6 -2 -6 2 -2 2 6 6 8 0 4 0
10x 0 0 0 0 0 0 0 -8 0 0 0 0 0 -8 0 -16
11x 0 0 0 0 0 -8 0 0 0 8 0 -8 0 8 0 0
12x 0 2 0 -2 -2 0 2 8 -2 0 -2 4 -4 6 0 -10
13x 0 -2 0 2 -2 -4 10 4 -2 4 -10 8 -4 -6 0 2
14x 0 -2 -6 -4 4 -2 -2 -4 -2 4 -4 -2 -2 0 4 2
Page 178
15x 0 -2 2 4 -12 6 -2 4 -6 -8 -8 2 2 4 0 -2
16x 0 0 6 -10 -2 -6 0 -4 8 0 -6 2 -6 -2 0 4
17x 0 -4 -2 2 6 -2 0 0 4 0 -2 2 6 -2 4 4
18x 0 -4 2 2 0 4 2 2 6 -2 0 -4 2 2 -4 -8
19x 0 0 6 10 -4 4 -6 -2 2 -2 0 0 -6 -2 0 0
1Ax 0 -2 6 -4 -6 0 -4 2 0 2 -2 0 6 0 0 2
1Bx 0 -2 2 0 -10 4 4 -6 -4 -2 -2 -8 -2 0 -4 -2
1Cx 0 -6 -4 -2 4 2 0 6 4 2 4 2 8 2 0 -6
1Dx 0 -2 -8 -2 0 2 -8 2 -4 -2 0 2 4 2 0 -2
1Ex 0 -4 -4 4 2 2 2 -2 2 -6 -6 -2 -4 0 0 0
1Fx 0 -4 0 0 -10 -2 2 -2 -6 2 6 2 0 -4 0 0
20x 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
21x 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
22x 0 -2 4 -2 2 0 -6 4 -2 -4 -6 -4 0 -2 16 2
23x 0 2 -4 2 2 -4 -6 8 -2 0 -6 -8 0 -6 -8 -2
24x 0 2 2 -8 0 6 2 4 -2 0 4 2 2 0 0 2
25x 0 2 2 -8 0 6 -6 -4 2 4 0 -2 -2 -4 -4 -2
26x 0 8 2 -6 -2 -6 -4 0 0 -8 6 -2 -6 -2 4 0
27x 0 -4 -6 -2 -10 -2 -4 4 4 0 2 6 -2 -2 0 0
28x 0 0 2 -2 0 0 -6 6 -6 -2 -4 -4 -2 -6 -8 0
29x 0 4 -2 -2 4 0 2 -6 -2 -2 -4 8 6 6 -12 0
2Ax 0 -2 2 0 -2 -4 4 2 4 -2 -2 0 6 -8 4 -2
2Bx 0 -10 -2 -4 2 8 4 2 -8 2 6 0 -2 0 0 2
2Cx 0 -6 4 -2 0 -2 -4 -14 0 -2 0 6 0 2 0 2
2Dx 0 -2 0 -2 4 -2 -4 -2 -8 2 -4 -2 4 -6 8 -2
2Ex 0 0 0 4 2 -10 -2 -2 -10 2 2 2 0 0 0 -4
2Fx 0 8 -4 0 -2 10 -2 -2 -2 10 6 -2 -4 -4 0 4
30x 0 -4 0 4 0 4 0 4 0 4 0 -4 0 -12 0 4
Page 179
31x 0 4 0 -4 0 4 0 4 0 4 0 -4 0 -4 0 -4
32x 0 -6 -4 -6 2 4 2 0 -2 0 2 0 0 2 8 -2
33x 0 6 4 6 2 0 2 4 -2 4 2 -4 0 6 0 2
34x 0 -2 -10 0 -4 -2 2 0 2 0 -4 -2 10 -4 -4 2
35x 0 6 -2 0 -4 -2 2 0 6 4 0 2 6 0 0 -2
36x 0 4 6 2 2 -6 4 4 -4 0 6 2 2 -6 0 0
37x 0 0 6 6 -6 -2 -4 0 0 8 -6 2 6 2 4 0
38x 0 8 10 -2 0 8 2 -2 -6 6 -4 4 6 2 0 0
39x 0 4 -2 -2 -4 0 -6 2 6 -2 -4 0 -2 6 4 0
3Ax 0 -10 10 0 6 -4 4 2 -4 -2 6 0 -2 0 -4 -2
3Bx 0 6 -2 -4 2 0 4 2 -8 -6 -2 0 6 0 0 2
3Cx 0 2 0 2 -4 -6 4 2 4 2 8 -2 0 2 4 -2
3Dx 0 -2 12 -6 8 2 -4 6 4 -2 -4 -2 4 2 -4 2
3Ex 0 -8 4 0 -2 2 -2 6 10 6 2 2 0 0 -4 0
3Fx 0 -8 0 4 2 -2 -10 -2 -6 6 -2 6 -4 4 -4 0
5. Tables simplified distributions of differences
By arry, you see the values of the differences in outputs of the table S and y input bits of the S-table
corresponding to differences in inputs. The expectancy is Tij64.
Distributions of the S - Table 1
00x 01x 02x 03x 04x 05x 06x 07x 08x 09x 0Ax 0Bx 0Cx 0Dx 0Ex 0Fx
0x 32 32 32 32 32 32 32 32 32 32 32 32 32 32 32 32
1x 26 33 36 30 34 34 31 31 33 33 32 32 32 30 31 34
2x 21 35 41 30 36 27 27 38 38 31 27 32 30 37 35 27
3x 26 34 30 31 32 33 34 32 29 34 32 31 34 33 35 32
4x 16 43 42 22 44 24 21 44 44 22 25 41 23 39 40 22
Page 180
5x 32 32 32 32 32 32 32 32 32 32 32 32 32 32 32 32
Distributions of the S - Table 2
00x 01x 02x 03x 04x 05x 06x 07x 08x 09x 0Ax 0Bx 0Cx 0Dx 0Ex 0Fx
0x 32 32 32 32 32 32 32 32 32 32 32 32 32 32 32 32
1x 30 32 34 32 32 32 32 32 32 32 32 32 32 34 32 30
2x 25 37 36 29 35 30 27 37 34 29 32 33 31 34 35 28
3x 25 30 36 36 35 35 27 31 37 33 29 29 30 30 37 32
4x 20 40 34 32 40 24 34 32 42 24 32 32 22 40 32 32
5x 32 32 32 32 32 32 32 32 32 32 32 32 32 32 32 32
Distributions of the S - Table 3
00x 01x 02x 03x 04x 05x 06x 07x 08x 09x 0Ax 0Bx 0Cx 0Dx 0Ex 0Fx
0x 32 32 32 32 32 32 32 32 32 32 32 32 32 32 32 32
1x 25 35 35 31 31 36 32 31 34 29 33 34 35 30 30 31
2x 23 33 30 37 37 33 34 29 37 30 35 30 29 34 27 34
3x 25 33 36 29 30 35 36 31 34 31 33 35 30 29 32 33
4x 17 40 39 29 34 34 33 29 41 21 30 38 35 33 27 32
5x 32 32 32 32 32 32 32 32 32 32 32 32 32 32 32 32
Distributions of the S - Table 4
00x 01x 02x 03x 04x 05x 06x 07x 08x 09x 0Ax 0Bx 0Cx 0Dx 0Ex 0Fx
0x 32 32 32 32 32 32 32 32 32 32 32 32 32 32 32 32
1x 30 32 32 32 32 32 34 32 32 30 32 32 32 32 32 34
2x 23 34 38 32 38 32 28 30 34 36 32 26 32 26 30 41
Page 181
3x 30 32 32 32 32 32 30 32 32 34 32 32 32 32 32 34
4x 19 36 40 32 40 30 26 32 36 34 30 28 32 28 32 37
5x 32 32 32 32 32 32 32 32 32 32 32 32 32 32 32 32
Distributions of the S - Table 5
00x 01x 02x 03x 04x 05x 06x 07x 08x 09x 0Ax 0Bx 0Cx 0Dx 0Ex 0Fx
0x 32 32 32 32 32 32 32 32 32 32 32 32 32 32 32 32
1x 29 32 32 32 32 32 31 32 32 32 32 34 32 34 32 32
2x 30 32 32 32 32 33 33 32 33 32 32 33 32 31 31 32
3x 22 39 39 27 29 35 37 27 37 29 30 33 35 29 27 37
4x 12 43 51 22 50 22 14 42 45 23 19 41 20 40 44 24
5x 32 32 32 32 32 32 32 32 32 32 32 32 32 32 32 32
Distributions of the S - Table 6
00x 01x 02x 03x 04x 05x 06x 07x 08x 09x 0Ax 0Bx 0Cx 0Dx 0Ex 0Fx
0x 32 32 32 32 32 32 32 32 32 32 32 32 32 32 32 32
1x 27 35 31 32 34 31 31 34 32 33 33 32 35 29 33 30
2x 25 31 33 36 37 34 32 27 34 29 35 32 31 34 29 33
3x 24 32 35 30 33 30 35 36 34 35 32 30 36 31 26 33
4x 15 37 47 27 44 28 19 35 35 39 30 26 33 25 32 40
5x 32 32 32 32 32 32 32 32 32 32 32 32 32 32 32 32
Distributions of the S - Table 7
00x 01x 02x 03x 04x 05x 06x 07x 08x 09x 0Ax 0Bx 0Cx 0Dx 0Ex 0Fx
0x 32 32 32 32 32 32 32 32 32 32 32 32 32 32 32 32
Page 182
1x 29 33 32 31 32 33 34 31 30 33 33 31 32 33 34 31
2x 23 28 37 36 32 30 32 34 37 35 29 31 35 35 31 27
3x 28 34 32 31 32 32 30 33 31 34 34 31 33 32 32 33
4x 20 38 41 28 38 29 26 35 42 27 24 36 25 36 39 28
5x 32 32 32 32 32 32 32 32 32 32 32 32 32 32 32 32
Distributions of the S - Table 8
00x 01x 02x 03x 04x 05x 06x 07x 08x 09x 0Ax 0Bx 0Cx 0Dx 0Ex 0Fx
0x 32 32 32 32 32 32 32 32 32 32 32 32 32 32 32 32
1x 29 33 33 30 33 32 32 33 34 31 31 34 31 33 32 31
2x 23 37 38 25 39 26 27 40 39 28 27 39 26 37 36 25
3x 30 32 33 32 33 32 31 32 33 32 32 32 31 32 33 32
4x 20 44 40 24 44 20 24 40 40 24 28 36 24 40 36 28
5x 32 32 32 32 32 32 32 32 32 32 32 32 32 32 32 32
6. Tables of the differential neuro-cryptanalyzer
Approximate tables calculated by the differential neuro-cryptanalyseur (with 10 presentations). The probability
is the value Tij.
S-Table 1
0x 1x 2x 3x 4x 5x 6x 7x 8x 9x Ax Bx Cx Dx Ex Fx
0x 0.496 0.493 0.493 0.493 0.494 0.492 0.494 0.493 0.494 0.493 0.492 0.492 0.493 0.492 0.493 0.493
1x 0.408 0.496 0.534 0.467 0.507 0.486 0.477 0.478 0.504 0.497 0.476 0.486 0.488 0.476 0.486 0.486
2x 0.326 0.505 0.572 0.423 0.511 0.414 0.403 0.522 0.518 0.443 0.413 0.471 0.441 0.517 0.494 0.412
3x 0.361 0.449 0.427 0.430 0.436 0.449 0.448 0.442 0.426 0.457 0.443 0.439 0.453 0.447 0.455 0.448
4x 0.191 0.523 0.516 0.271 0.541 0.277 0.248 0.533 0.530 0.267 0.295 0.483 0.278 0.483 0.472 0.266
5x 0.289 0.287 0.288 0.288 0.286 0.287 0.286 0.286 0.287 0.287 0.287 0.287 0.287 0.286 0.286 0.287
Page 183
S-table 2
0x 1x 2x 3x 4x 5x 6x 7x 8x 9x Ax Bx Cx Dx Ex Fx
0x 0.497 0.494 0.494 0.493 0.495 0.492 0.491 0.493 0.495 0.493 0.494 0.493 0.495 0.494 0.494 0.493
1x 0.467 0.480 0.506 0.480 0.492 0.490 0.477 0.485 0.493 0.488 0.480 0.479 0.489 0.488 0.485 0.480
2x 0.361 0.541 0.542 0.461 0.524 0.433 0.400 0.524 0.524 0.428 0.454 0.462 0.437 0.512 0.505 0.436
3x 0.321 0.449 0.484 0.453 0.468 0.467 0.377 0.455 0.466 0.454 0.429 0.427 0.427 0.445 0.482 0.430
4x 0.230 0.523 0.415 0.382 0.509 0.263 0.400 0.407 0.537 0.269 0.387 0.406 0.259 0.513 0.400 0.381
5x 0.295 0.290 0.290 0.289 0.289 0.286 0.288 0.290 0.290 0.287 0.290 0.290 0.291 0.289 0.289 0.289
S-table 3
0x 1x 2x 3x 4x 5x 6x 7x 8x 9x Ax Bx Cx Dx Ex Fx
0x 0.495 0.493 0.494 0.494 0.494 0.494 0.494 0.494 0.495 0.493 0.494 0.493 0.494 0.493 0.492 0.494
1x 0.374 0.515 0.527 0.482 0.491 0.512 0.504 0.473 0.521 0.455 0.497 0.514 0.502 0.472 0.449 0.499
2x 0.326 0.507 0.502 0.480 0.516 0.490 0.484 0.465 0.525 0.429 0.483 0.481 0.476 0.493 0.430 0.477
3x 0.331 0.454 0.472 0.436 0.435 0.464 0.452 0.425 0.463 0.436 0.445 0.456 0.443 0.415 0.433 0.449
4x 0.187 0.492 0.480 0.379 0.437 0.410 0.420 0.363 0.513 0.255 0.398 0.462 0.400 0.411 0.312 0.401
5x 0.295 0.290 0.290 0.290 0.290 0.290 0.290 0.291 0.290 0.291 0.290 0.290 0.290 0.289 0.288 0.289
S-table 4
0x 1x 2x 3x 4x 5x 6x 7x 8x 9x Ax Bx Cx Dx Ex Fx
0x 0.498 0.493 0.495 0.493 0.495 0.493 0.494 0.494 0.494 0.493 0.494 0.494 0.493 0.495 0.494 0.495
1x 0.457 0.490 0.495 0.480 0.483 0.487 0.491 0.486 0.488 0.481 0.485 0.496 0.488 0.486 0.483 0.490
2x 0.311 0.499 0.565 0.489 0.580 0.471 0.374 0.446 0.522 0.511 0.460 0.367 0.463 0.379 0.467 0.574
3x 0.405 0.438 0.452 0.439 0.439 0.445 0.430 0.435 0.443 0.449 0.436 0.429 0.434 0.424 0.446 0.461
4x 0.201 0.440 0.520 0.390 0.510 0.378 0.305 0.361 0.455 0.401 0.368 0.314 0.377 0.313 0.372 0.476
5x 0.294 0.290 0.291 0.290 0.290 0.289 0.290 0.290 0.290 0.290 0.290 0.290 0.290 0.291 0.290 0.290
Page 184
S-table 5
0x 1x 2x 3x 4x 5x 6x 7x 8x 9x Ax Bx Cx Dx Ex Fx
0x 0.496 0.494 0.495 0.494 0.493 0.493 0.494 0.493 0.494 0.493 0.494 0.493 0.493 0.493 0.493 0.493
1x 0.455 0.484 0.478 0.483 0.466 0.497 0.485 0.480 0.480 0.491 0.489 0.489 0.495 0.484 0.482 0.498
2x 0.440 0.472 0.475 0.462 0.481 0.475 0.473 0.464 0.475 0.472 0.467 0.464 0.474 0.456 0.465 0.481
3x 0.301 0.546 0.555 0.376 0.414 0.469 0.501 0.392 0.515 0.414 0.410 0.472 0.464 0.407 0.409 0.471
4x 0.157 0.609 0.707 0.272 0.647 0.285 0.184 0.538 0.627 0.283 0.247 0.524 0.260 0.496 0.543 0.331
5x 0.294 0.288 0.287 0.291 0.286 0.289 0.290 0.289 0.288 0.290 0.291 0.288 0.290 0.289 0.289 0.290
S-table 6
0x 1x 2x 3x 4x 5x 6x 7x 8x 9x Ax Bx Cx Dx Ex Fx
0x 0.499 0.493 0.495 0.494 0.493 0.493 0.493 0.493 0.494 0.494 0.493 0.493 0.493 0.494 0.496 0.494
1x 0.409 0.505 0.495 0.487 0.508 0.492 0.454 0.501 0.500 0.498 0.496 0.481 0.502 0.469 0.488 0.499
2x 0.373 0.478 0.468 0.487 0.528 0.478 0.503 0.464 0.486 0.463 0.479 0.471 0.472 0.479 0.430 0.469
3x 0.301 0.457 0.495 0.420 0.428 0.453 0.482 0.443 0.461 0.465 0.442 0.445 0.457 0.442 0.389 0.471
4x 0.153 0.477 0.680 0.341 0.622 0.345 0.194 0.449 0.453 0.513 0.373 0.316 0.414 0.289 0.414 0.518
5x 0.297 0.289 0.291 0.290 0.288 0.289 0.290 0.290 0.289 0.292 0.289 0.289 0.290 0.289 0.293 0.292
S-table 7
0x 1x 2x 3x 4x 5x 6x 7x 8x 9x Ax Bx Cx Dx Ex Fx
0x 0.497 0.494 0.495 0.494 0.493 0.493 0.493 0.494 0.495 0.493 0.493 0.493 0.493 0.494 0.493 0.494
1x 0.449 0.495 0.469 0.478 0.491 0.491 0.489 0.486 0.461 0.487 0.488 0.492 0.492 0.485 0.498 0.492
2x 0.351 0.455 0.520 0.520 0.485 0.456 0.462 0.479 0.553 0.469 0.456 0.453 0.464 0.506 0.443 0.456
3x 0.387 0.462 0.446 0.416 0.440 0.448 0.443 0.443 0.436 0.448 0.440 0.438 0.449 0.426 0.438 0.452
4x 0.221 0.462 0.524 0.341 0.495 0.317 0.290 0.414 0.524 0.336 0.291 0.432 0.308 0.442 0.469 0.335
5x 0.295 0.291 0.290 0.289 0.290 0.291 0.291 0.291 0.290 0.291 0.291 0.291 0.291 0.289 0.291 0.291
Page 185
S-table 8
0x 1x 2x 3x 4x 5x 6x 7x 8x 9x Ax Bx Cx Dx Ex Fx
0x 0.495 0.494 0.494 0.494 0.494 0.492 0.494 0.494 0.495 0.493 0.494 0.494 0.494 0.494 0.494 0.495
1x 0.443 0.500 0.496 0.463 0.502 0.465 0.473 0.500 0.491 0.468 0.472 0.493 0.474 0.494 0.491 0.474
2x 0.338 0.499 0.519 0.400 0.535 0.382 0.399 0.535 0.533 0.412 0.410 0.499 0.402 0.512 0.486 0.404
3x 0.408 0.456 0.450 0.423 0.453 0.435 0.432 0.435 0.451 0.443 0.437 0.432 0.436 0.438 0.440 0.445
4x 0.222 0.497 0.486 0.265 0.512 0.238 0.269 0.487 0.458 0.296 0.303 0.429 0.279 0.435 0.419 0.322
5x 0.294 0.291 0.291 0.292 0.290 0.291 0.292 0.290 0.290 0.291 0.291 0.290 0.292 0.289 0.290 0.291
7 Tables of the linear neuro-cryptanalyzer
S-table 1
0x 1x 2x 3x 4x 5x 6x 7x 8x 9x Ax Bx Cx Dx Ex Fx
0x 0.504 0.531 0.543 0.522 0.506 0.509 0.505 0.502 0.505 0.499 0.500 0.500 0.504 0.509 0.500 0.502
1x 0.555 0.529 0.500 0.379 0.517 0.391 0.503 0.667 0.639 0.545 0.539 0.692 0.544 0.359 0.366 0.507
2x 0.598 0.632 0.549 0.720 0.504 0.592 0.624 0.701 0.625 0.521 0.284 0.554 0.559 0.554 0.389 0.066
3x 0.690 0.729 0.706 0.639 0.506 0.753 0.549 0.514 0.576 0.733 0.550 0.519 0.323 0.655 0.289 0.240
4x 0.576 0.626 0.640 0.839 0.548 0.760 0.656 0.532 0.652 0.658 0.792 0.592 0.590 0.352 0.287 0.251
5x 0.723 0.728 0.710 0.708 0.724 0.696 0.712 0.696 0.754 0.724 0.687 0.729 0.731 0.689 0.675 0.684
S-table 2
0x 1x 2x 3x 4x 5x 6x 7x 8x 9x Ax Bx Cx Dx Ex Fx
0x 0.500 0.518 0.546 0.513 0.504 0.498 0.505 0.507 0.498 0.496 0.502 0.512 0.496 0.498 0.519 0.524
1x 0.510 0.548 0.511 0.443 0.486 0.497 0.550 0.516 0.482 0.504 0.562 0.512 0.447 0.502 0.668 0.510
2x 0.482 0.532 0.605 0.467 0.617 0.583 0.526 0.627 0.537 0.365 0.669 0.471 0.567 0.474 0.628 0.311
3x 0.579 0.560 0.663 0.620 0.603 0.526 0.496 0.303 0.464 0.633 0.597 0.634 0.395 0.460 0.616 0.786
4x 0.672 0.657 0.630 0.509 0.660 0.767 0.686 0.567 0.690 0.772 0.543 0.554 0.742 0.385 0.391 0.377
5x 0.728 0.724 0.716 0.703 0.720 0.733 0.695 0.690 0.724 0.713 0.775 0.717 0.707 0.722 0.659 0.634
Page 186
S-table 3
0x 1x 2x 3x 4x 5x 6x 7x 8x 9x Ax Bx Cx Dx Ex Fx
0x 0.494 0.528 0.550 0.510 0.503 0.507 0.506 0.511 0.501 0.495 0.506 0.505 0.505 0.503 0.498 0.512
1x 0.535 0.578 0.350 0.604 0.496 0.566 0.513 0.803 0.559 0.525 0.570 0.324 0.442 0.360 0.494 0.524
2x 0.542 0.437 0.544 0.467 0.492 0.518 0.586 0.695 0.536 0.463 0.396 0.123 0.722 0.357 0.832 0.502
3x 0.505 0.481 0.641 0.762 0.595 0.574 0.653 0.656 0.548 0.394 0.565 0.838 0.395 0.235 0.462 0.757
4x 0.505 0.572 0.616 0.583 0.608 0.627 0.398 0.563 0.556 0.367 0.617 0.880 0.819 0.368 0.784 0.629
5x 0.727 0.724 0.695 0.696 0.717 0.708 0.703 0.694 0.730 0.733 0.702 0.748 0.705 0.760 0.685 0.718
S-table 4
0x 1x 2x 3x 4x 5x 6x 7x 8x 9x Ax Bx Cx Dx Ex Fx
0x 0.502 0.527 0.543 0.521 0.492 0.497 0.512 0.500 0.500 0.495 0.503 0.516 0.498 0.491 0.504 0.507
1x 0.403 0.430 0.525 0.531 0.529 0.503 0.628 0.585 0.417 0.360 0.485 0.552 0.495 0.566 0.585 0.726
2x 0.570 0.480 0.518 0.573 0.522 0.566 0.447 0.272 0.622 0.637 0.526 0.454 0.514 0.469 0.783 0.260
3x 0.545 0.464 0.543 0.439 0.553 0.448 0.561 0.535 0.640 0.564 0.689 0.587 0.695 0.562 0.570 0.561
4x 0.641 0.689 0.649 0.524 0.762 0.669 0.448 0.632 0.597 0.502 0.536 0.610 0.659 0.241 0.740 0.623
5x 0.709 0.707 0.706 0.689 0.693 0.680 0.710 0.722 0.729 0.736 0.741 0.718 0.733 0.709 0.685 0.733
S-table 5
0x 1x 2x 3x 4x 5x 6x 7x 8x 9x Ax Bx Cx Dx Ex Fx
0x 0.498 0.531 0.547 0.515 0.499 0.495 0.507 0.520 0.502 0.513 0.504 0.485 0.512 0.507 0.499 0.509
1x 0.456 0.585 0.425 0.530 0.411 0.482 0.474 0.468 0.587 0.773 0.518 0.511 0.511 0.518 0.510 0.516
2x 0.531 0.614 0.493 0.540 0.508 0.541 0.524 0.527 0.530 0.547 0.409 0.534 0.648 0.538 0.542 0.524
3x 0.566 0.603 0.630 0.657 0.570 0.589 0.759 0.616 0.557 0.568 0.650 0.219 0.450 0.736 0.575 0.051
4x 0.604 0.596 0.469 0.618 0.533 0.715 0.650 0.451 0.587 0.720 0.514 0.344 0.440 0.627 0.725 0.949
5x 0.704 0.709 0.689 0.711 0.673 0.689 0.703 0.711 0.737 0.743 0.714 0.738 0.697 0.736 0.696 0.737
Page 187
S-table 6
0x 1x 2x 3x 4x 5x 6x 7x 8x 9x Ax Bx Cx Dx Ex Fx
0x 0.505 0.526 0.547 0.520 0.505 0.504 0.499 0.496 0.500 0.512 0.506 0.514 0.509 0.485 0.505 0.520
1x 0.455 0.460 0.482 0.514 0.448 0.645 0.435 0.487 0.531 0.301 0.540 0.486 0.598 0.675 0.656 0.503
2x 0.423 0.442 0.537 0.606 0.616 0.628 0.426 0.440 0.588 0.411 0.593 0.602 0.506 0.604 0.453 0.786
3x 0.580 0.597 0.585 0.617 0.467 0.657 0.615 0.511 0.766 0.760 0.452 0.645 0.515 0.507 0.301 0.316
4x 0.679 0.676 0.527 0.726 0.610 0.642 0.790 0.659 0.450 0.510 0.582 0.738 0.462 0.742 0.595 0.071
5x 0.709 0.712 0.709 0.755 0.712 0.727 0.683 0.706 0.709 0.707 0.700 0.745 0.712 0.682 0.740 0.645
S-table 7
0x 1x 2x 3x 4x 5x 6x 7x 8x 9x Ax Bx Cx Dx Ex Fx
0x 0.502 0.526 0.543 0.509 0.495 0.517 0.506 0.514 0.496 0.498 0.500 0.504 0.499 0.490 0.518 0.520
1x 0.408 0.363 0.458 0.563 0.494 0.557 0.439 0.725 0.465 0.373 0.474 0.541 0.613 0.575 0.576 0.749
2x 0.437 0.458 0.535 0.484 0.377 0.534 0.736 0.773 0.727 0.568 0.496 0.460 0.543 0.625 0.440 0.277
3x 0.665 0.640 0.686 0.514 0.600 0.568 0.601 0.614 0.570 0.428 0.582 0.225 0.523 0.383 0.594 0.573
4x 0.609 0.603 0.713 0.613 0.553 0.697 0.707 0.579 0.640 0.520 0.551 0.285 0.636 0.323 0.714 0.822
5x 0.701 0.722 0.697 0.710 0.721 0.712 0.744 0.719 0.731 0.701 0.717 0.698 0.718 0.724 0.696 0.688
S-table 8
0x 1x 2x 3x 4x 5x 6x 7x 8x 9x Ax Bx Cx Dx Ex Fx
0x 0.502 0.531 0.543 0.525 0.504 0.493 0.503 0.522 0.500 0.497 0.502 0.515 0.498 0.502 0.507 0.497
1x 0.545 0.601 0.578 0.604 0.489 0.519 0.398 0.511 0.445 0.454 0.456 0.657 0.507 0.502 0.505 0.498
2x 0.538 0.520 0.516 0.489 0.607 0.508 0.612 0.565 0.681 0.624 0.517 0.536 0.523 0.573 0.569 0.080
3x 0.562 0.552 0.597 0.680 0.596 0.642 0.584 0.574 0.540 0.501 0.562 0.555 0.510 0.391 0.573 0.577
4x 0.631 0.572 0.594 0.661 0.587 0.705 0.674 0.434 0.608 0.670 0.645 0.597 0.674 0.444 0.624 0.643
5x 0.731 0.724 0.729 0.693 0.731 0.700 0.728 0.751 0.699 0.710 0.726 0.697 0.723 0.636 0.736 0.640
Page 189
8. The measures of learning of the XOR tables
It comes to presentations of the 65536 examples to learn an XOR 8-bit.
TSS represents the overall error rate, success is the percentage of bits output equal to the bits
of the examples and OK is the percentage of outputs values equal to the examples presented.
Presentation TSS Success OK
1 9027,00 98.24 87.38
4 3325,00 99.37 94.98
9 3087,00 99.42 95.33
10 1734,00 99.67 97,38
11 1,390.00 99.74 97.91
12 1325,35 99.75 98.00
13 1197,76 99.77 98.19
14 1113,64 99,79 98.32
15 1051,14 99.80 98,41
16 676,32 99.87 98,98
17 396,19 99.93 99.40
18 315.32 99.98 99.53
19 178,82 99.99 99.73
20 91.81 100.00 99.87
21 41.69 100.00 99.94
22 26.25 100.00 99.97
23 20.38 100.00 99.97
24 15,22 100.00 99.98
25 10.81 100.00 99.99
26 8.13 100.00 100.00
These values are obtained by the experience for initialization of the random weight with a
learning rate Epsilon equal to 0.5. The number of binary inputs is 16, the number of hidden
neurons is 32 and the number of neurons output is 8.
Page 190
We note that at the end of a single presentation was 87% of the correct output values what is
ample in Cryptography.
Similarly, the number of presentation doesn't have to exceed 30 while simpler operations such
as XOR 1-bit or 4-bit XOR to 200 to 500 presentations according to the random weight
initialisation.
9. The massively parallel machines
MasPar
Machine SIMD created by the American company MASPAR of Sunnyvale, California.
The MP-1 machine contains an o-ring dimension grid 2 with 256 x 256 elementary processors
(PE) 4-bit. 8 Directions are possible.
Its clock rate is 12.5 MHz.
It contains a record of 16-bit flags, one Executive Bit (E.bit), a bit (M.bit), a Transmission Bit
(T.bit) Memory and a Recieve Bit (R.bit) that allow the user to control PE, memory and
cellular communication.
Communication between PE can be done in 3 ways depending on whether the user uses or not
3 posts S1, S2 or S3 routers.
Each PE has 16 KB of RAM and 40 registers of 32-bit. Operations are on 1,8,16,32 or 64-bit.
The PE simulate floating-point arithmetic.
The programming is done through MPL (Maspar Parallel Language) equivalent to the C
added MPAL (Maspar Parallel Application Library) library.
The performance of this machine ranges from 0.55 to 2.4 GigaFlops (floating Operations per
second).
CM-5
This hybrid SIMD and MIMD machine was manufactured by Thinking Machine. This is done
ten improved, synchronized with the delta-parallelism MIMD machine.
It consists of 16384 Sparc processors and 4 vector processors Texas Instrument.
Each node has 32 MB of DRAM with a bandwidth of 1 GB/s.
Page 191
A node
It has 3 communications networks: control, data and diagnostics.
Transfer to 4-neighbours time: 20 MB/s
Transfer to 16-neighbours time: 10 MB/s
Time of transfer to other neighbors: 5 MB/s
The structure of the communication links is Fat-Tree (tree with 3 levels of depths). Routing is
a Wormhole.
User operations are of three kinds: distribution (for the memory management), combination
(management of parallelism) and global. The CMMD software is a library of functions in C,
Lisp and Fortran.
Its performances are 45 Gflops to 1024 processors.